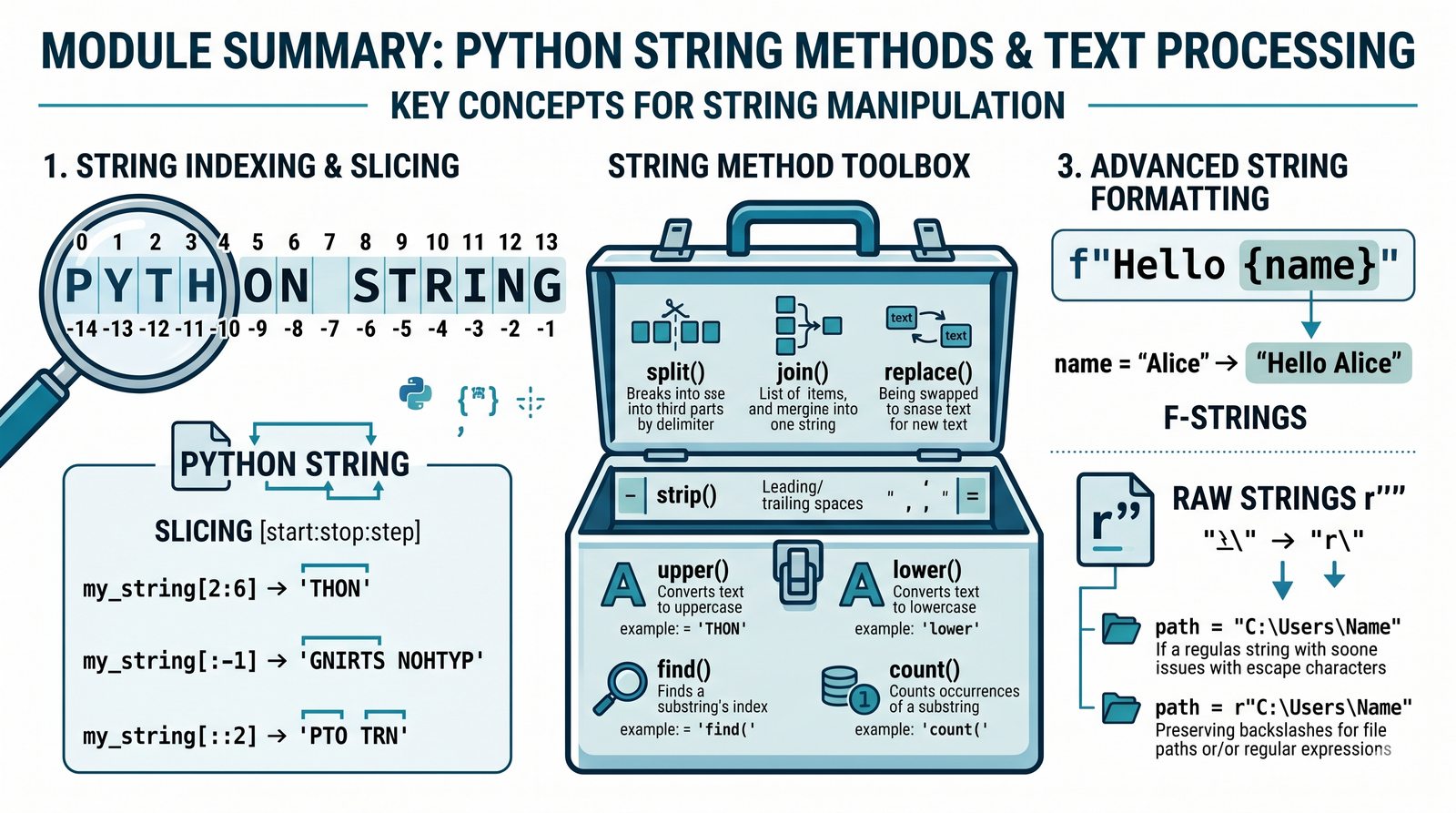
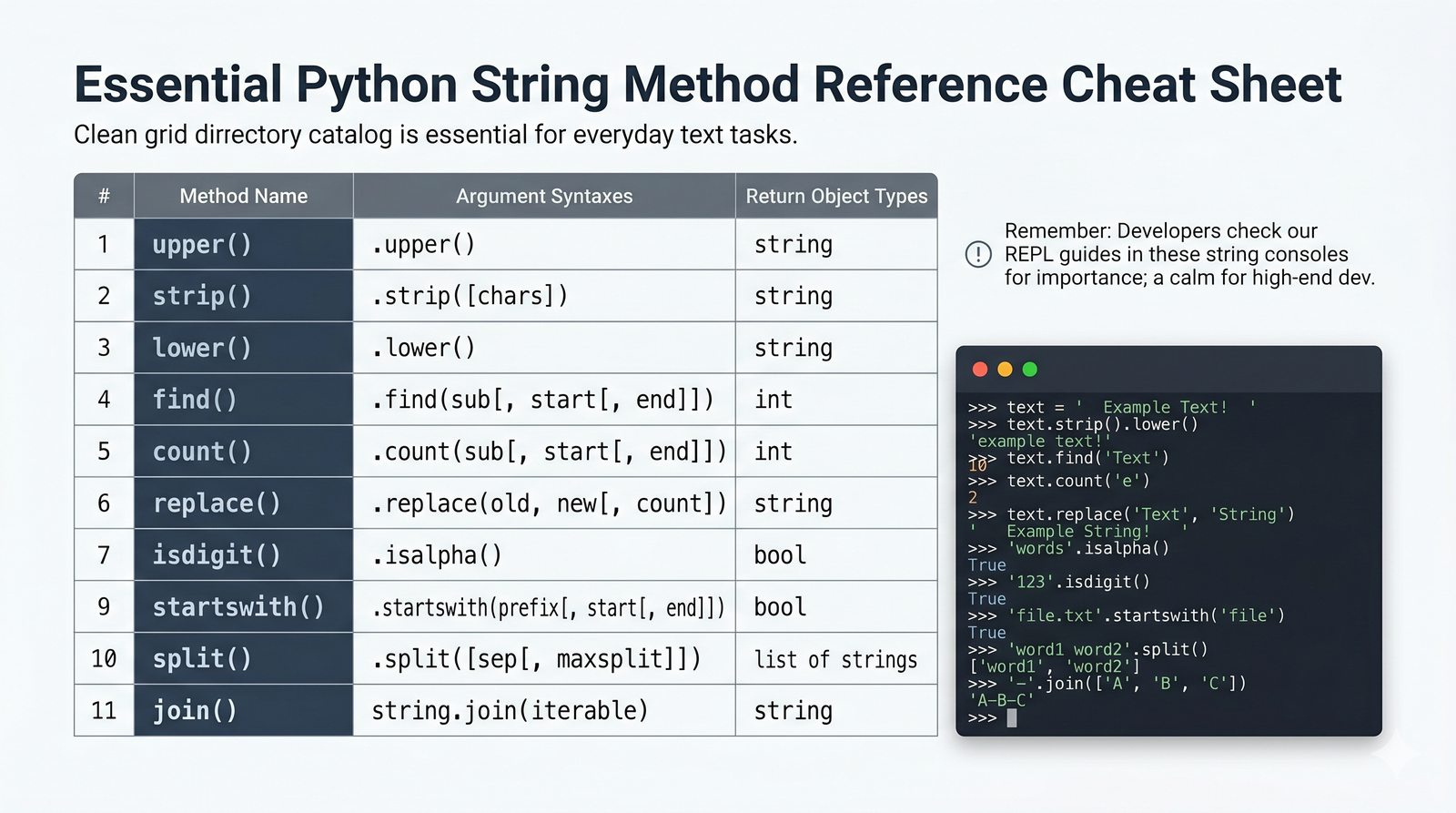
Moduł w całości poświęcony jest zaawansowanemu przetwarzaniu łańcuchów znaków (typ str) w języku Python. Omówiono w nim mechanizmy indeksowania dodatniego i ujemnego, wycinki (slicing) z krokiem oraz zasadę niemutowalności napisów. Przedstawiono bogaty zestaw wbudowanych metod