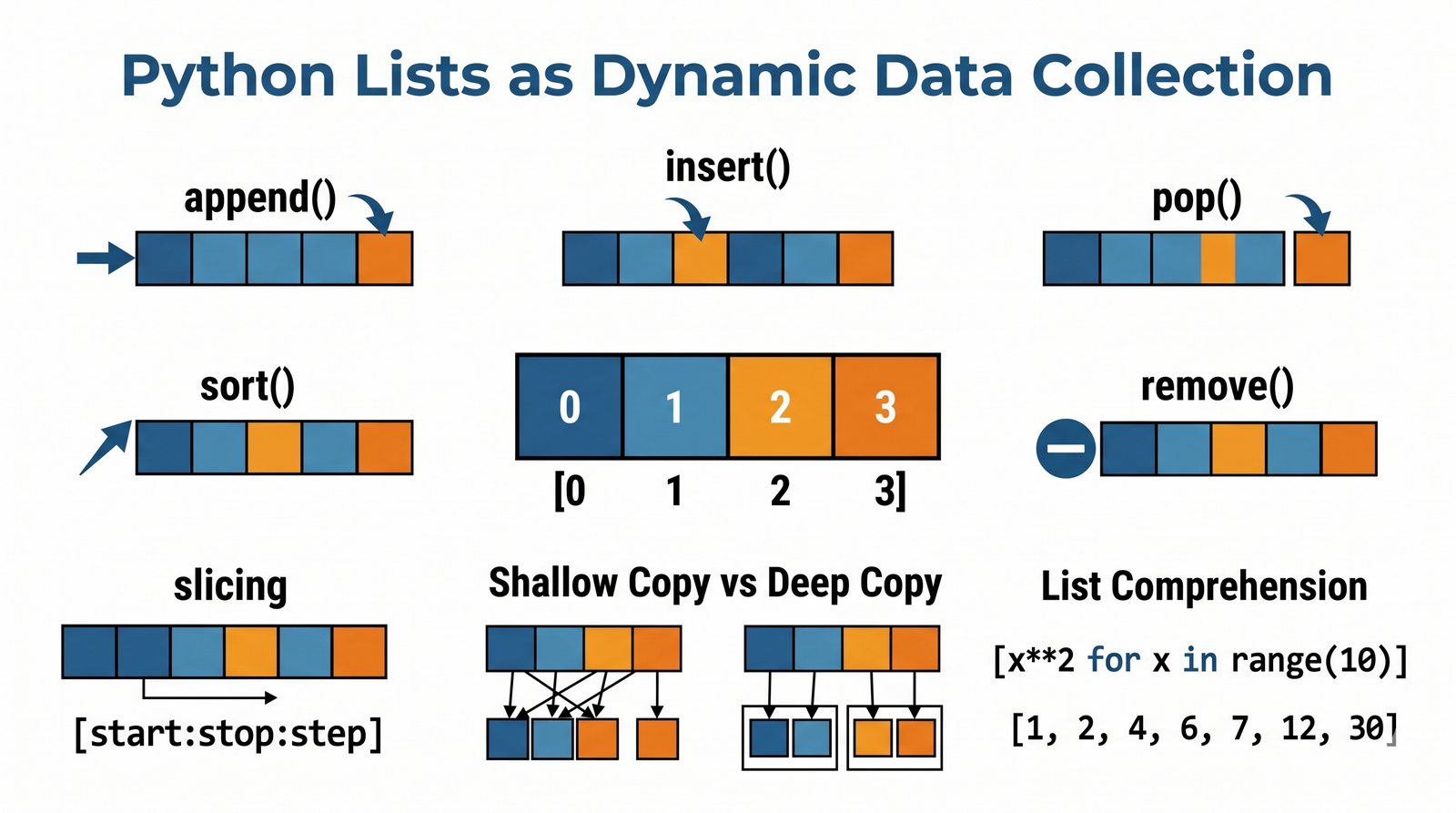
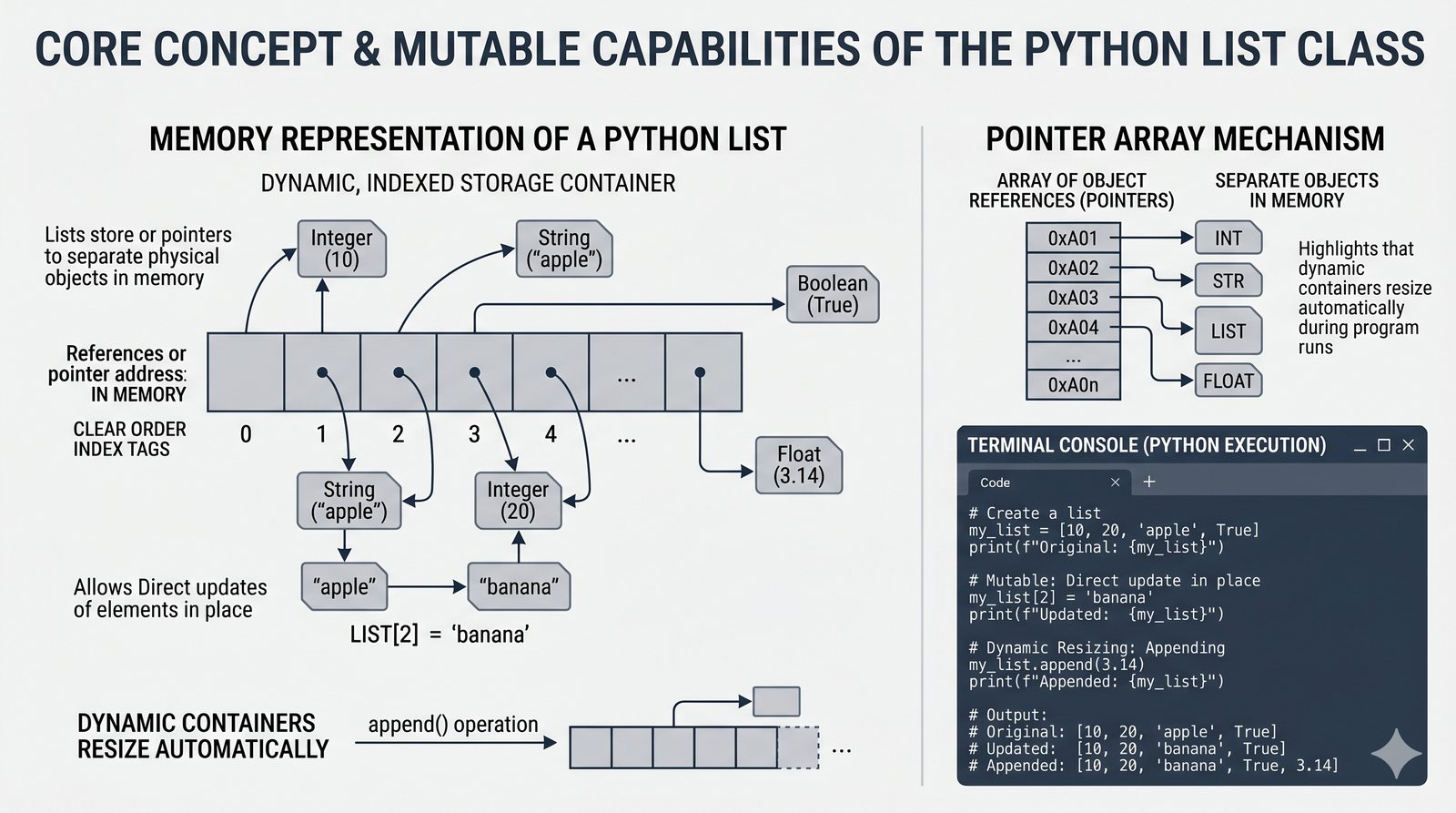
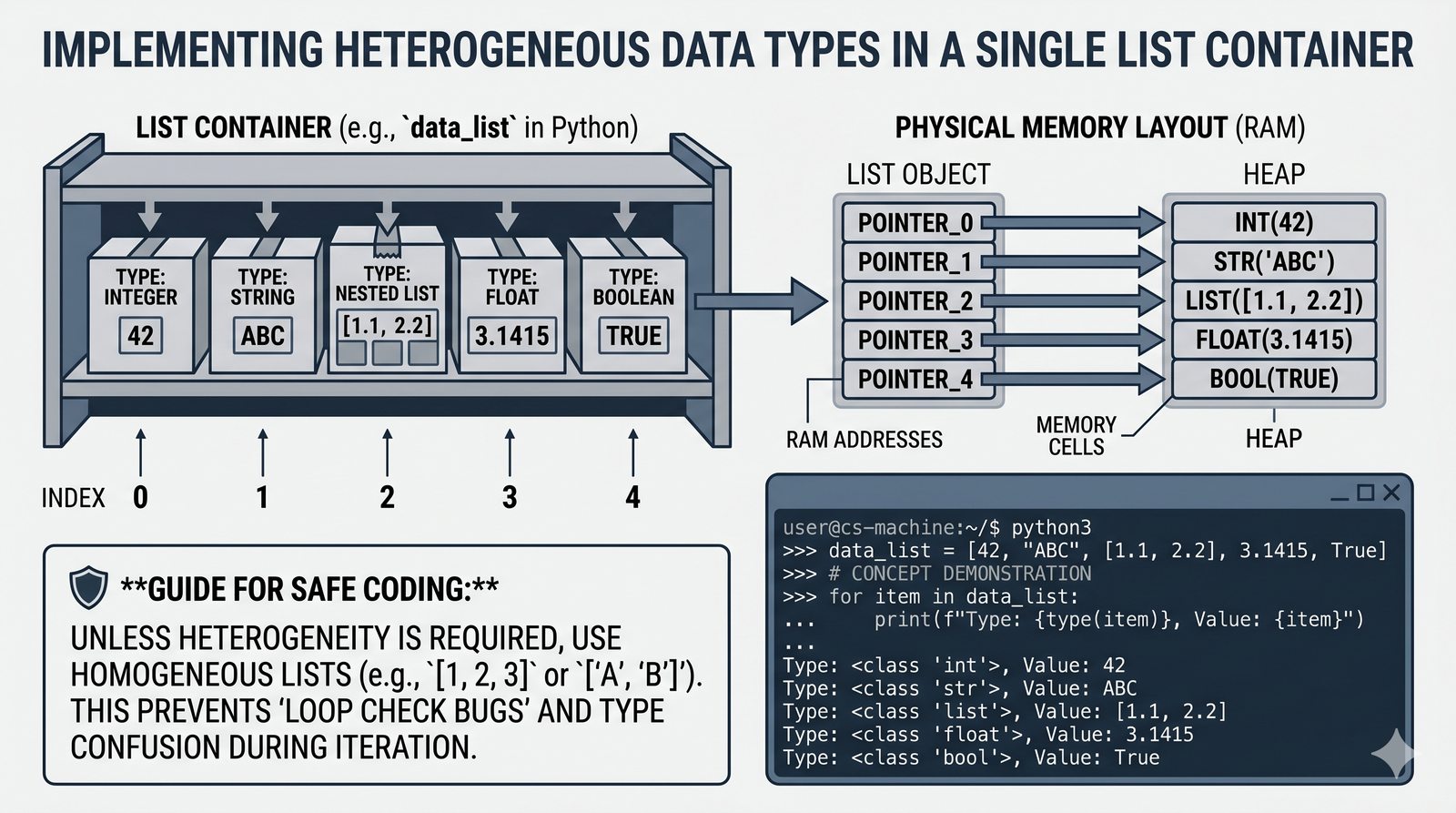
Moduł w całości poświęcony jest jednej z najważniejszych i najczęściej używanych struktur danych w języku Python – dynamicznym listom (typ list). Omówiono w nim mechanizmy tworzenia list, indeksowania dodatniego i ujemnego oraz wycinków (slicing) z krokiem, które pozwalają na