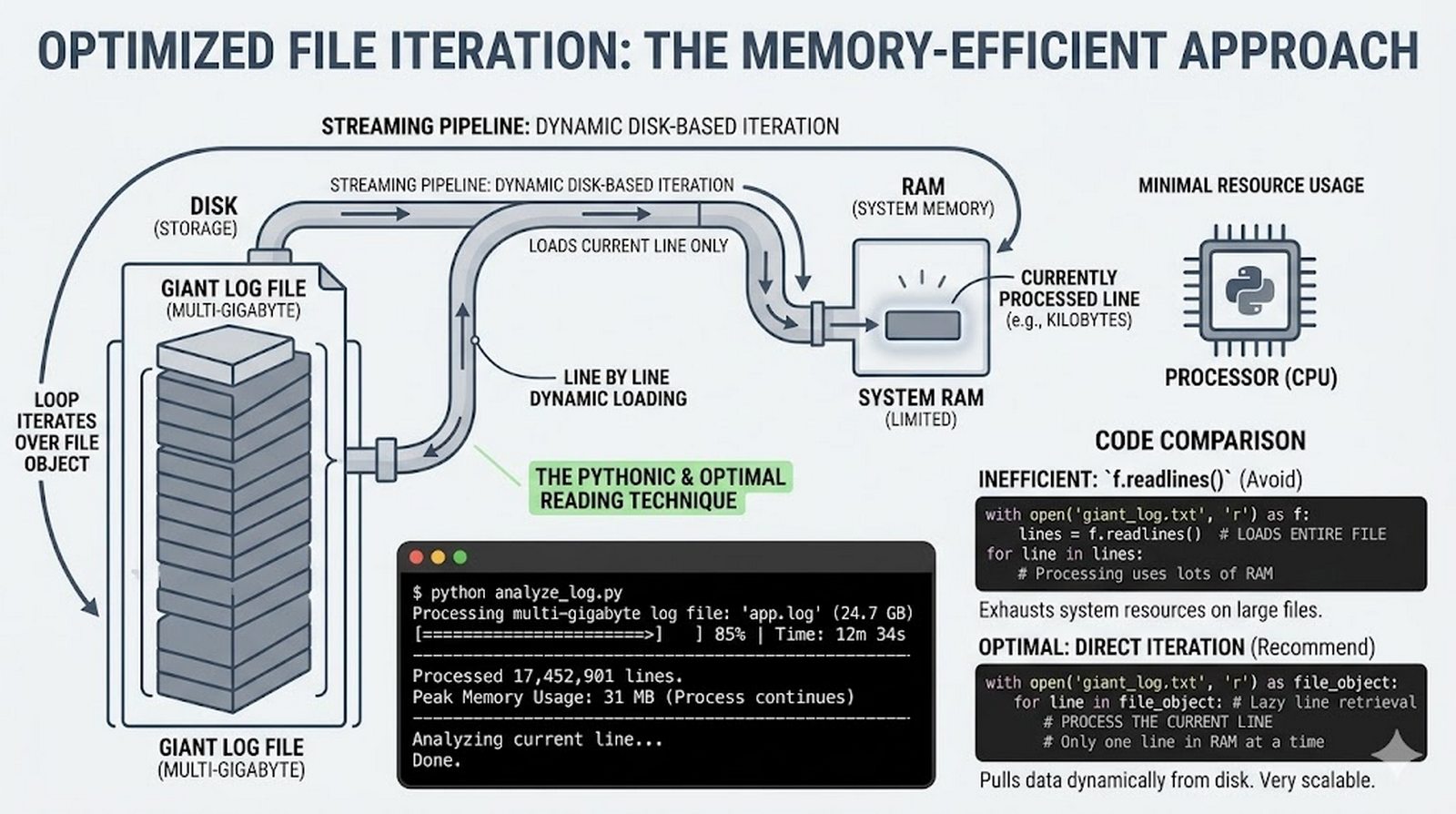
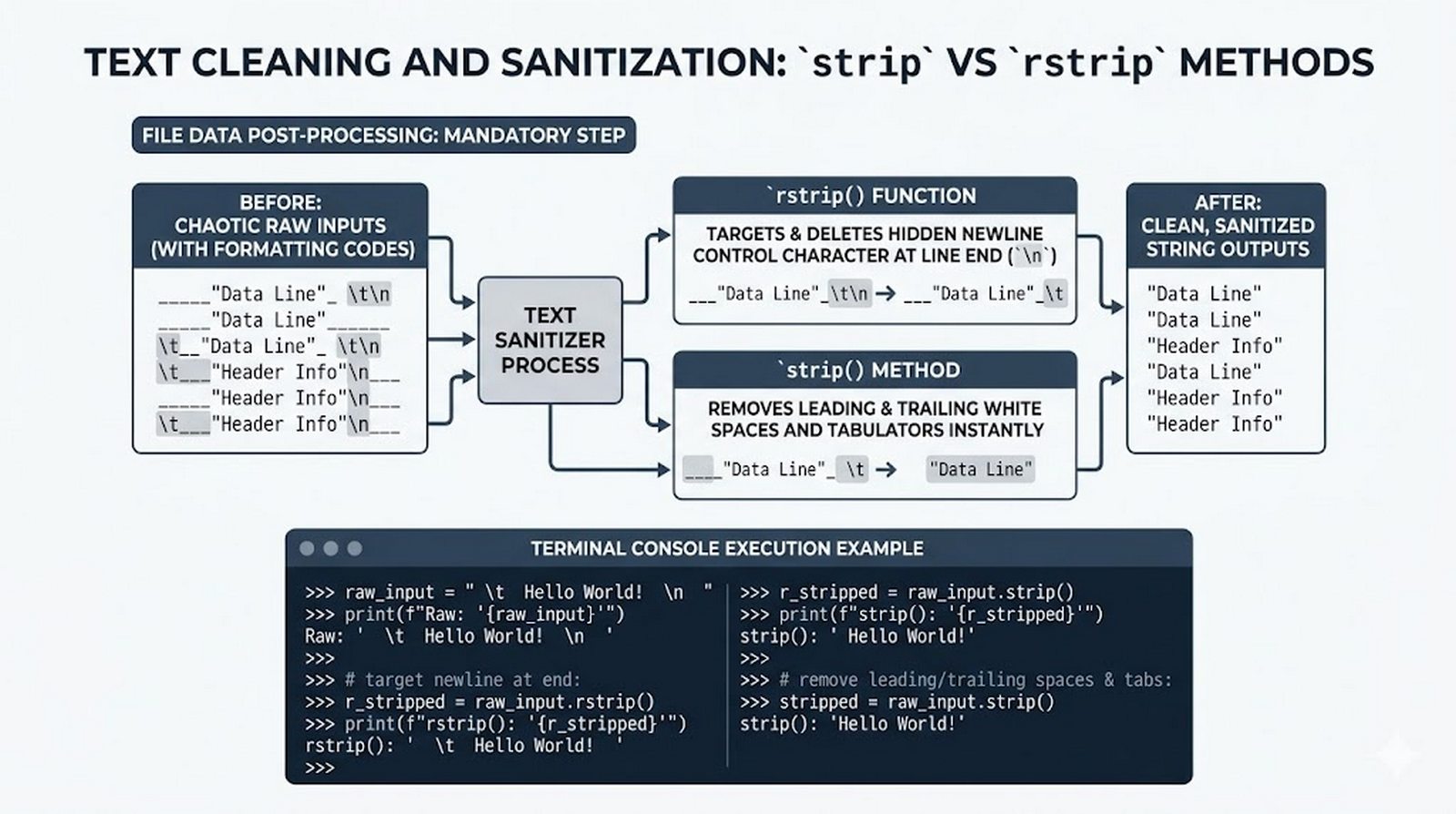
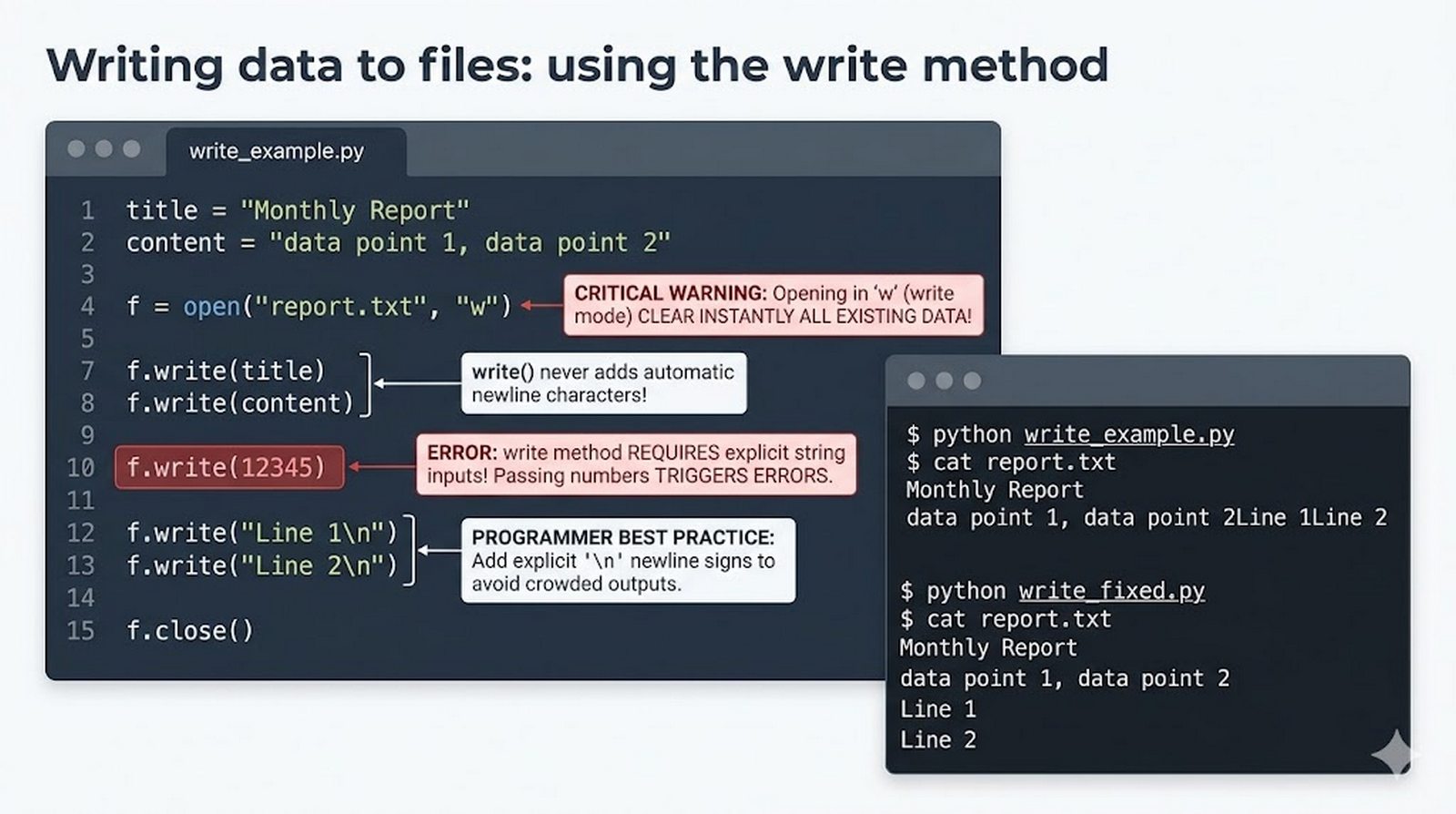
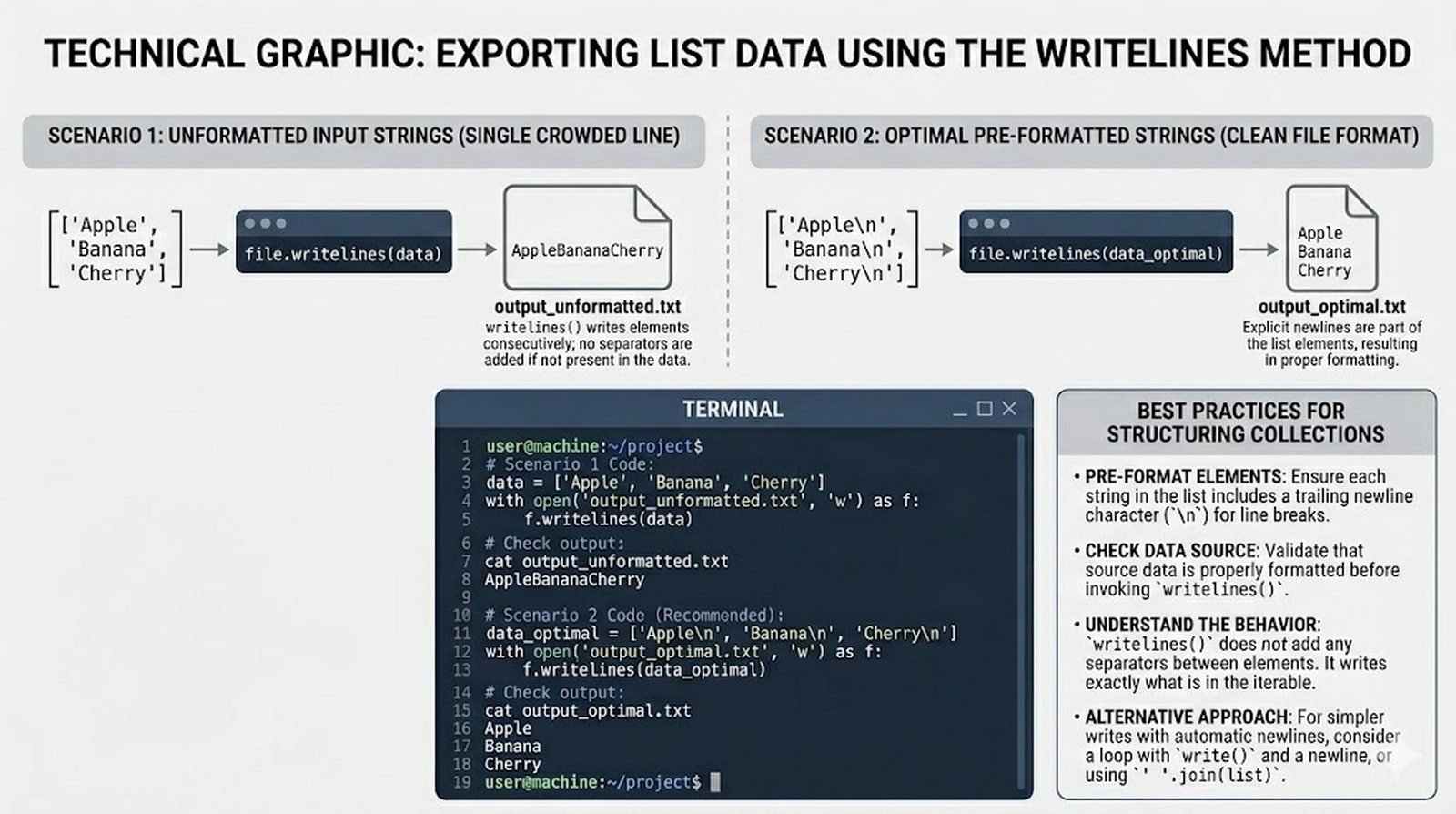
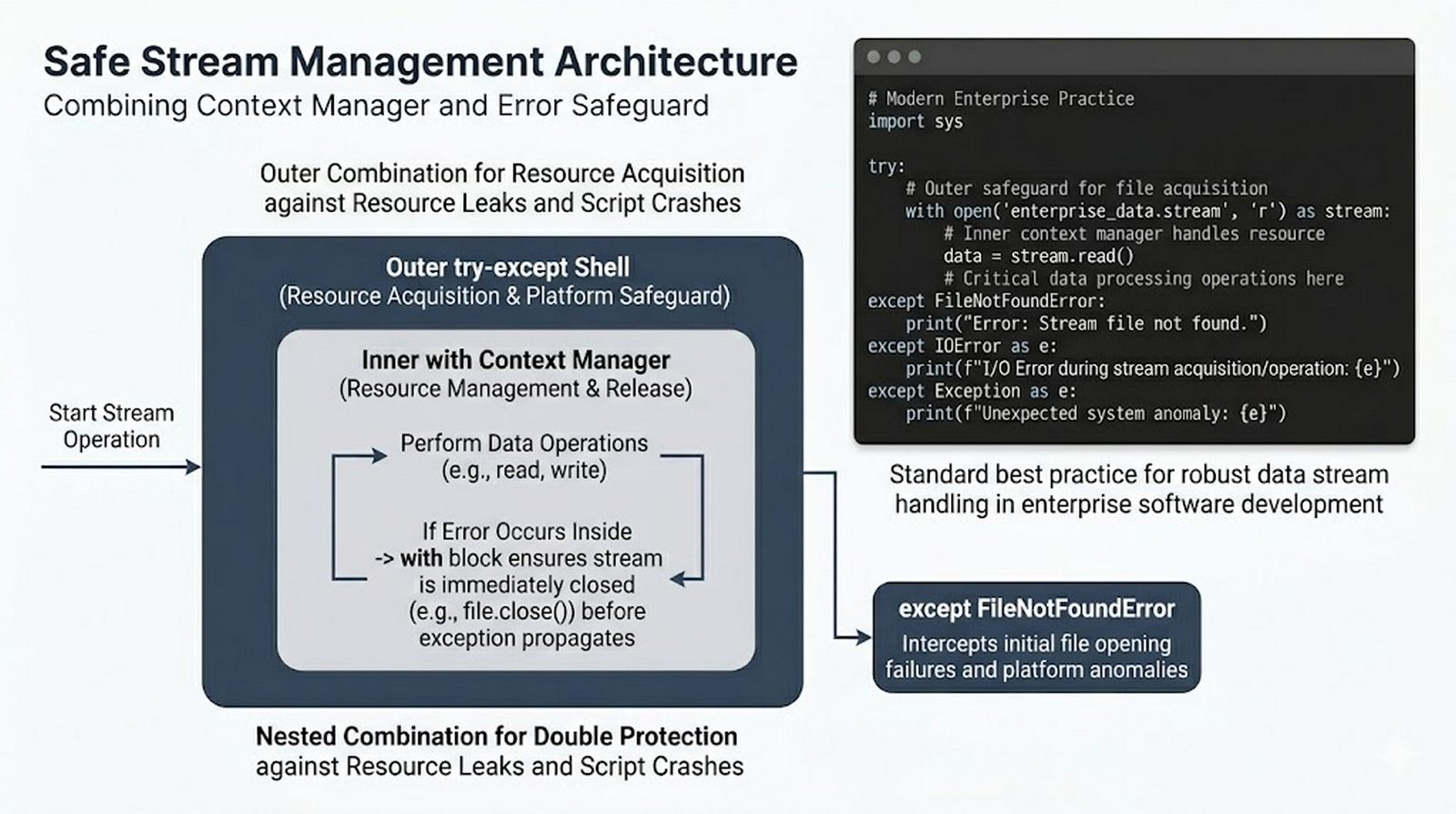
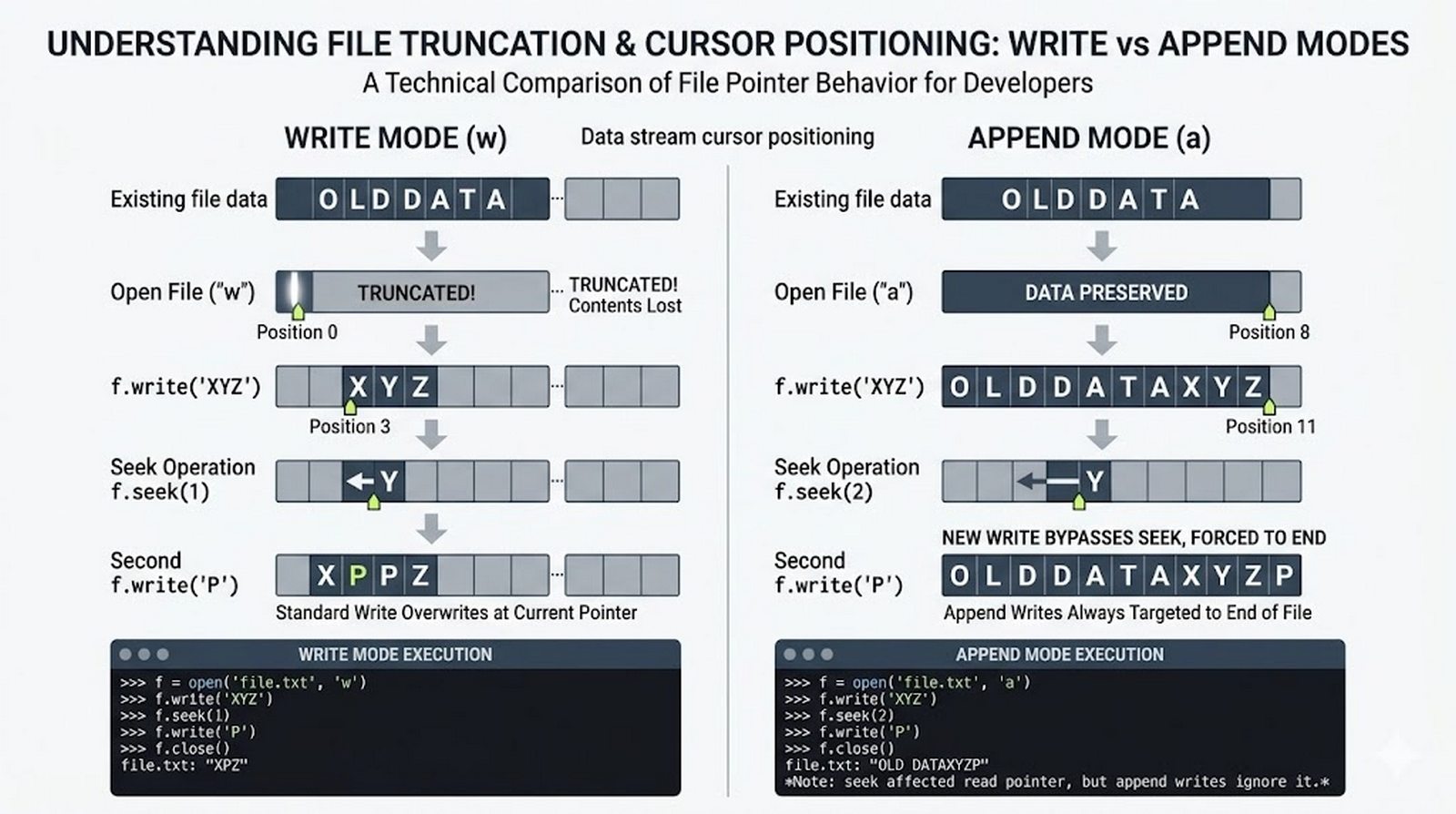
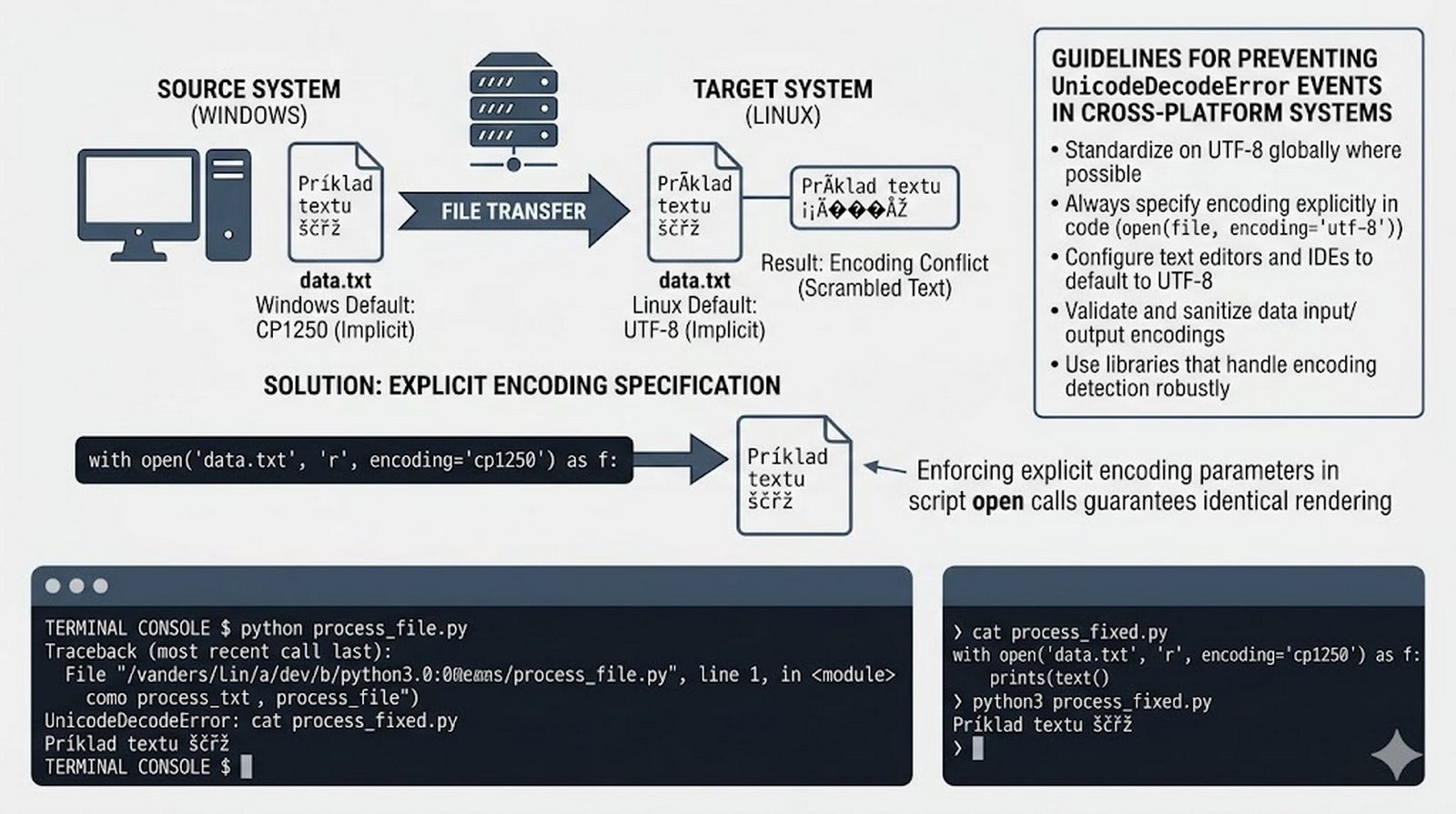
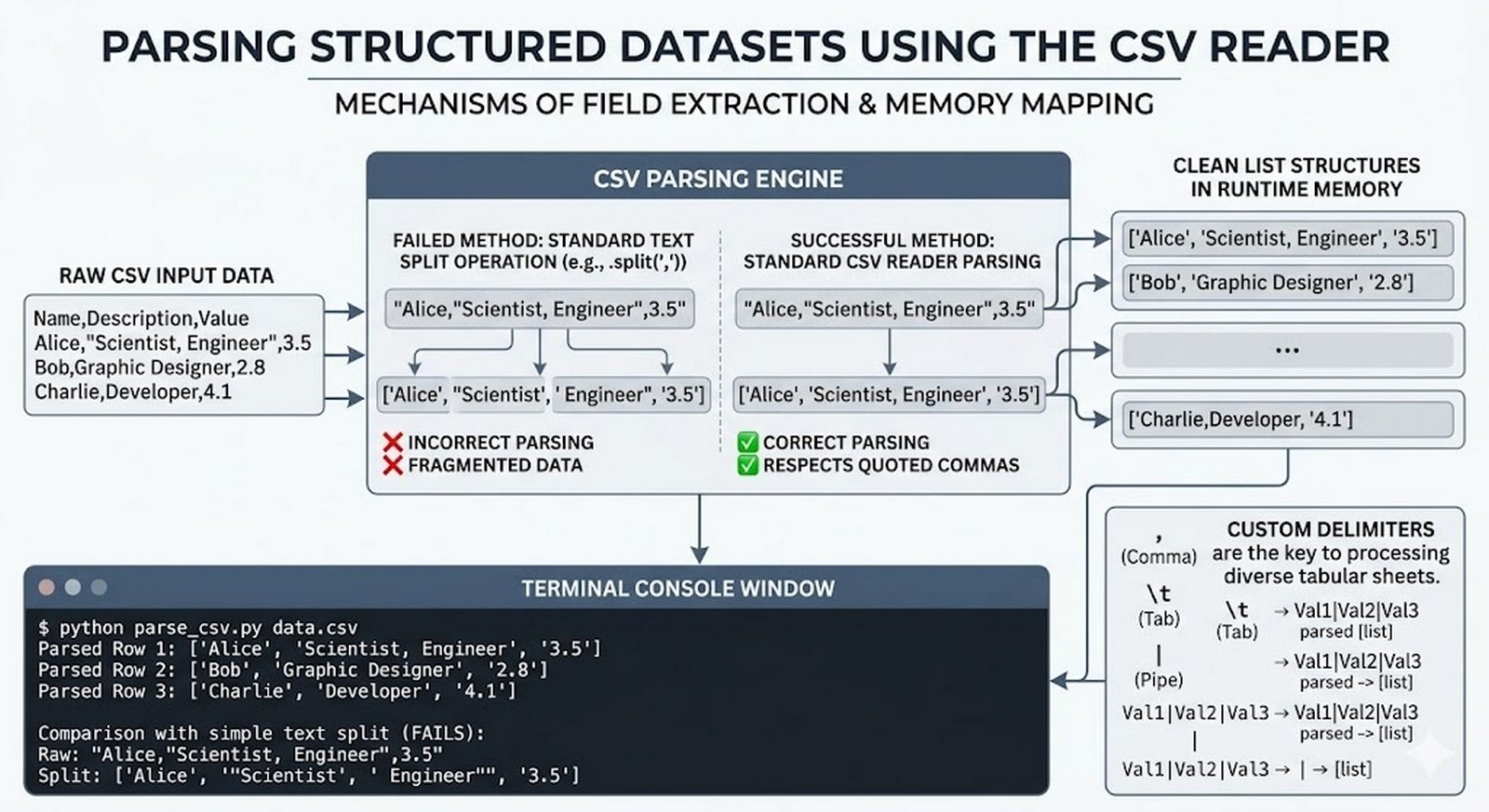
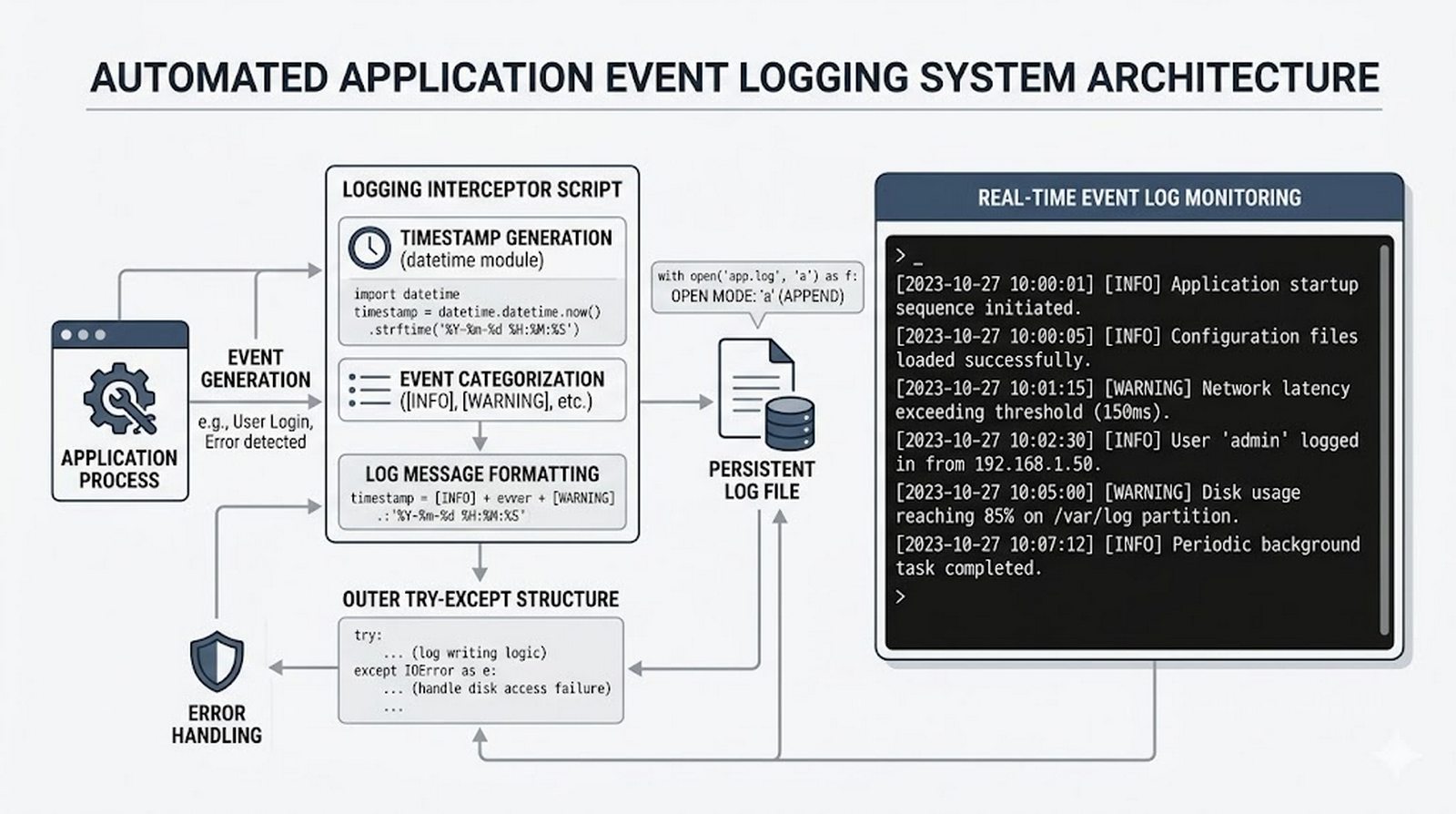
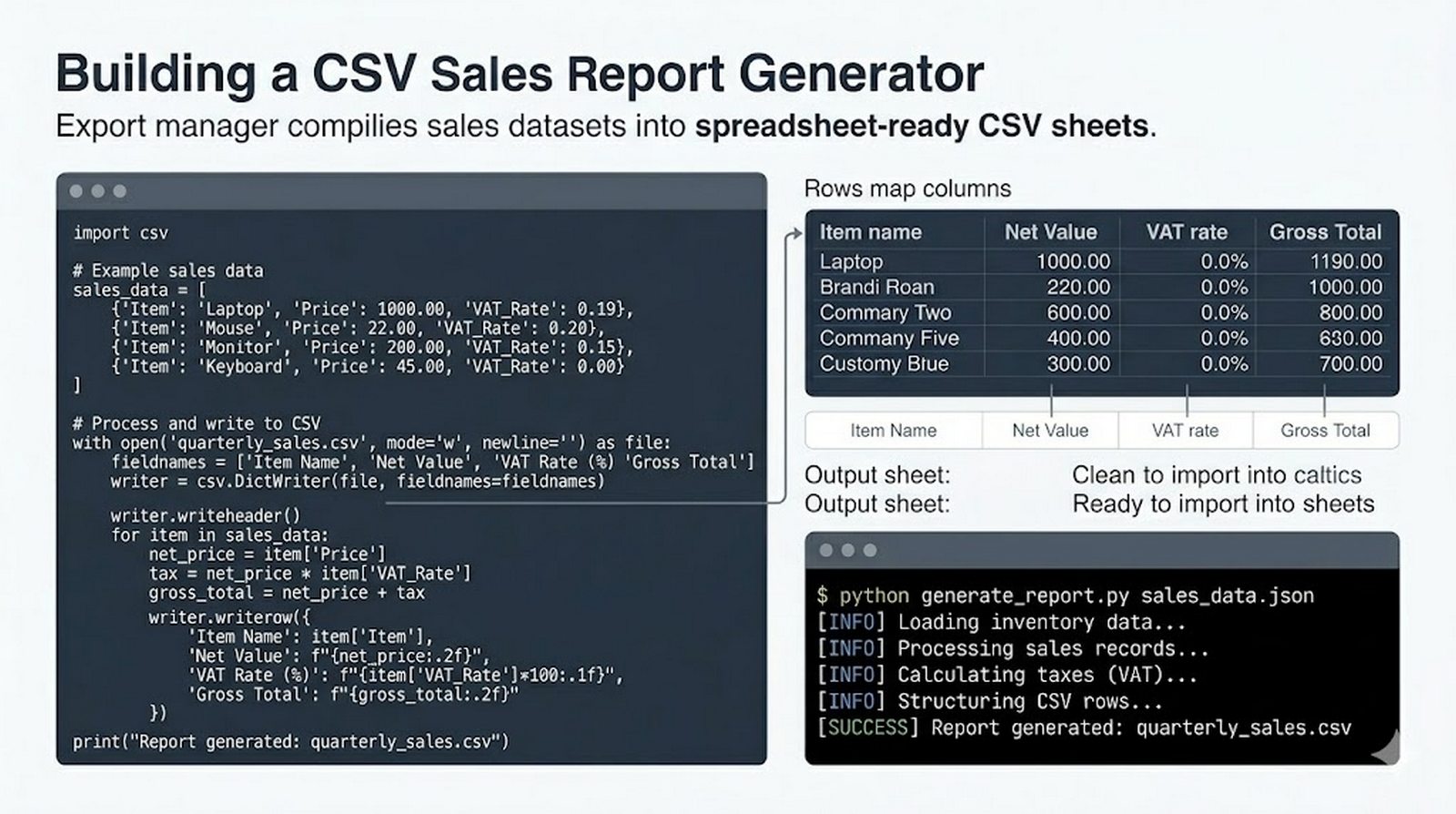
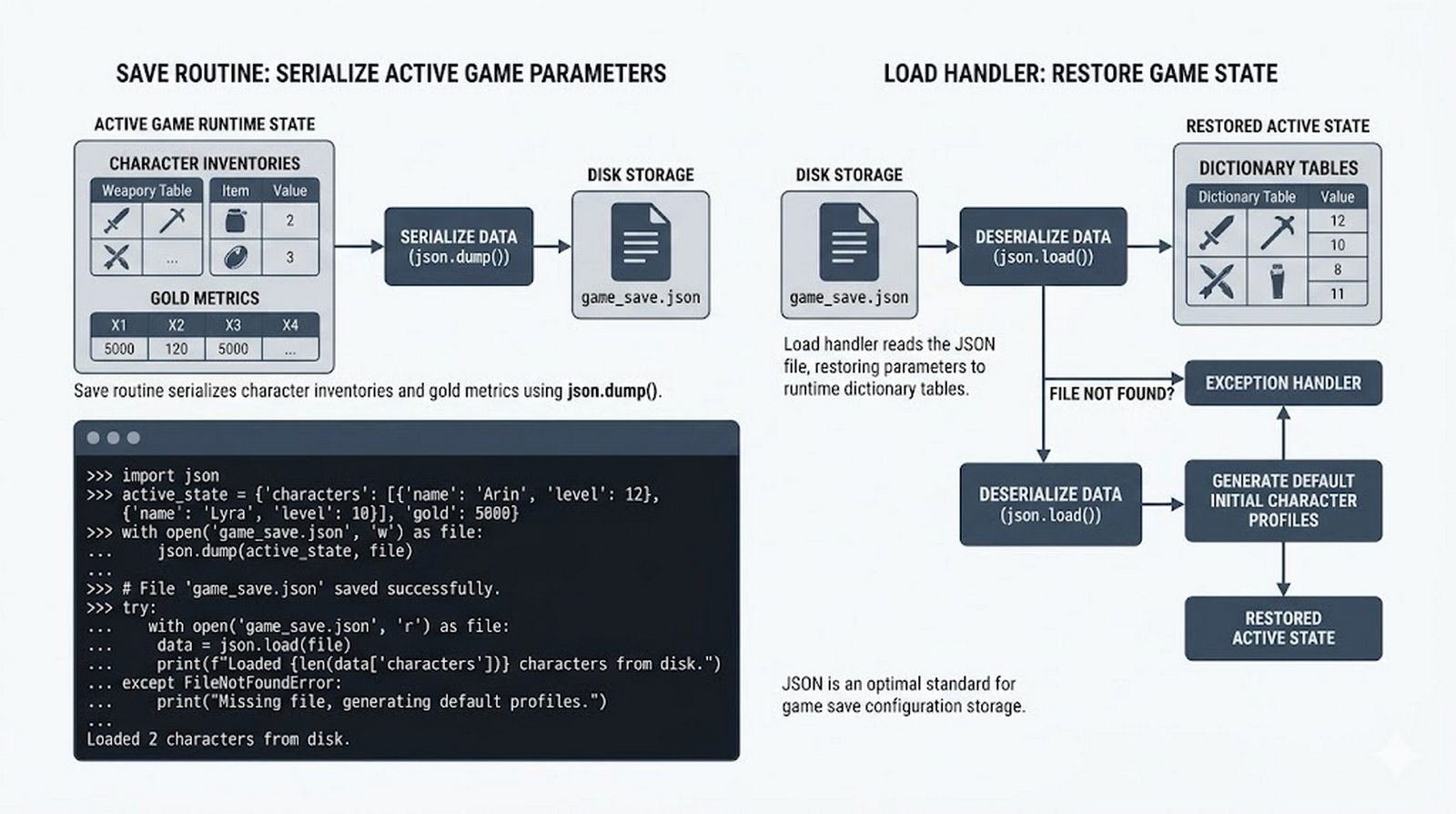
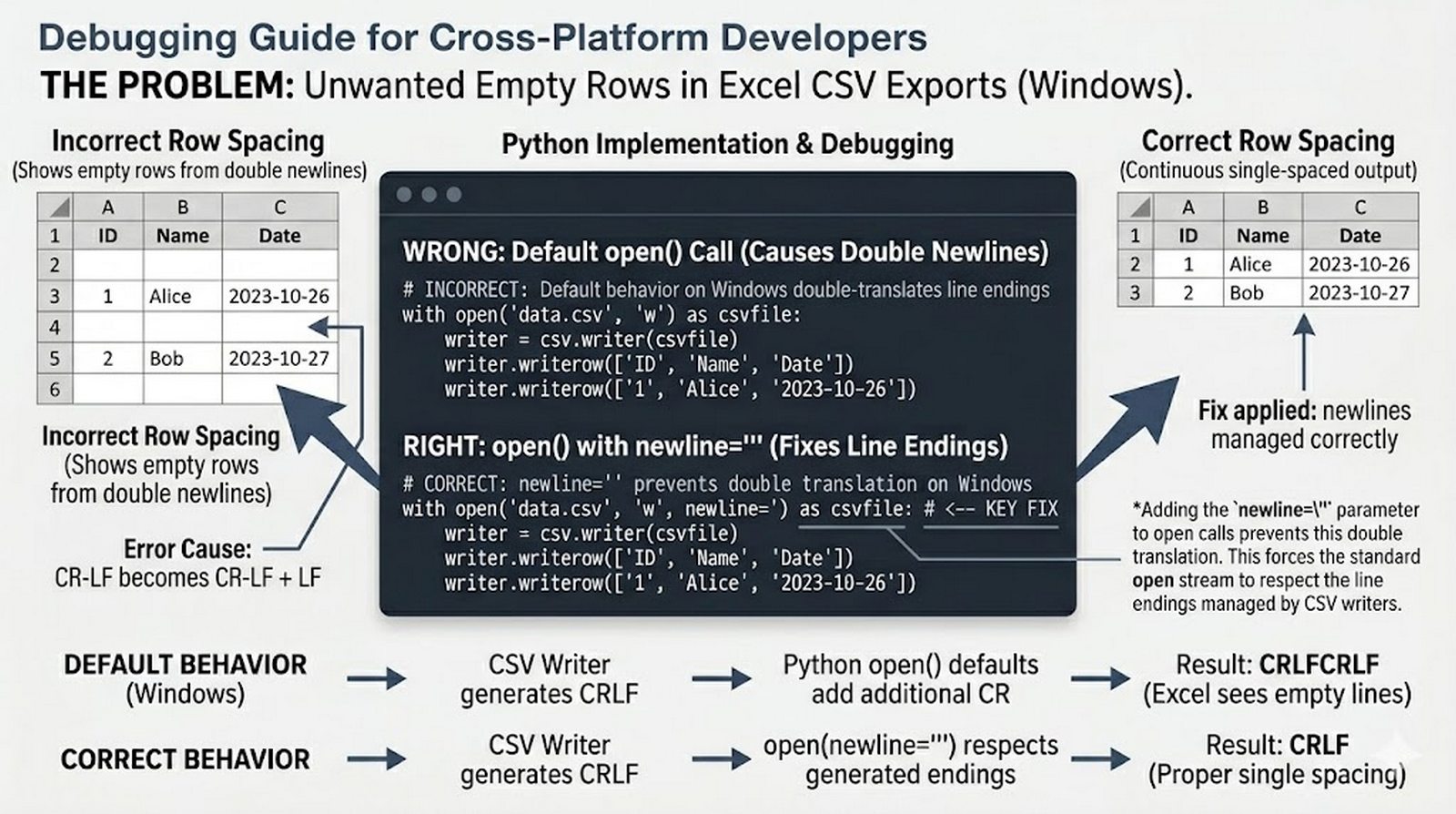
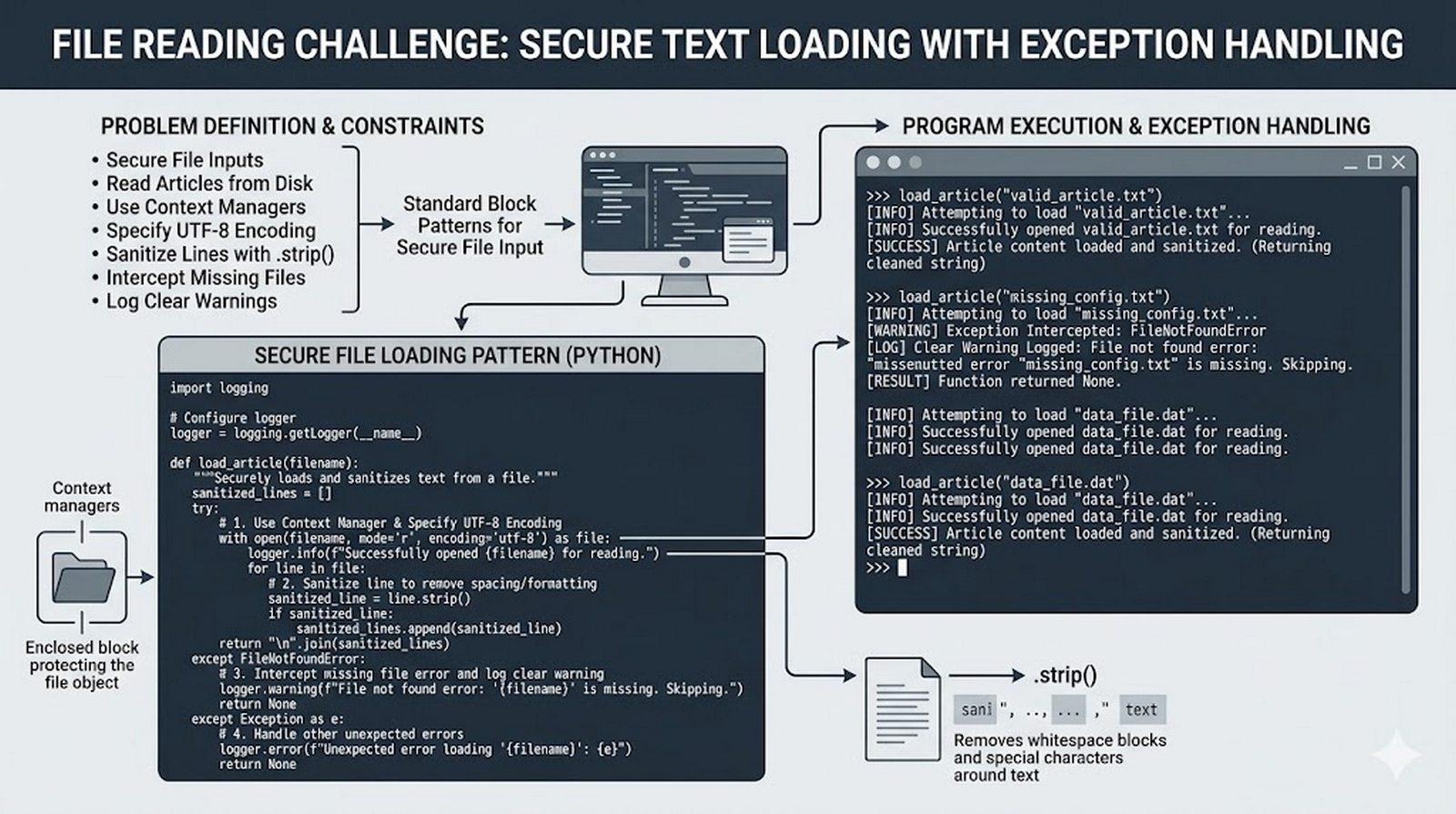
