Ten moduł wprowadza kluczowe koncepcje związane z organizacją kodu w Pythonie – od definicji modułu jako pliku .py, przez różne formy importowania (import, from...import, aliasowanie), aż po zaawansowane mechanizmy, takie jak pakiety, plik __init__.py i zmienna __name__. Omówione zostały najważniejsze moduły biblioteki standardowej (math, random, datetime, os, sys, string) oraz praktyczne zasady ich wykorzystania w codziennej pracy programisty. Szczegółowo przeanalizowano mechanizm wyszukiwania modułów przez interpreter (sys.path, PYTHONPATH) oraz proces tworzenia własnych modułów i pakietów. Moduł wprowadza również w tematykę zarządzania zależnościami zewnętrznymi – menedżer pip, repozytorium PyPI, plik requirements.txt oraz izolację środowisk za pomocą venv. Całość uzupełniają praktyczne przykłady kodu oraz wyjaśnienie dobrych praktyk, takich jak unikanie importu gwiazdkowego i stosowanie aliasów branżowych.
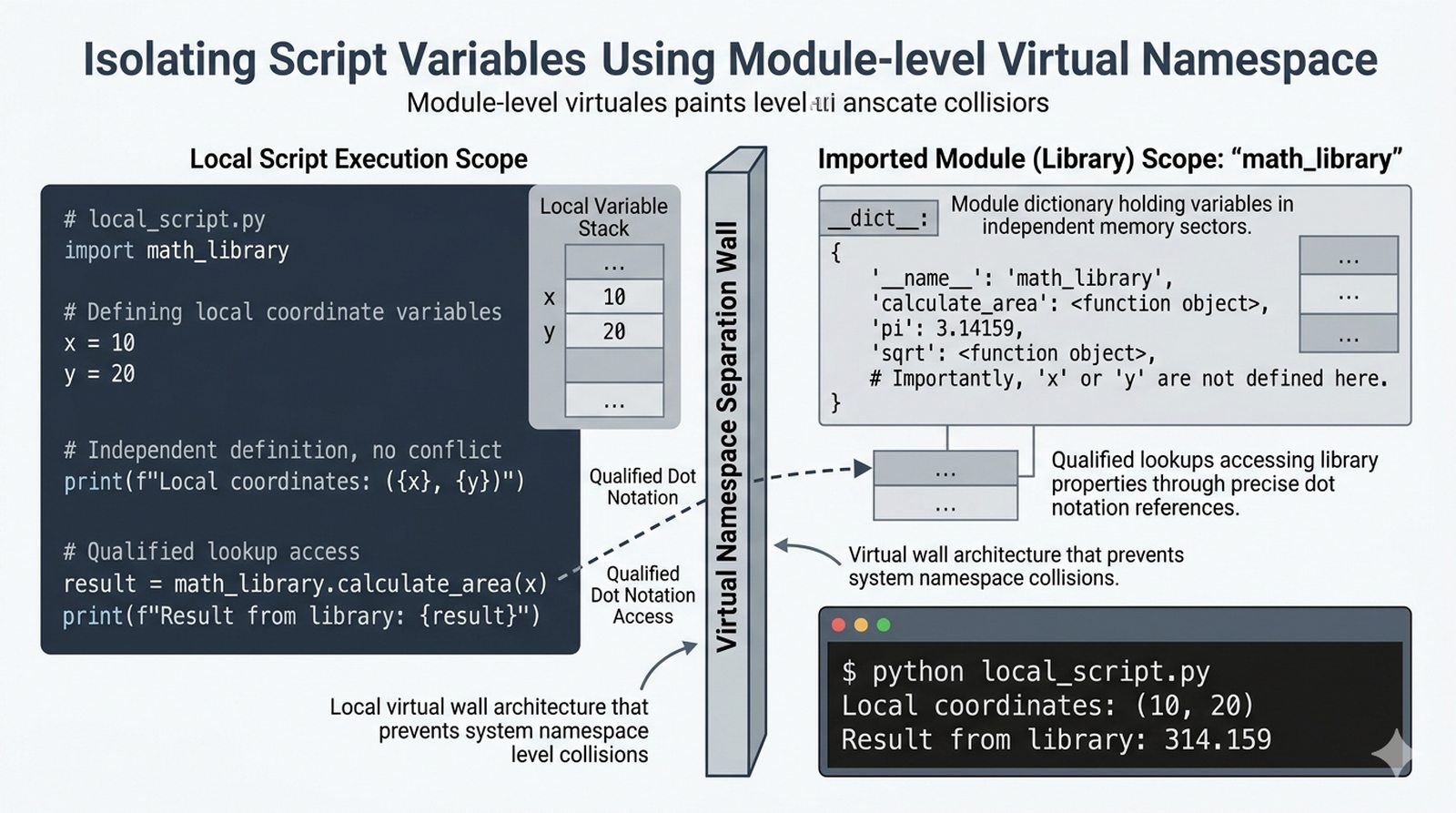
- Moduły i importowanie – definicja modułu, składnia
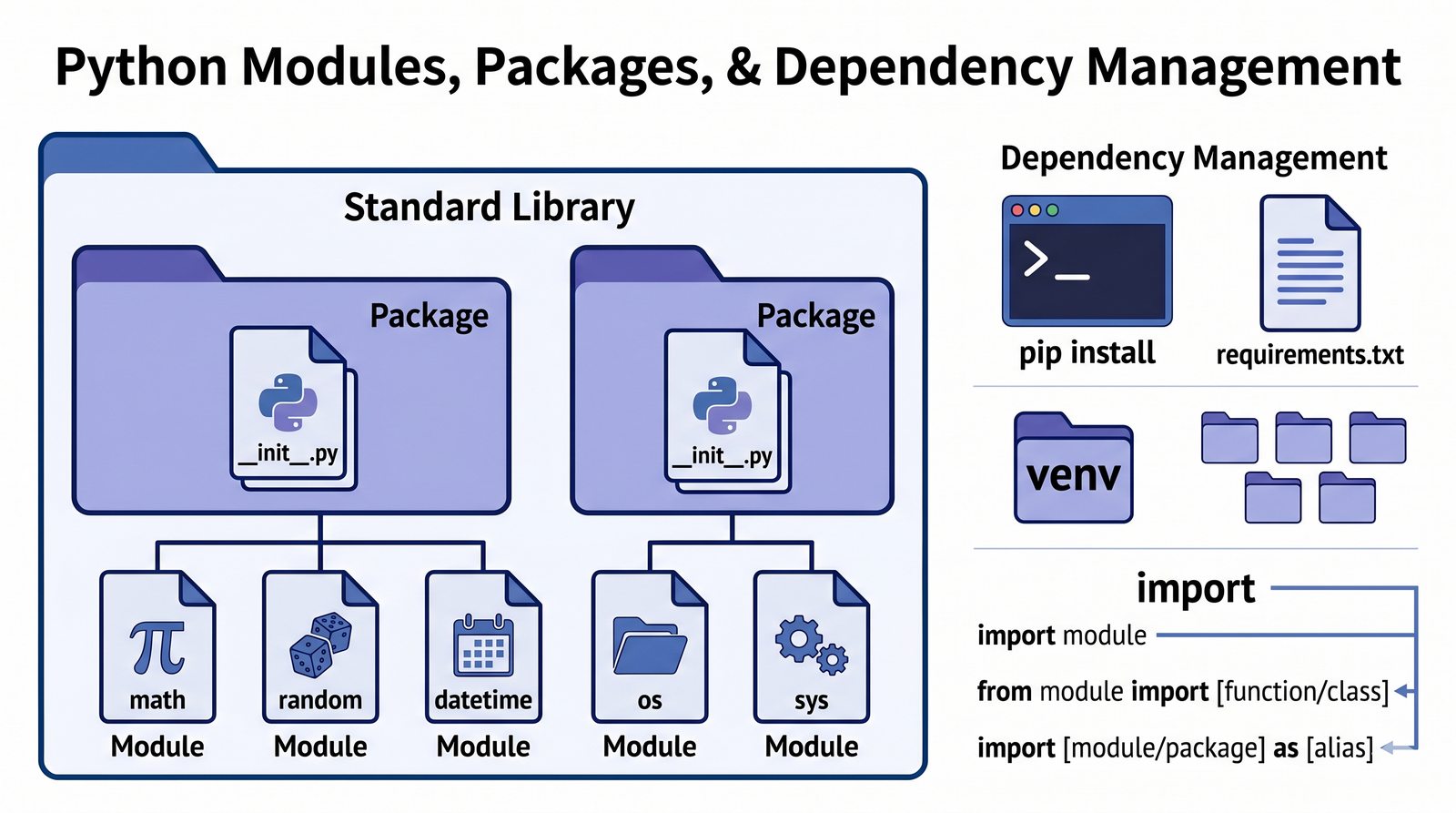
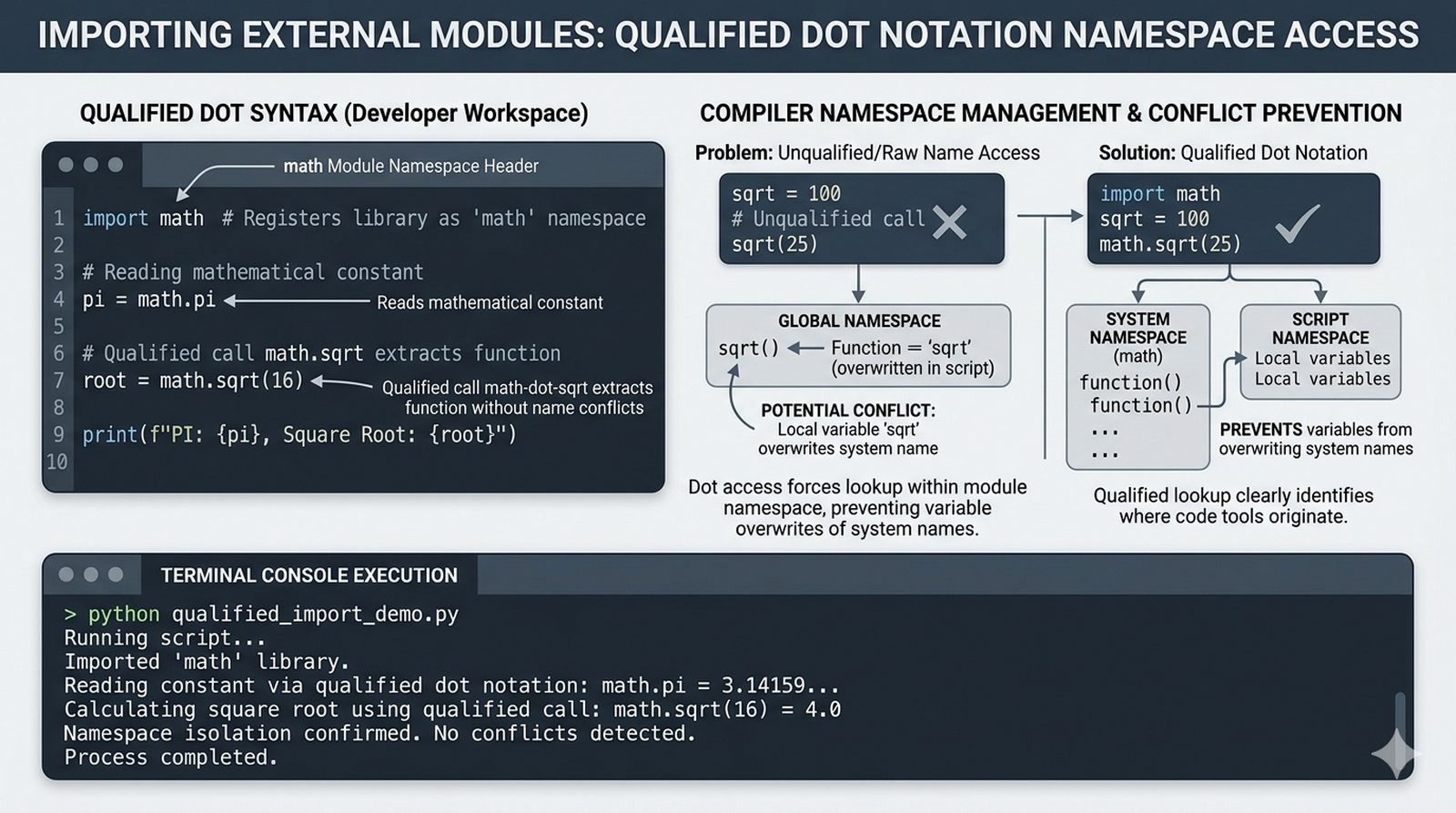
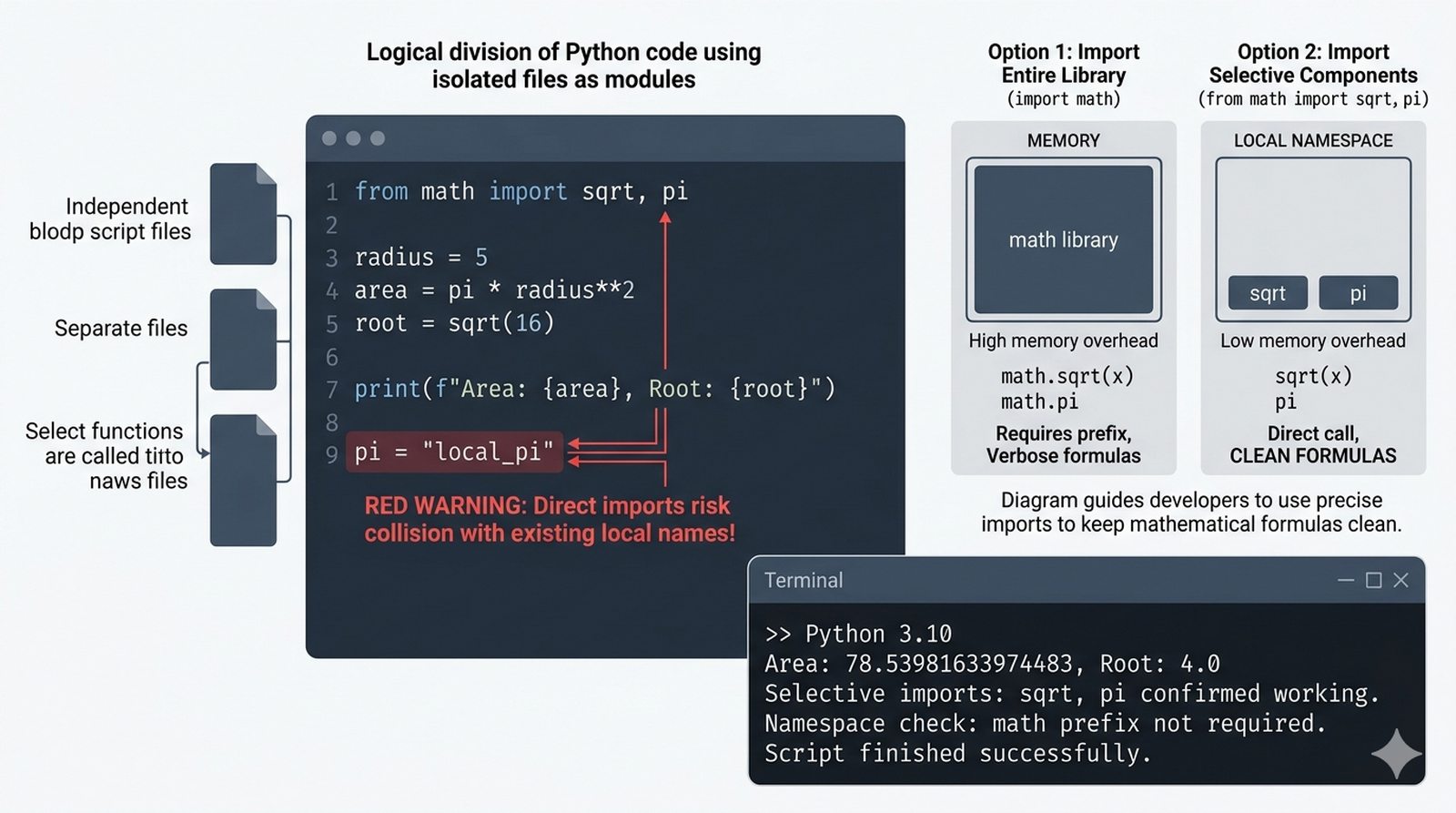