elastyczne wyodrębnianie fragmentów kolekcji. Przedstawiono bogaty zestaw wbudowanych metod modyfikujących listy w miejscu, takich jak append(), insert(), extend(), remove(), pop() oraz sort(), a także funkcje wbudowane len() i sorted(). Szczegółowo przeanalizowano mechanizmy kopiowania list, w tym kopiowanie powierzchowne (shallow copy) oraz pełne (deep copy) z modułu copy, wraz z pułapką aliasingu referencji. Materiał zawiera również zaawansowane techniki, takie jak wyrażenia listowe (list comprehension), listy zagnieżdżone oraz praktyczne programy i ćwiczenia utrwalające wiedzę.
Kluczowe zagadnienia modułu:
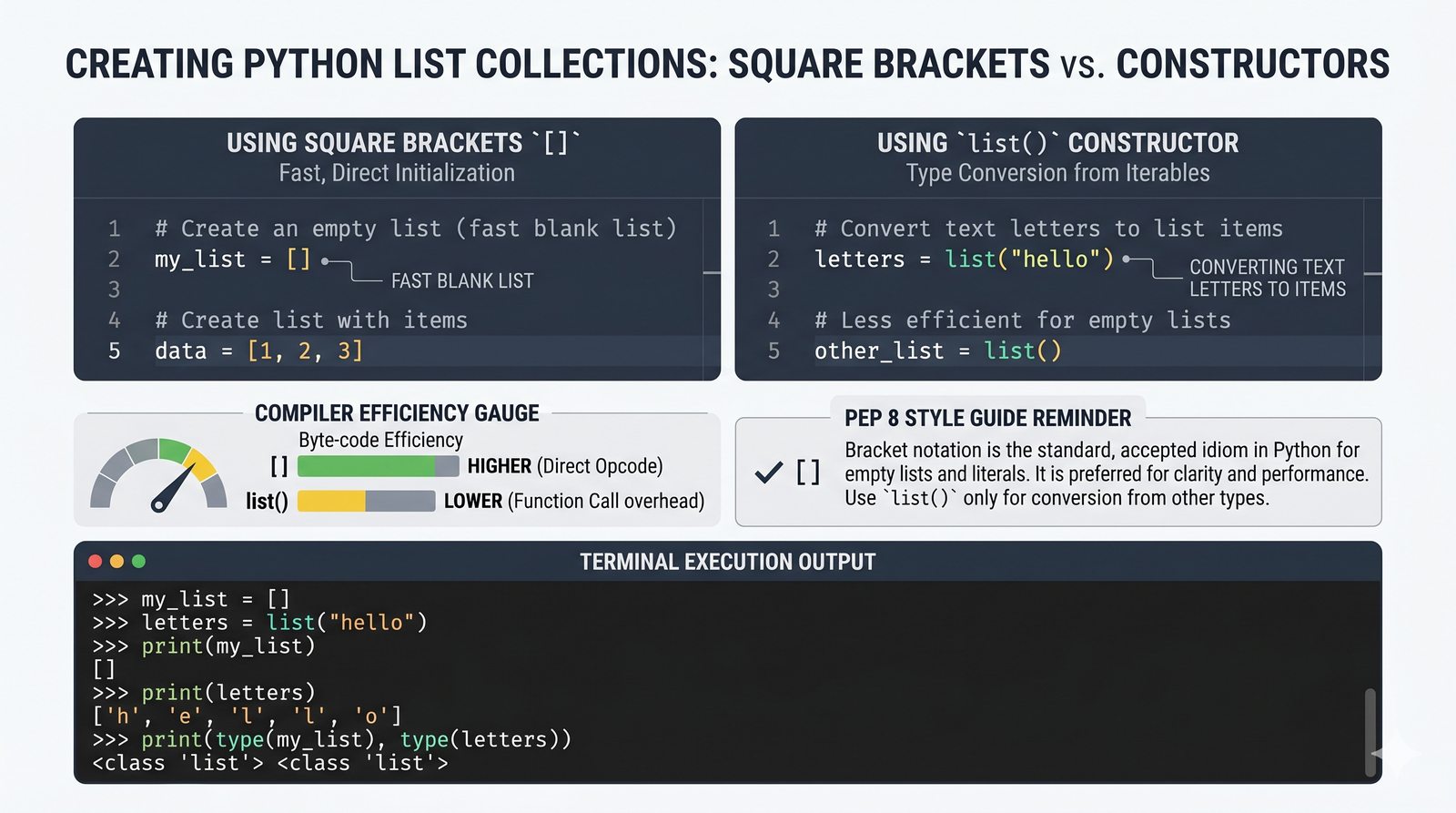
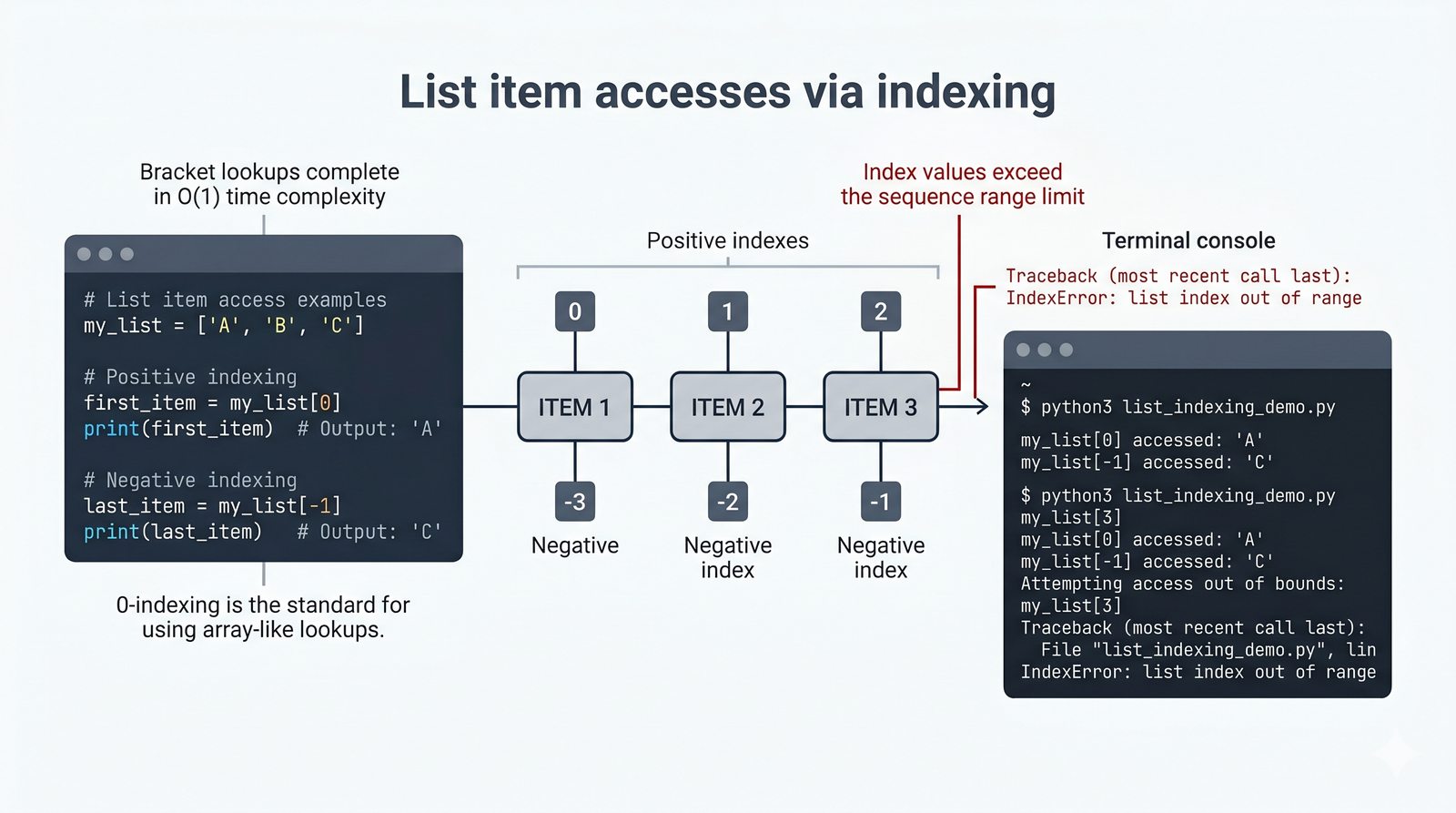
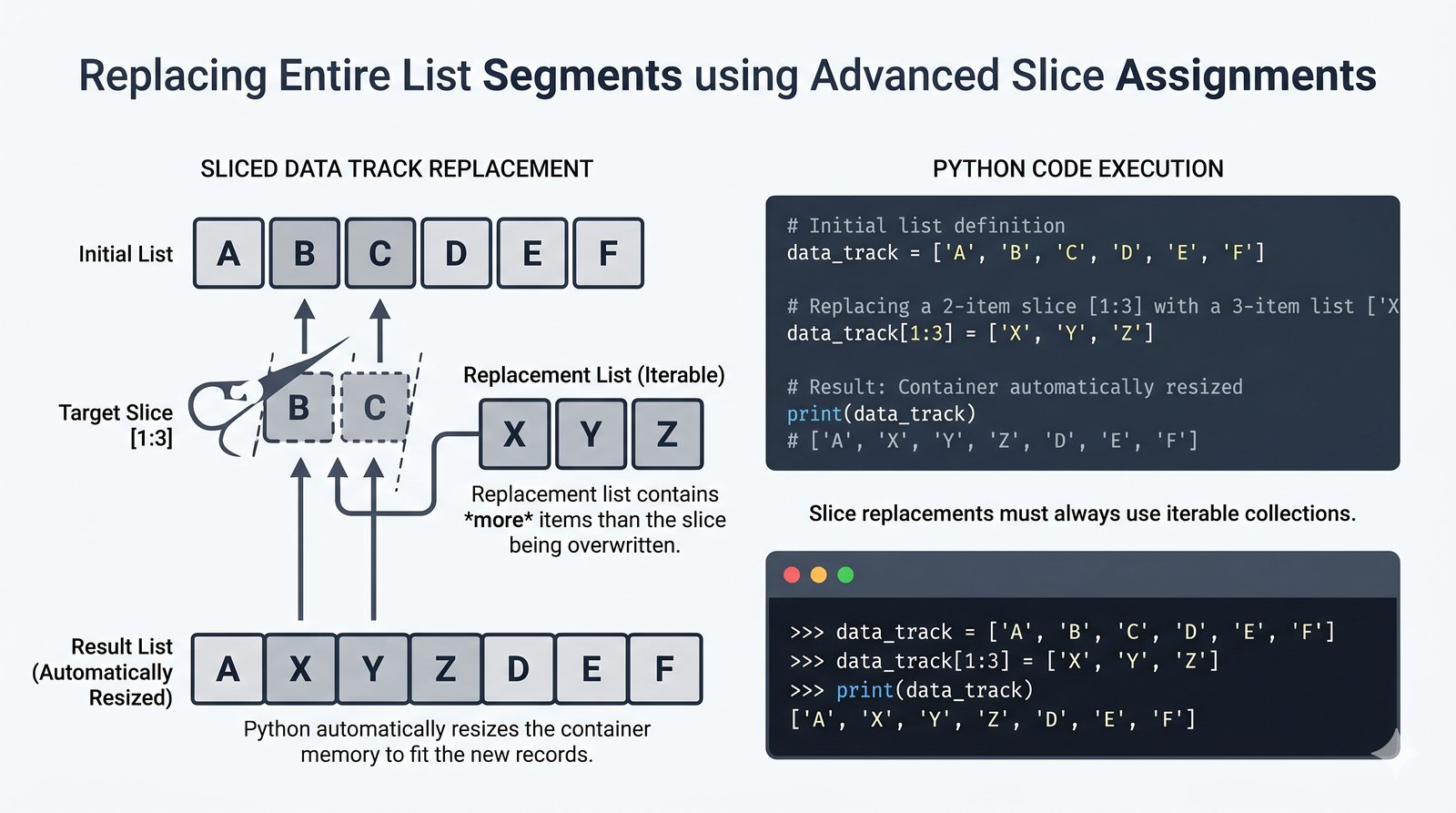
- Tworzenie, indeksowanie i wycinki — definiowanie list za pomocą