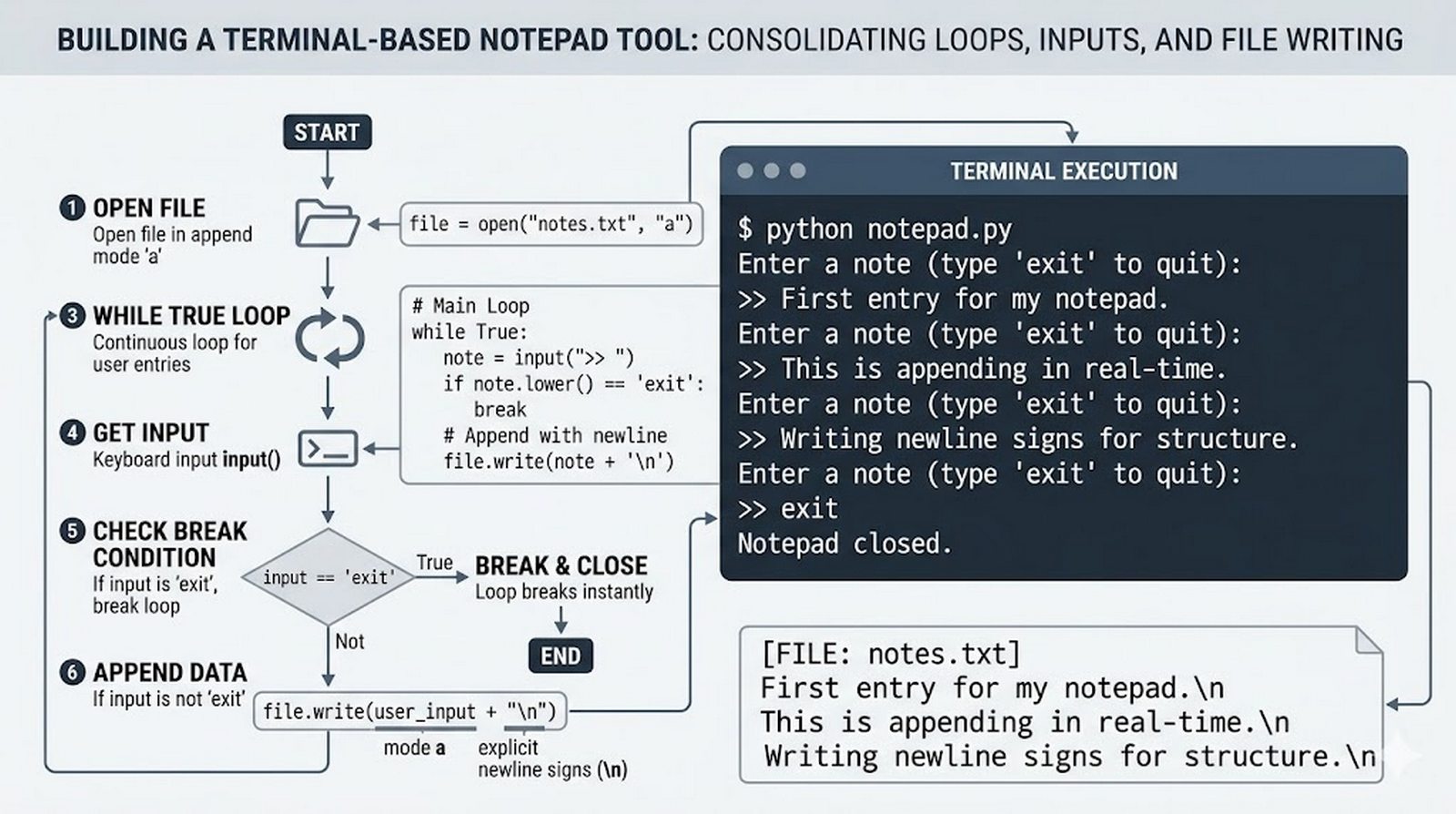
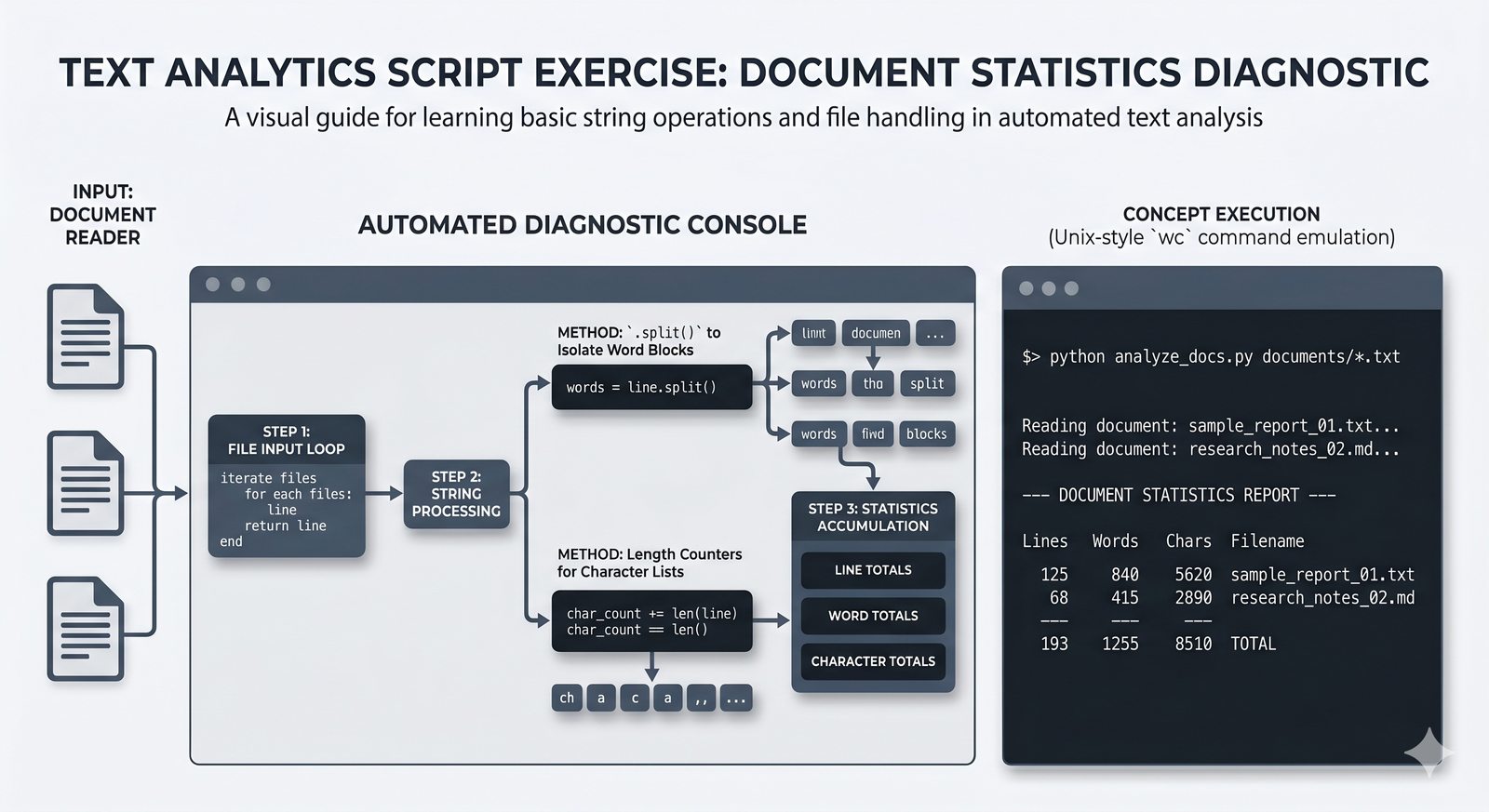
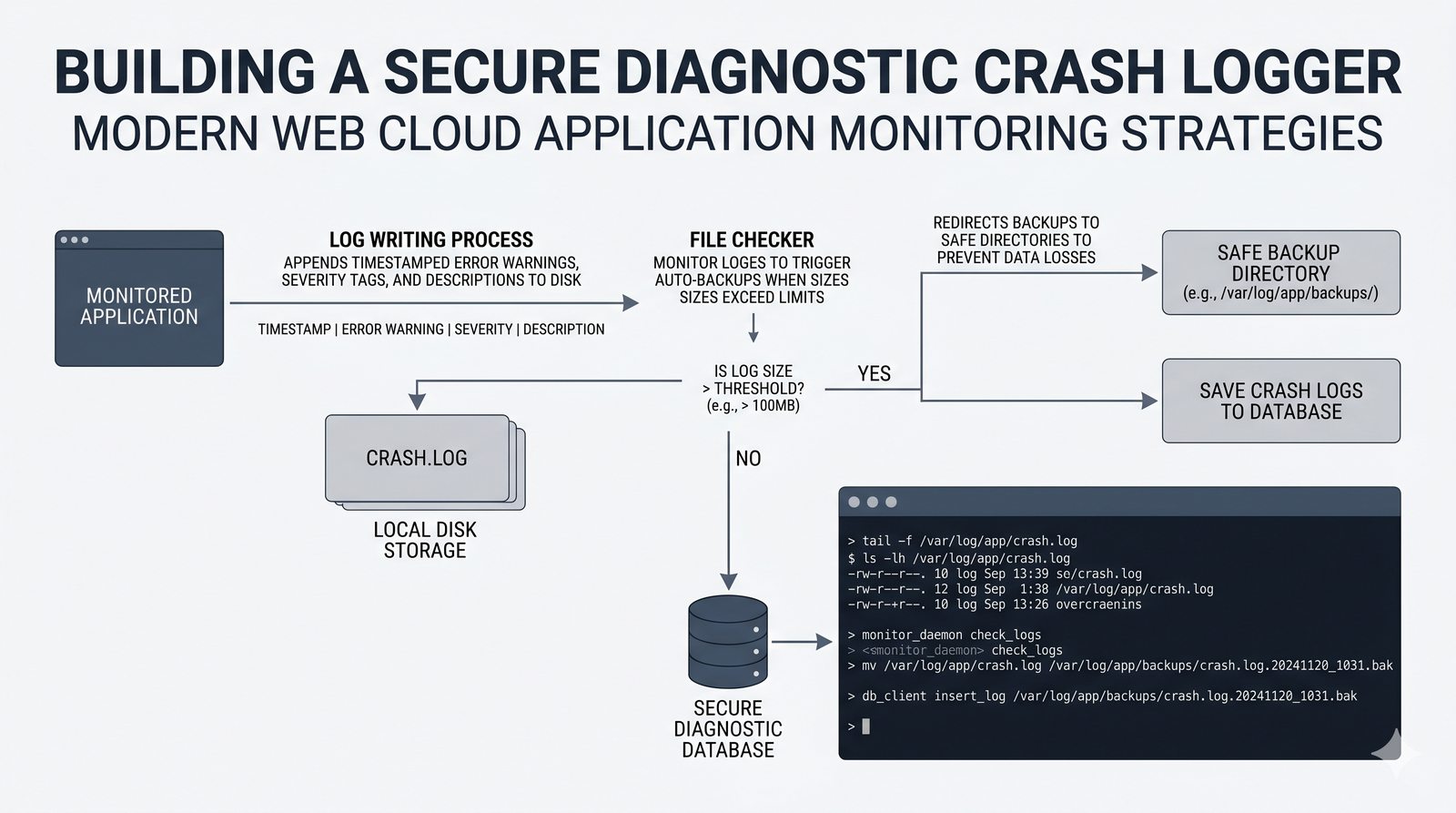
Ten moduł w całości poświęcony jest operacjom na plikach w języku Python -- od otwierania i zamykania plików za pomocą funkcji open() oraz menedżera kontekstu with, przez różne tryby dostępu (odczyt, zapis, dopisywanie, tryb wyłączny), aż po szczegółowe metody czytania (read, readline, readlines, iteracja) i zapisu danych (write, writelines, print). Omówione zostały kluczowe zagadnienia, takie jak ścieżki względne i bezwzględne, kodowanie znaków UTF-8, zarządzanie wskaźnikiem pozycji (tell/seek) oraz sprawdzanie istnienia pliku przed otwarciem. Szczególną uwagę poświęcono bezpiecznemu przetwarzaniu plików -- od obsługi błędów wejścia-wyjścia przez tryb wyłącznego tworzenia 'x', aż po wydajne techniki pracy z dużymi plikami tekstowymi. Moduł wprowadza również praktyczną pracę z popularnymi formatami danych CSV i JSON wraz z dedykowanymi modułami csv i json, a także nowoczesnym narzędziem pathlib do zarządzania ścieżkami.
