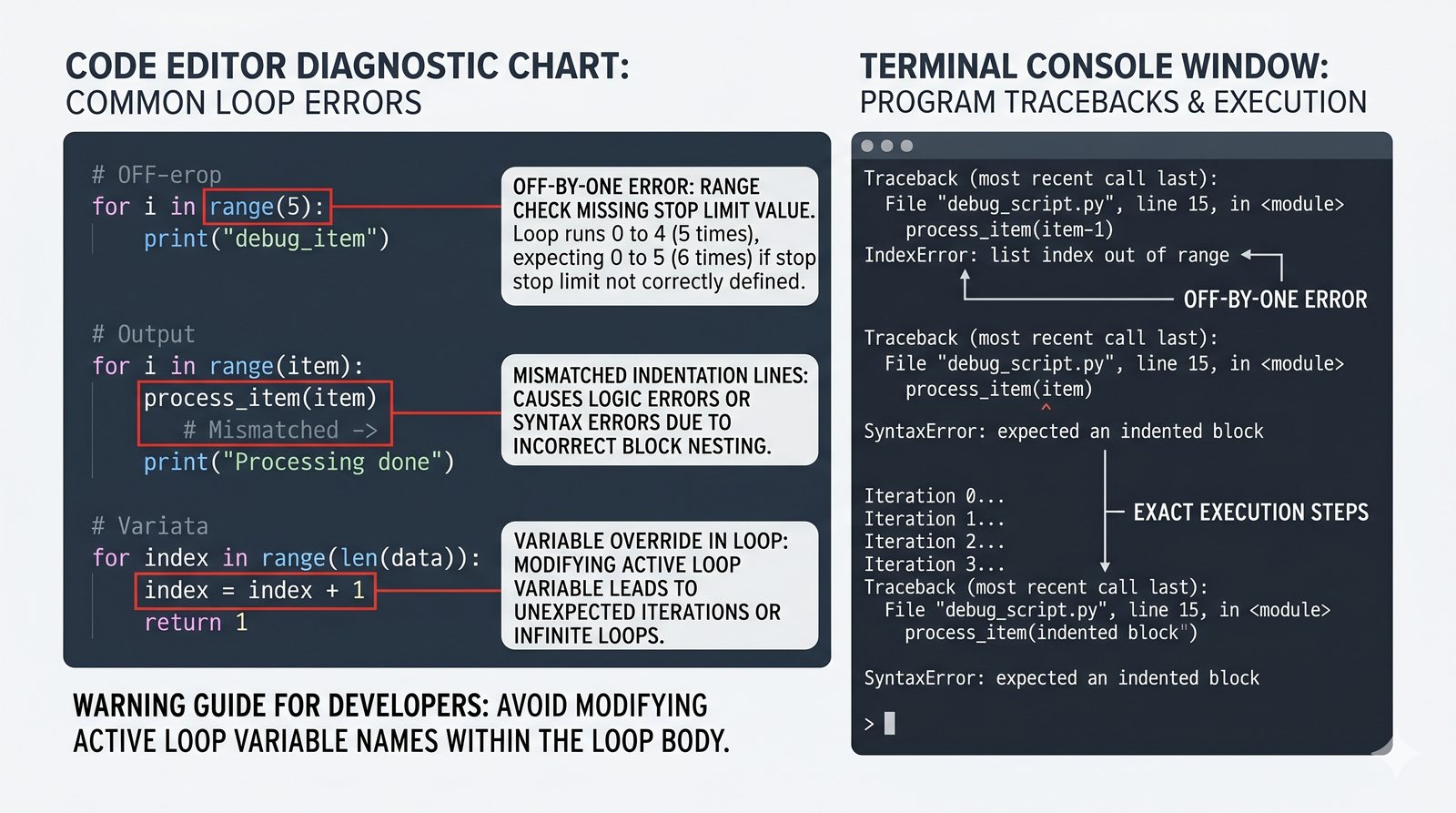
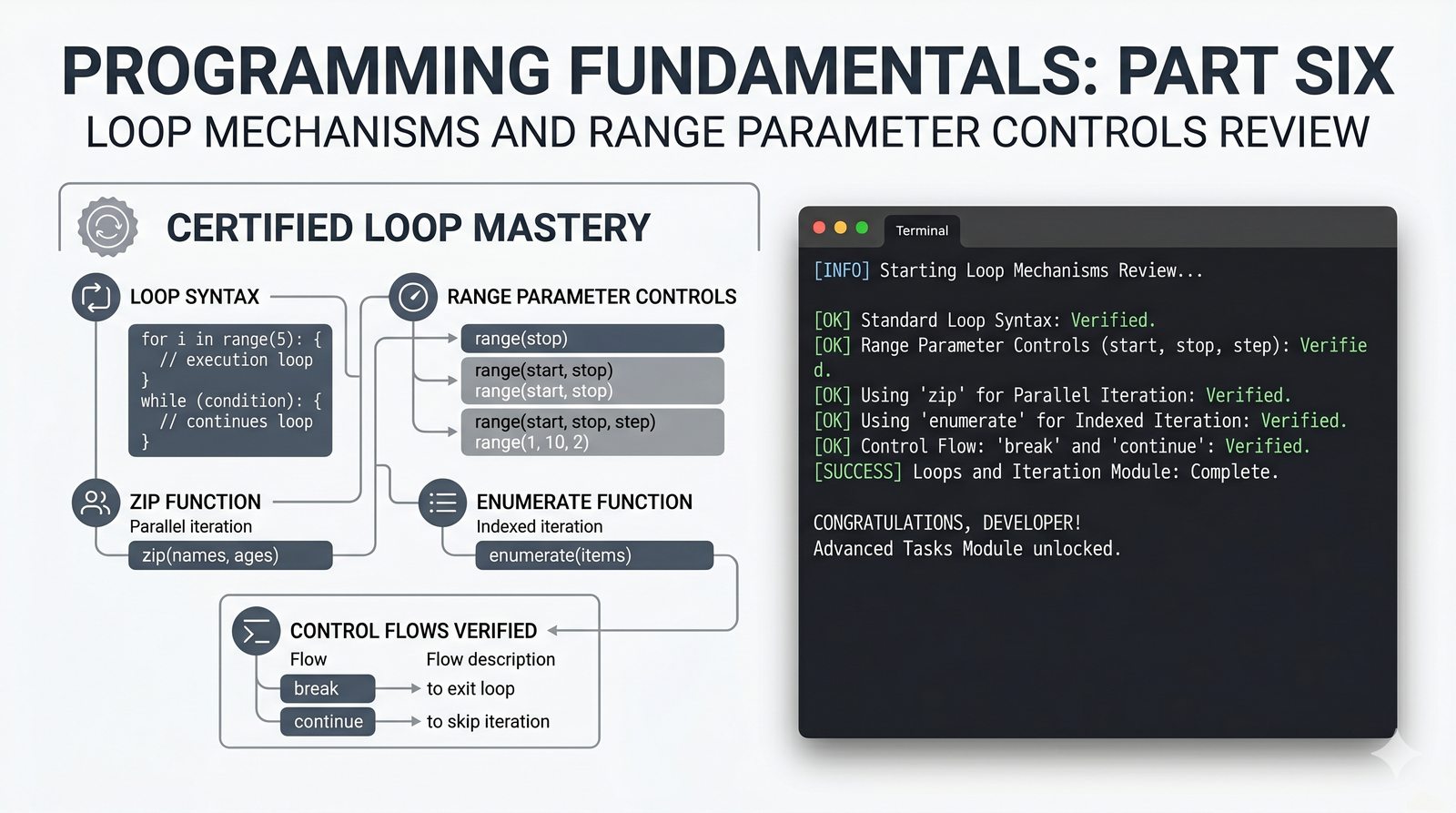
Moduł szczegółowo omawia pętlę for w Pythonie – od podstawowej składni i iterowania po listach, napisach oraz słownikach, aż po zaawansowane funkcje range(), enumerate() i zip(). Przedstawiono techniki sterowania