tekstowych, takich jak split(), join(), replace(), strip() i wiele innych, umożliwiających wygodną manipulację danymi tekstowymi. Szczegółowo przeanalizowano techniki formatowania tekstu, od operatora % i metody format(), aż po najnowocześniejsze f-stringi z obsługą wyrażeń i formatowania liczb. Materiał zawiera również praktyczne programy i ćwiczenia, w tym analizator tekstu, walidator e-mail oraz generator raportów.
Kluczowe zagadnienia modułu:
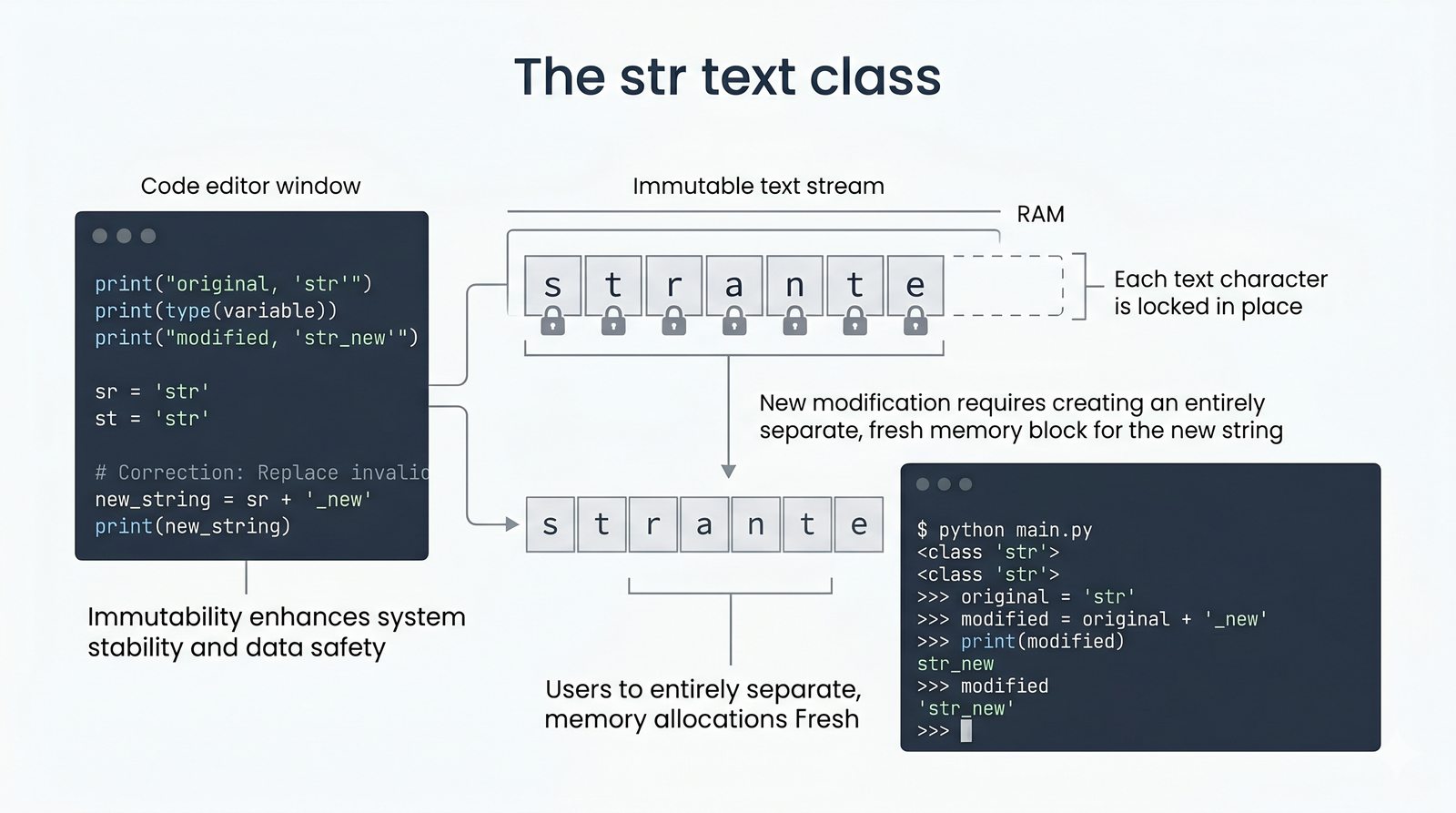
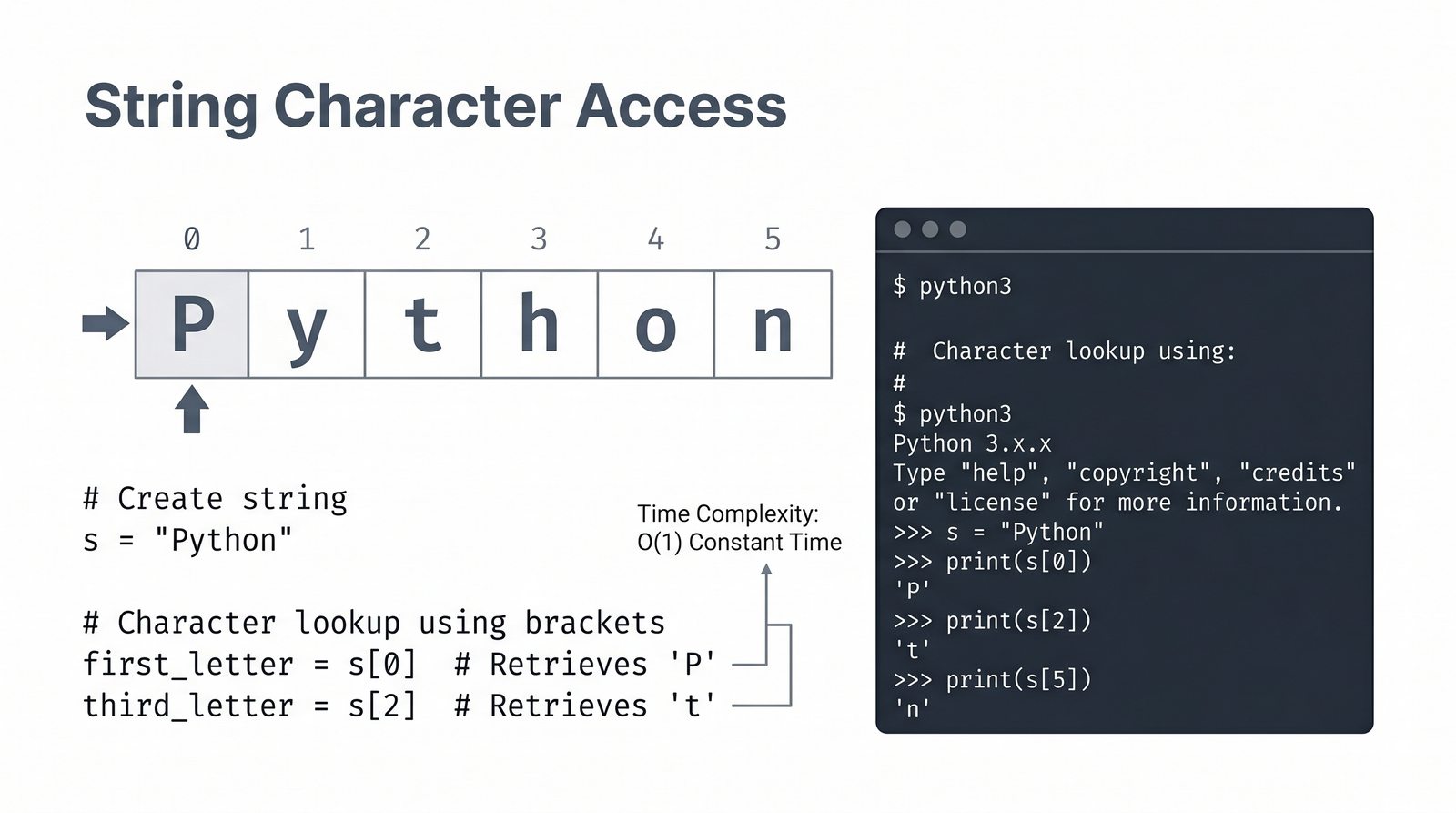
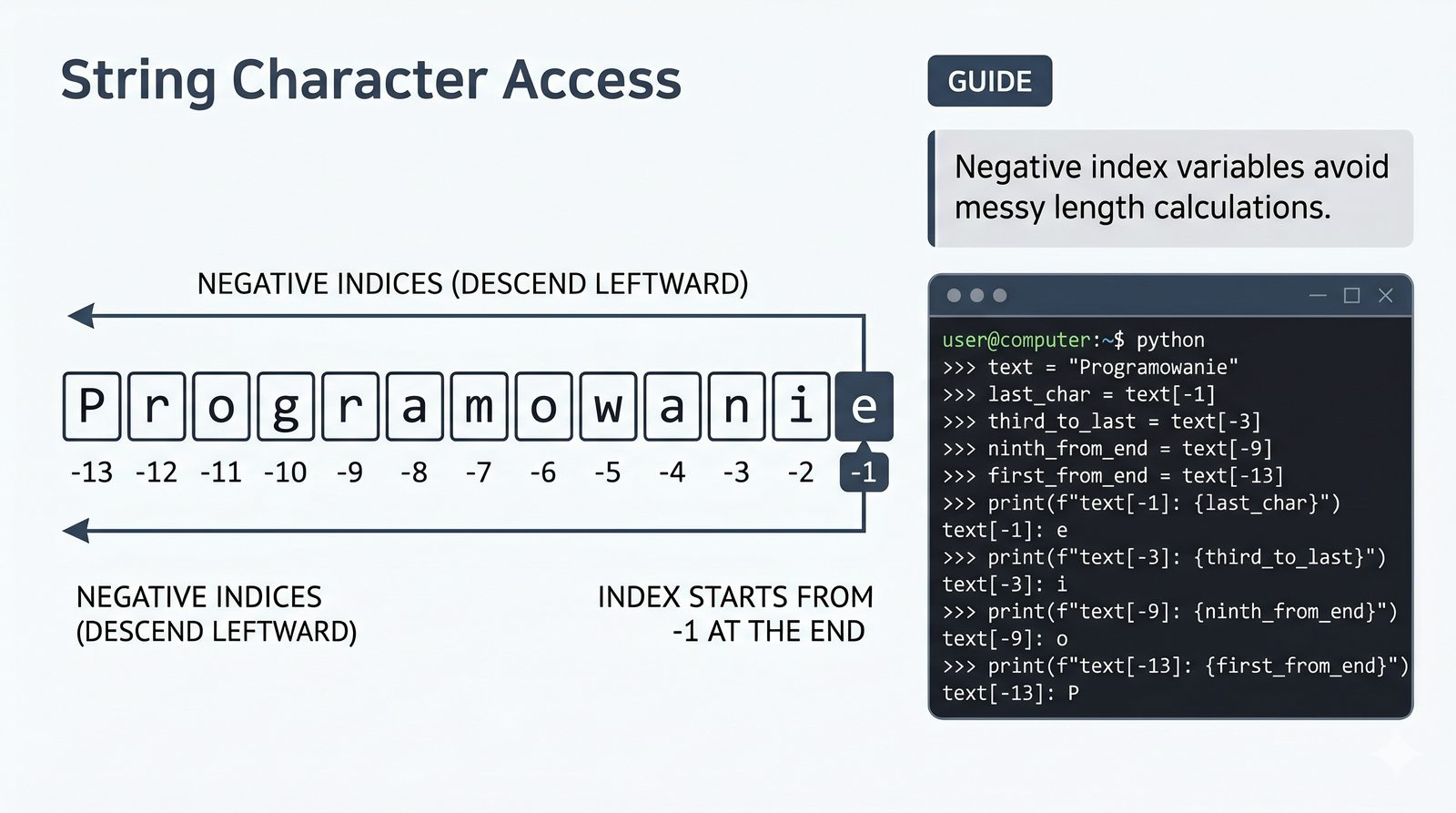
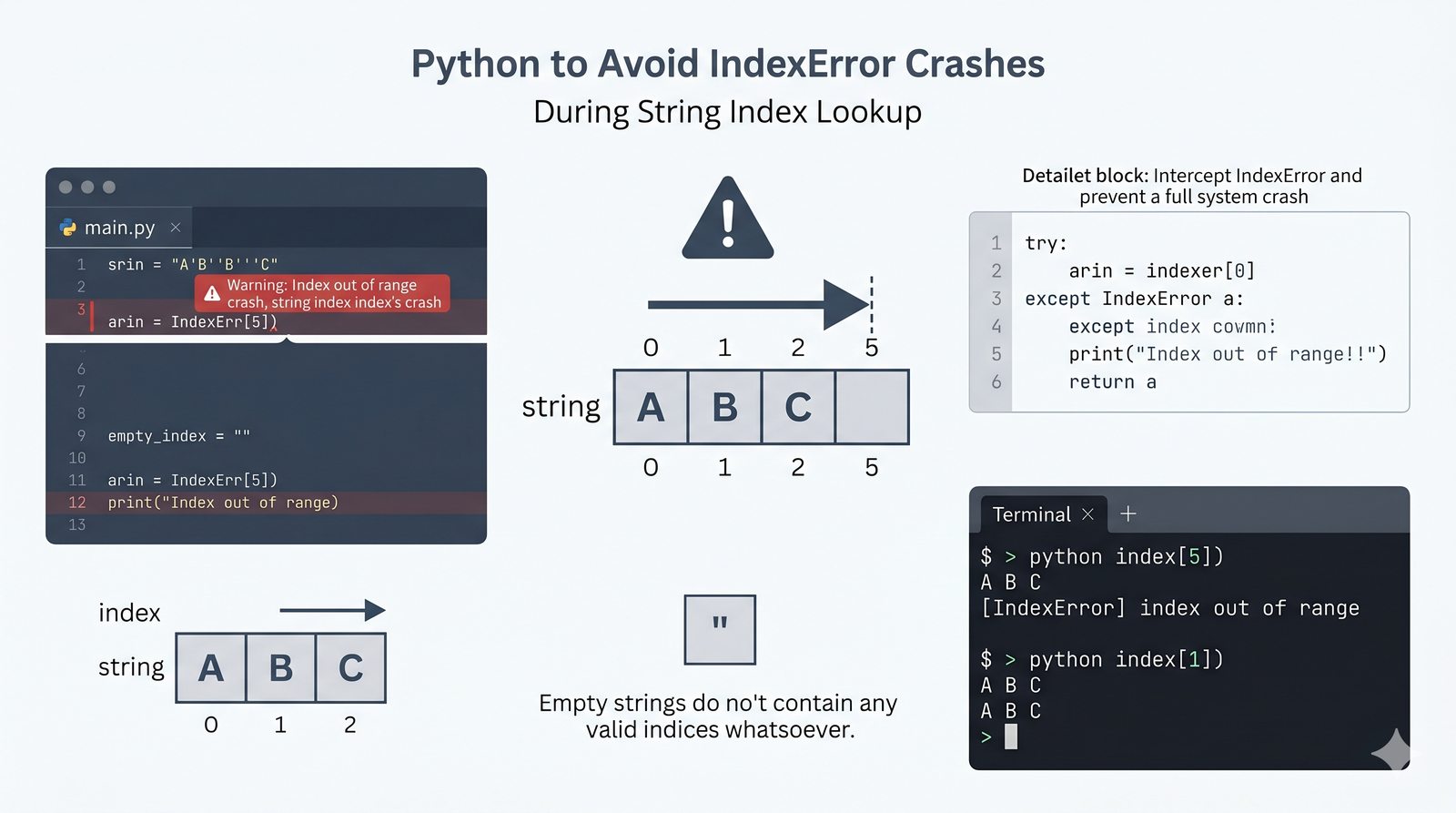
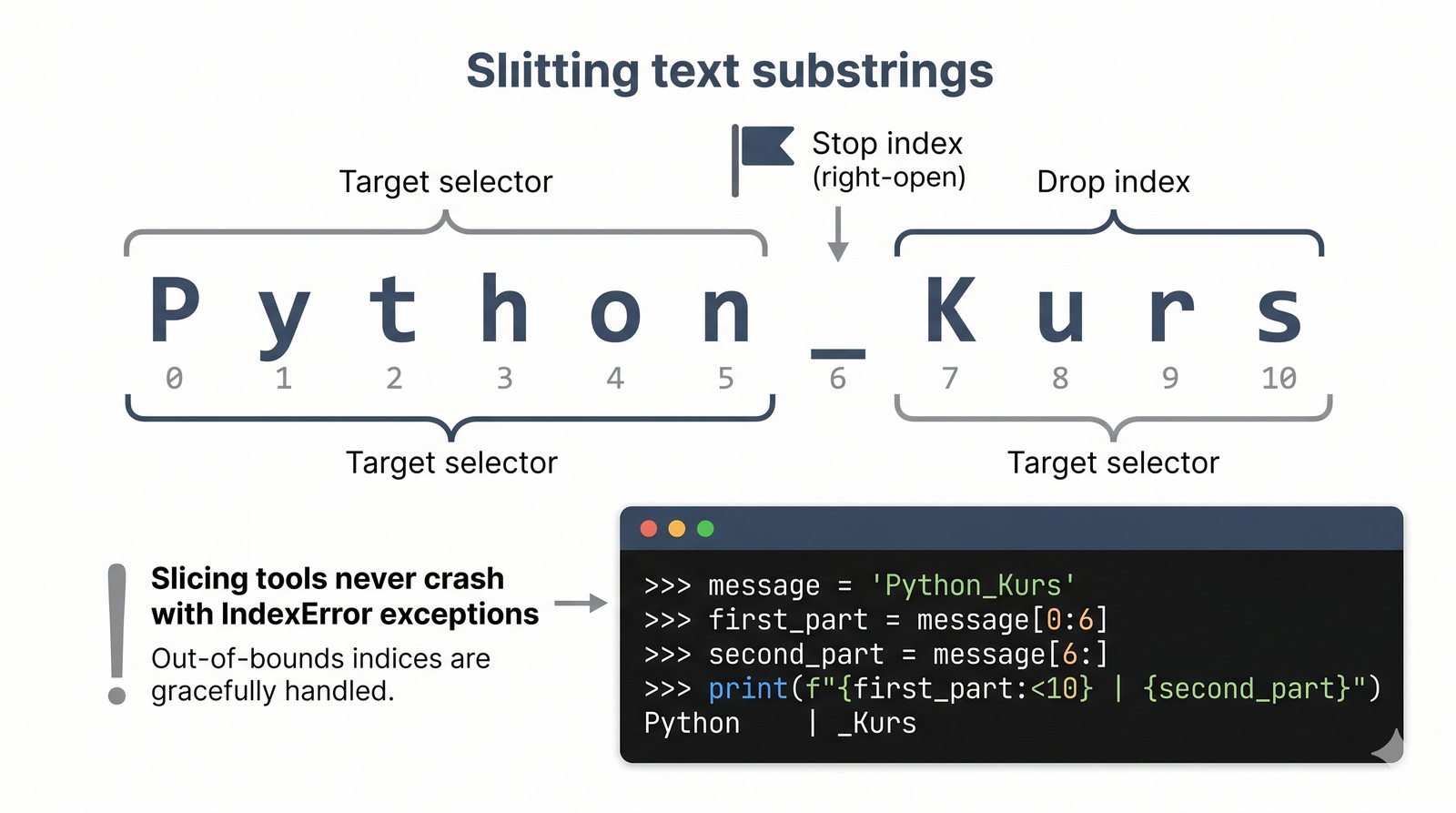
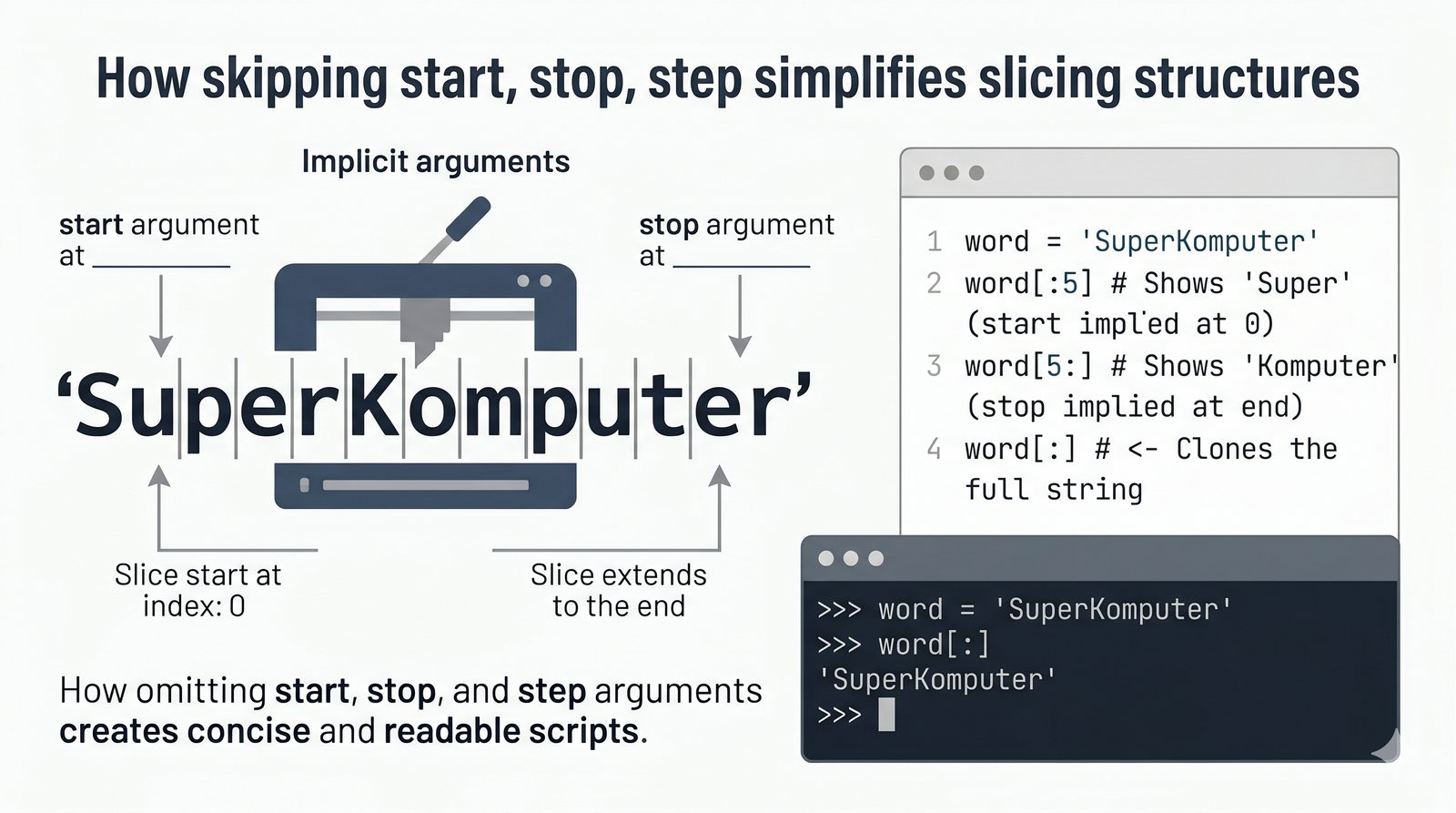
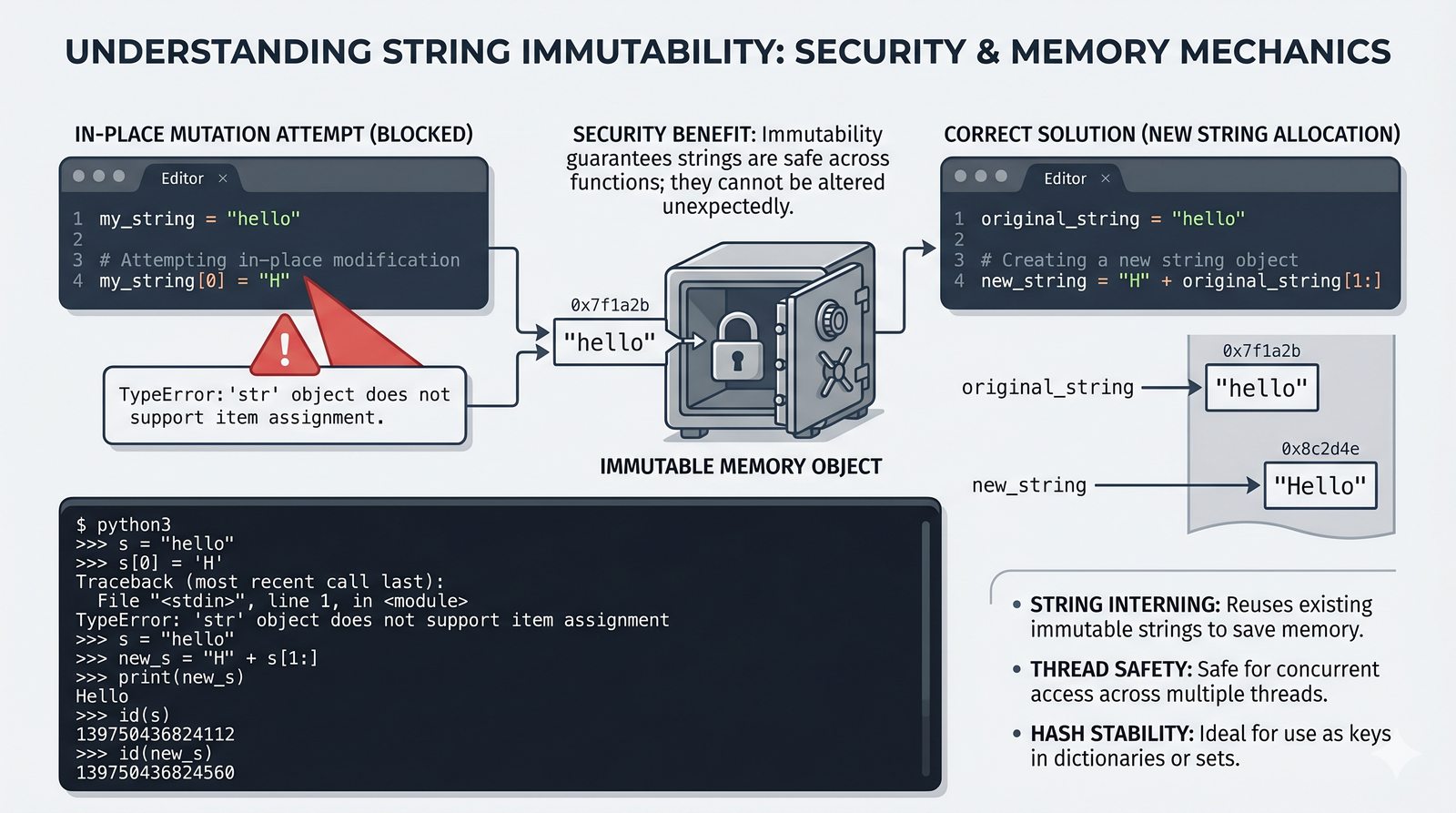
