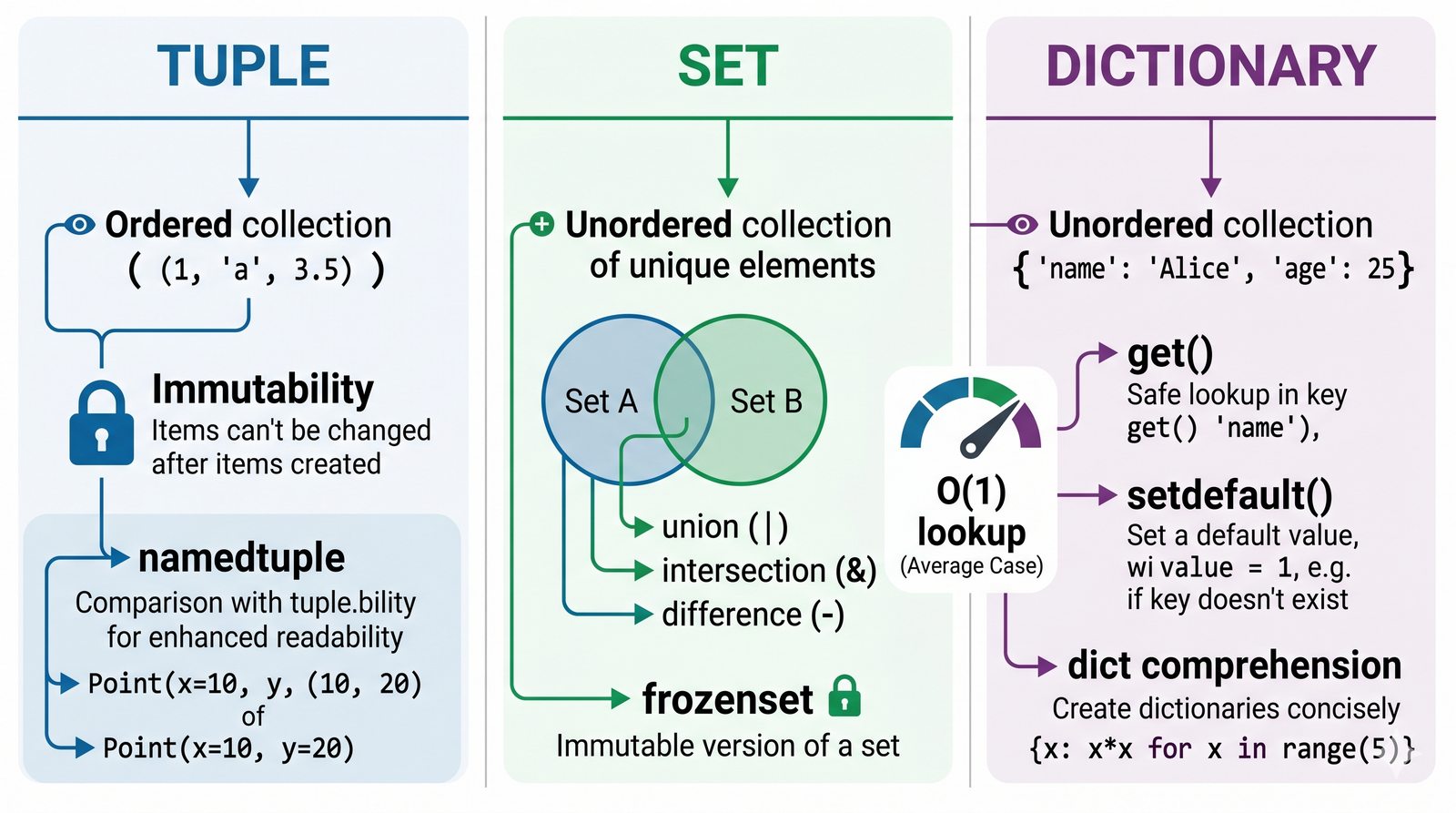
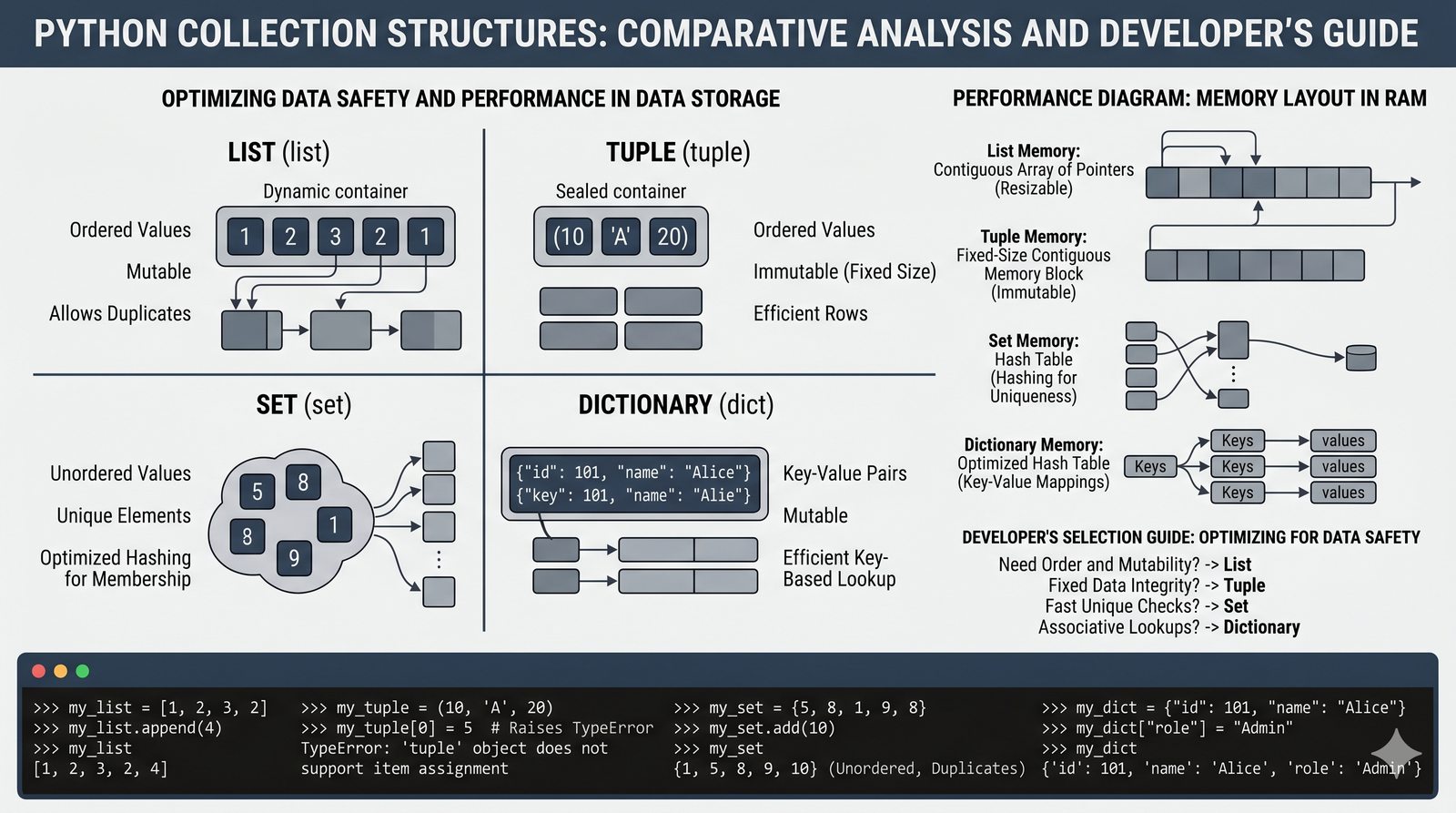
Moduł poświęcony jest trzem zaawansowanym strukturom danych w Pythonie: krotkom (tuple), zbiorom (set) oraz słownikom (dict). Krotki to niemutowalne kolekcje uporządkowane, idealne do przechowywania stałych rekordów i konfiguracji, z możliwością rozpakowywania i użycia jako kluczy słowników. Zbiory