przepływem pętli, takie jak break, continue oraz unikalną klauzulę else. Osobne slajdy poświęcono funkcjom reversed() i sorted(), zagnieżdżonym pętlom oraz bezpiecznemu modyfikowaniu kolekcji podczas iteracji. Moduł zawiera praktyczne programy (generator grup, statystyki ocen, filtrowanie zakupów, histogram) oraz zestawienie typowych błędów i czterech podstawowych wzorców programistycznych z pętlami.
Kluczowe zagadnienia modułu:
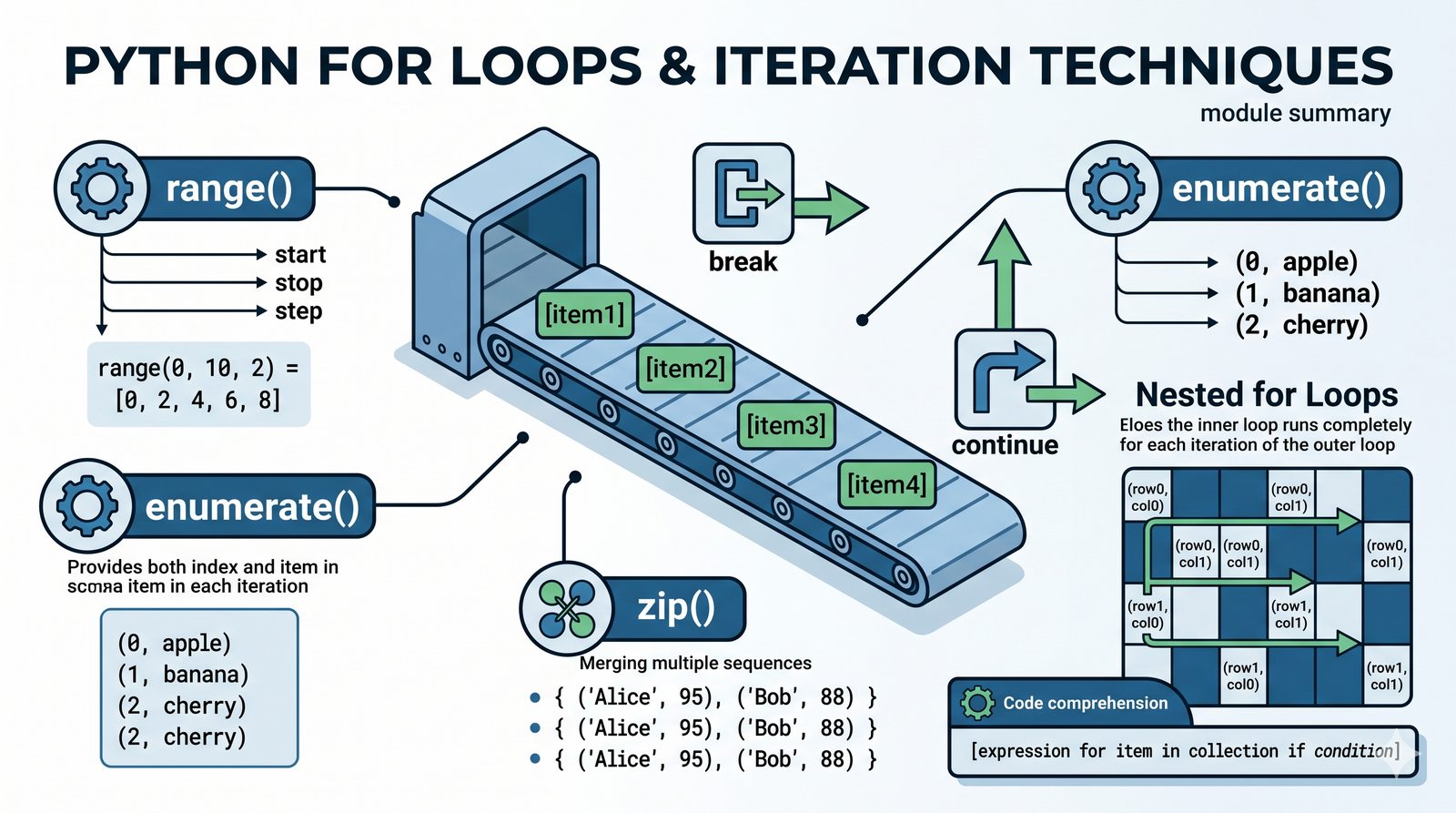
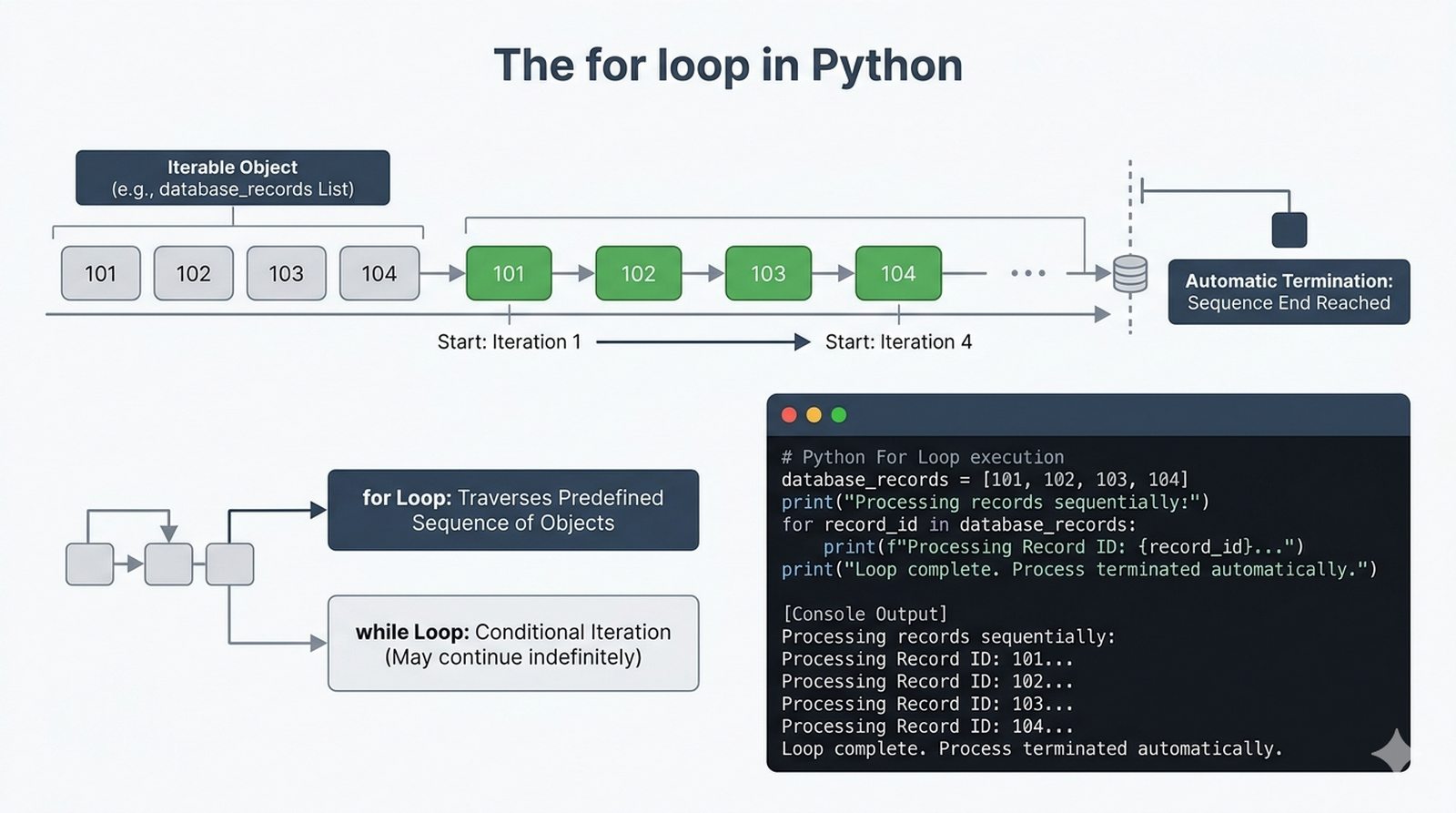
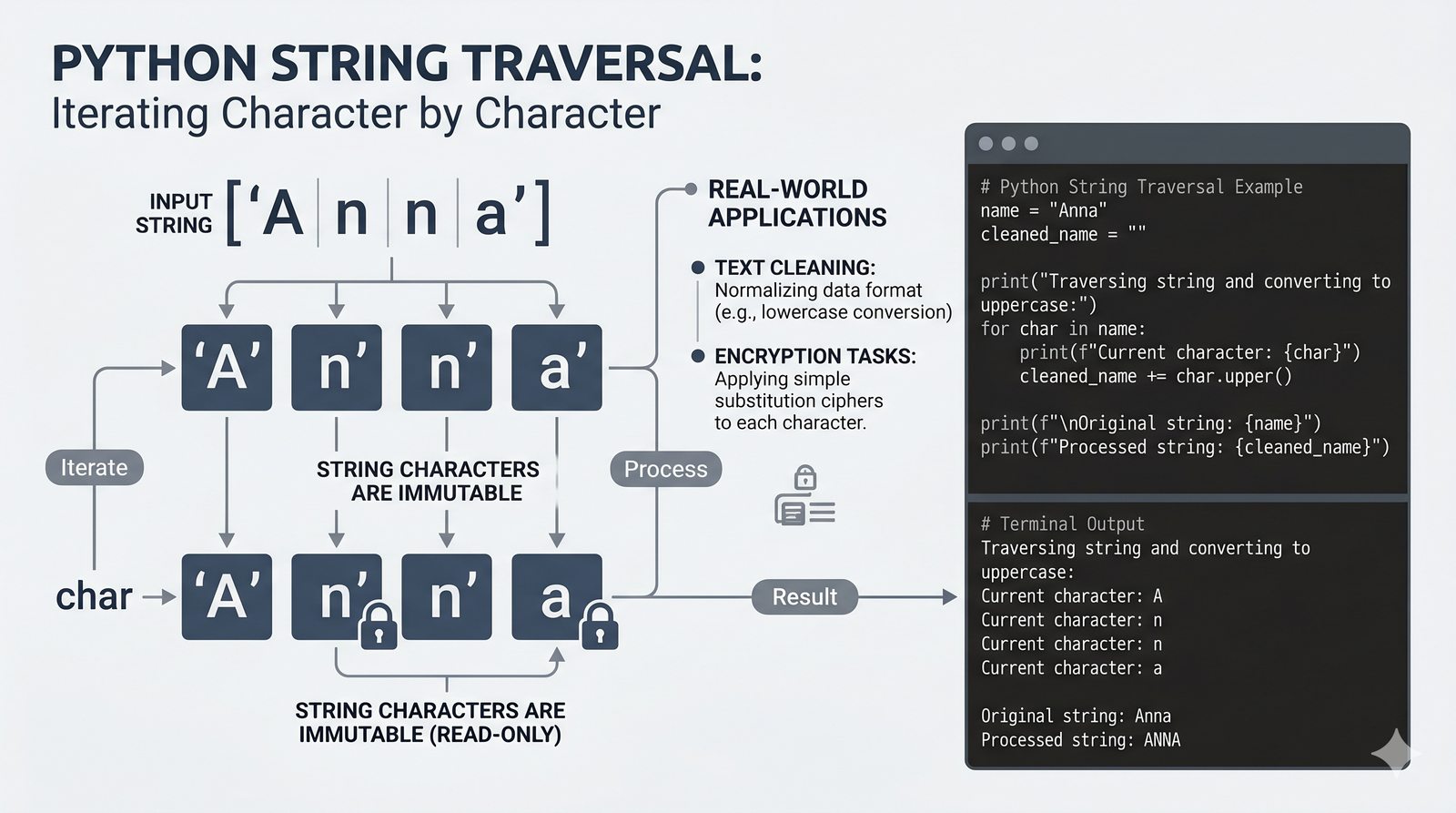
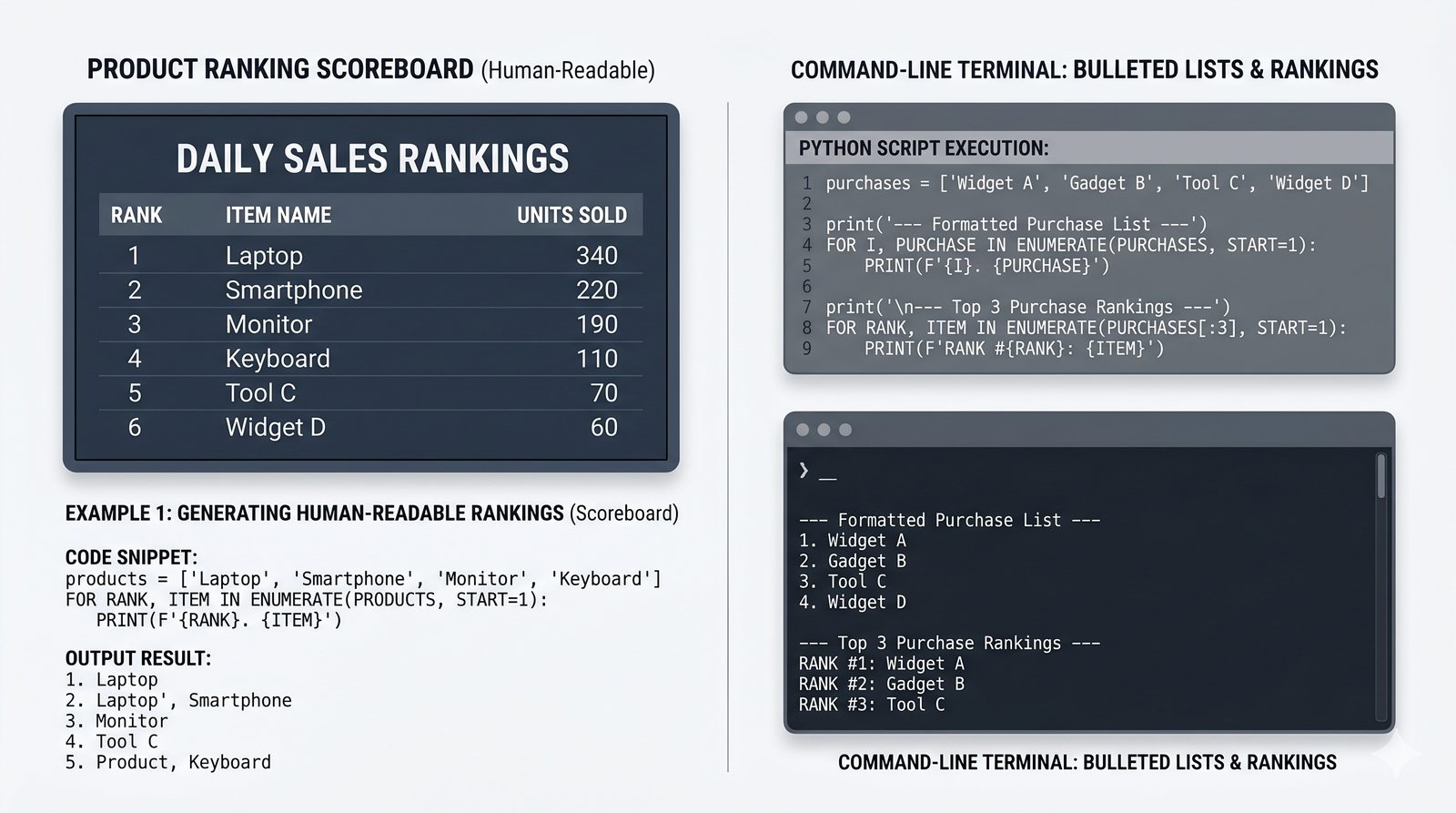