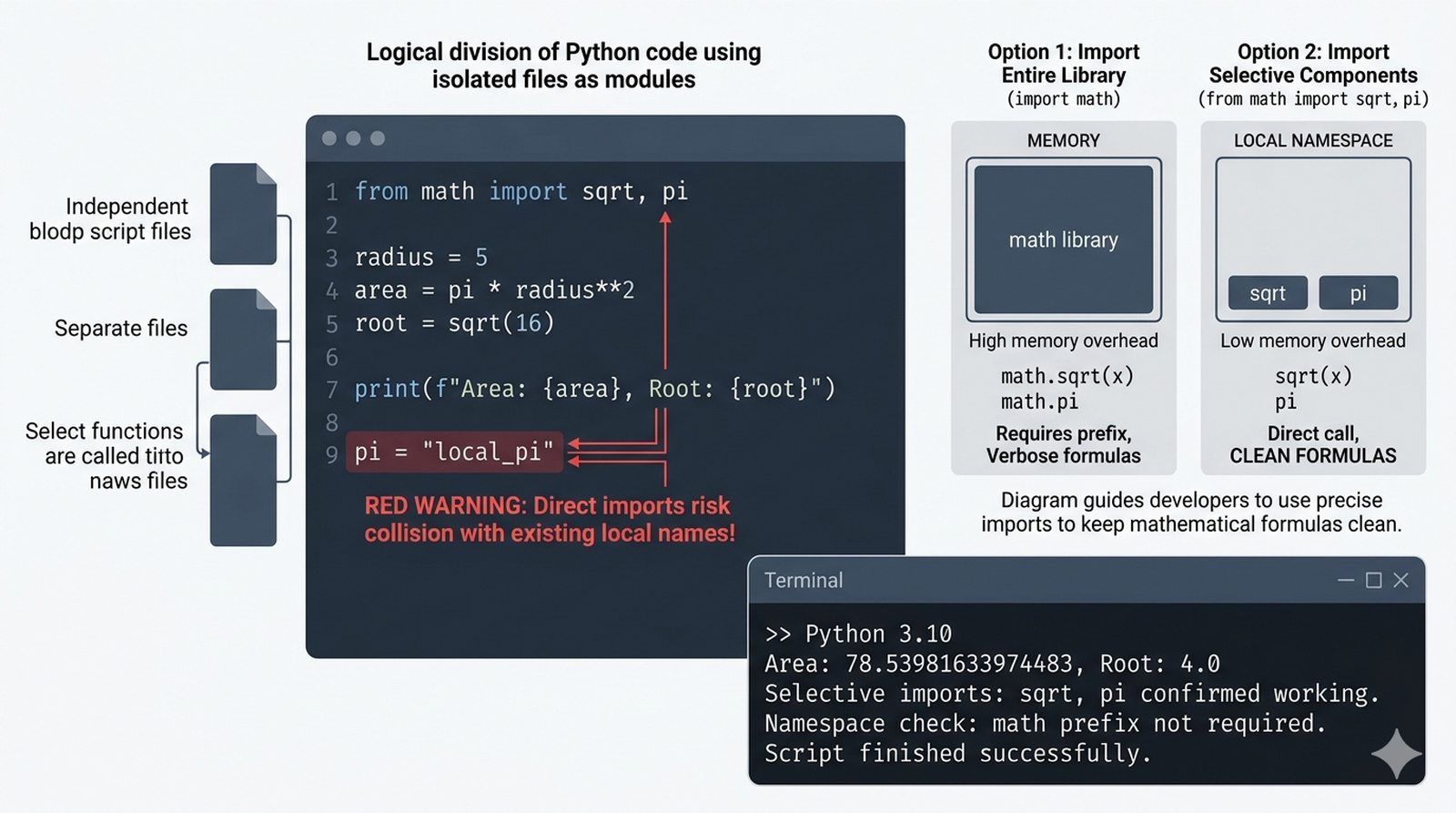
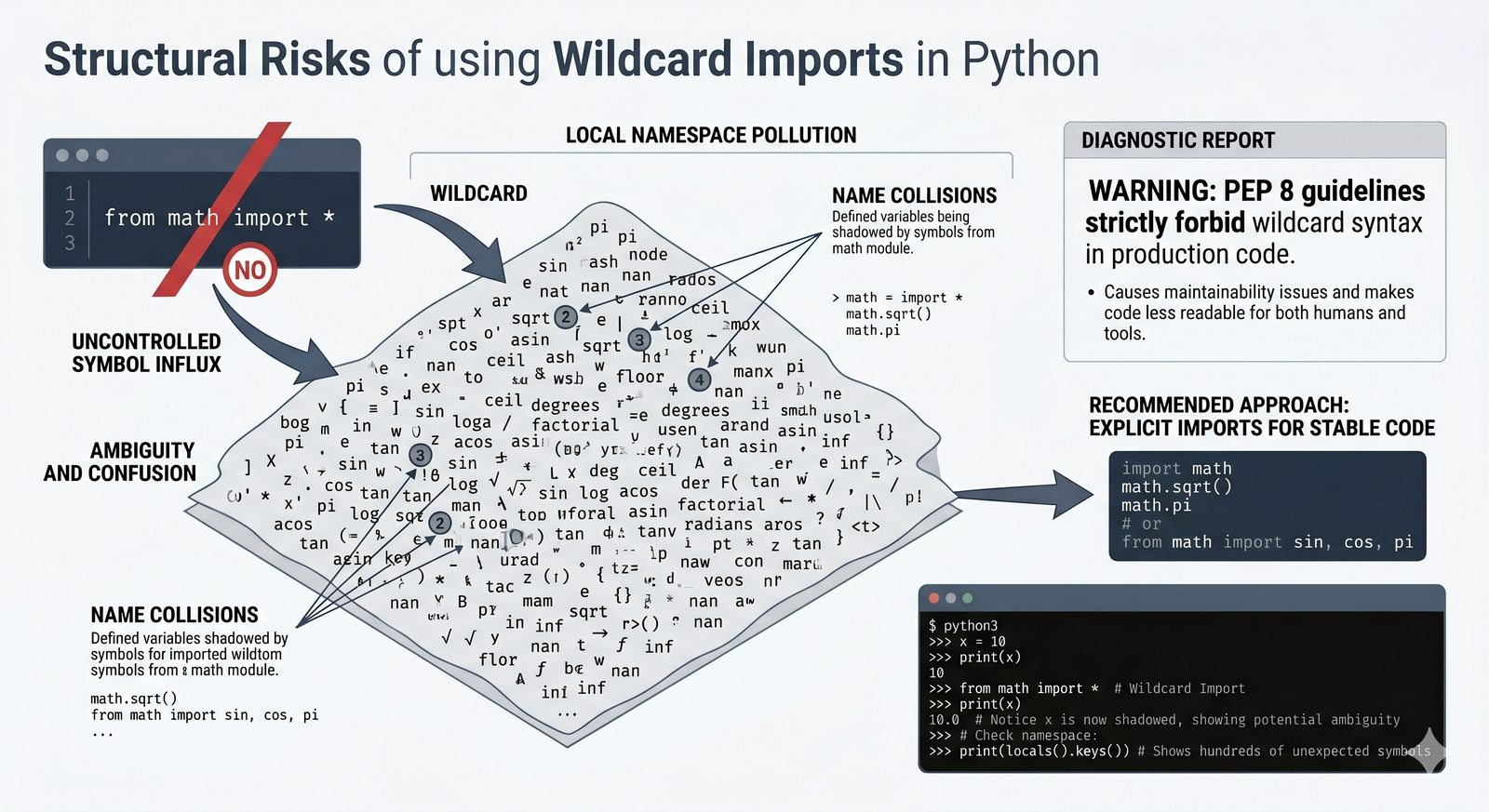
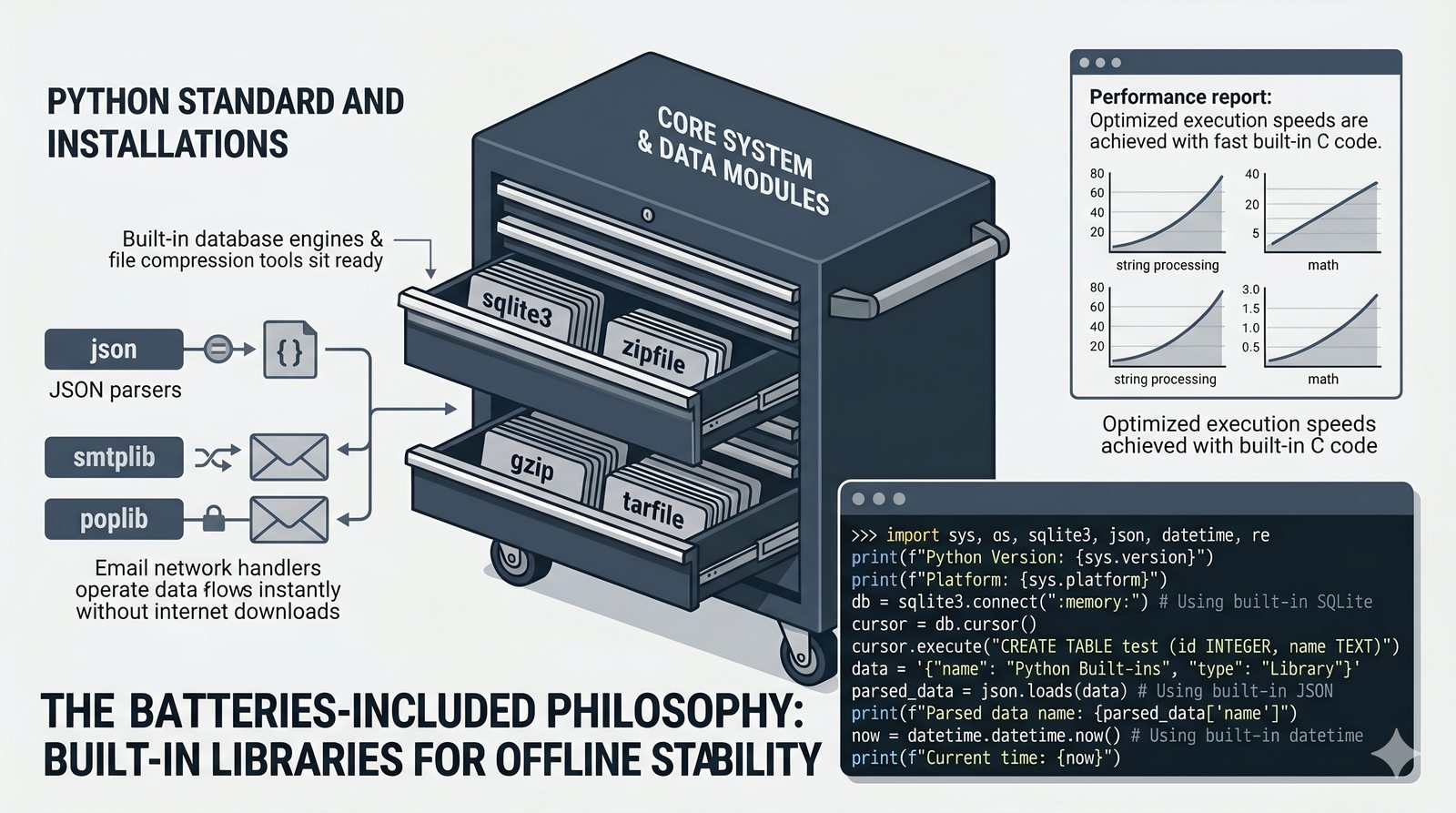
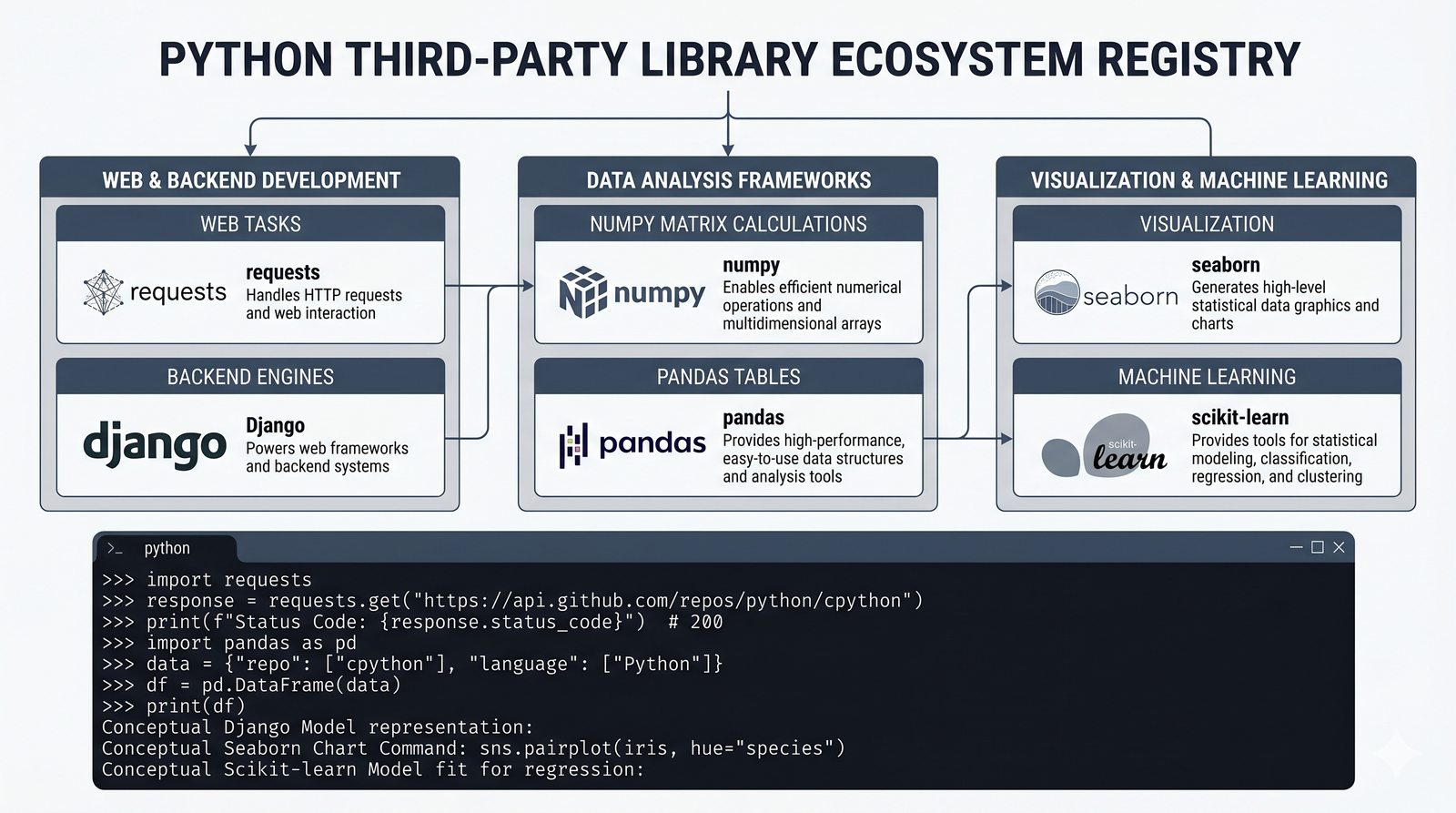
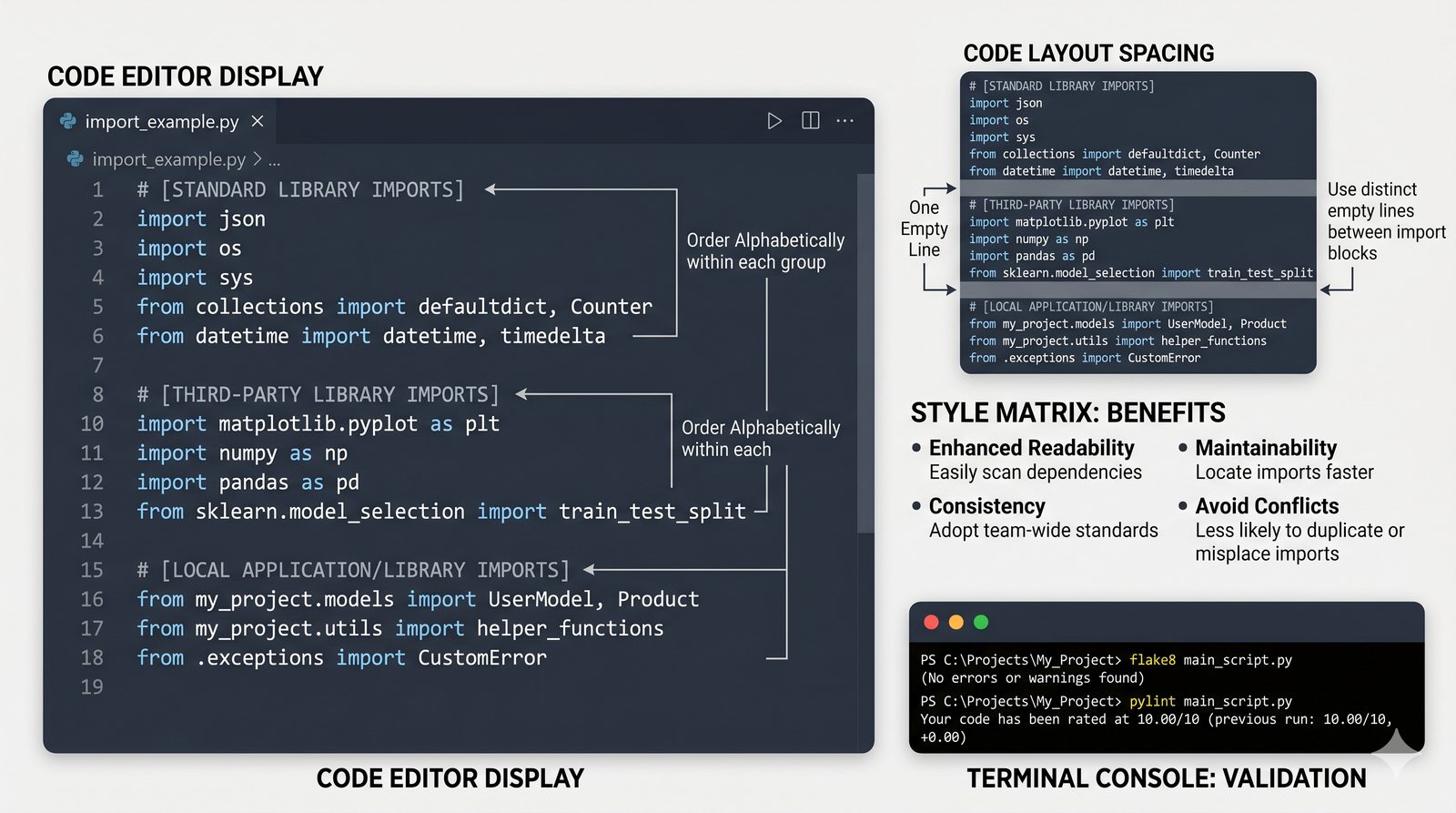
import,from...import,as, pułapka importu gwiazdkowego (*) - Biblioteka standardowa – przegląd modułów
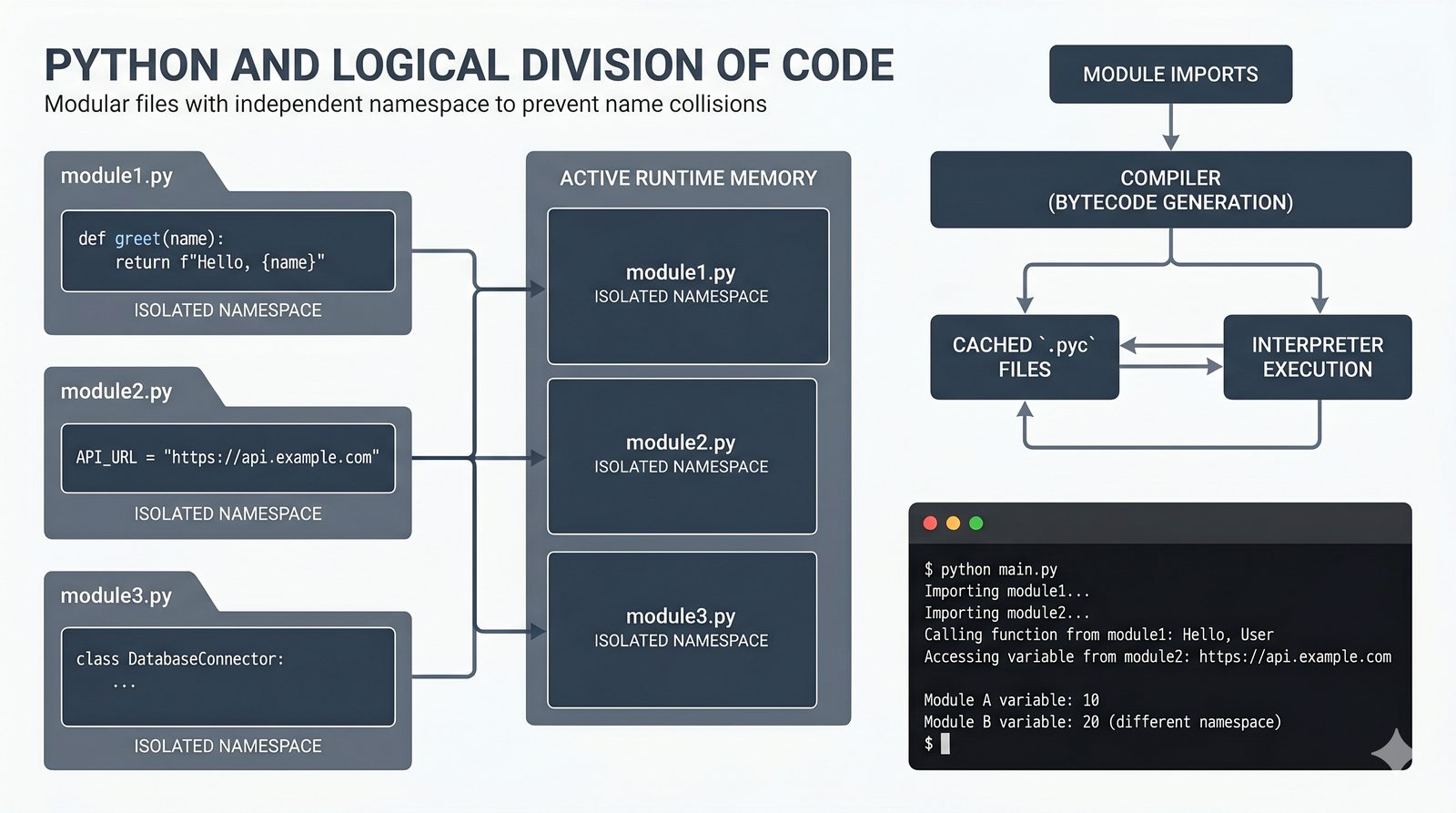
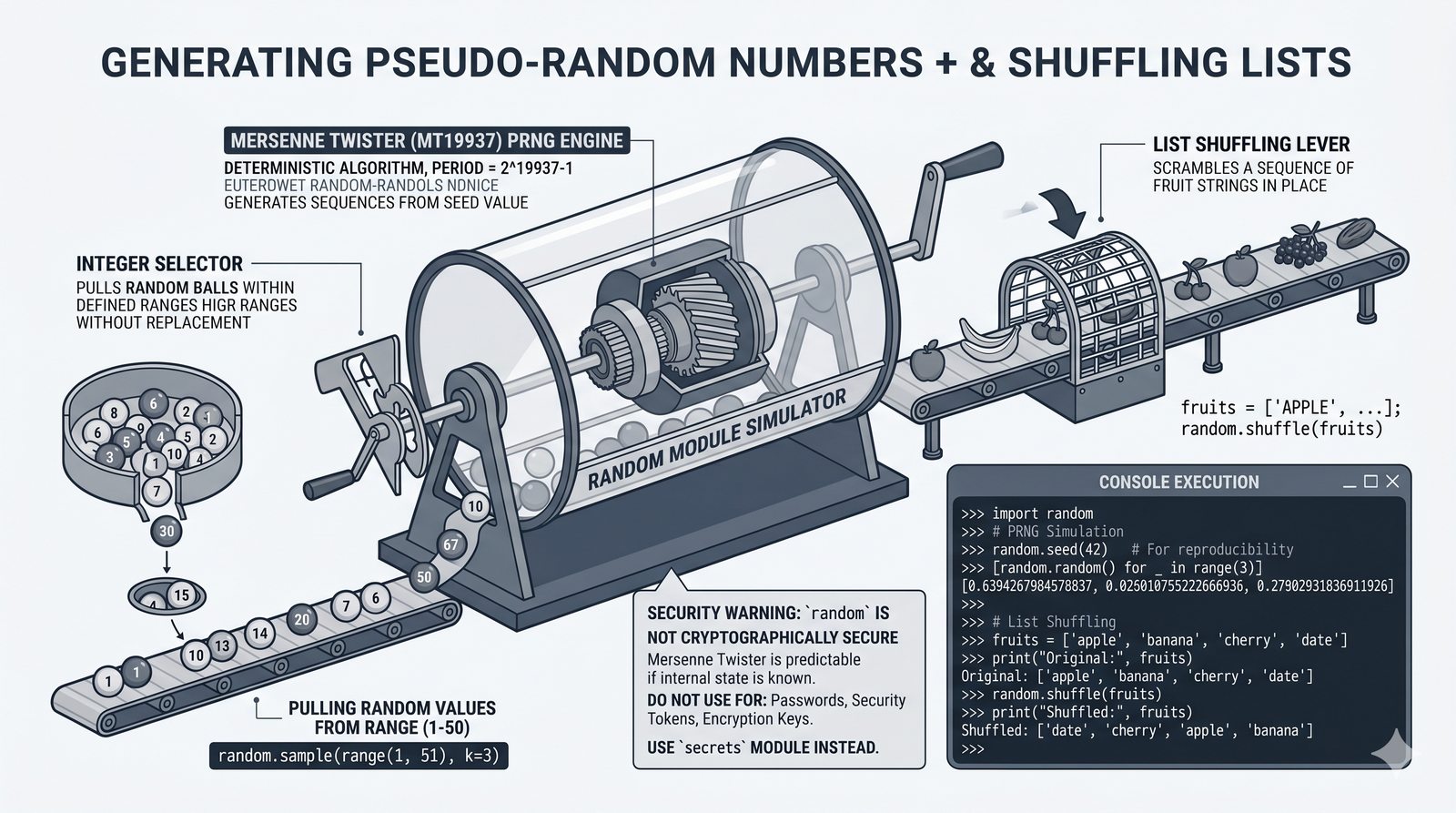