przechowują unikalne wartości i oferują wydajne operacje matematyczne (suma, przecięcie, różnica) oraz błyskawiczne wyszukiwanie elementów w czasie O(1). Słowniki to mutowalne struktury klucz-wartość zoptymalizowane pod kątem szybkiego dostępu do danych, obsługujące zaawansowane techniki, takie jak wyrażenia słownikowe (dict comprehension) i słowniki zagnieżdżone. W module znajdują się również praktyczne programy i ćwiczenia utrwalające omawiane koncepcje.
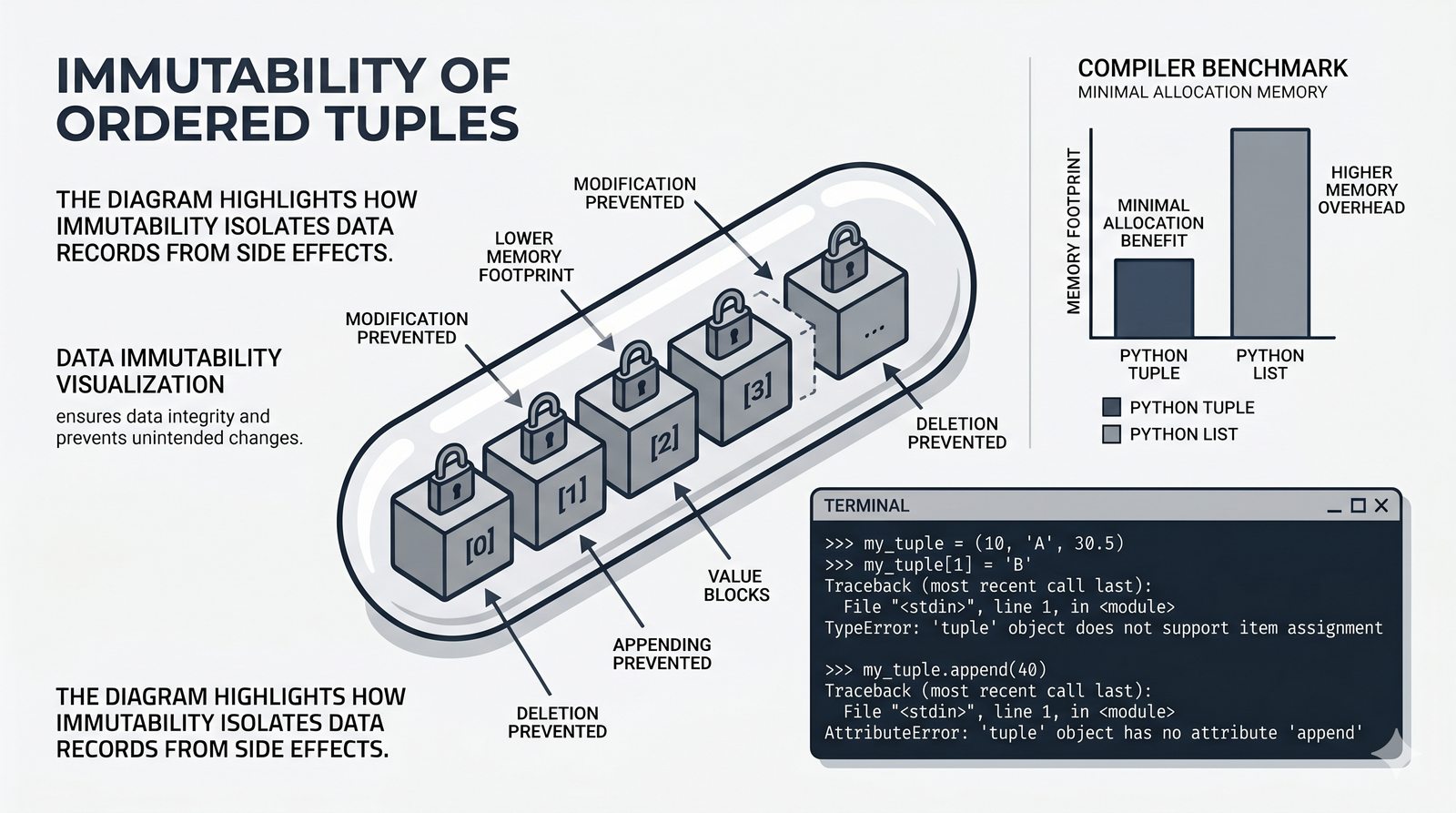
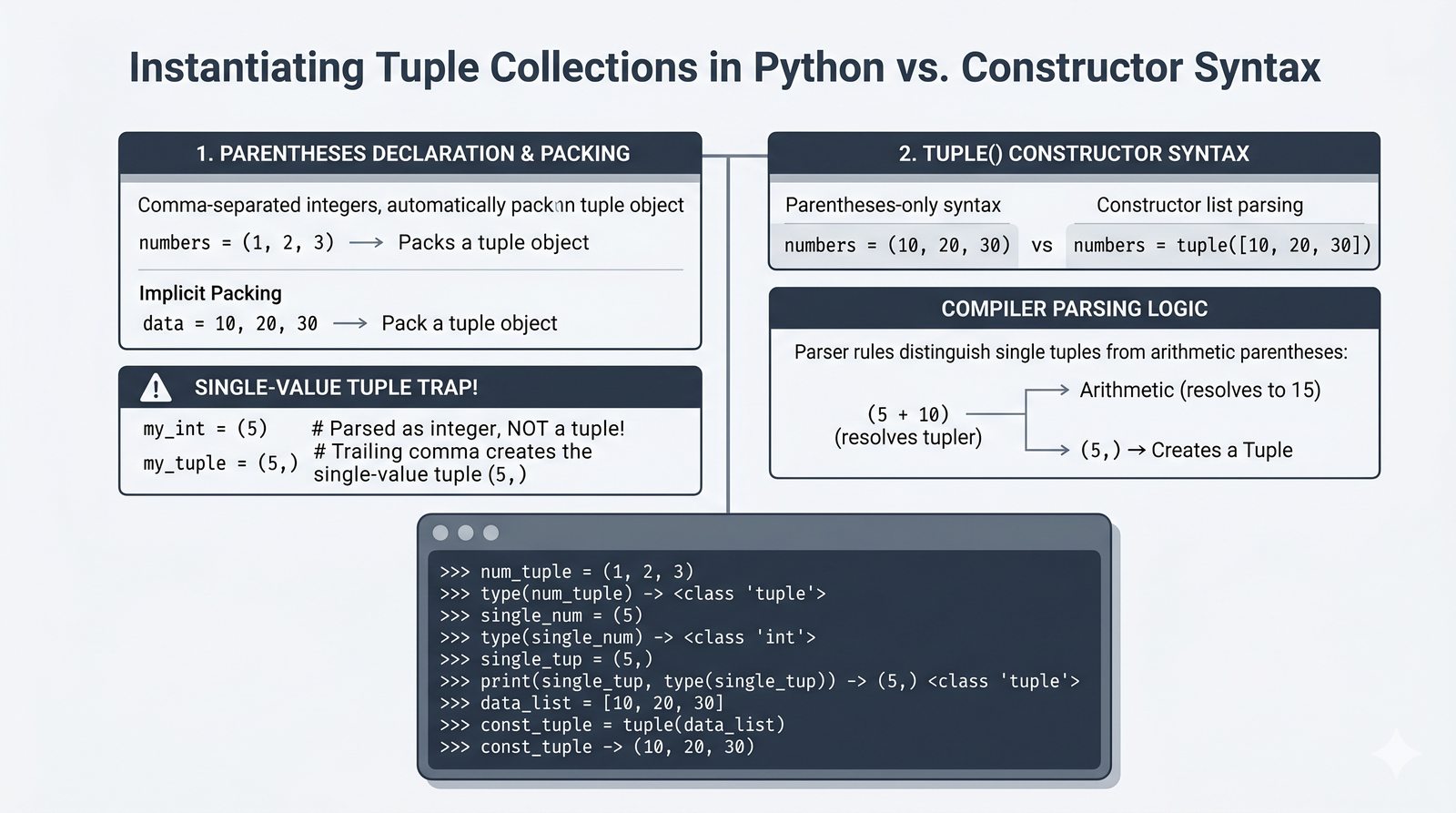
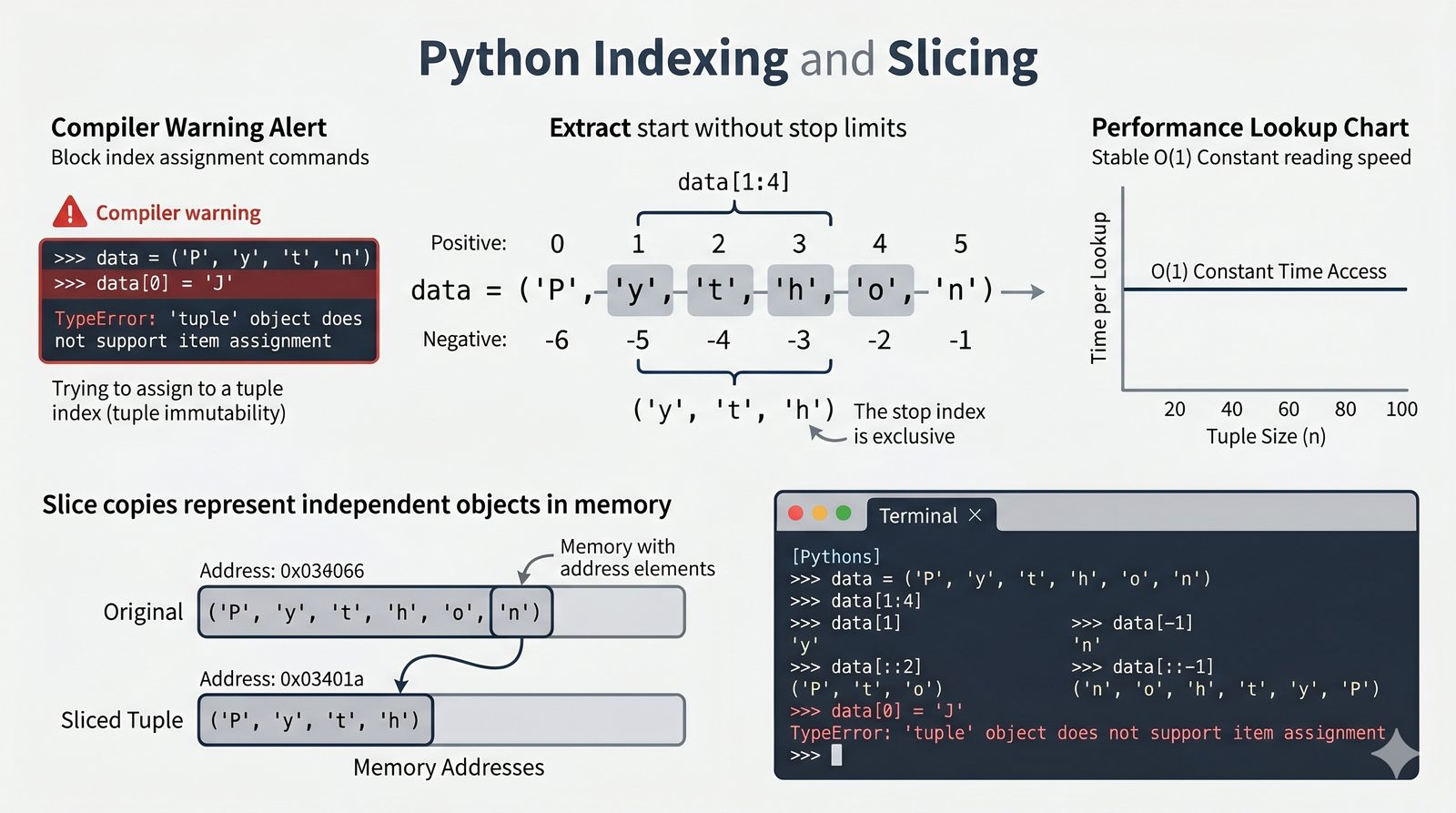
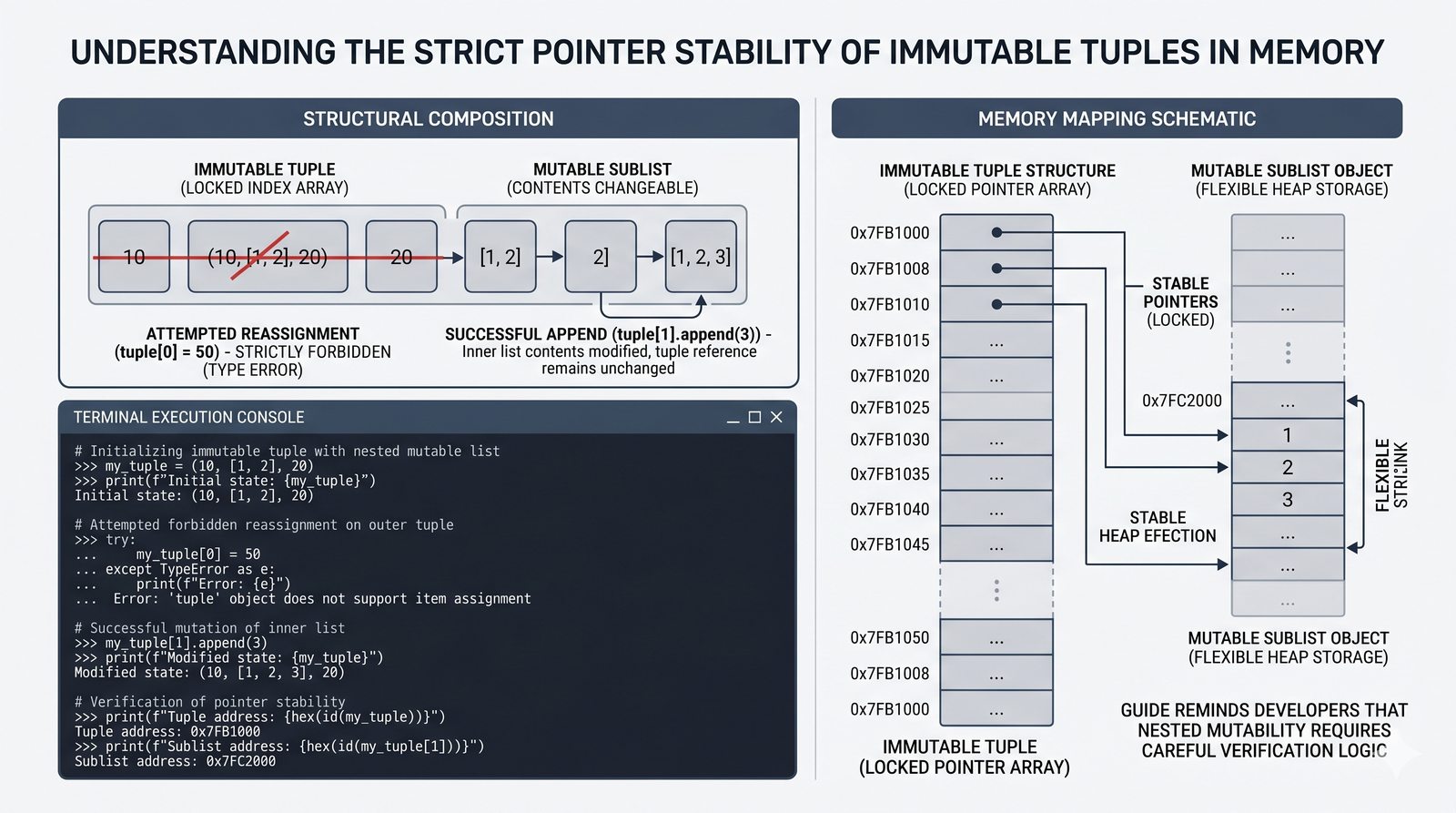
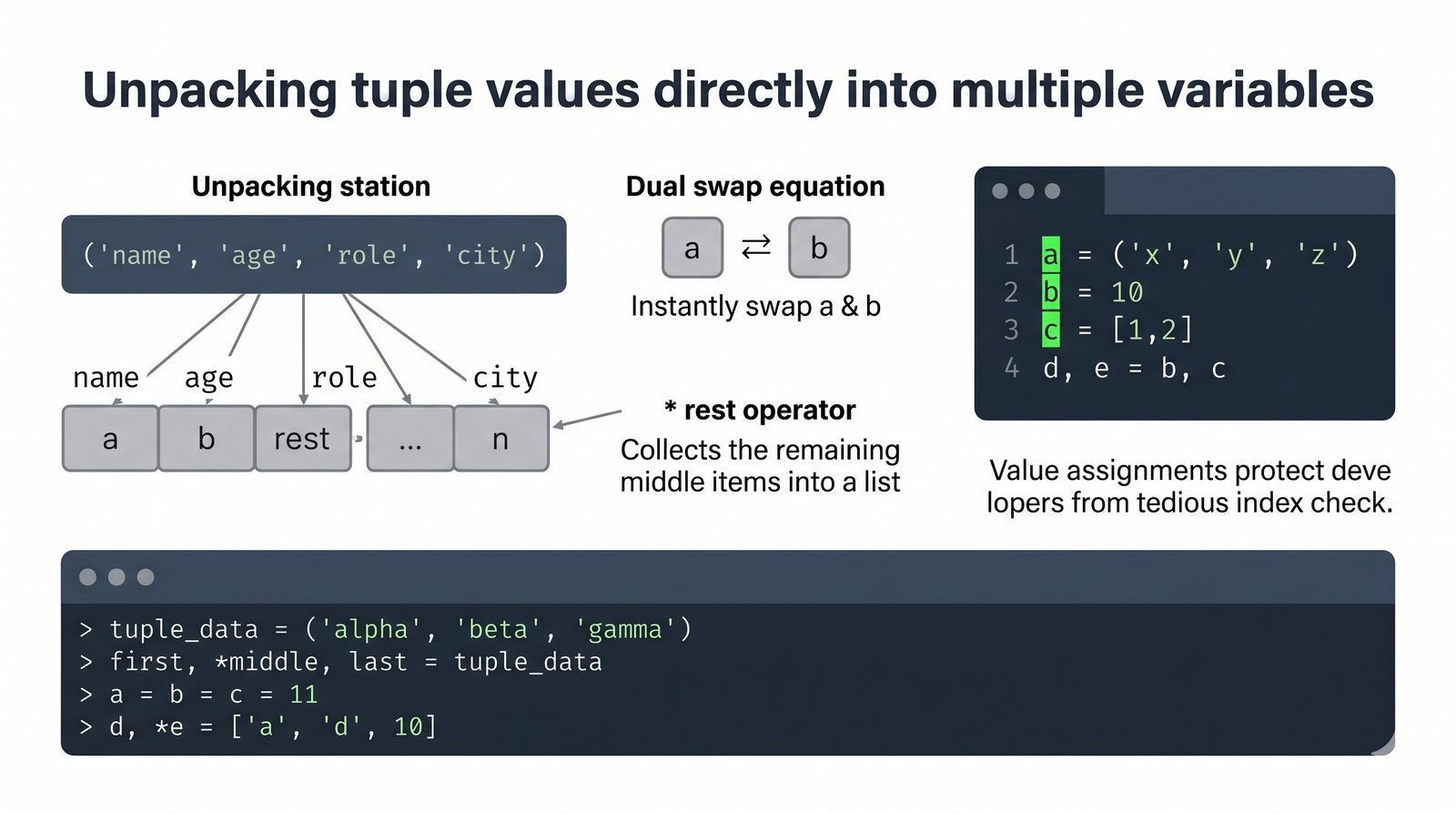
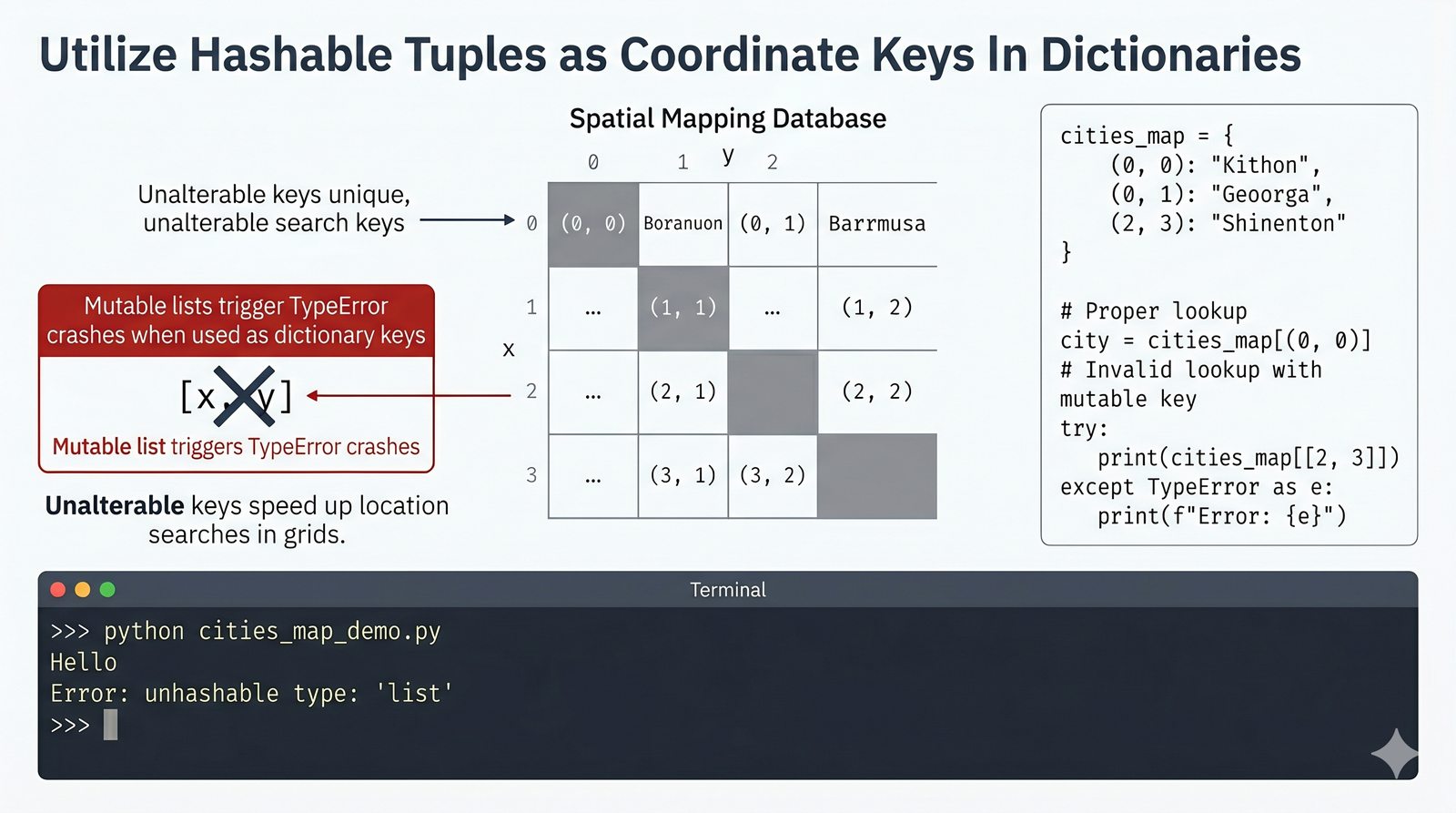
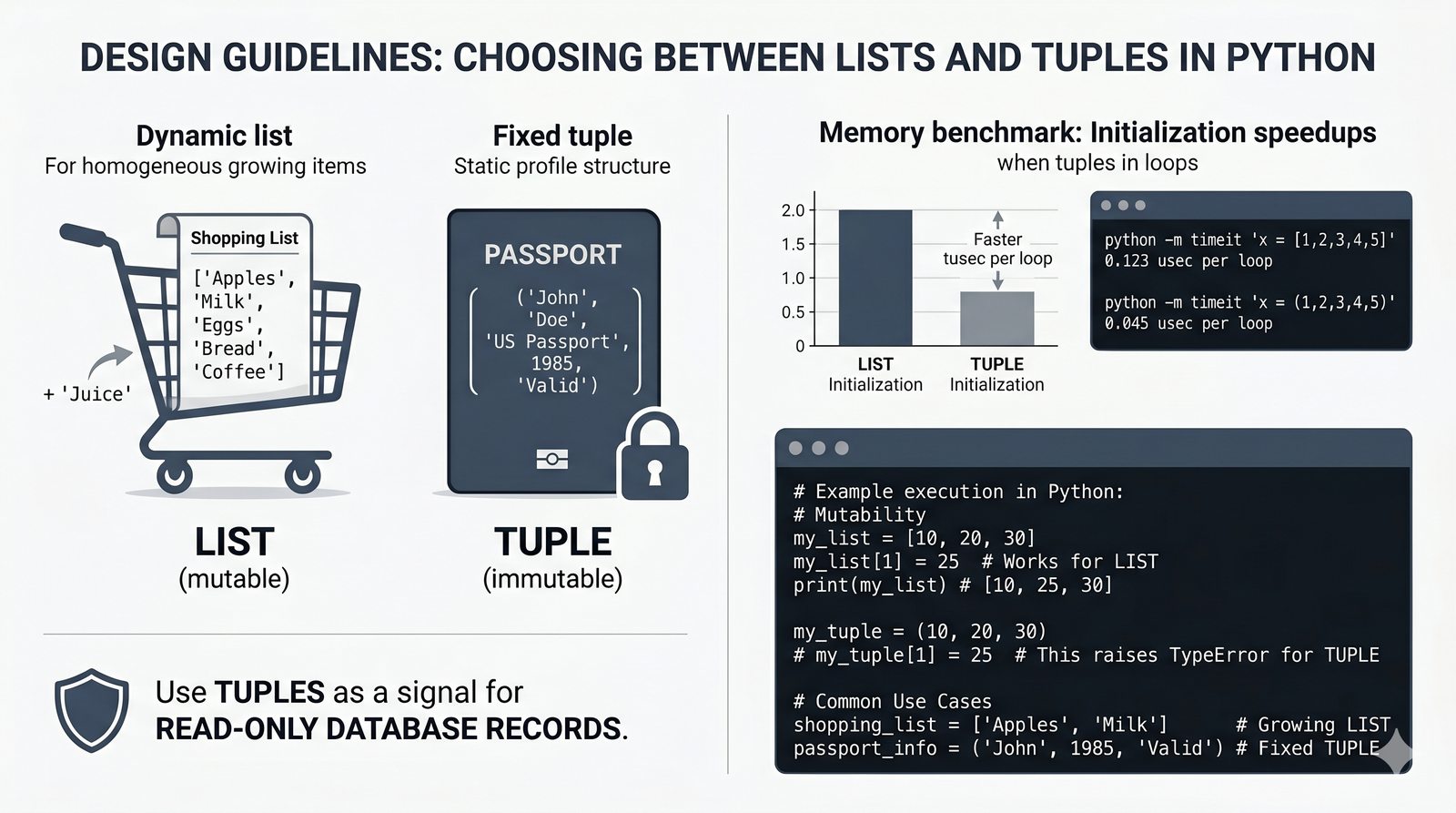