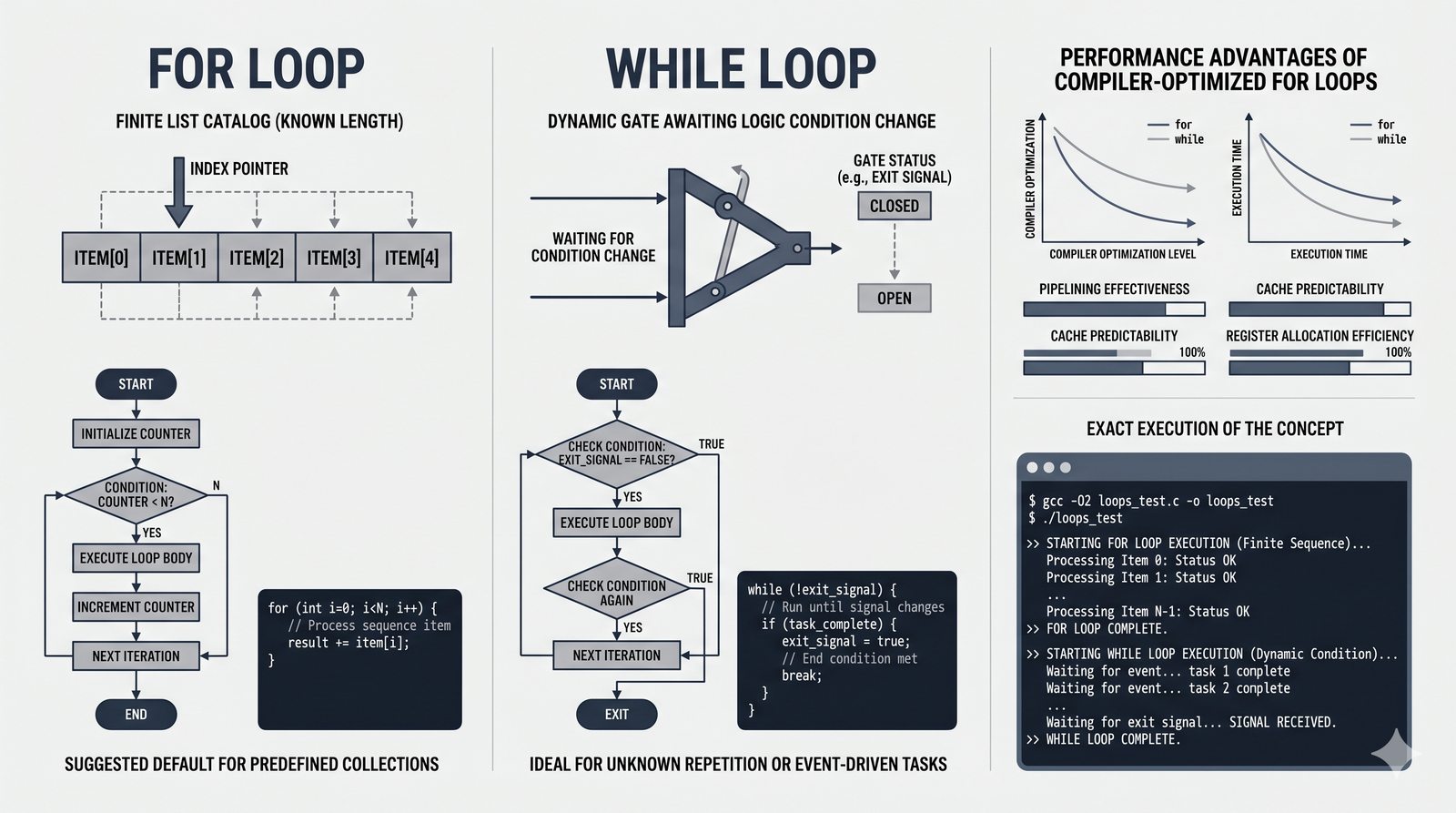
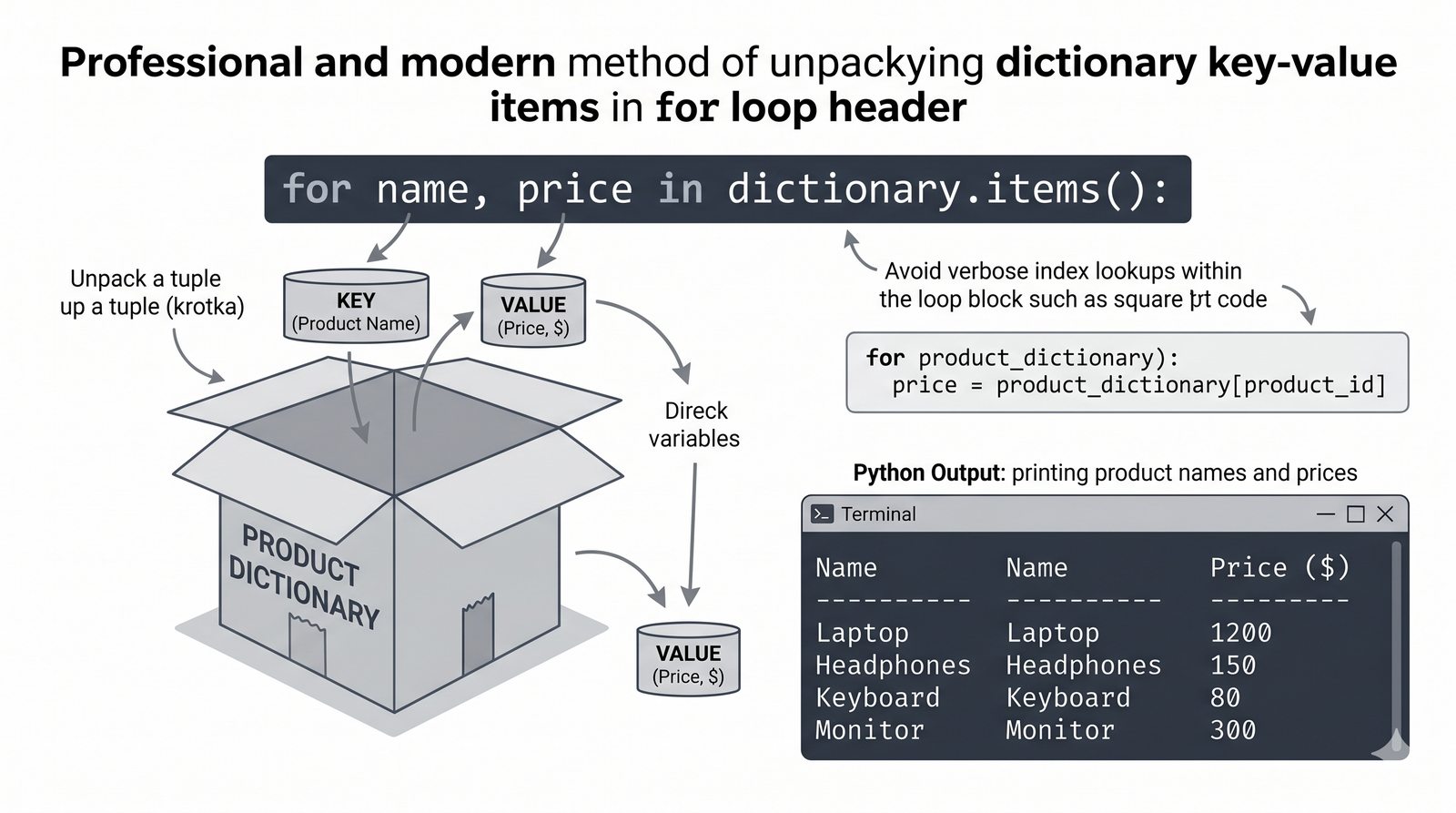
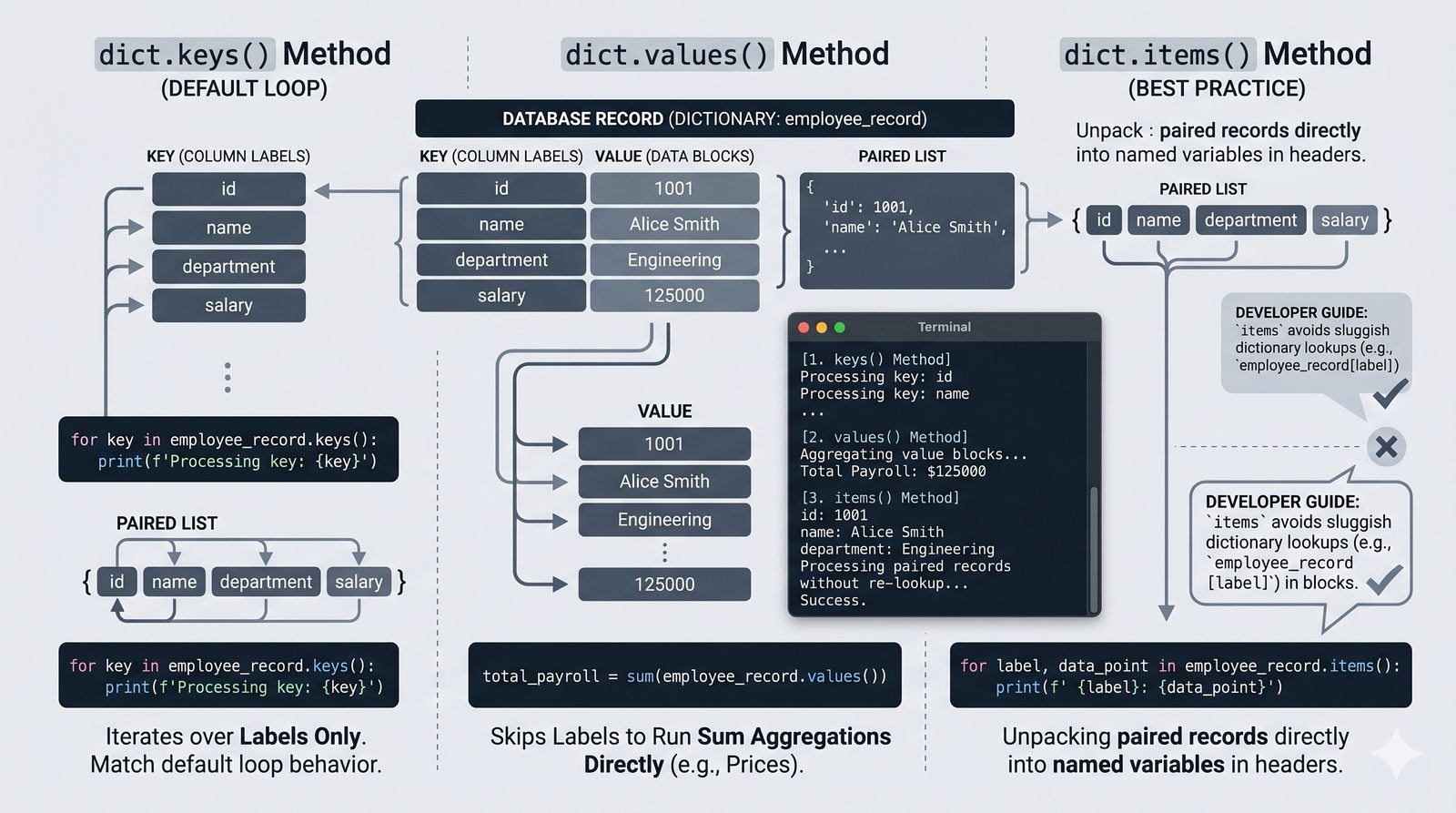
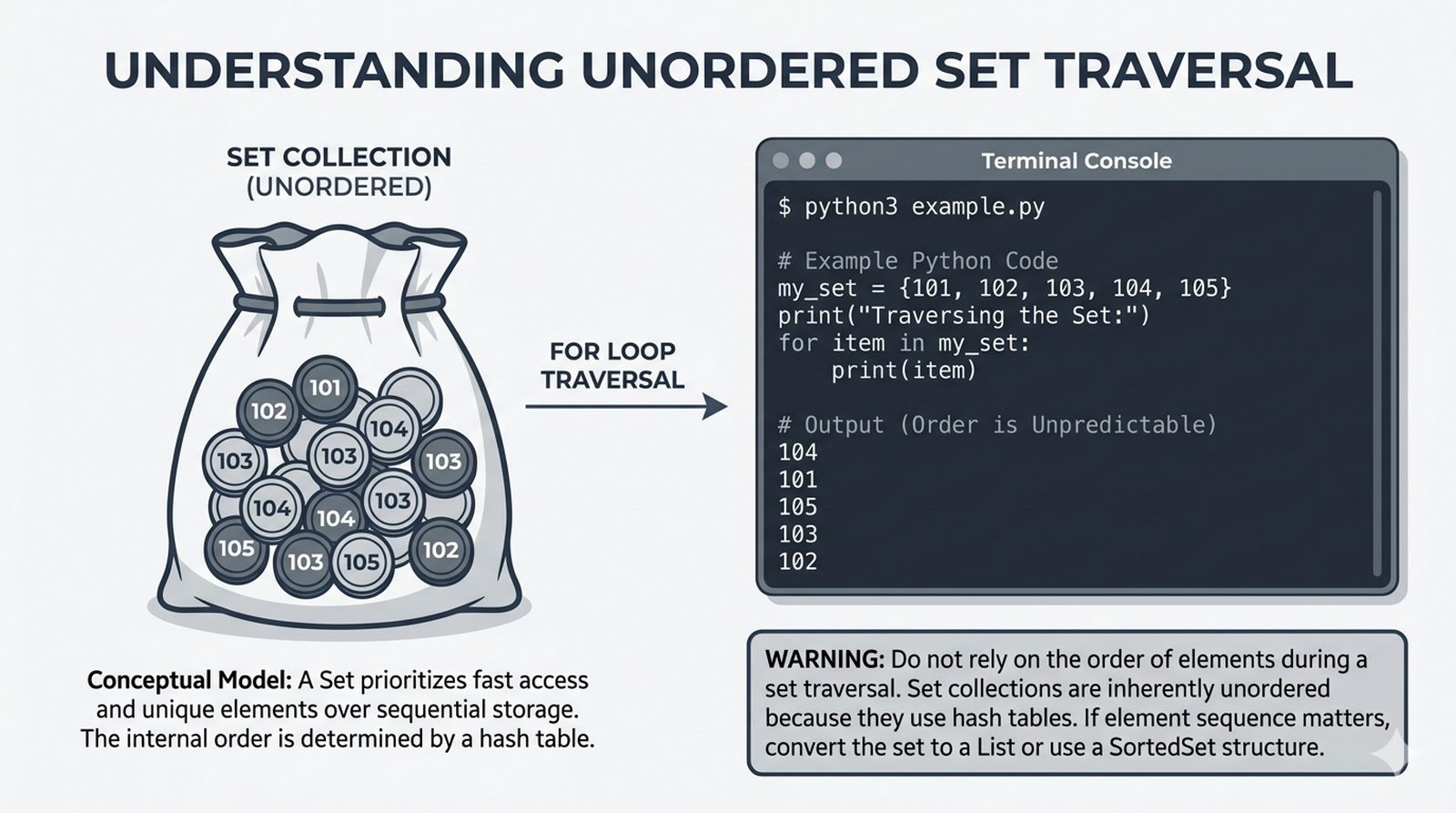
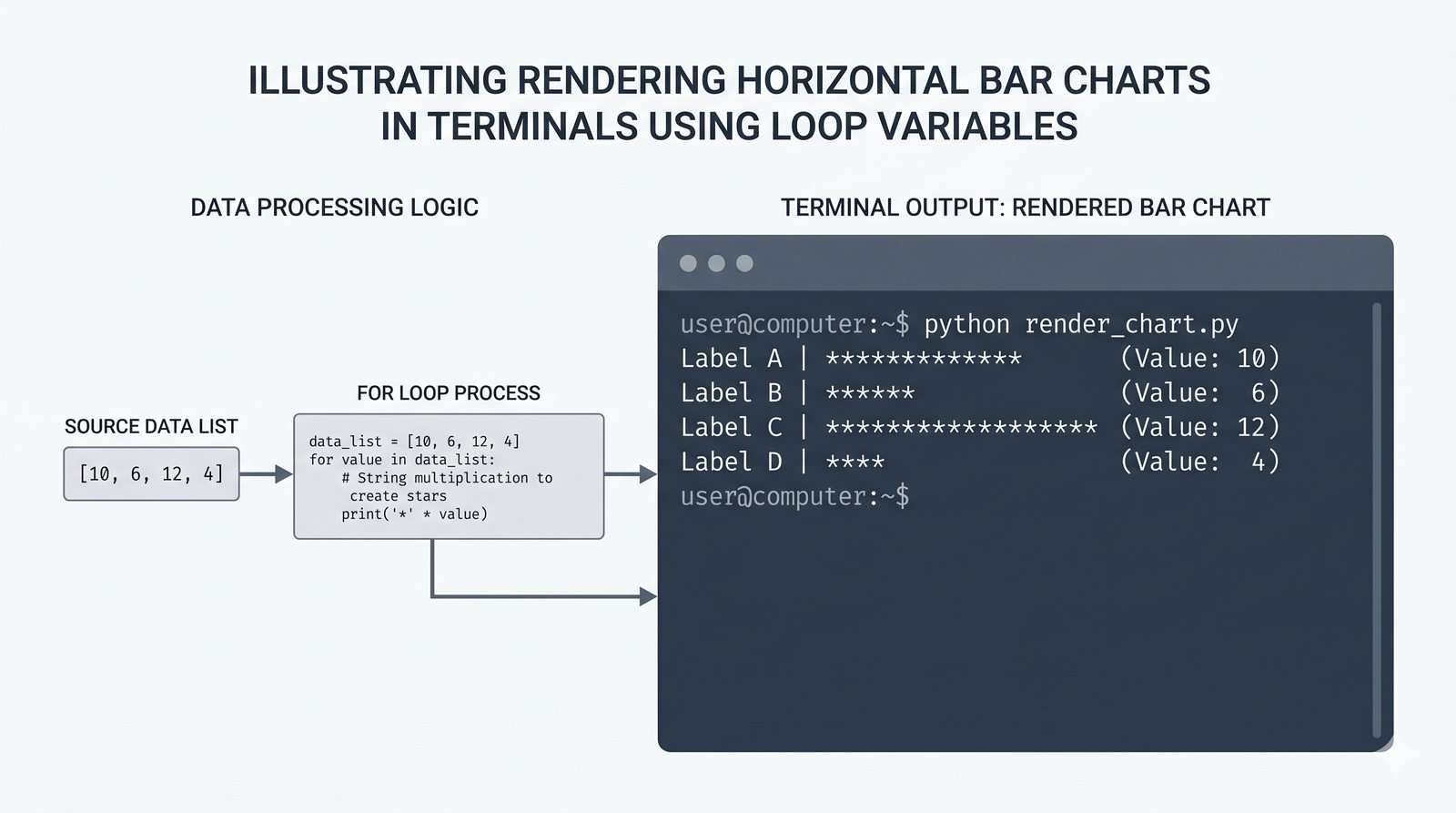
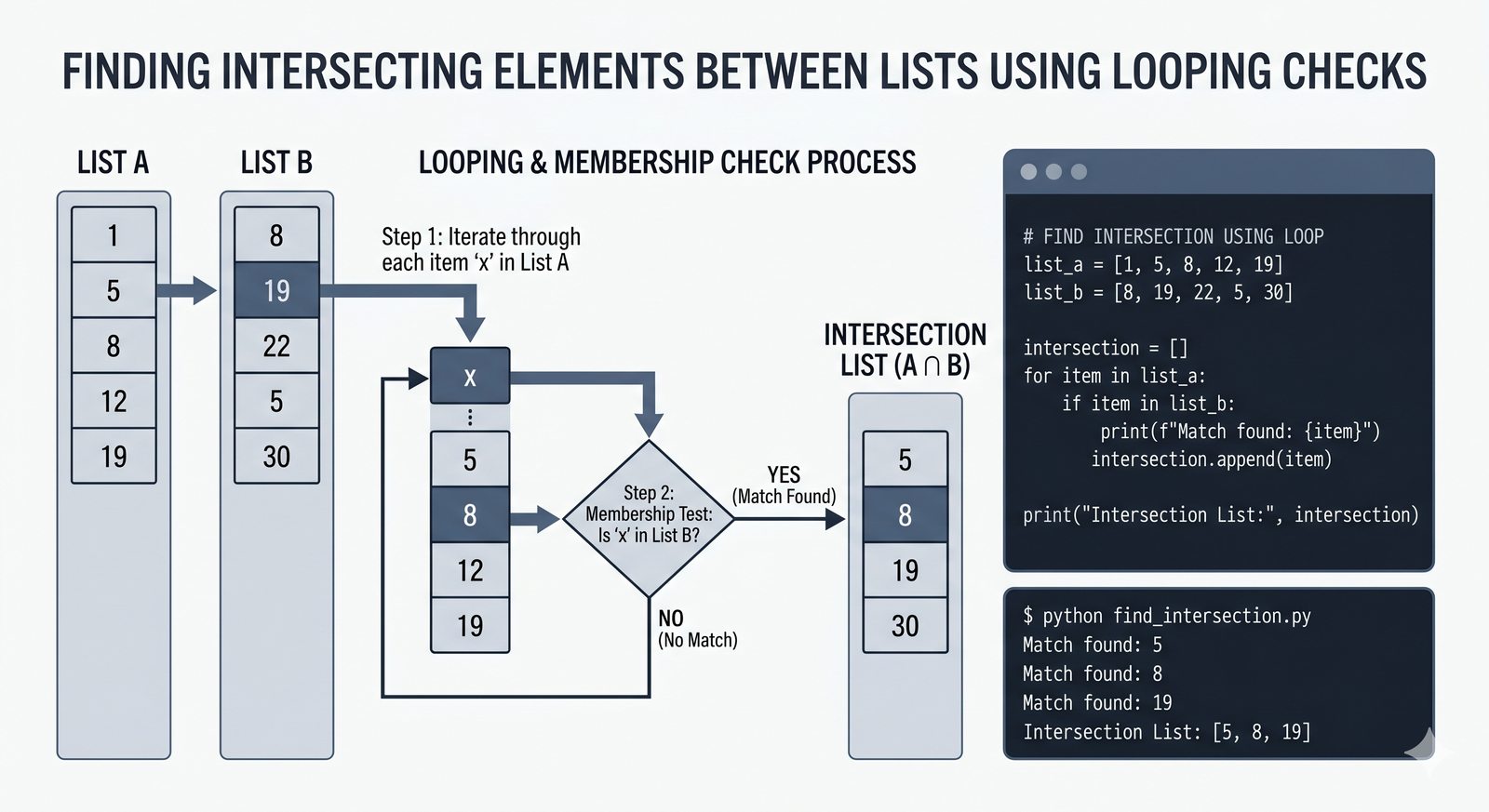