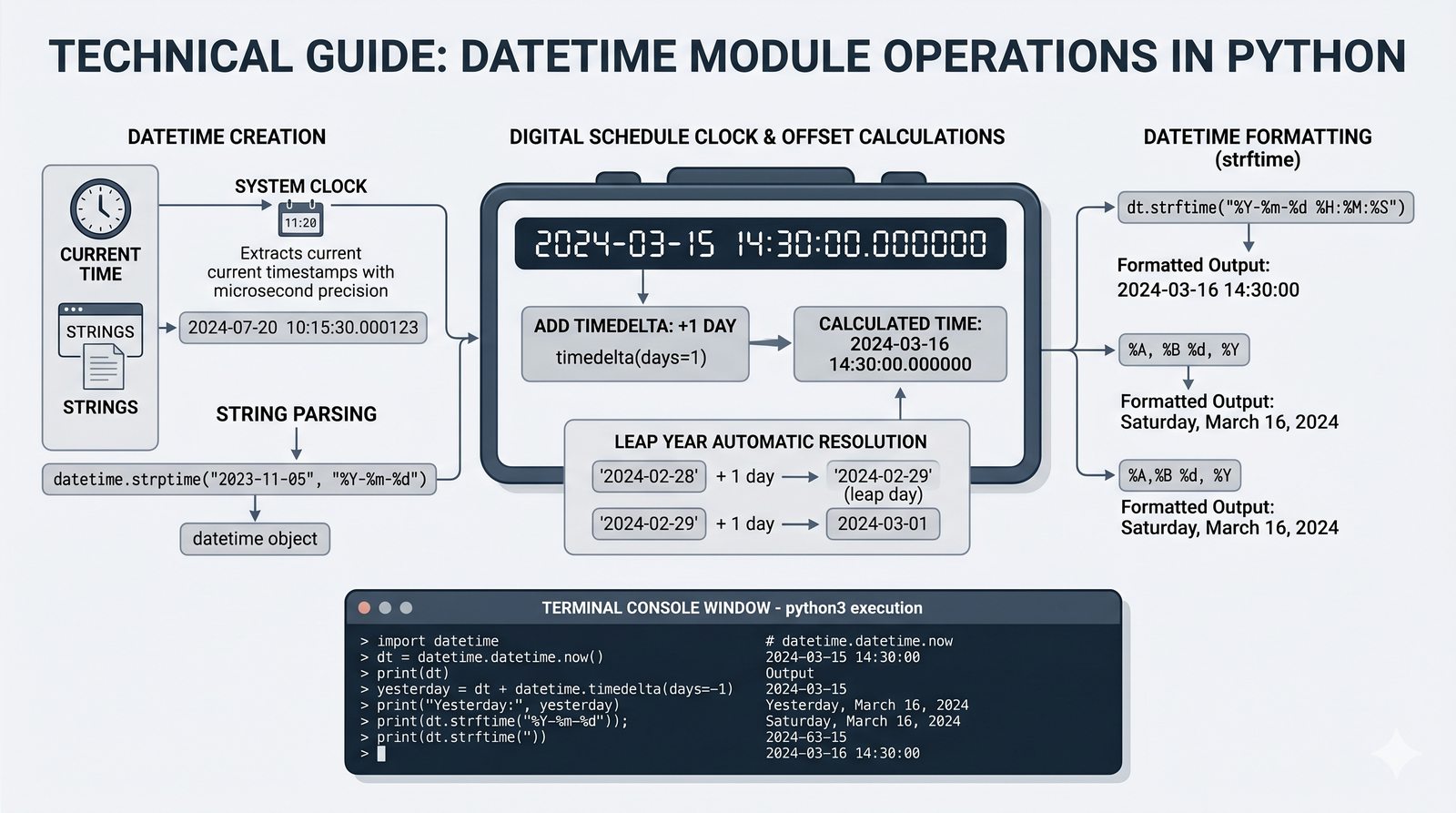
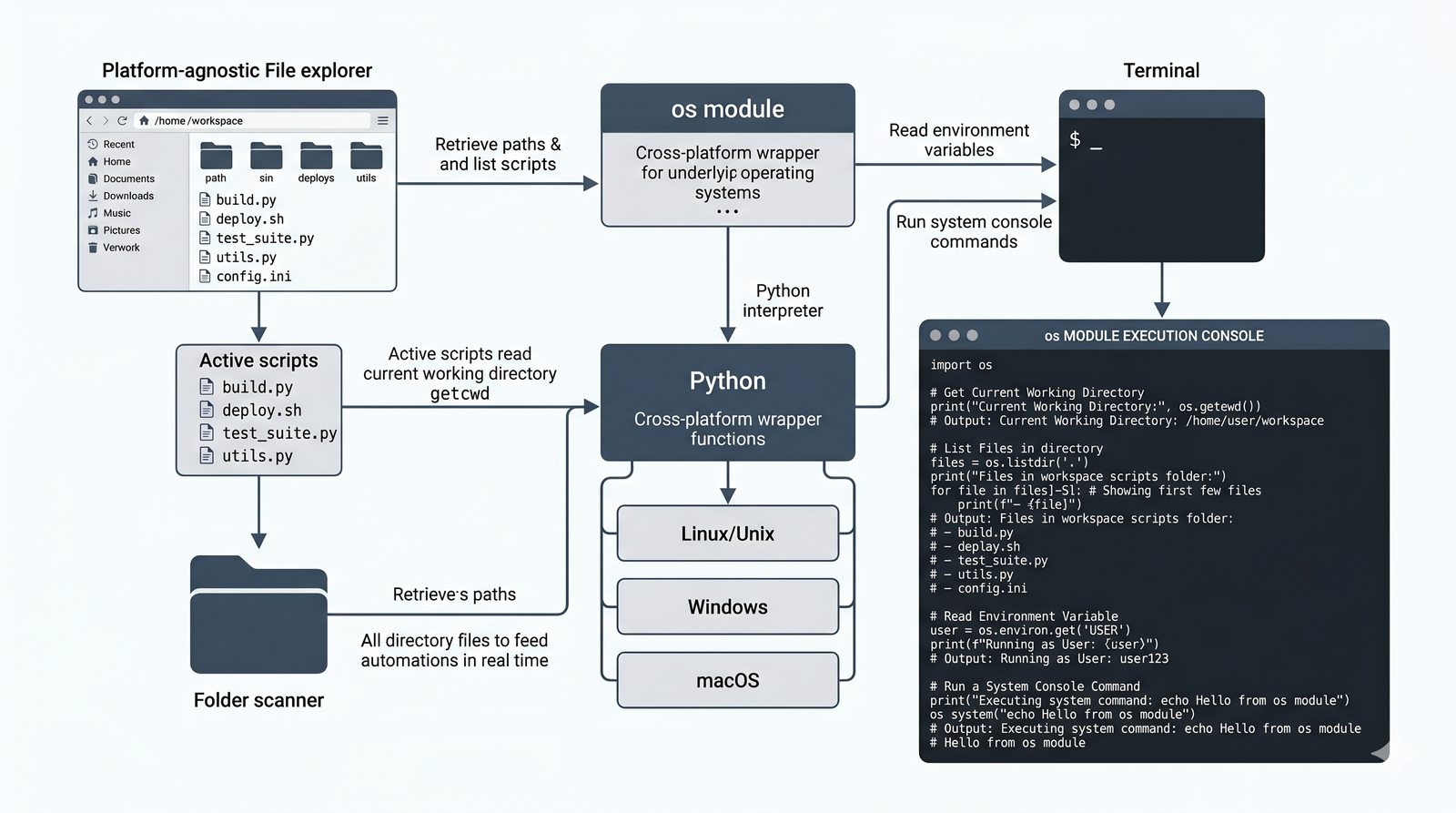
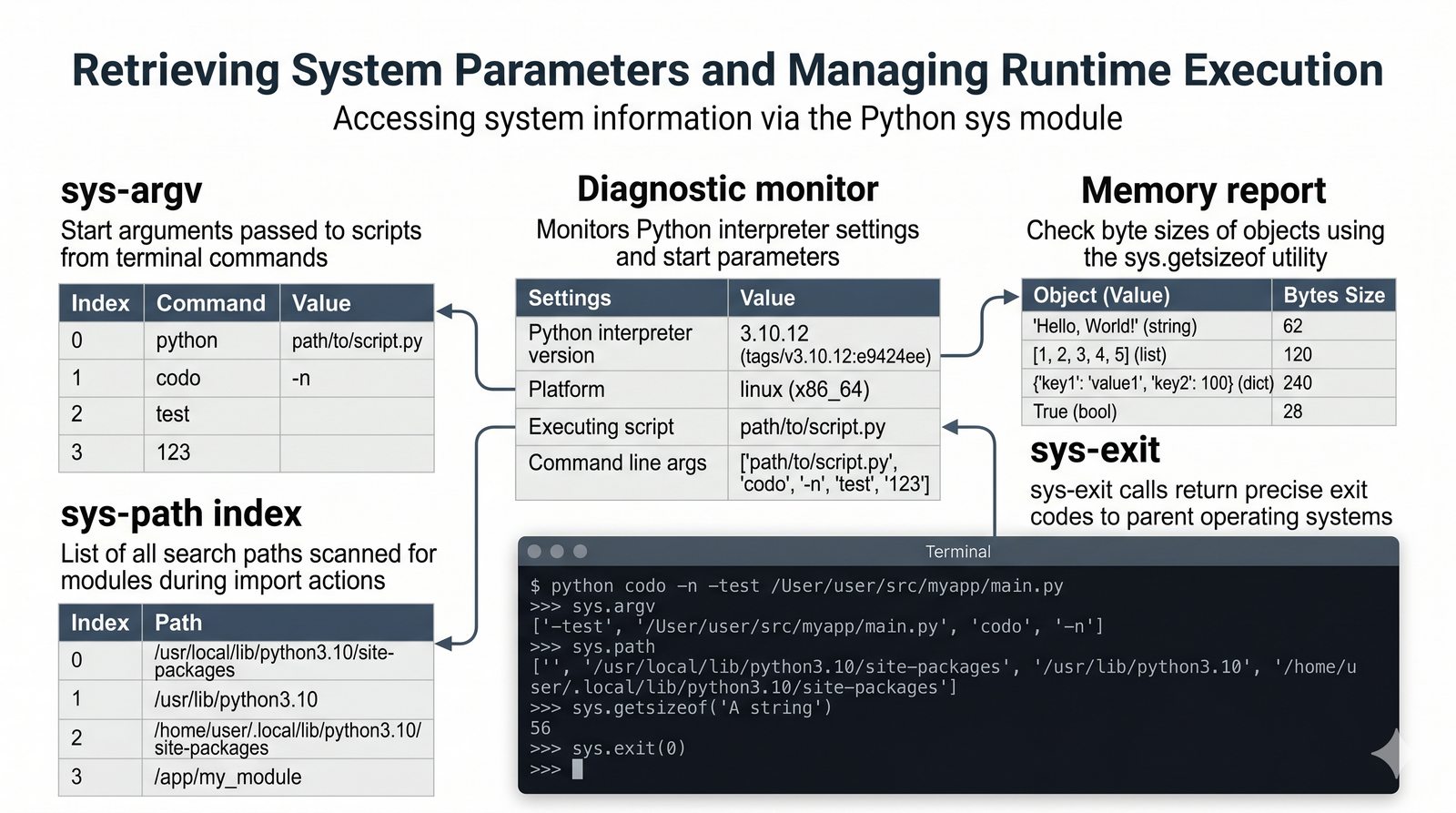
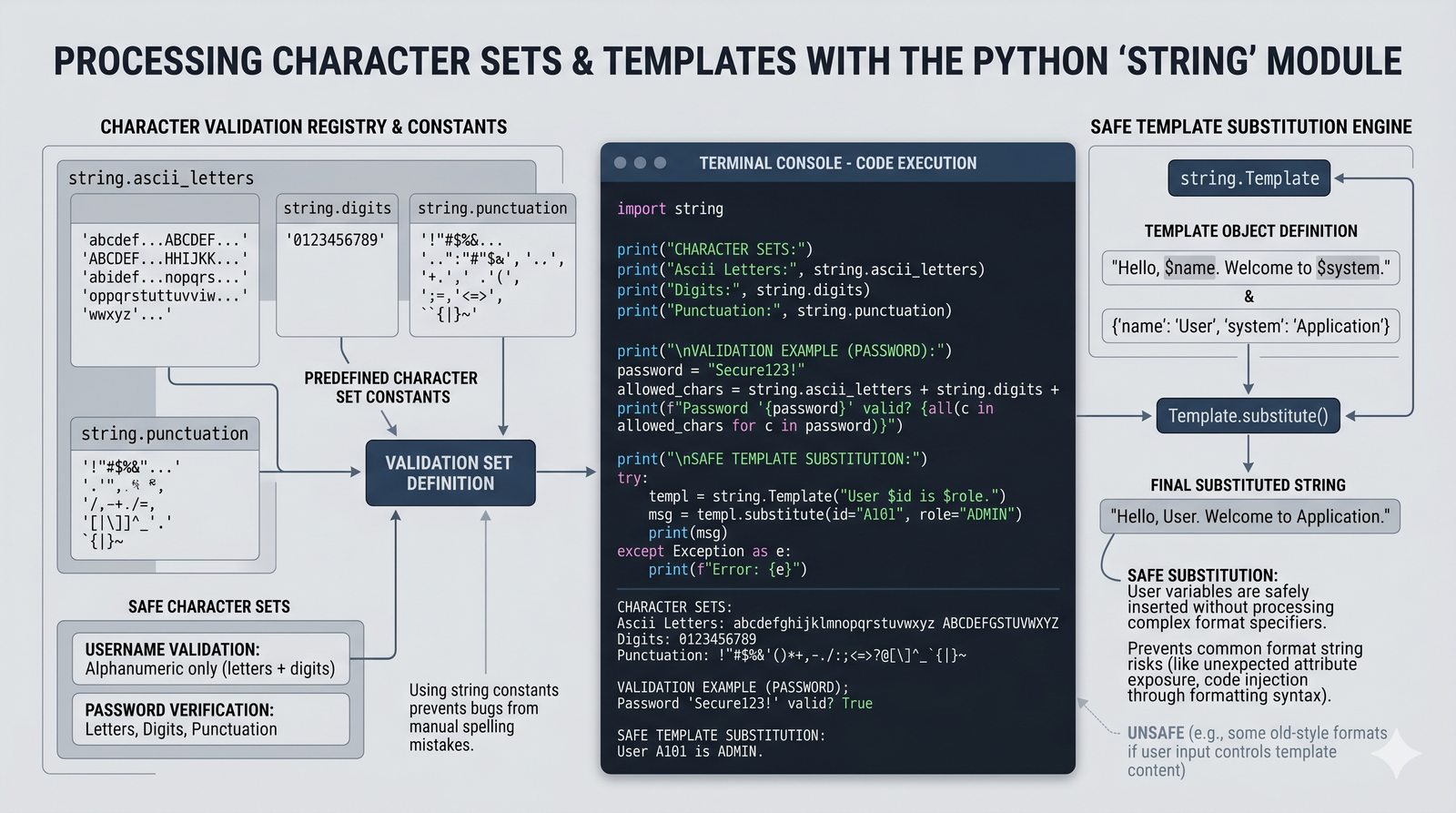
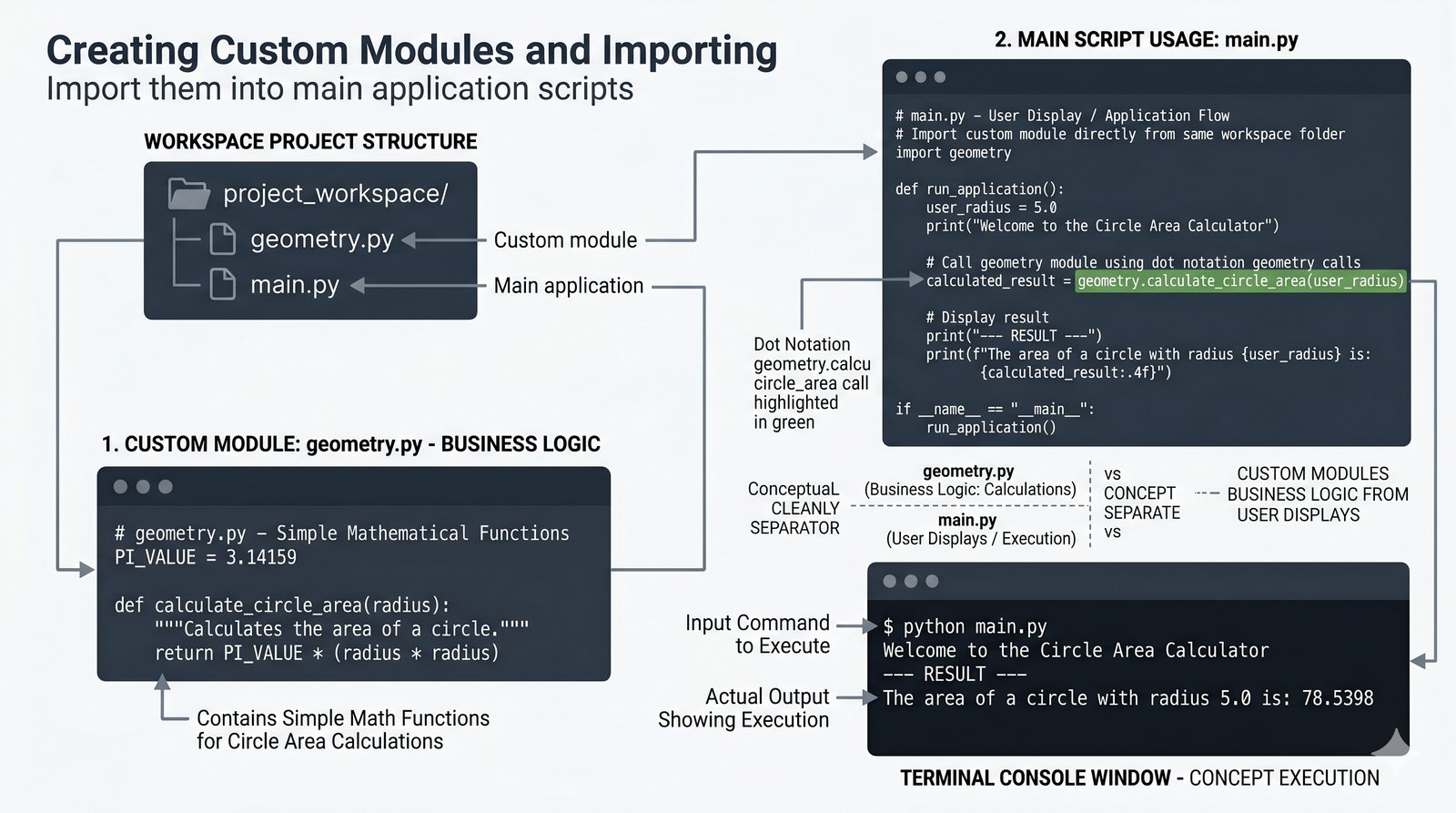
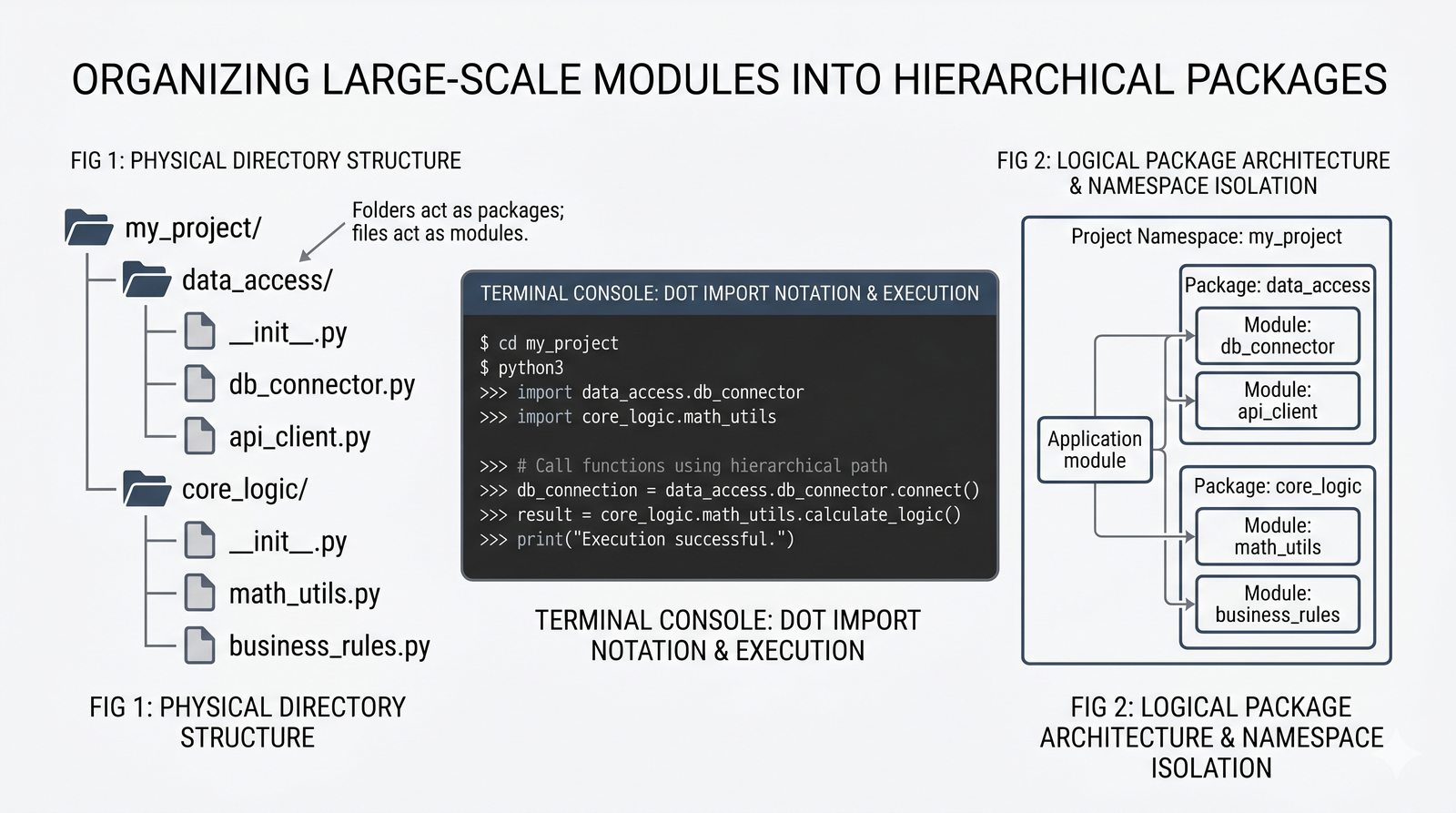
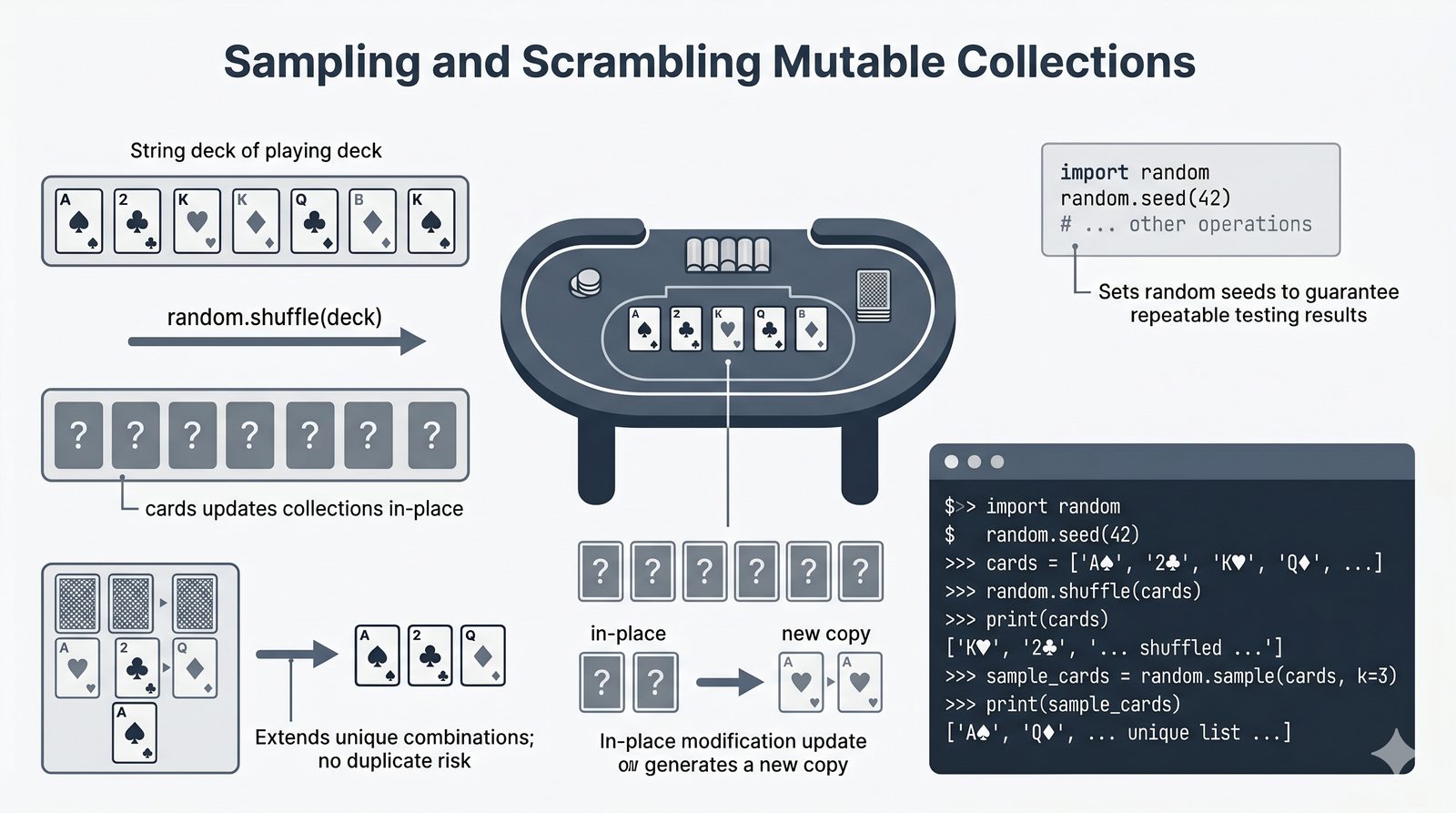
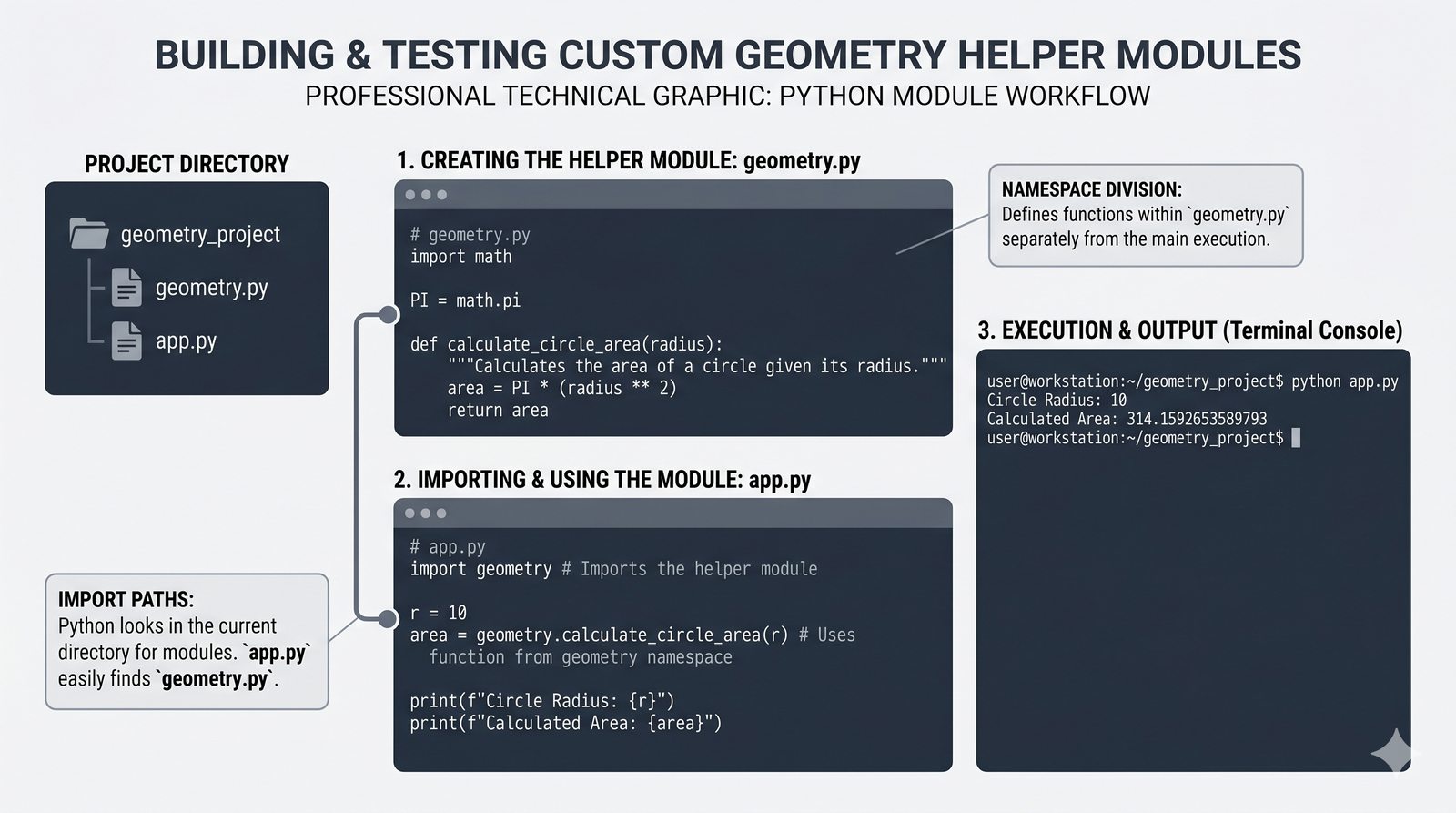