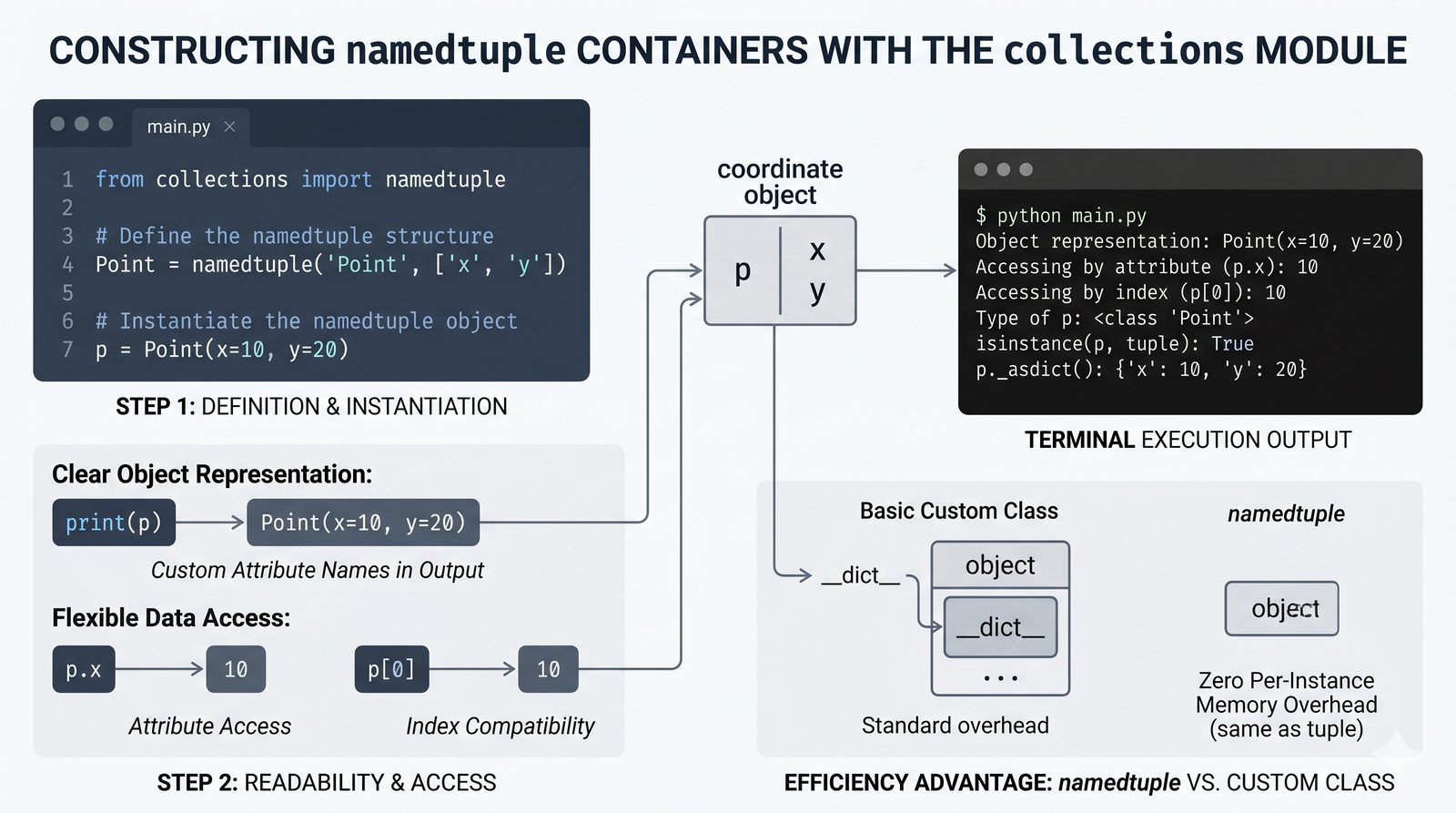
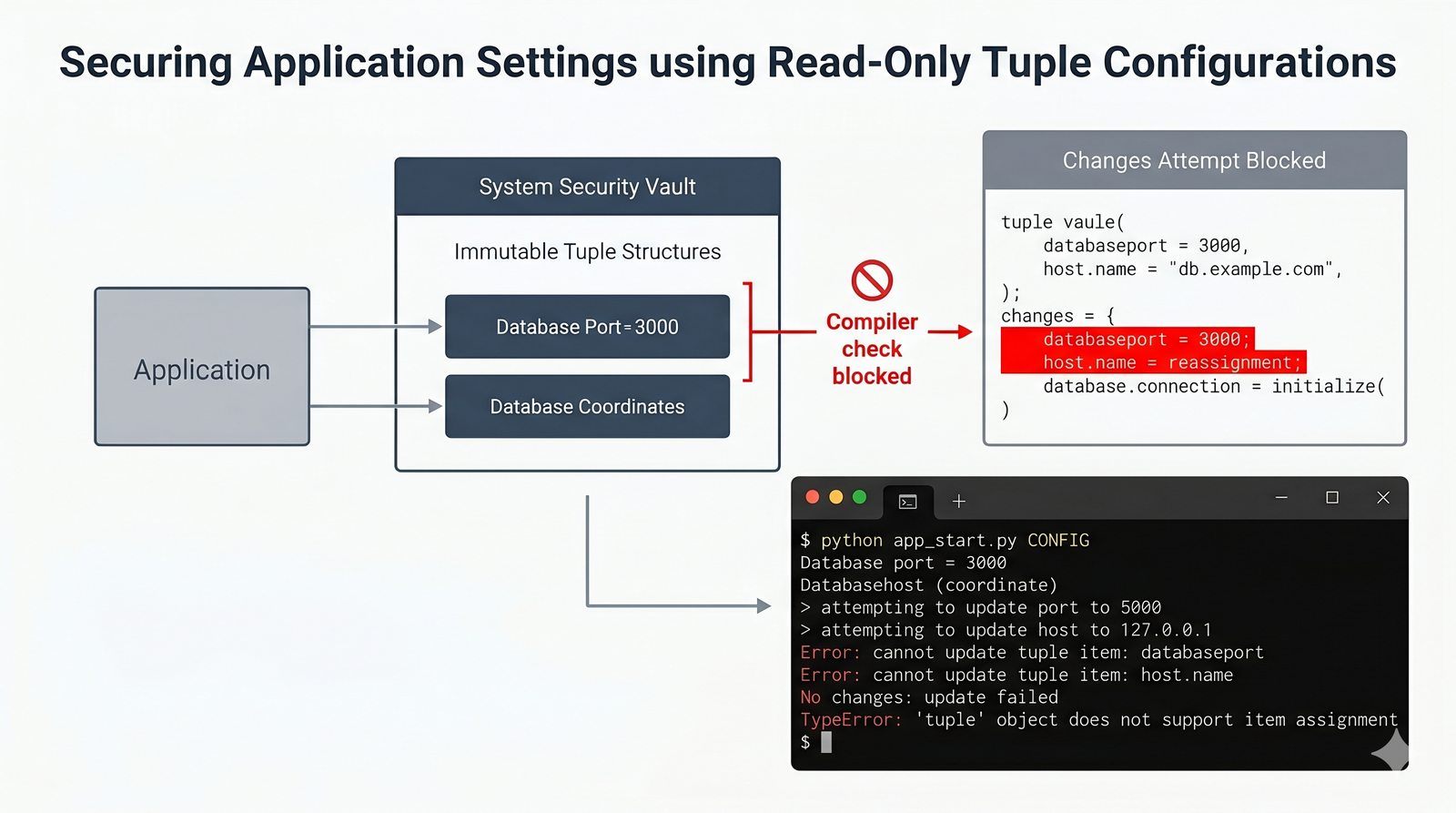
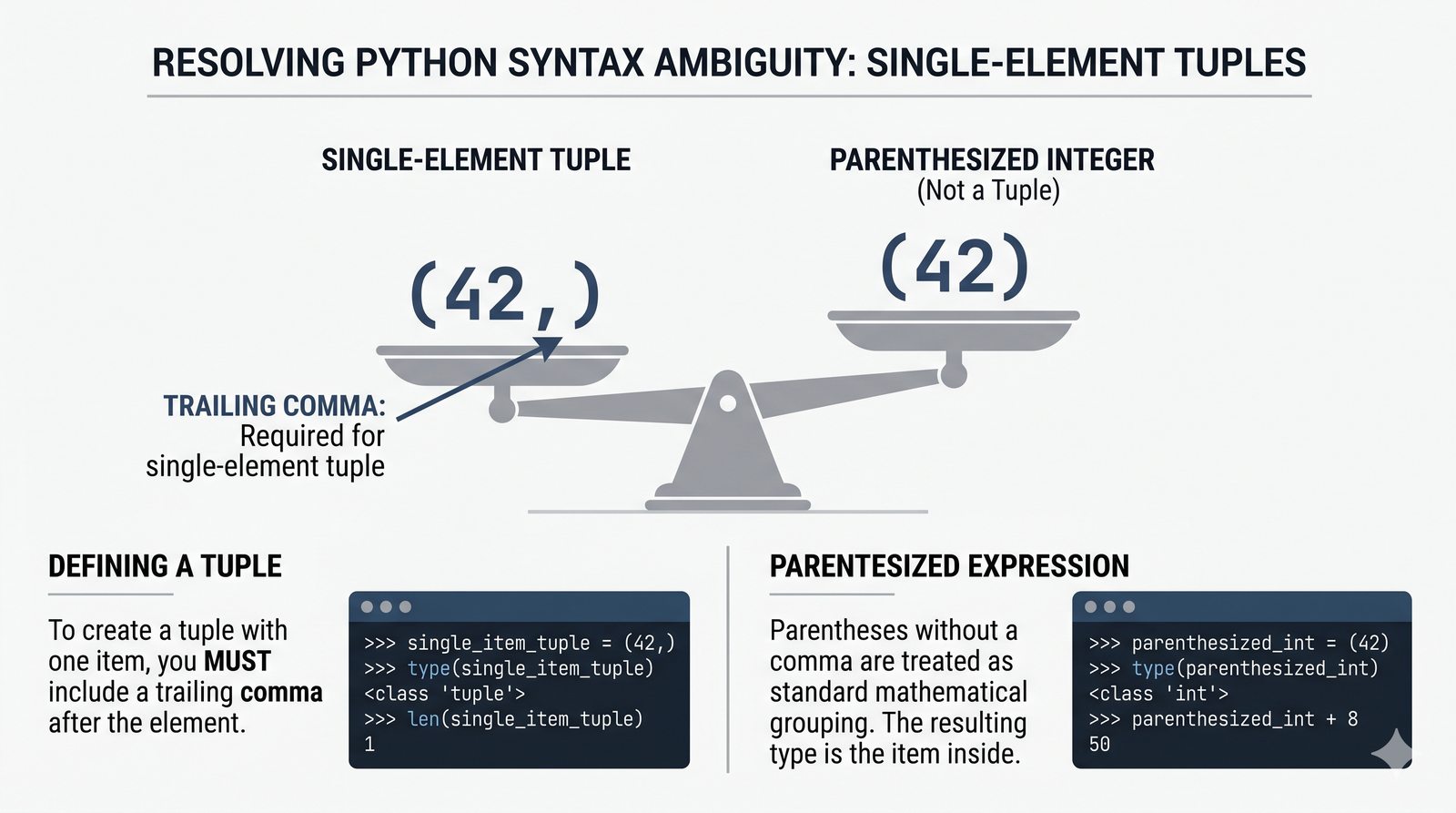
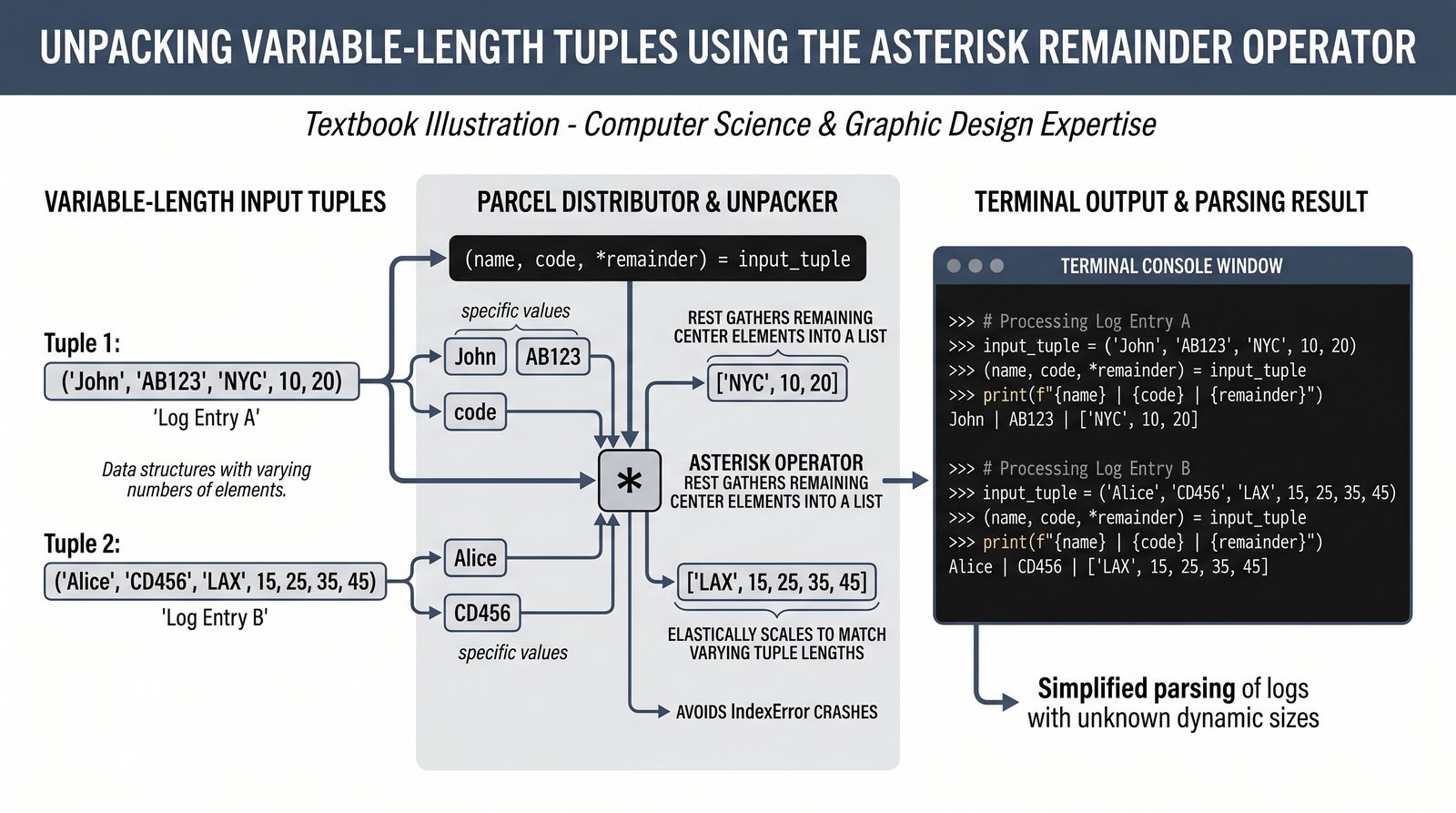
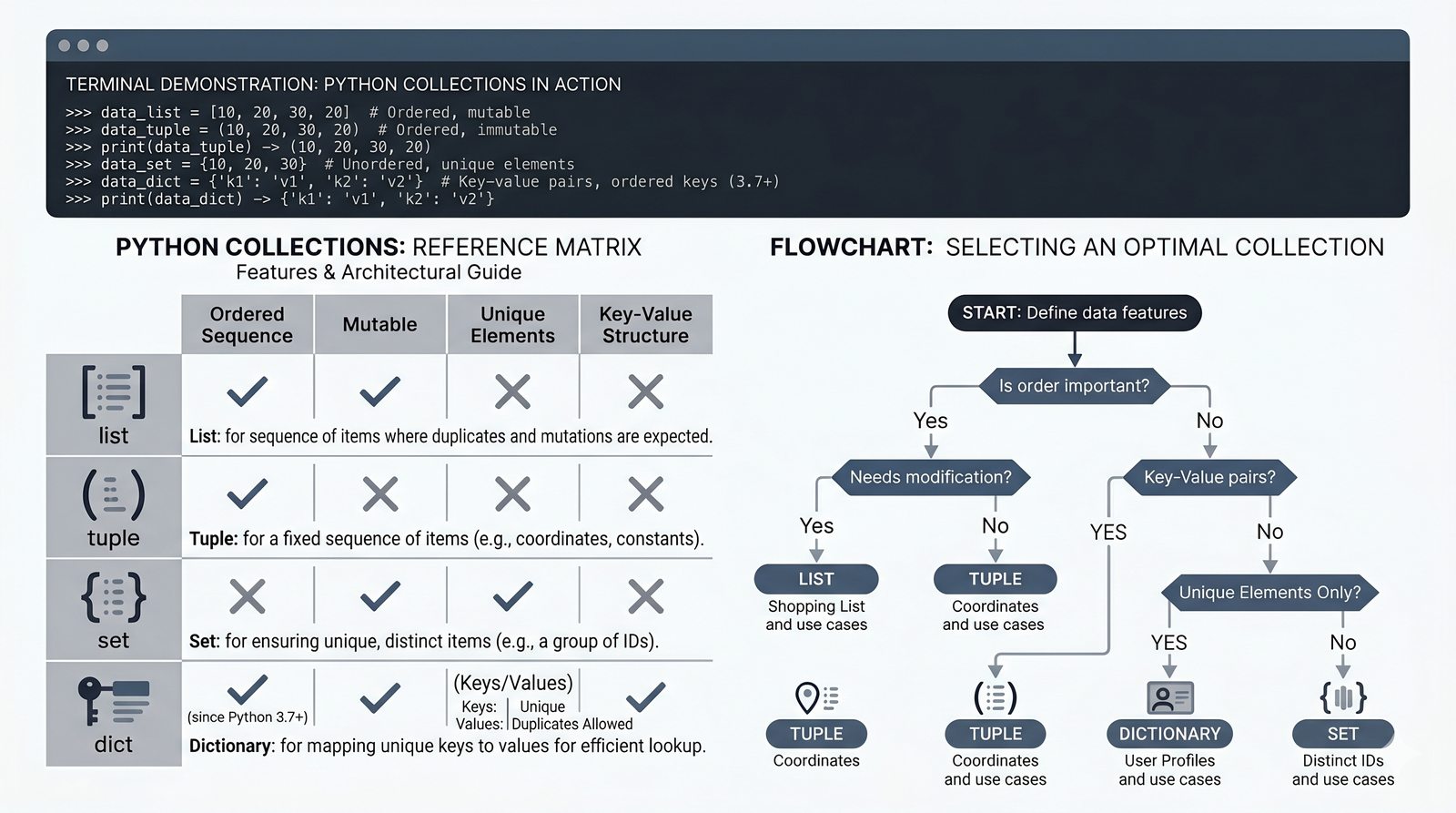
- Krotki -- niemutowalność, indeksowanie, rozpakowywanie, namedtuple oraz zastosowanie jako klucze słowników
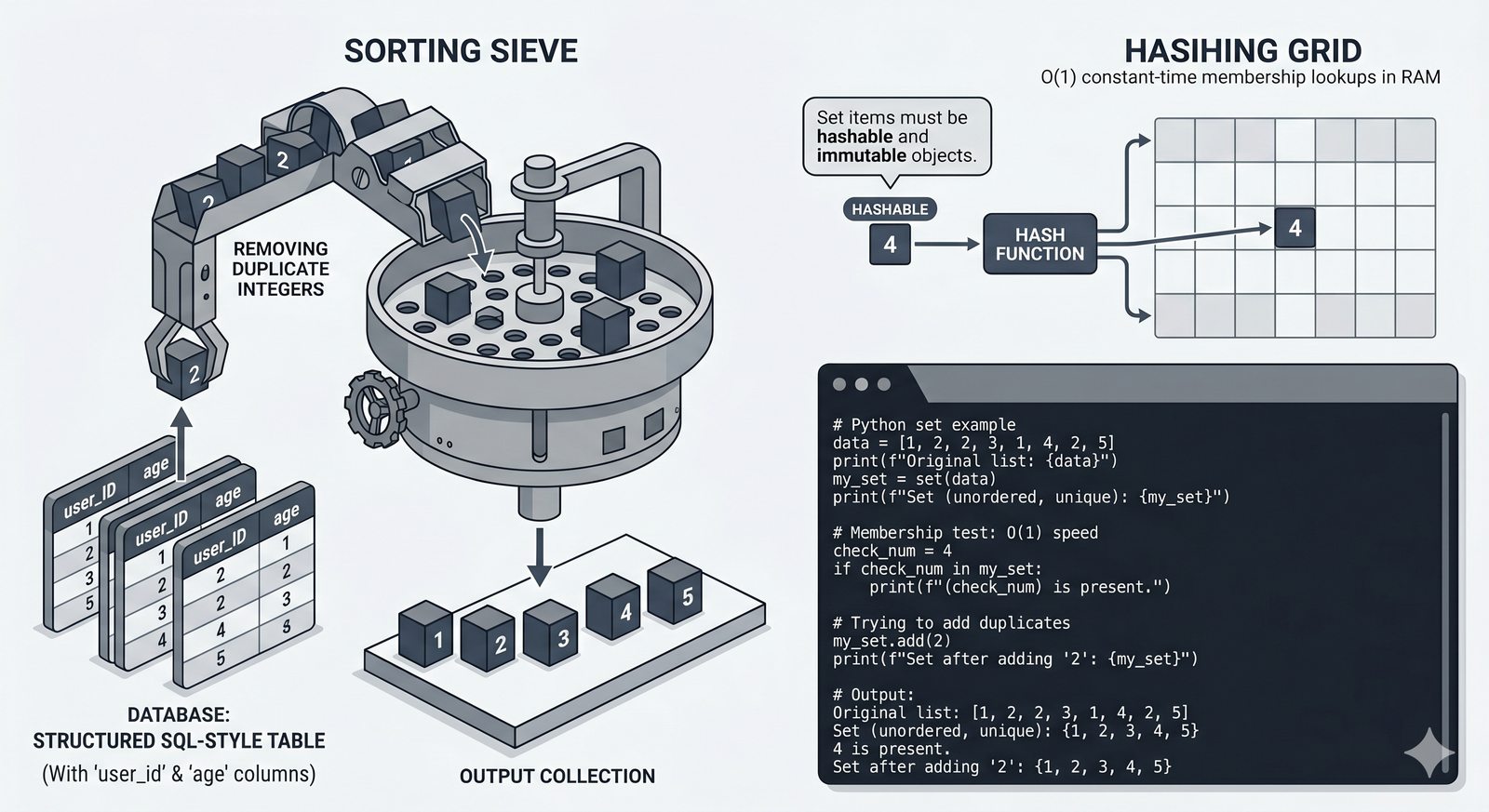
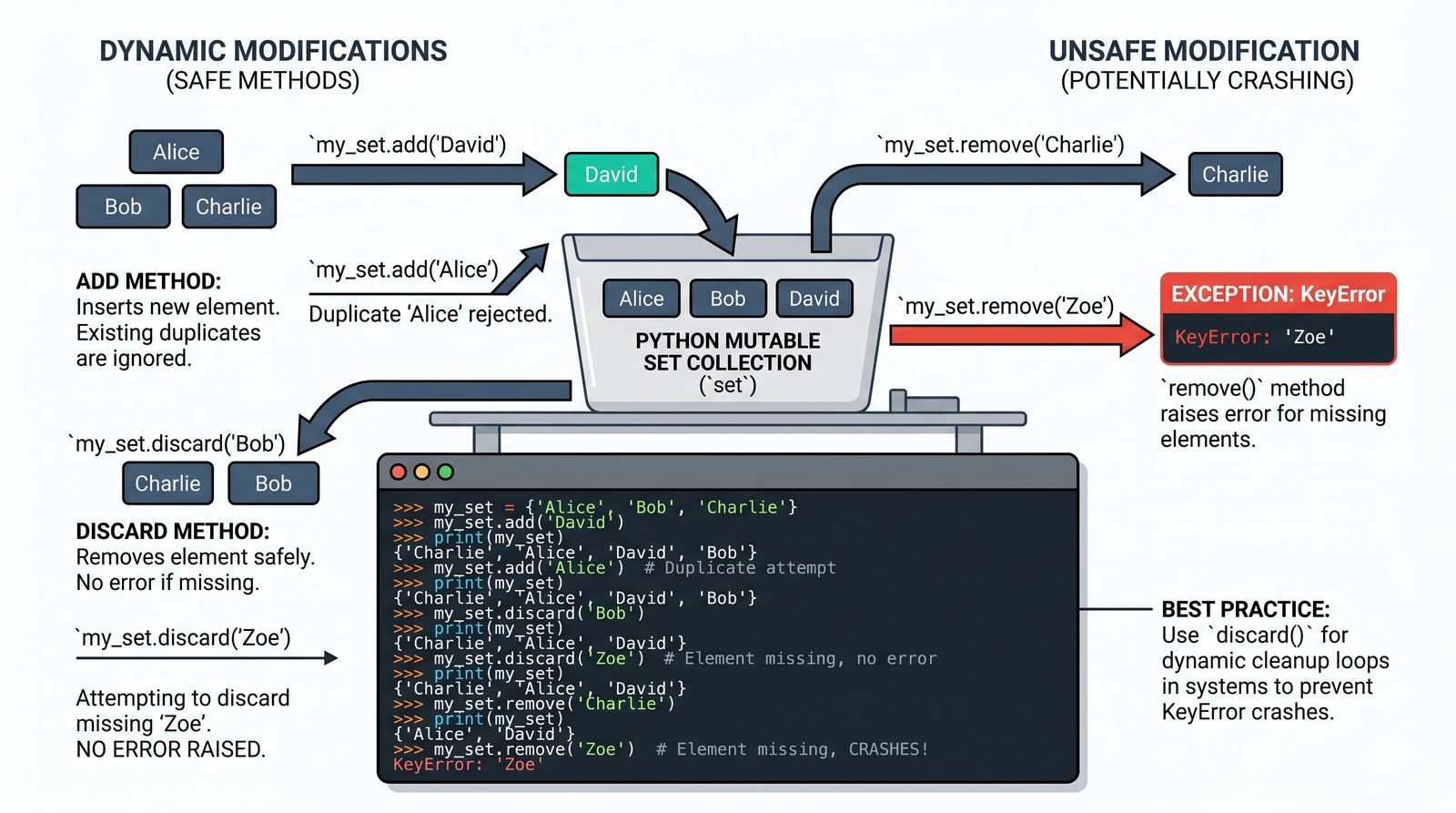