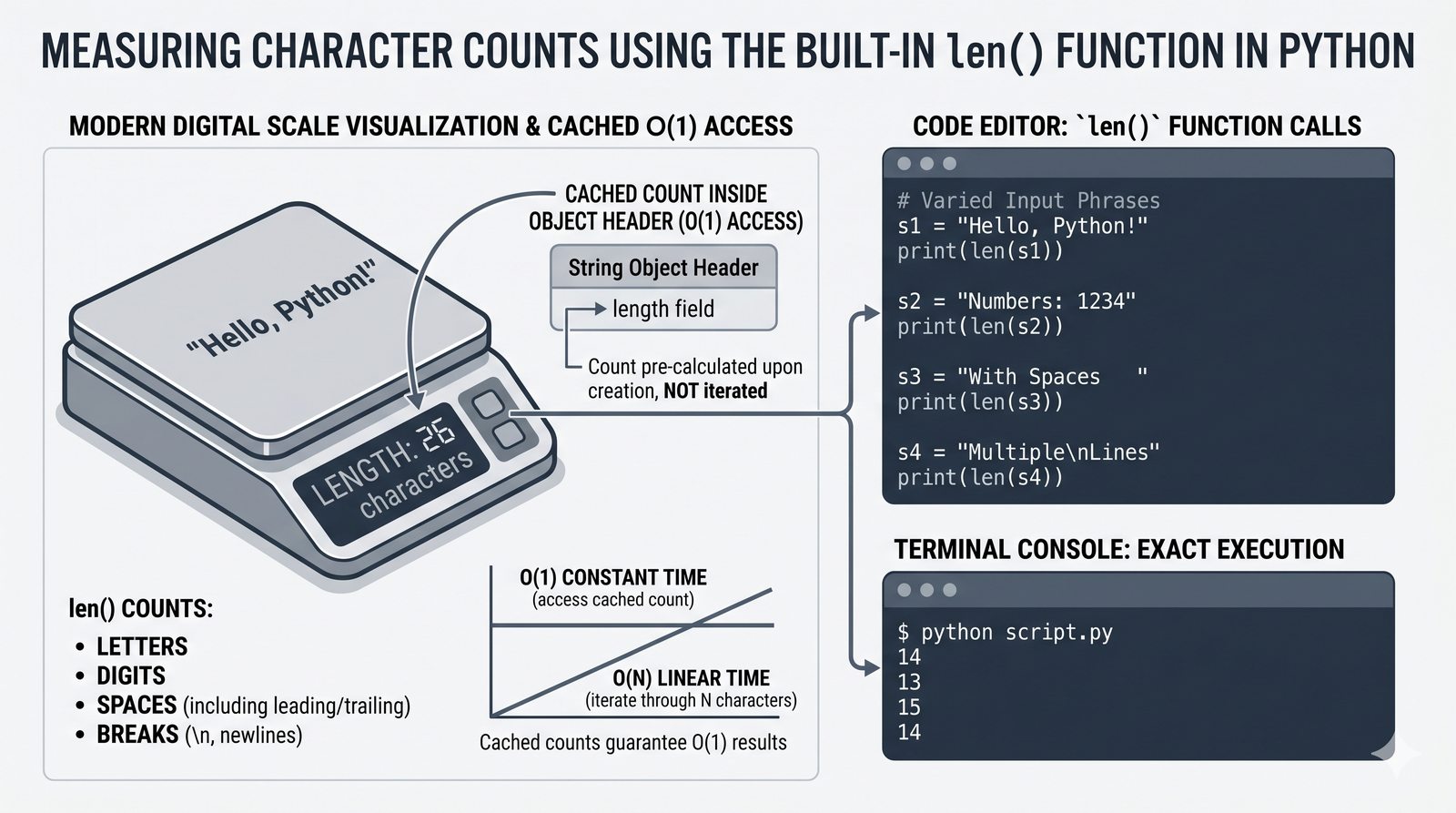
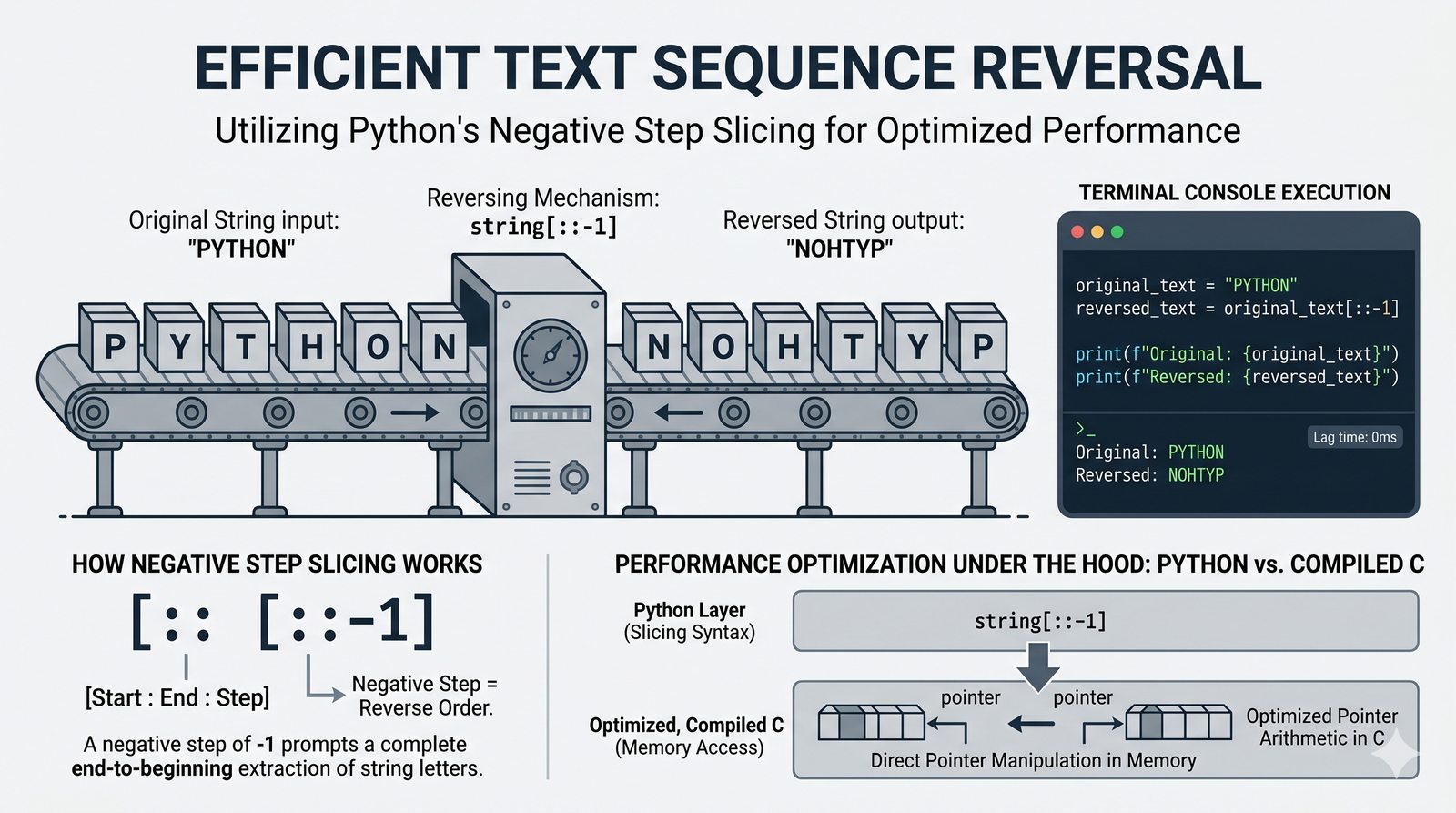
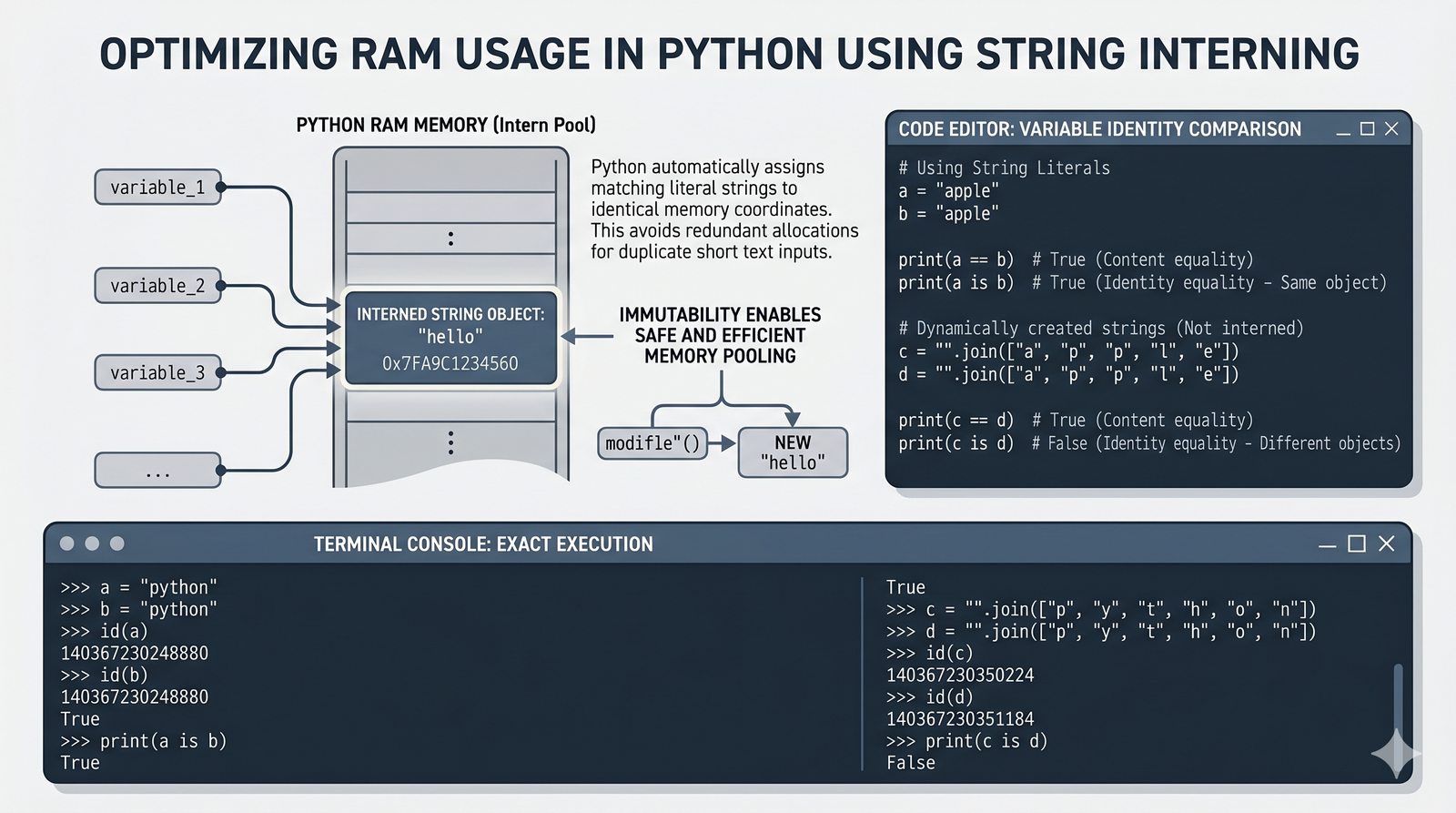
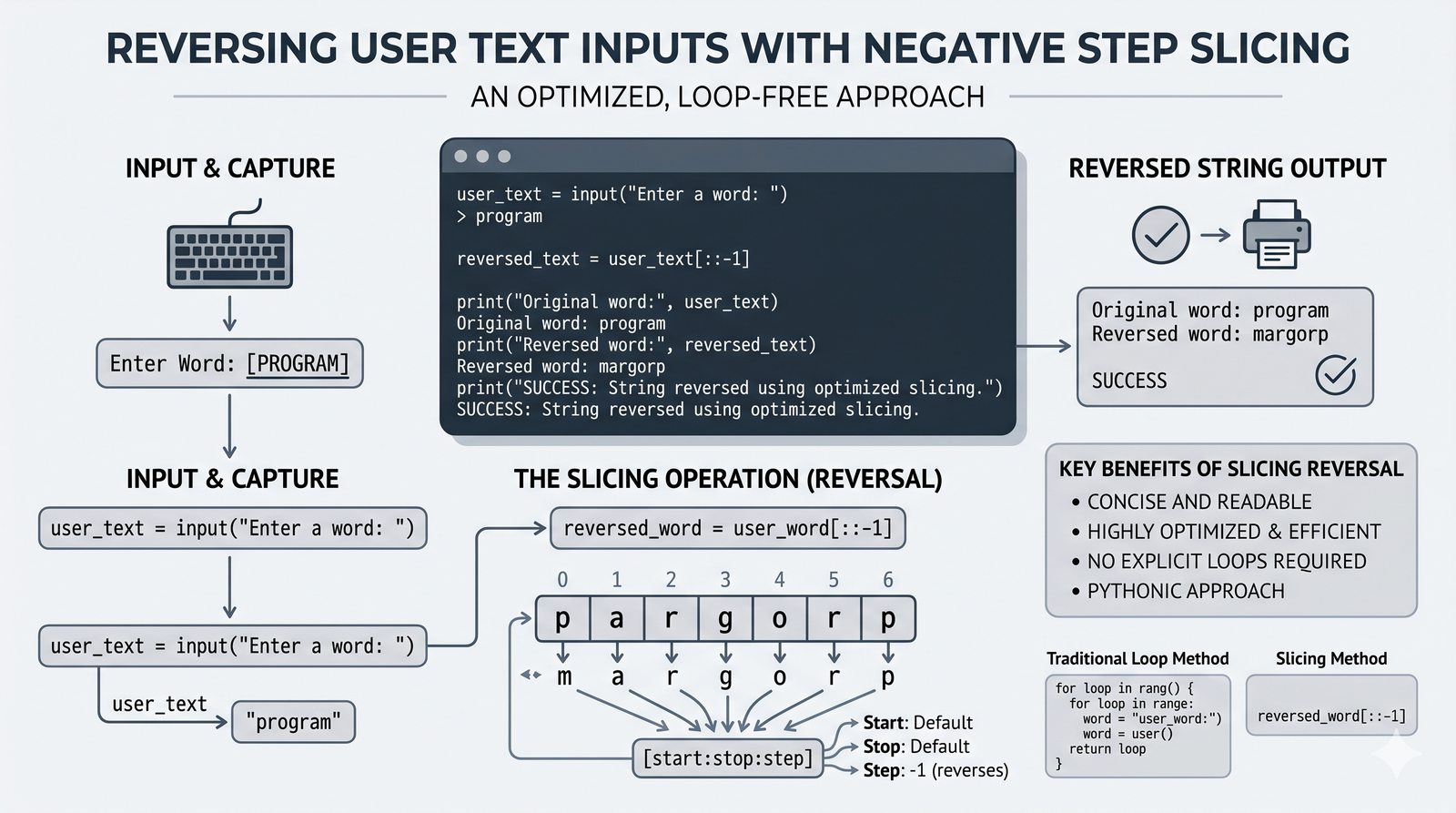
- Indeksowanie, wycinki i niemutowalność — dostęp do znaków, wyodrębnianie fragmentów [start:stop:krok] oraz konsekwencje niezmienności typu str
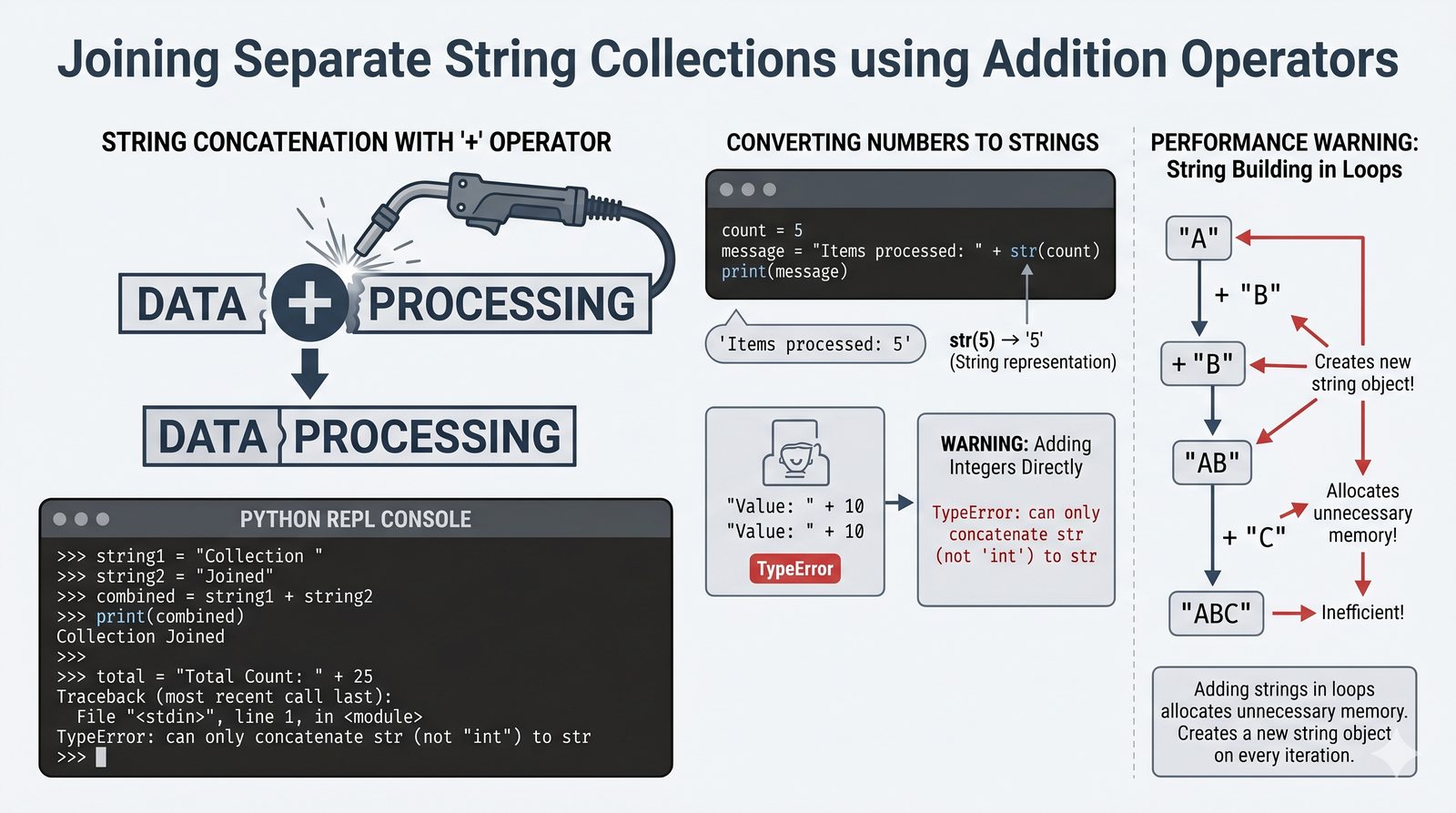