math,random,datetime,os,sys,stringi ich praktyczne zastosowania - Własne moduły i pakiety – tworzenie pliku
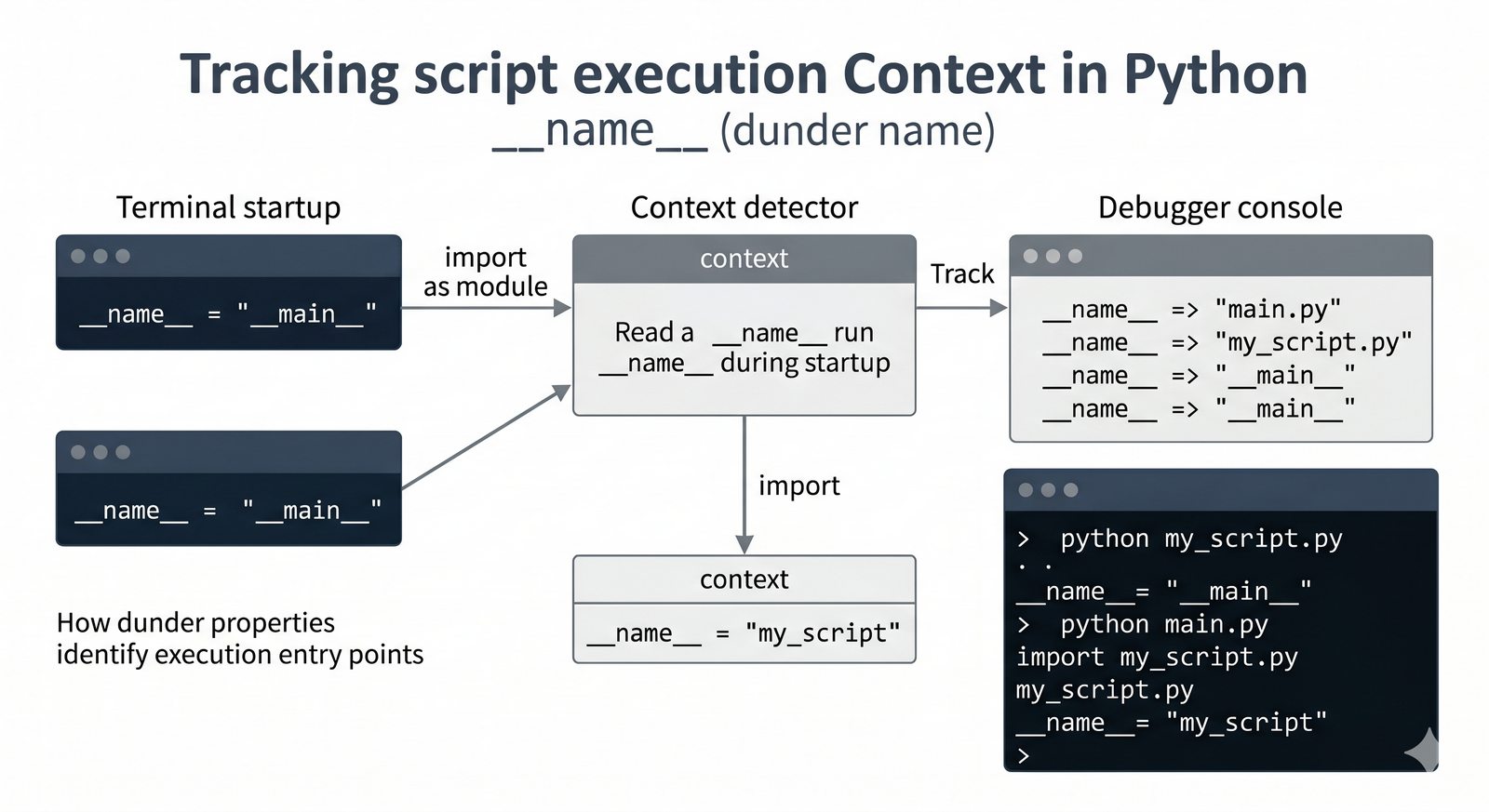
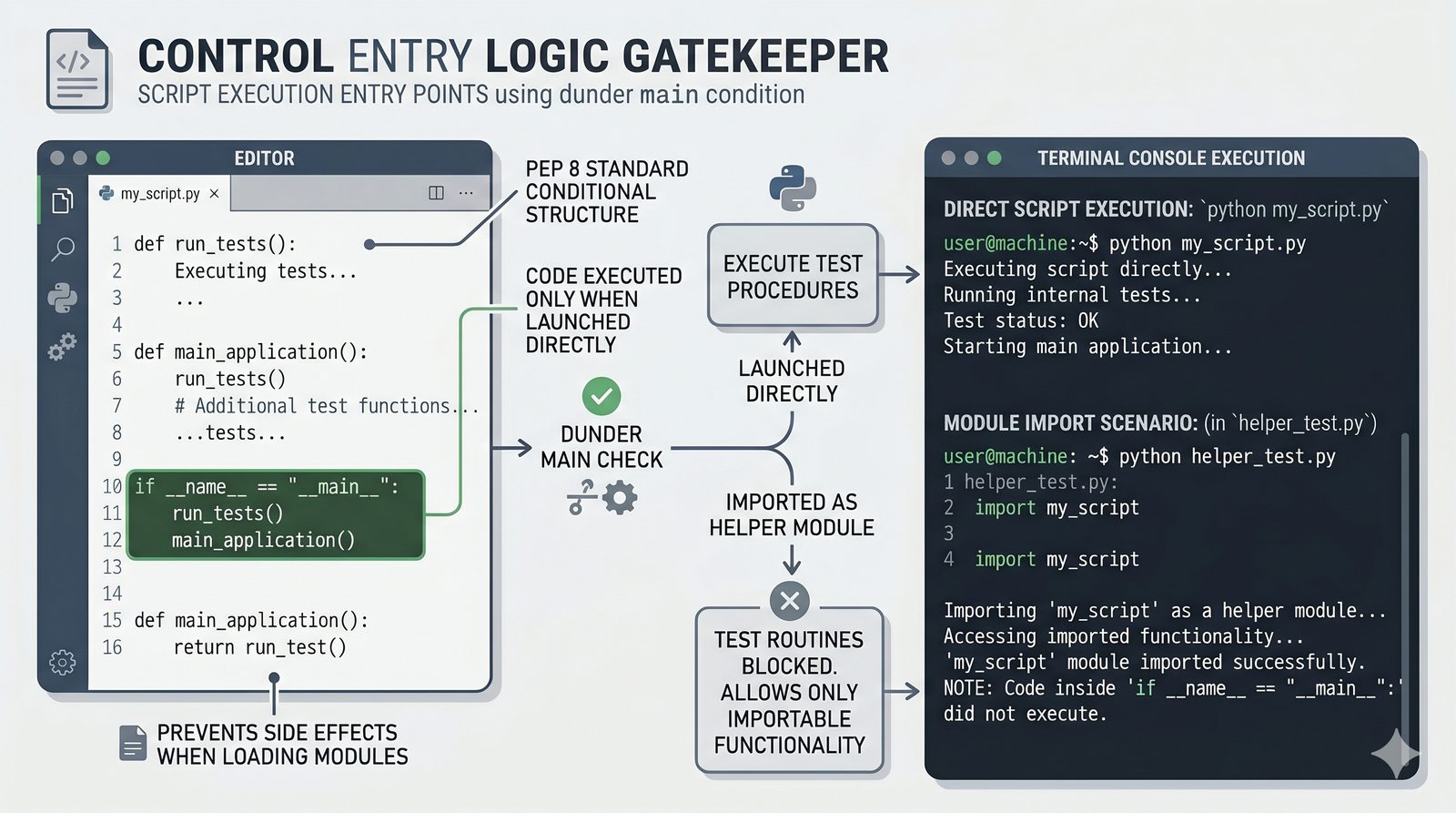
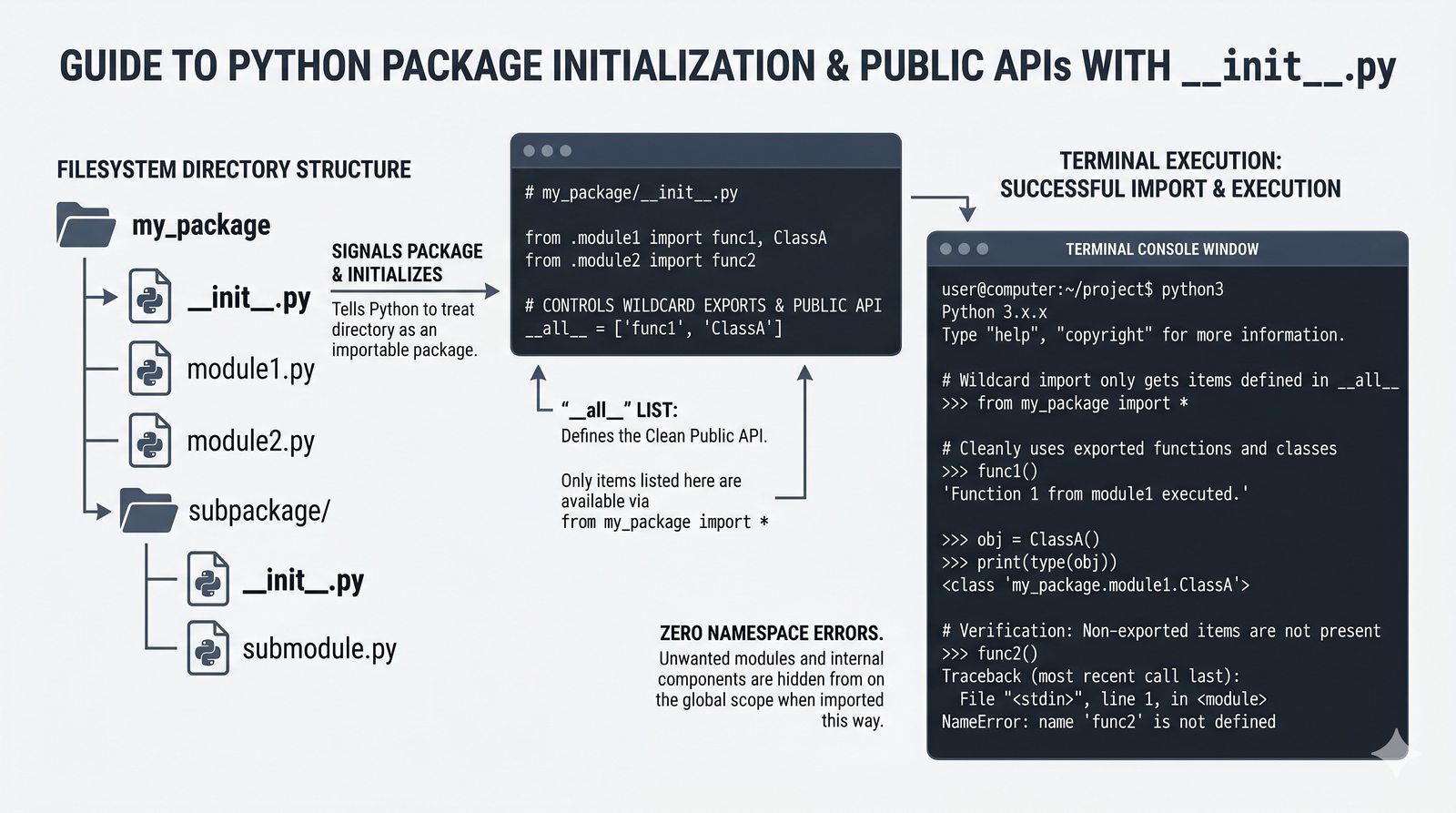
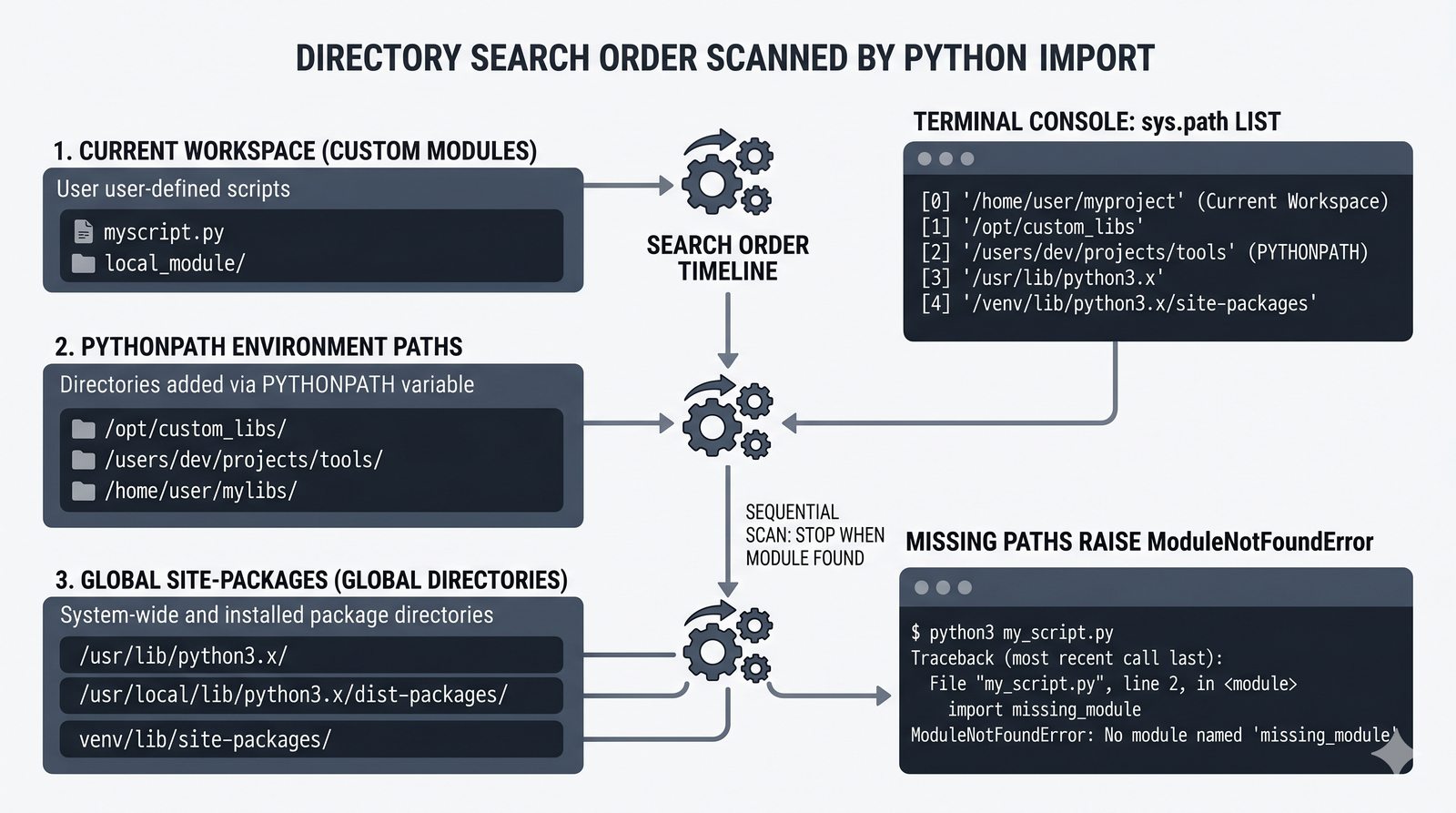
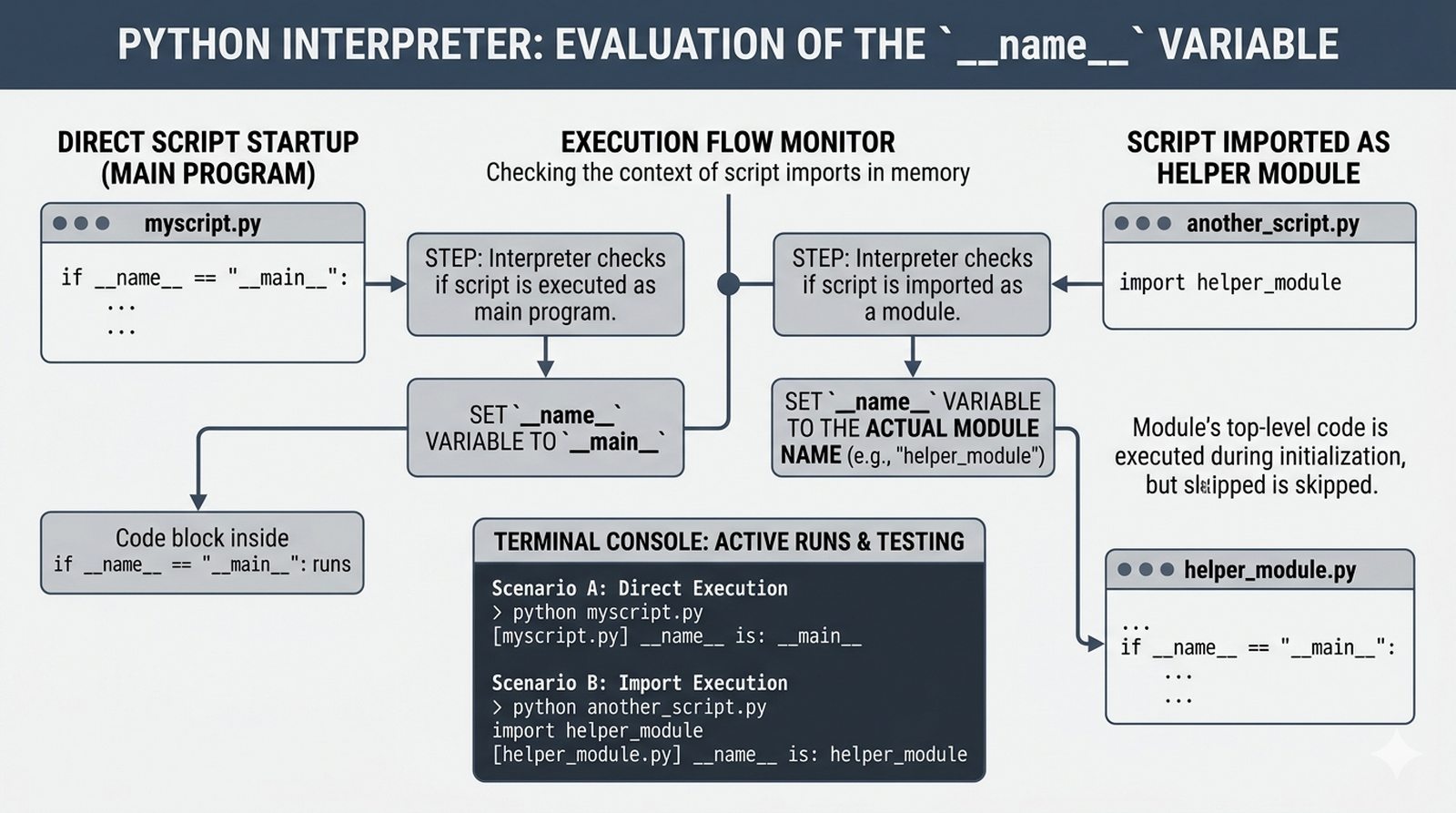
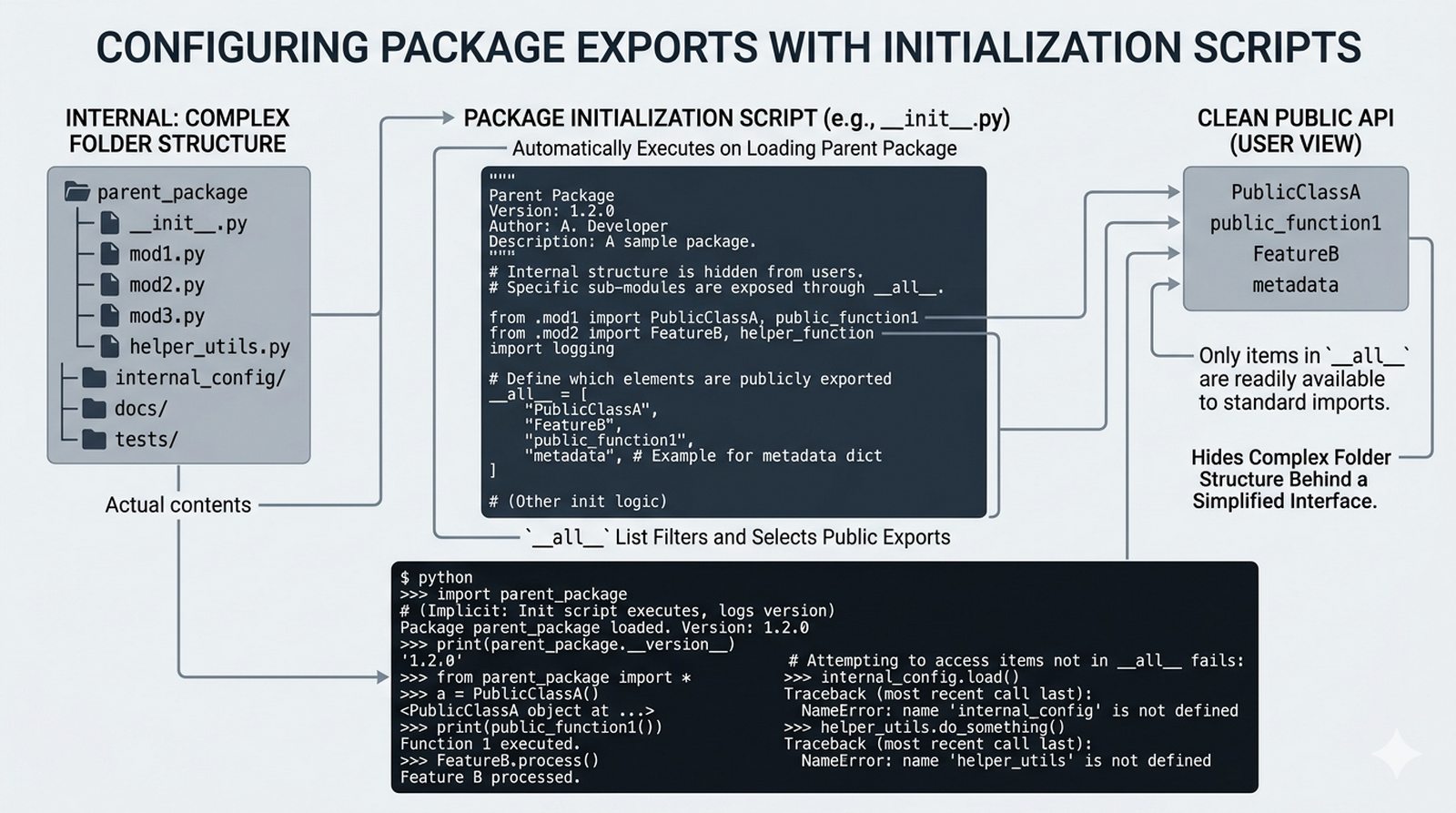
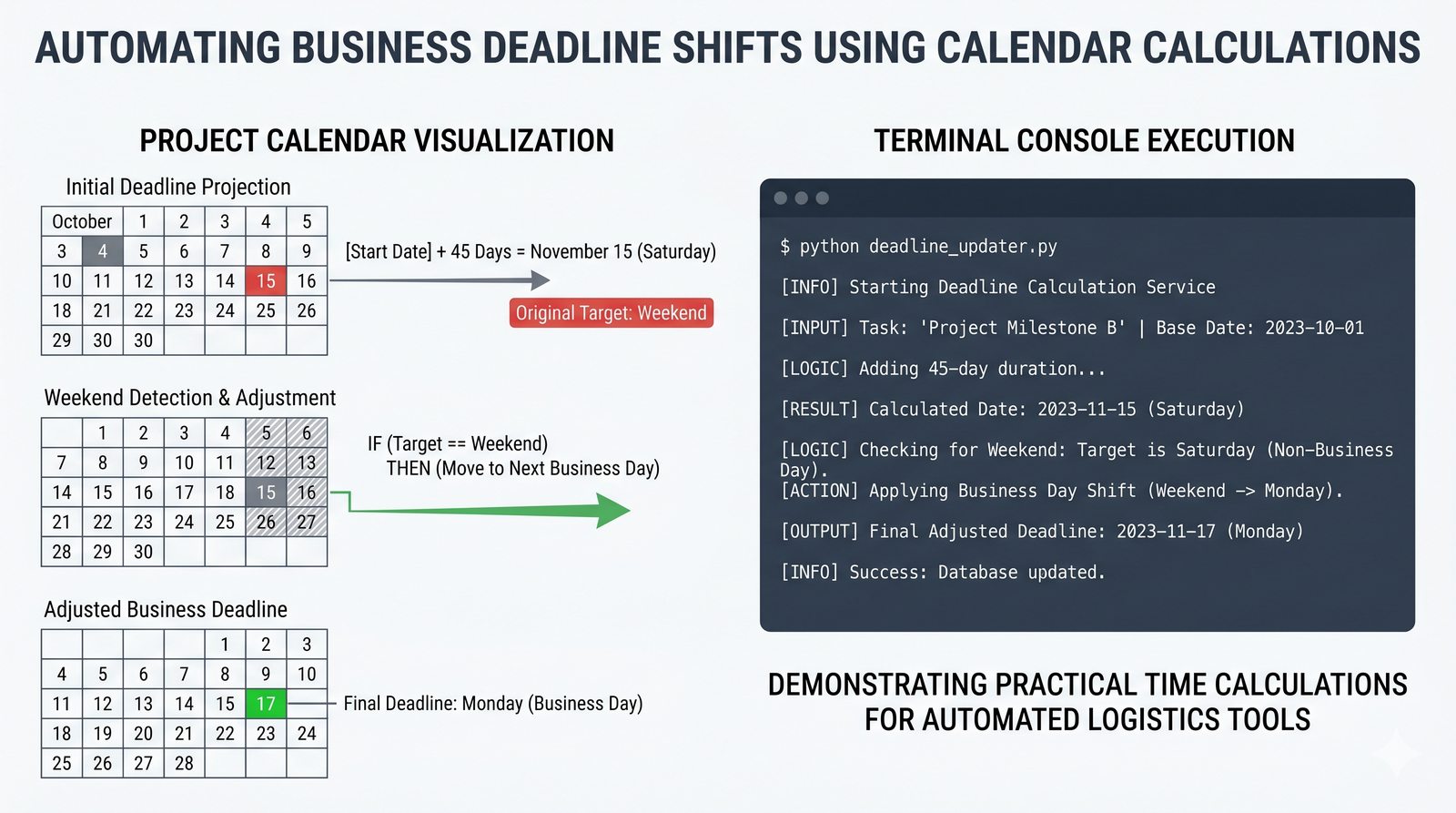