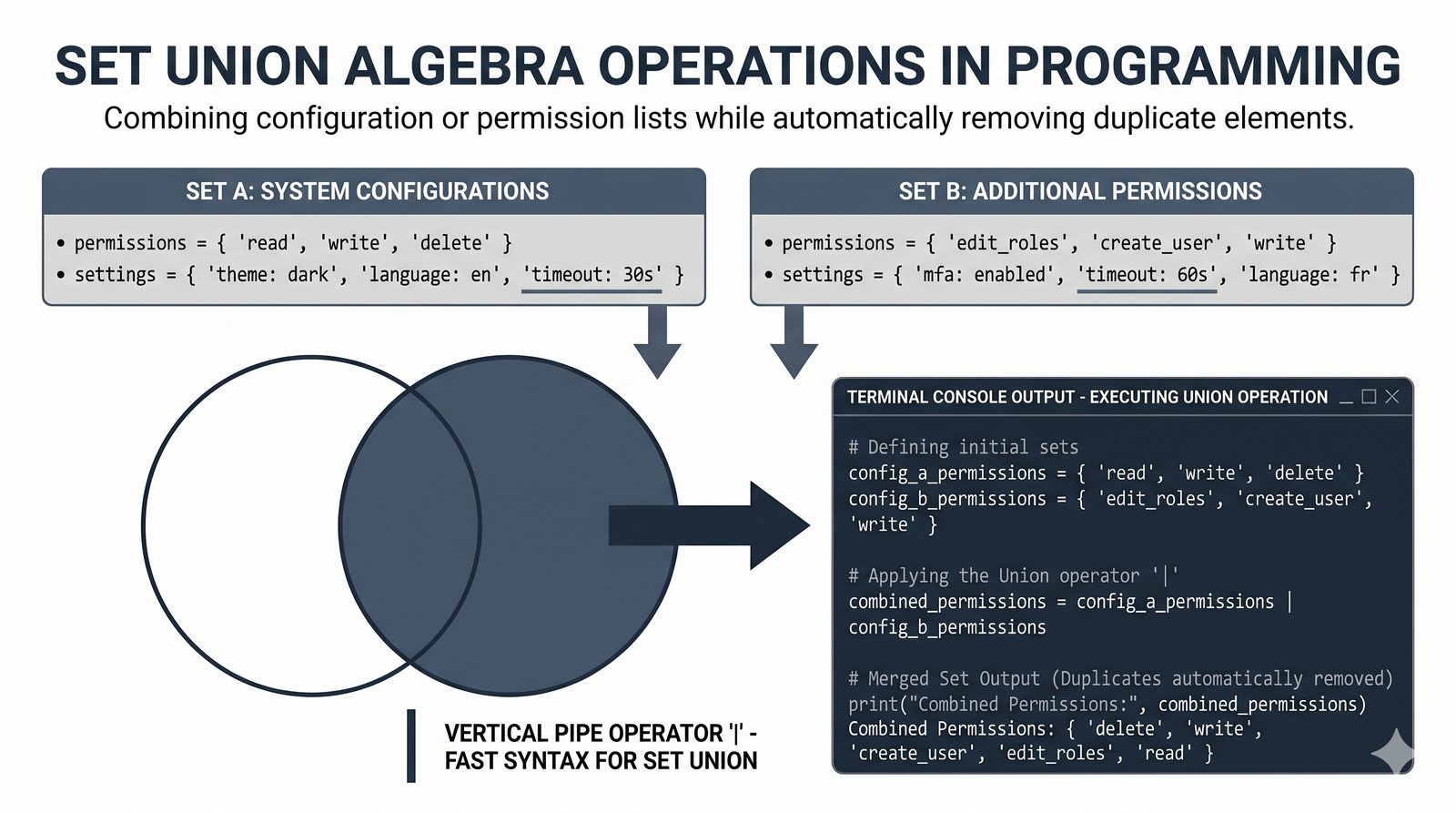
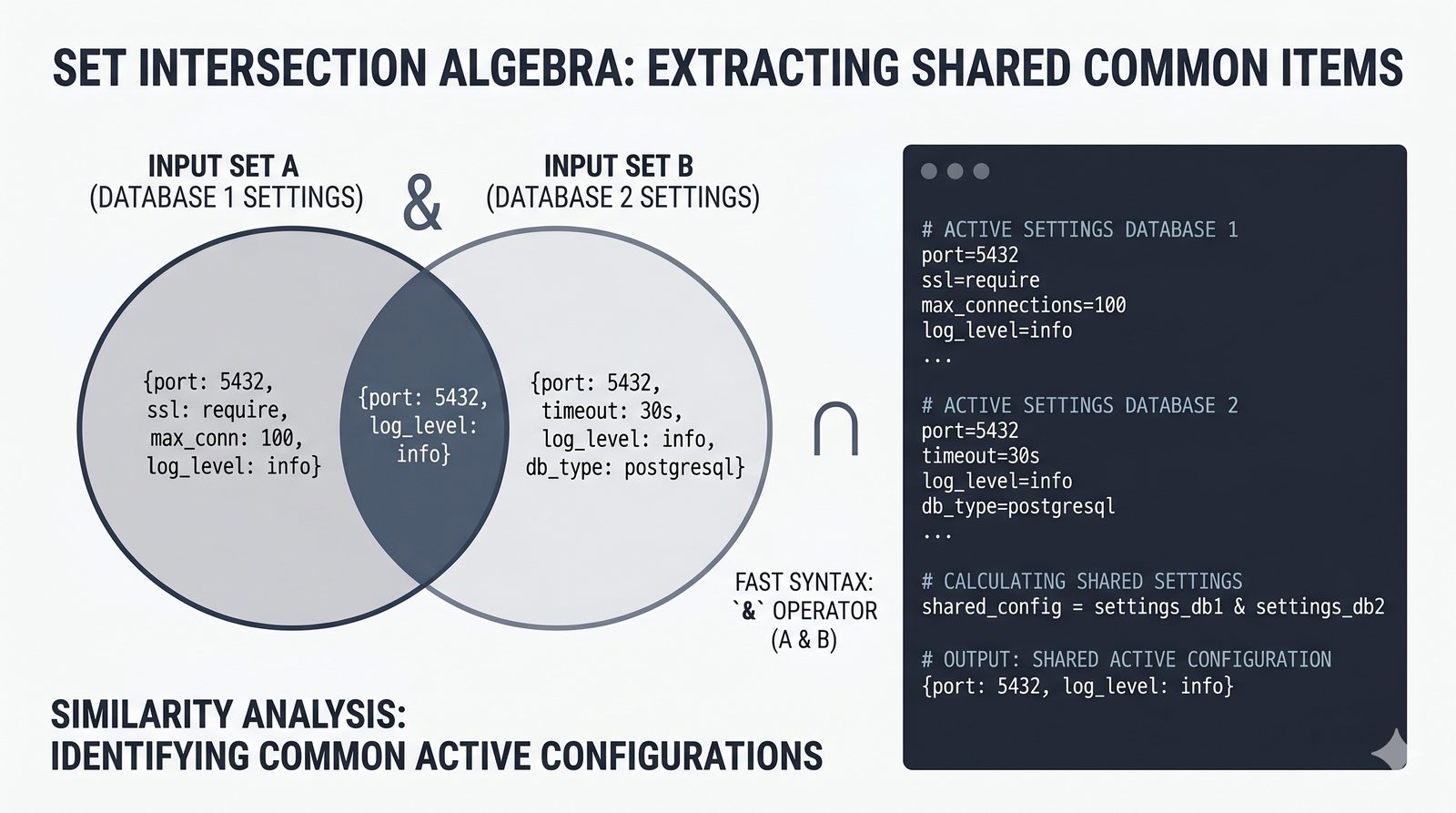
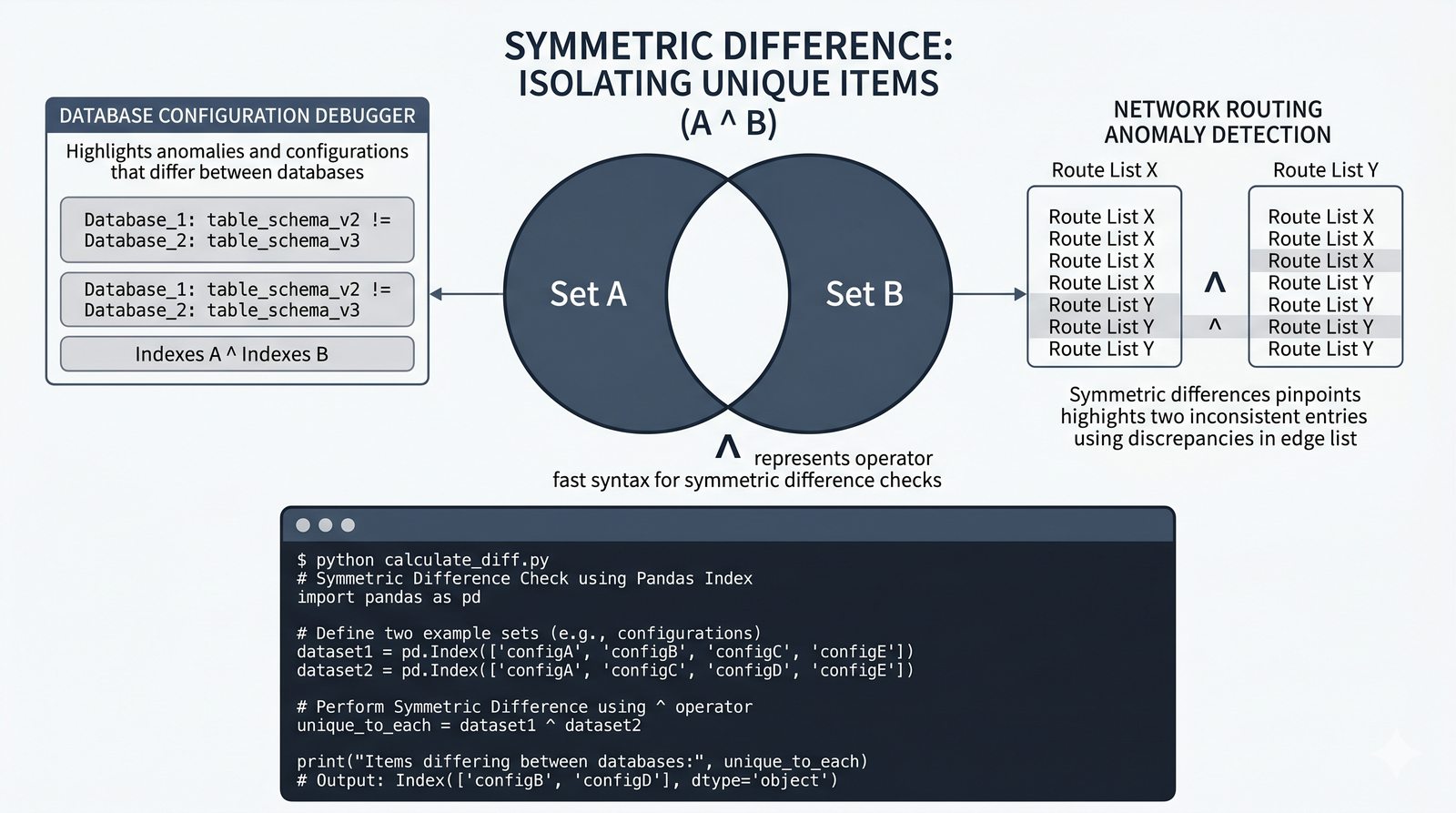
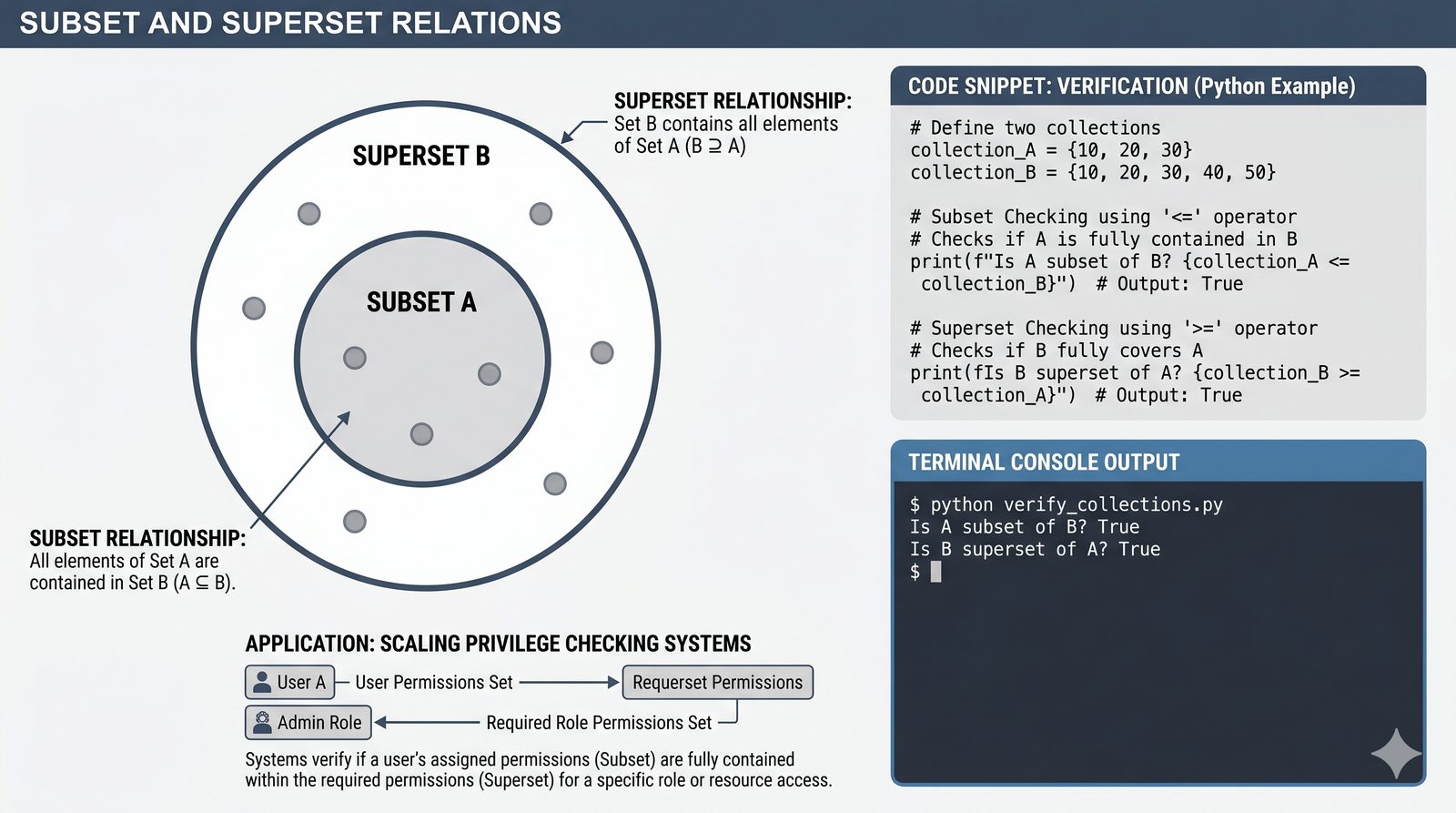
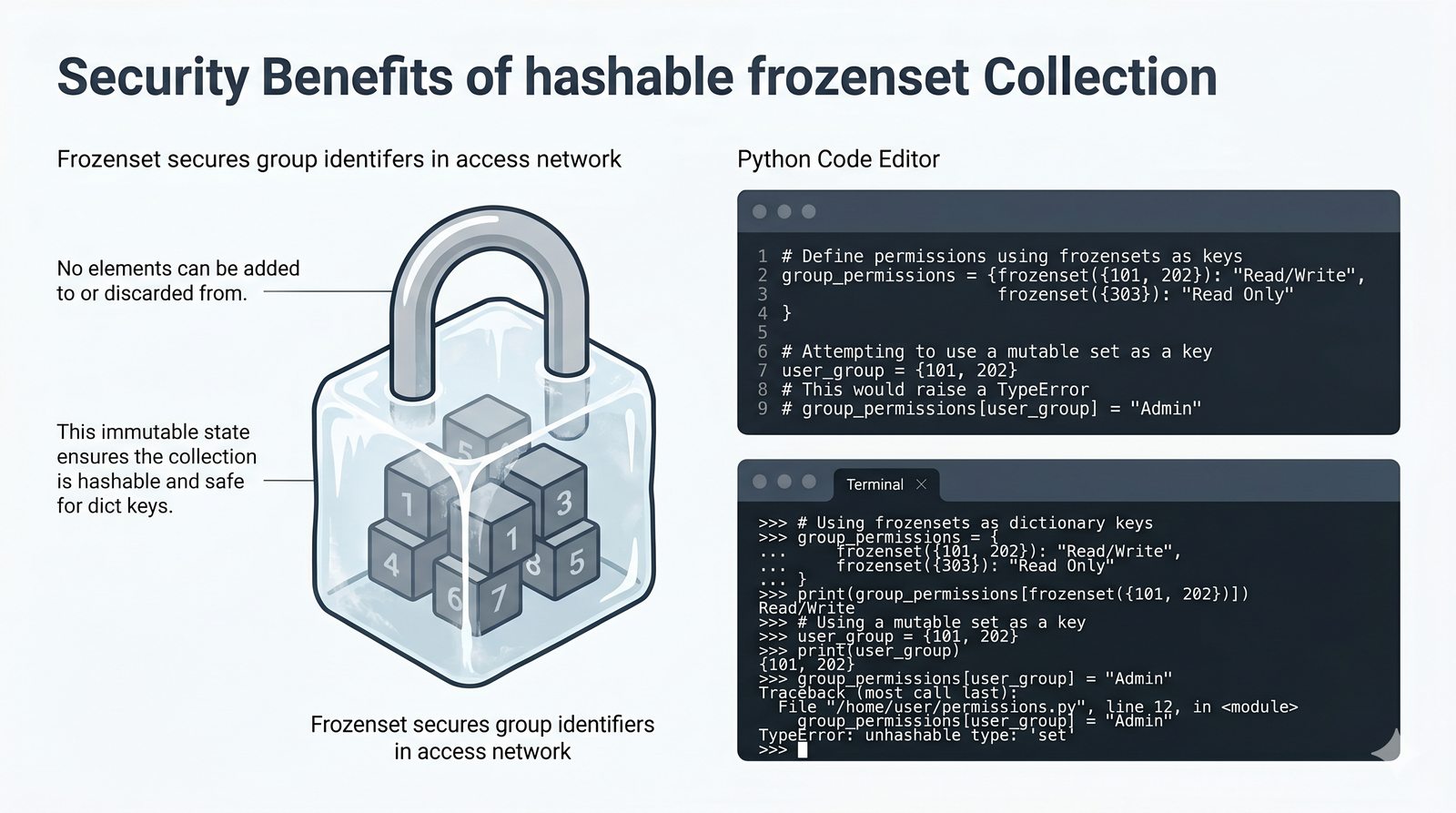
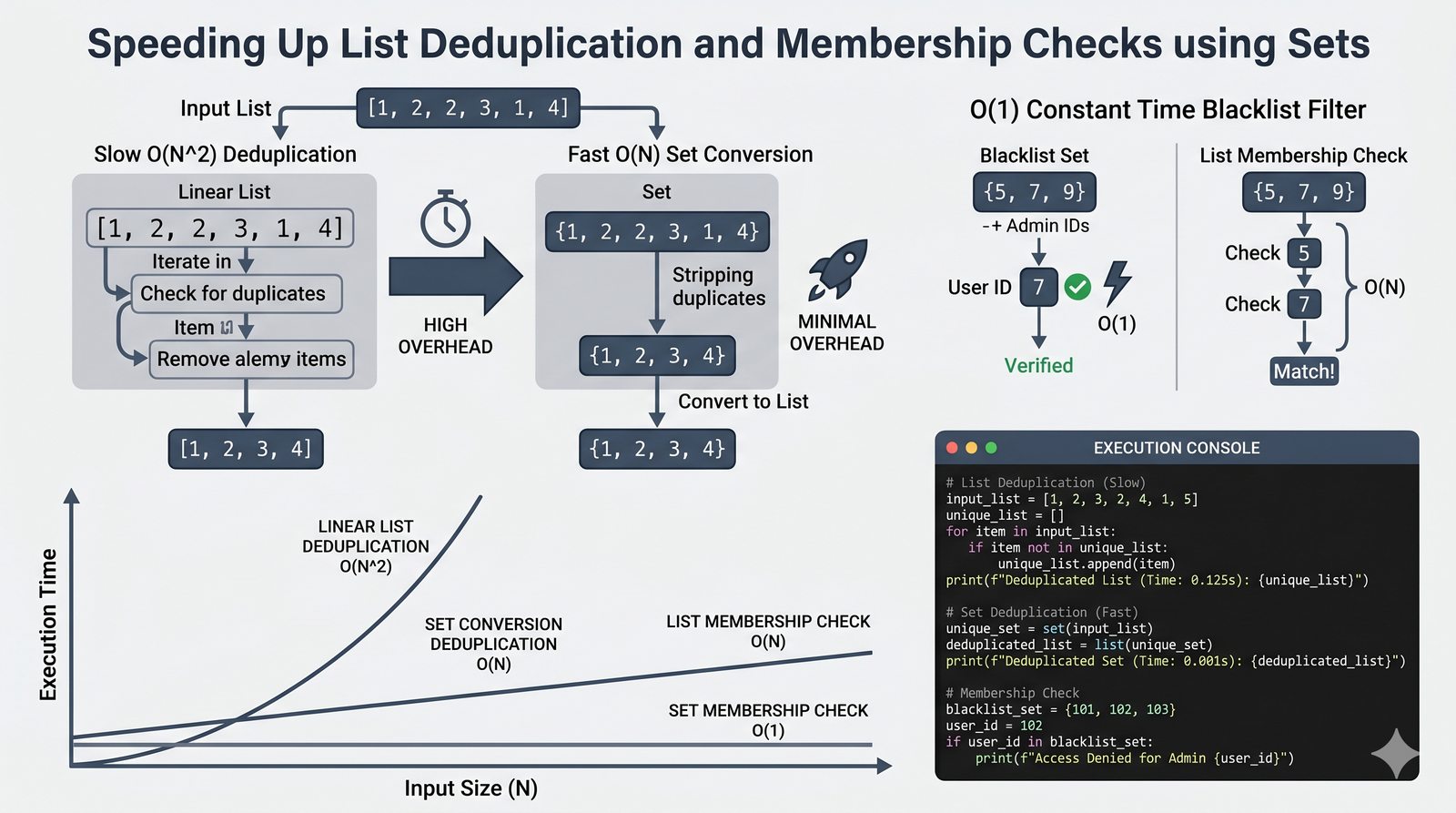
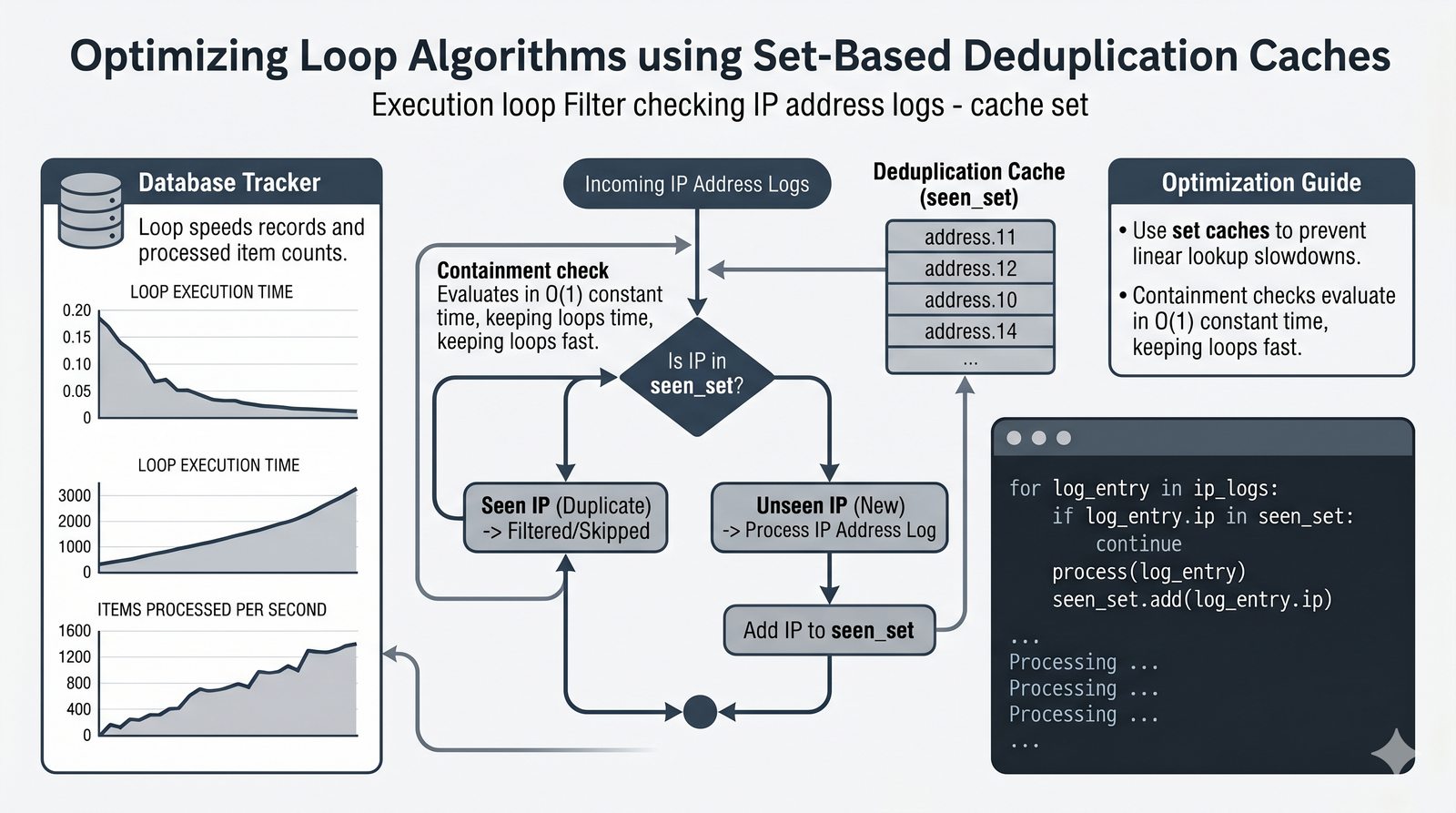
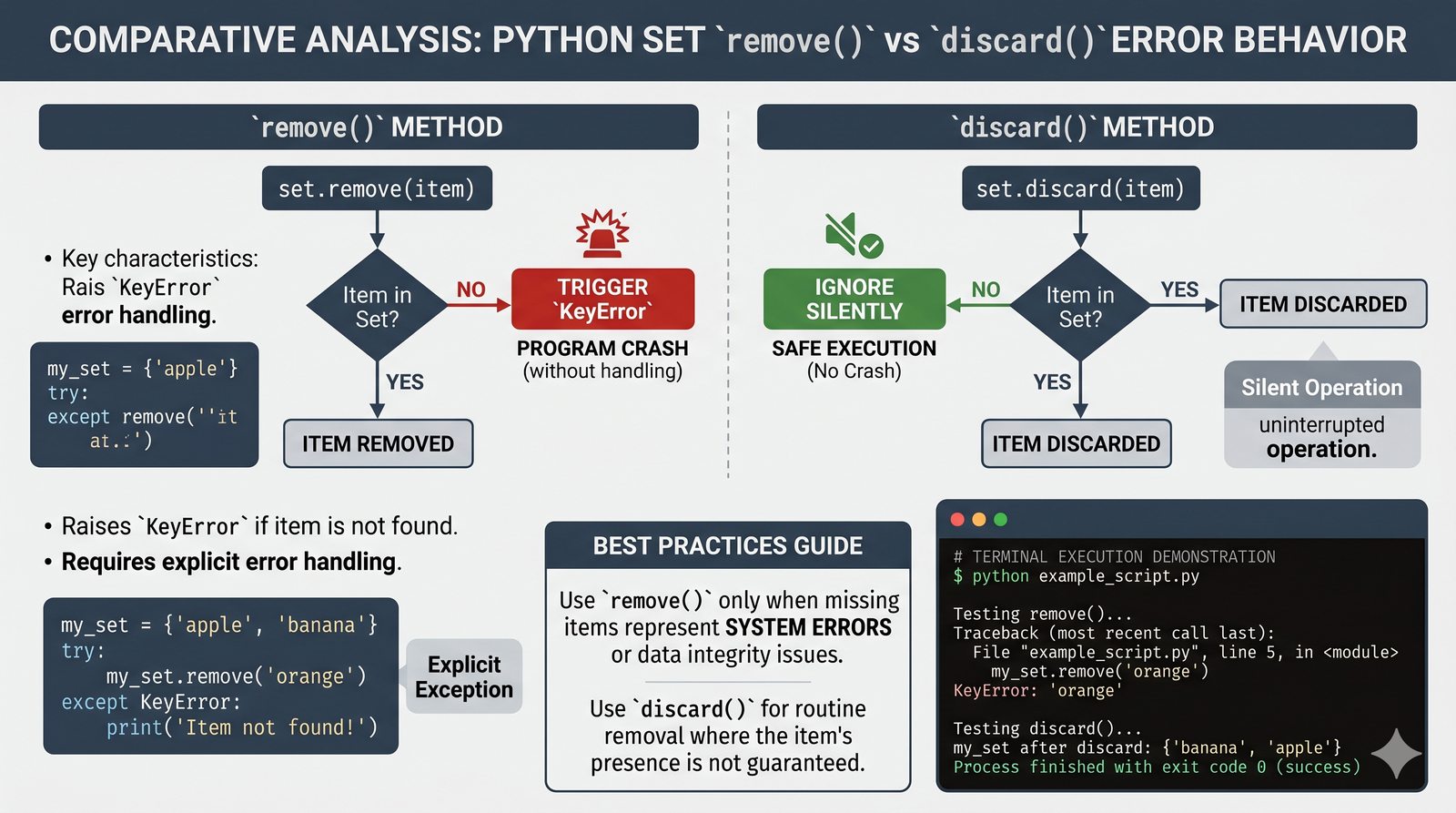
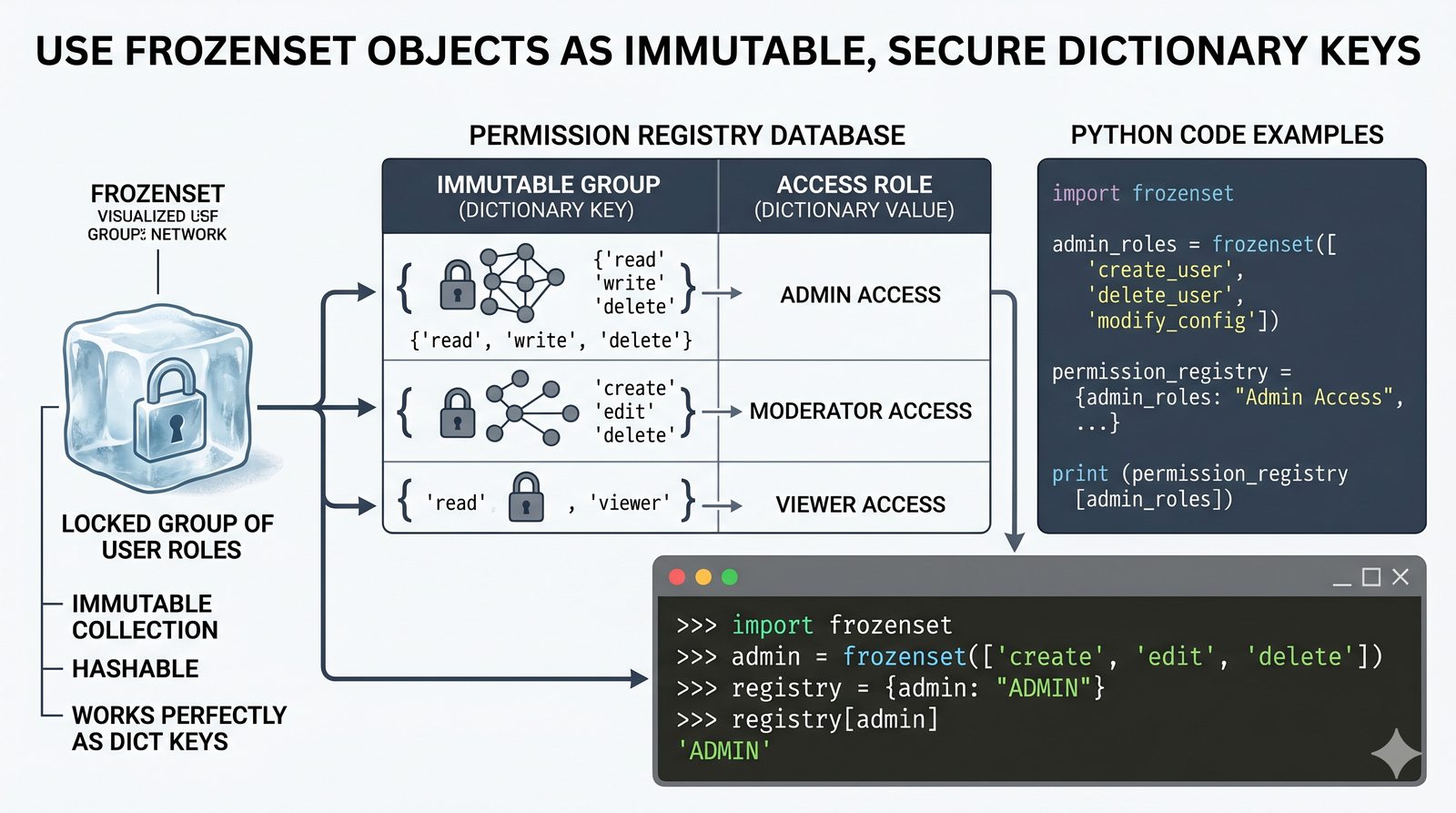