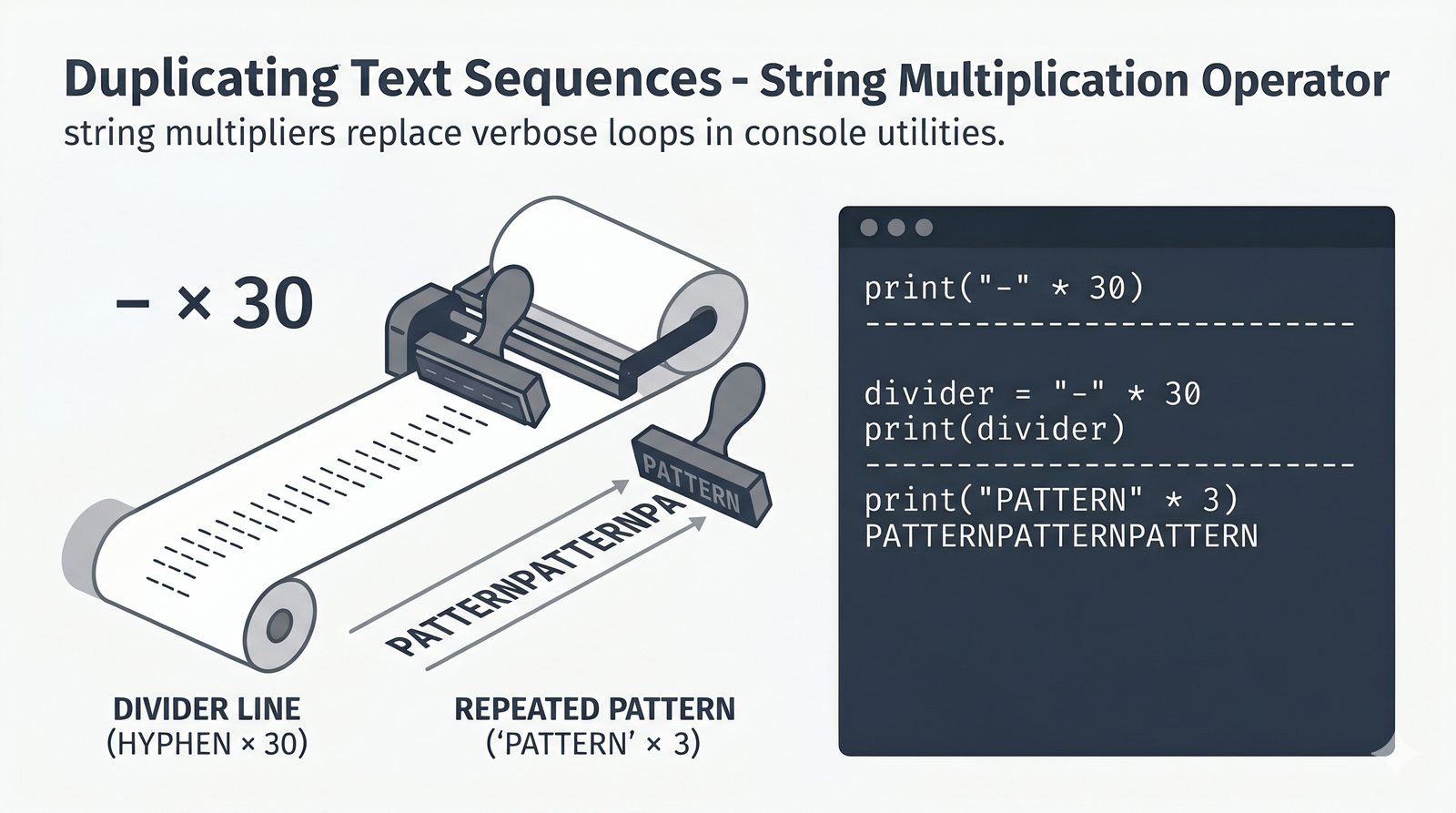
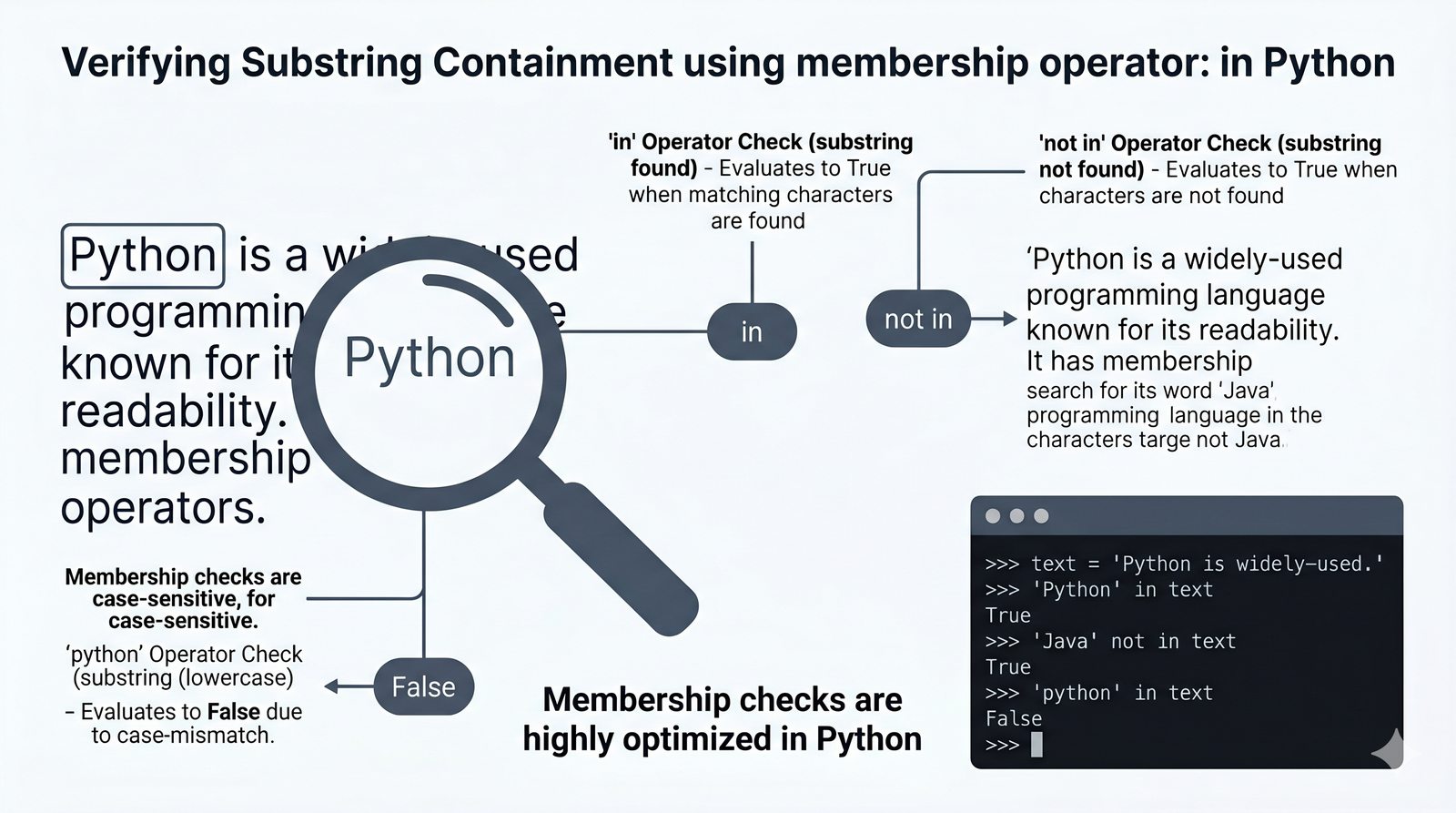
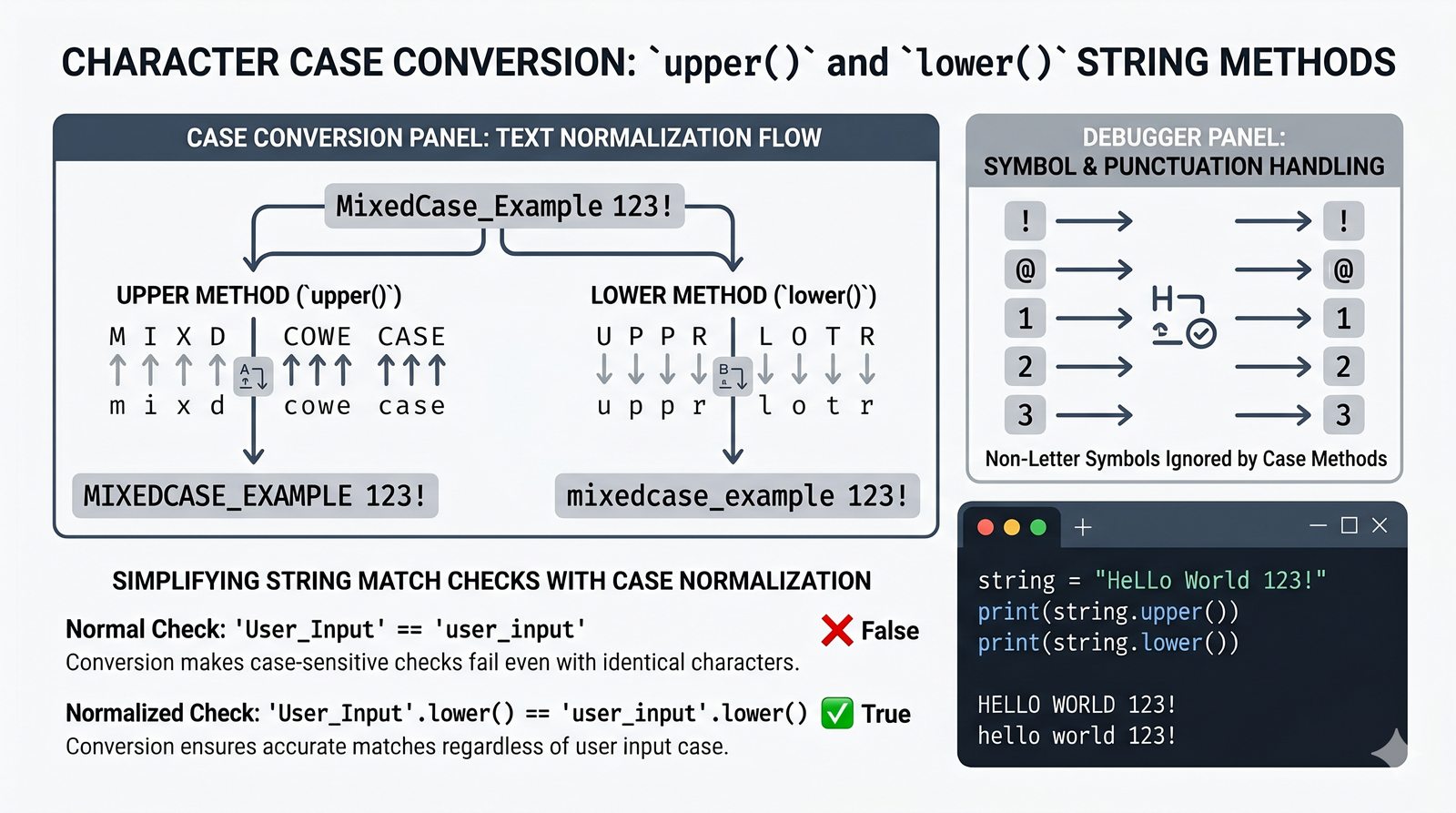
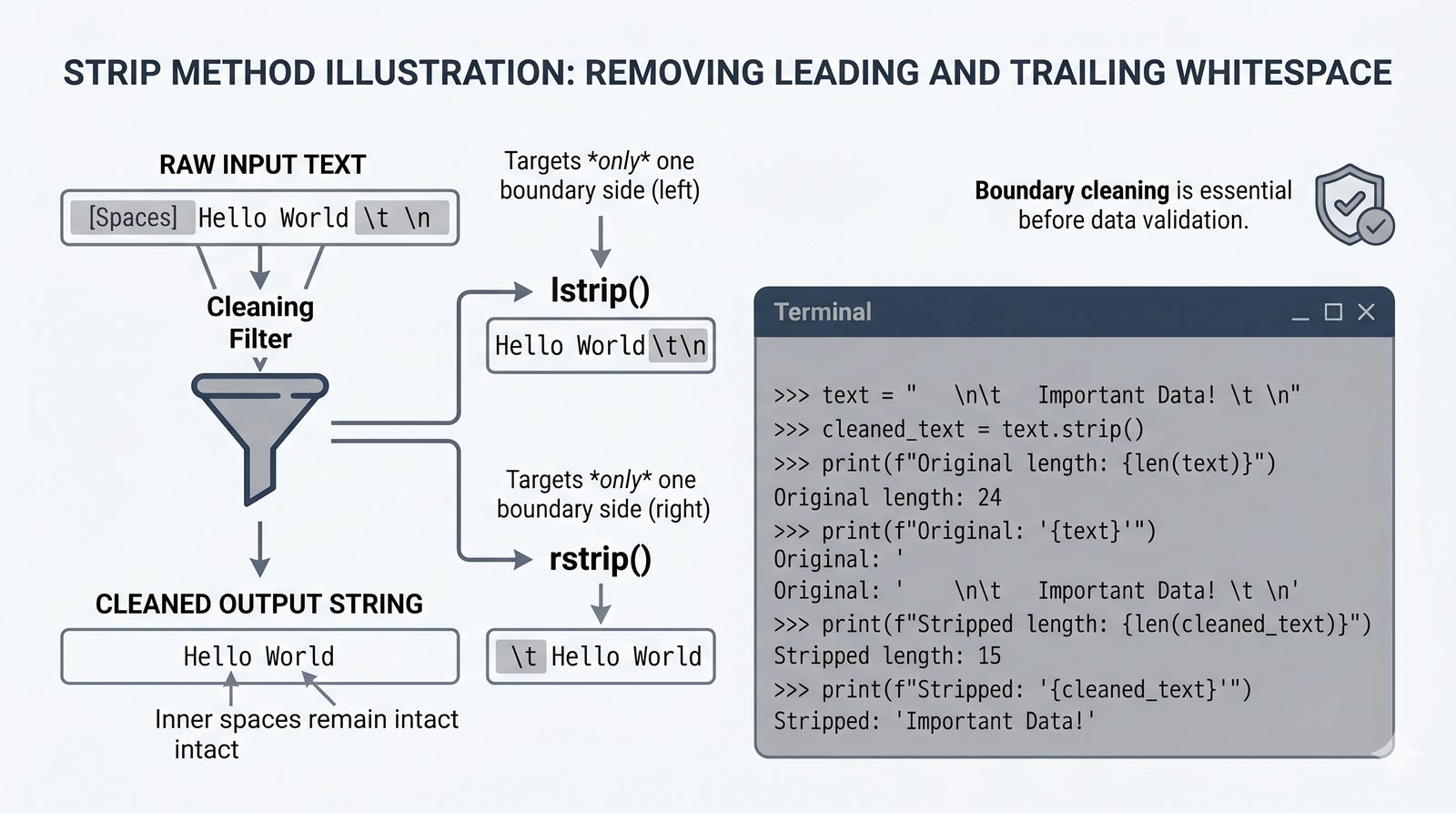
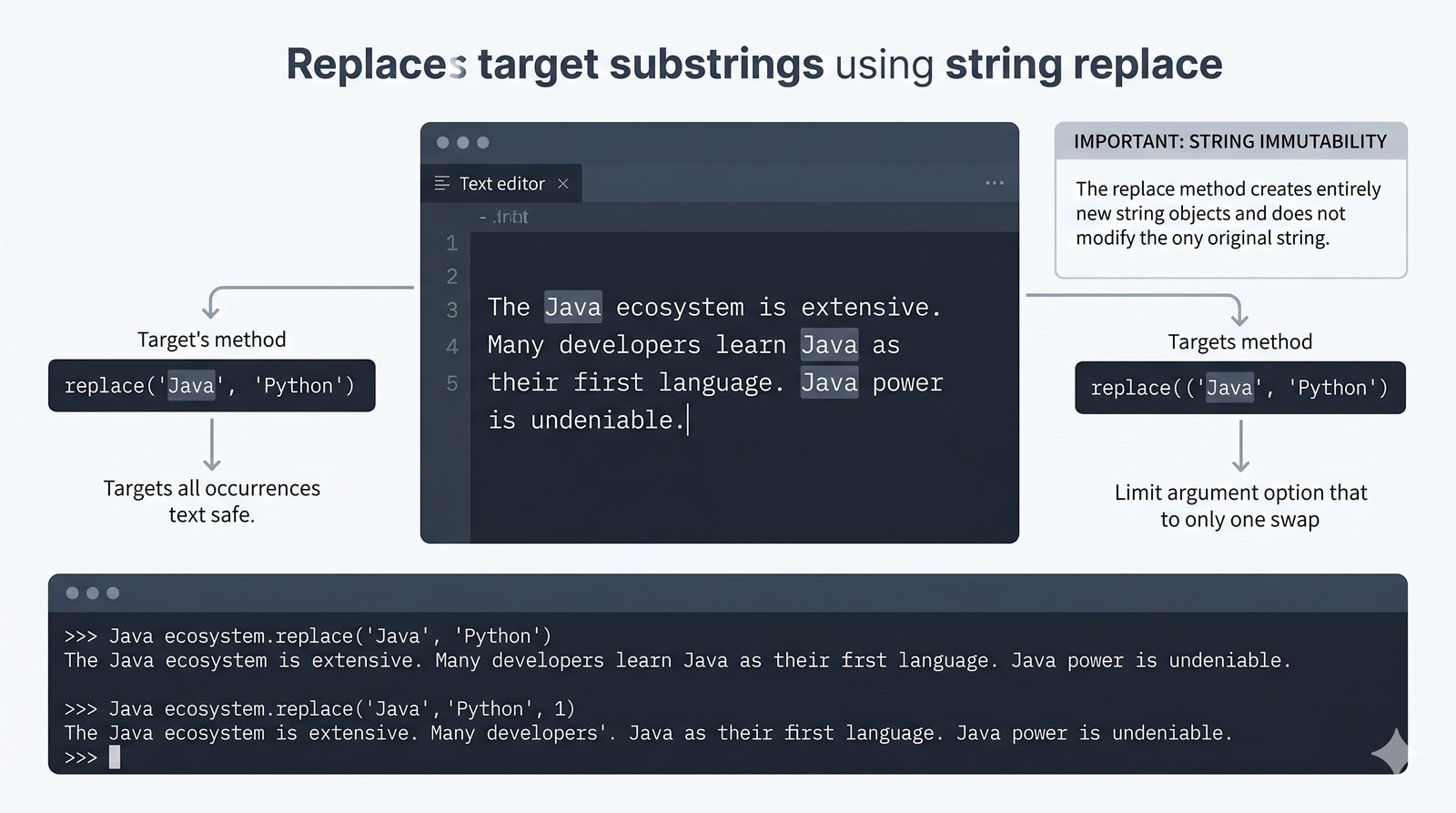
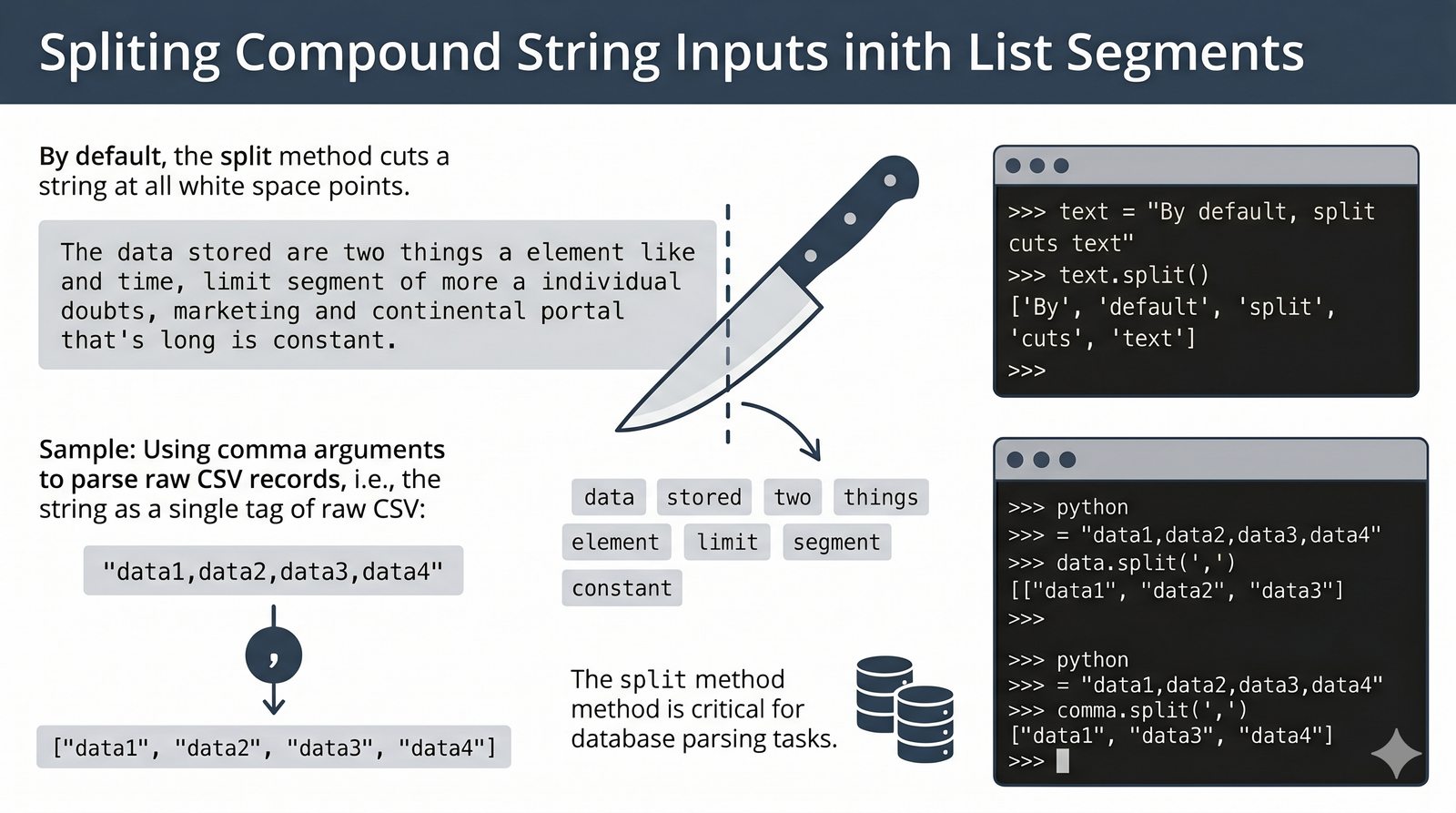
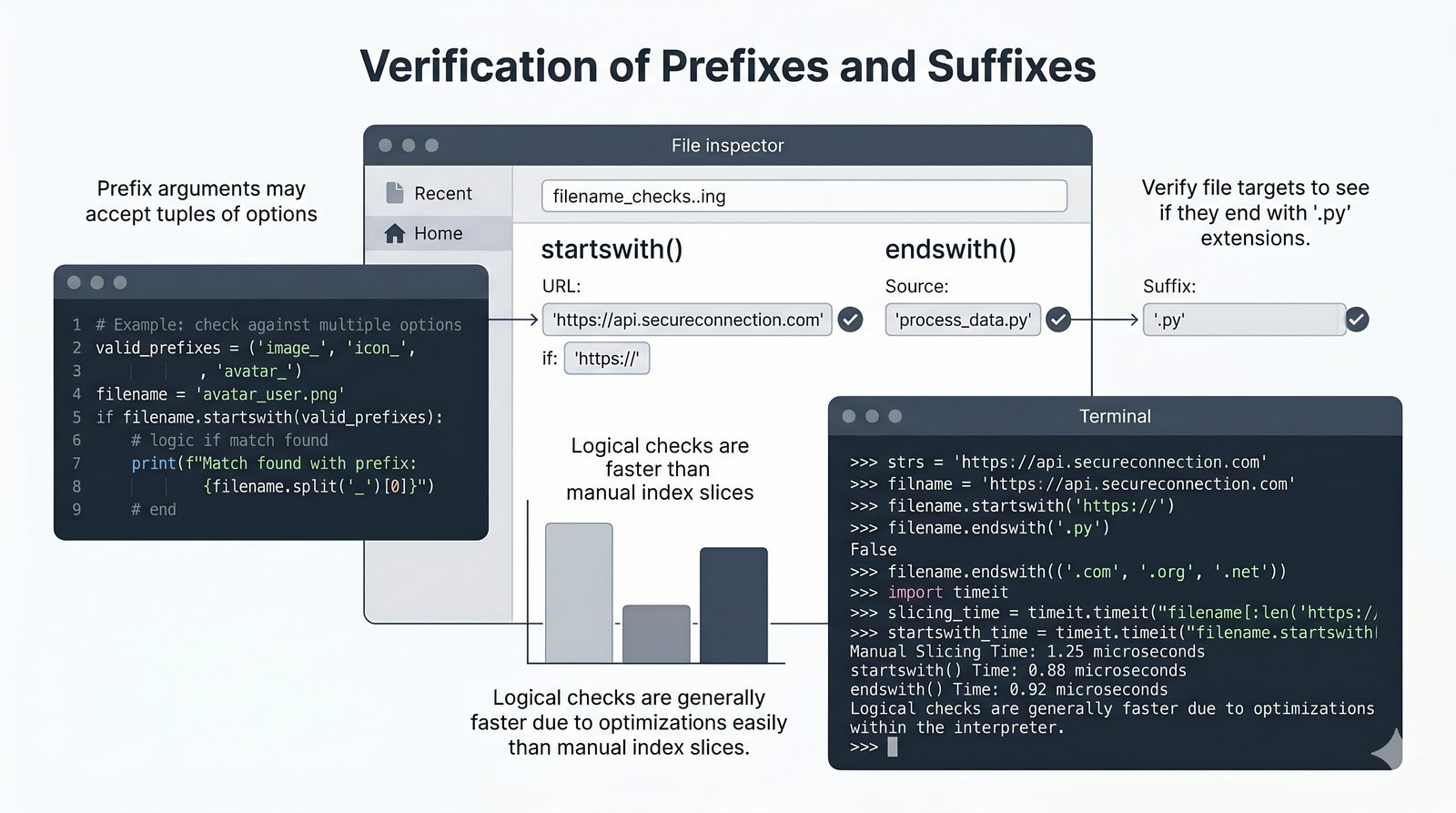
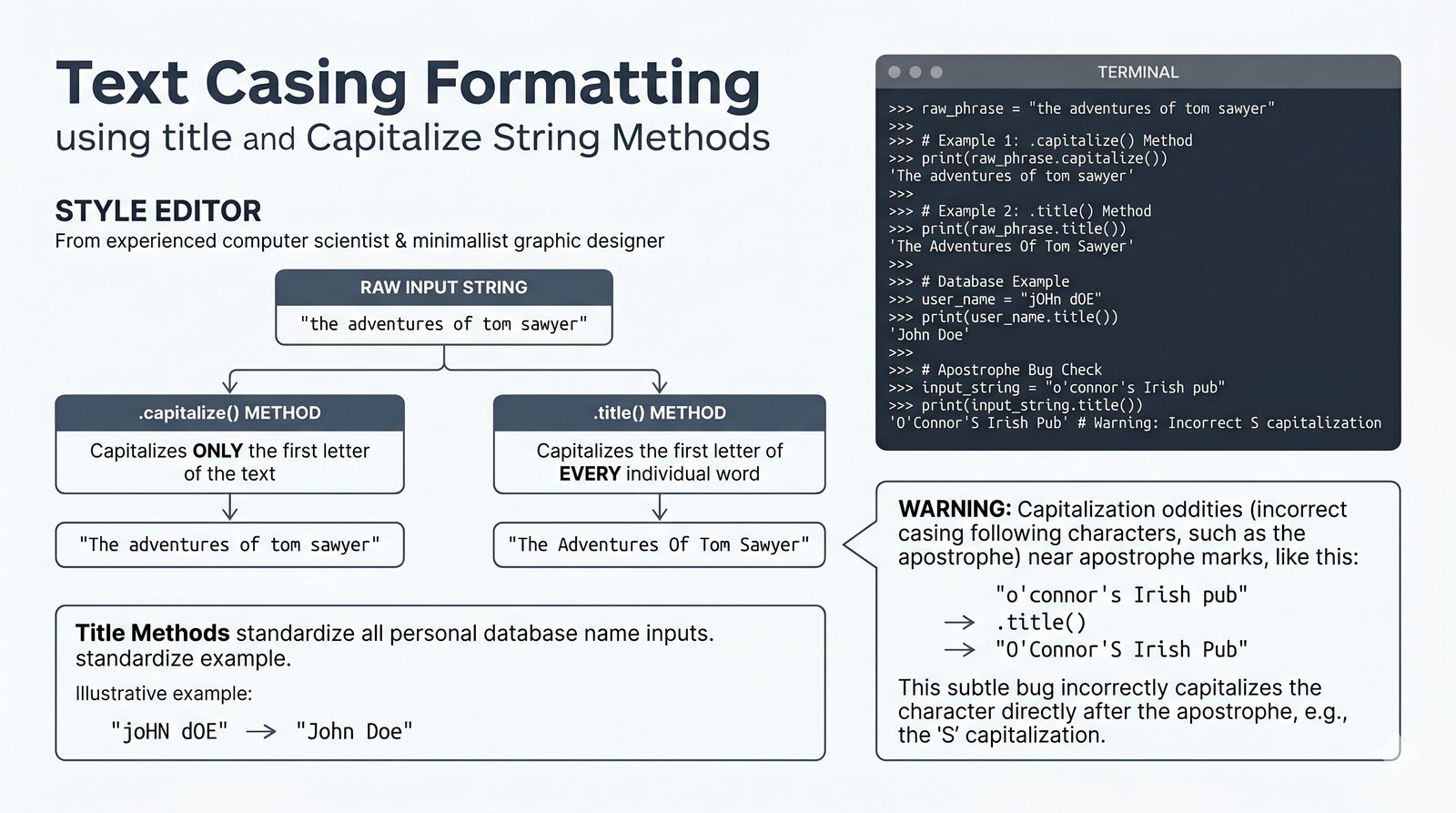
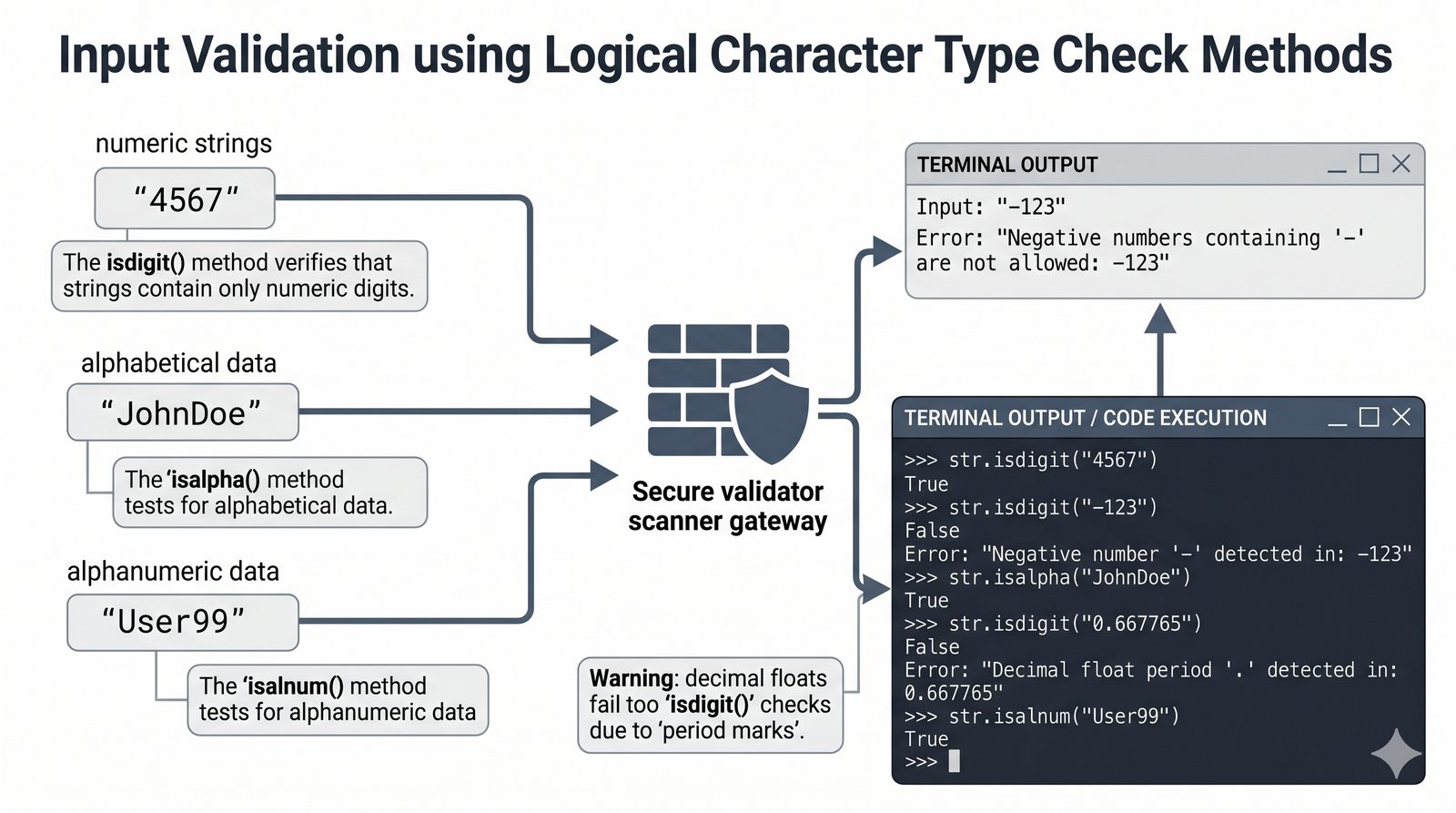