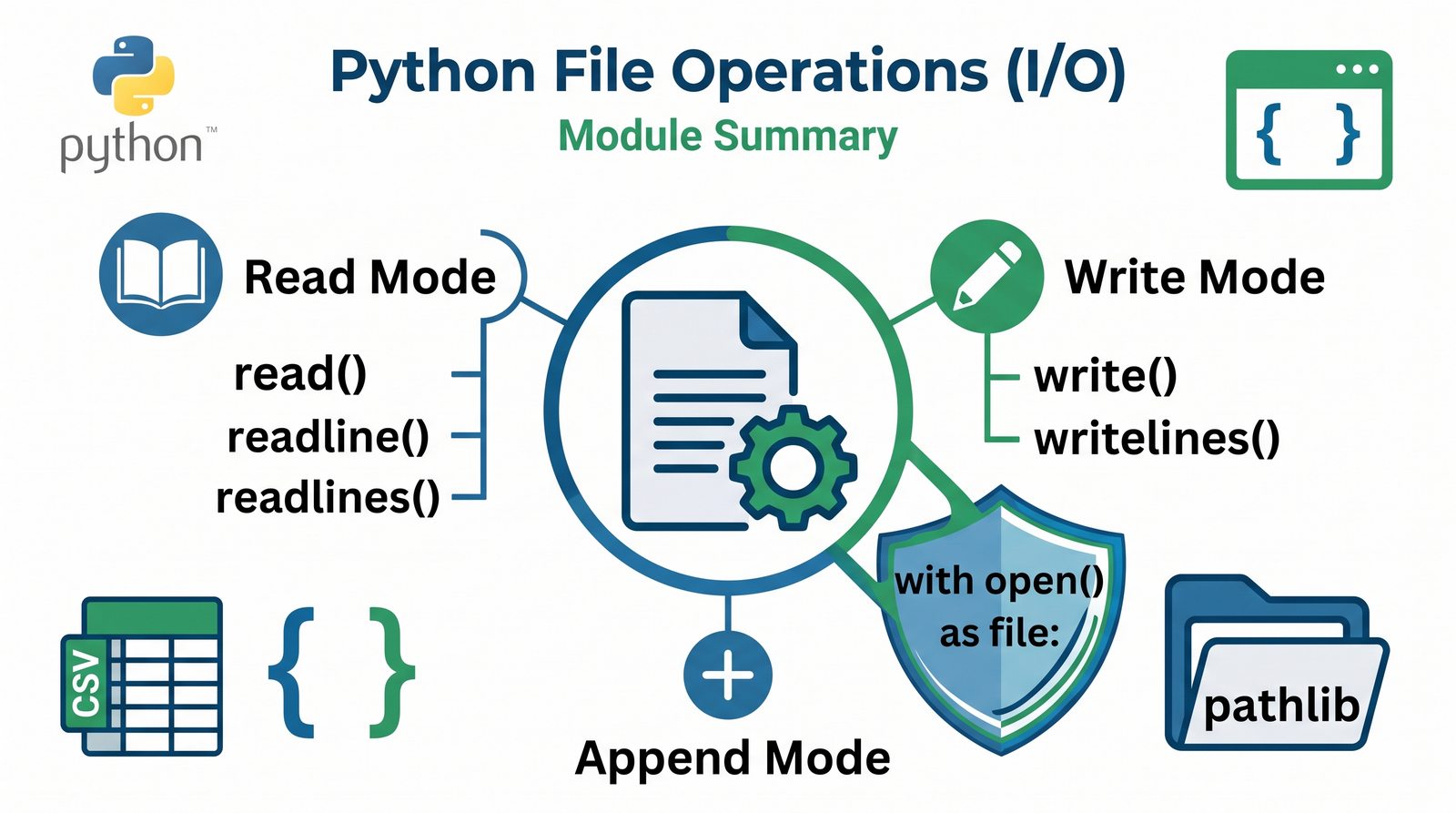
- Otwieranie i zamykanie plików -- funkcja
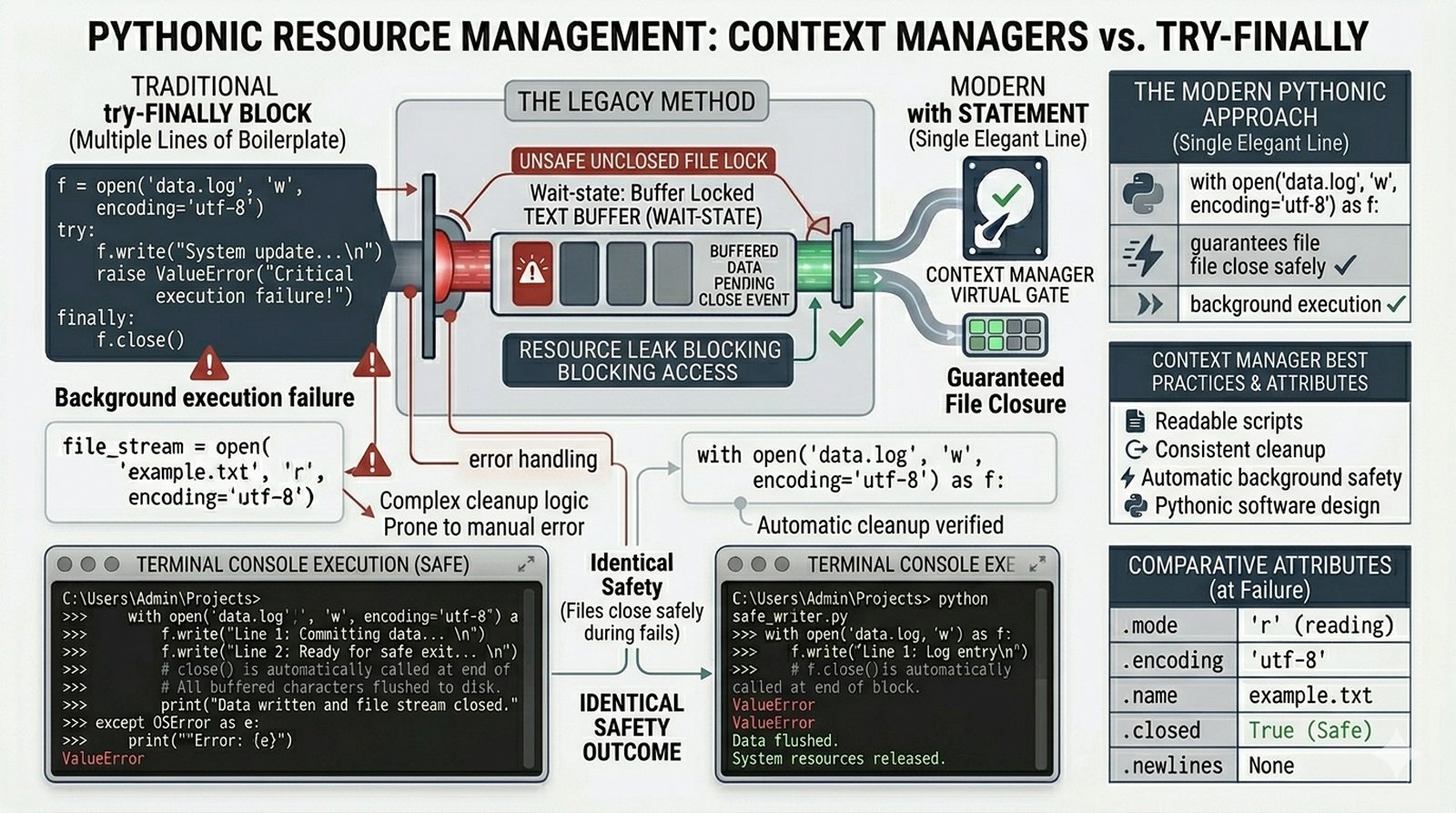
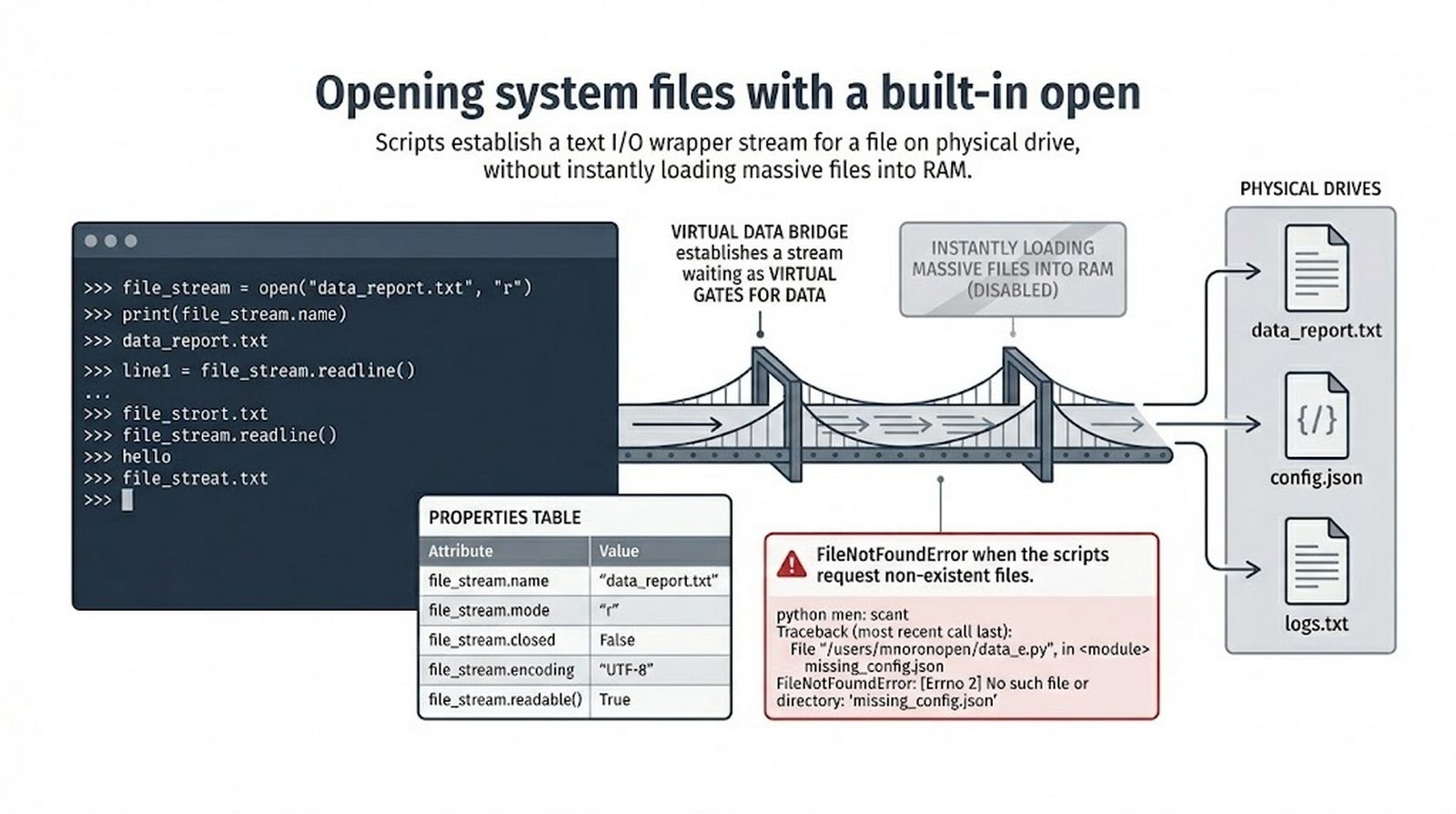
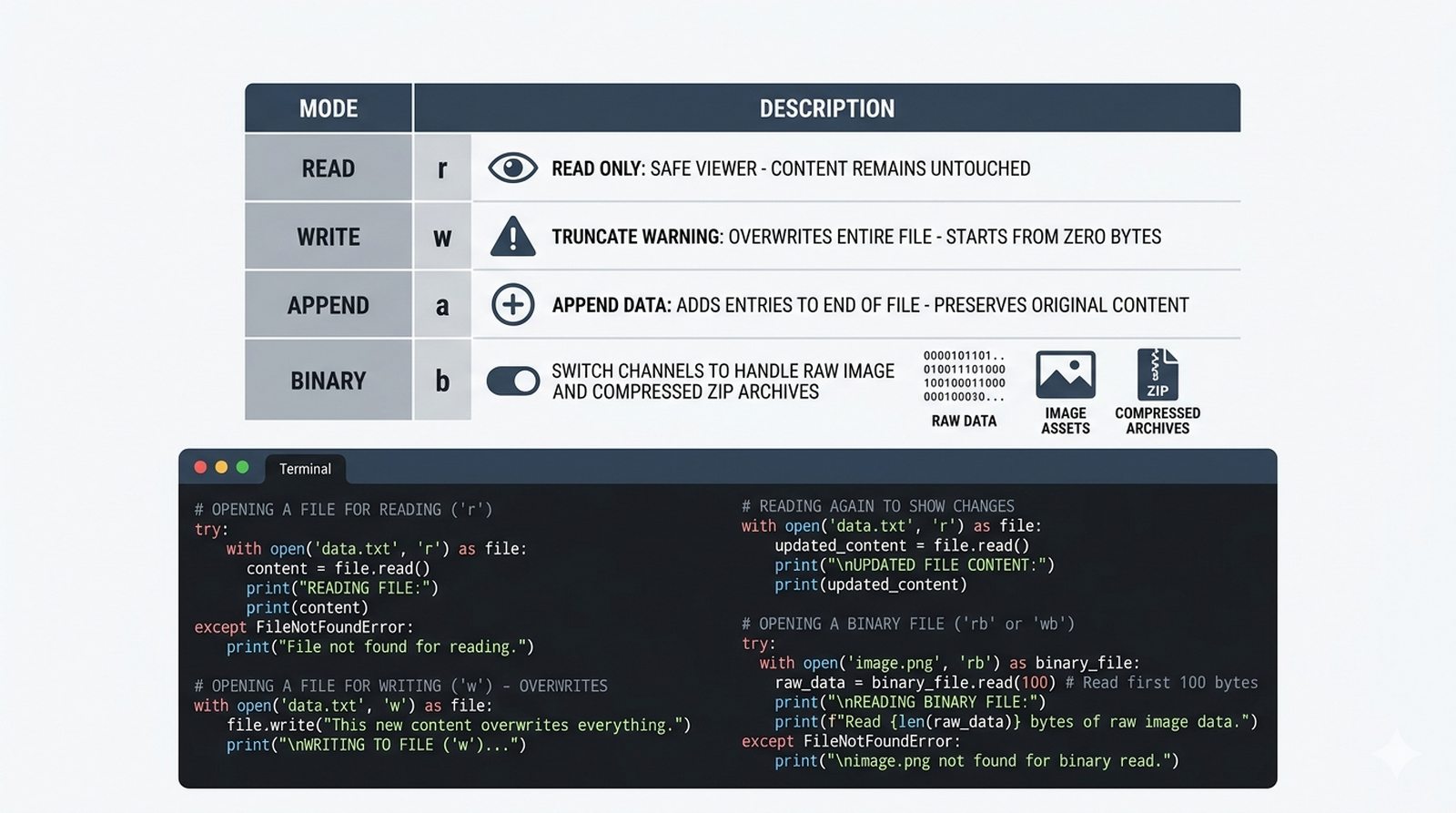
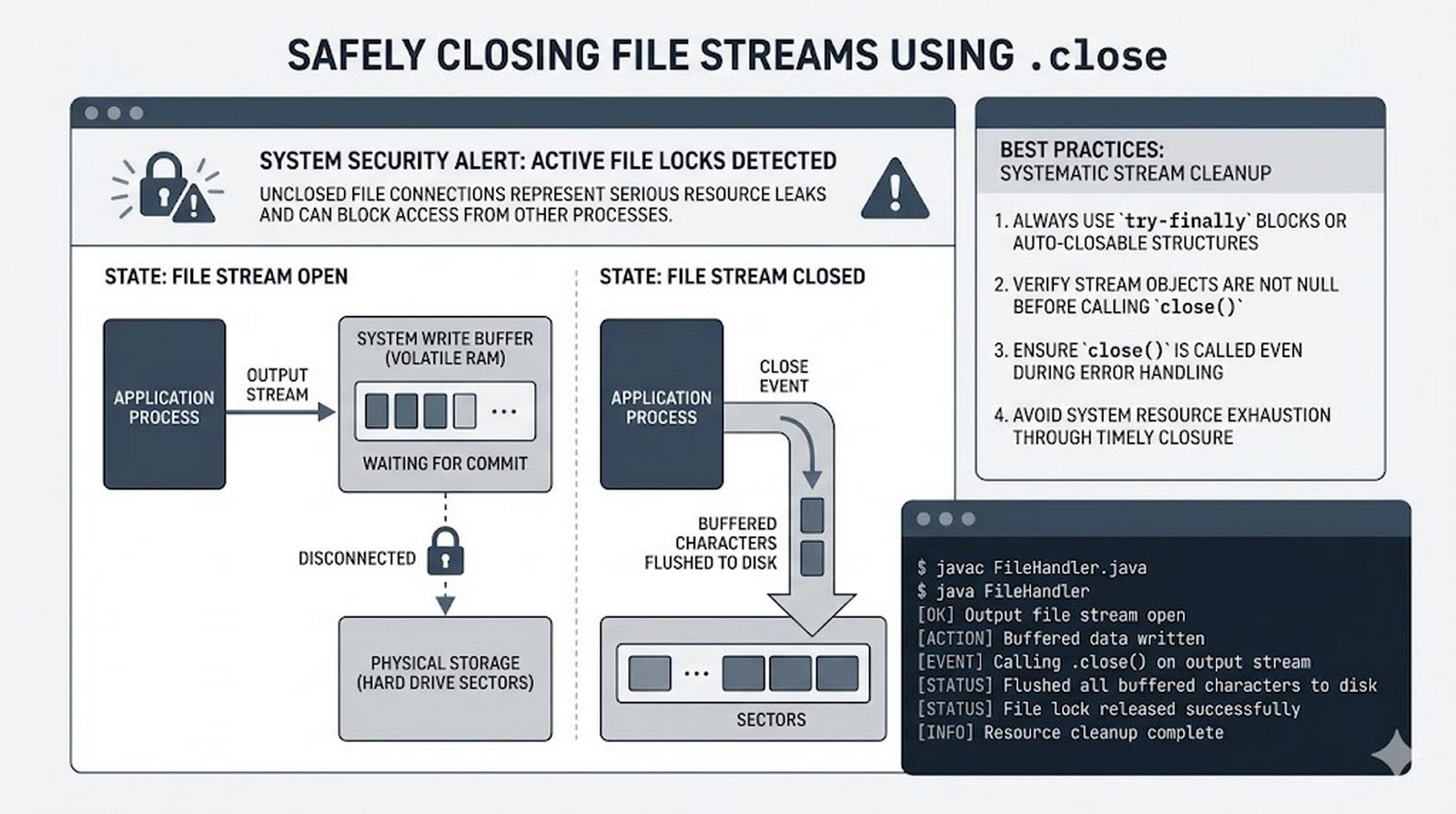
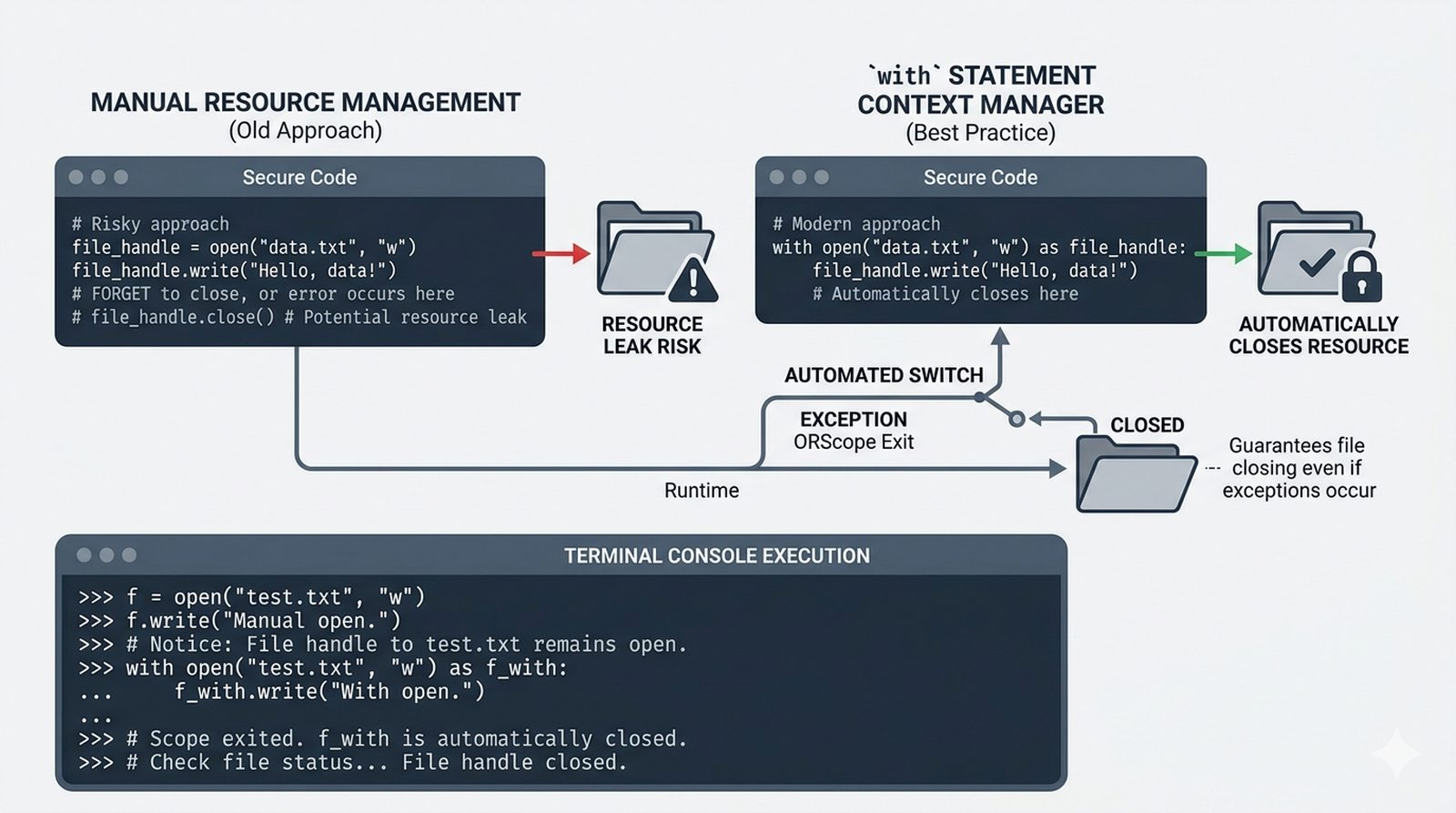
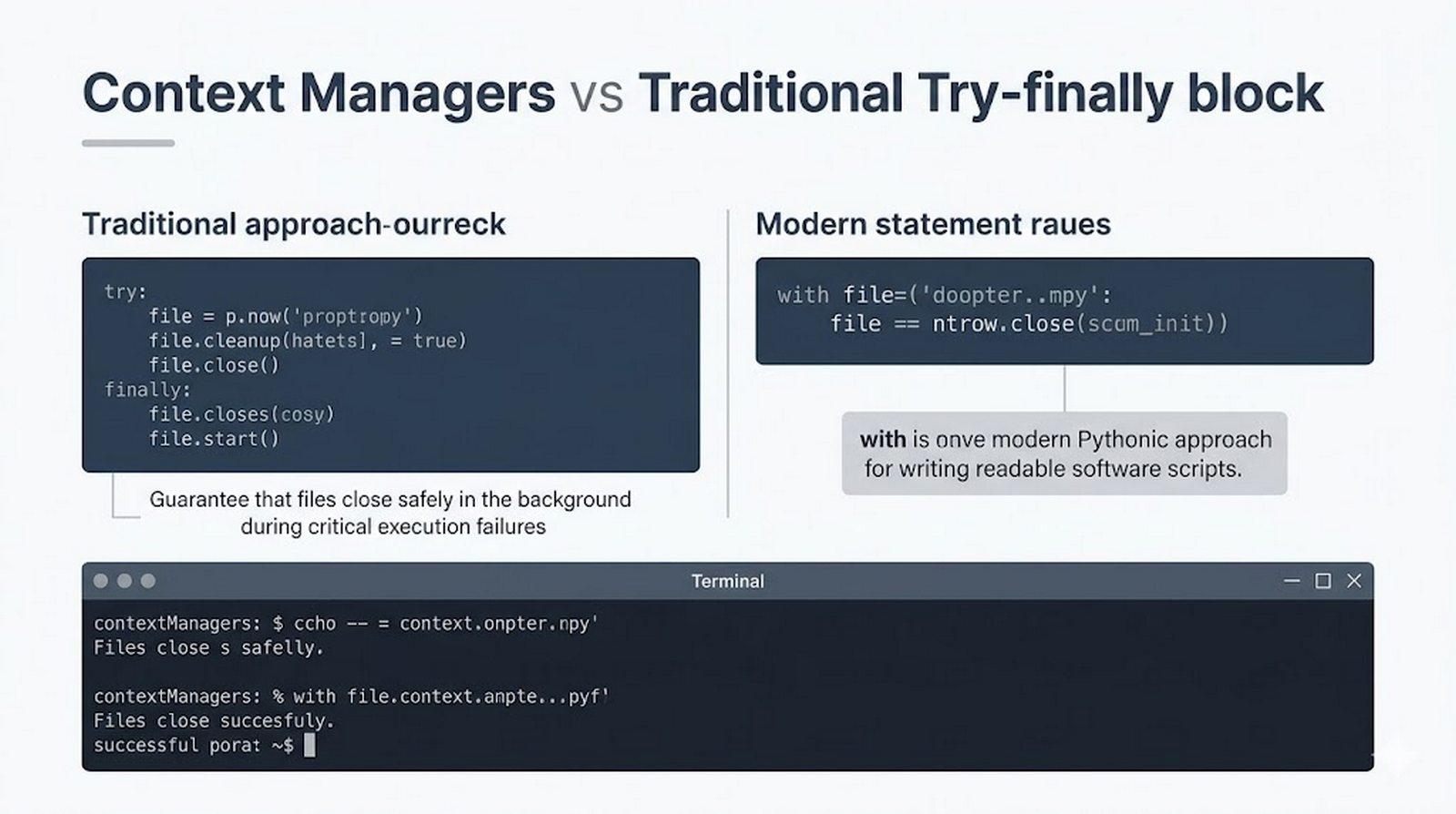