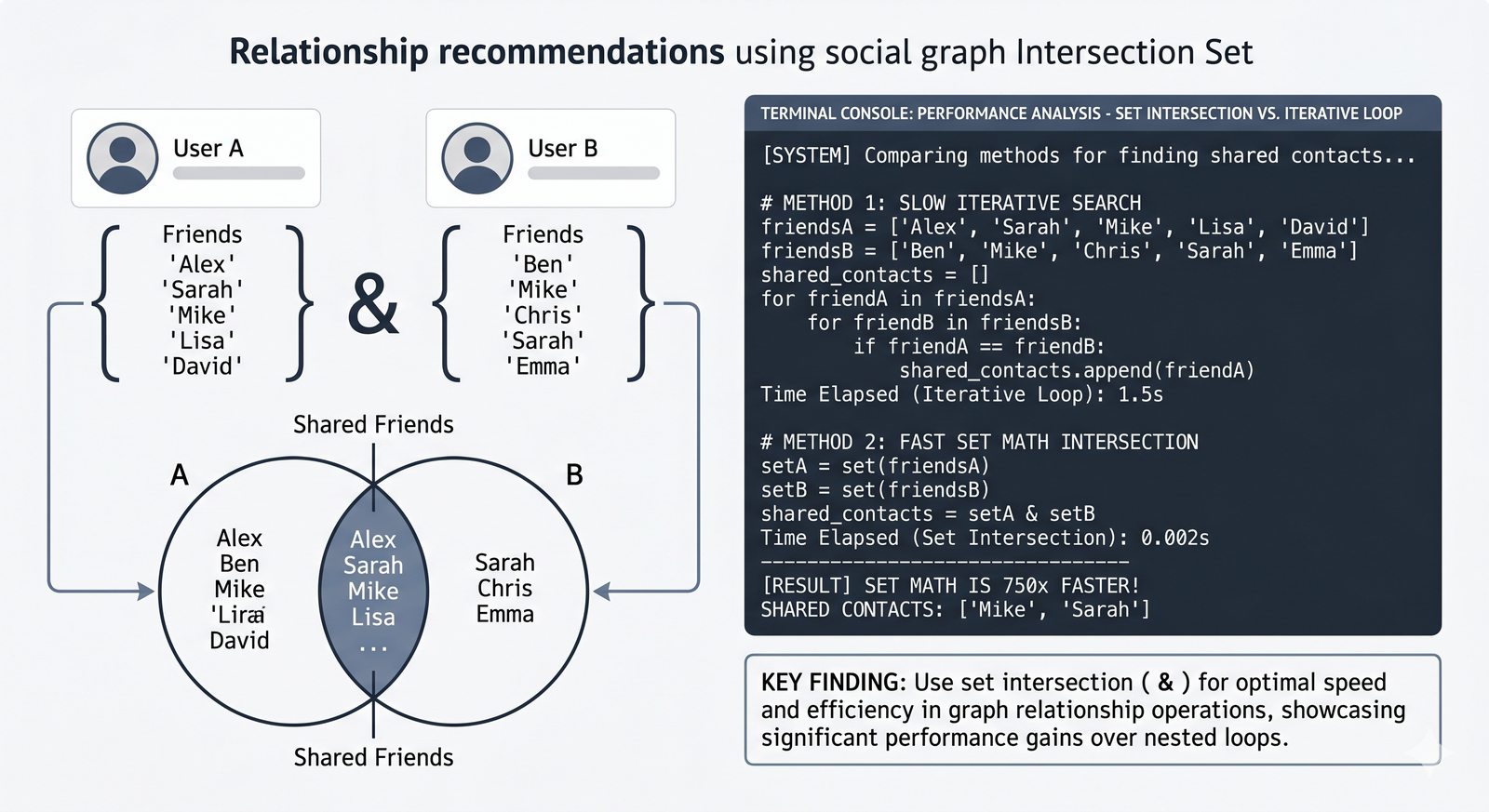
- Zbiory -- unikalność elementów, operacje algebraiczne (suma, przecięcie, różnica), frozenset i praktyczne zastosowania
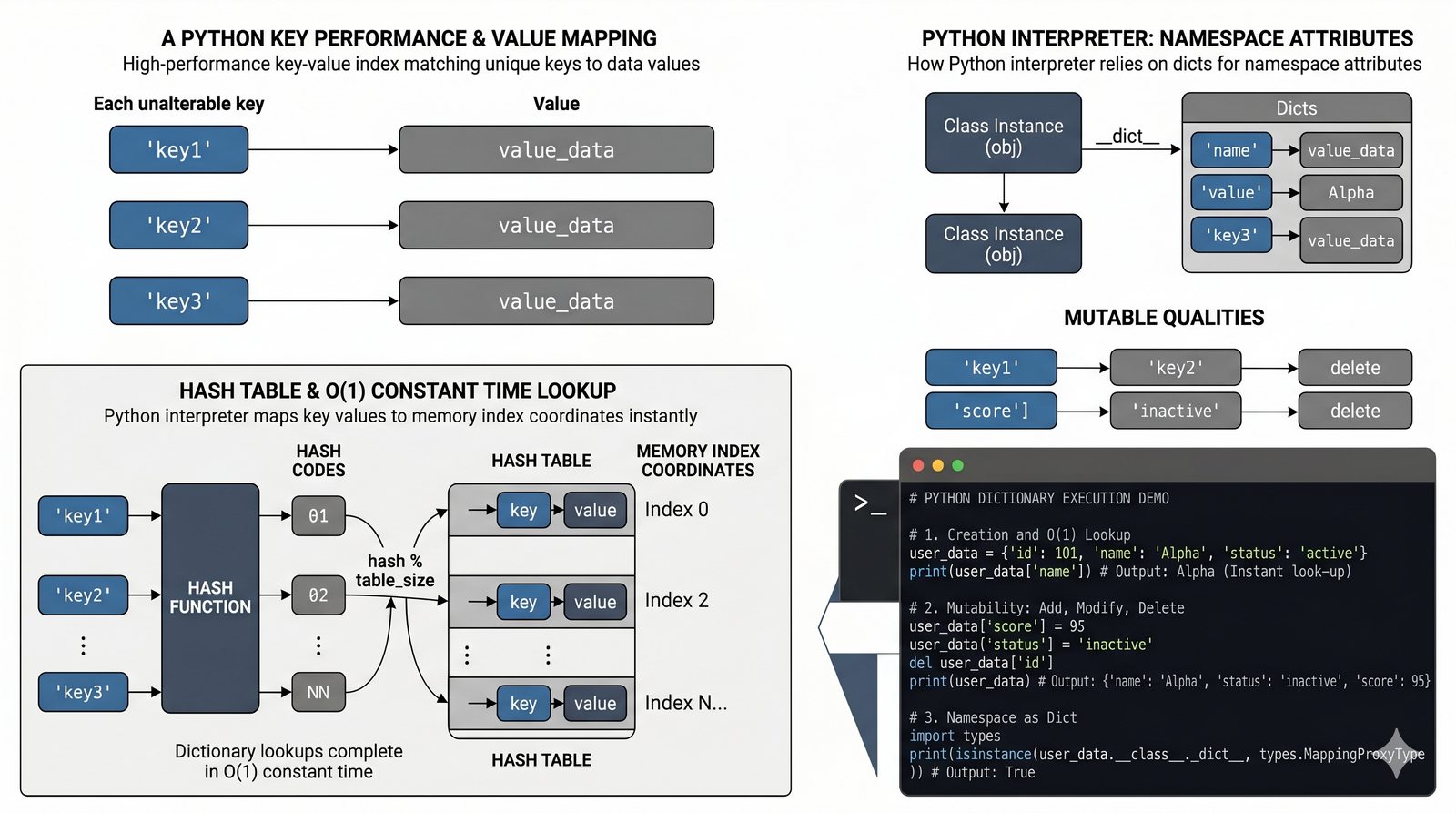
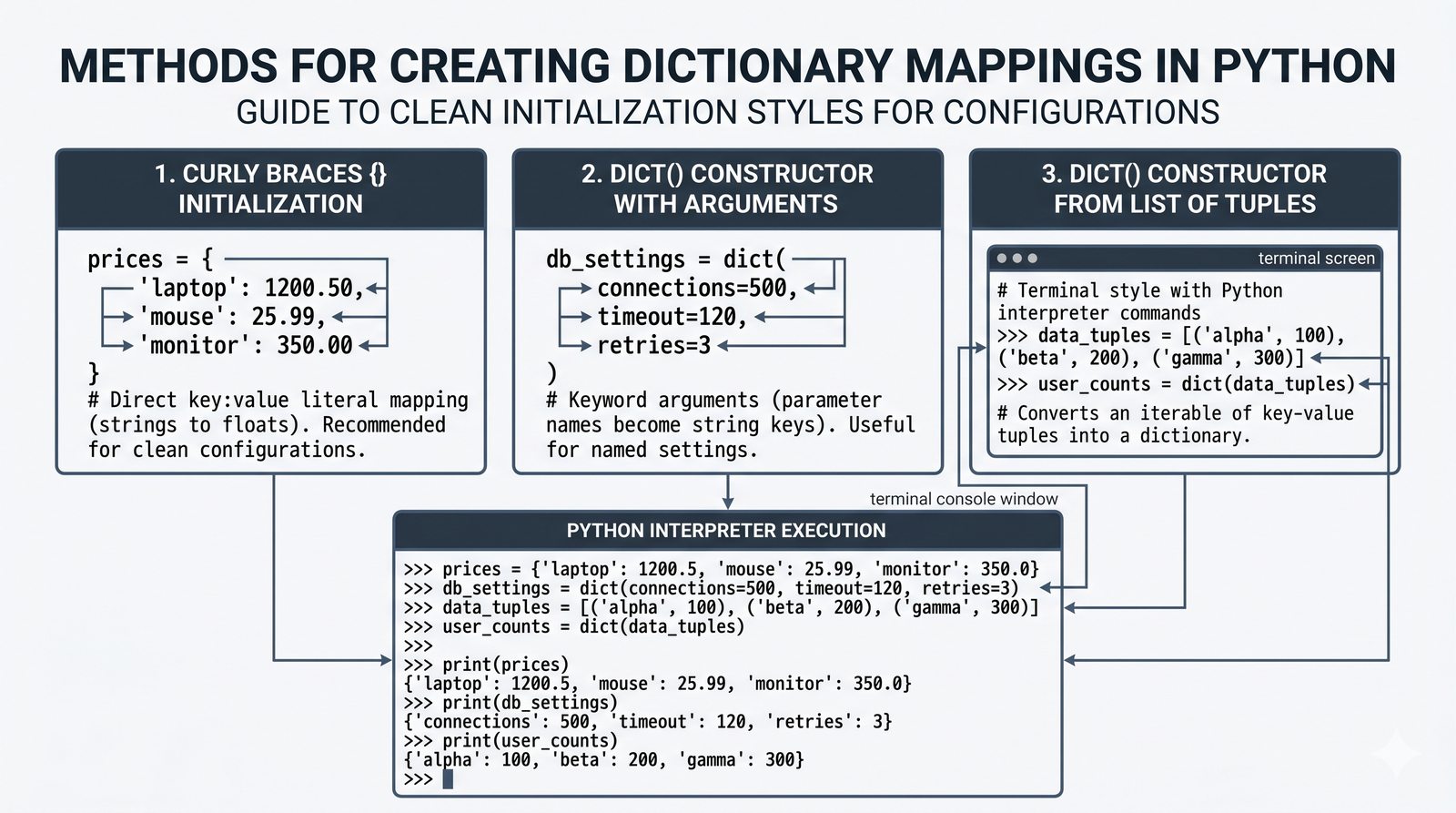
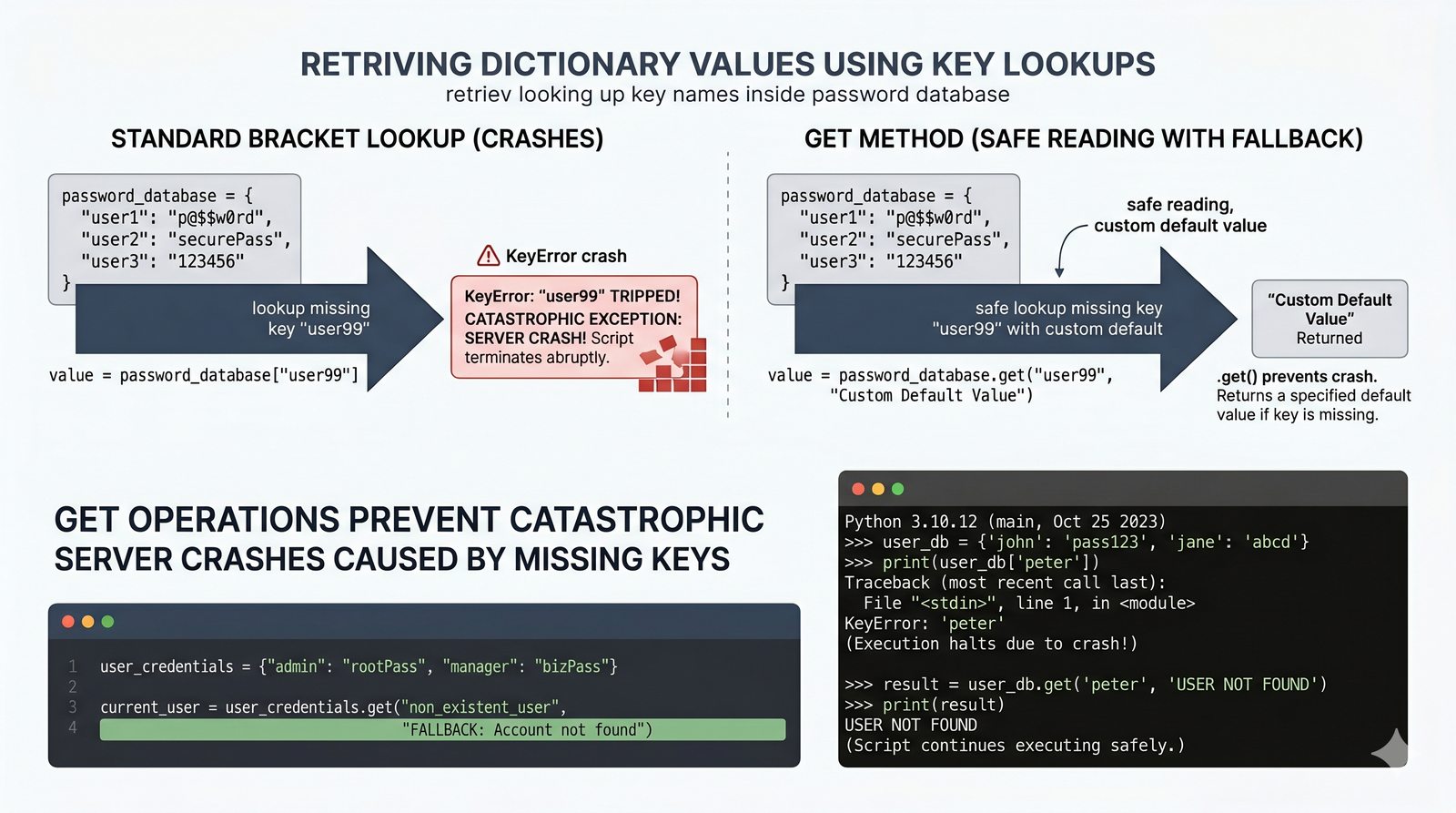
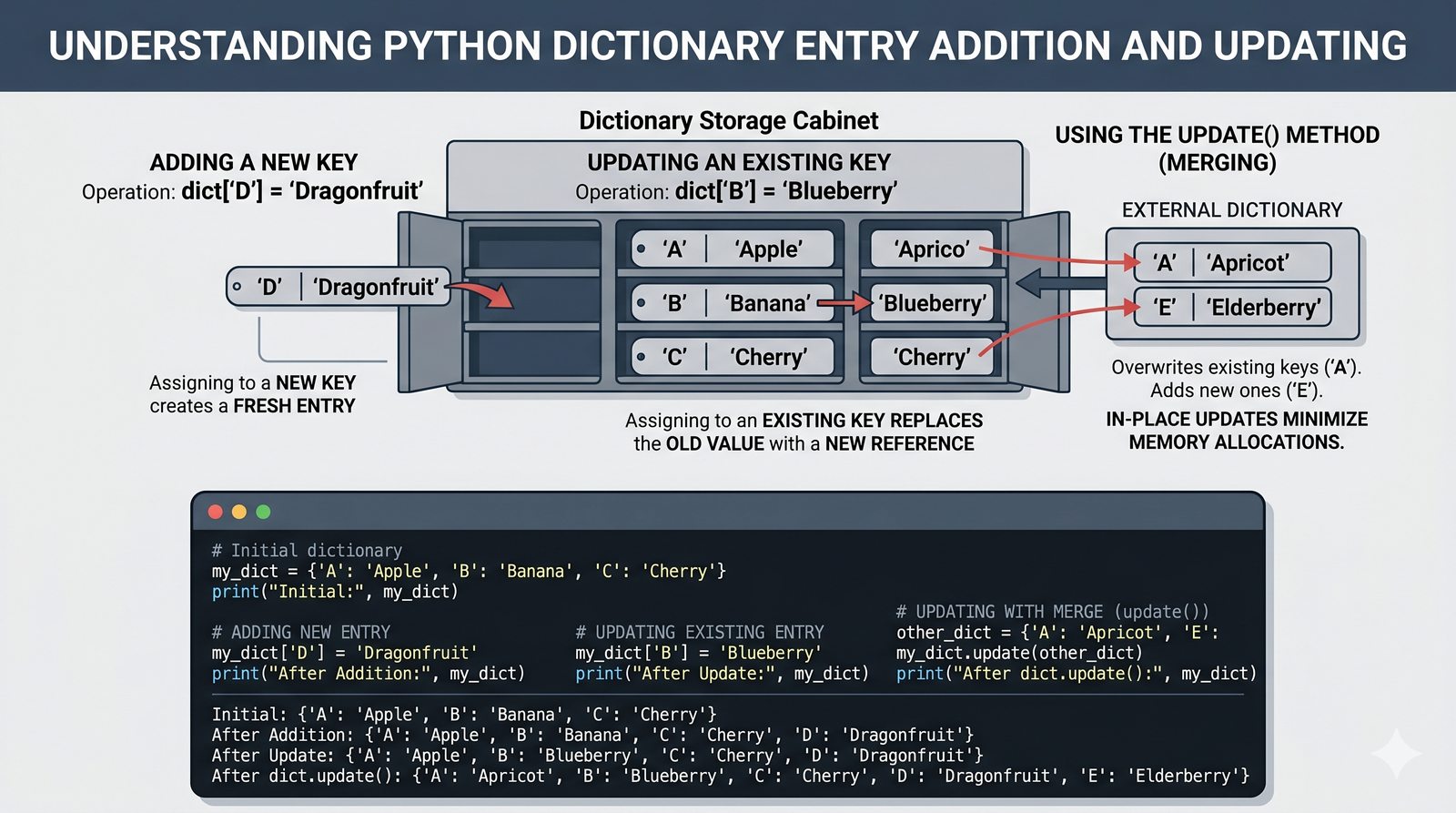
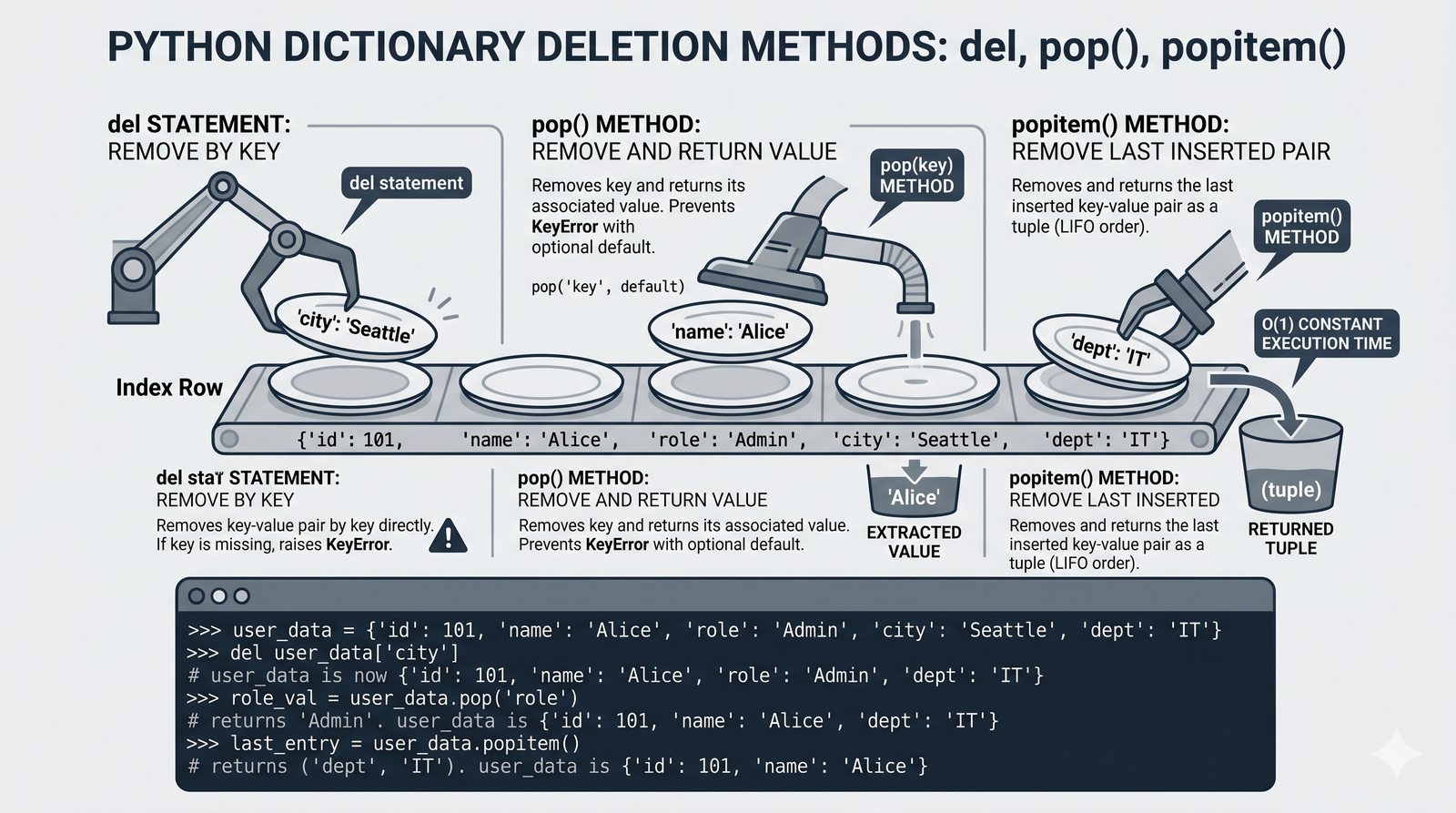