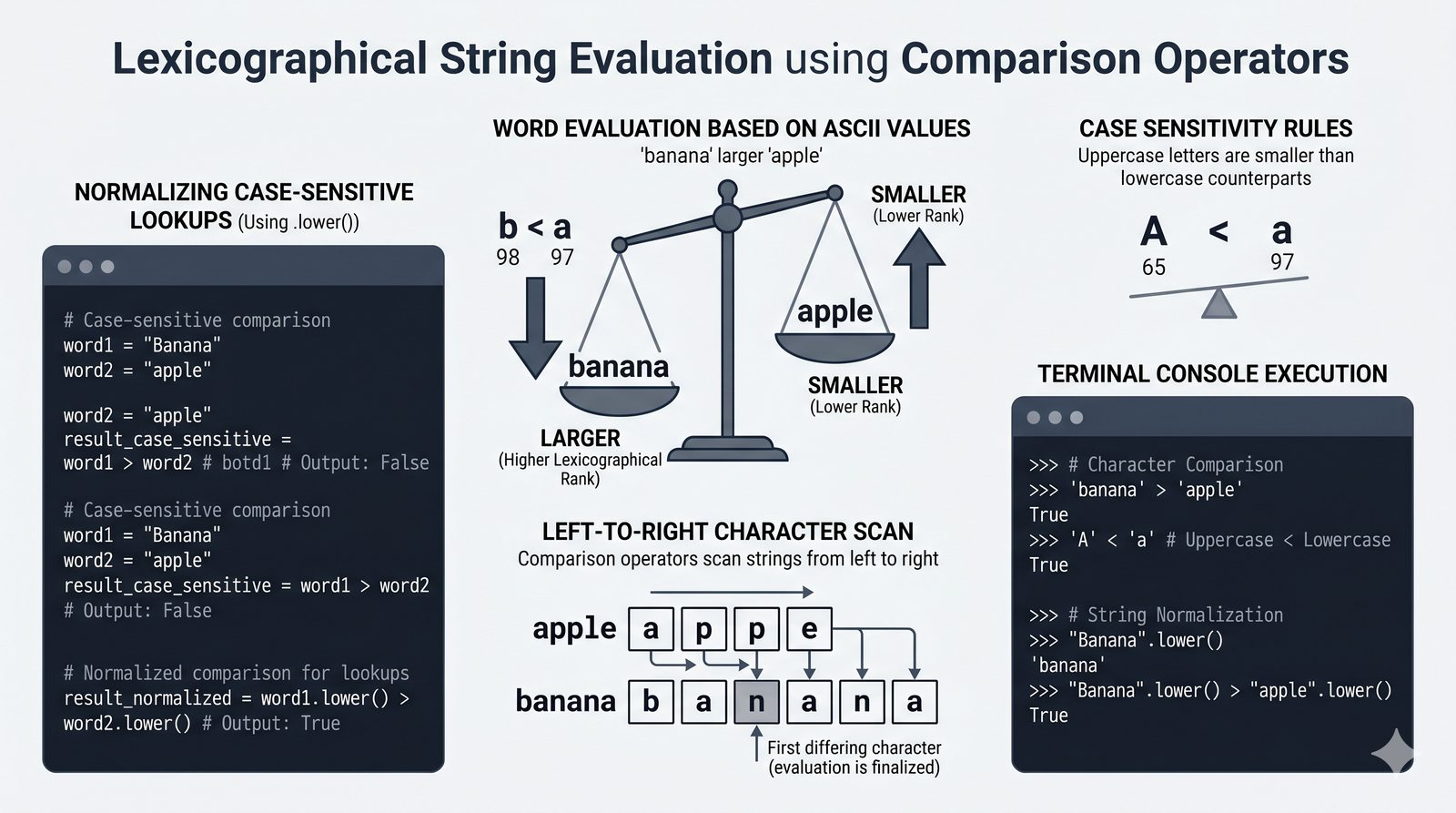
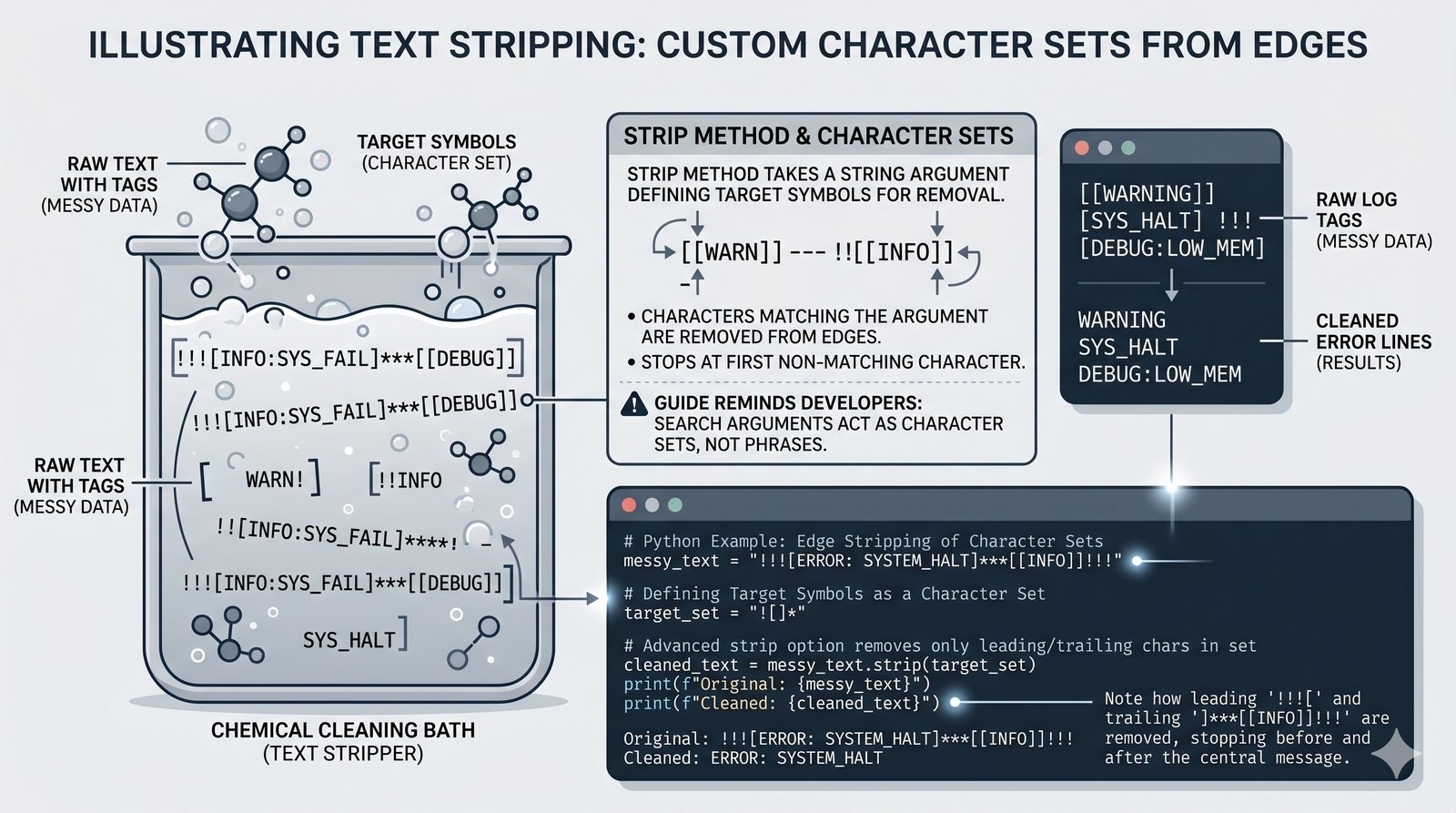
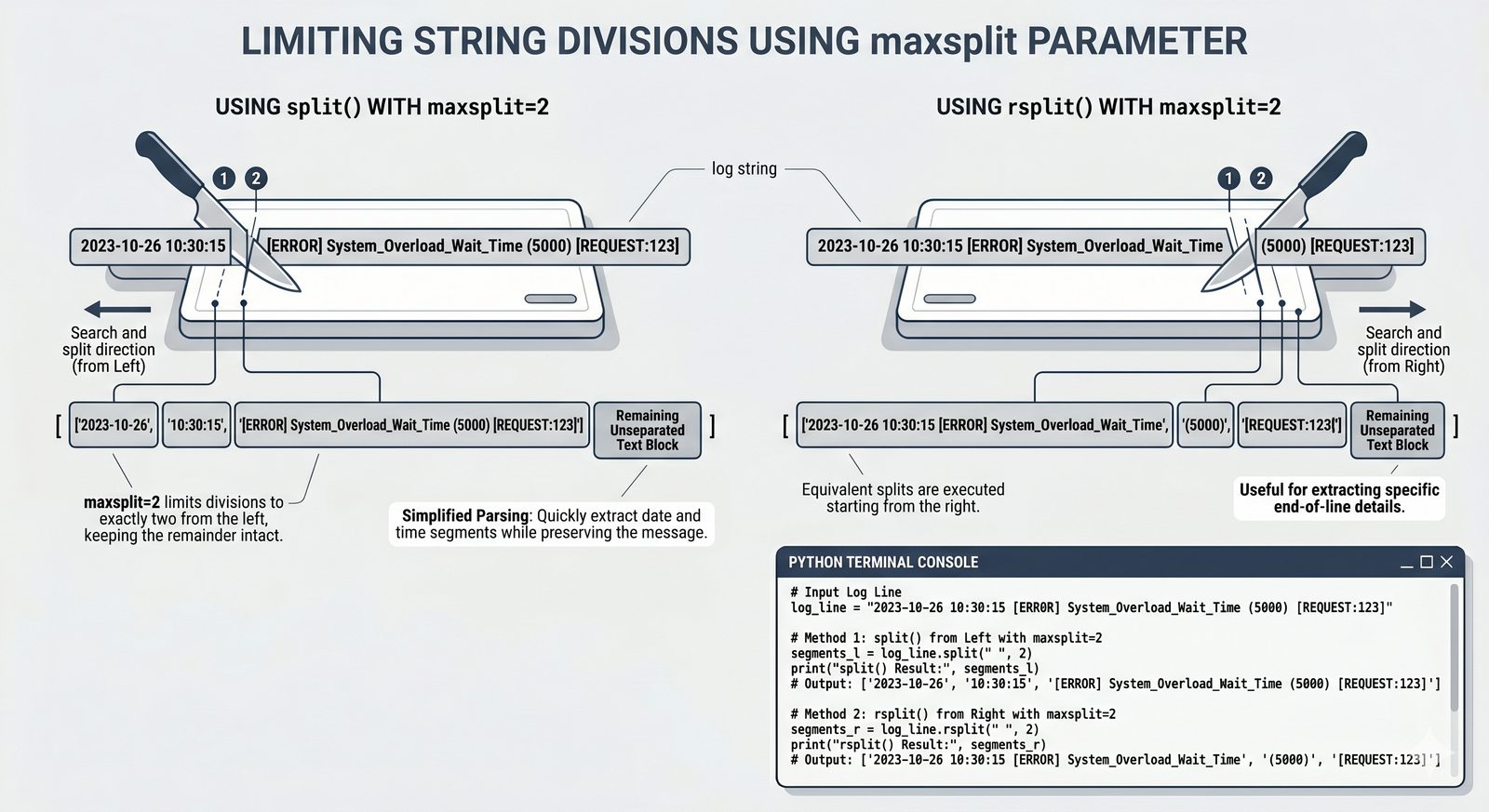
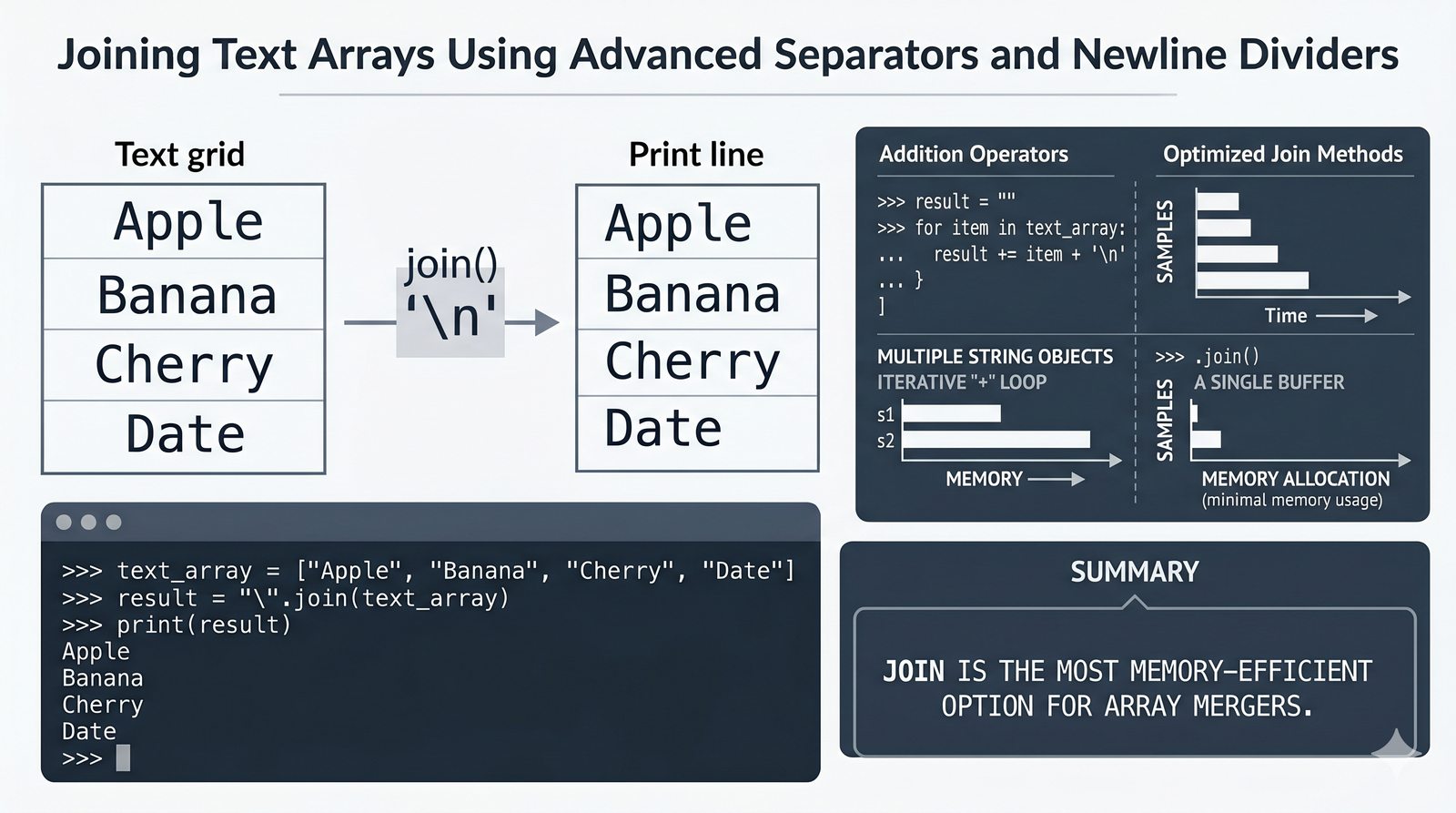
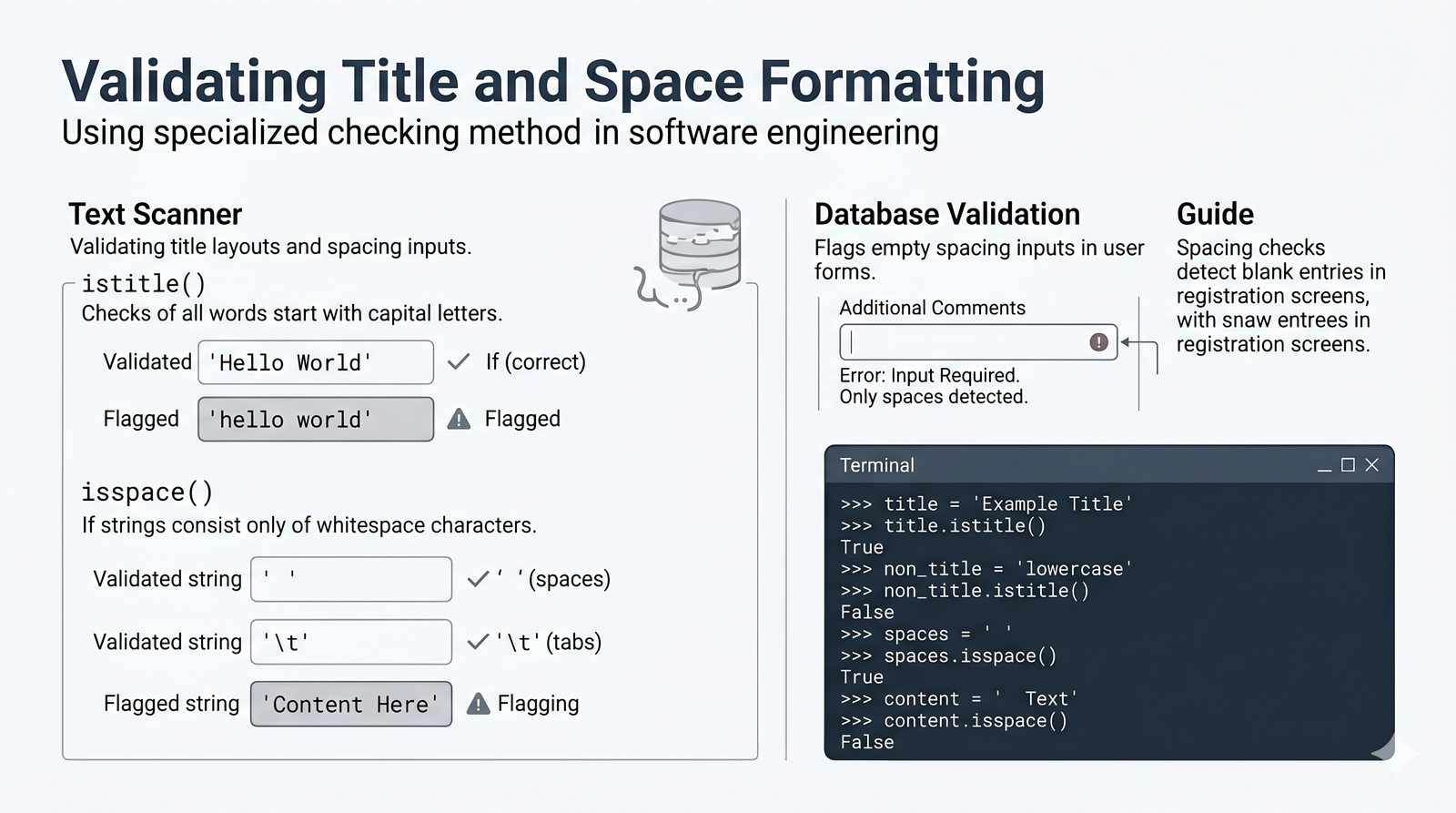
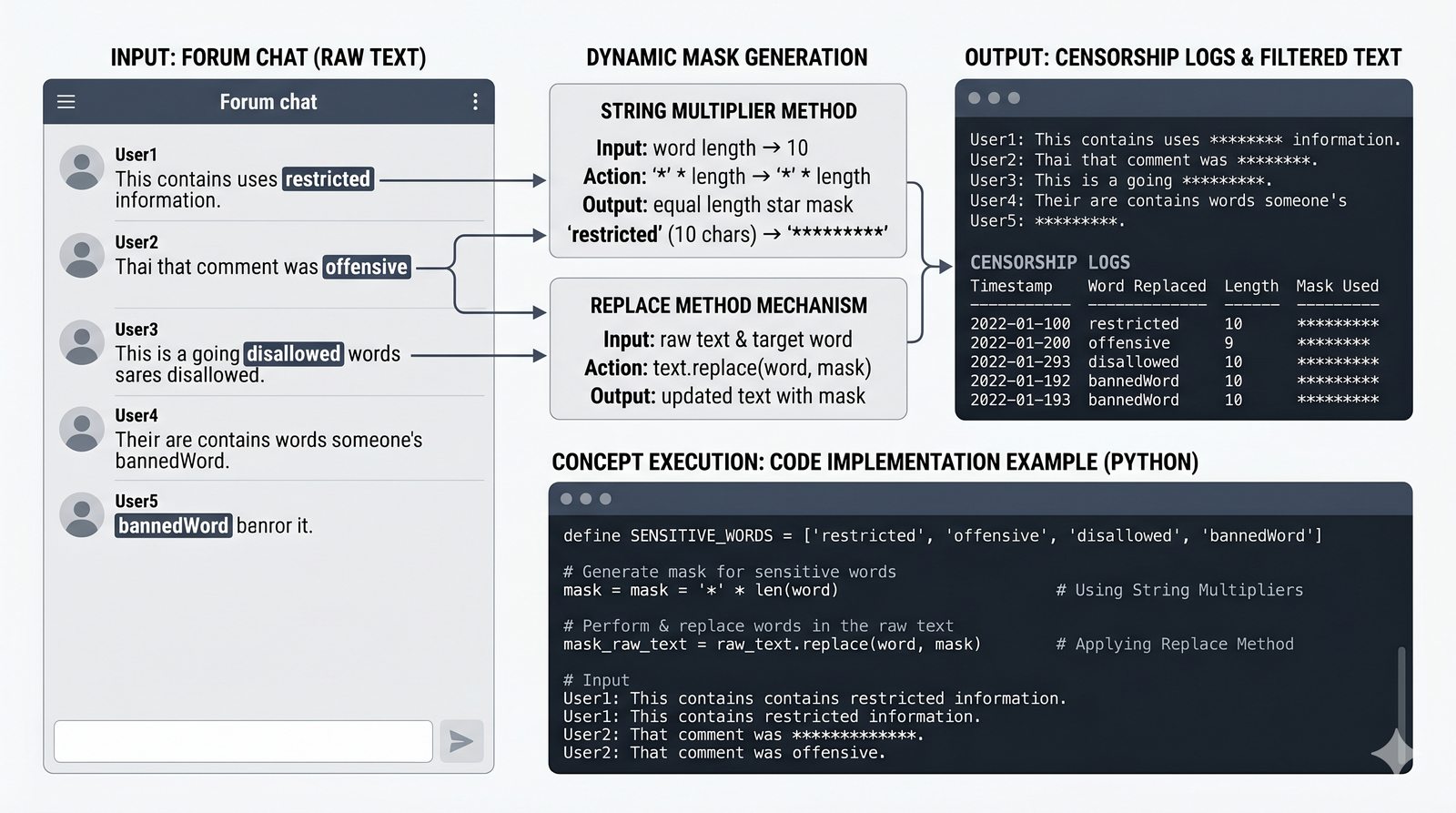
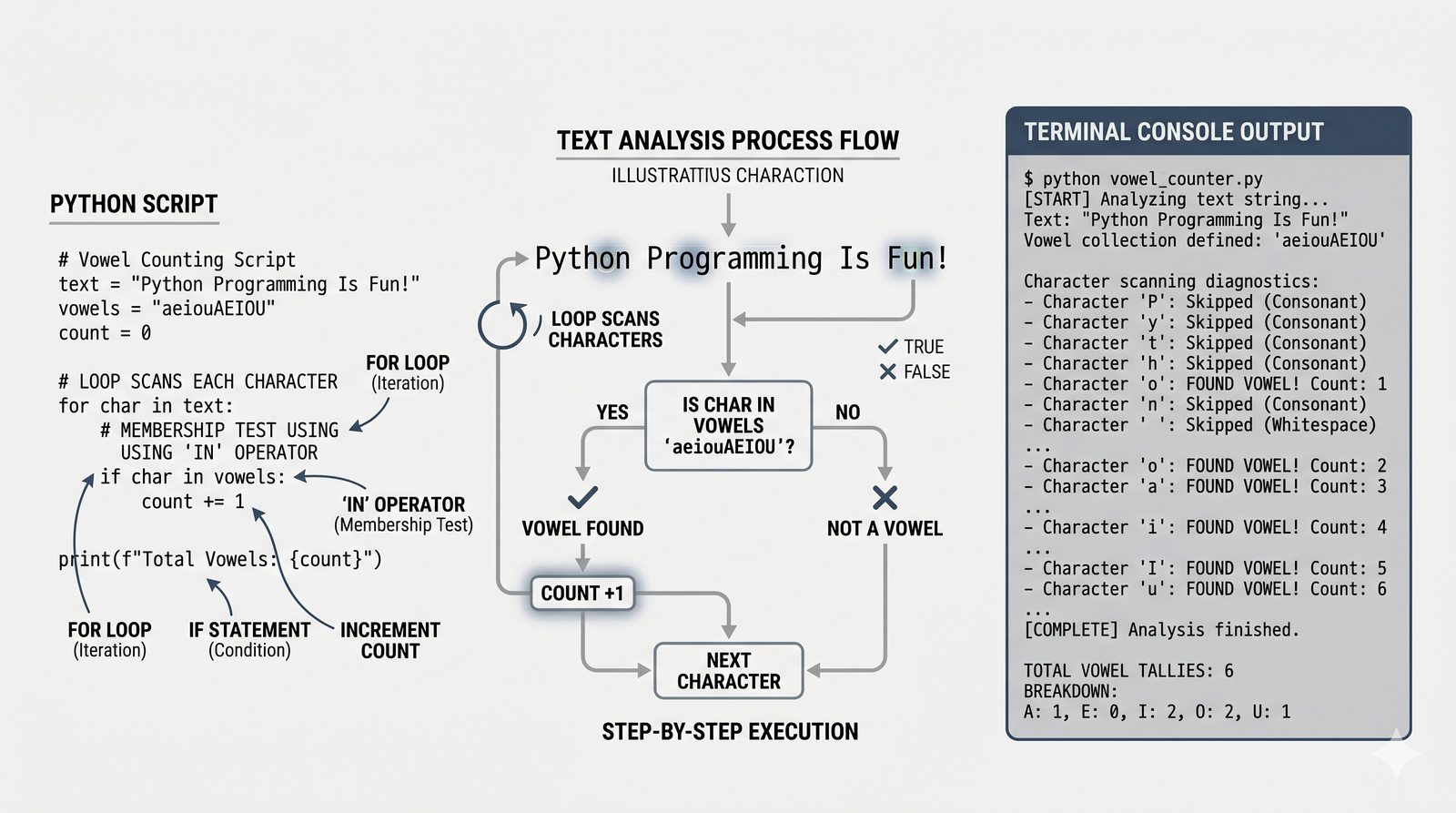
- Wbudowane metody tekstowe — split(), join(), replace(), strip(), upper(), lower(), find(), count() i