open(), tryby dostępu (r,w,a,x), menedżer kontekstuwithvs tradycyjneclose() - Metody odczytu danych --
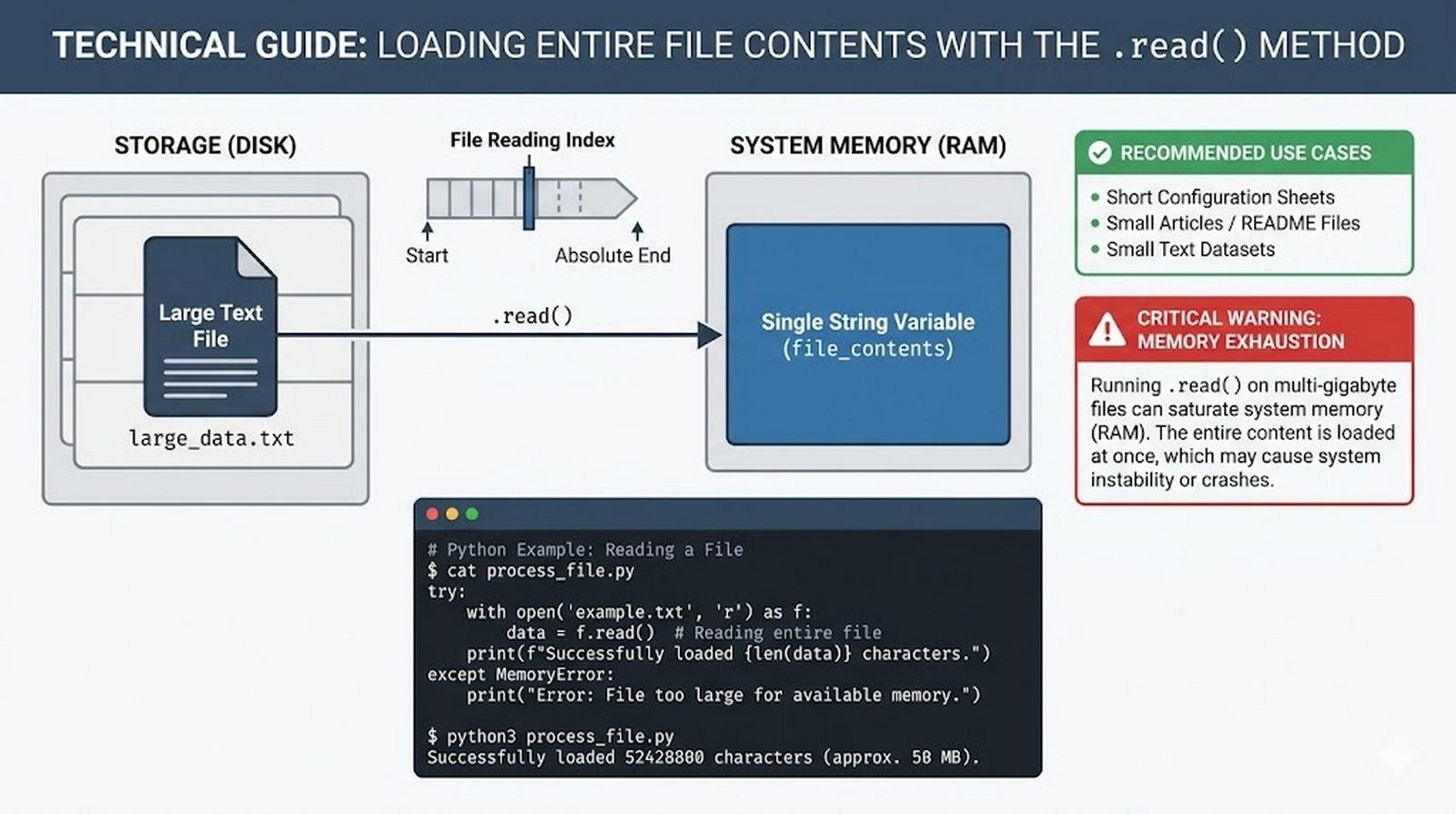
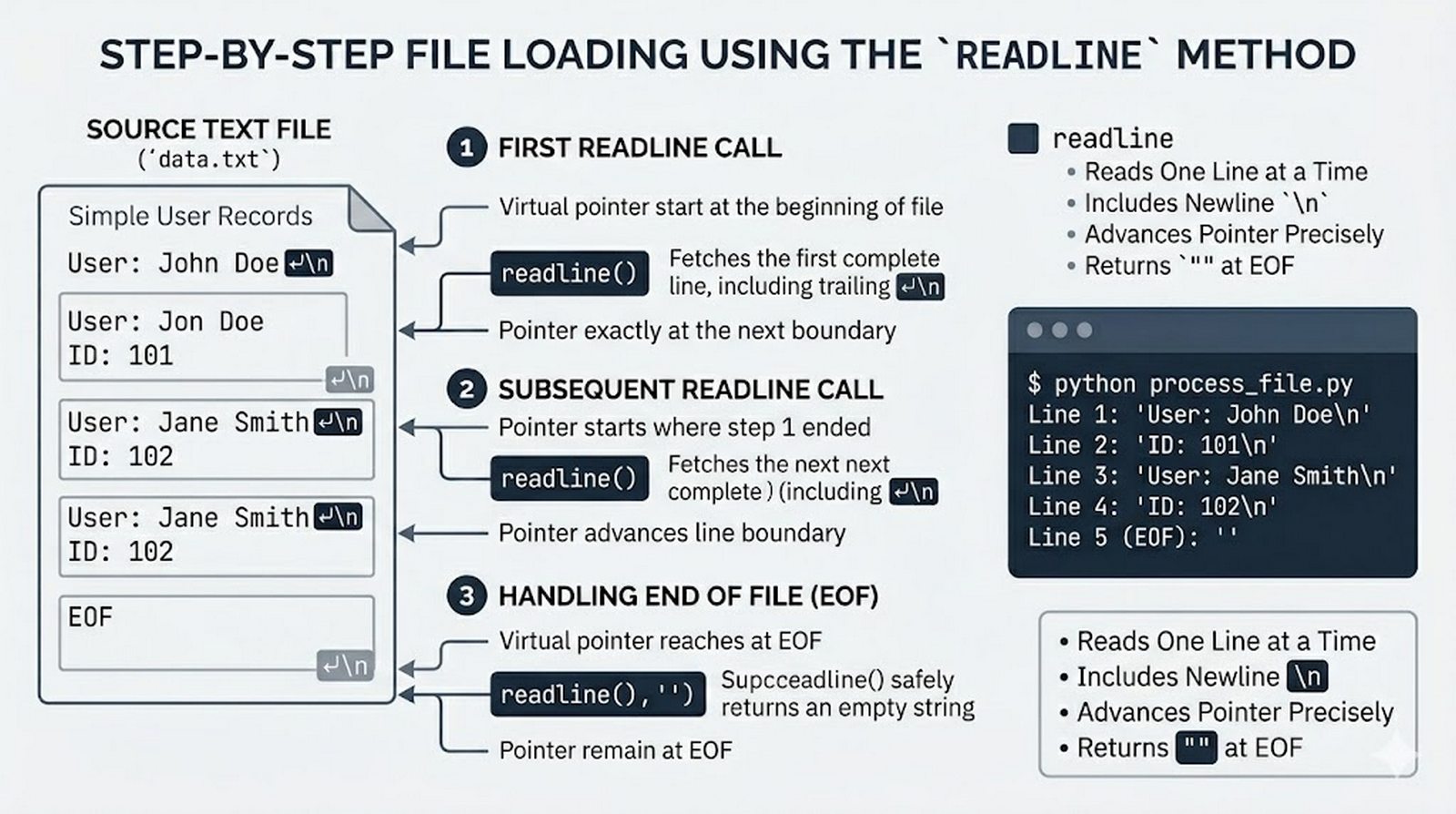
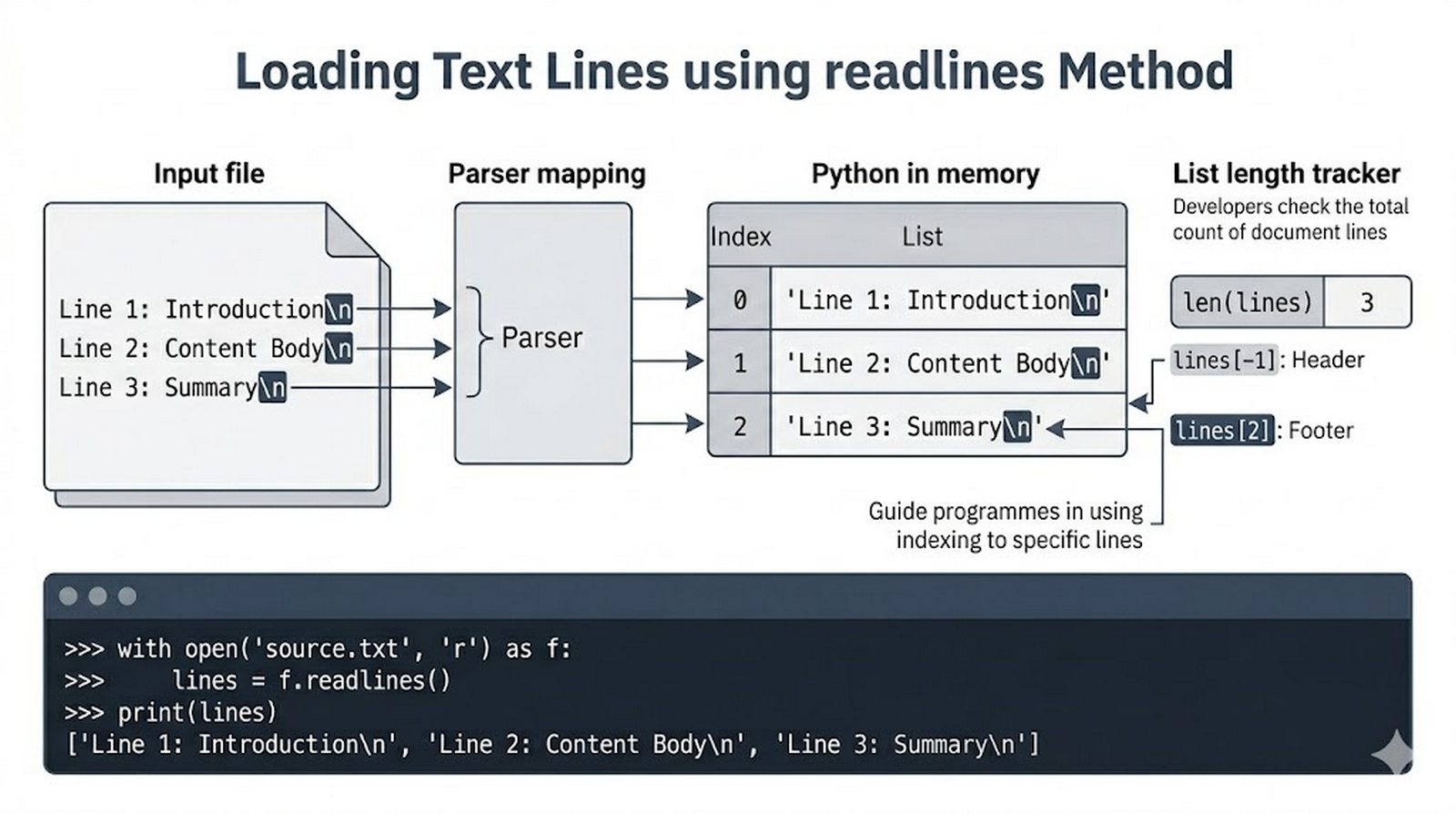
read(),readline(),readlines(), iteracja po obiekcie pliku, usuwanie znaków nowej liniistrip() - Zapis danych do pliku --