.py, struktura pakietów, plik__init__.py, zmienna__name__i warunekif __name__ == '__main__' - Zarządzanie zależnościami –
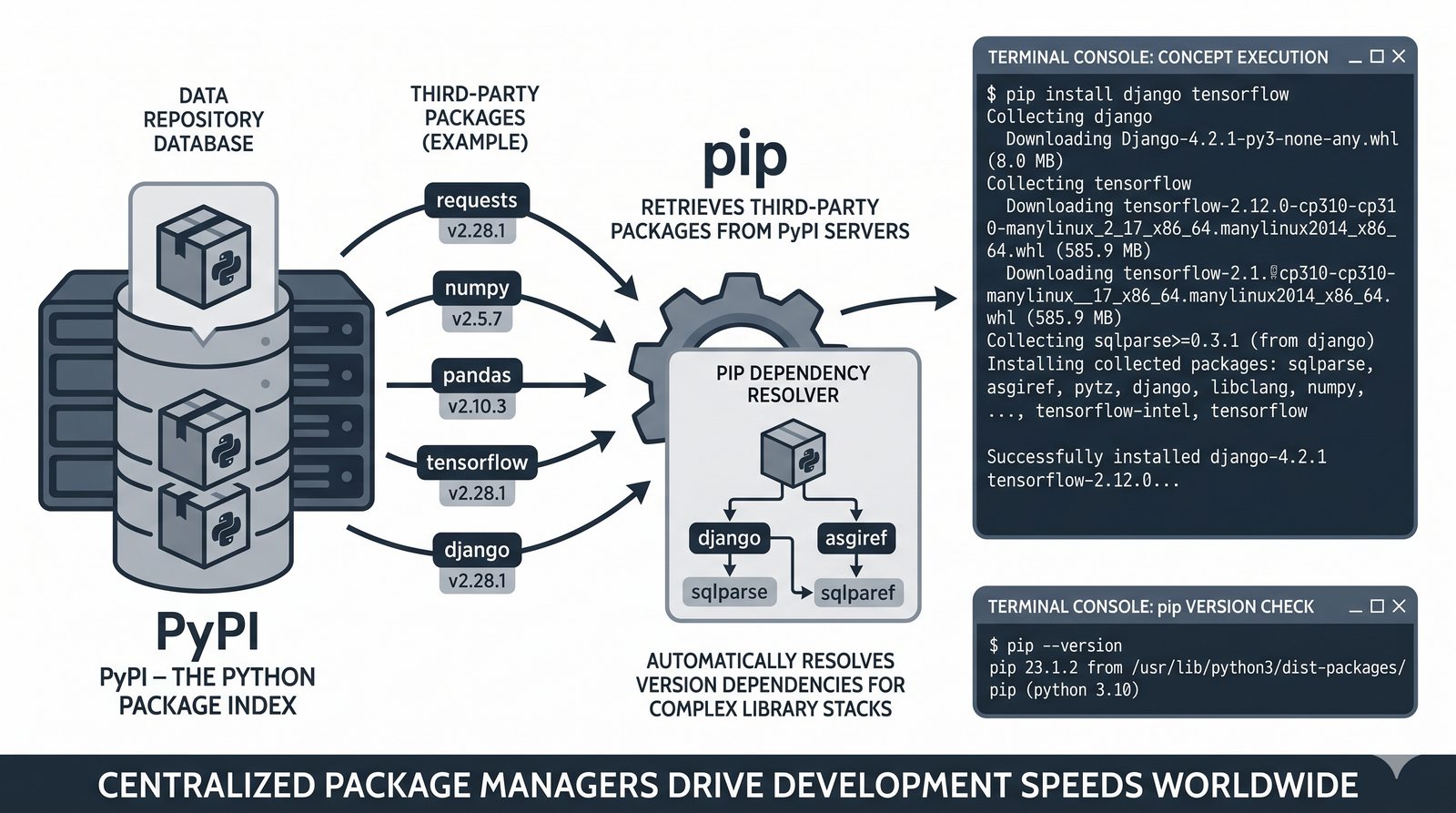
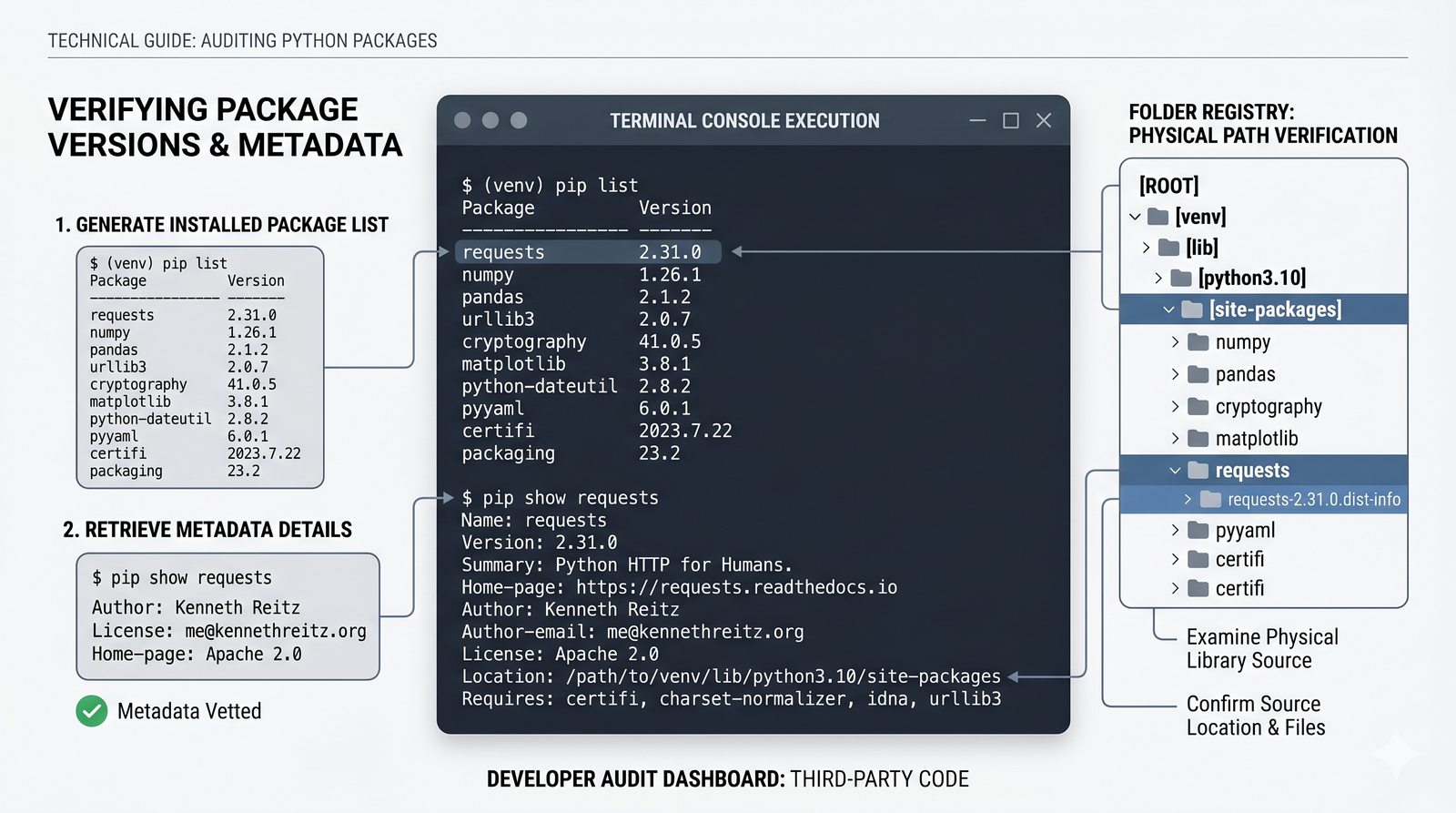
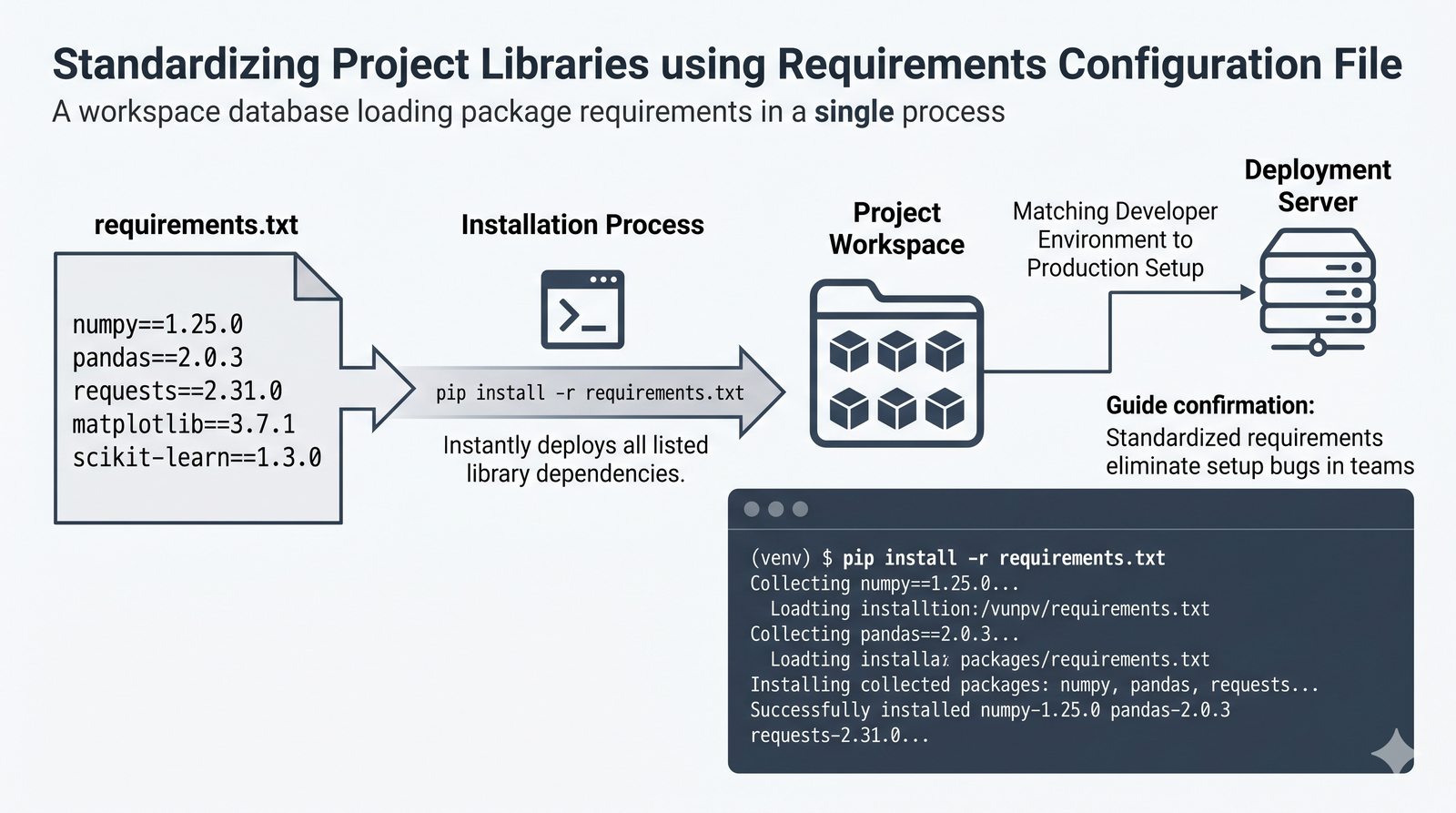
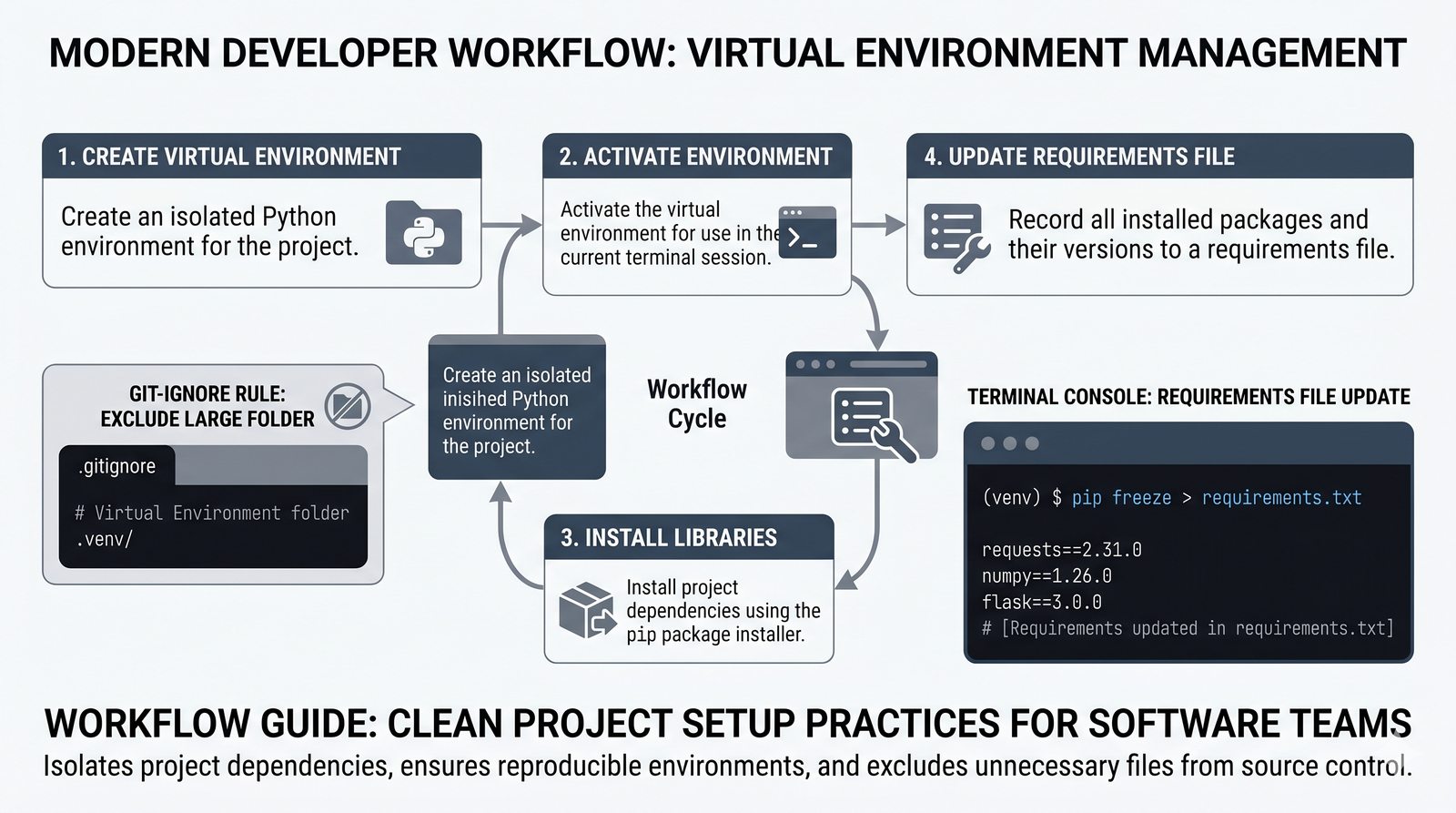
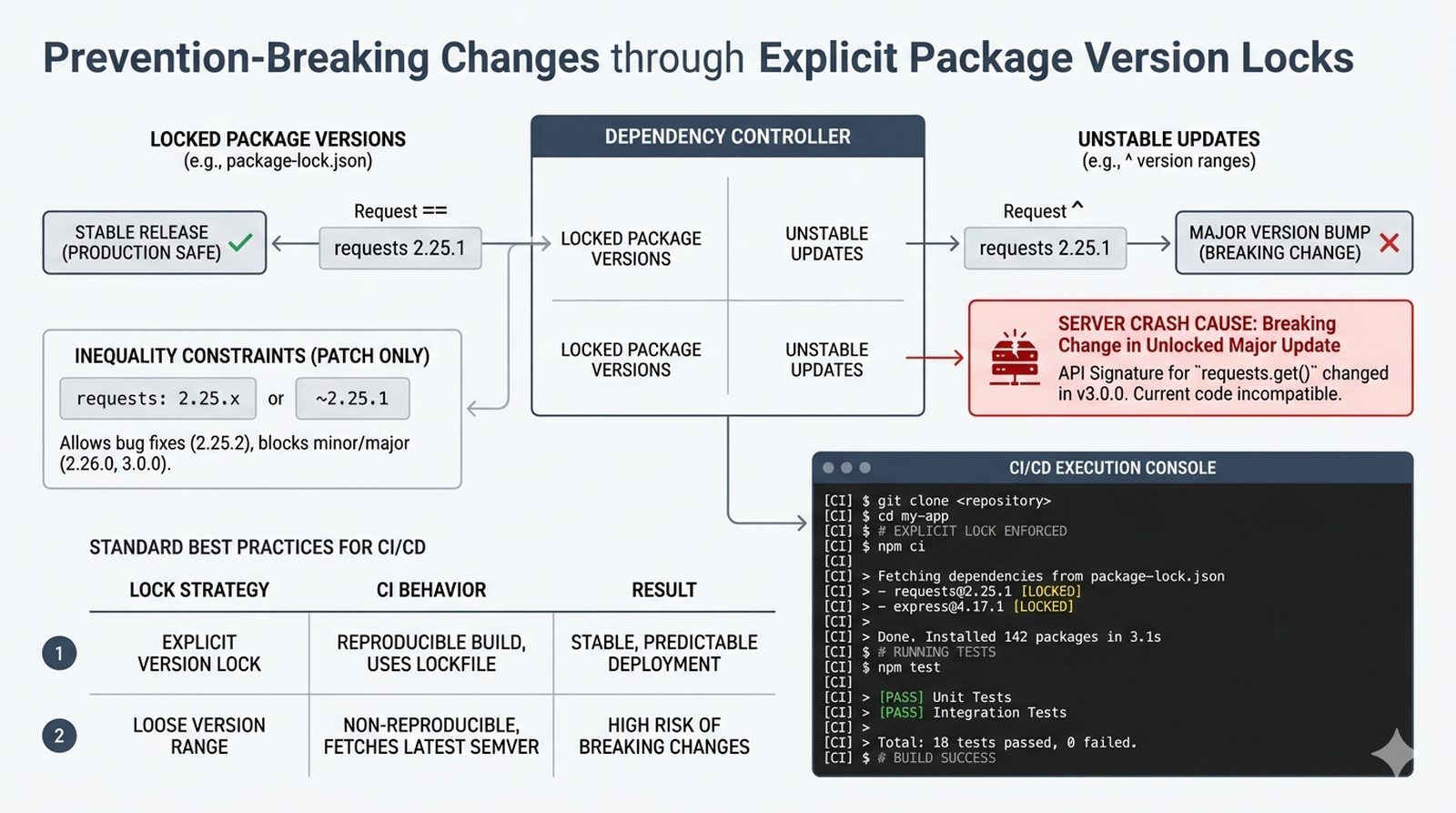
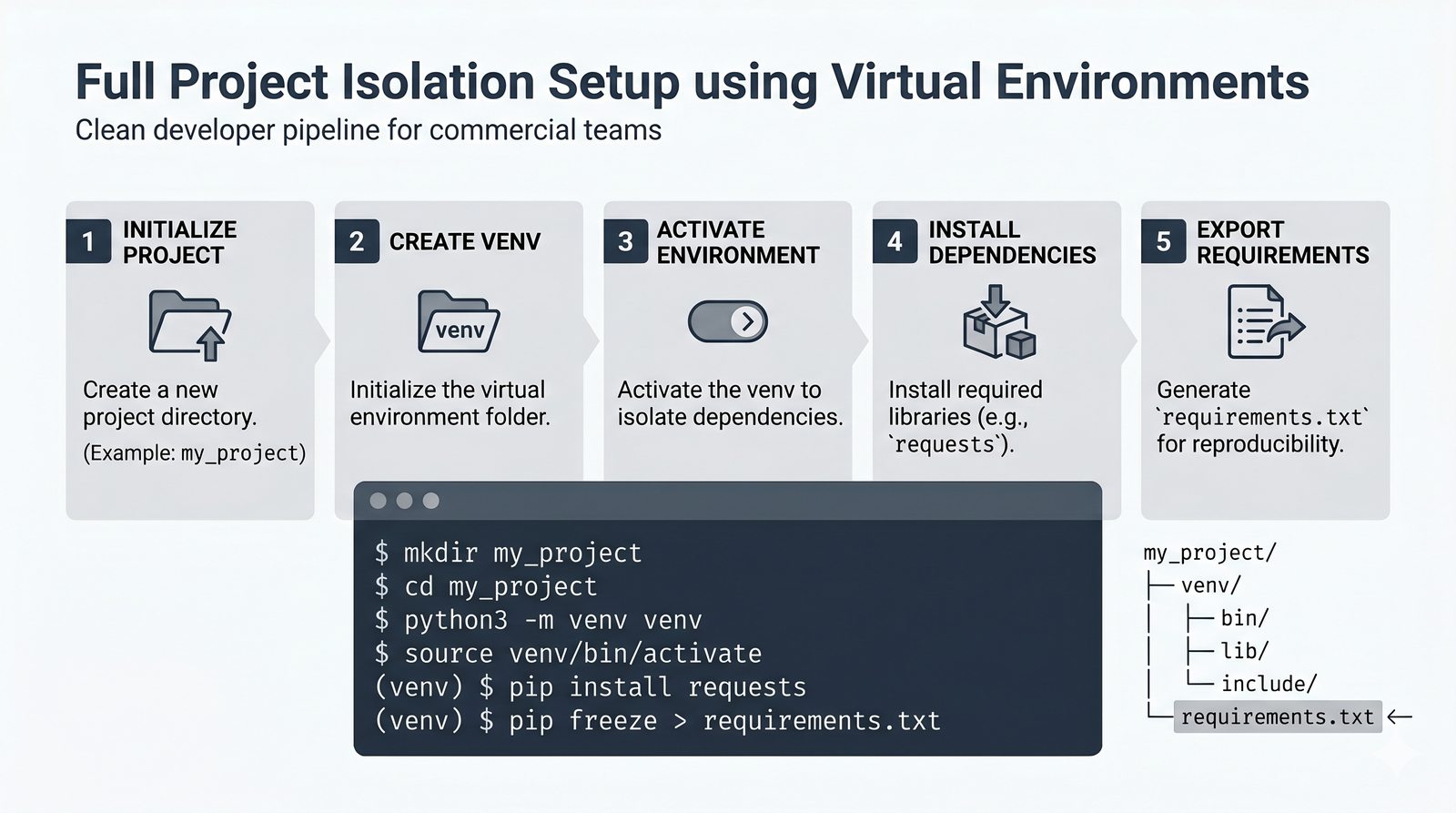