- Pętla for – składnia z dwukropkiem, iterowanie po listach, stringach, słownikach (.keys(), .values(), .items()) i zbiorach
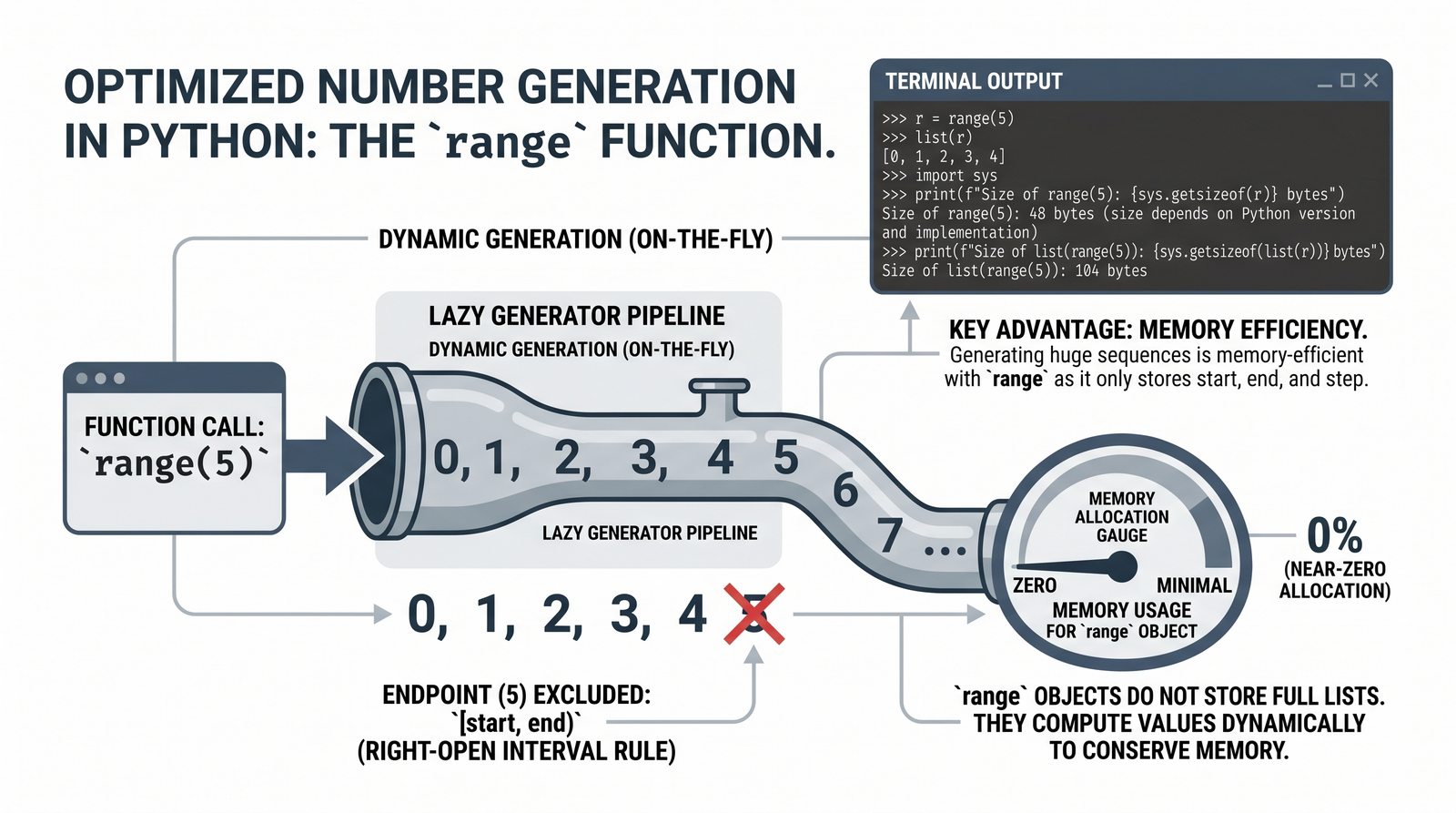
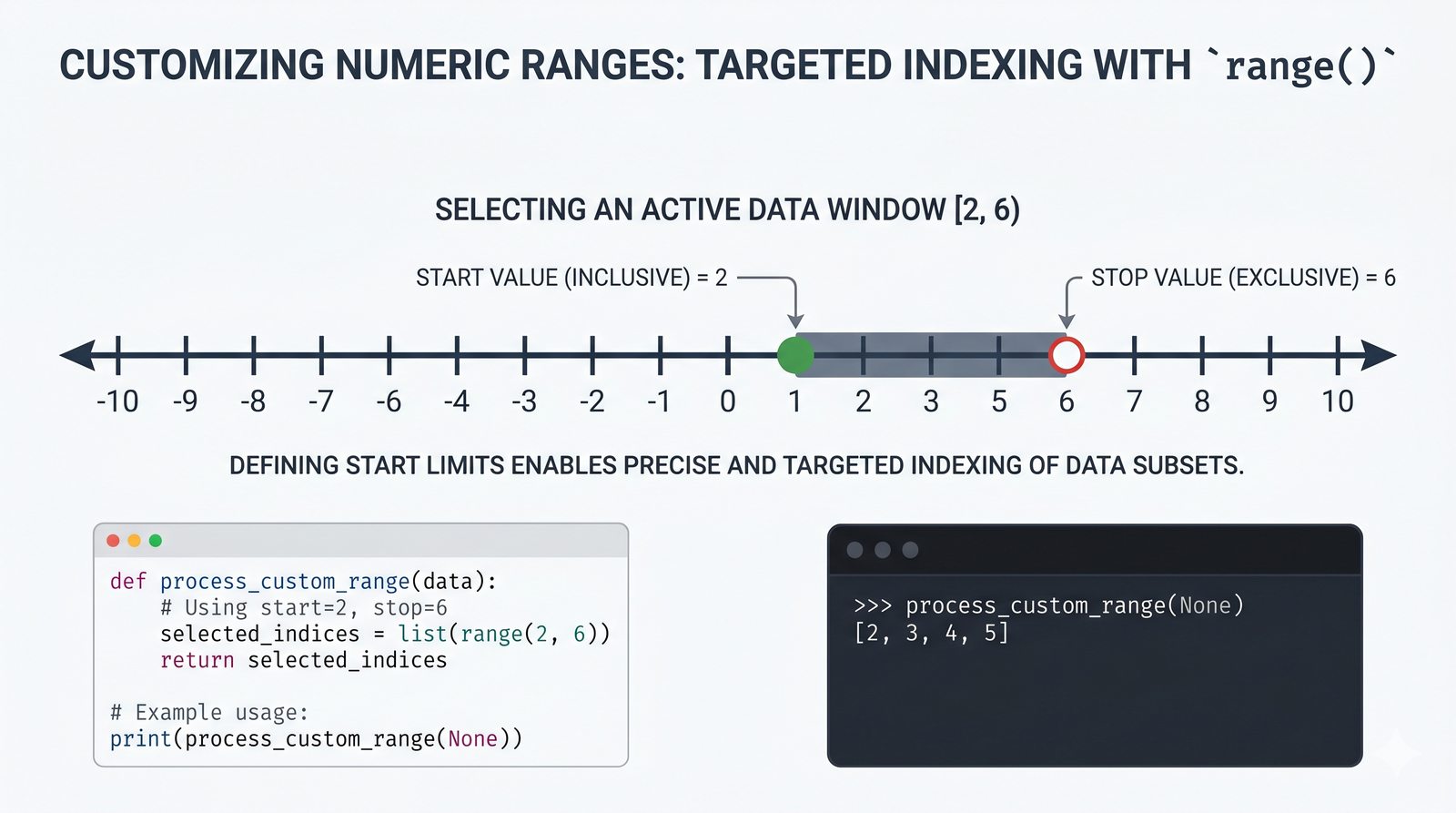
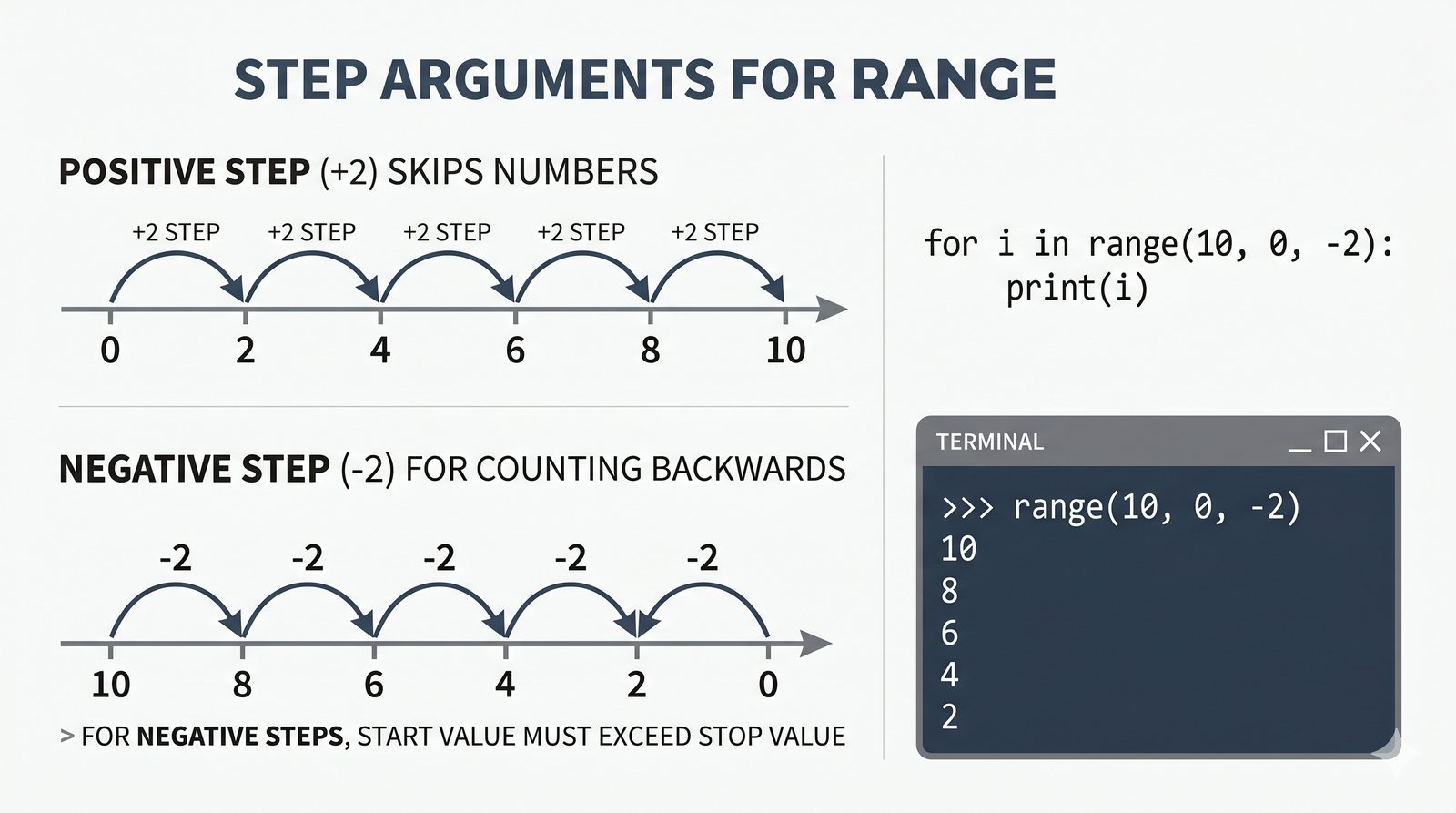
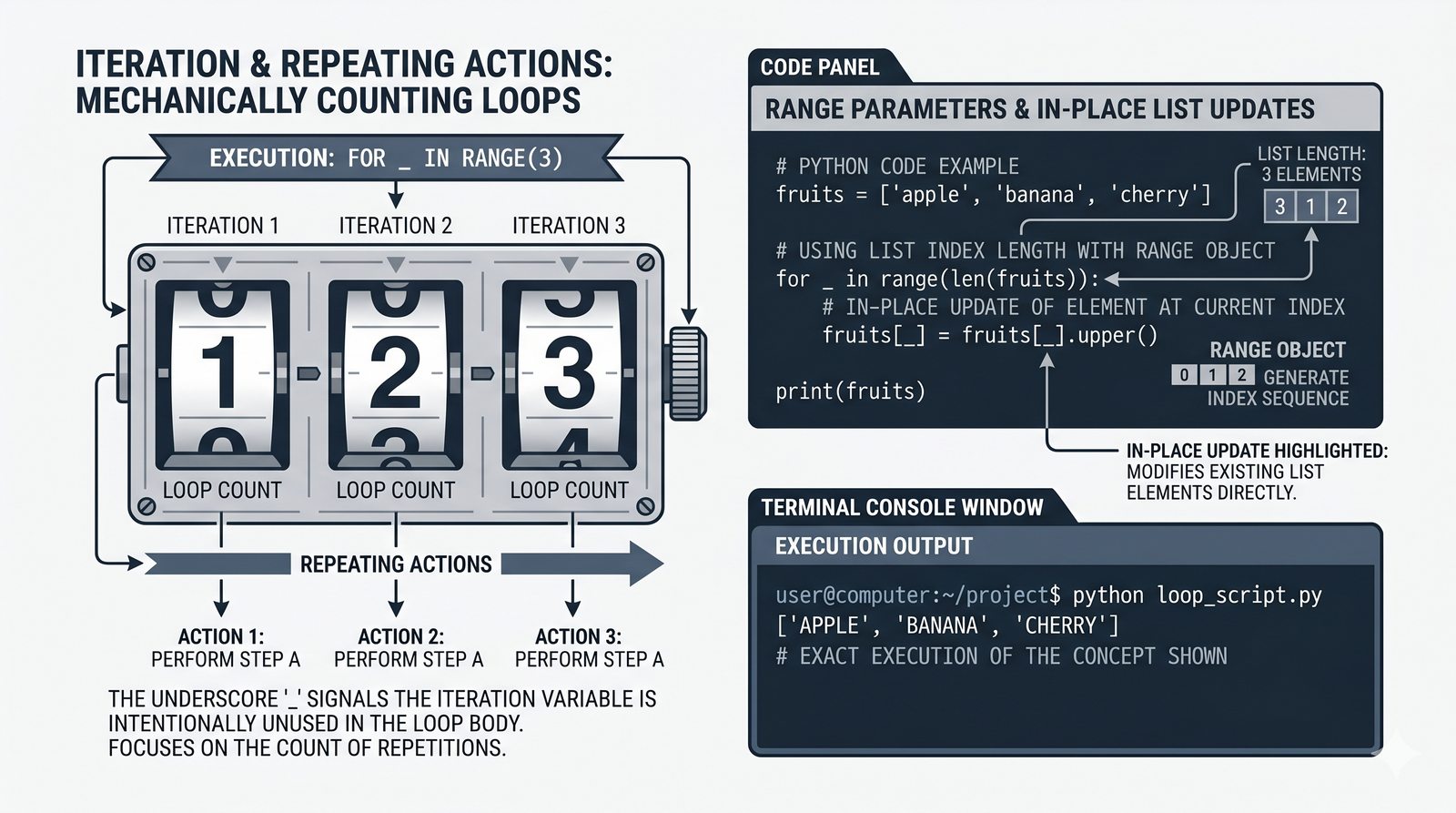
- Funkcja range() – trzy warianty (stop, start+stop, start+stop+step), krok dodatni i ujemny, zastosowania
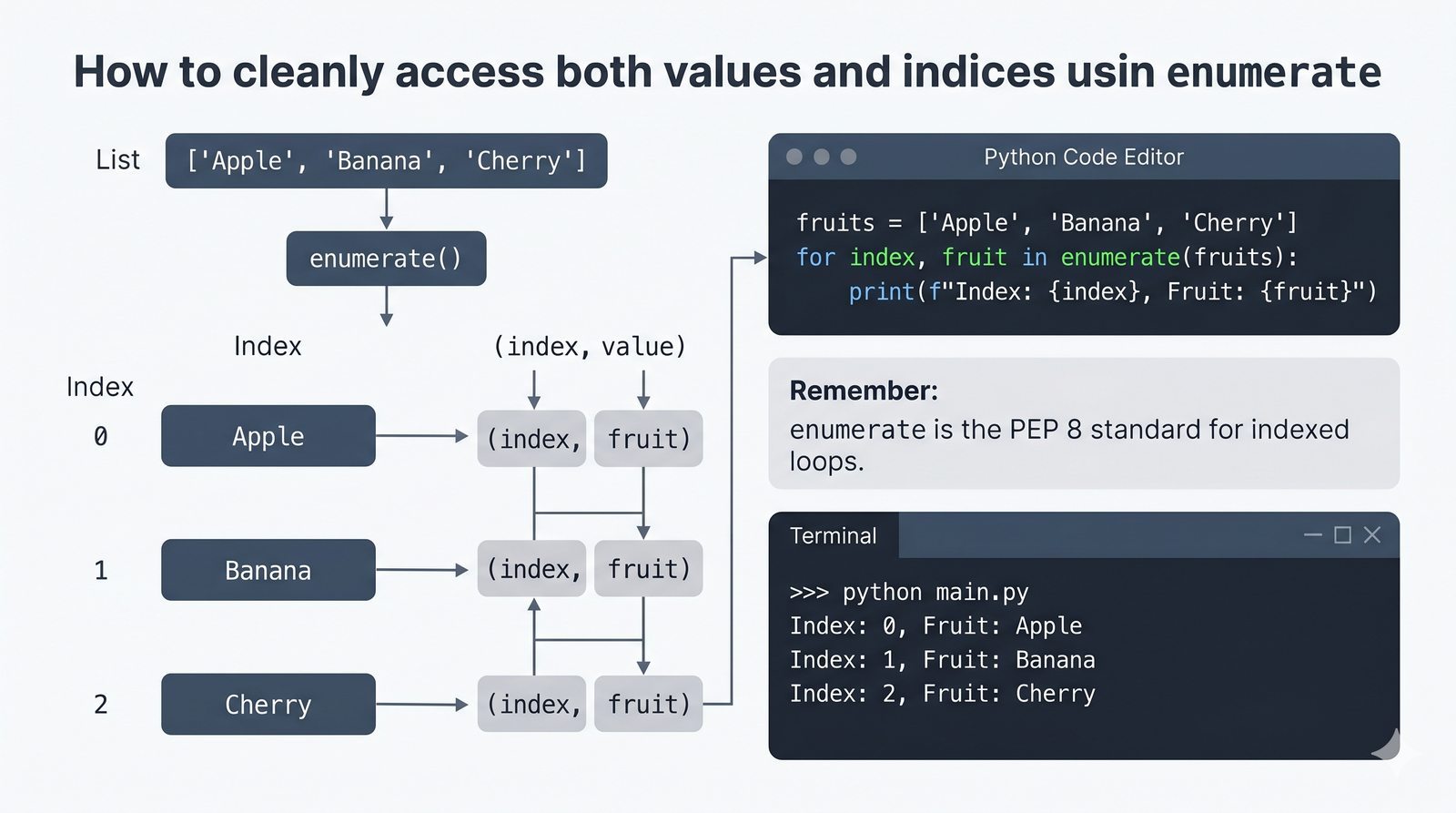
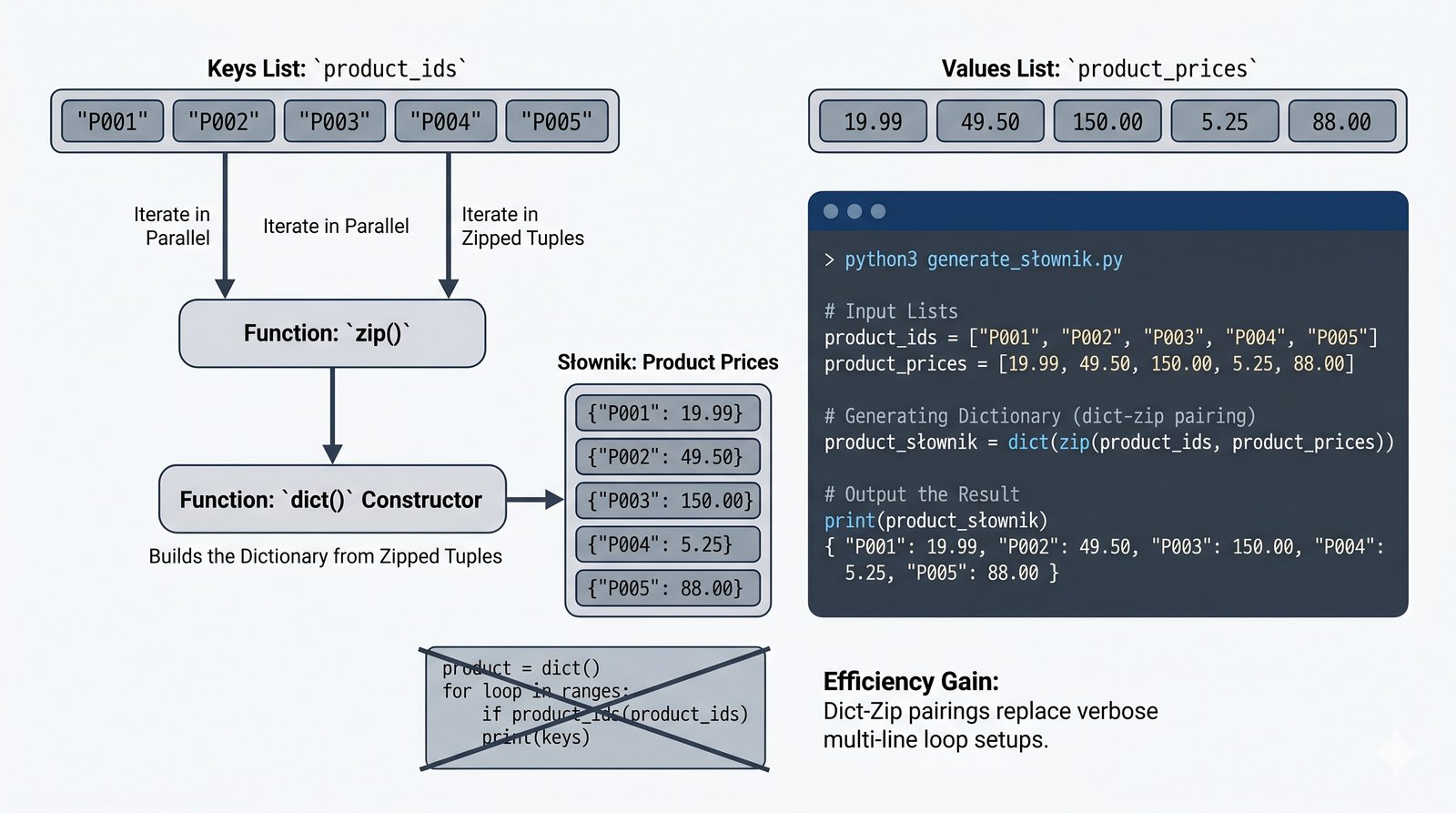
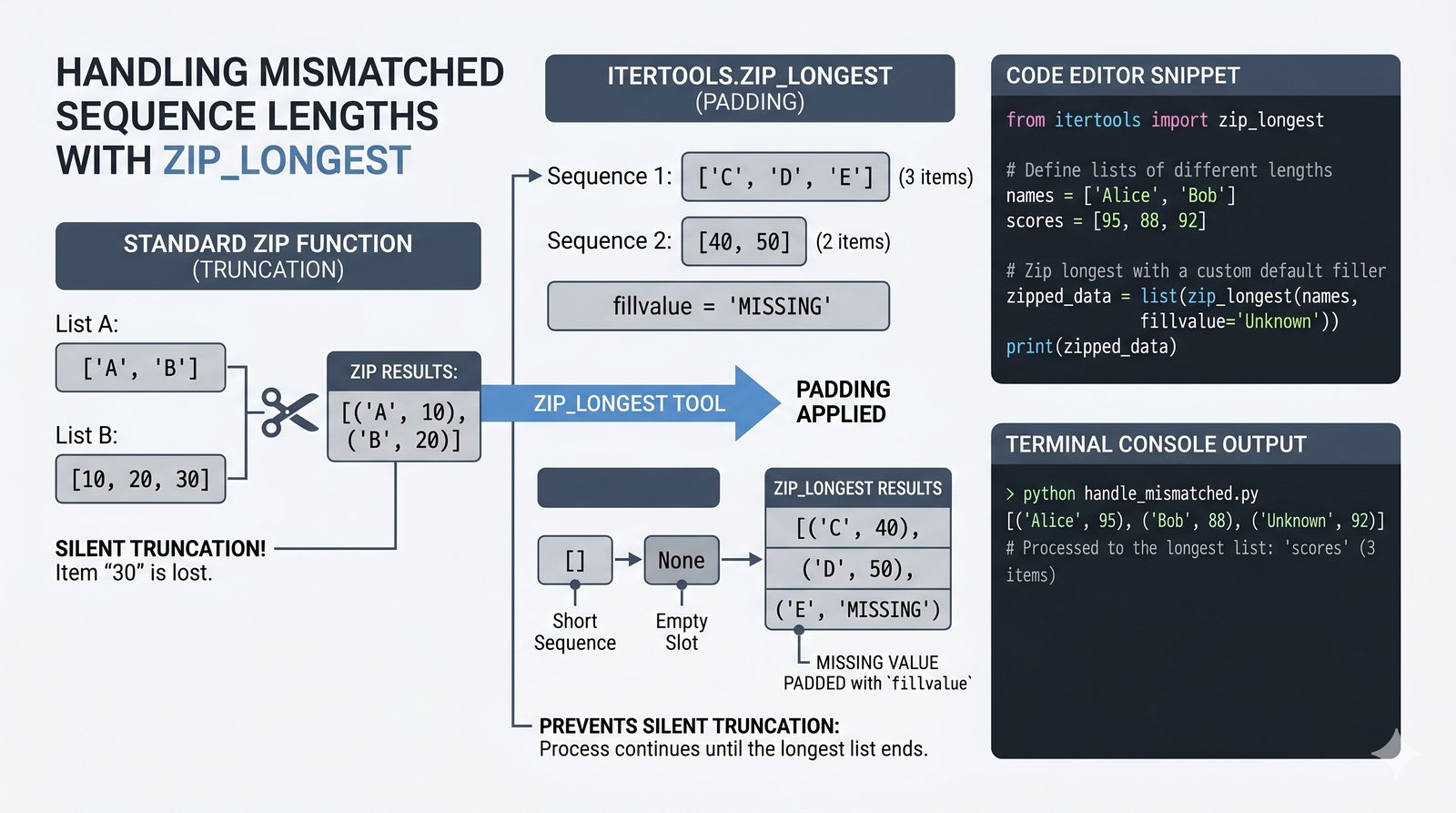
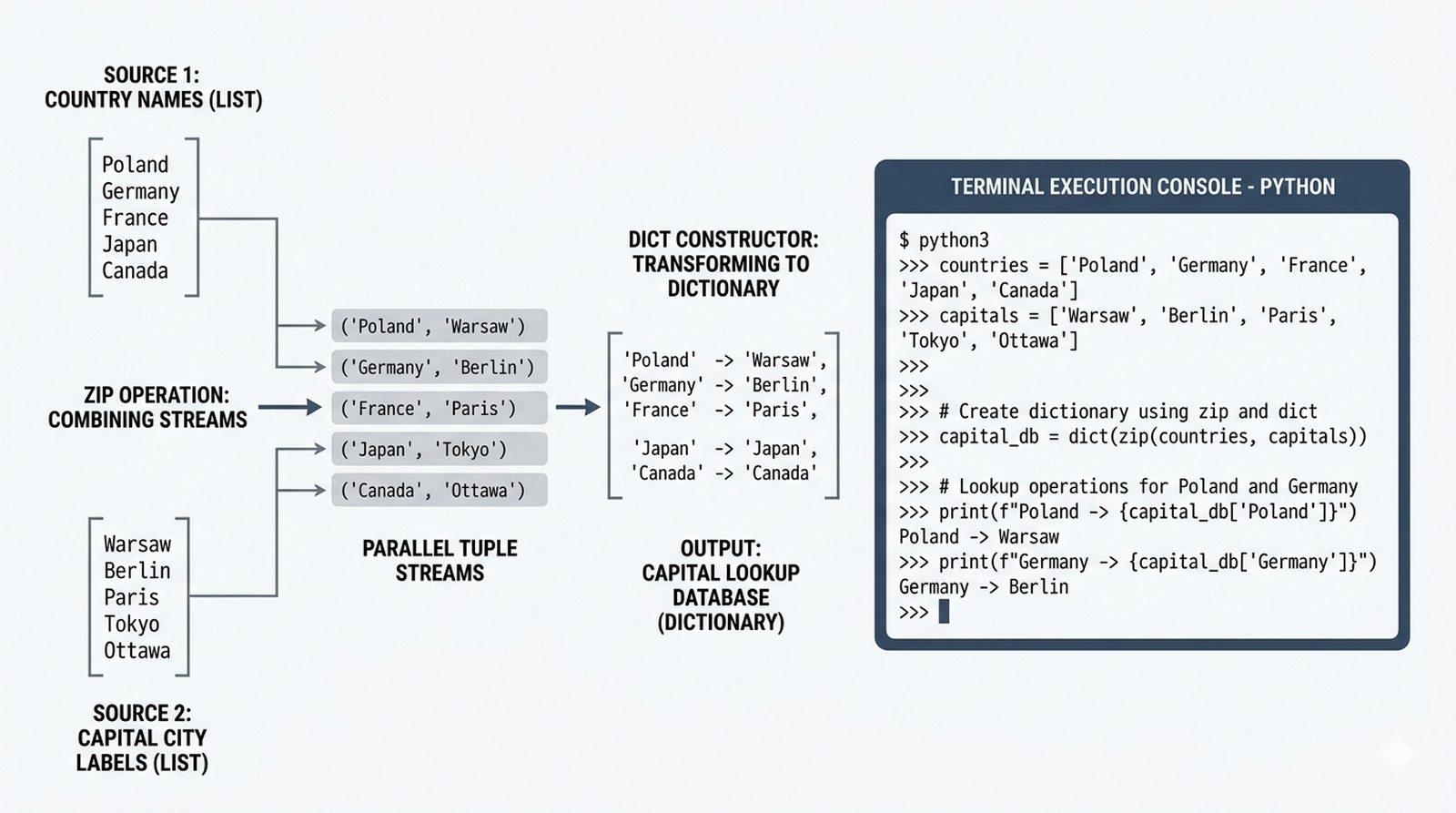
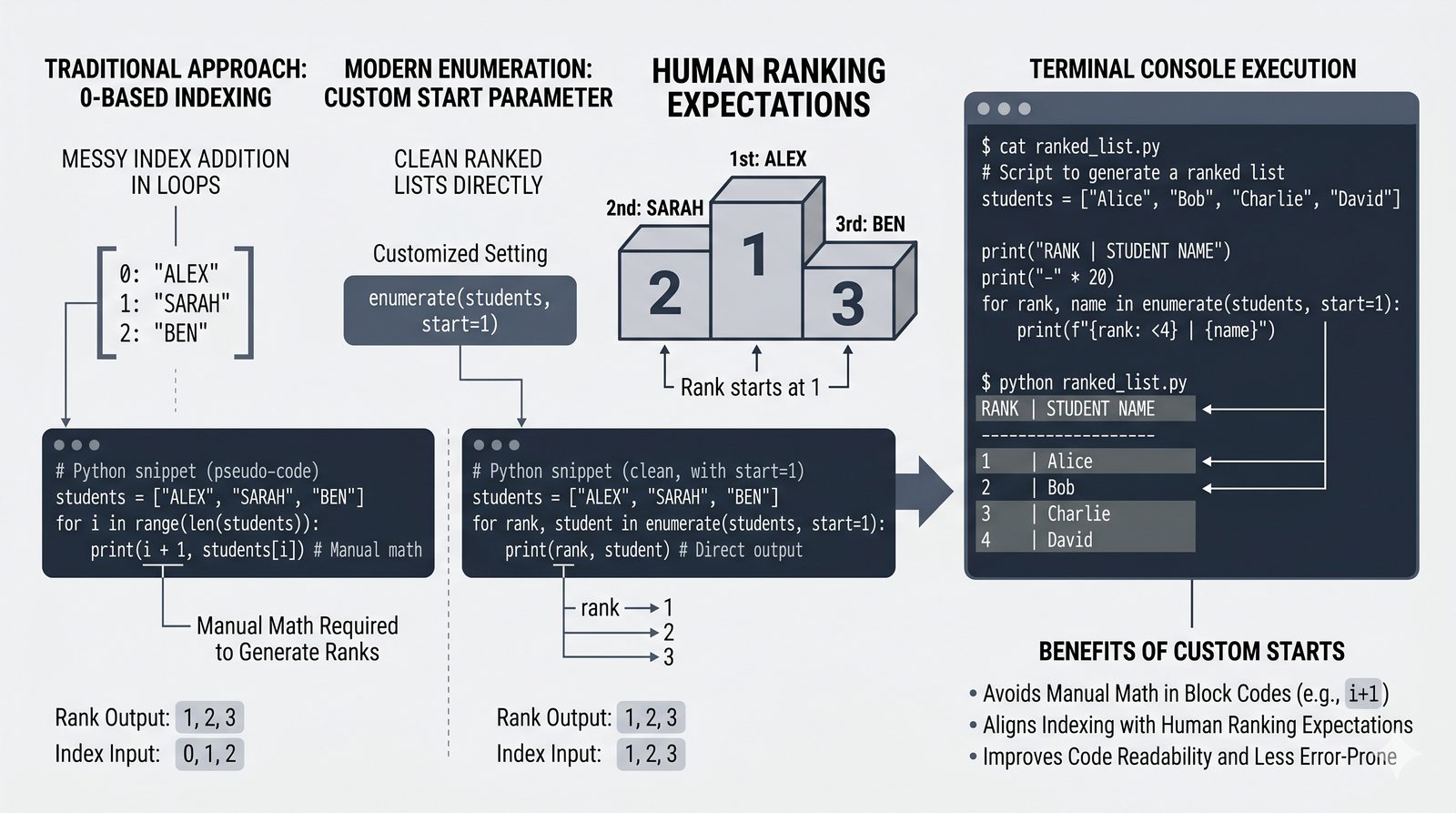