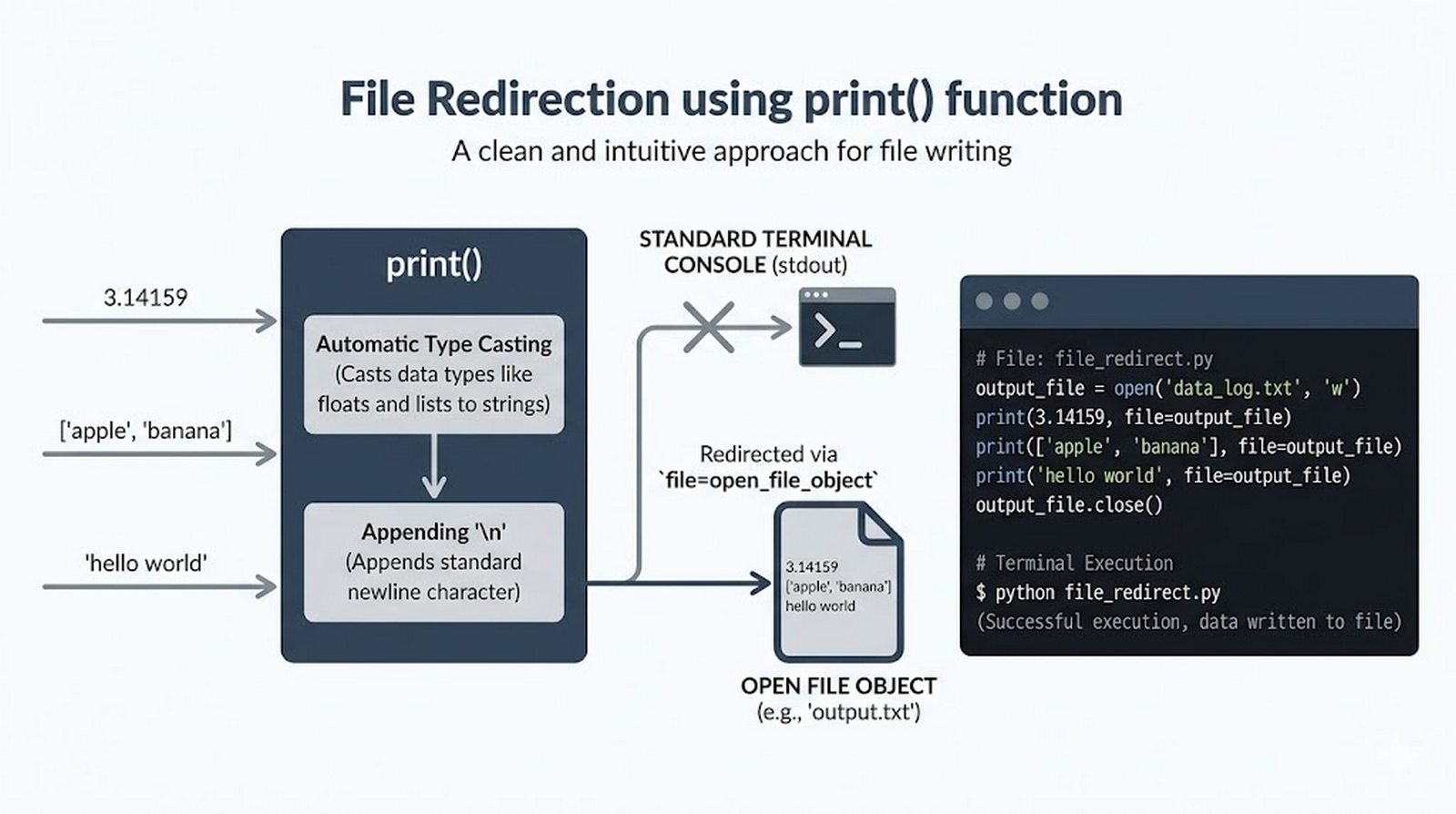
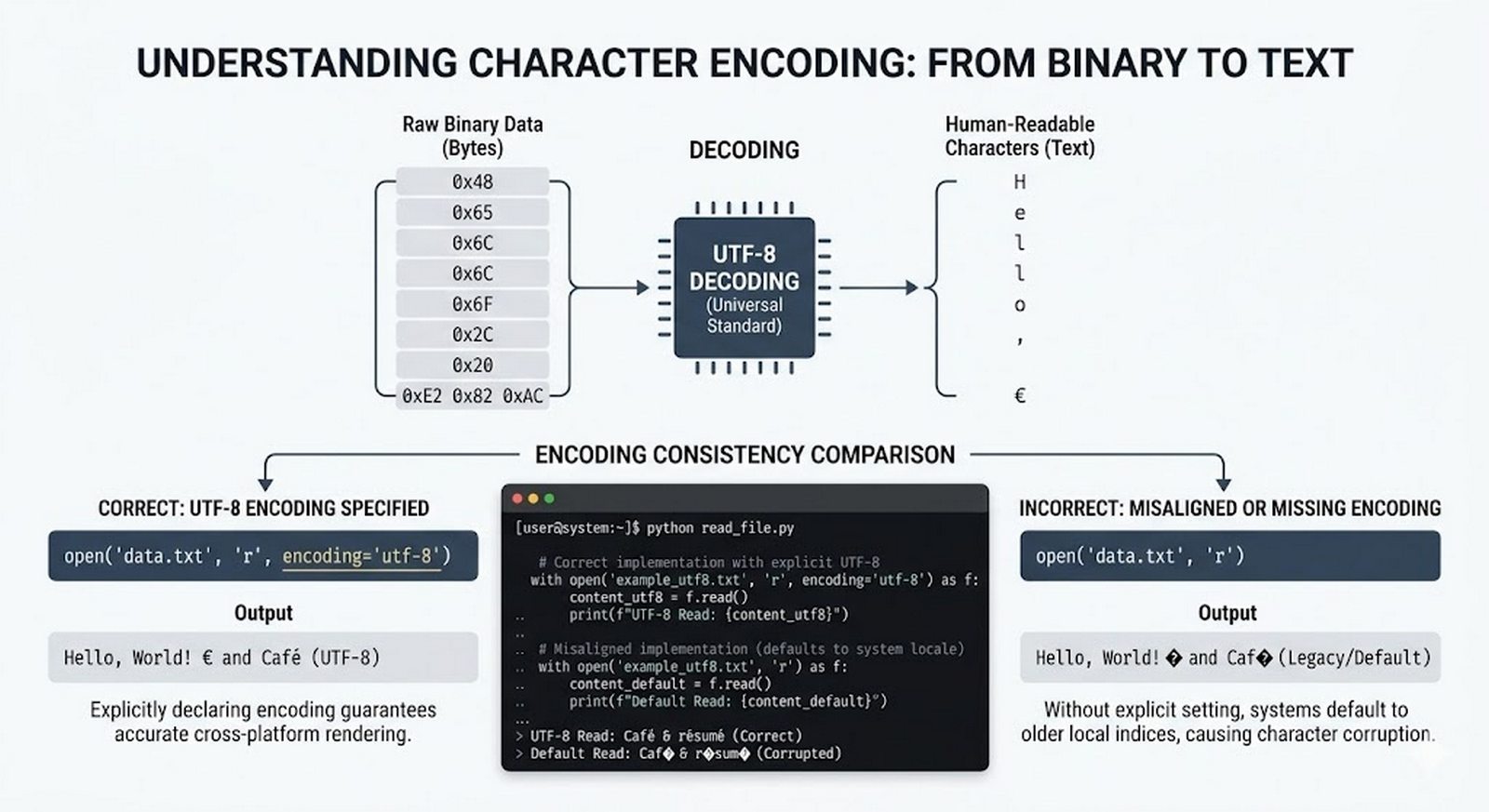
write(),writelines(), przekierowanieprint()z parametremfile, tryb dopisywania'a' - Zaawansowane techniki -- kodowanie UTF-8, zarządzanie wskaźnikiem
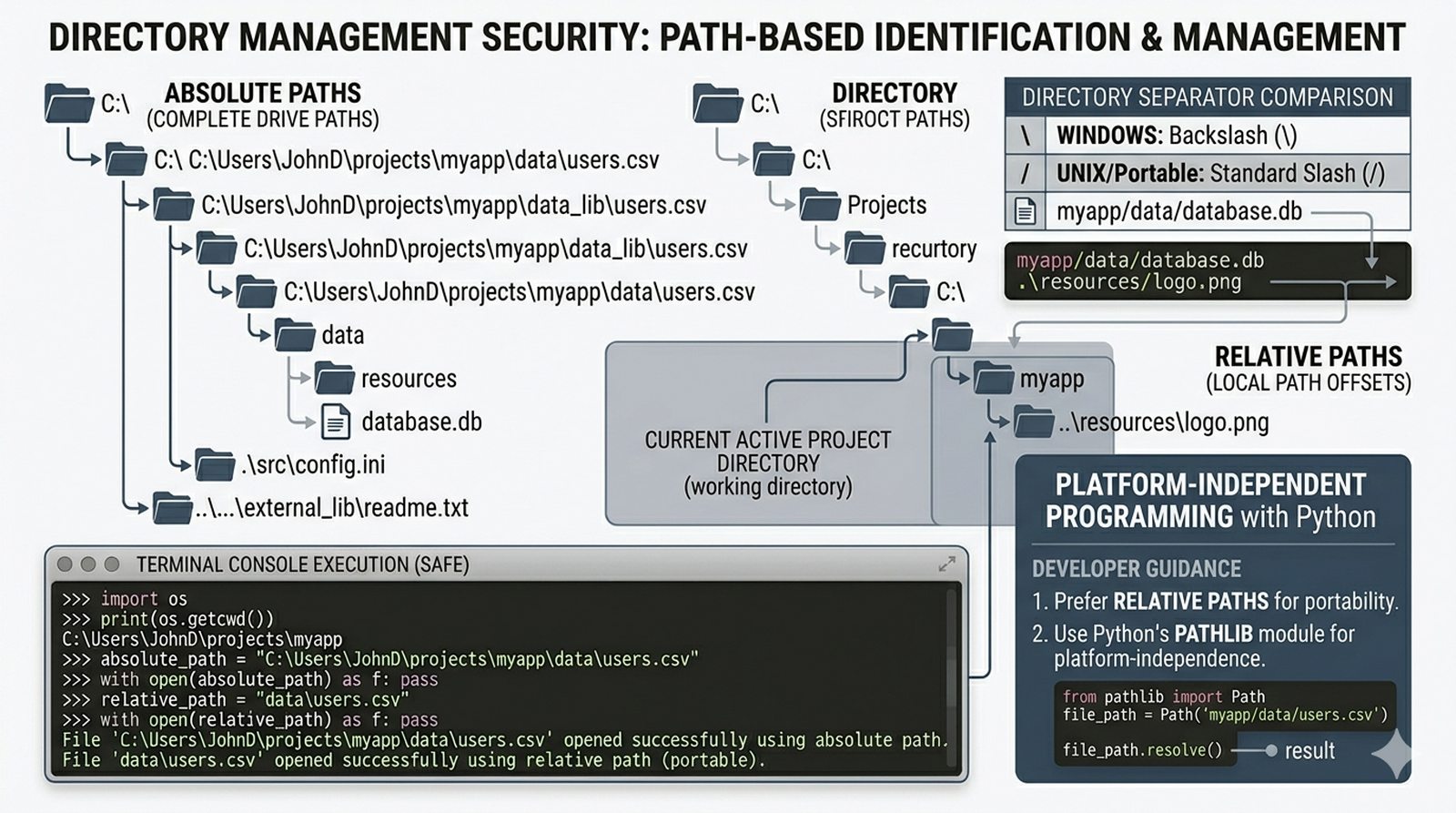
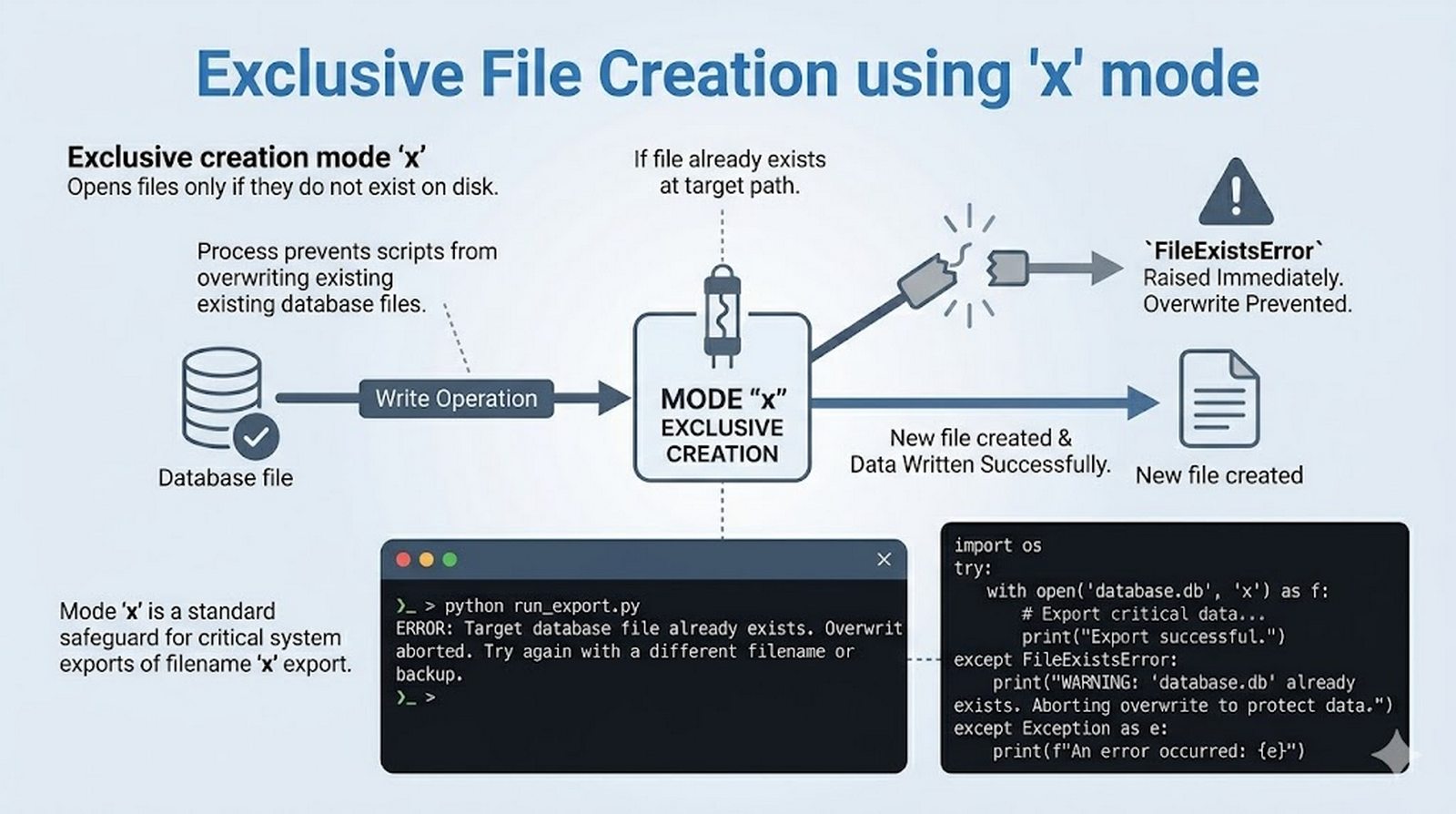