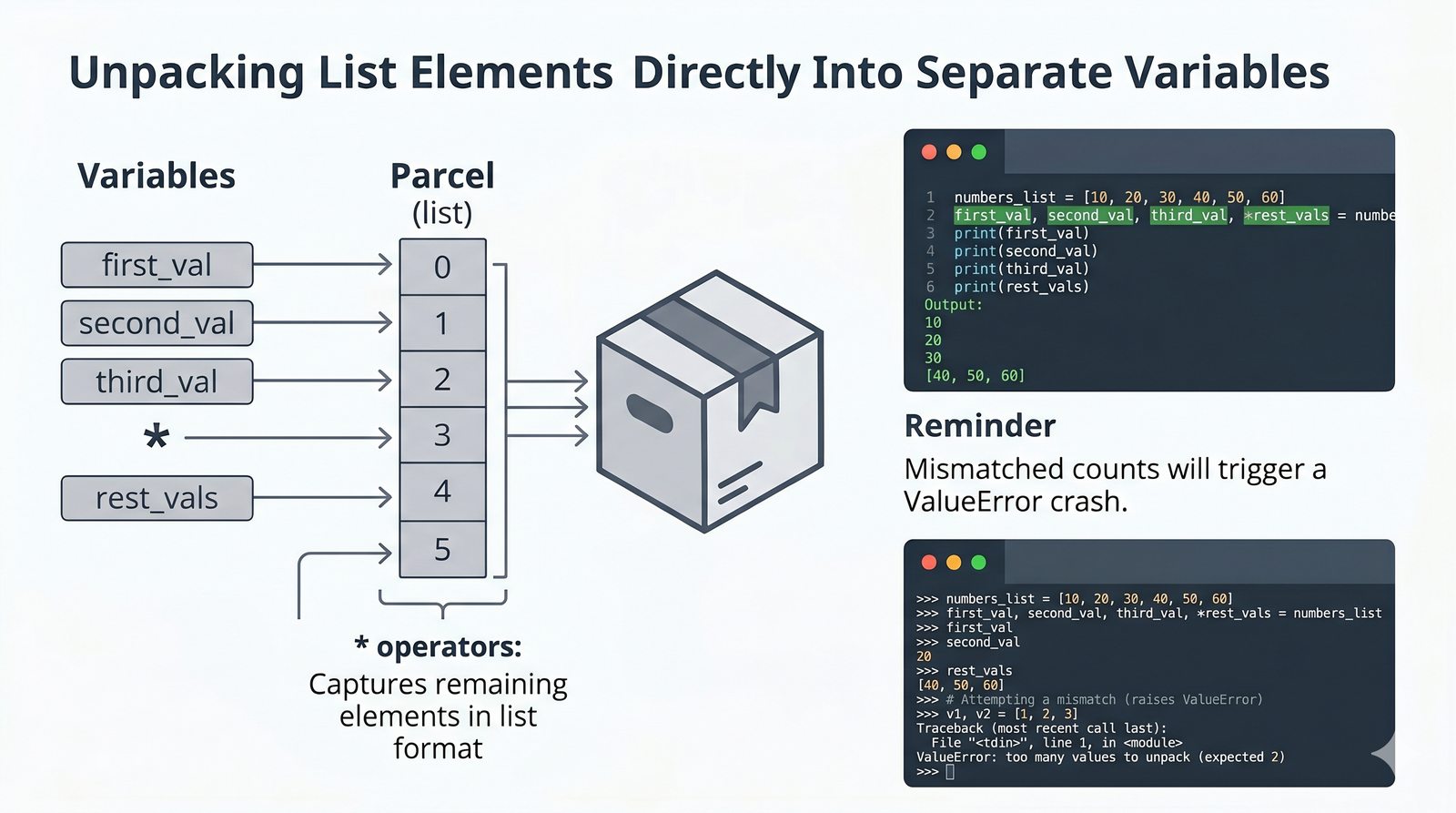
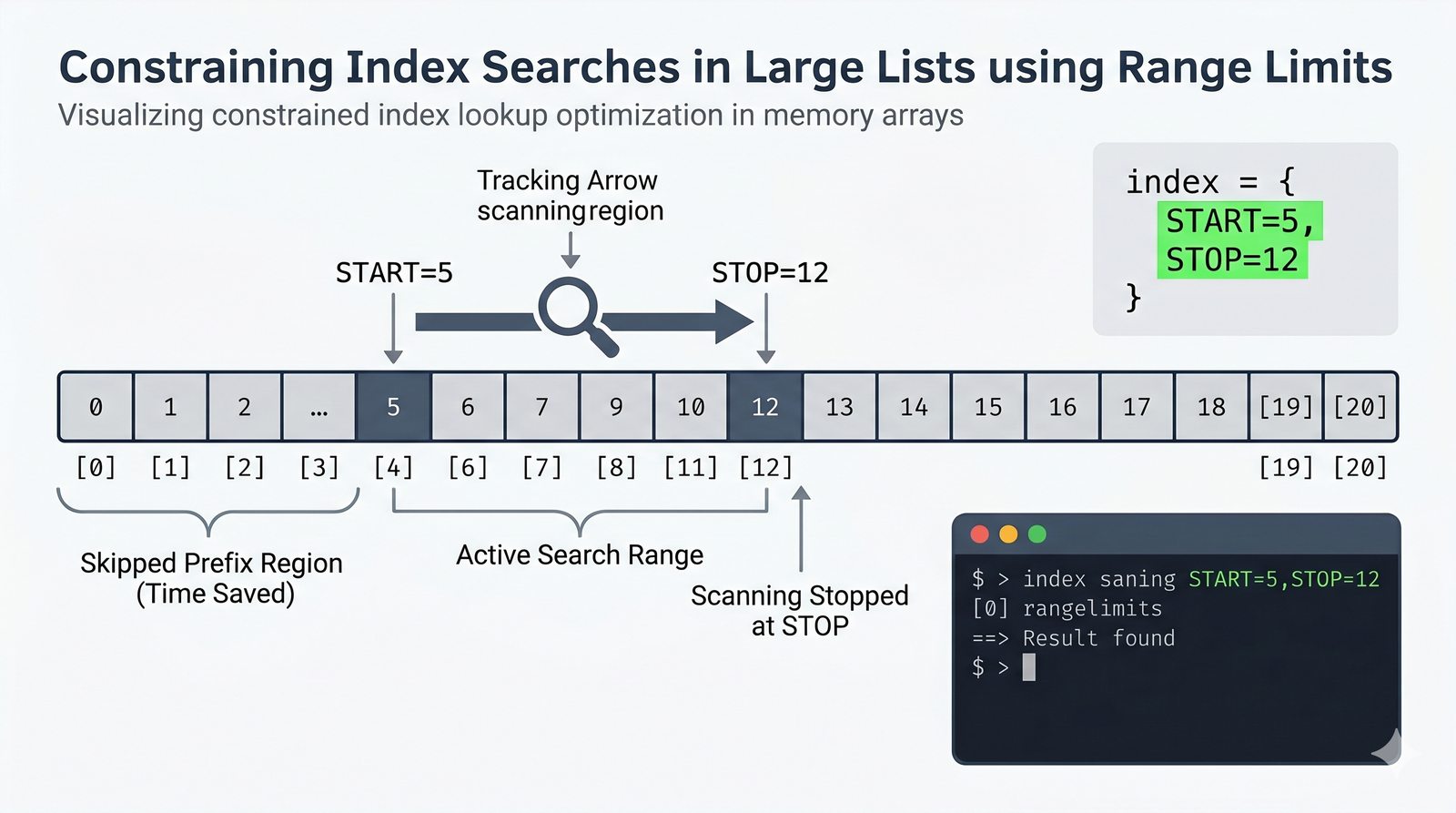
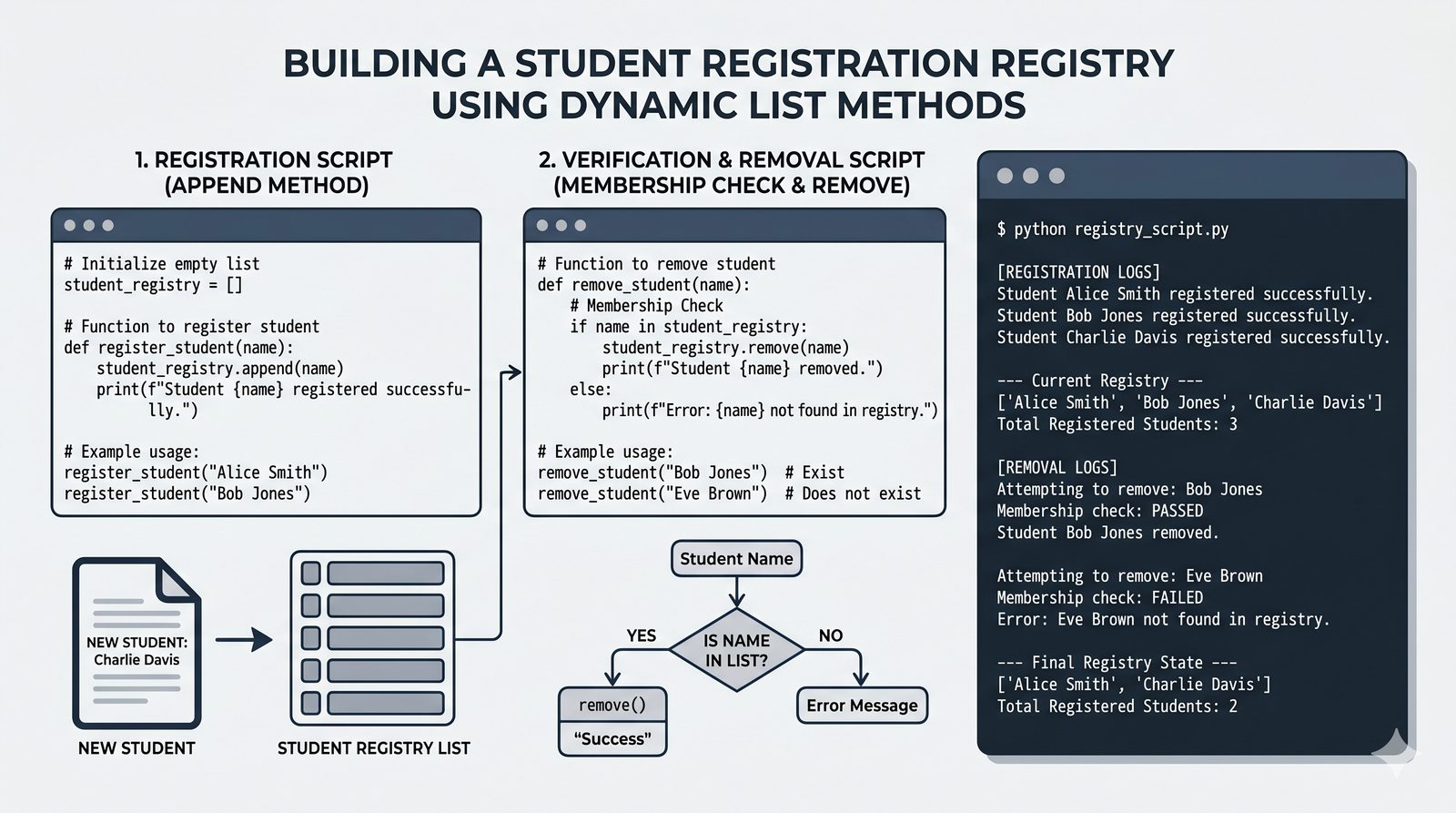
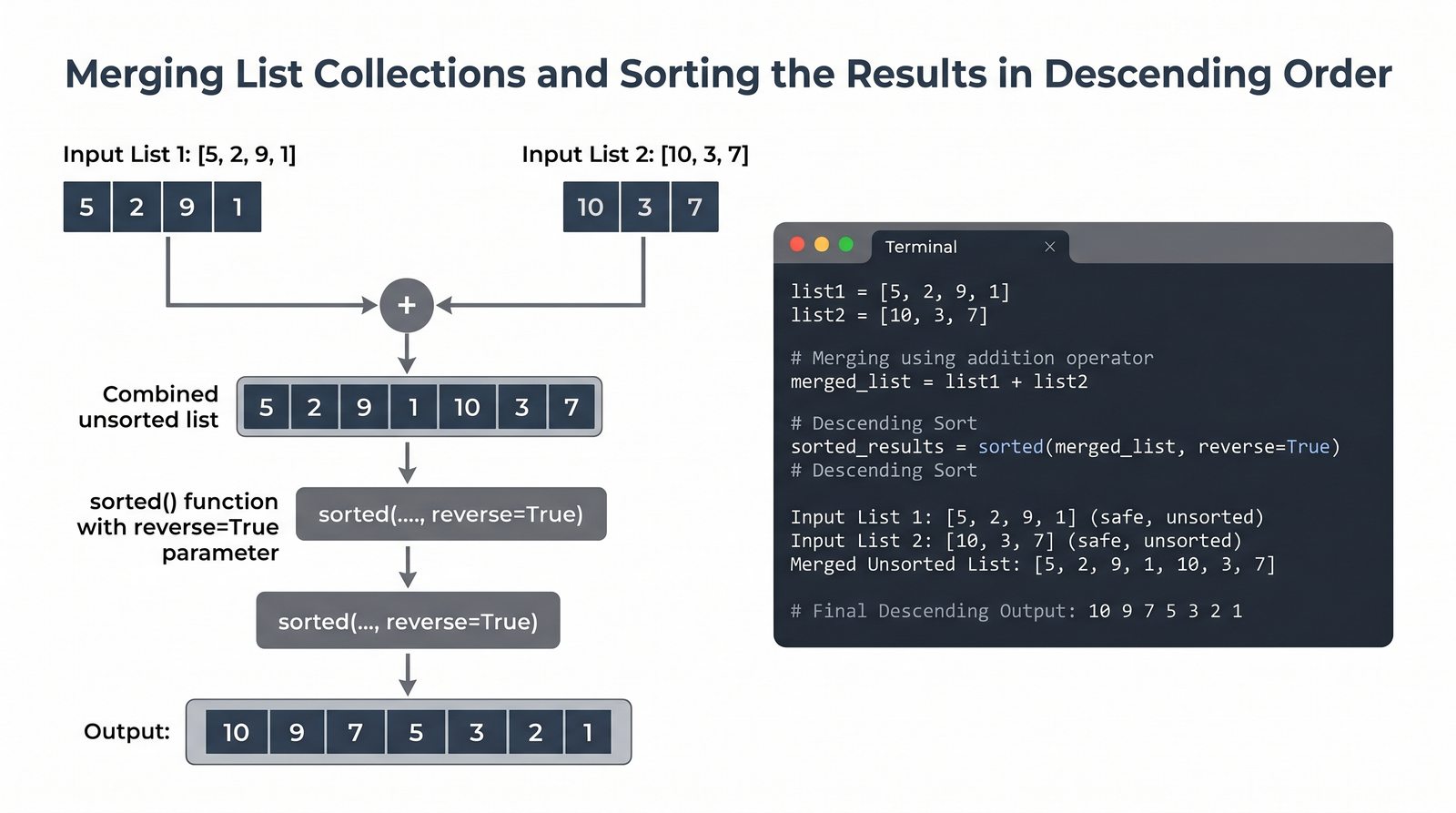
[], dostęp przez indeksy dodatnie i ujemne oraz wyodrębnianie fragmentów[start:stop:krok] - Modyfikacja w miejscu — dodawanie (
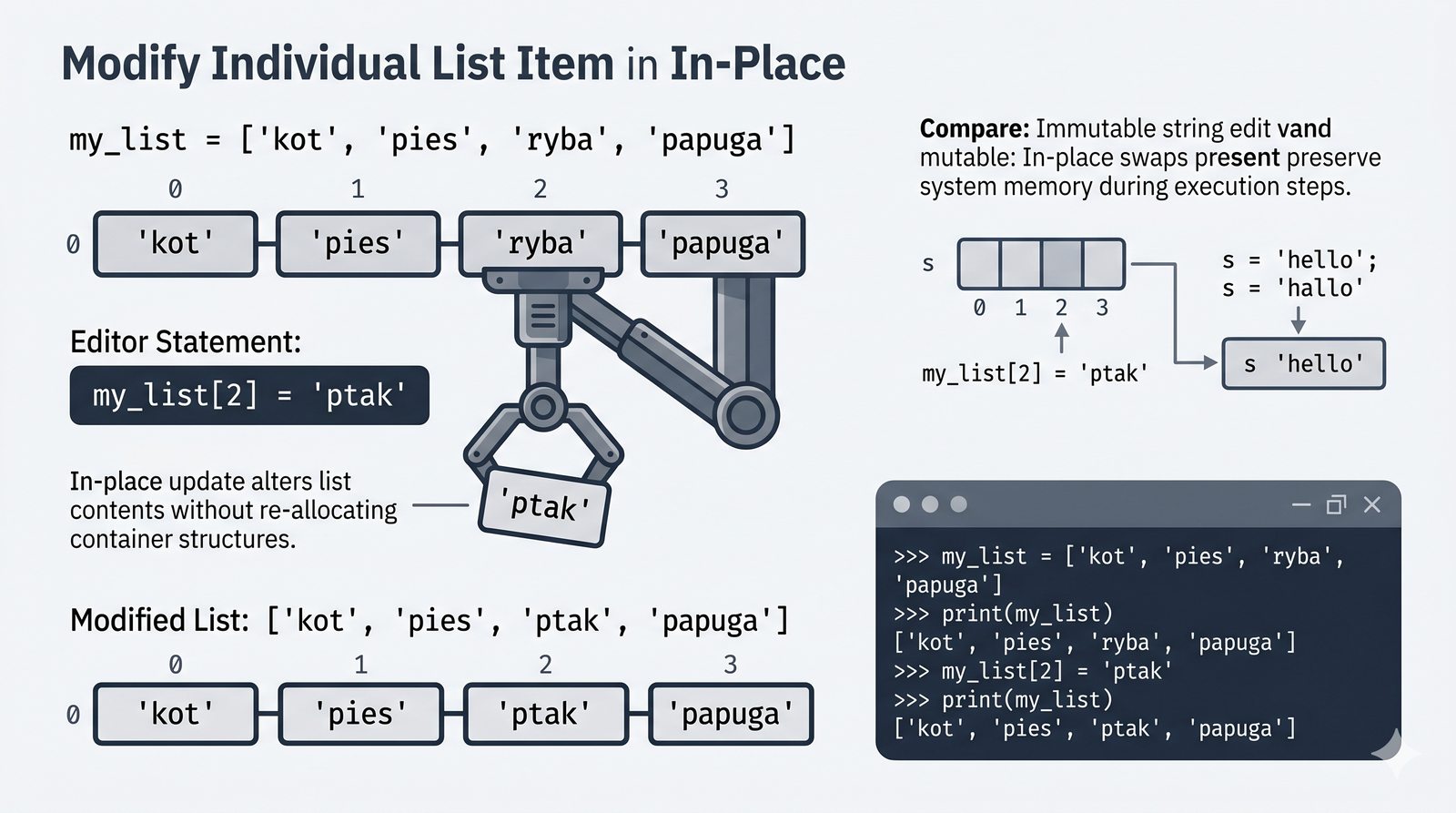
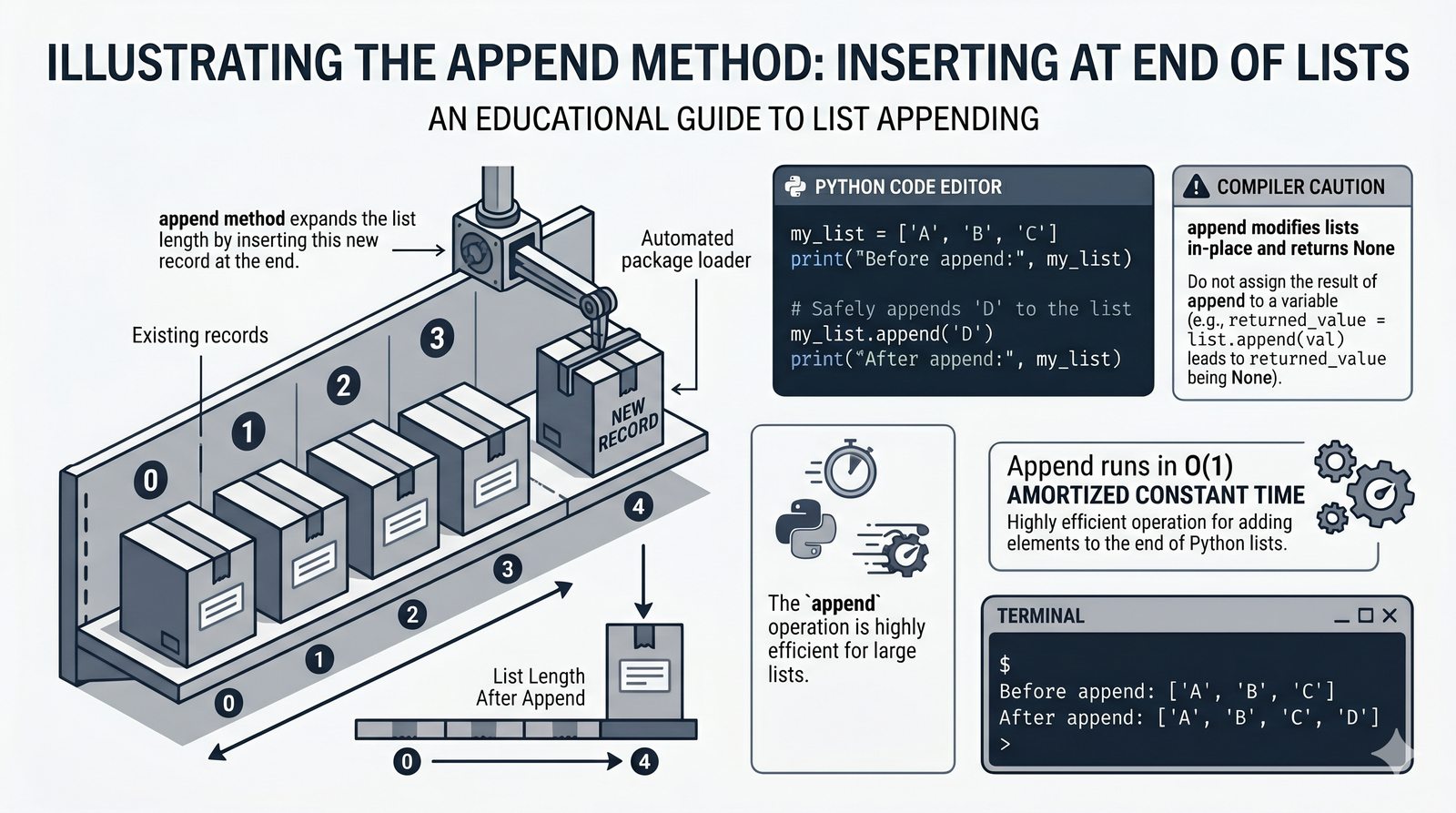