inne do transformacji i wyszukiwania danych
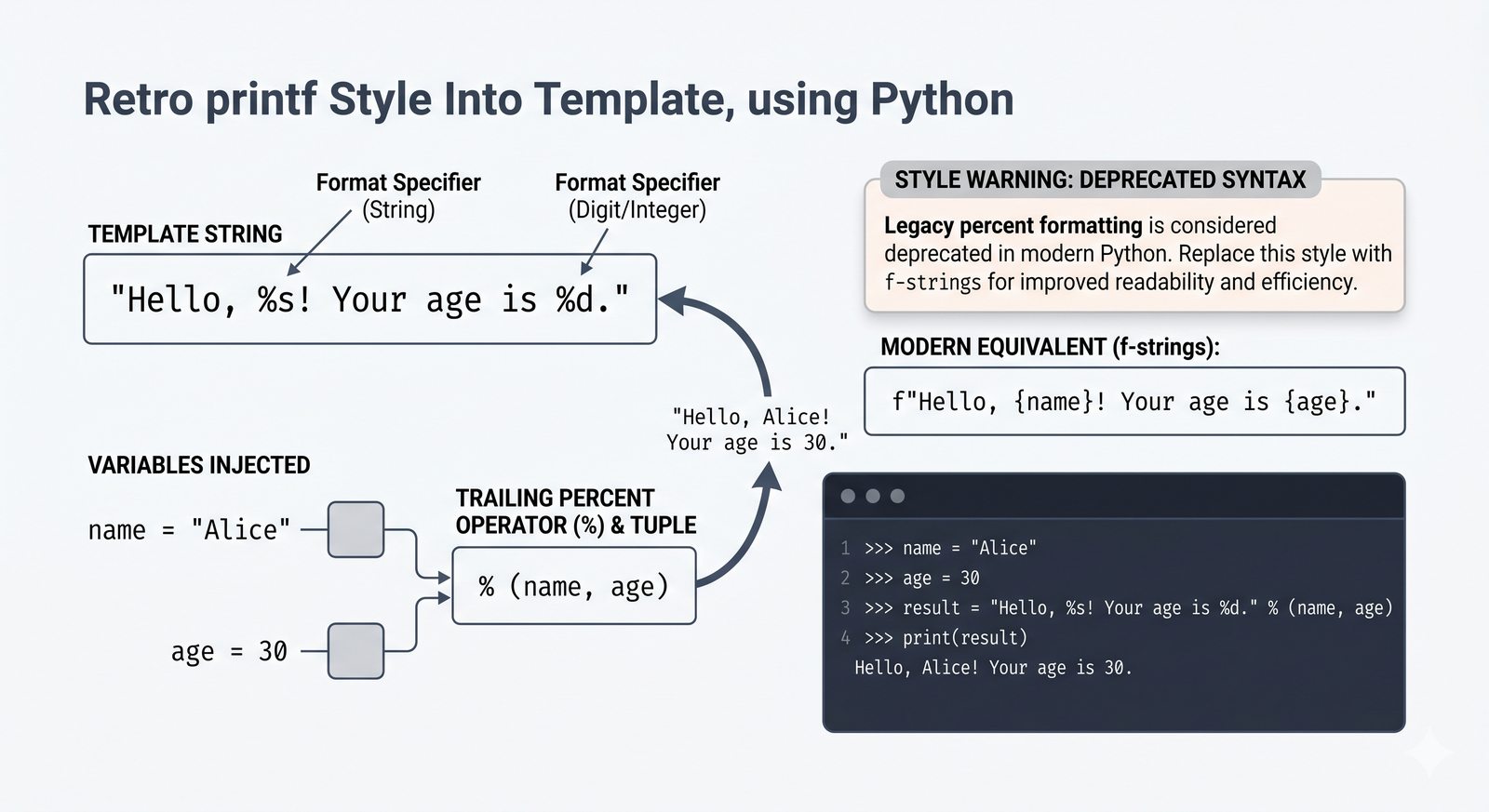
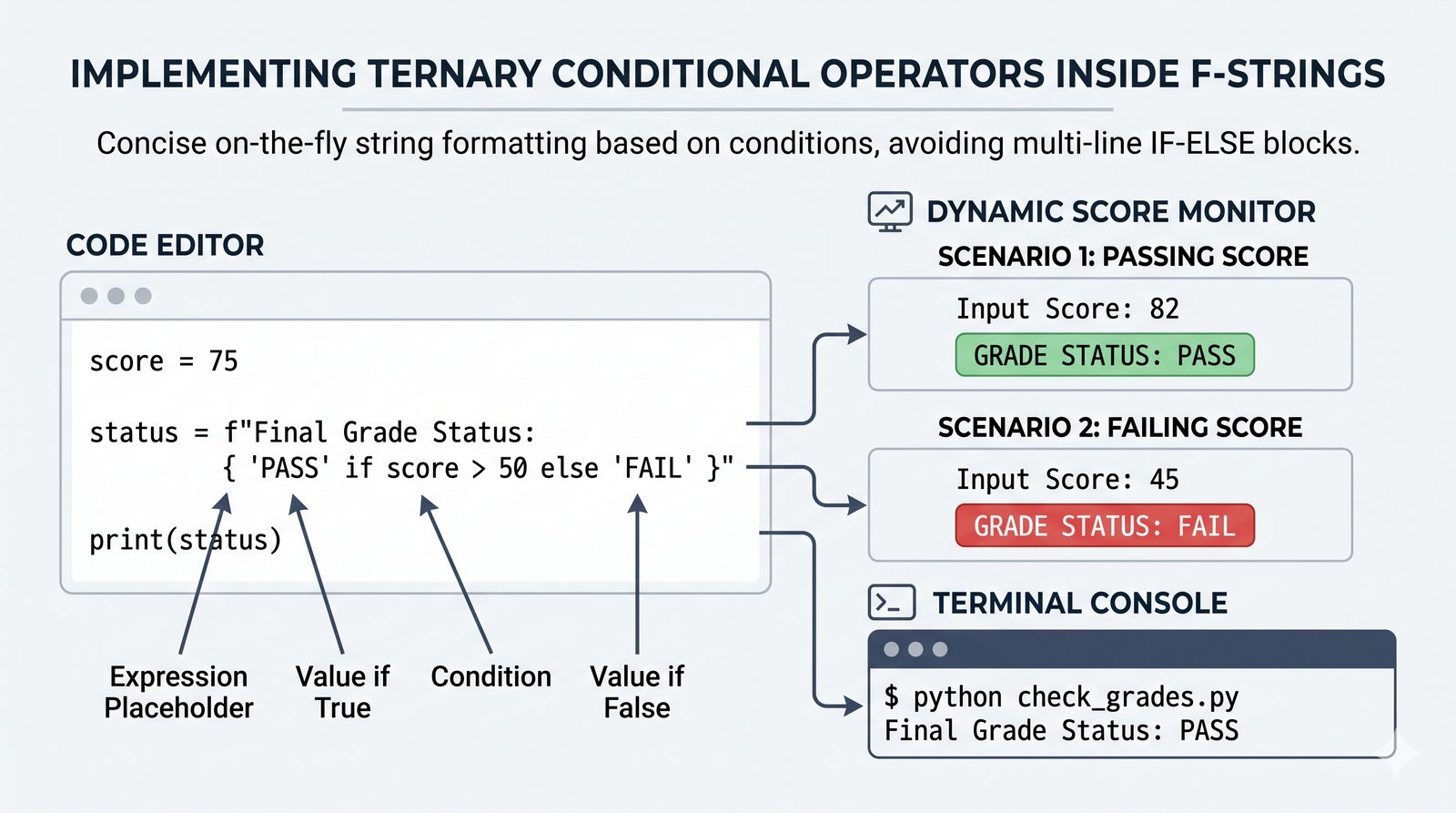
- Nowoczesne formatowanie tekstu — operator %, metoda format() i f-stringi z wyrażeniami, formatowaniem liczb oraz wyrównaniem do boków
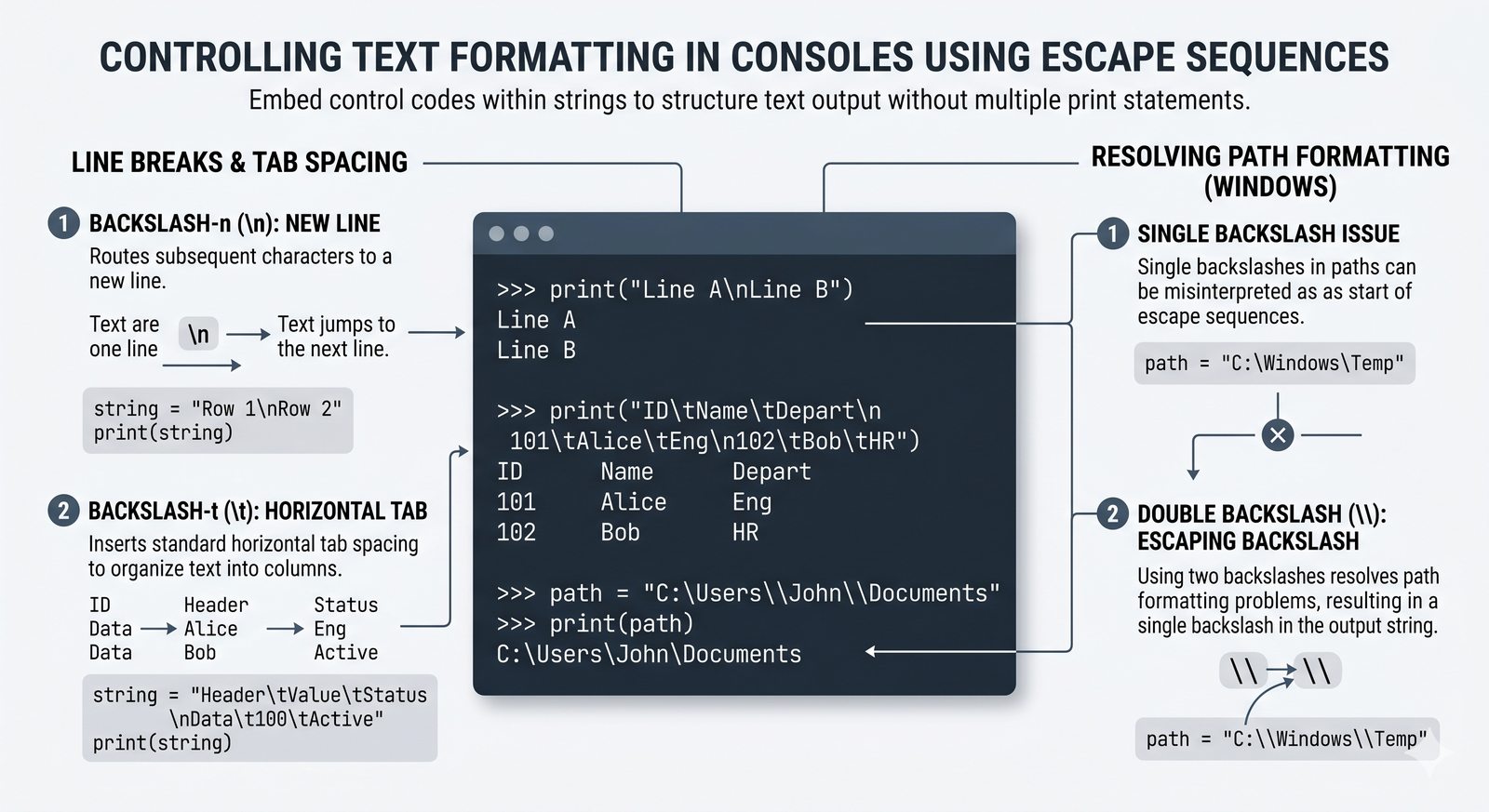
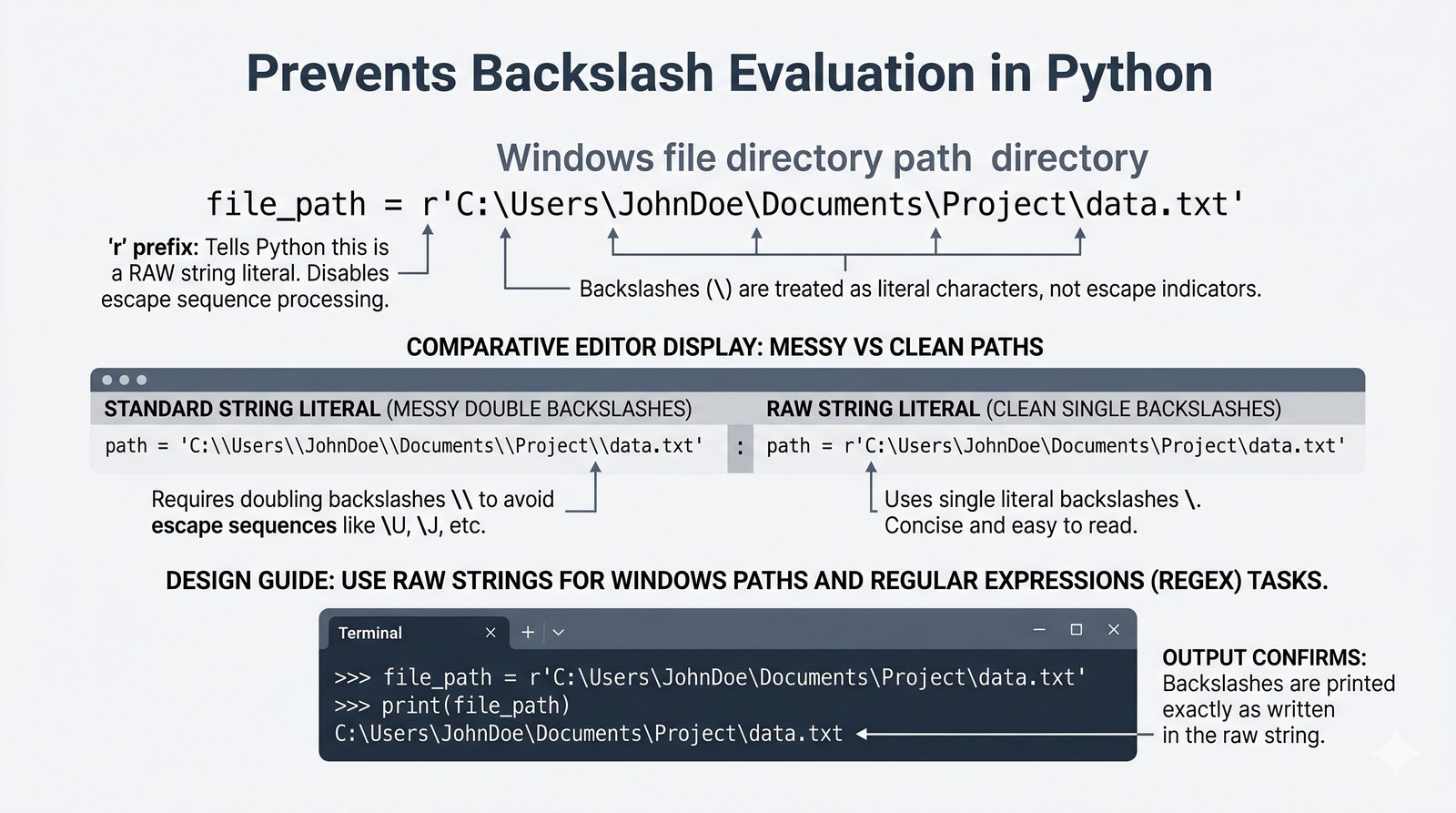