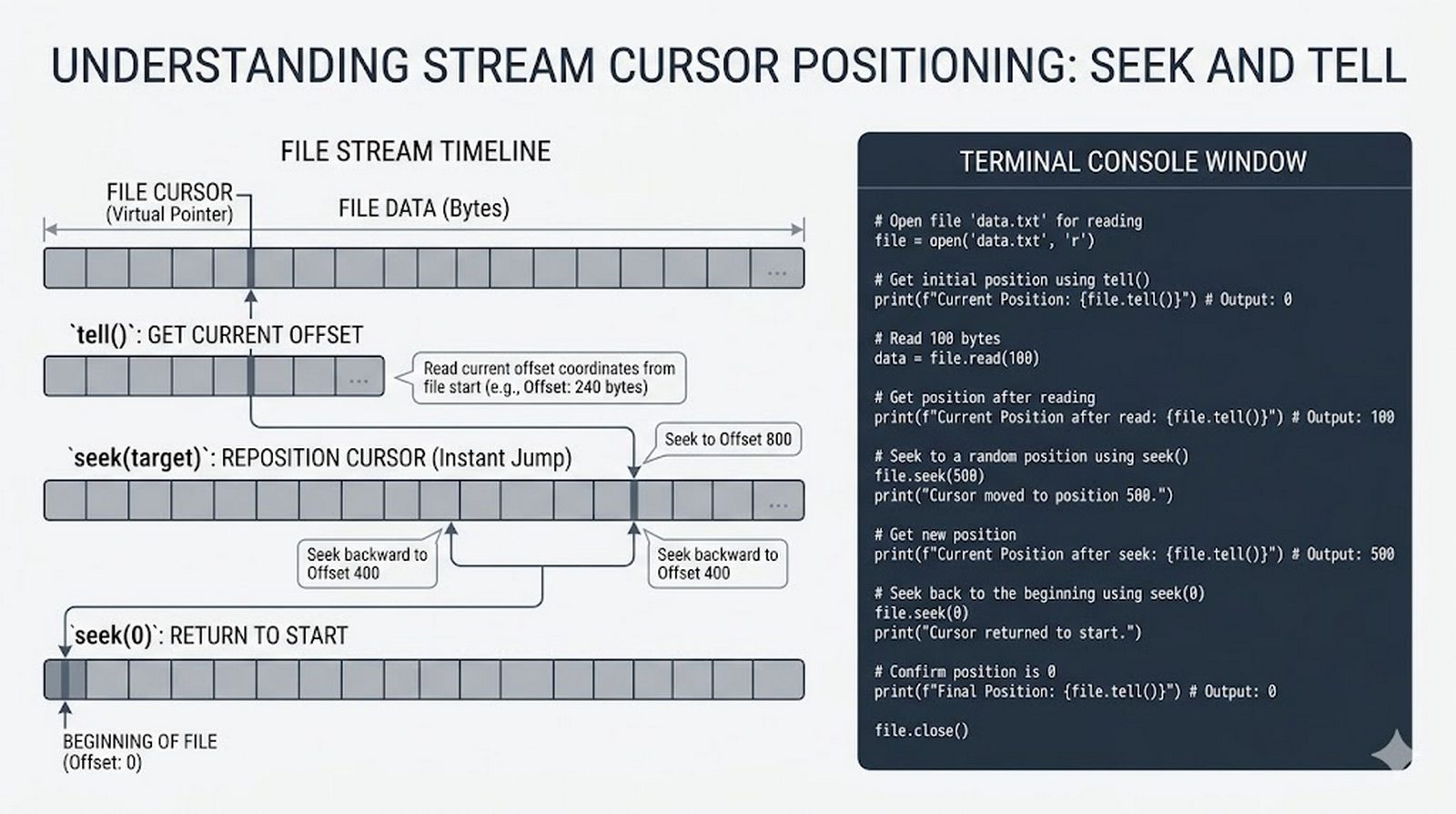
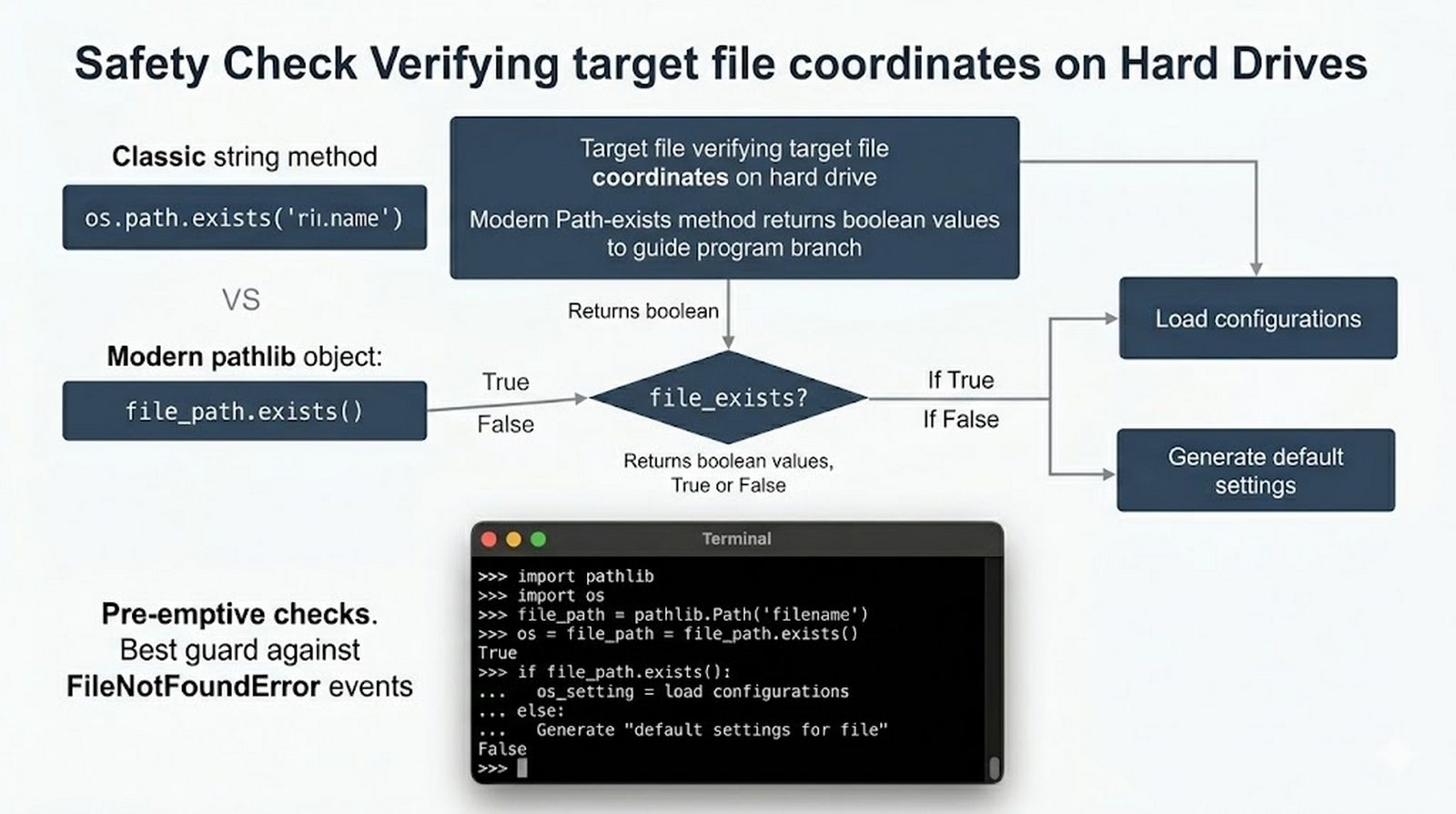
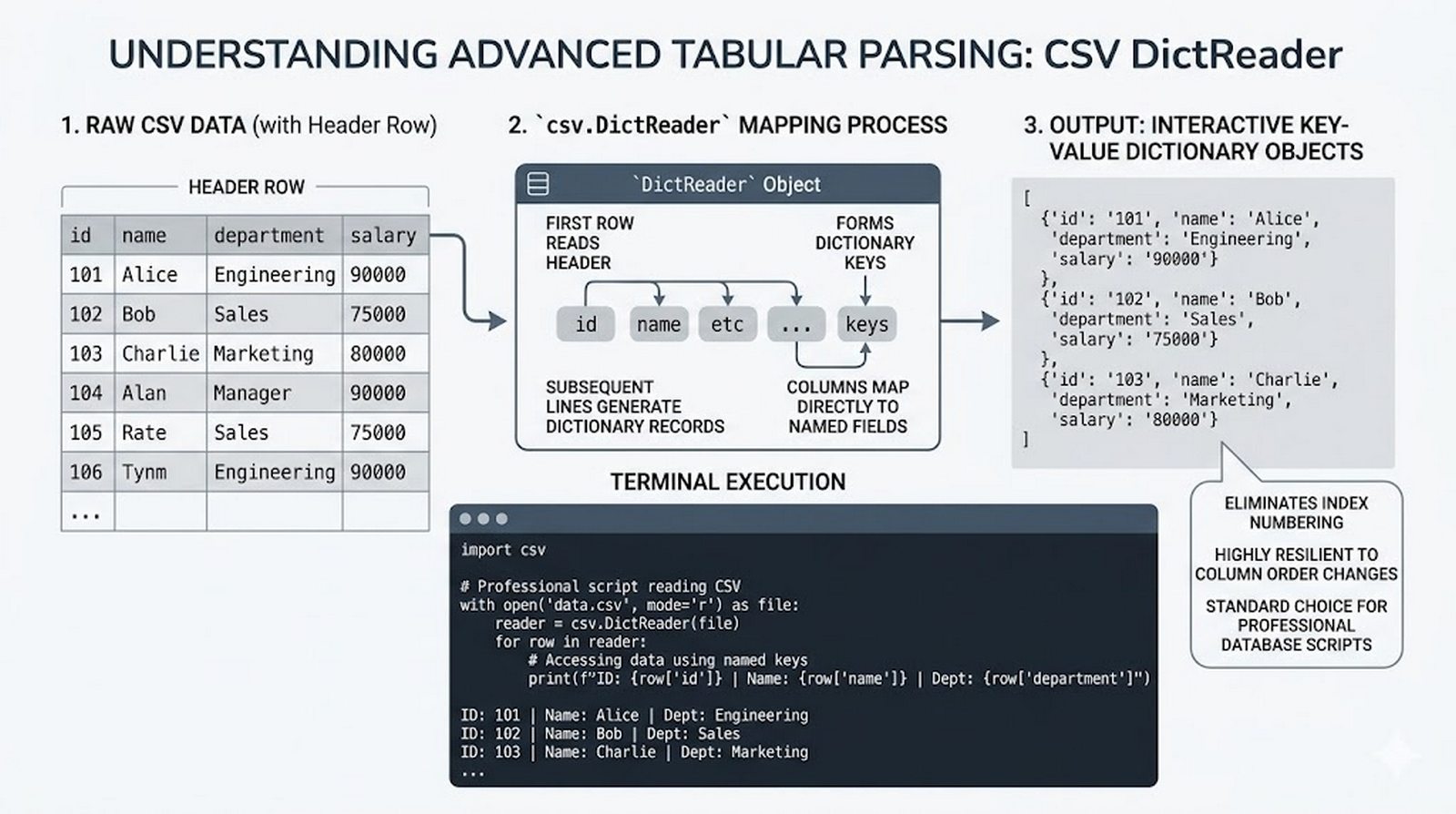
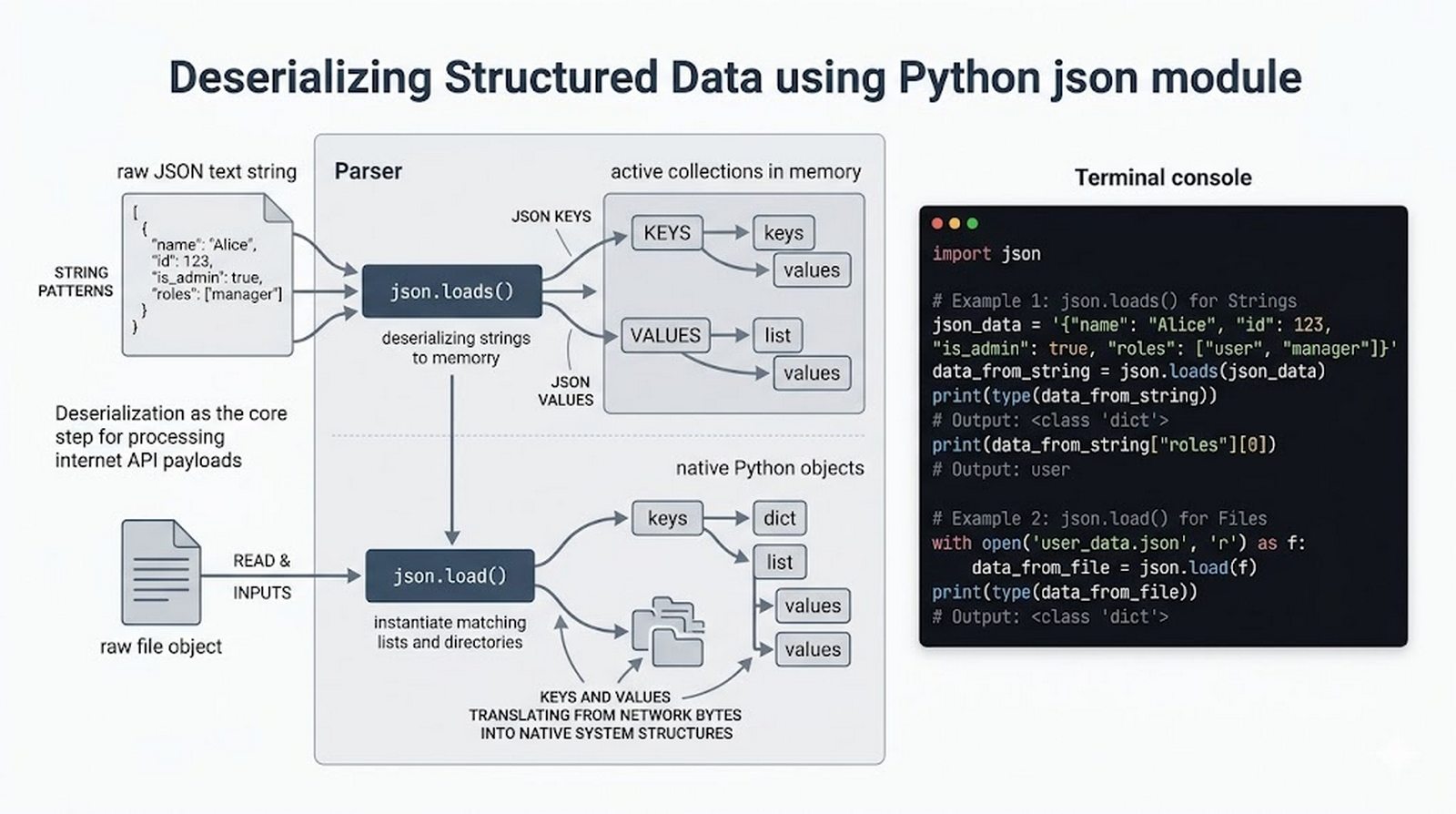
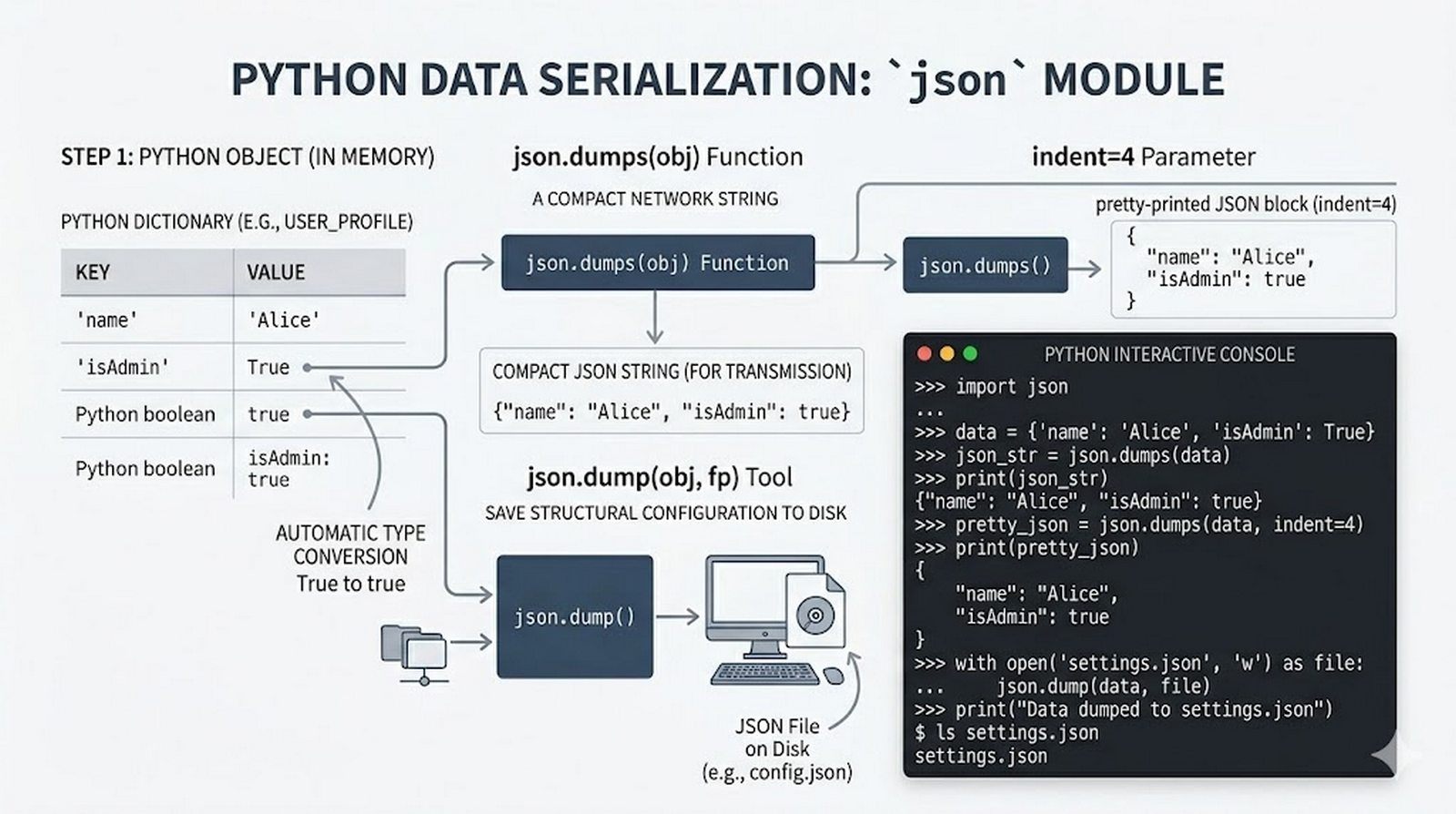
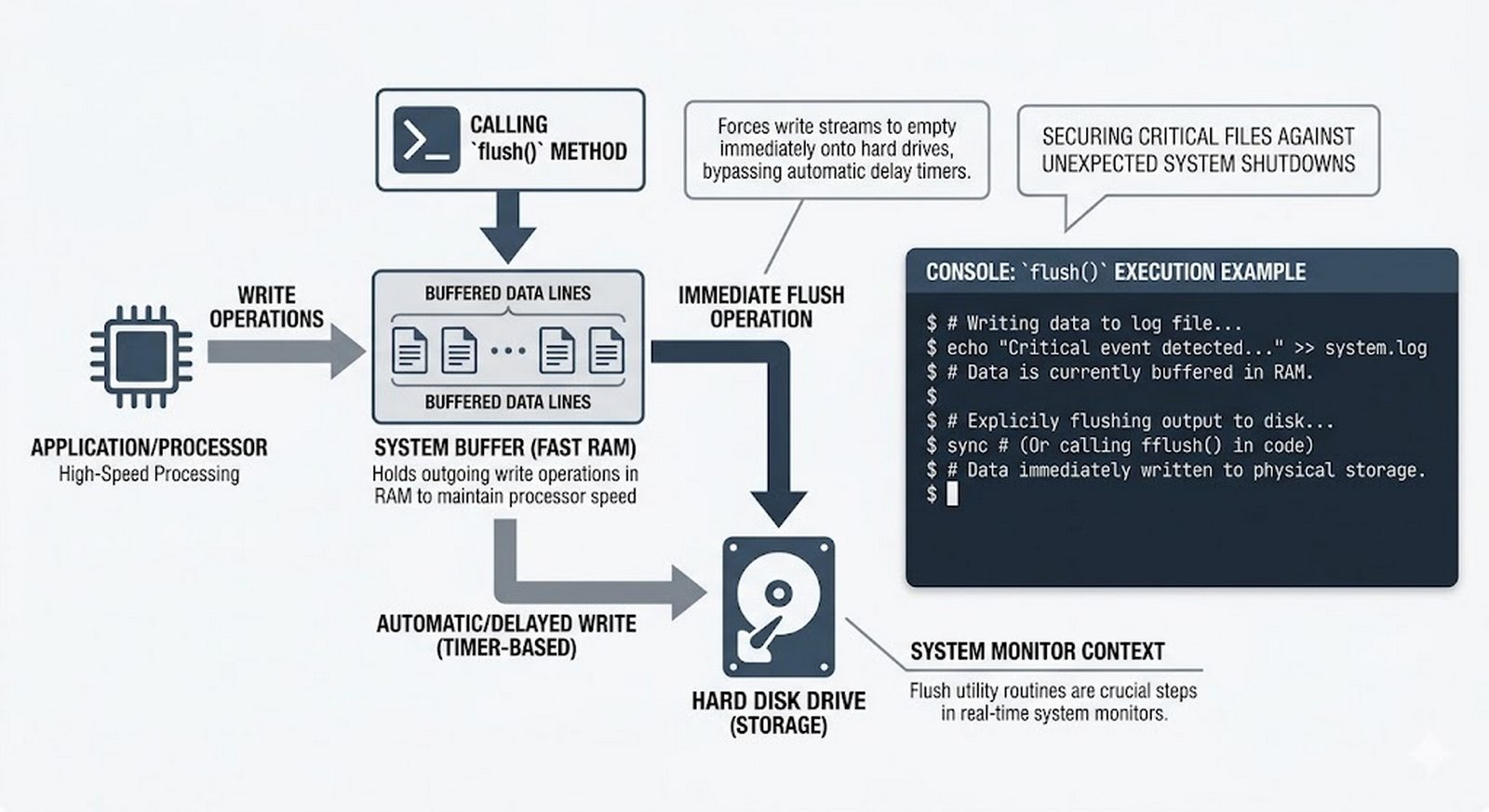
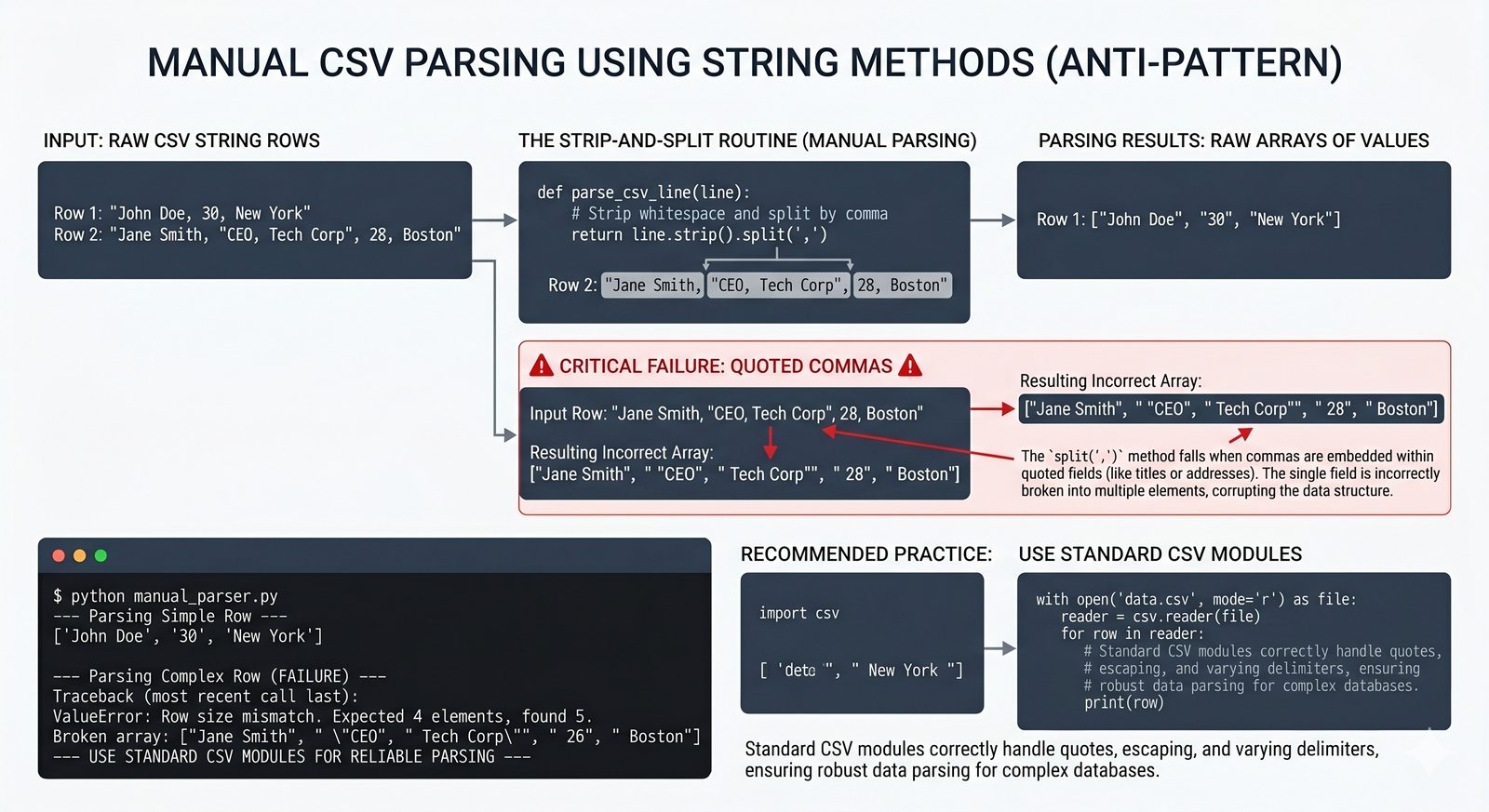