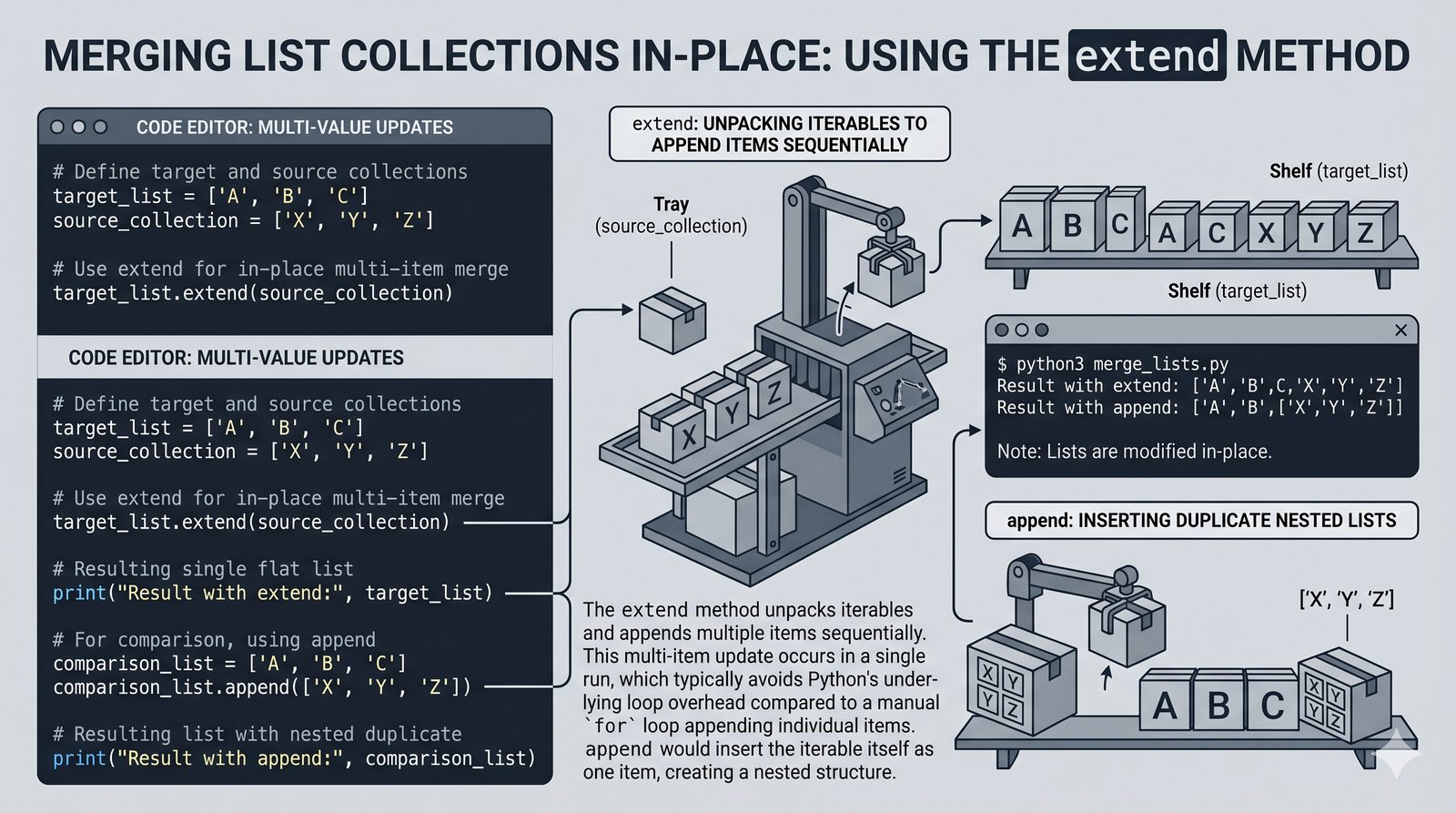
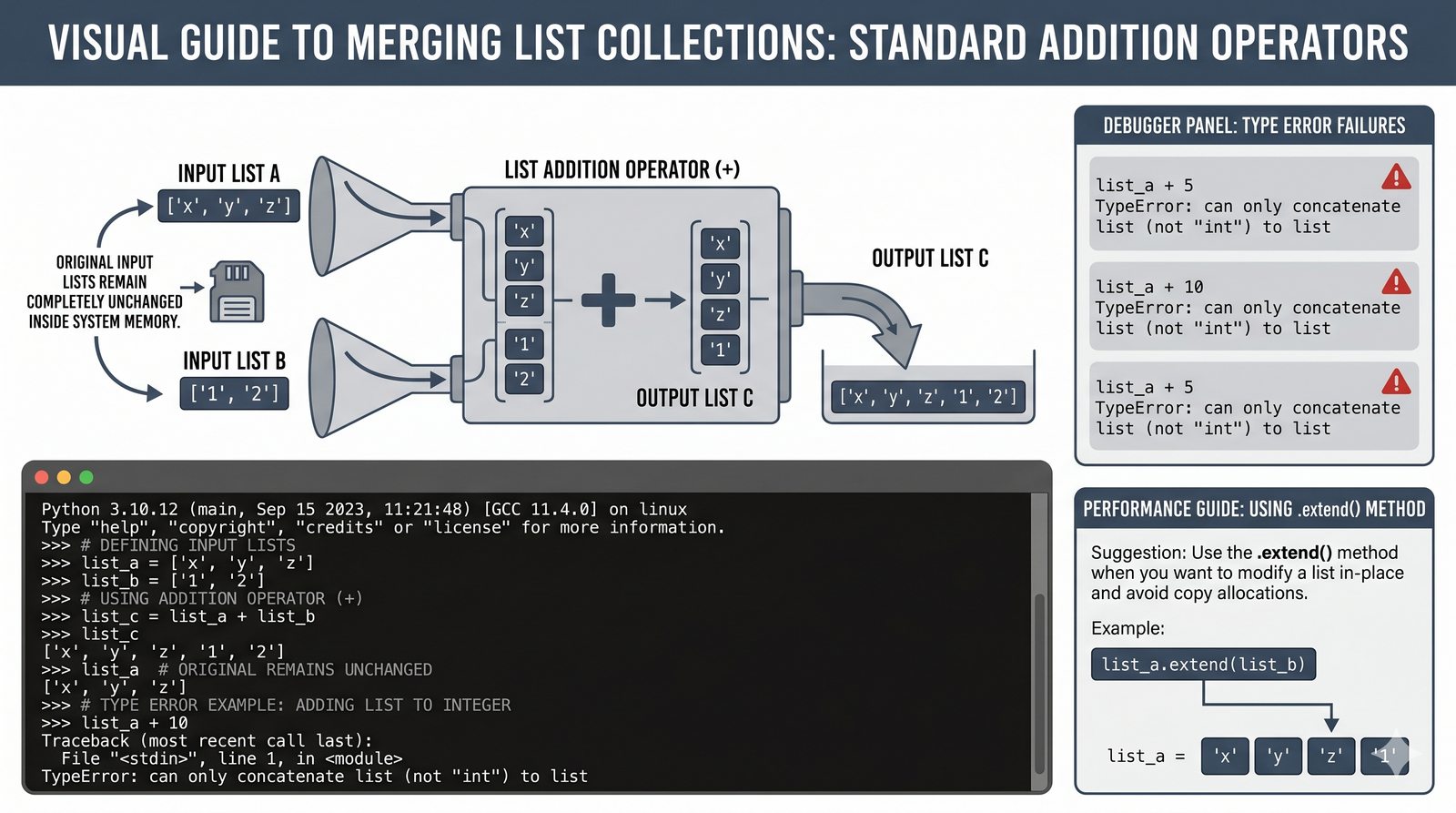
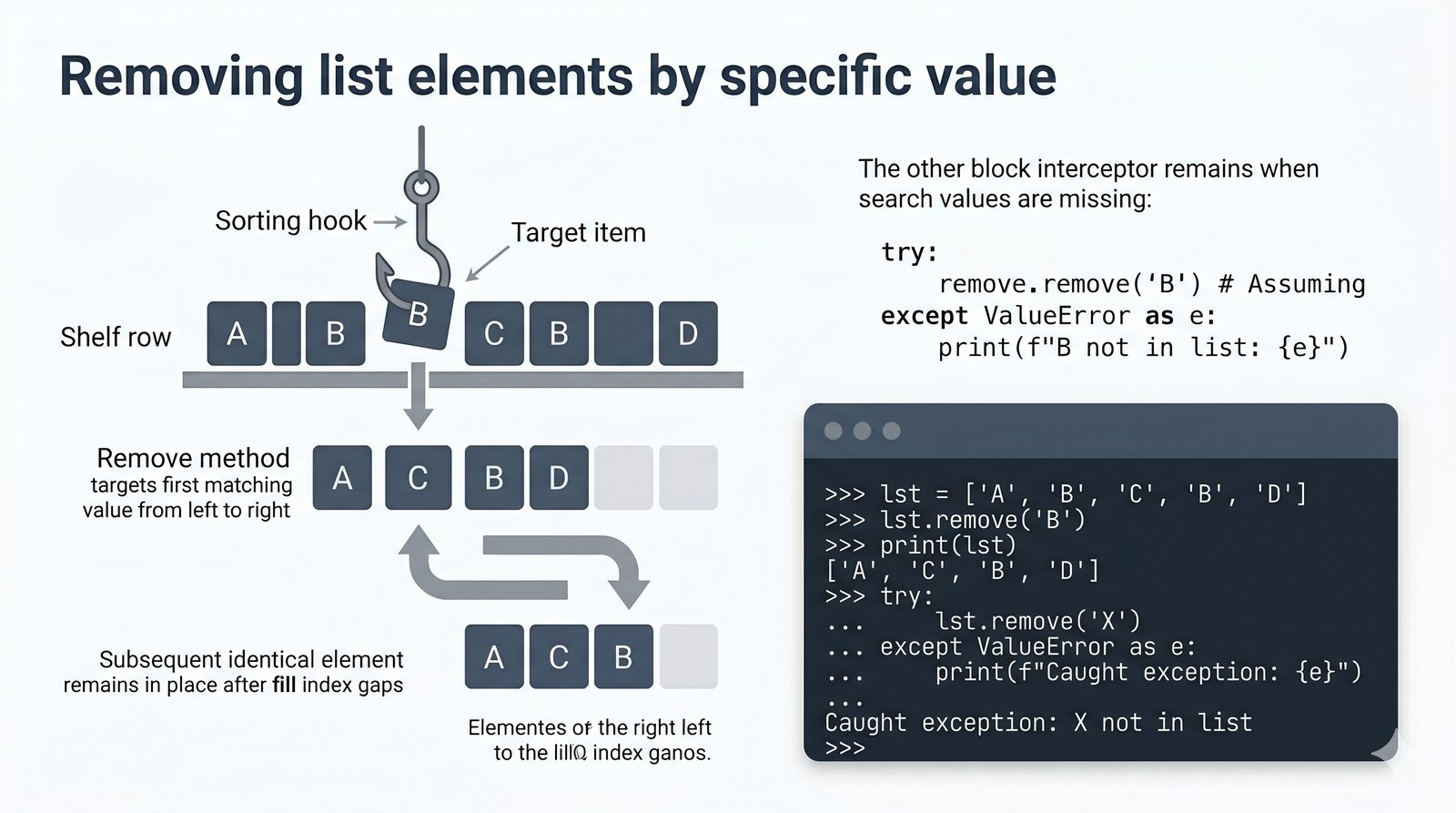
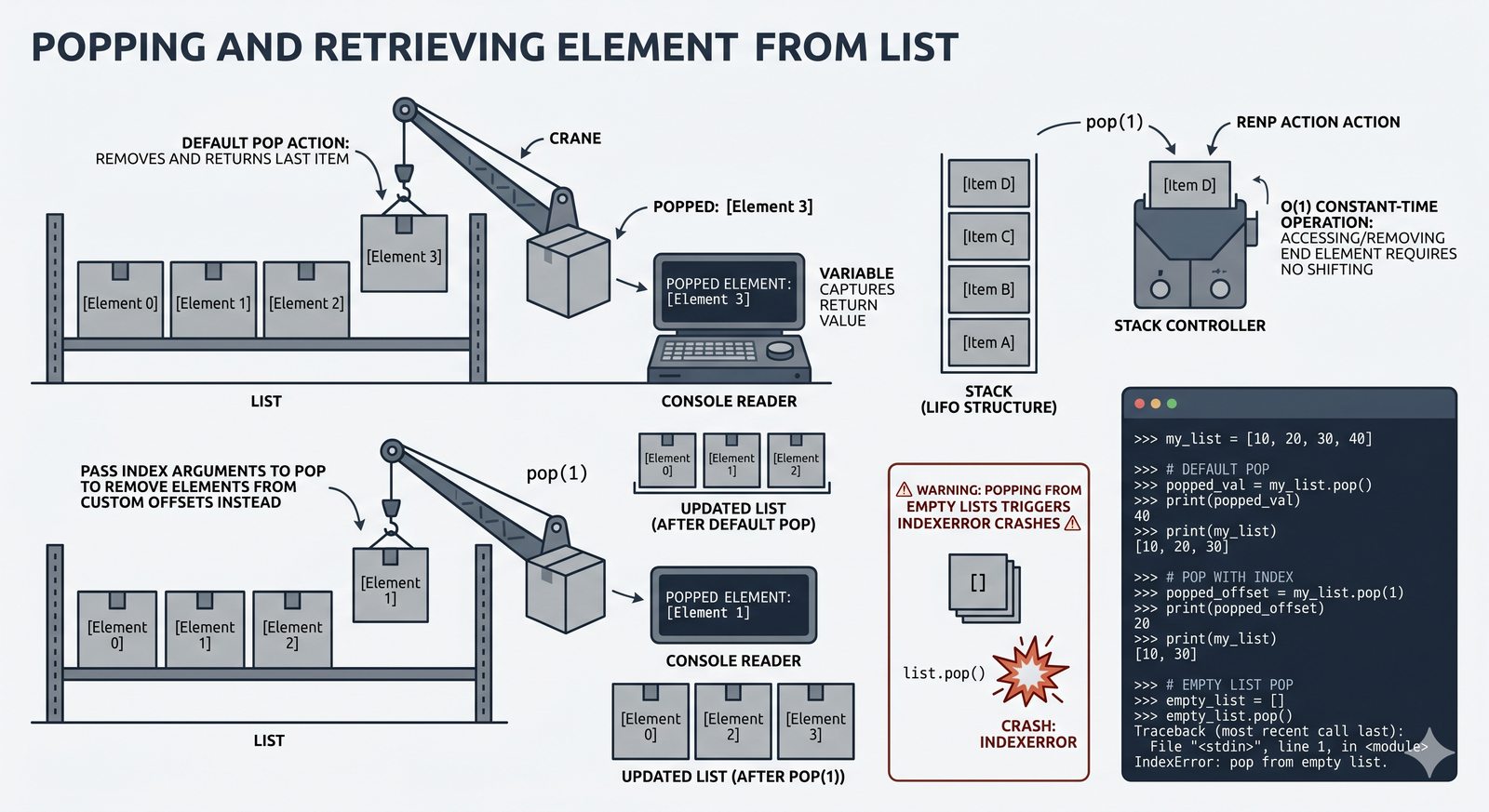
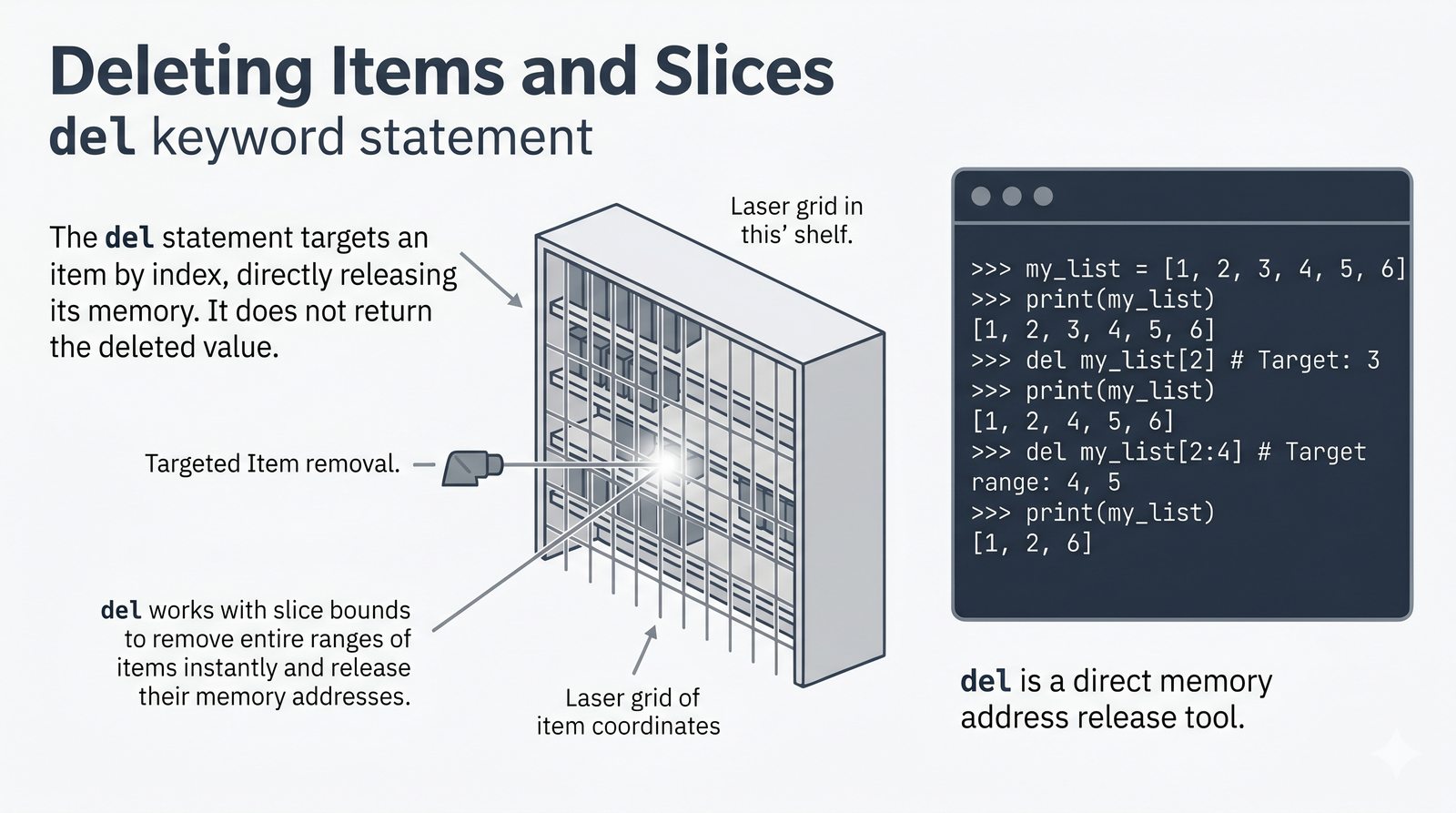
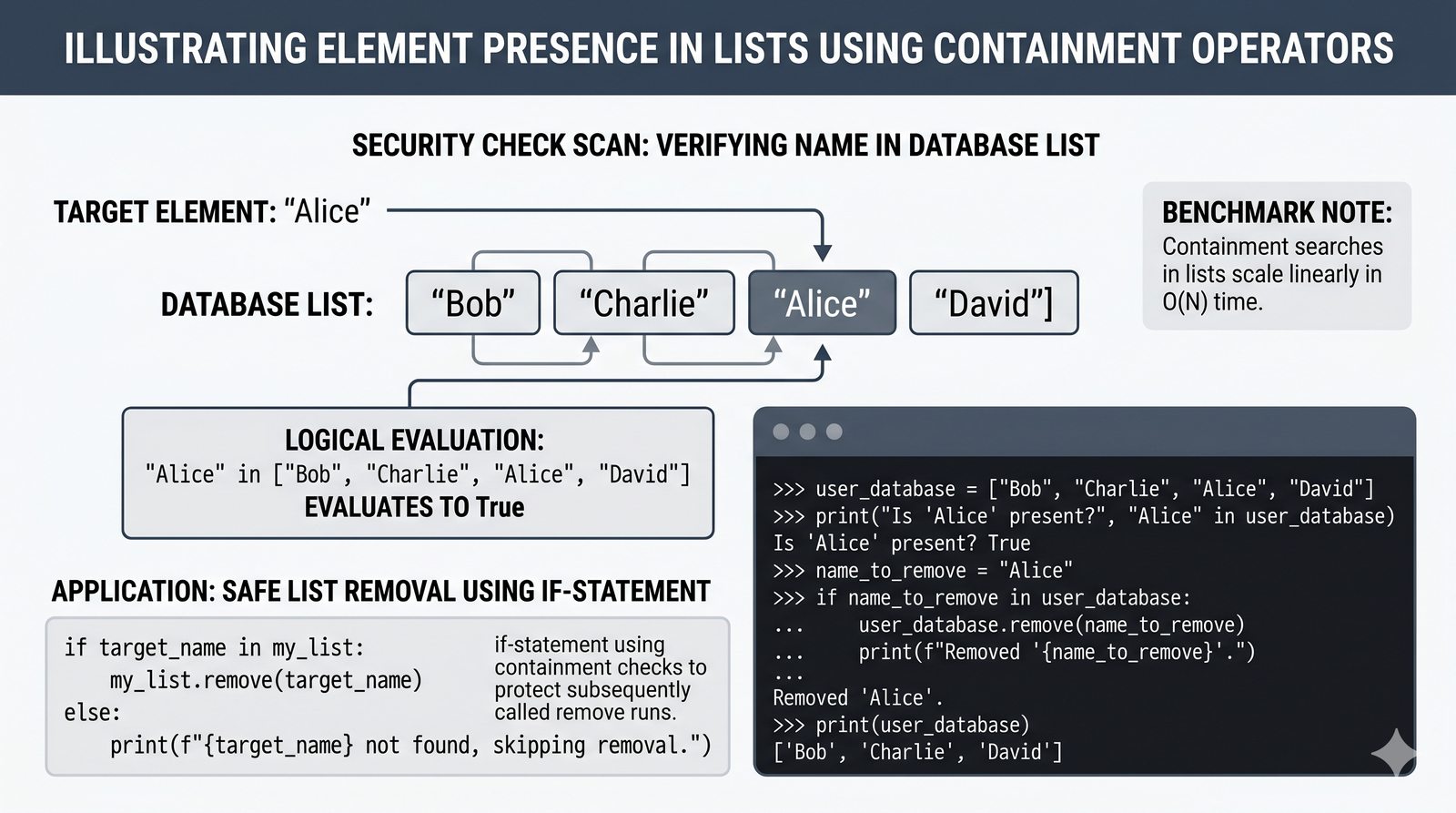
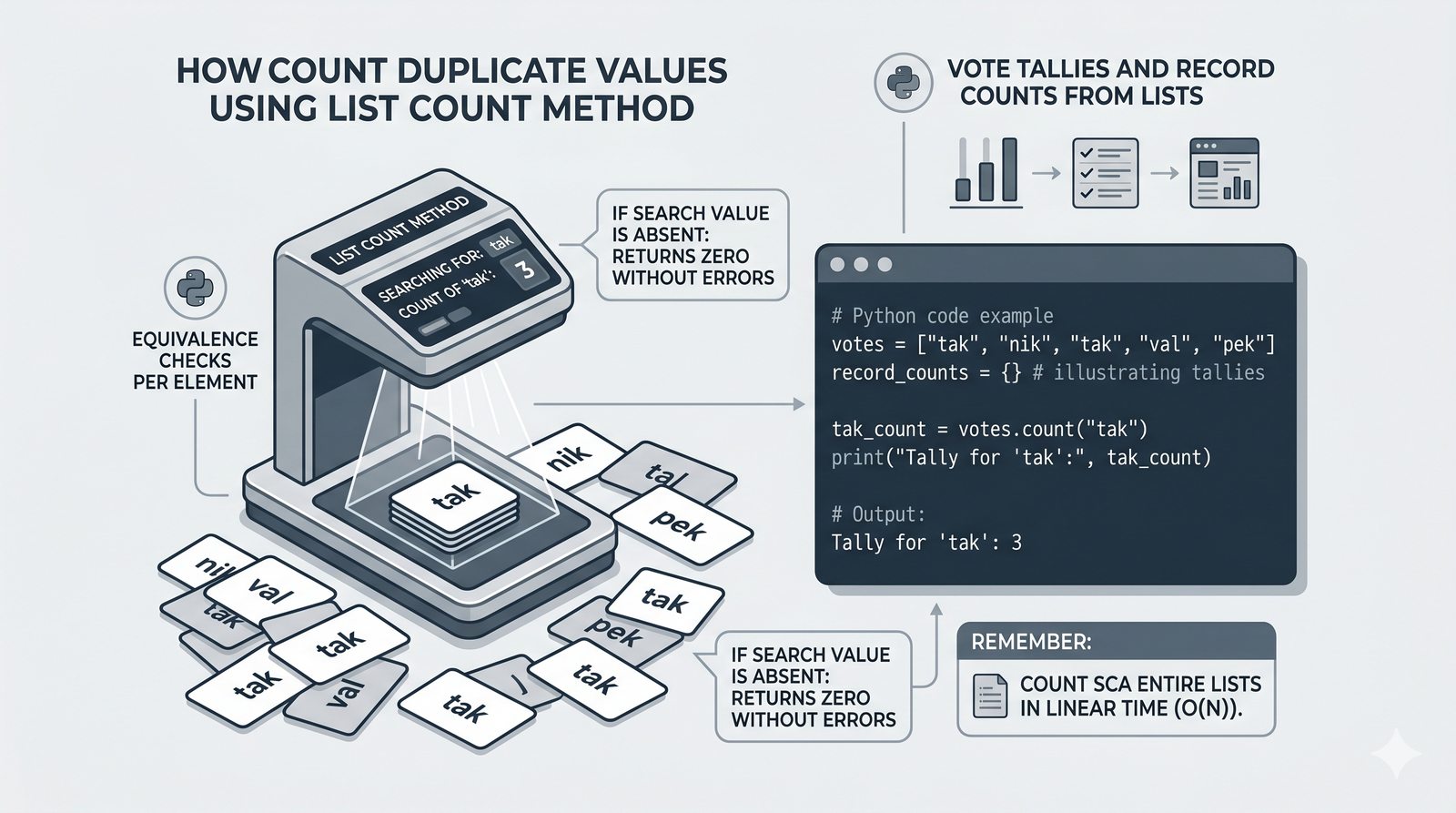
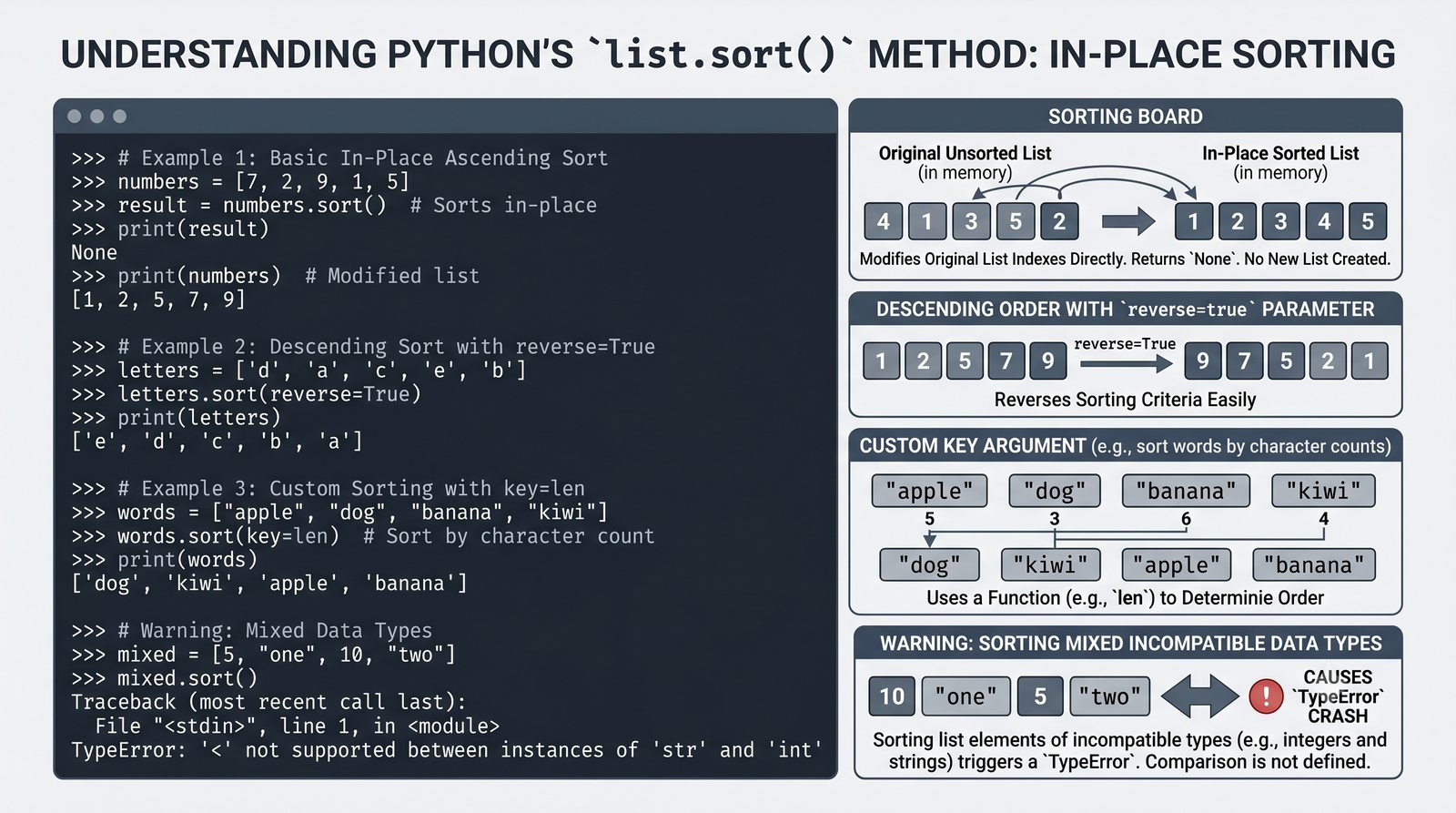
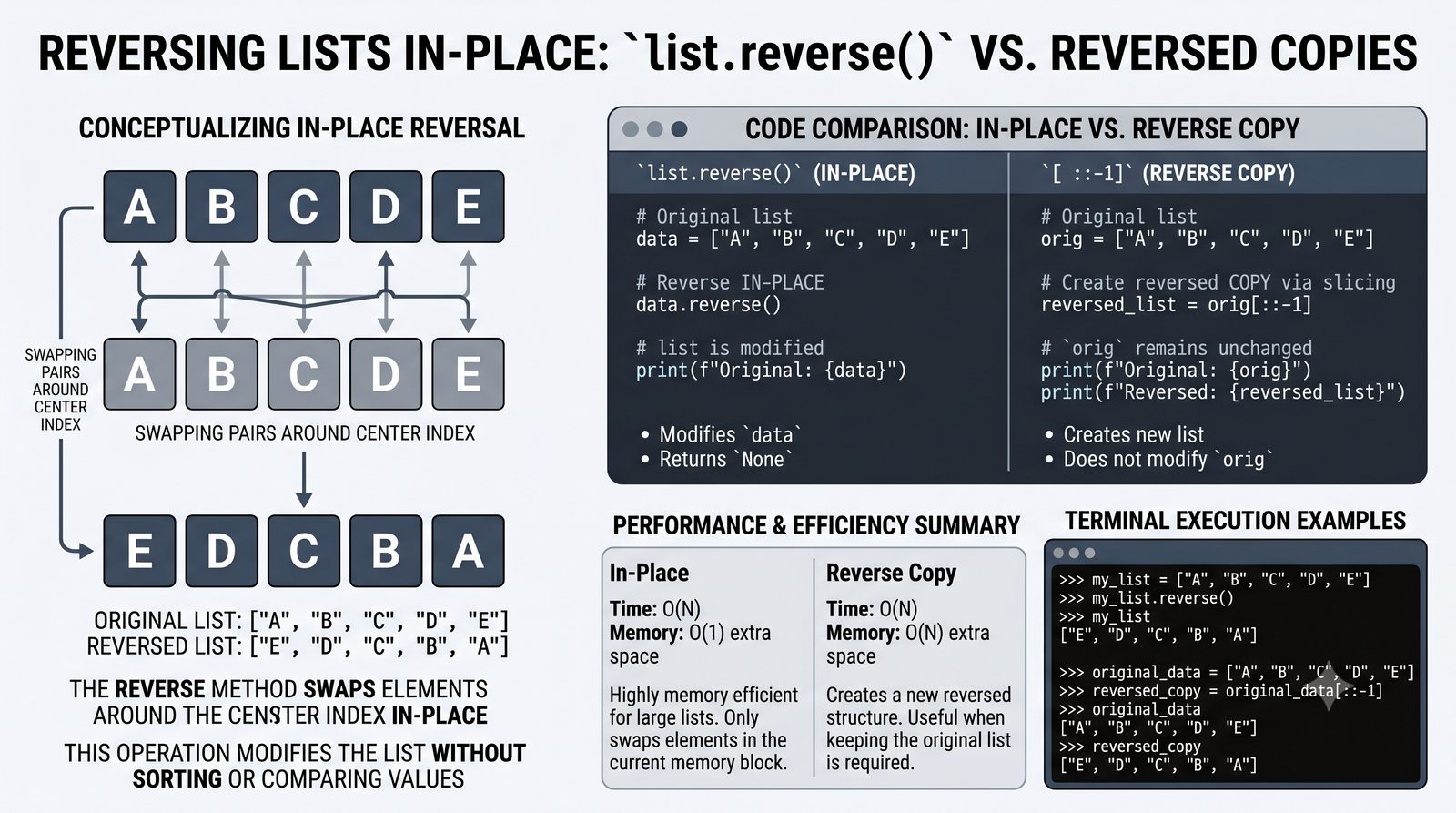
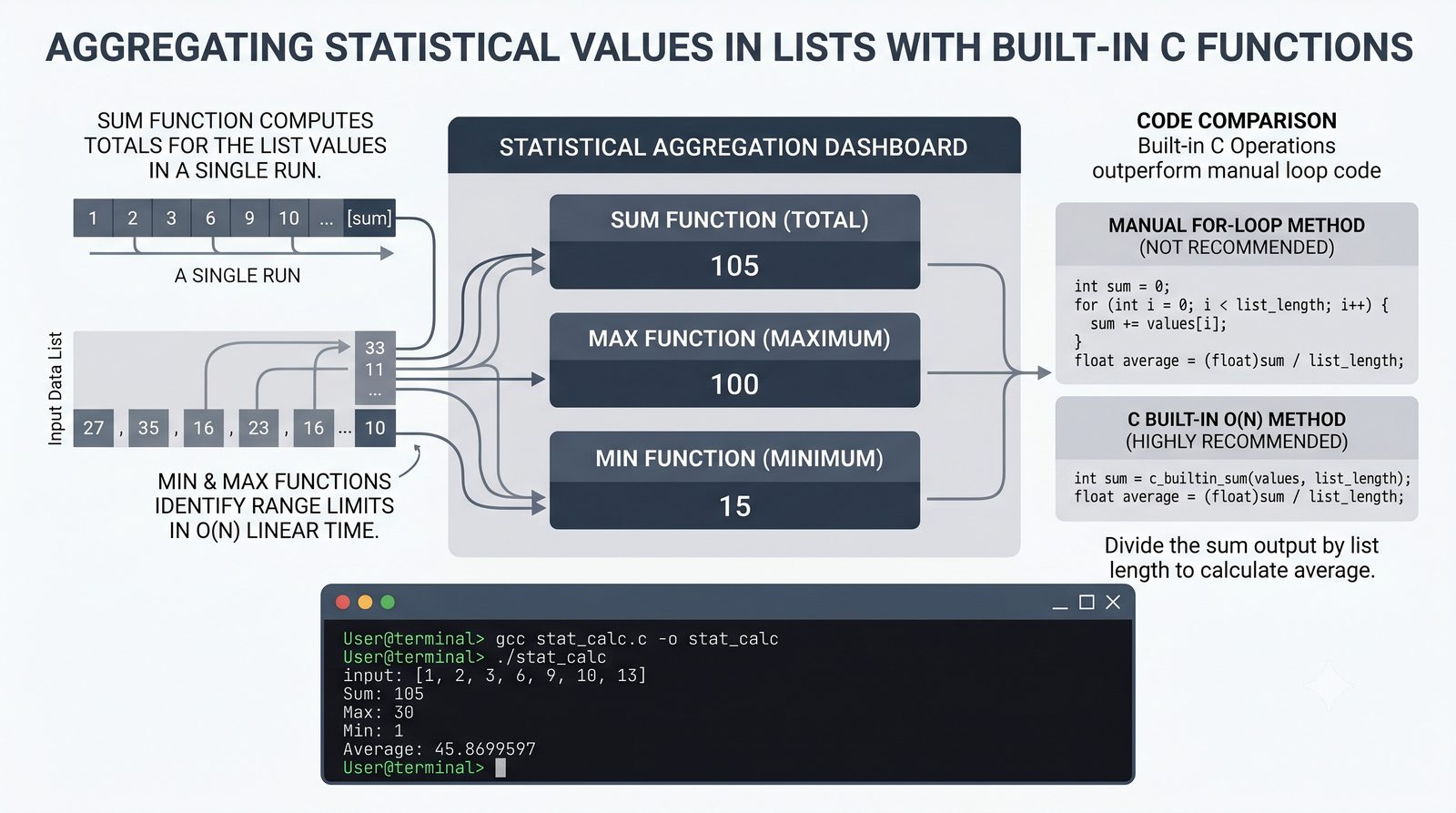