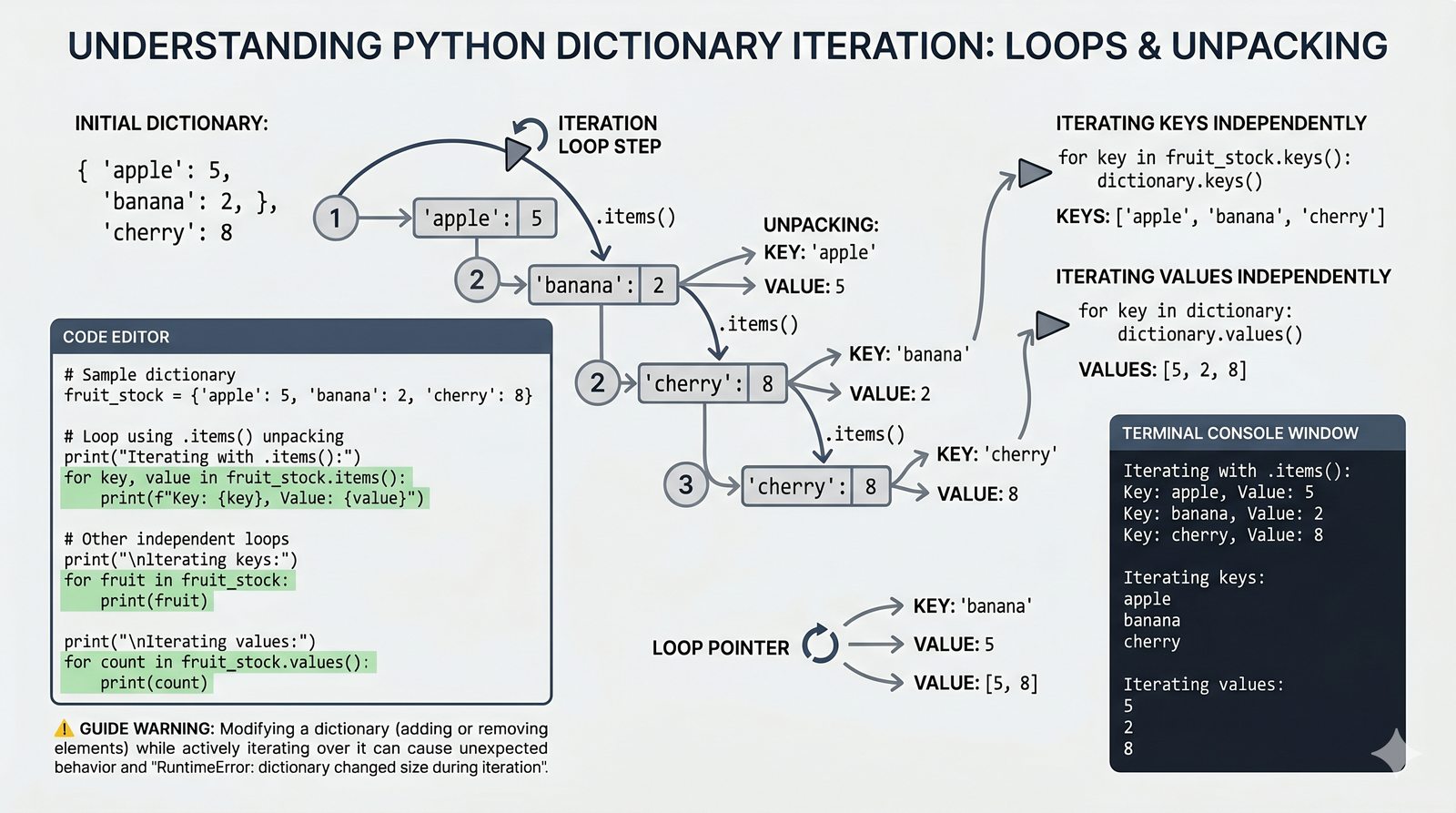
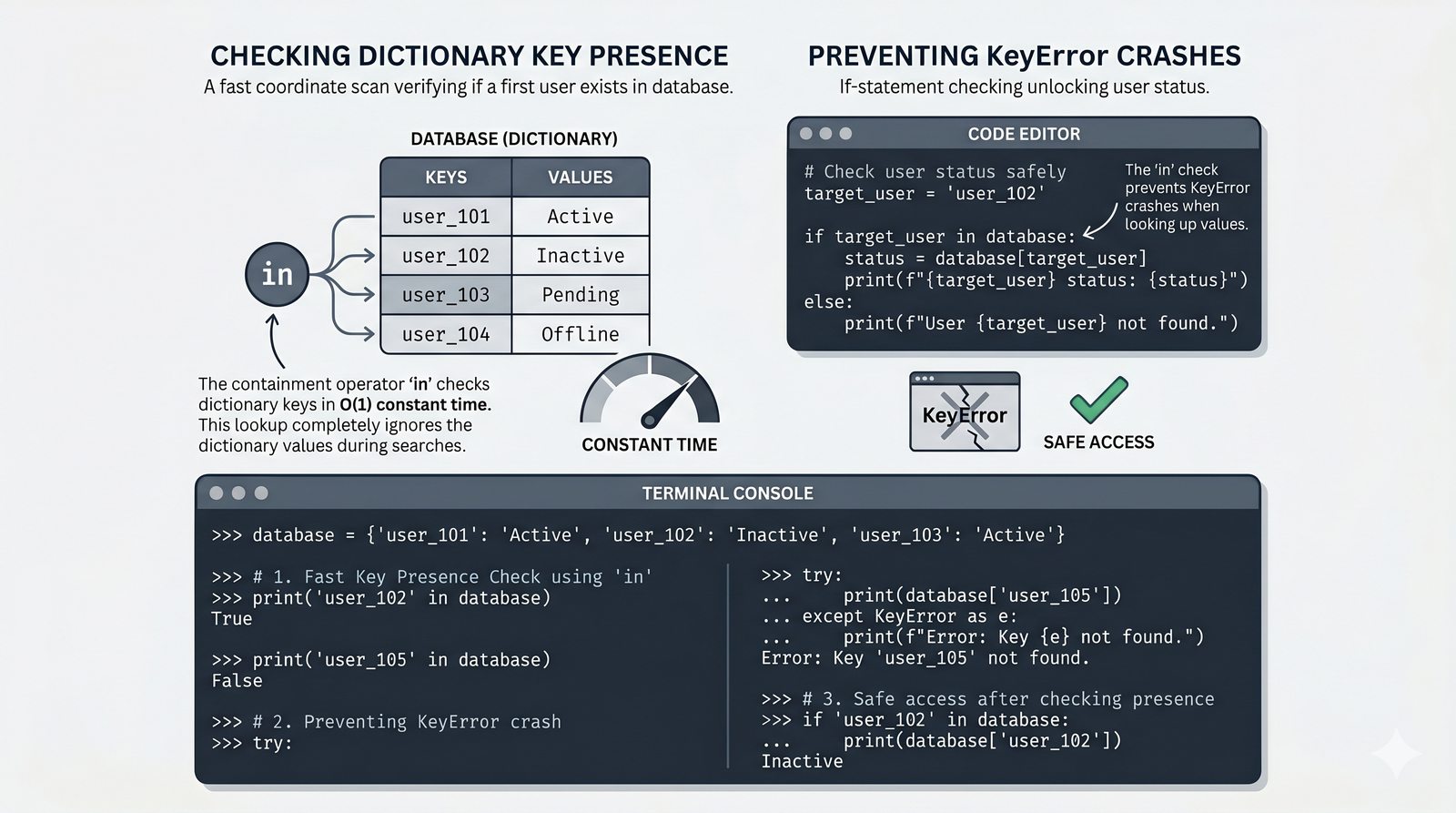
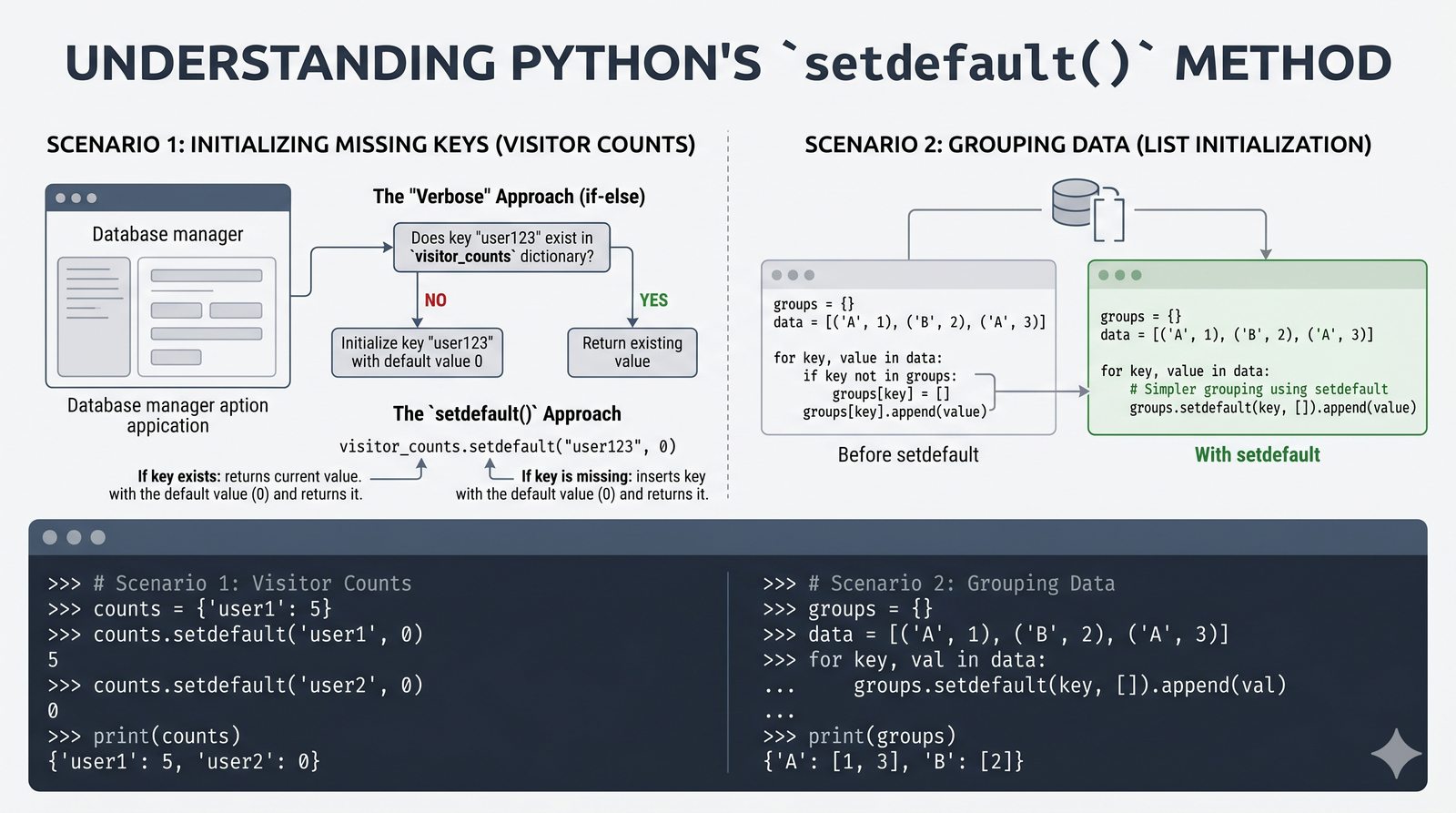
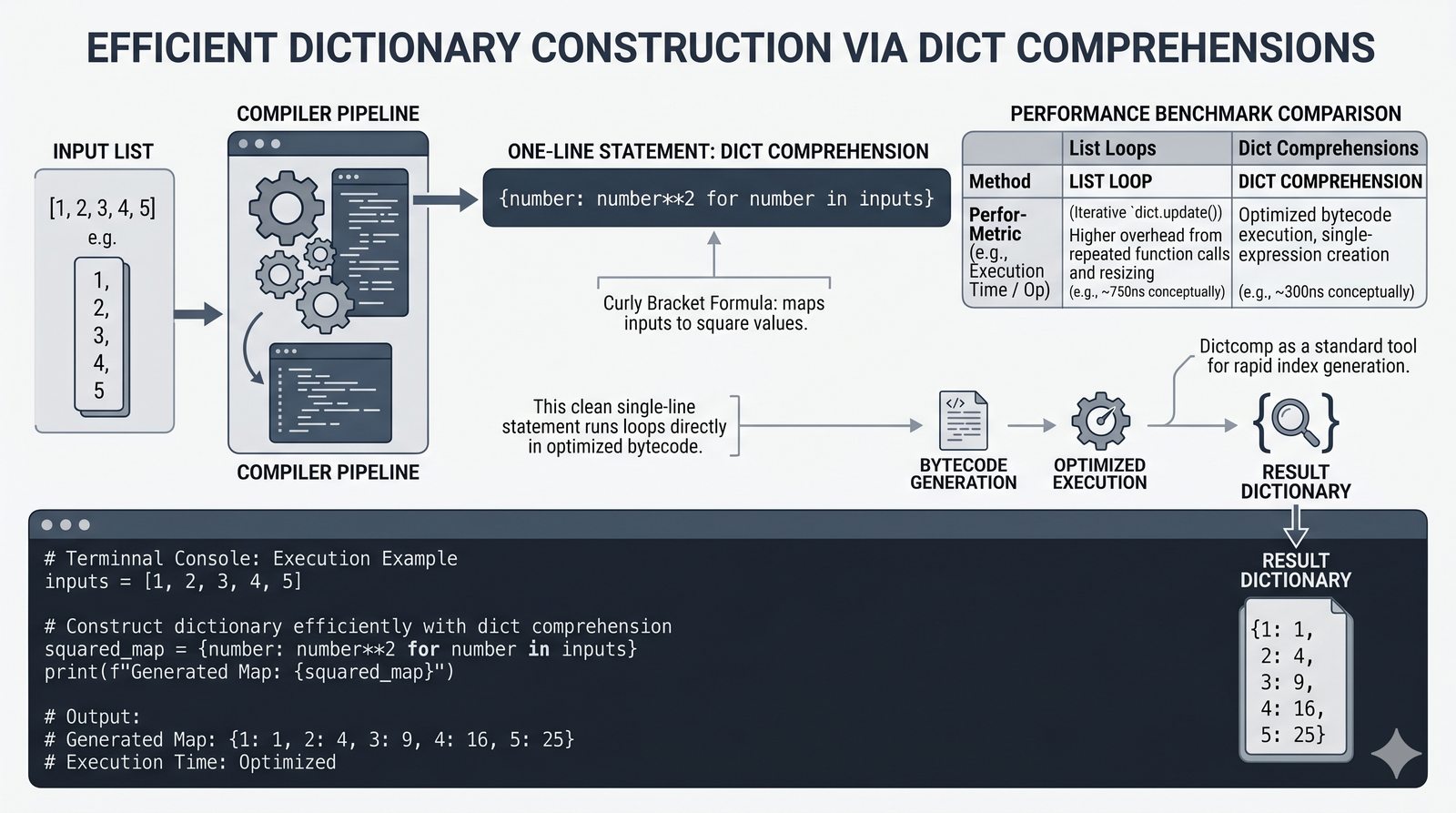
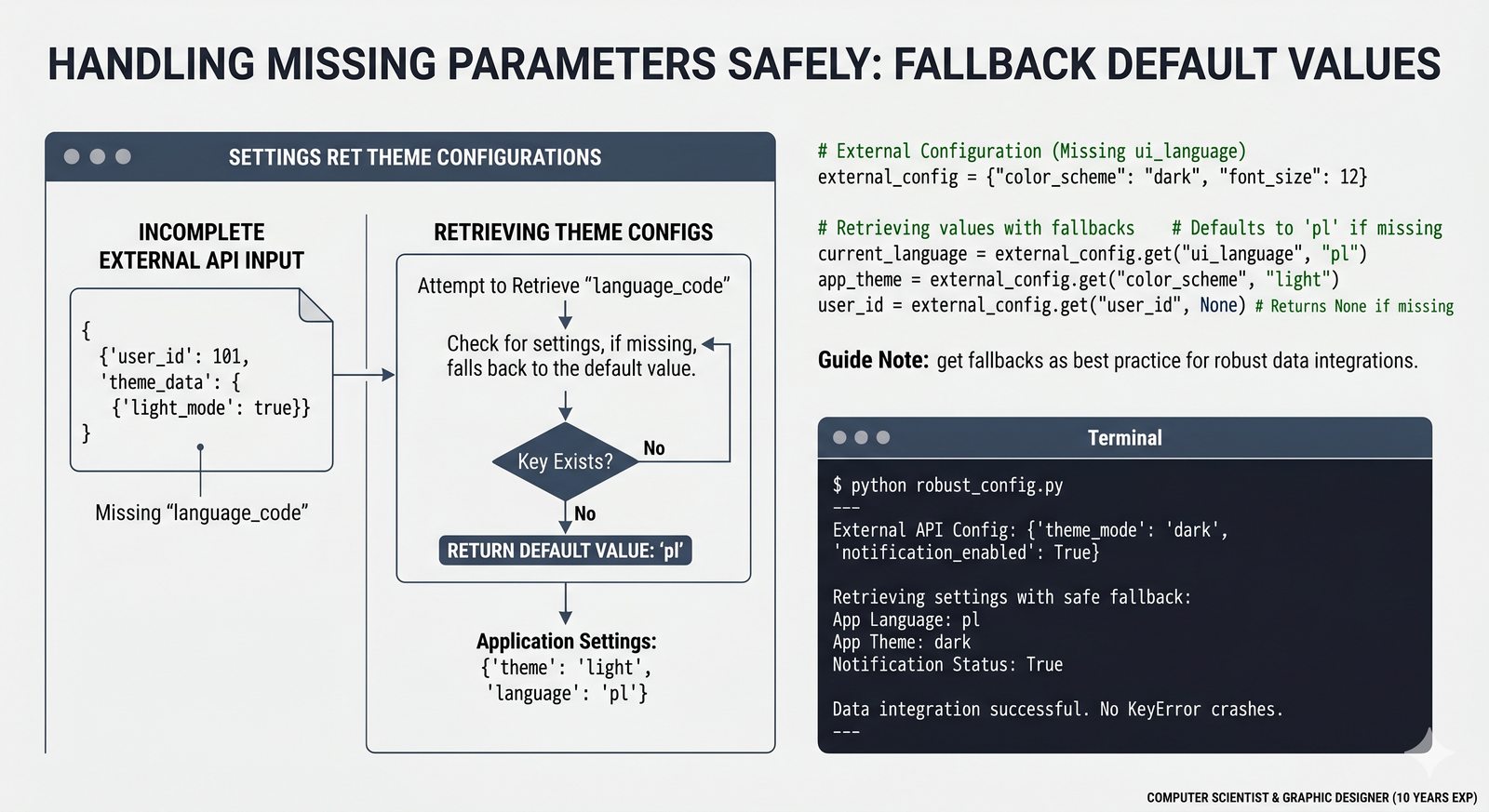
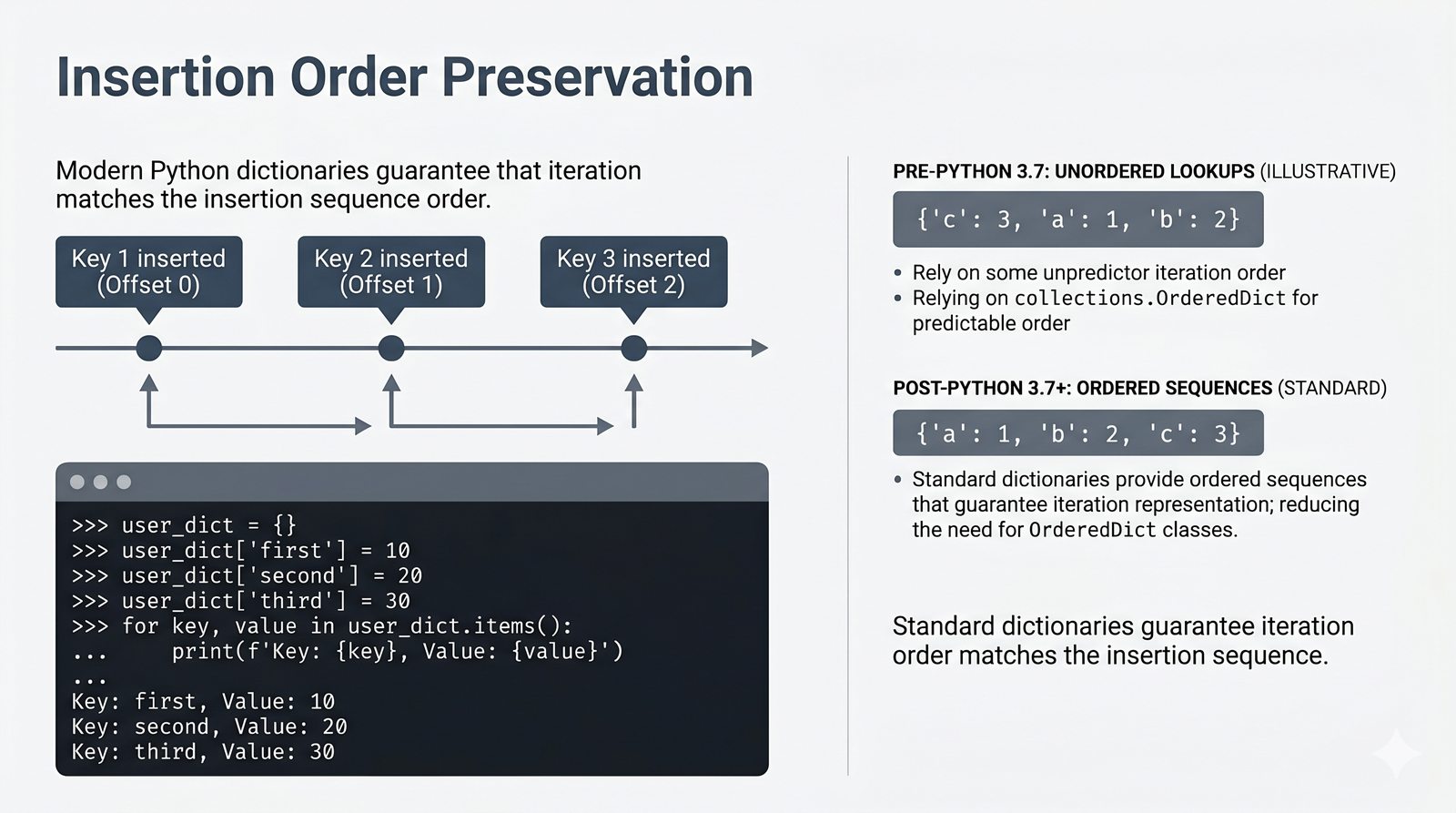
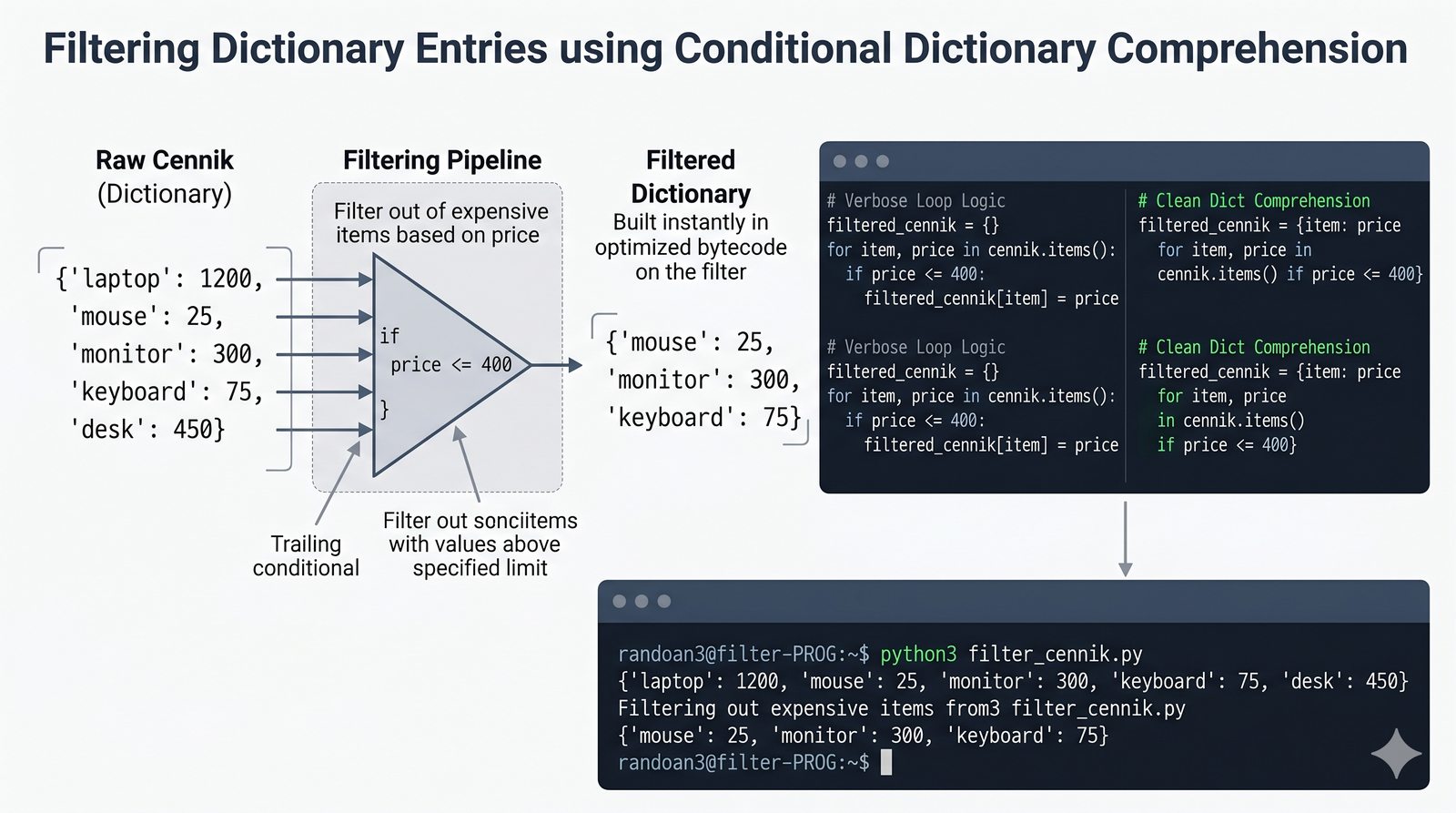
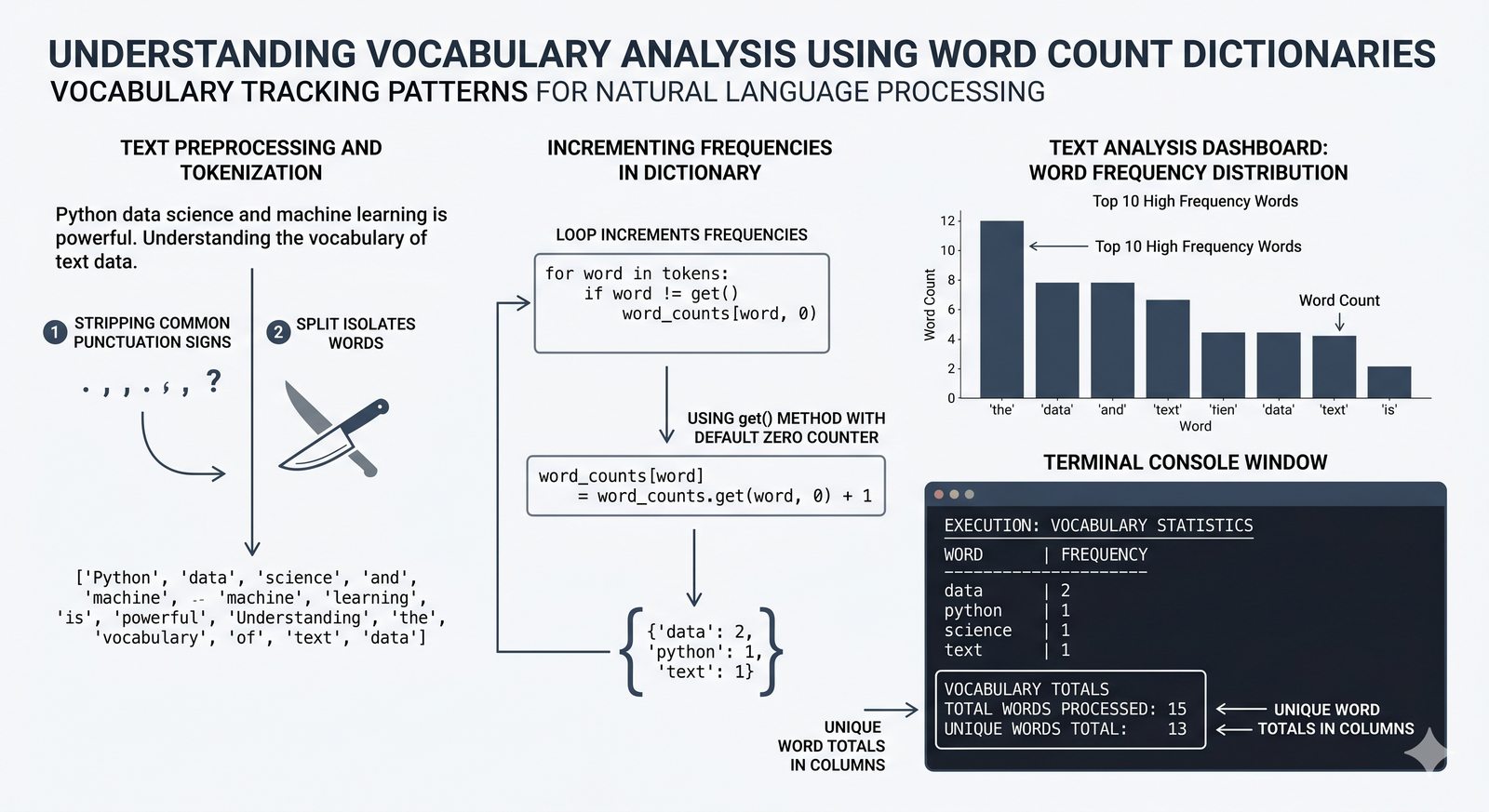
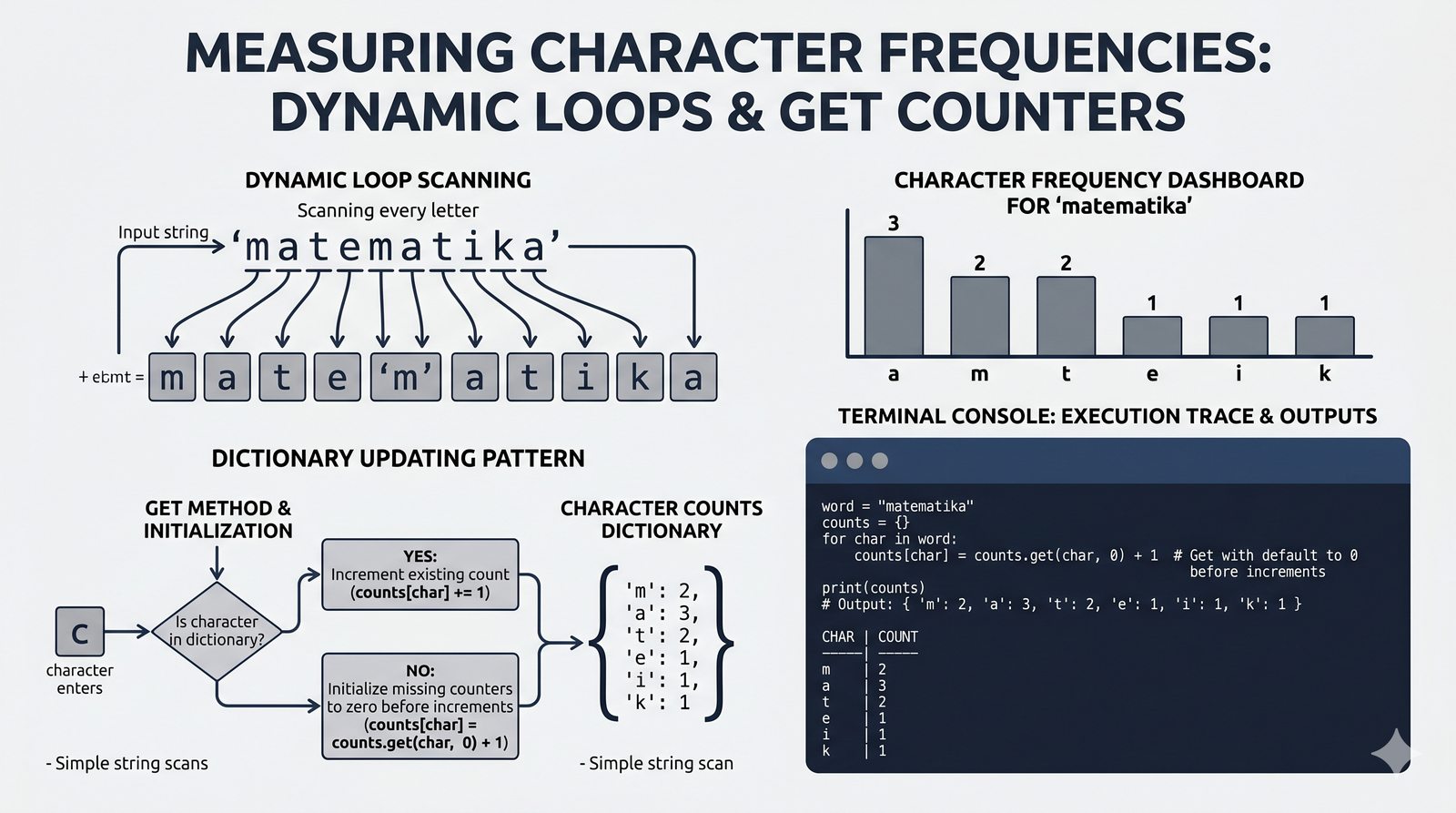