- Znaki specjalne i raw stringi — sekwencje ucieczki \n, \t, \\ oraz surowe napisy r"" do pracy ze ścieżkami i wyrażeniami regularnymi
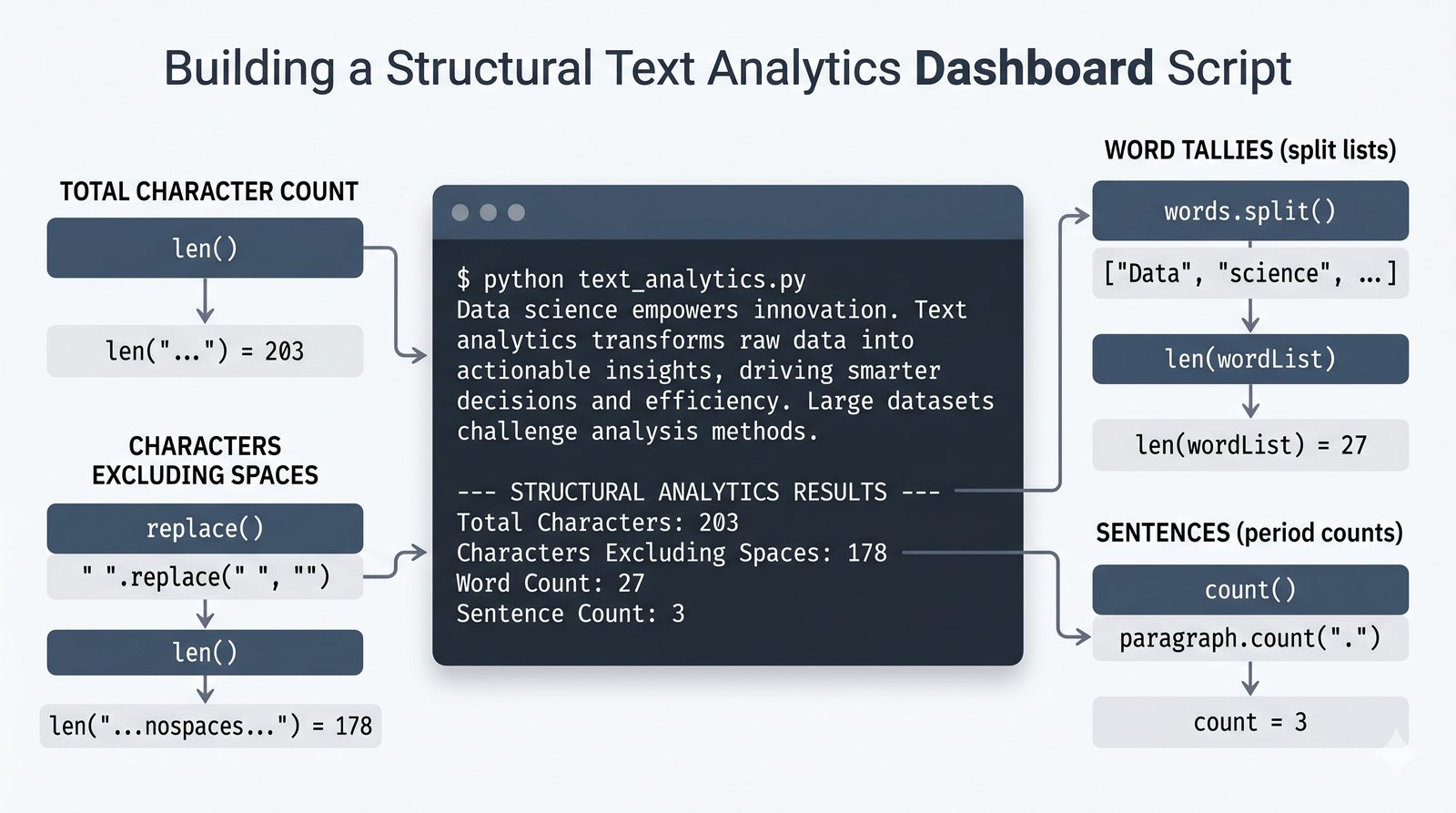
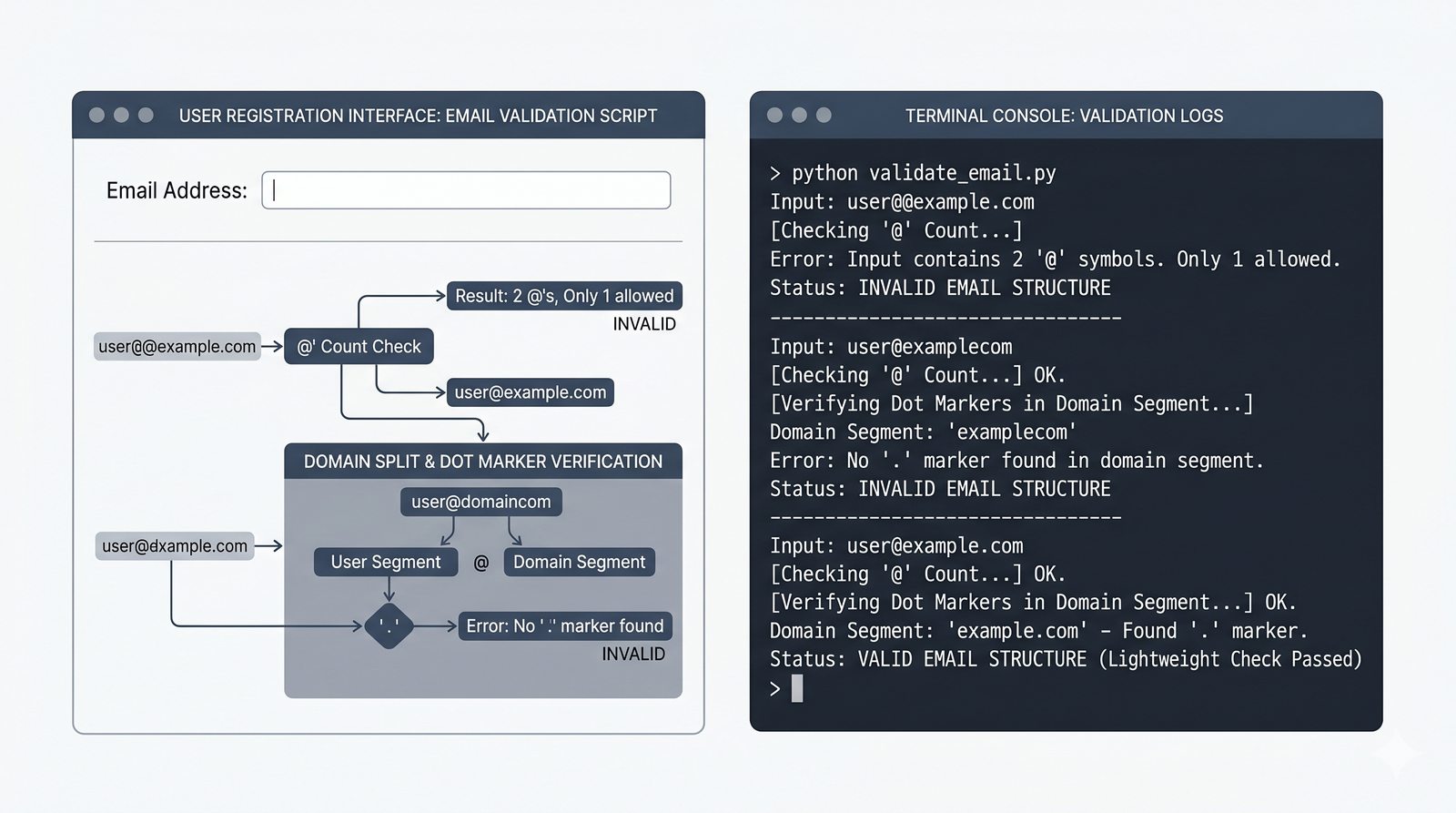
- Programy i ćwiczenia praktyczne — analizator tekstu, walidator e-mail, formatowanie raportów, odwracanie słów, palindrom i cenzurowanie tekstu