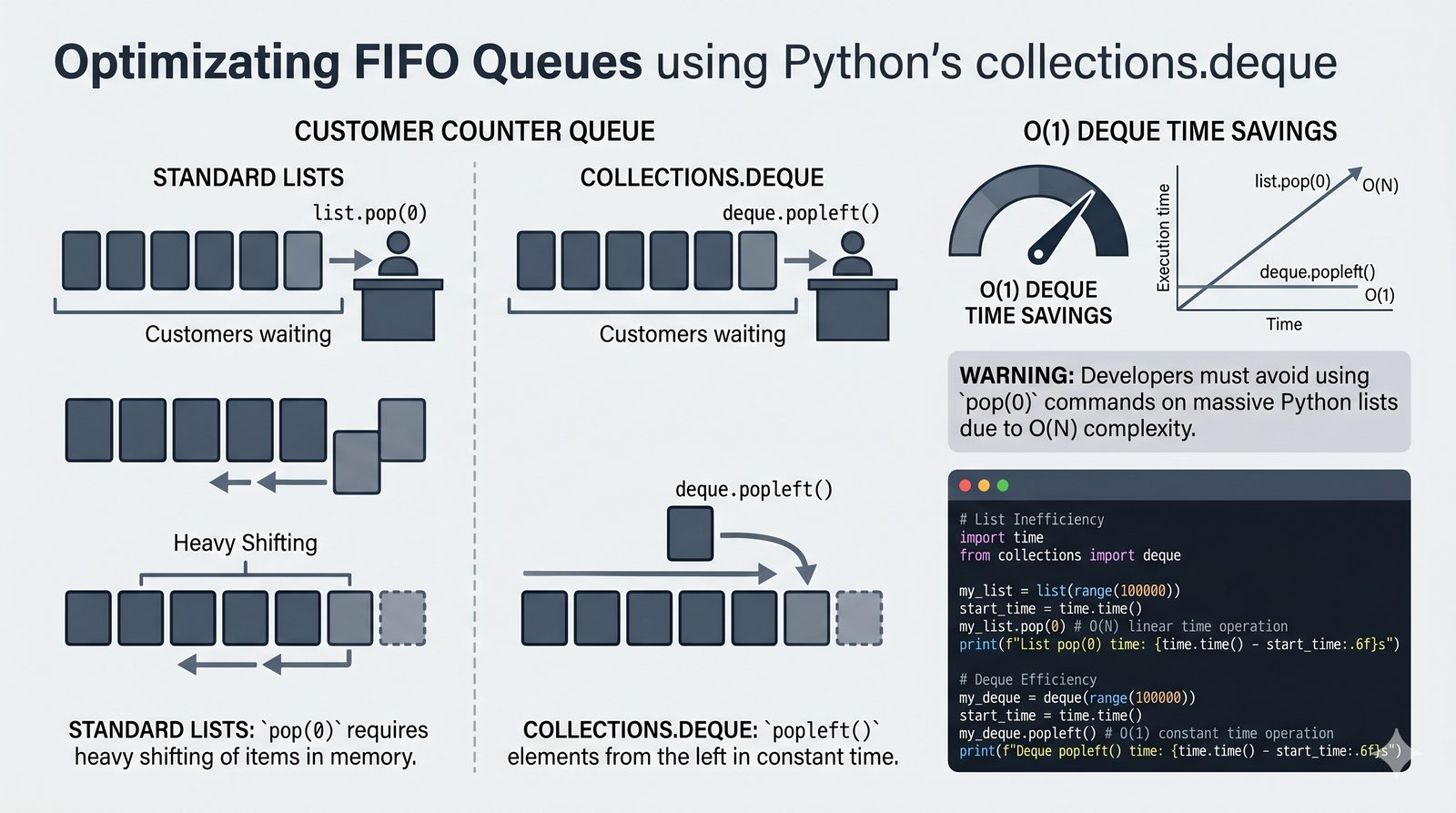
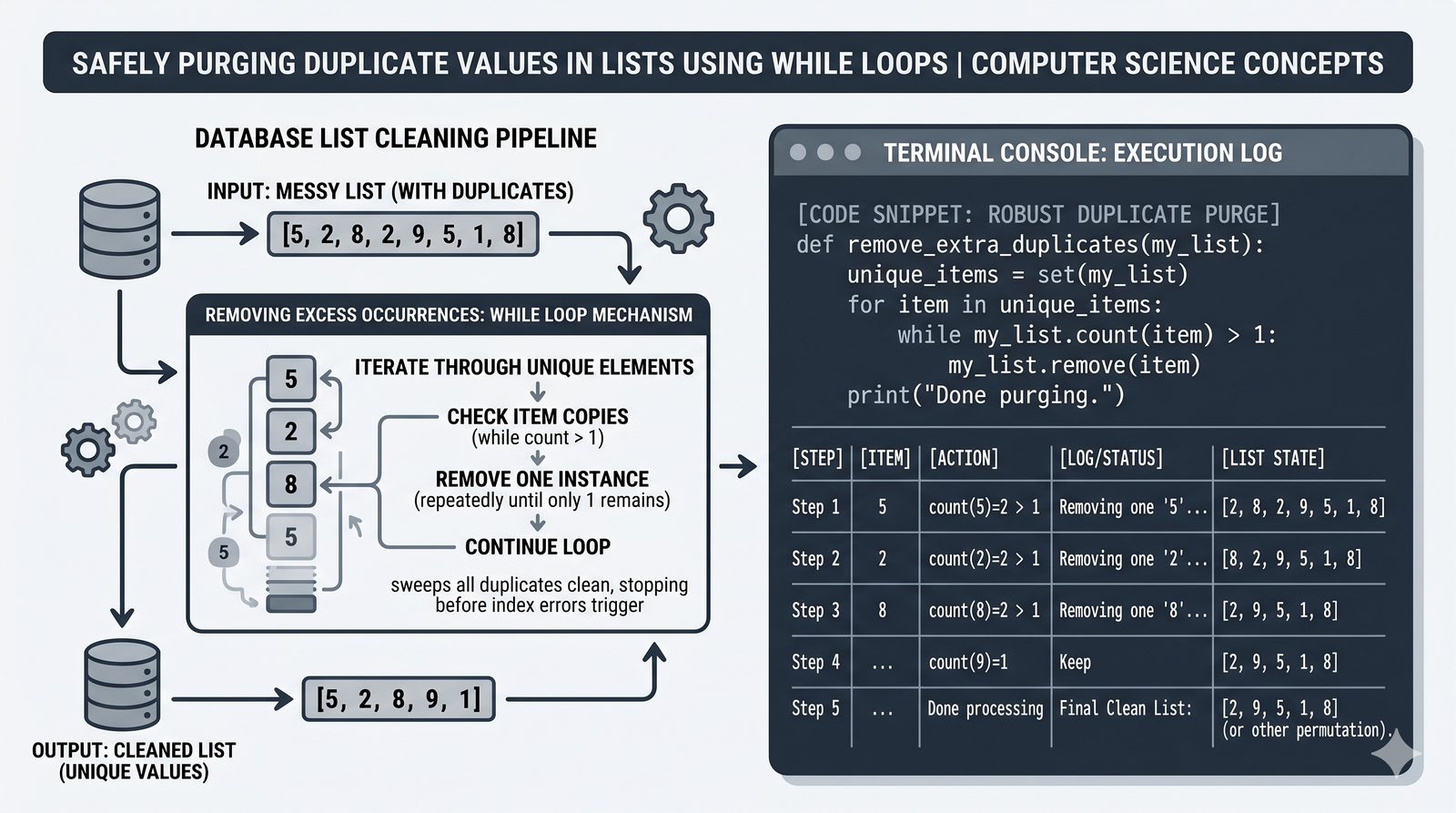
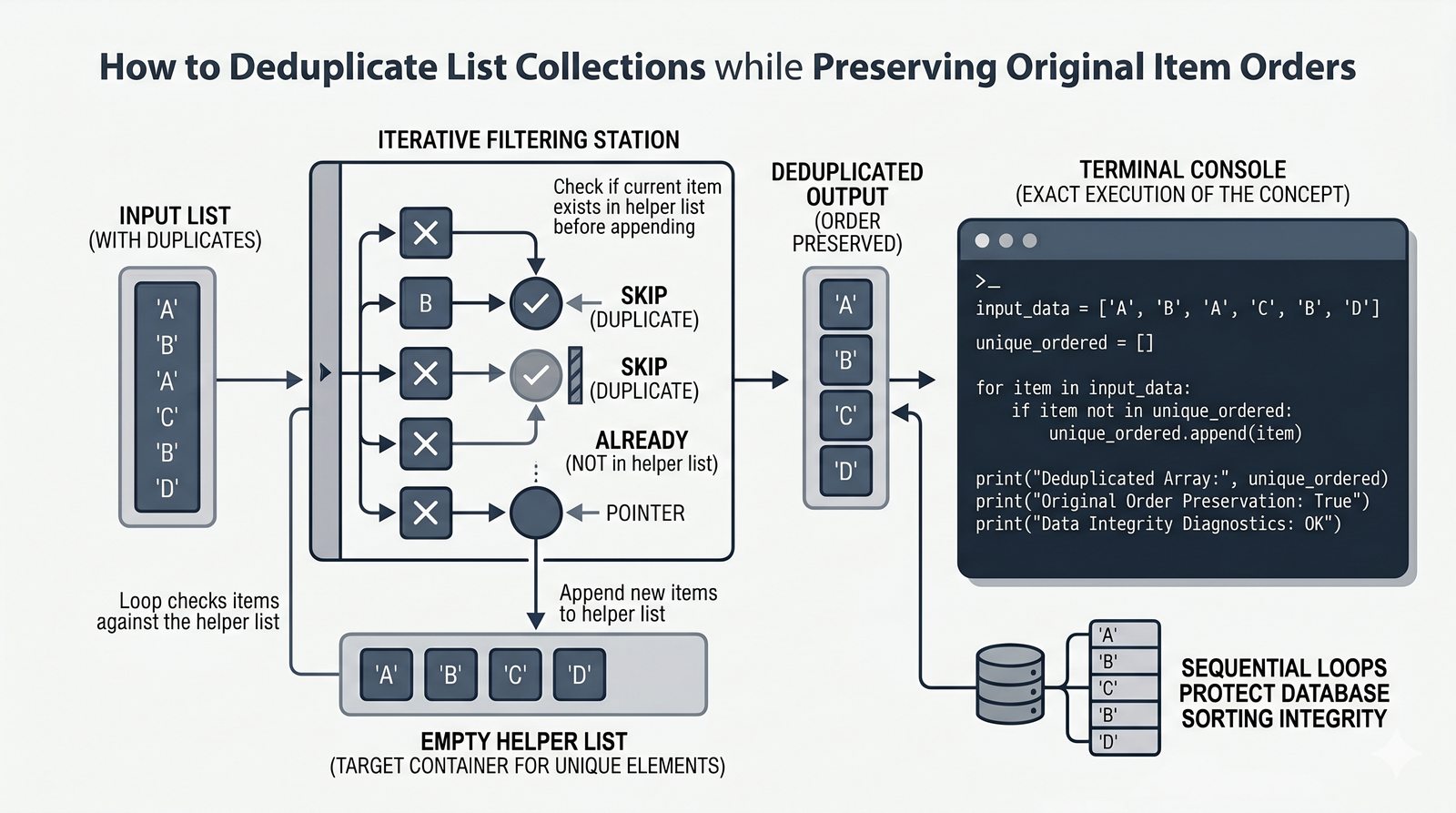
append,insert,extend), usuwanie (remove,pop,del,clear) oraz sortowanie i odwracanie (sort,sorted,reverse) - Kopiowanie list i aliasing — kopiowanie powierzchowne (
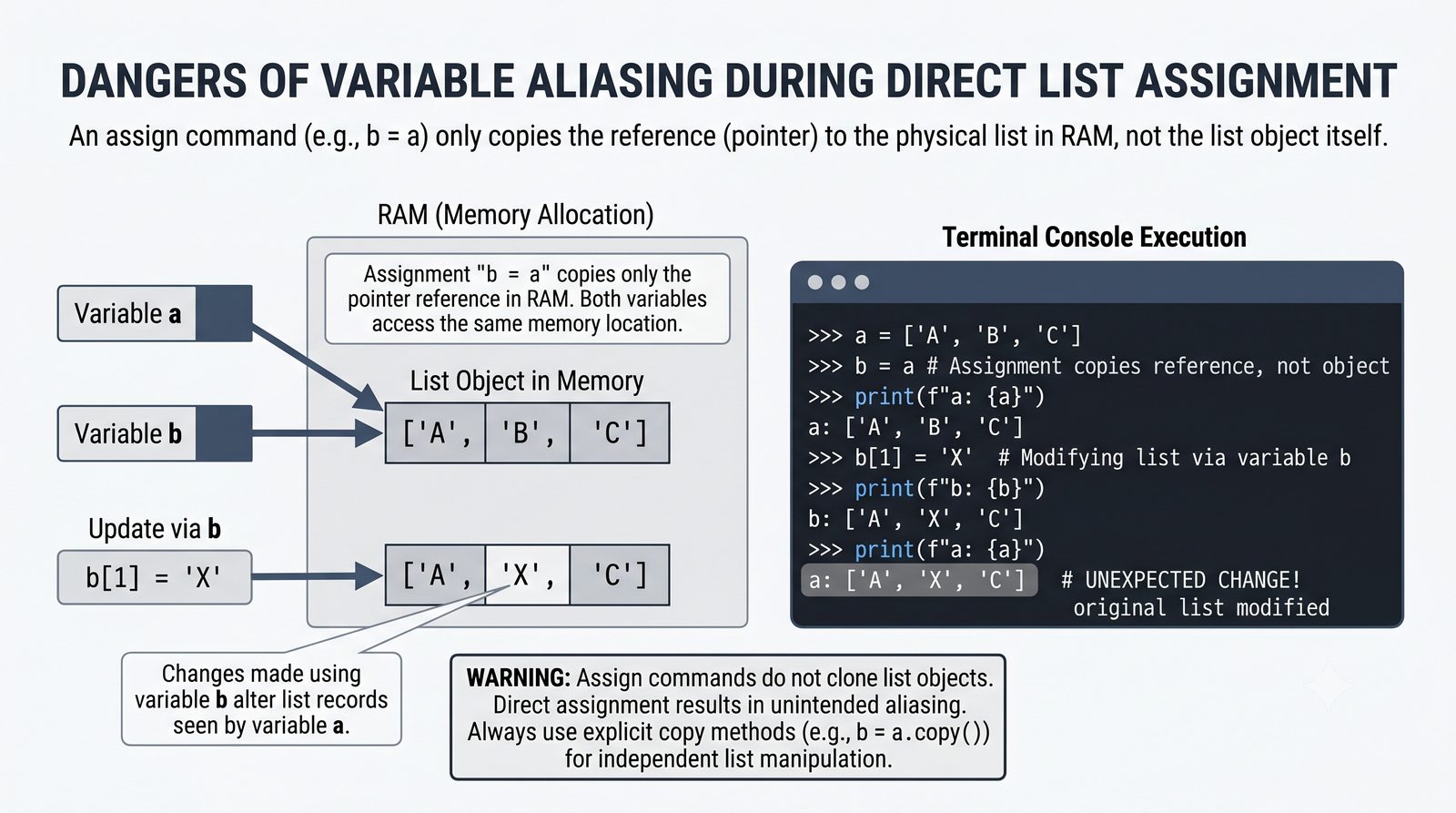
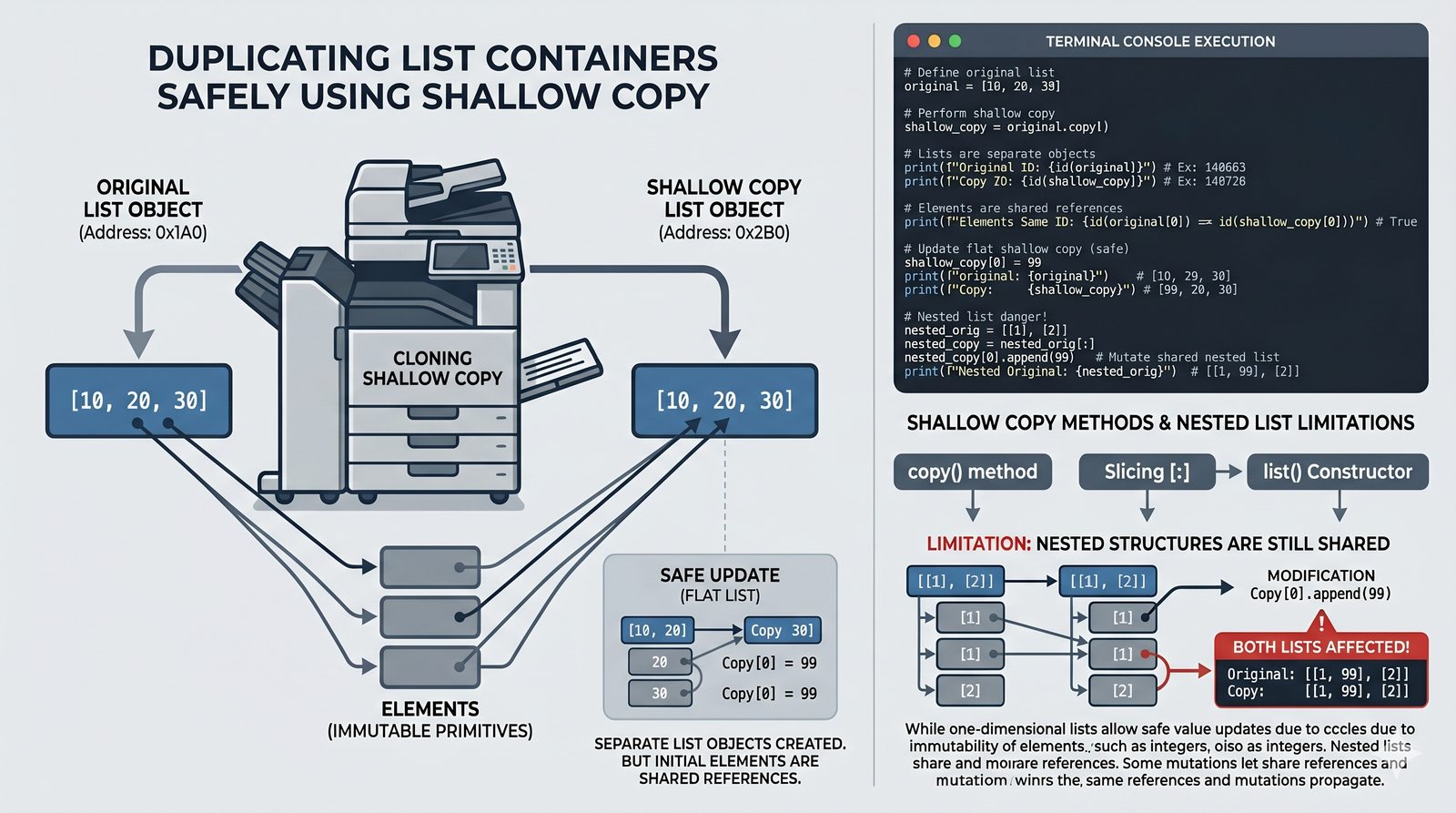
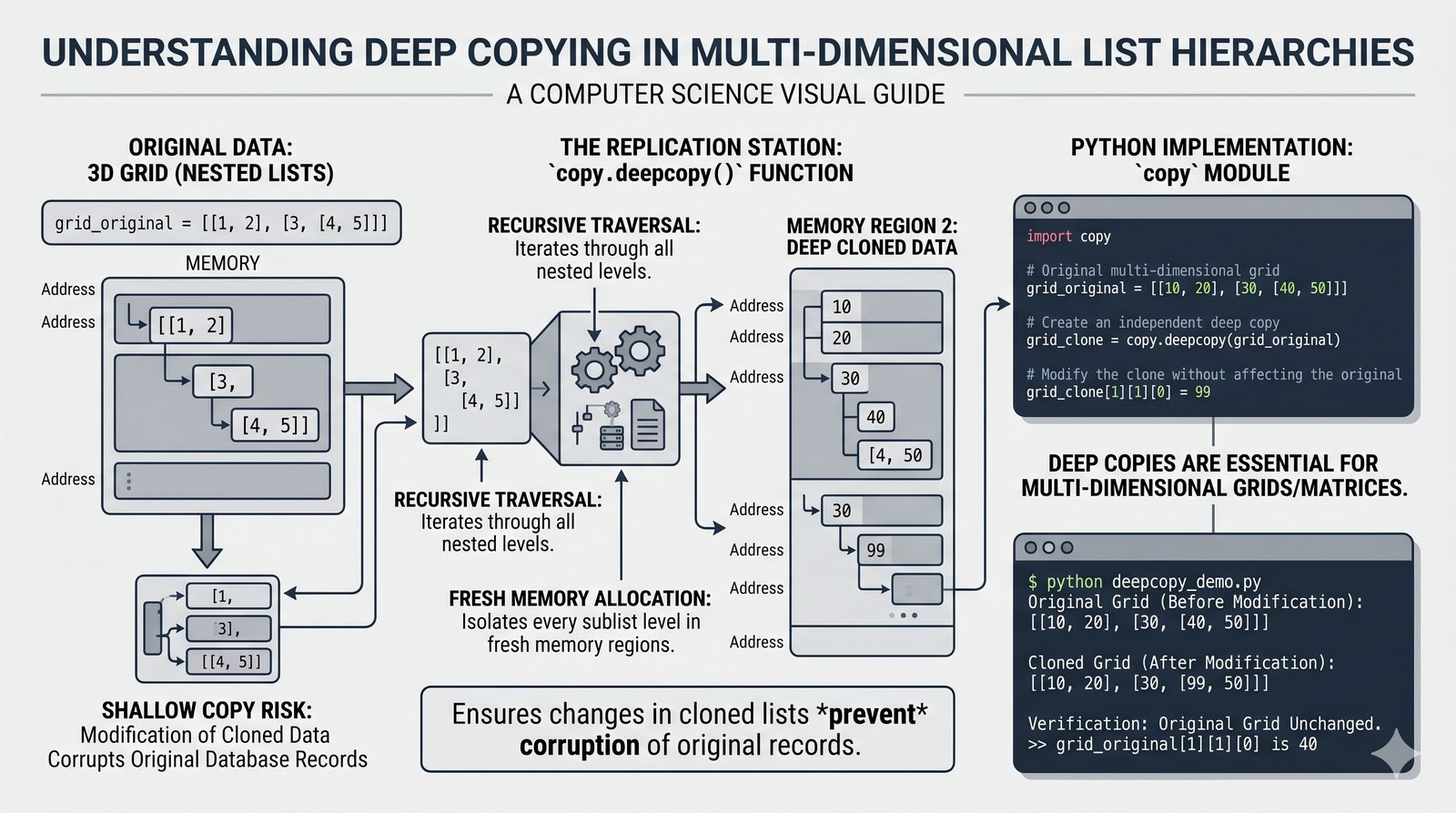