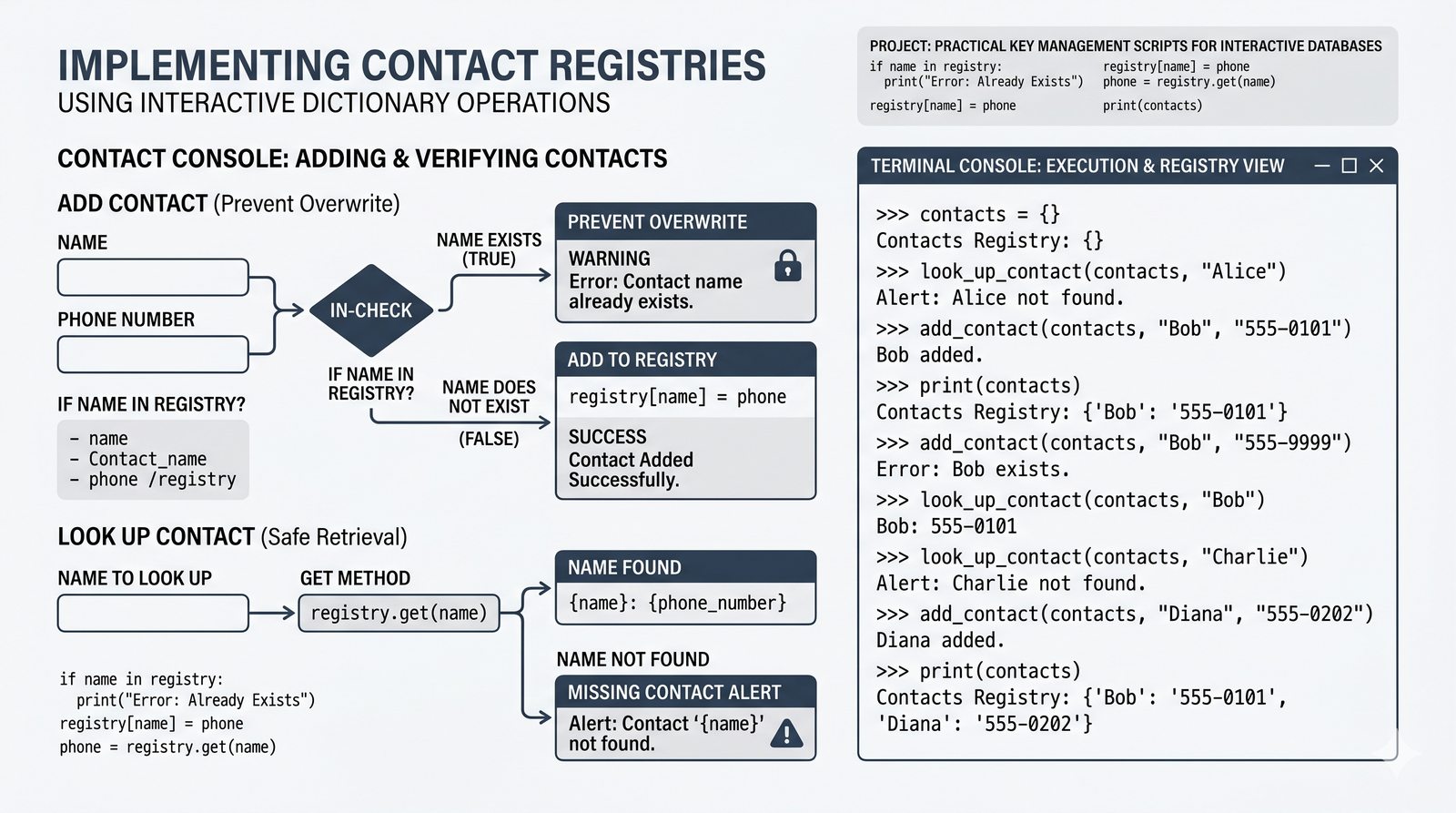
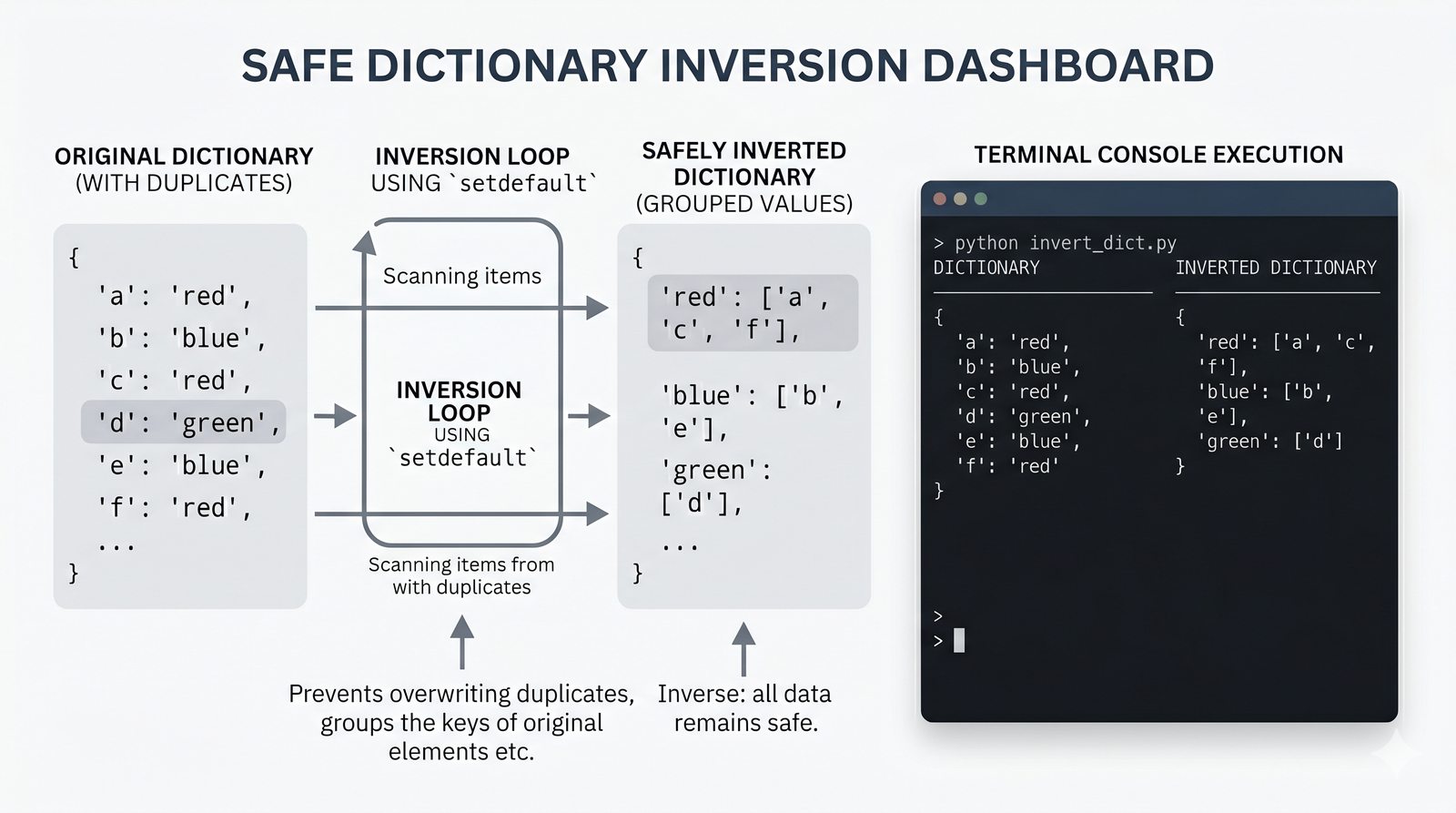
- Słowniki -- tworzenie, modyfikacja, bezpieczny dostęp (get, setdefault), iteracja i dict comprehension
- Zaawansowane wzorce -- słowniki zagnieżdżone, filtrowanie danych, porównanie wydajności kolekcji
- Ćwiczenia praktyczne -- system magazynowy, wyszukiwanie wspólnych znajomych, licznik słów i inwersja słownika