- Funkcje enumerate() i zip() – indeksowanie z parametrem start, łączenie sekwencji, zip_longest z itertools
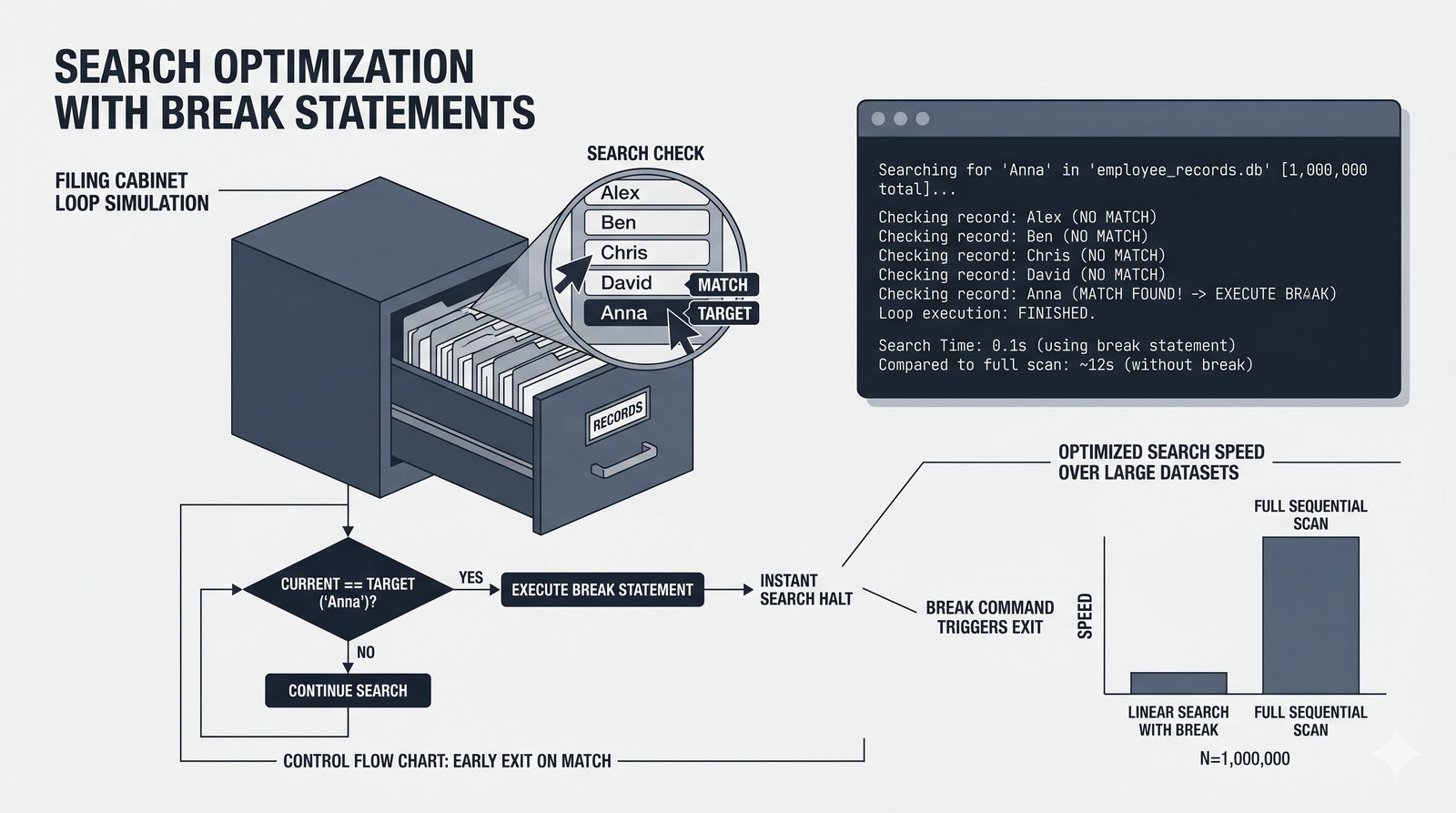
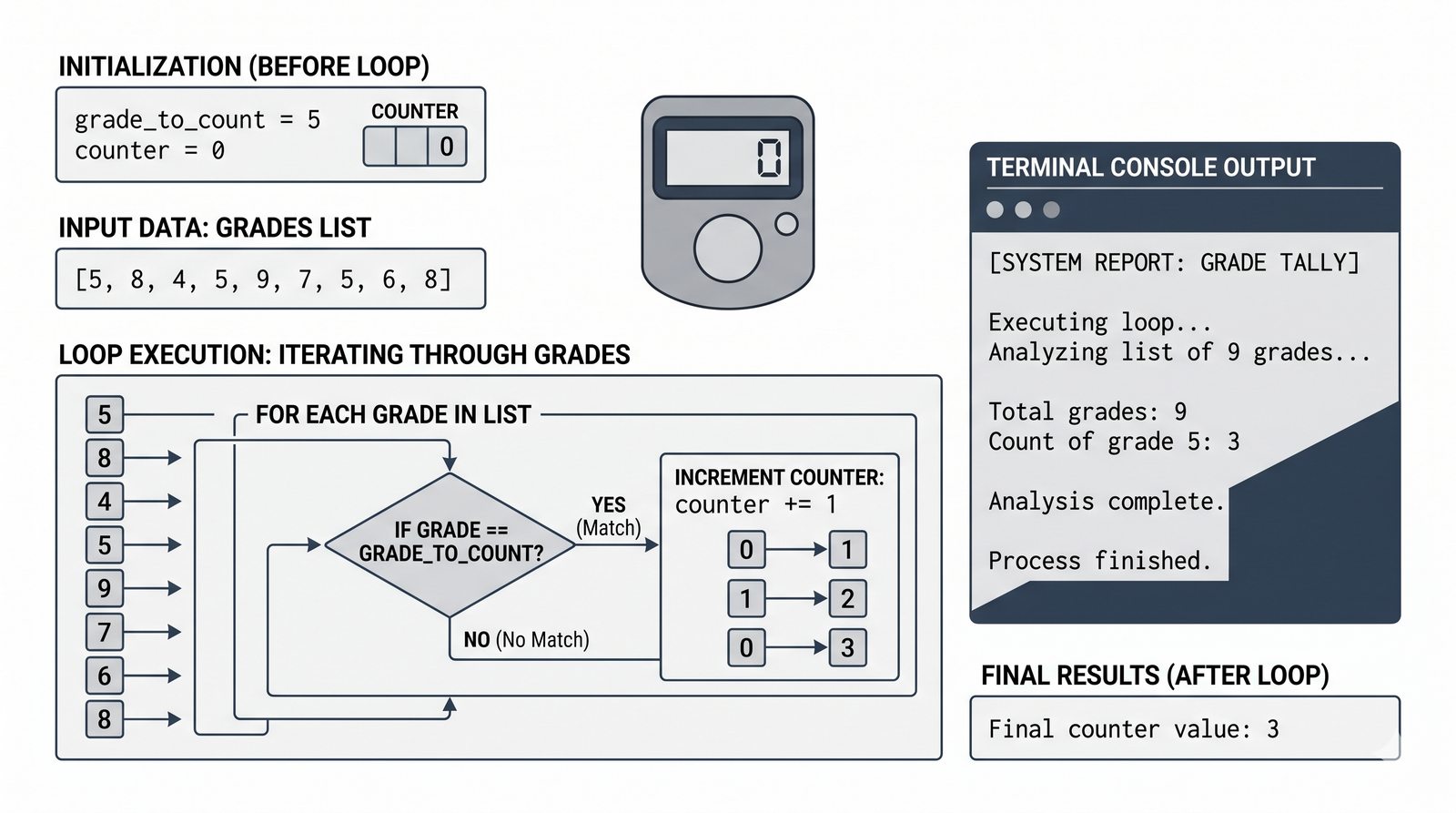
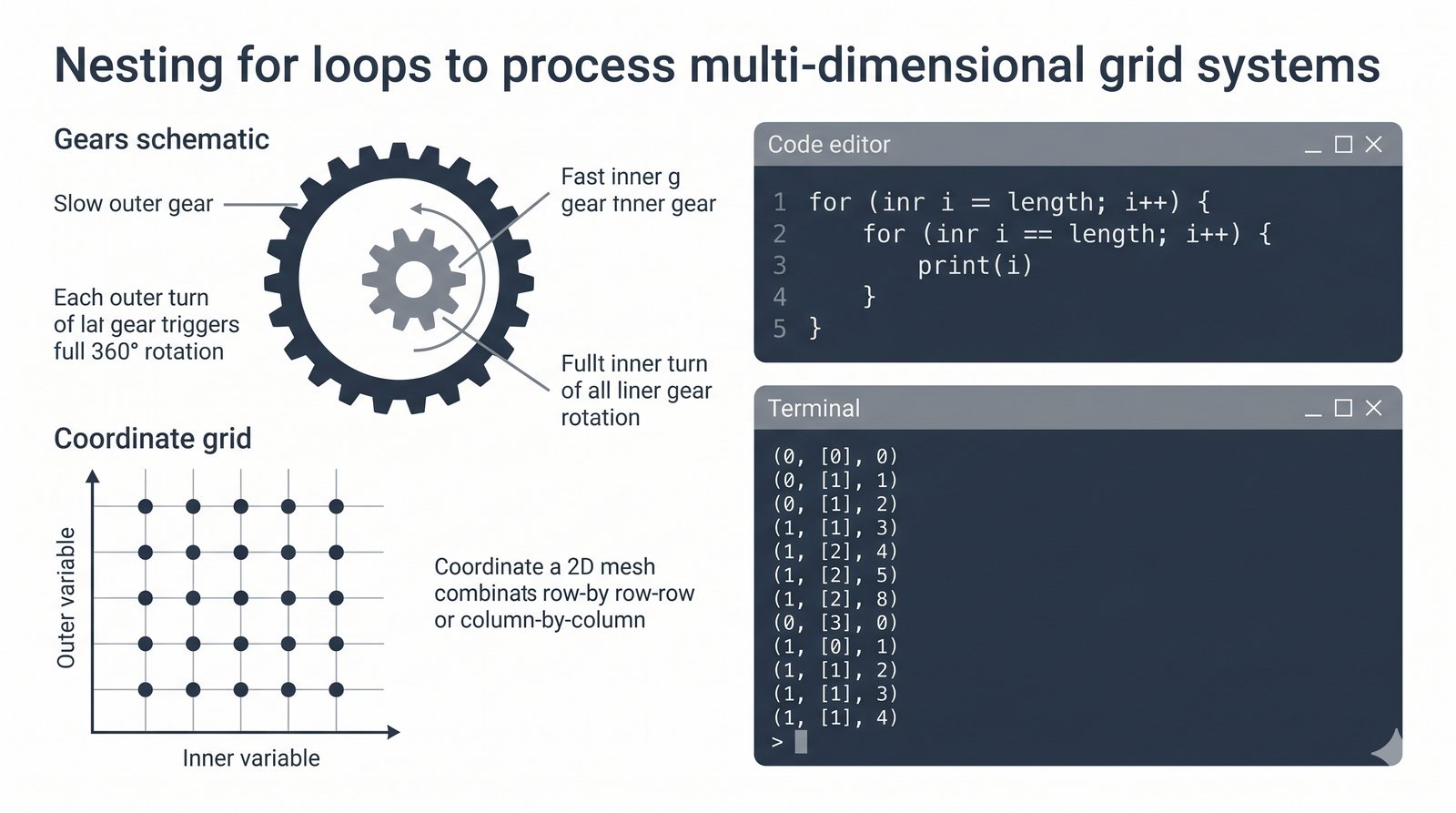
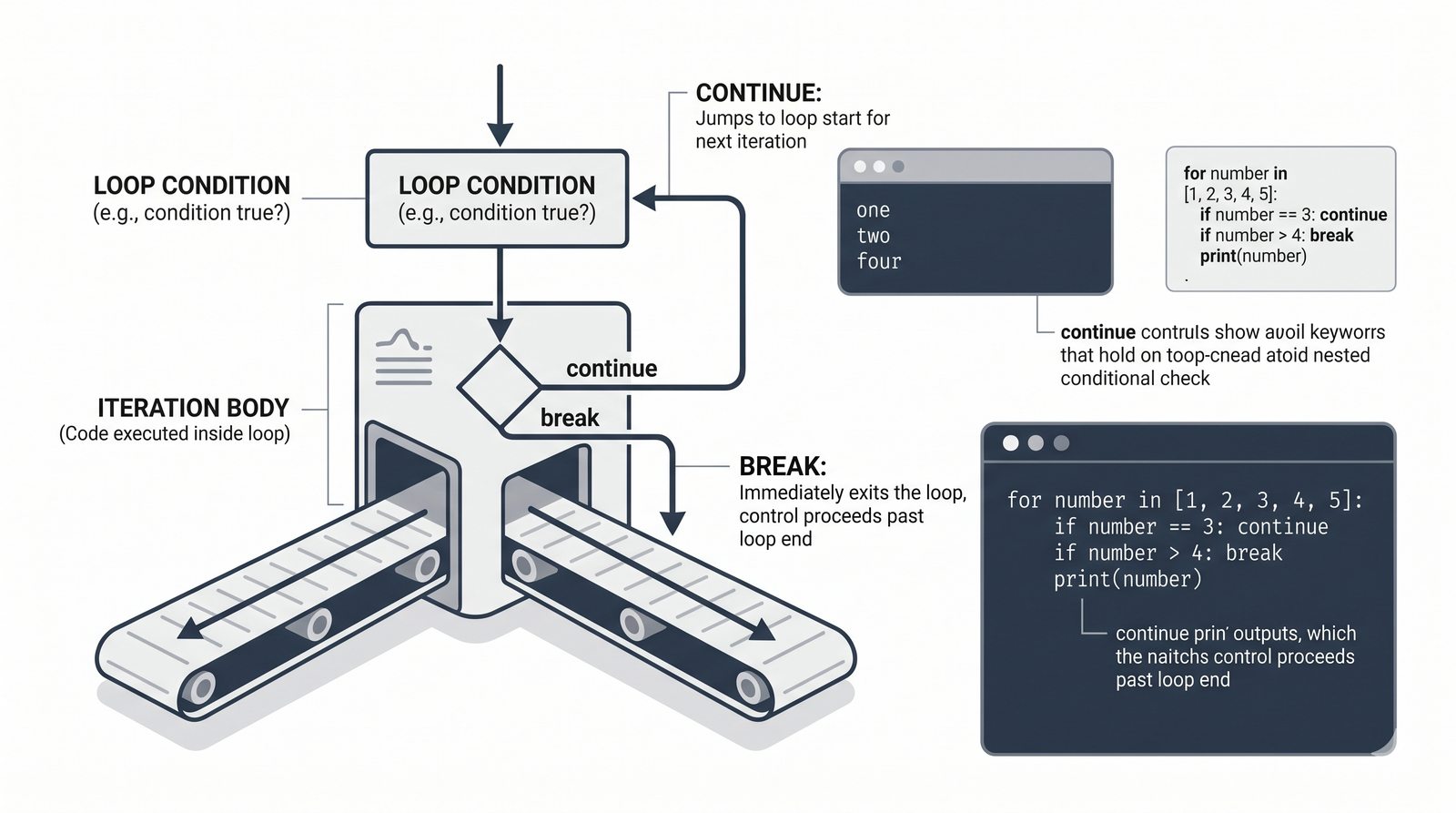
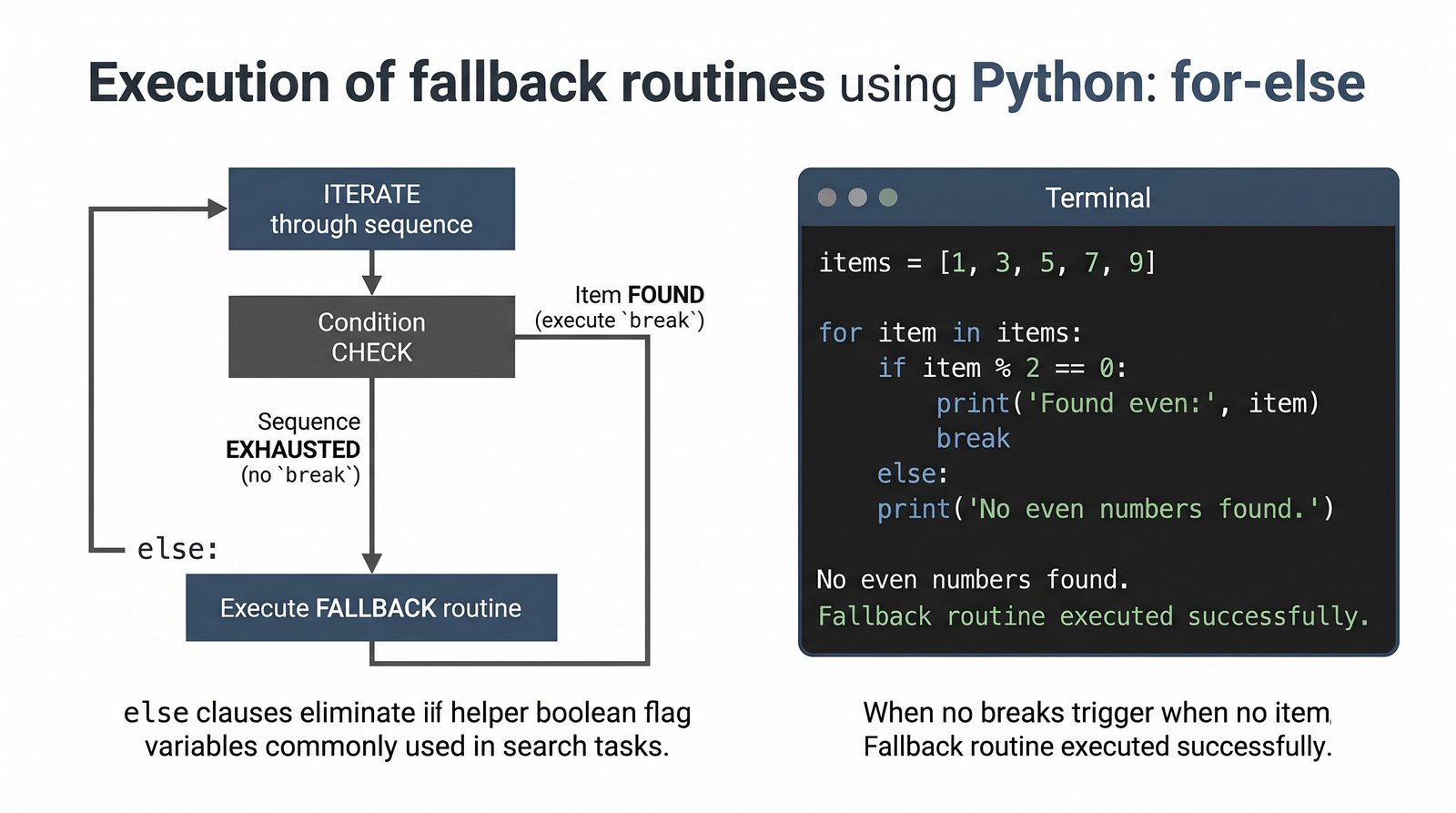