pip, instalacja i usuwanie pakietów, PyPI, plikrequirements.txti precyzyjne wersjonowanie - Środowiska wirtualne –
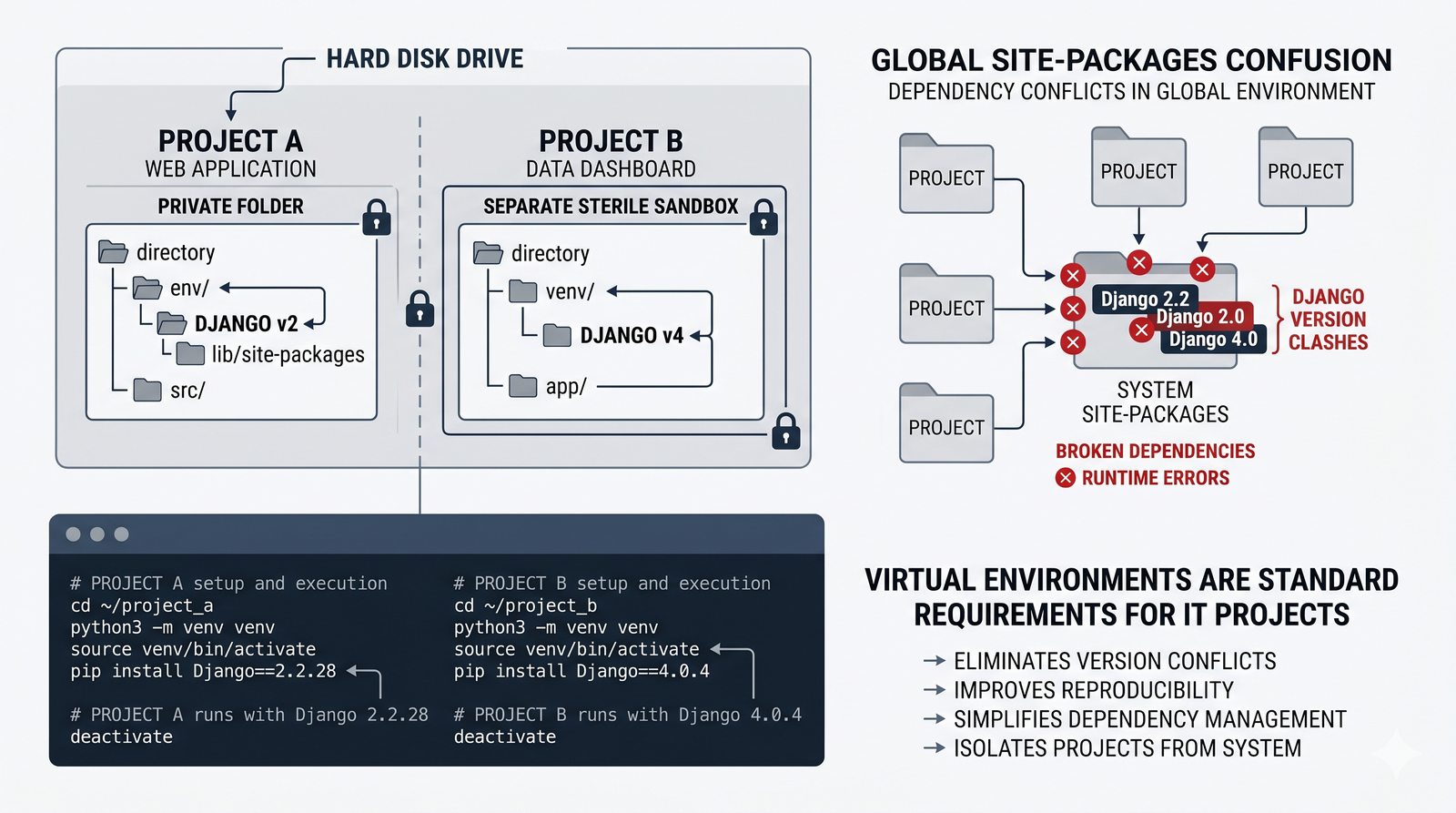
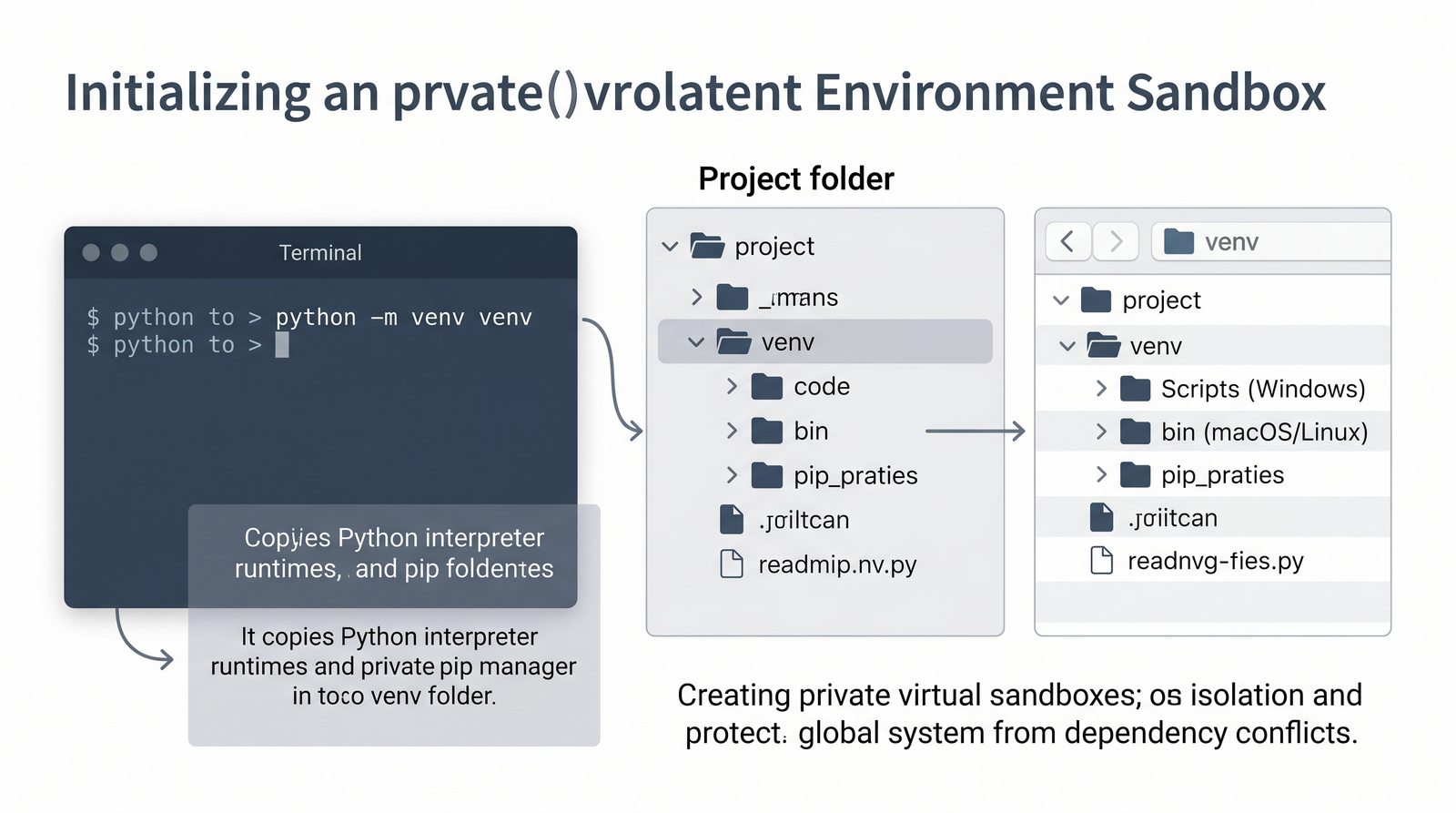
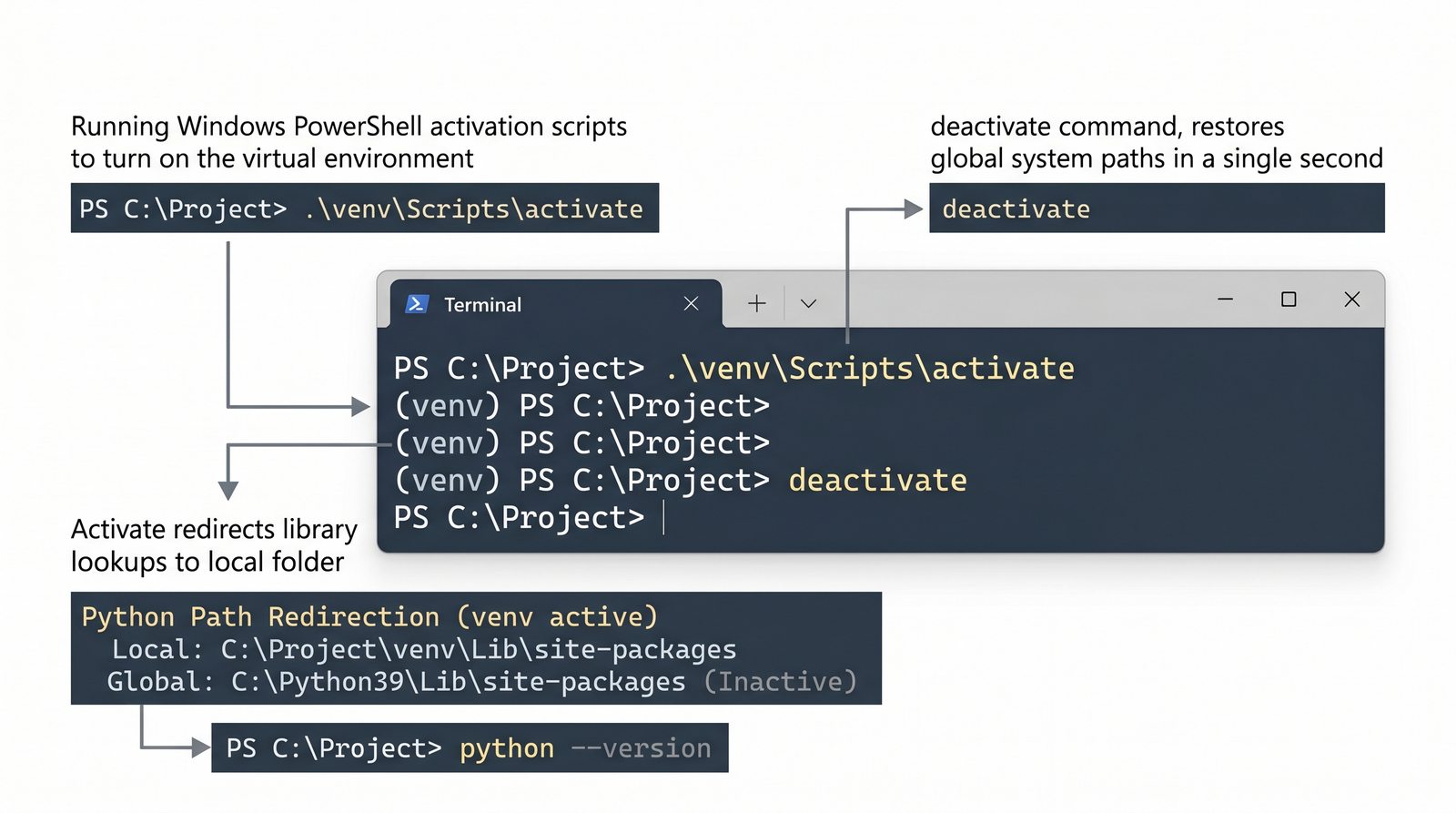
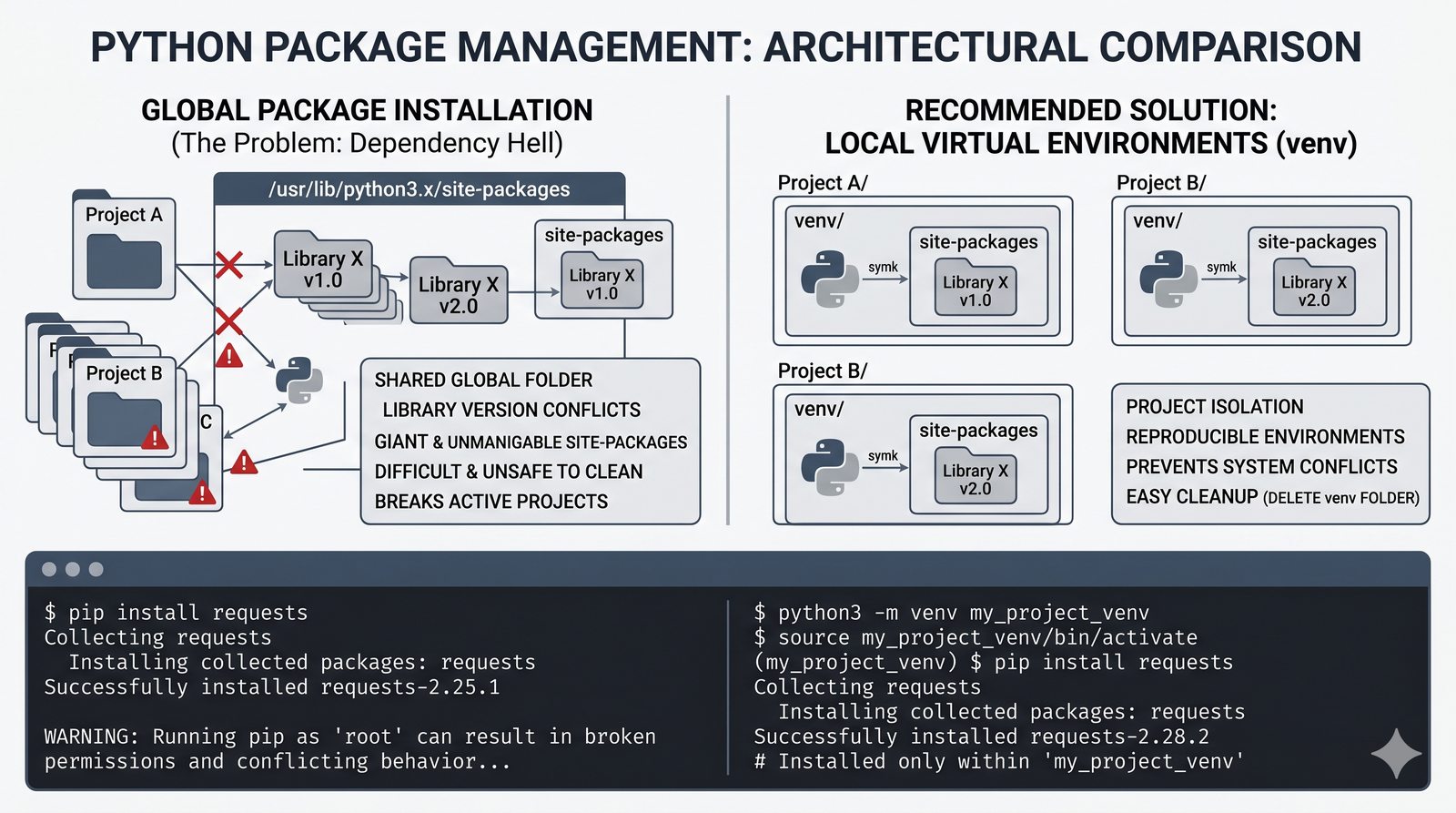
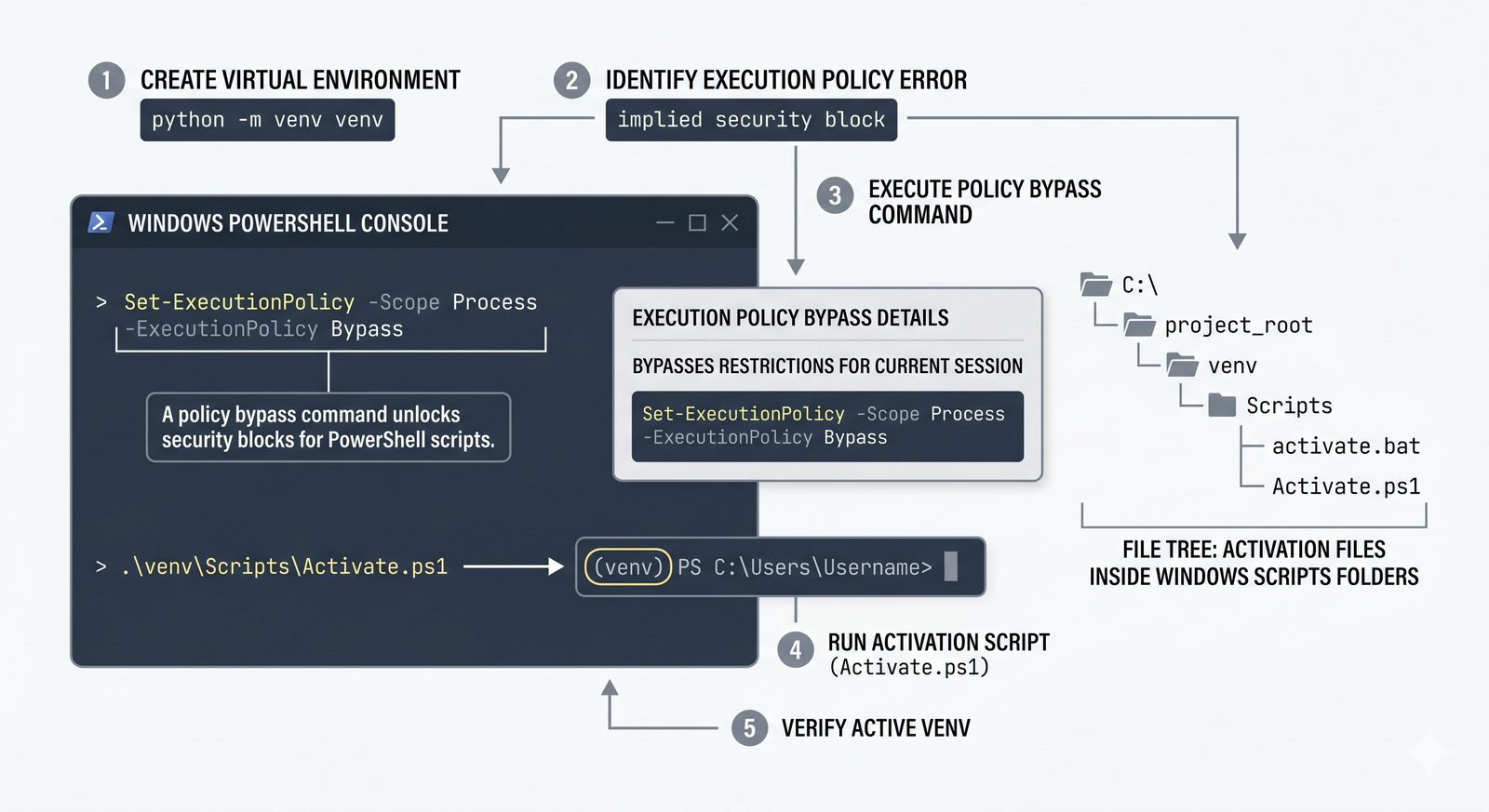
venv, tworzenie, aktywacja, dezaktywacja, izolacja zależności, workflow zrequirements.txti.gitignore