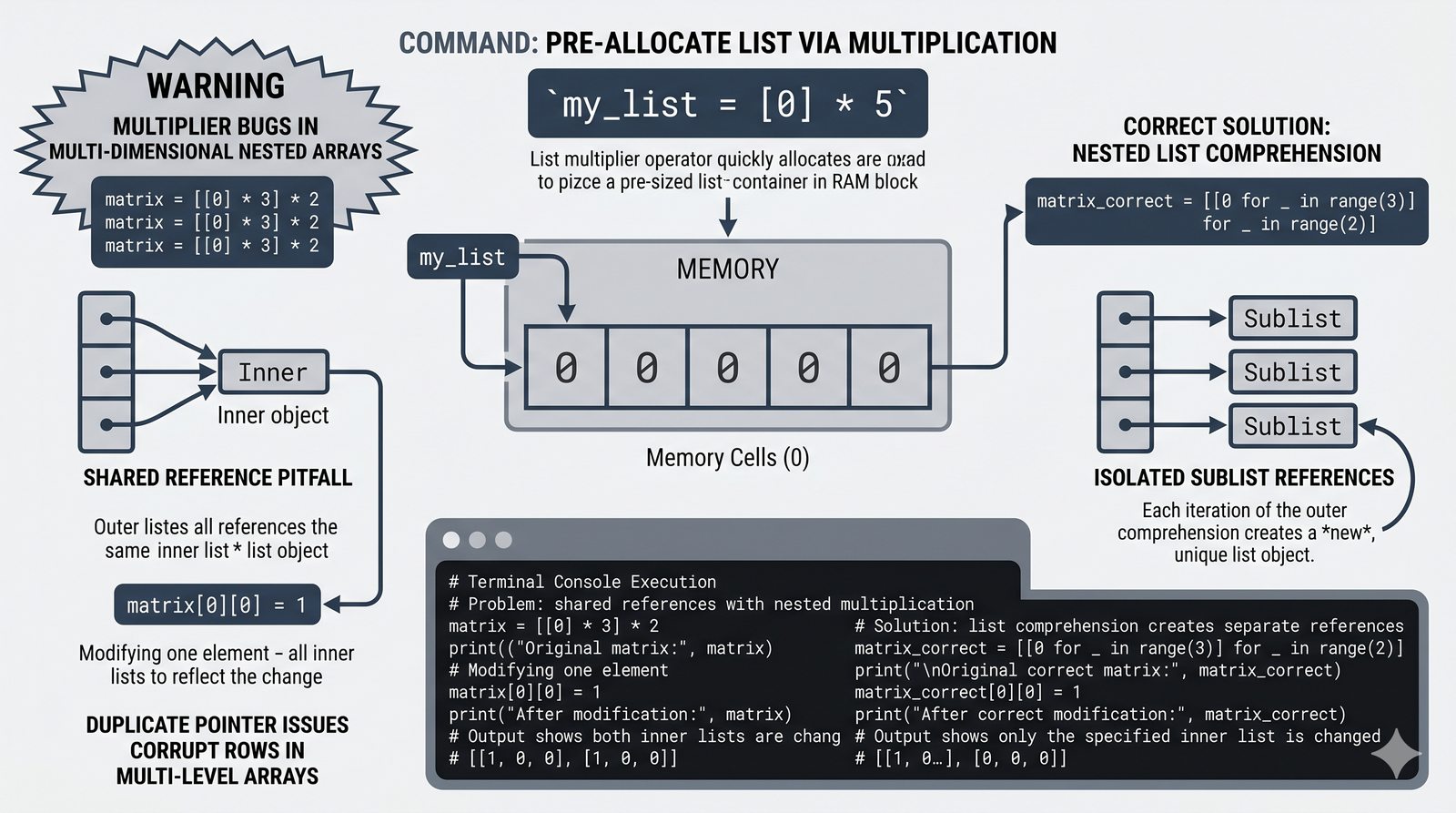
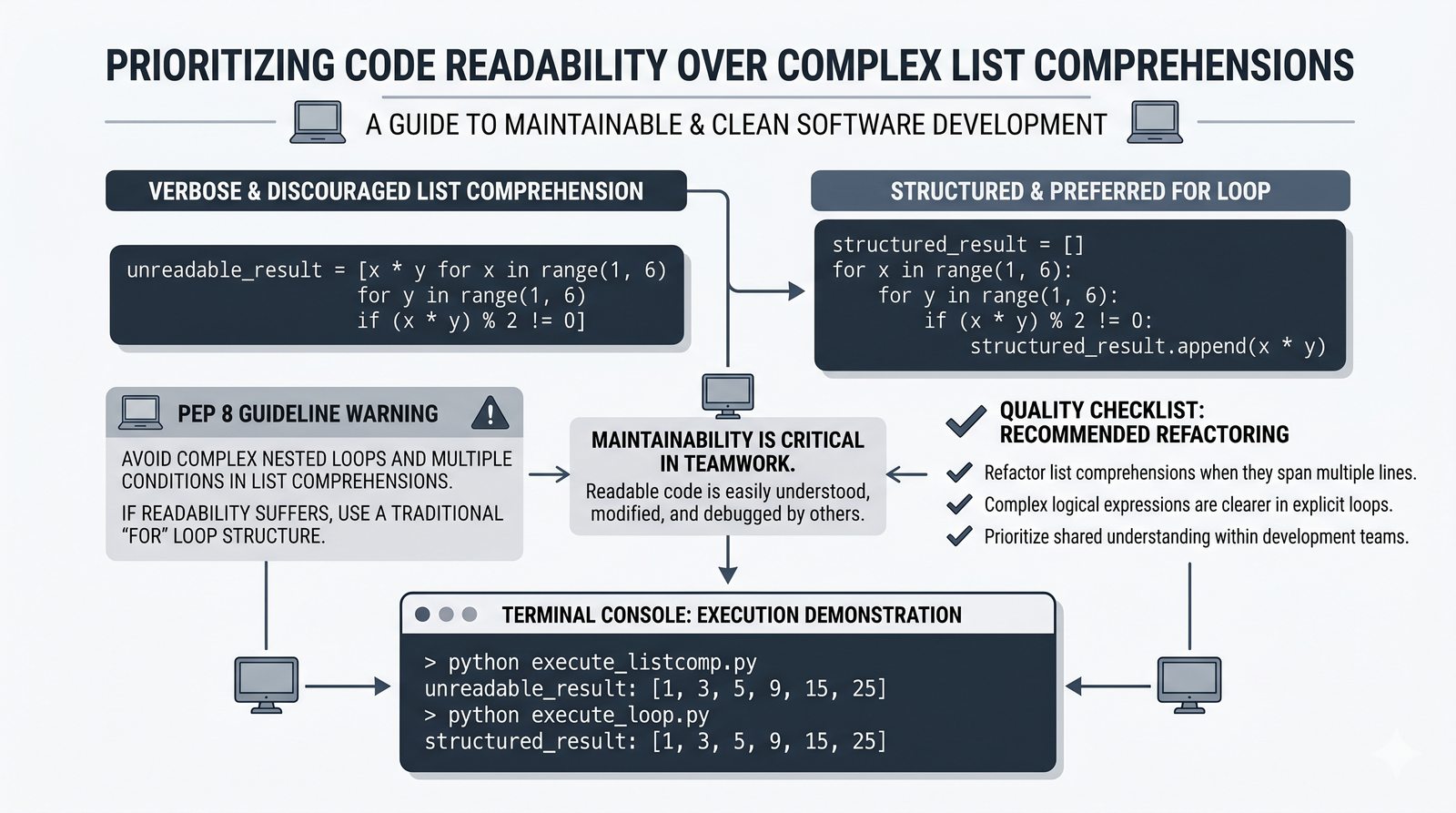
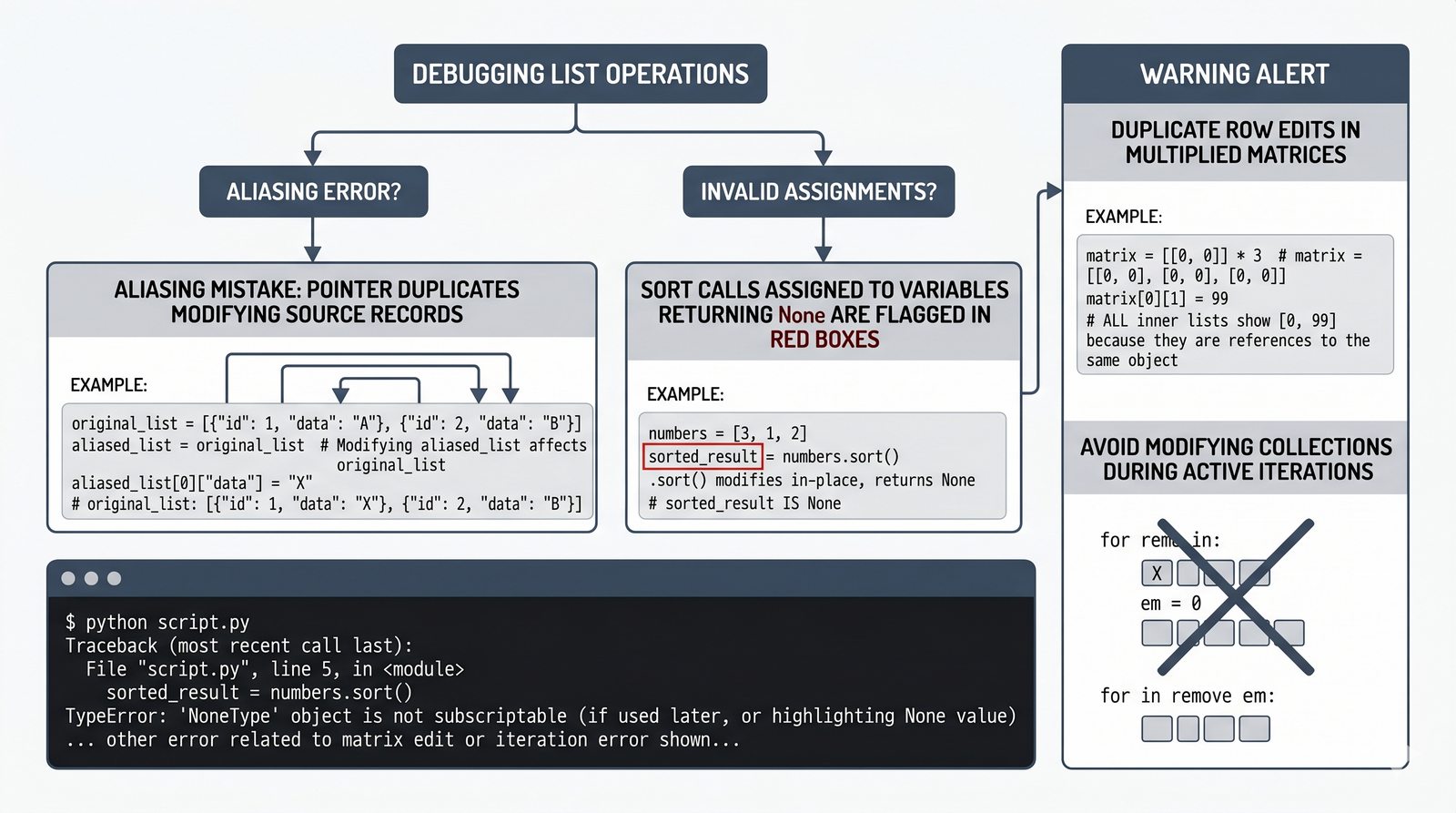
copy(),[:]) vs pełne (deepcopy()) oraz problem współdzielenia referencji w pamięci - Wyrażenia listowe (list comprehension) — składnia
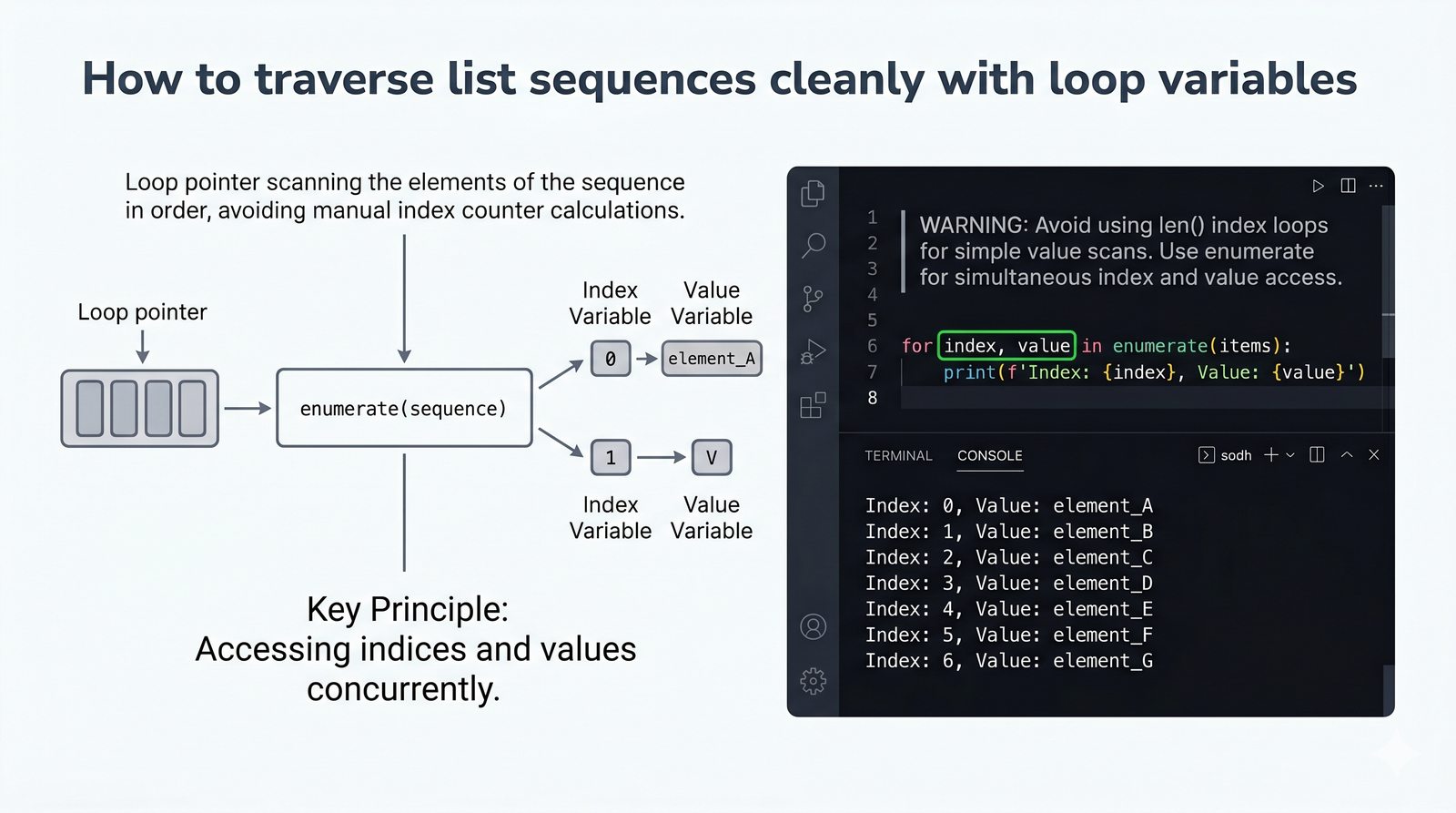
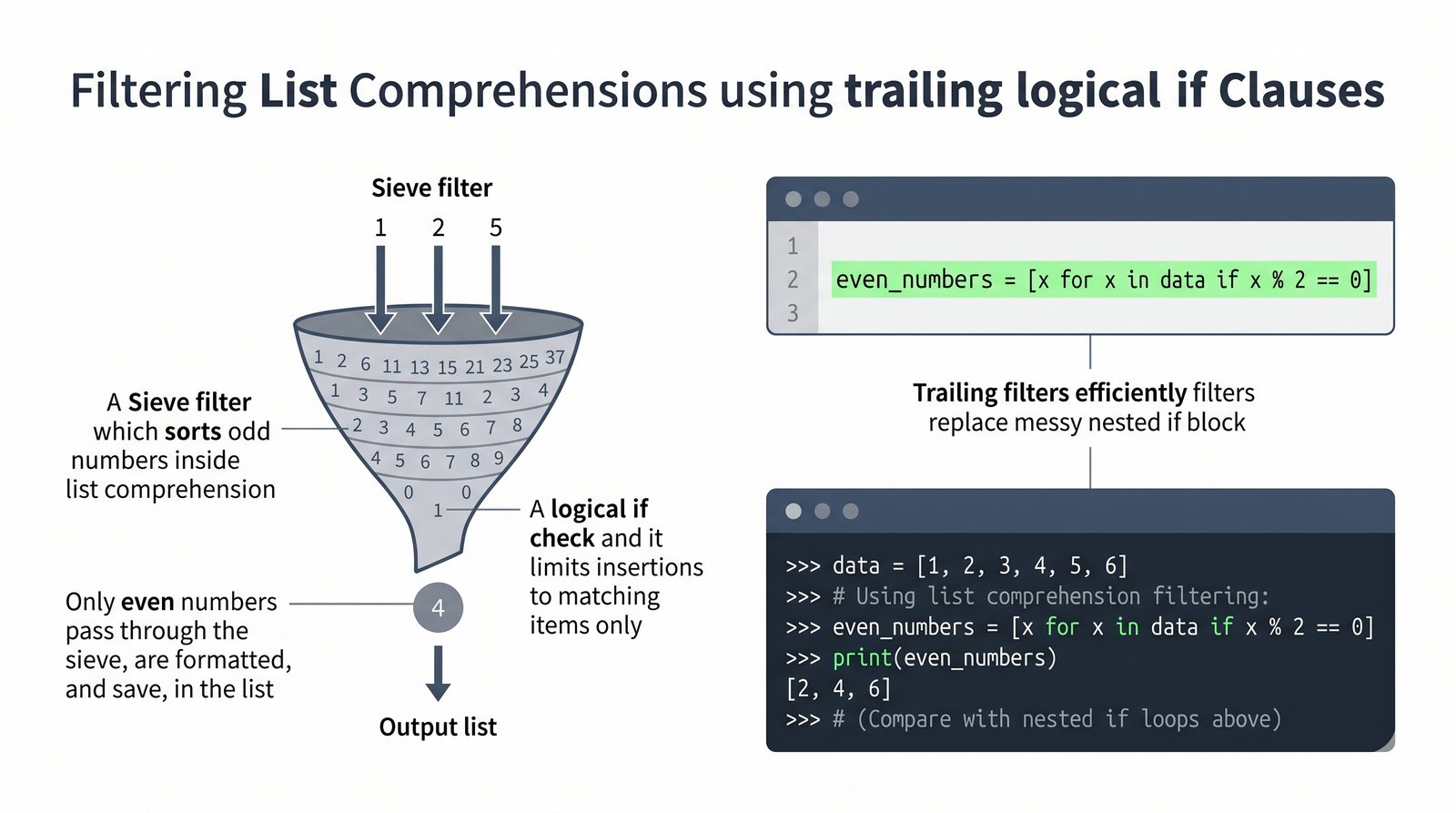
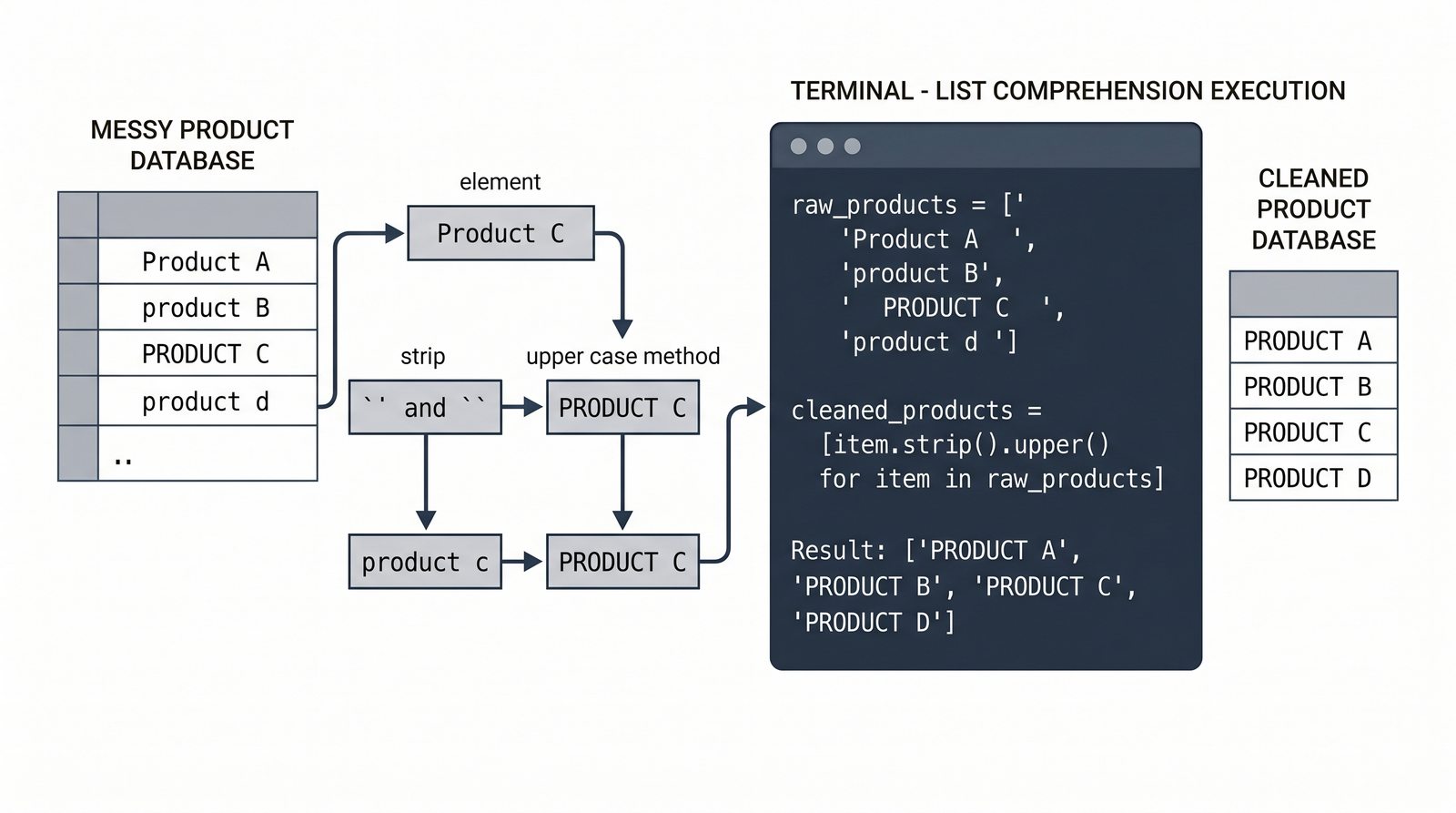