tell()/seek(), sprawdzanie istnienia pliku (pathlib), obsługa błędów I/O - Formaty danych i dobre praktyki -- CSV i JSON z modułami
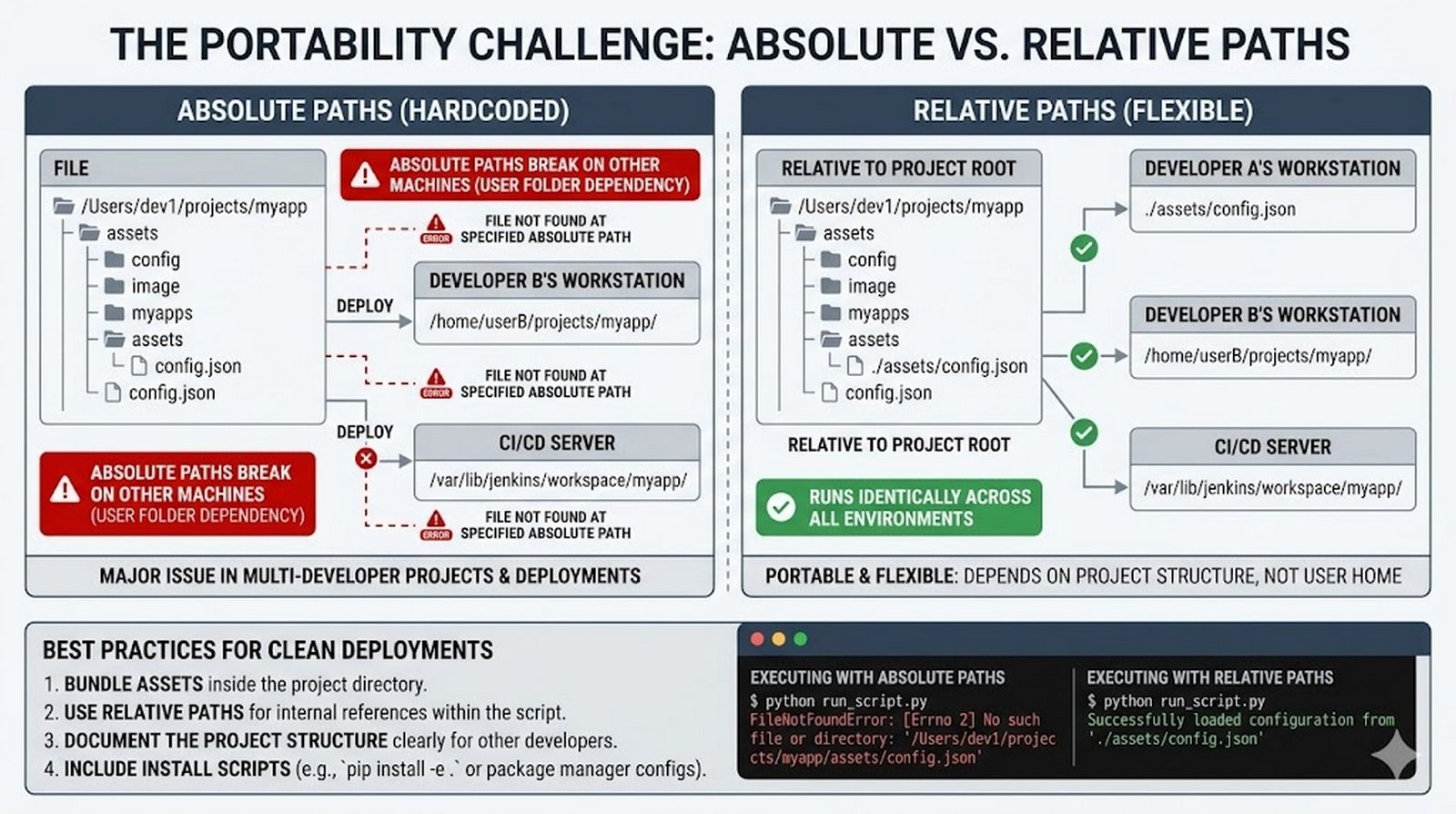
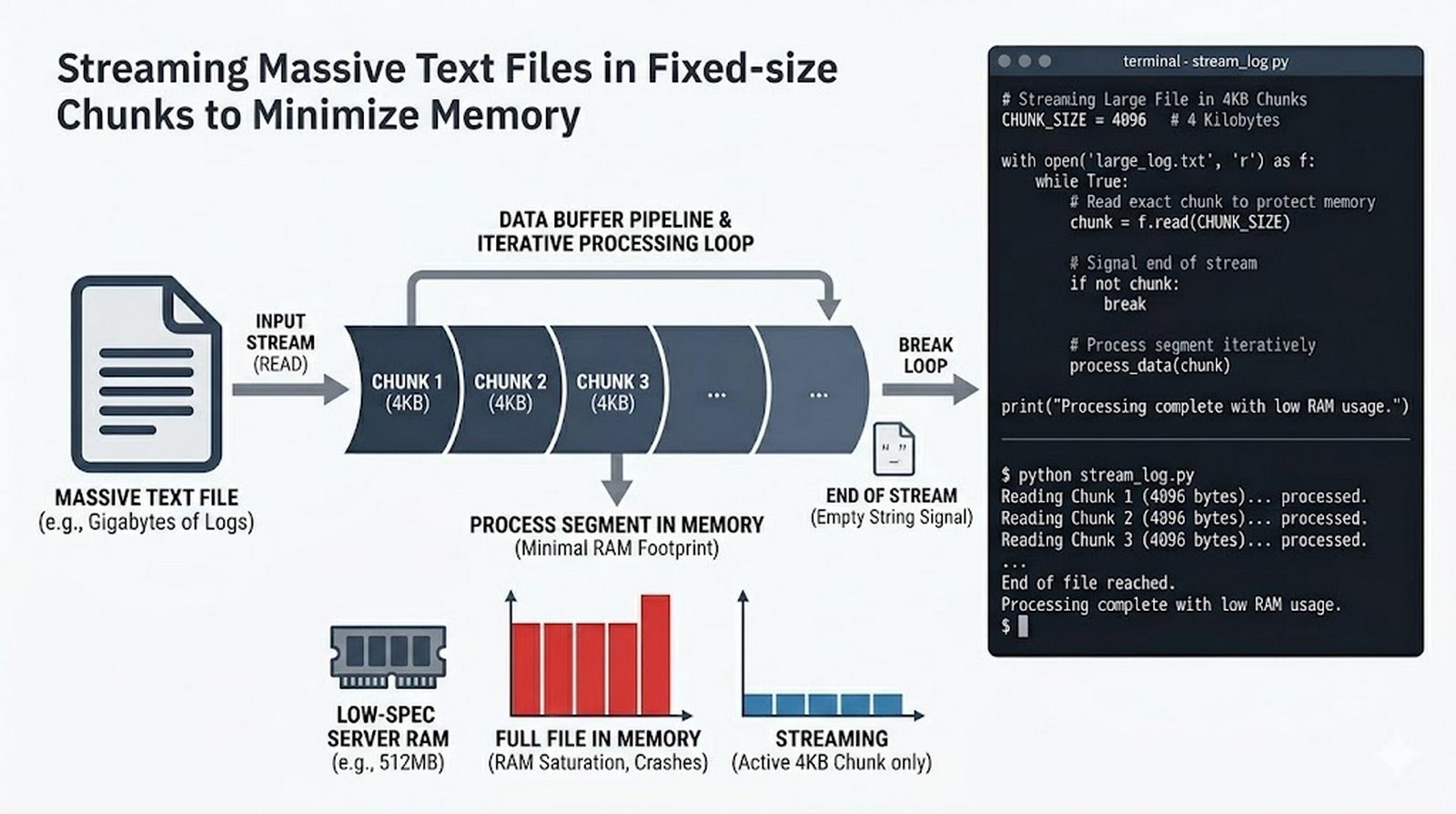
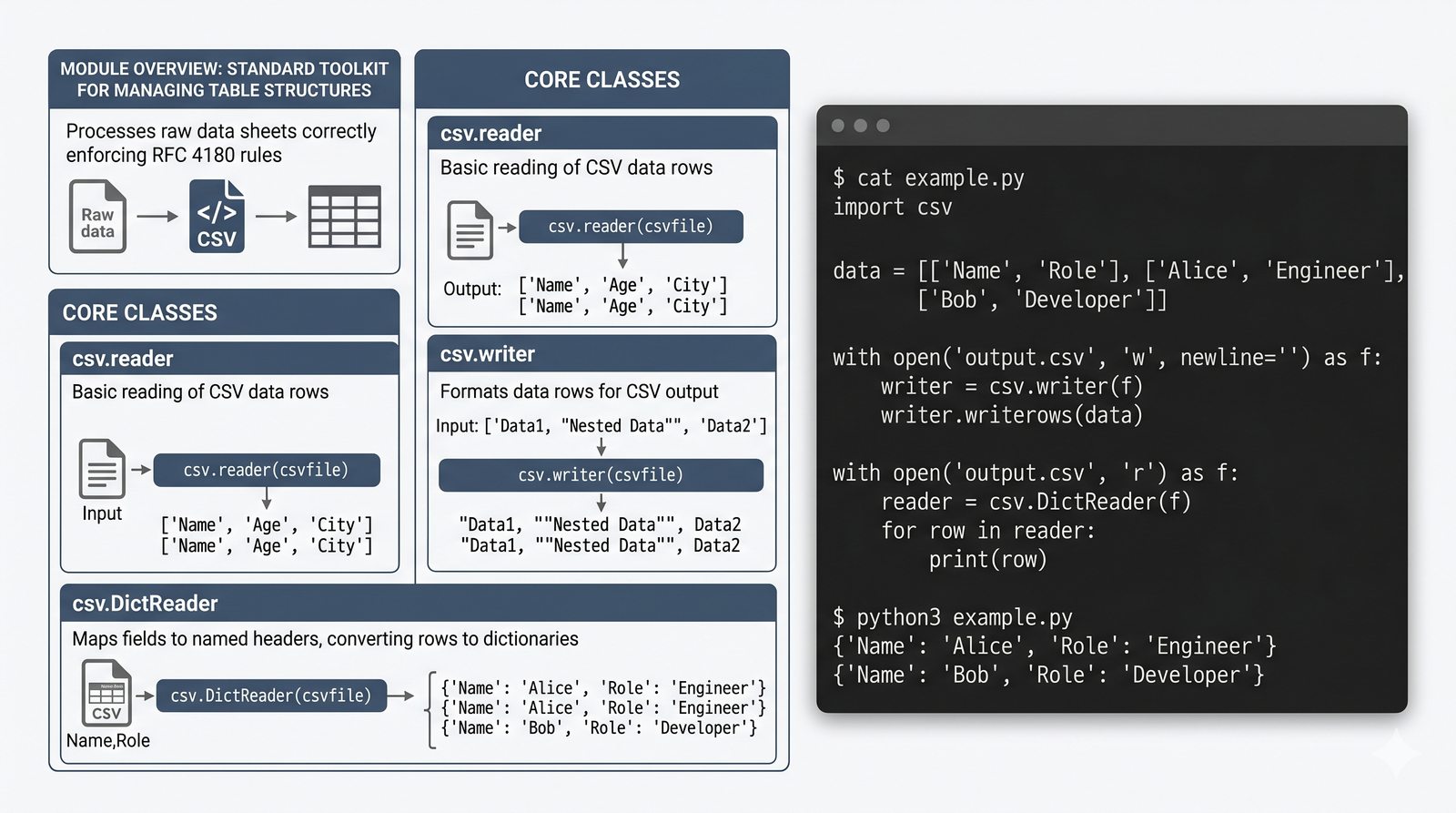
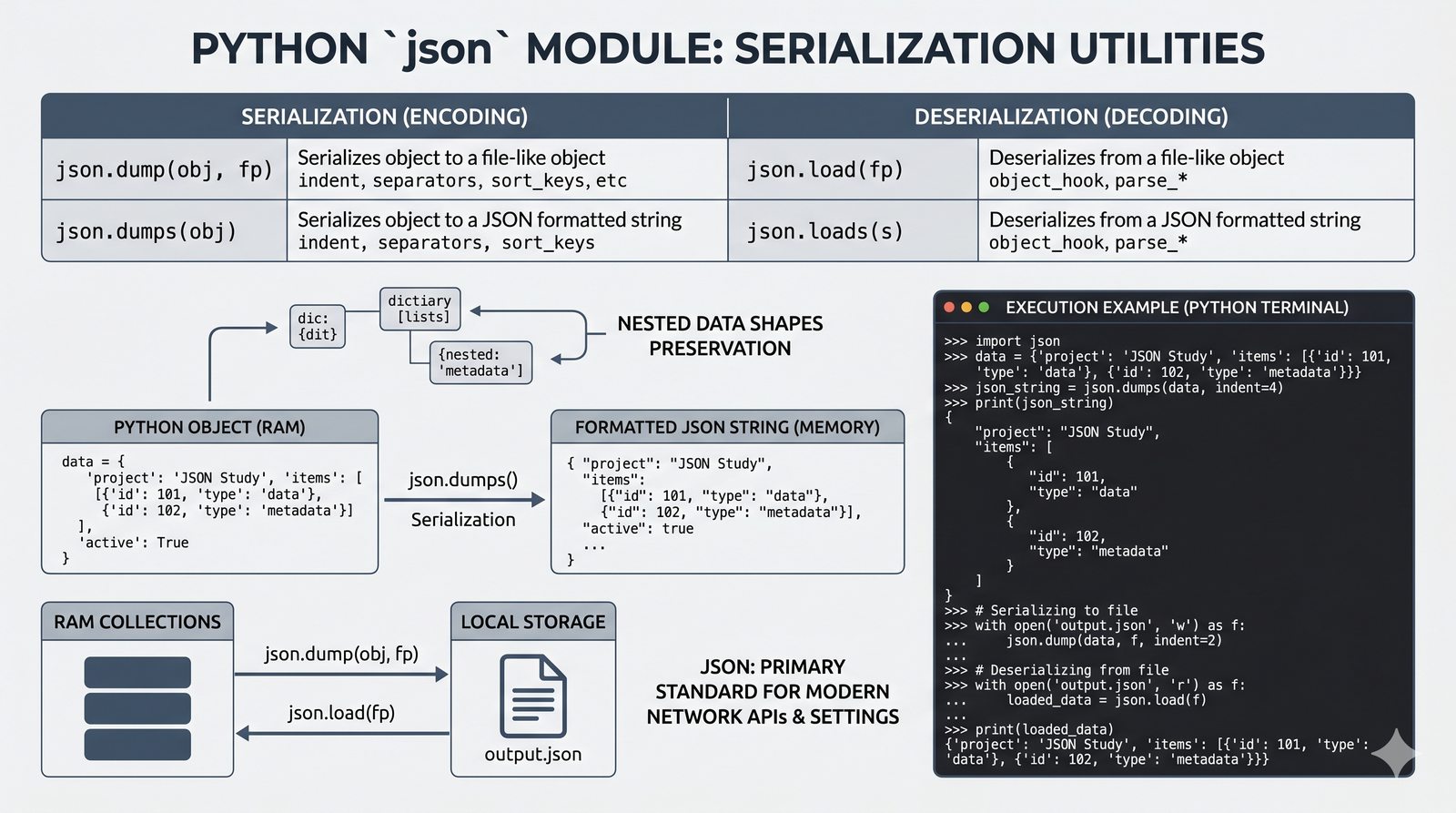
csv/json,pathlib, ścieżki względne, wydajne przetwarzanie dużych plików