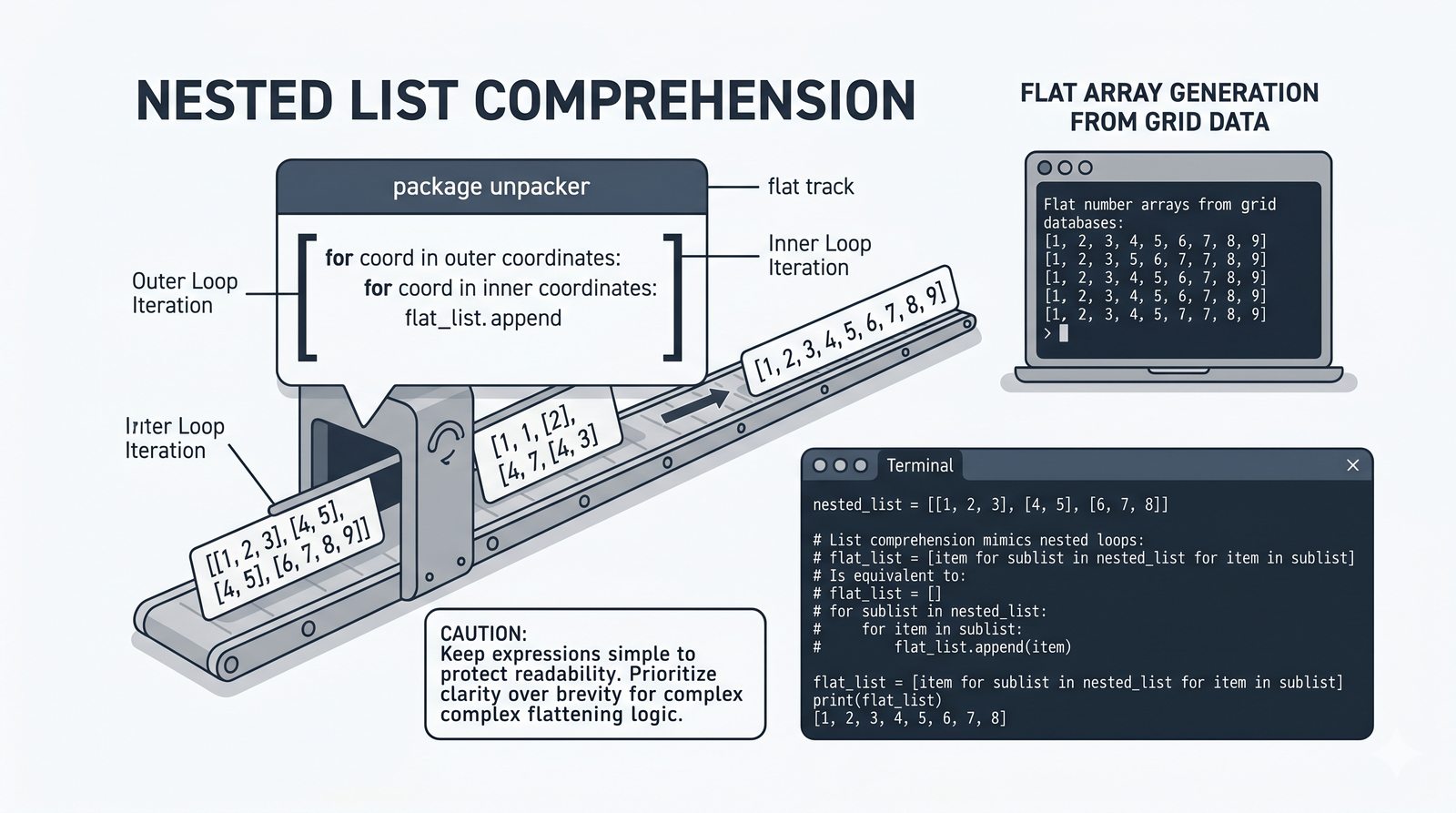
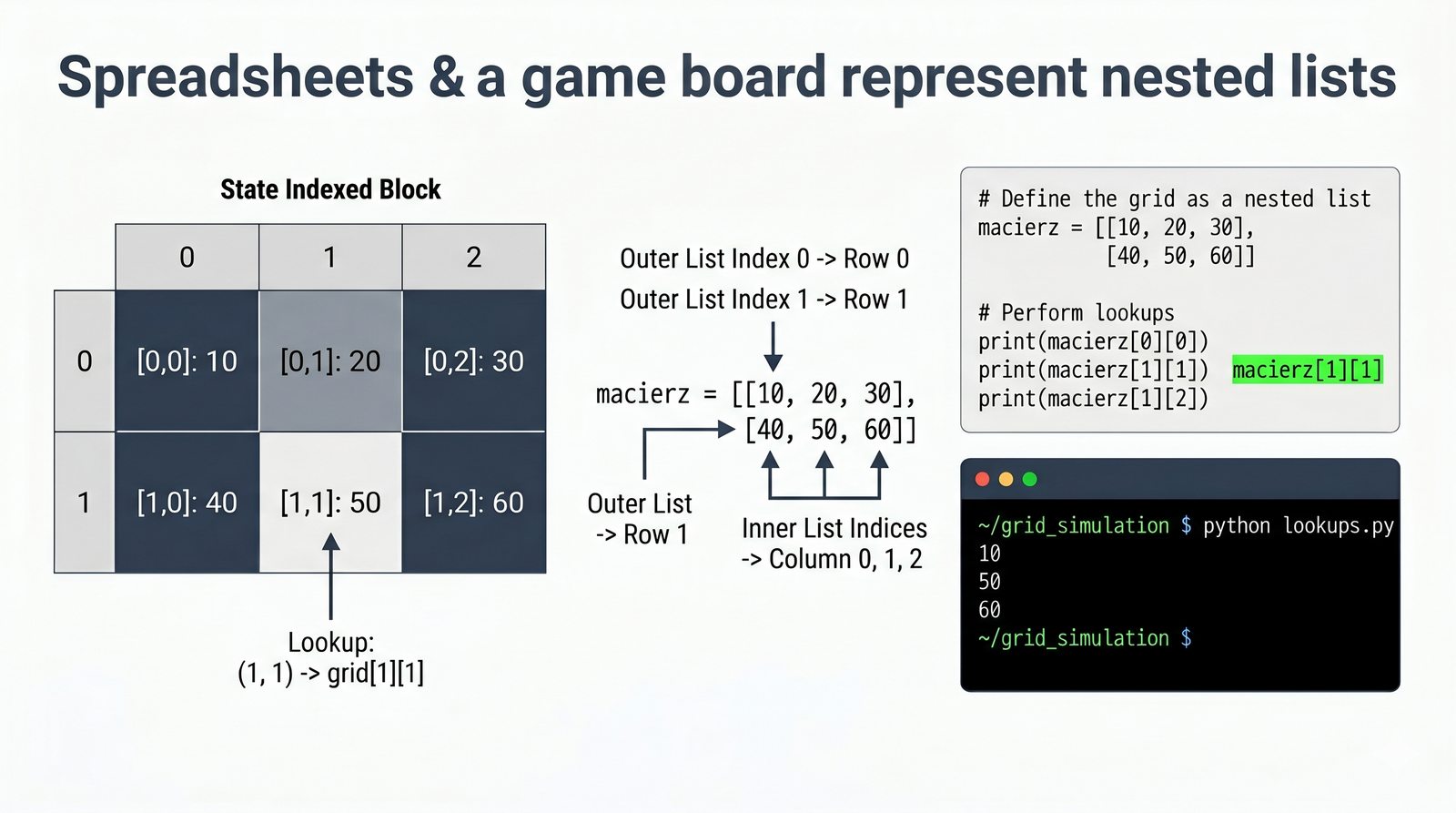
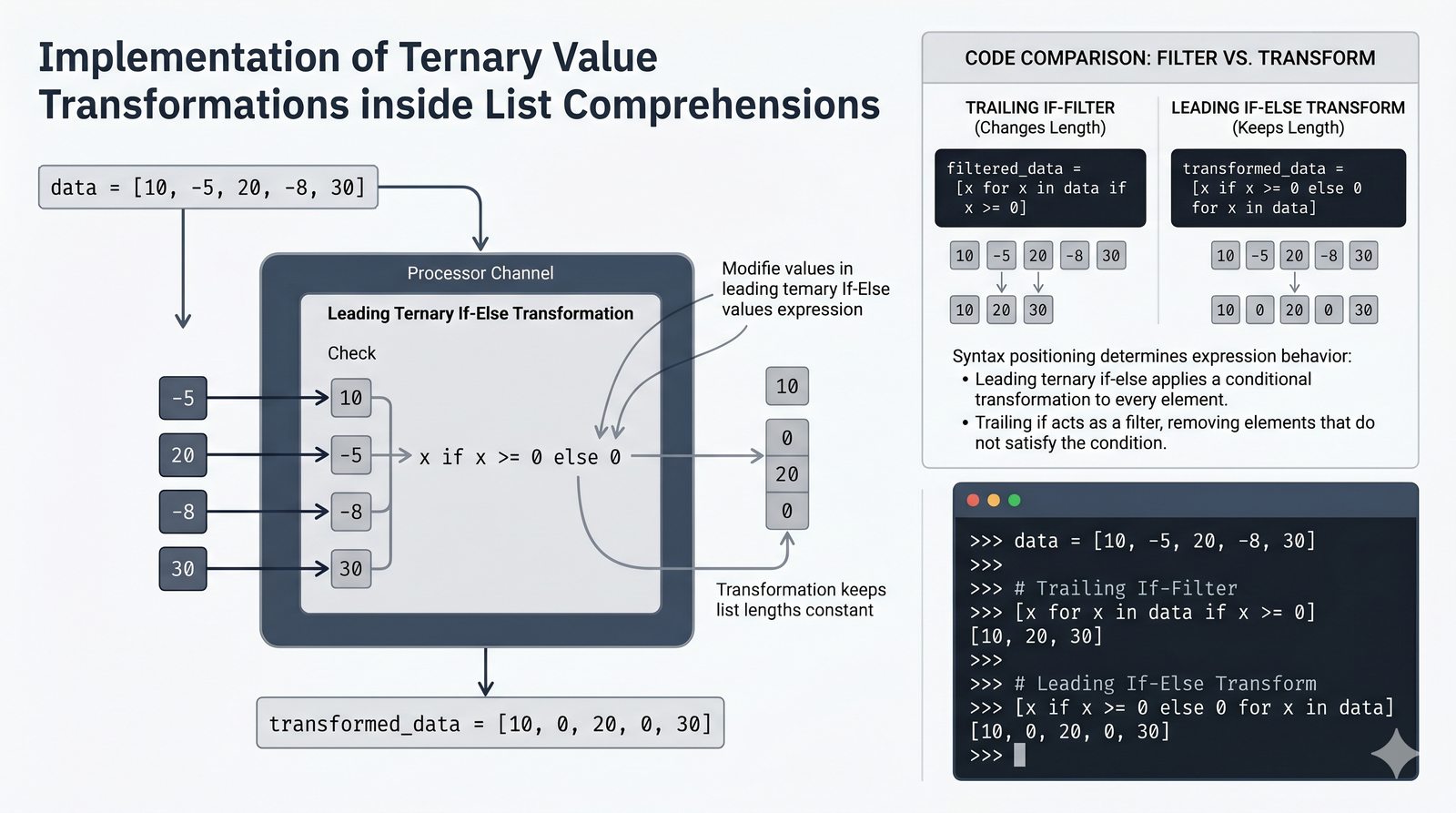
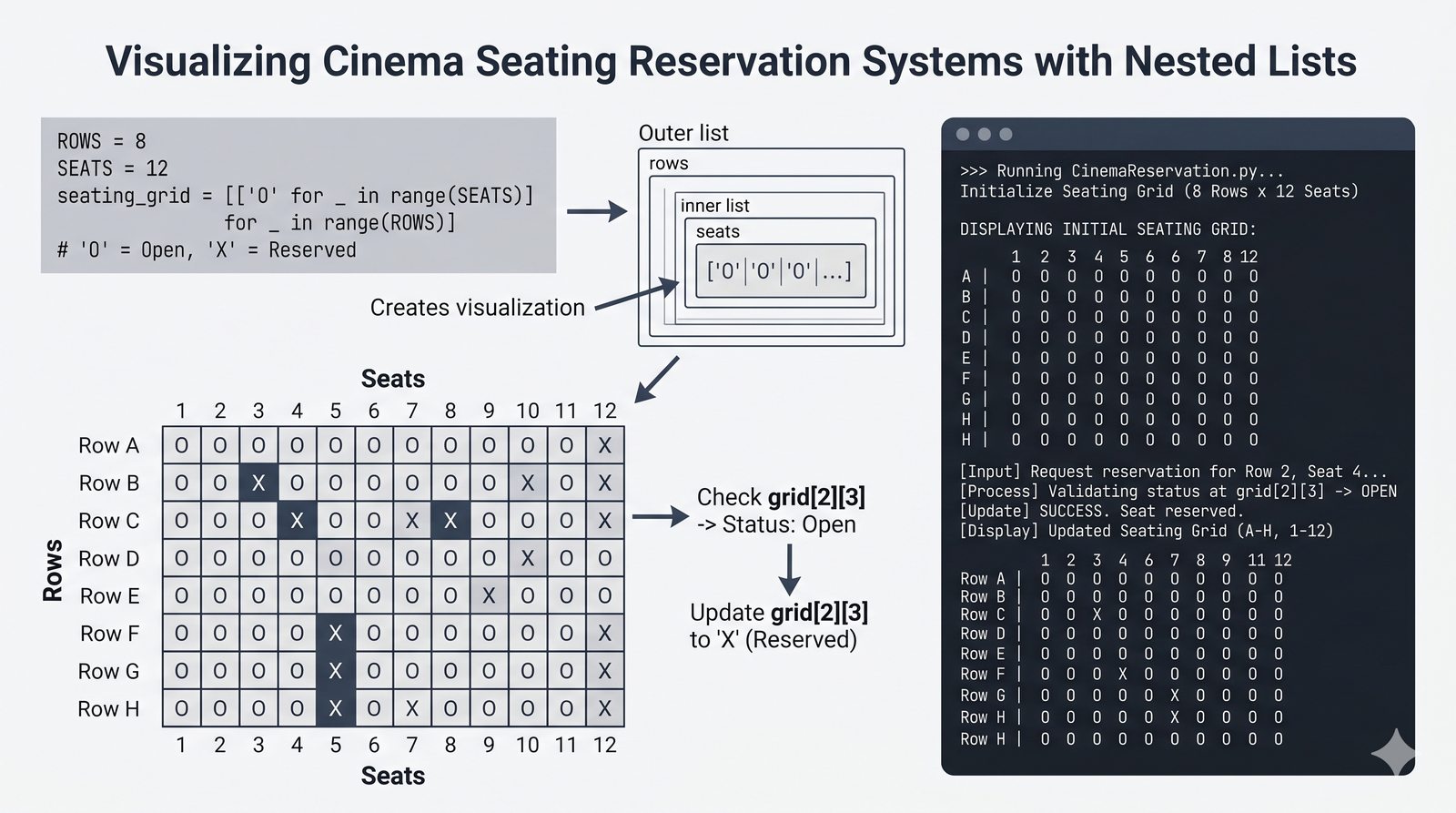
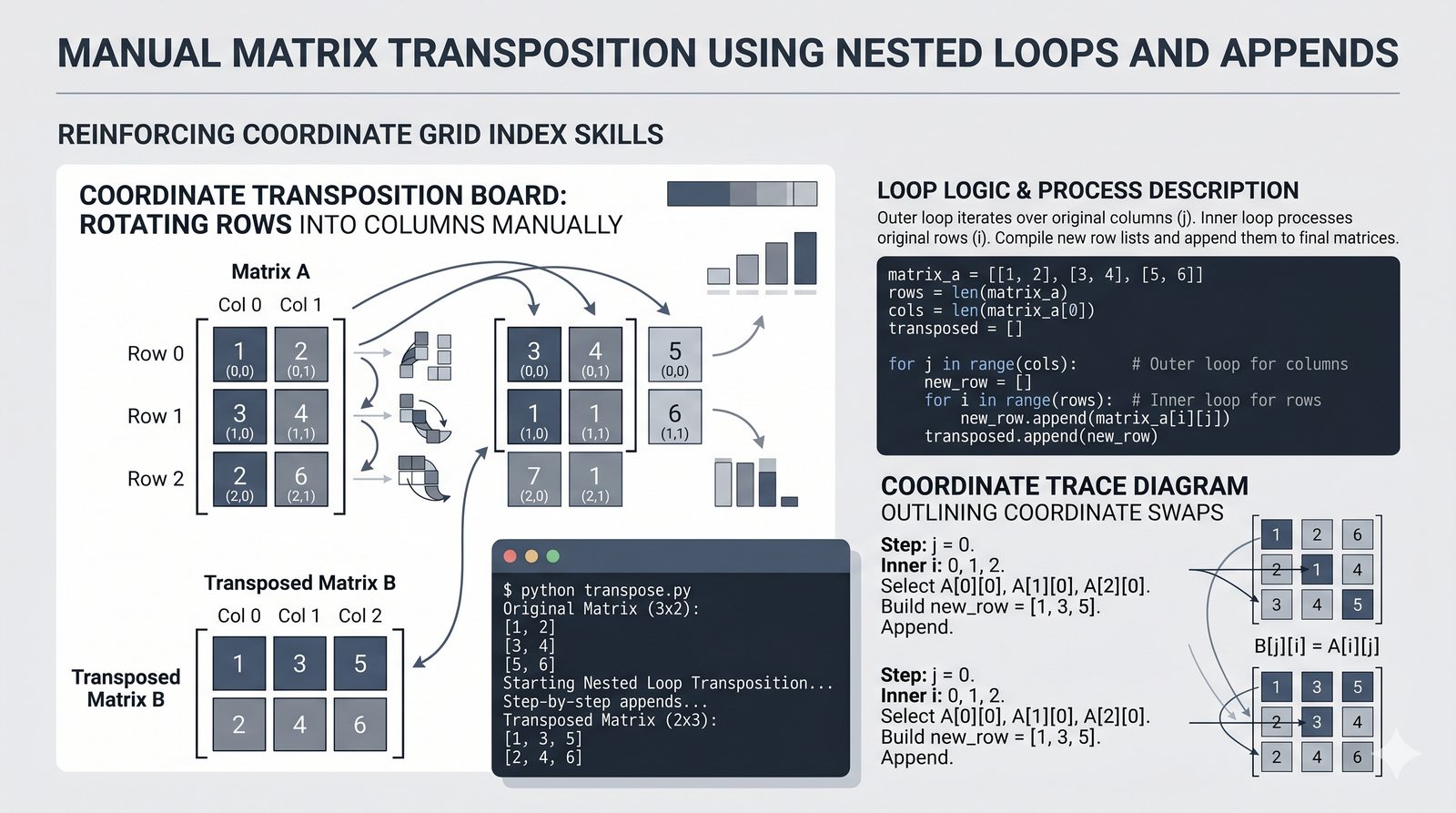
[wyrażenie for element in kolekcja if warunek]do szybkiej i czytelnej transformacji danych - Listy zagnieżdżone i macierze — tworzenie struktur wielowymiarowych, indeksowanie dwuwymiarowe oraz transpozycja macierzy