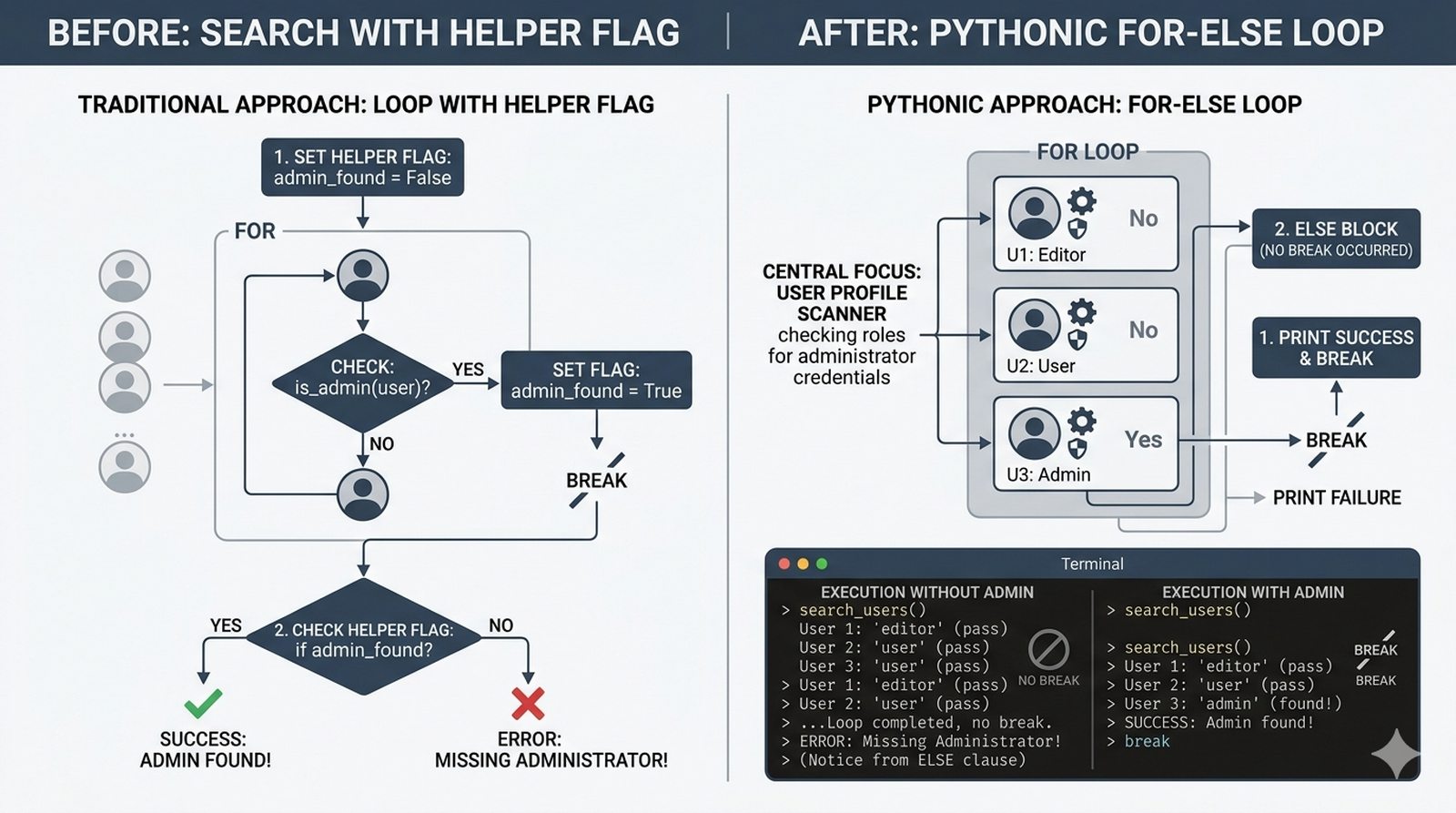
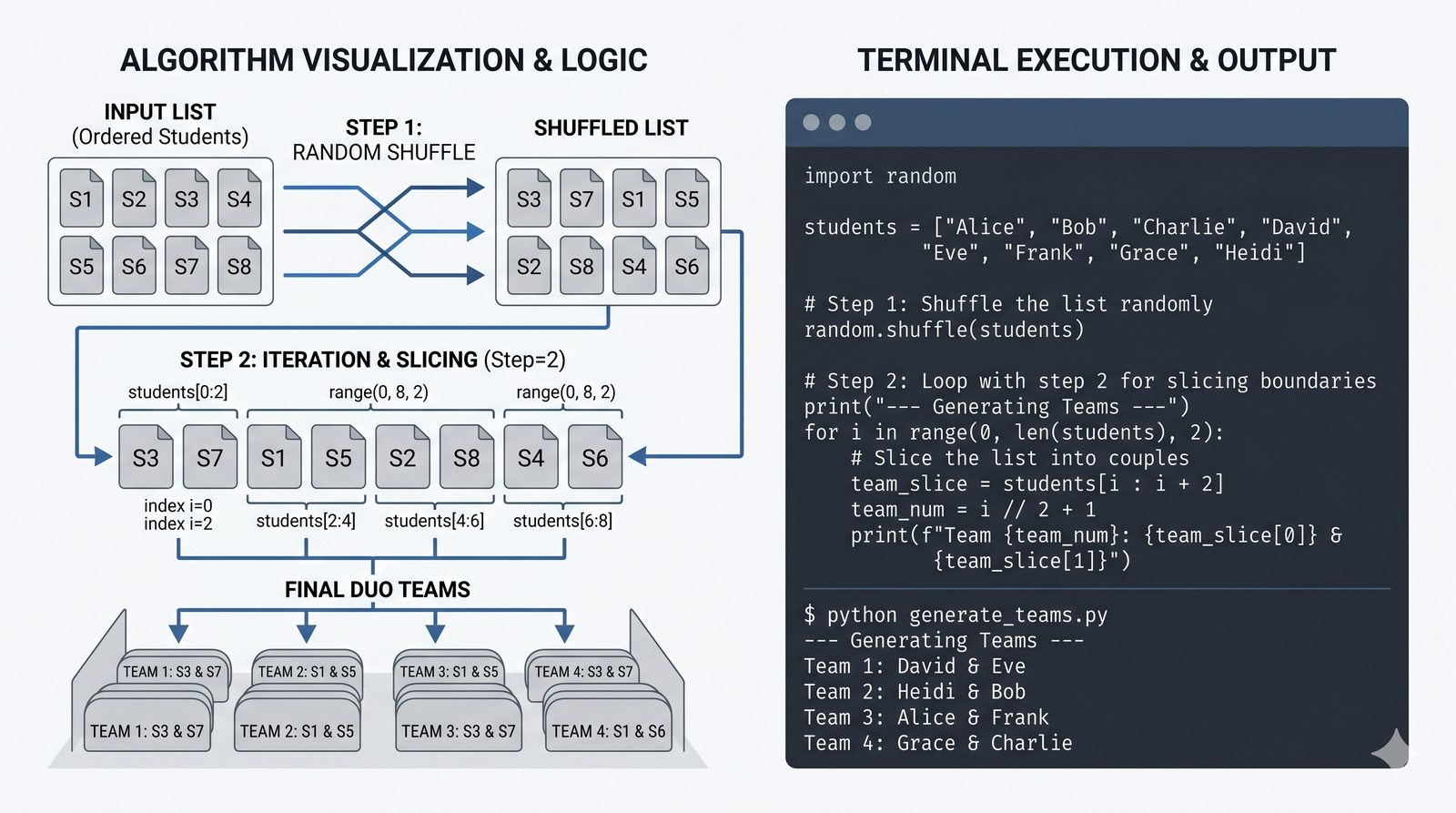
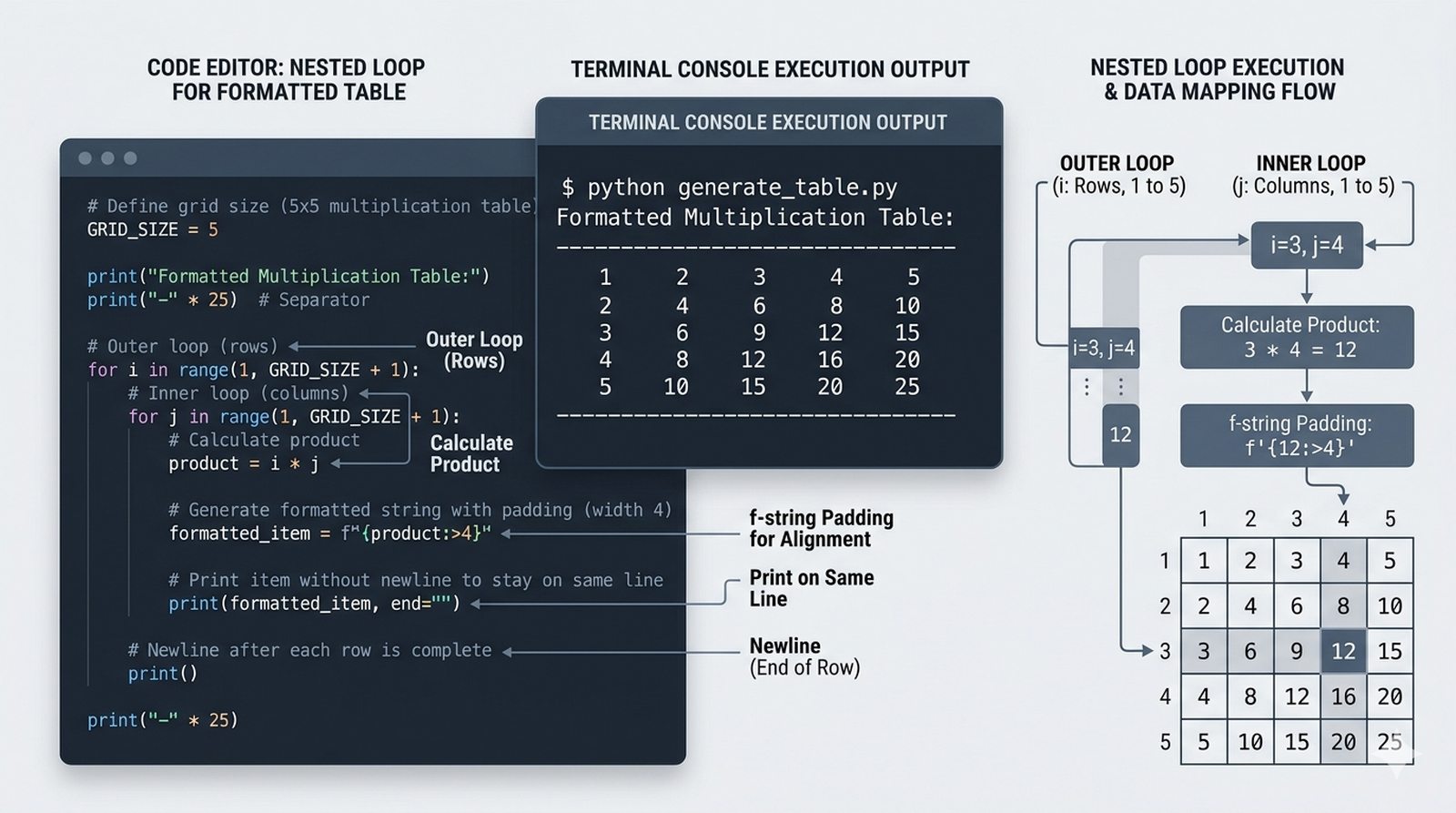
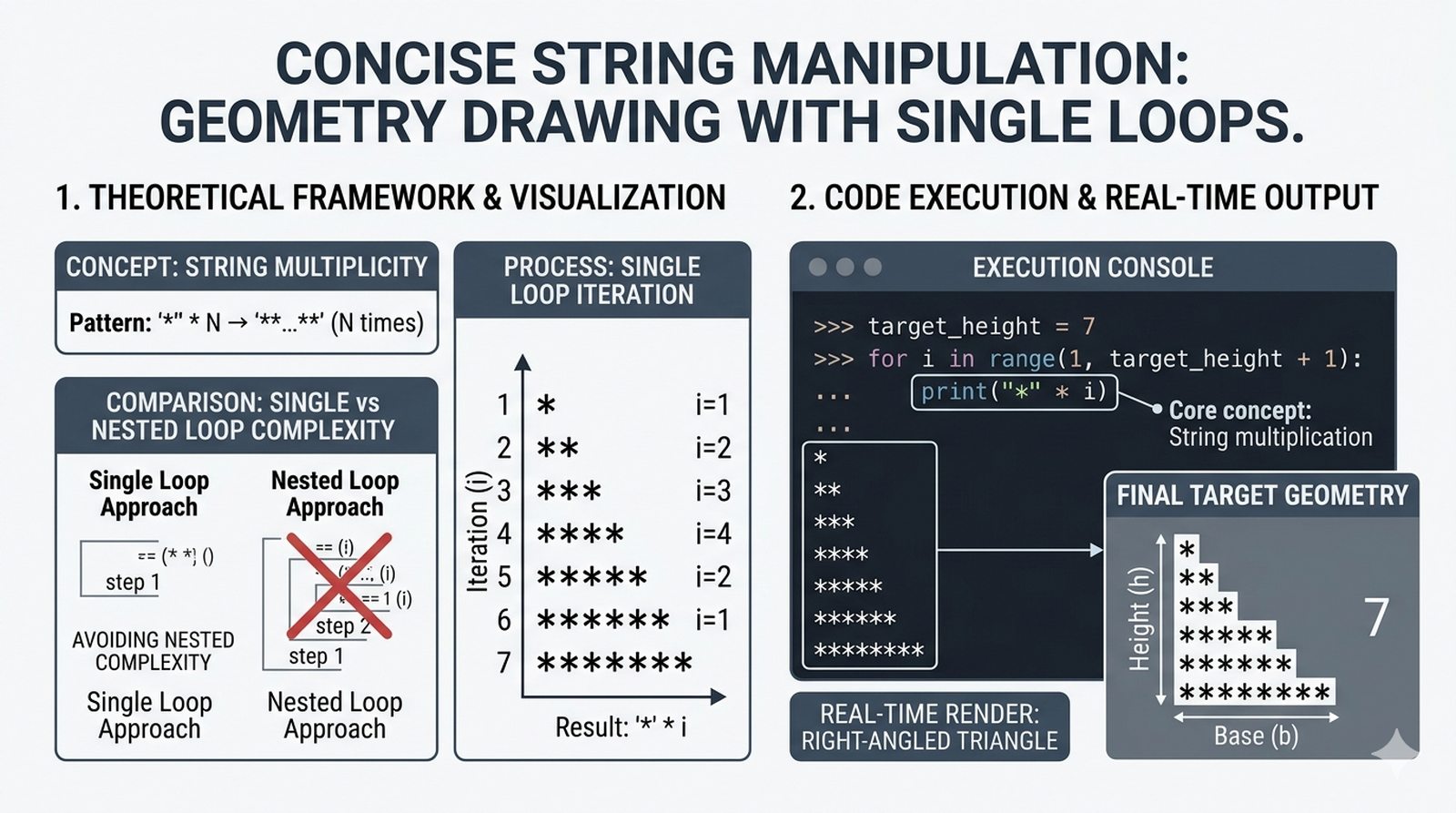
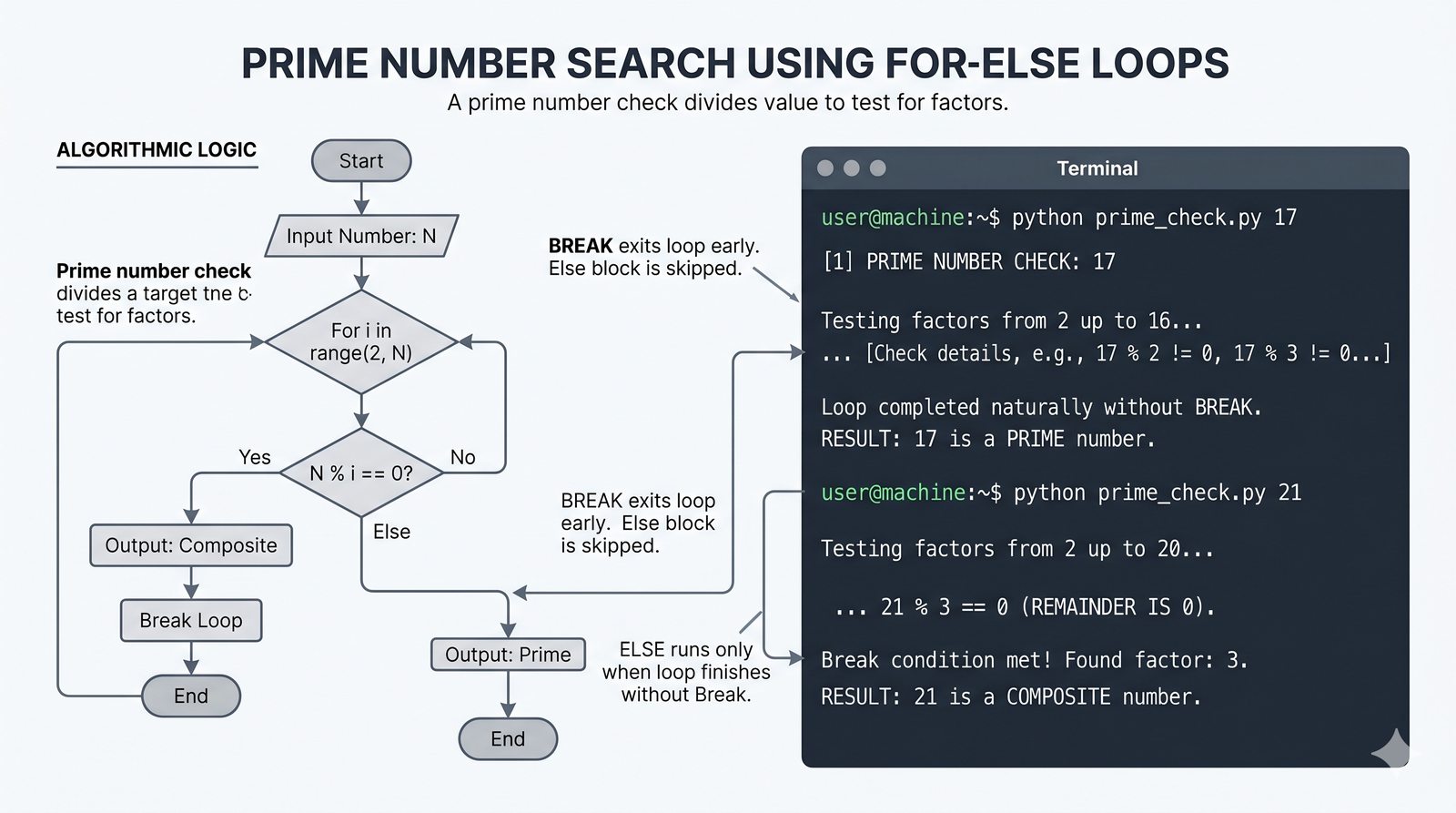
- Sterowanie pętlą – break, continue, for...else, zagnieżdżone pętle (szachownica, tabliczka mnożenia)
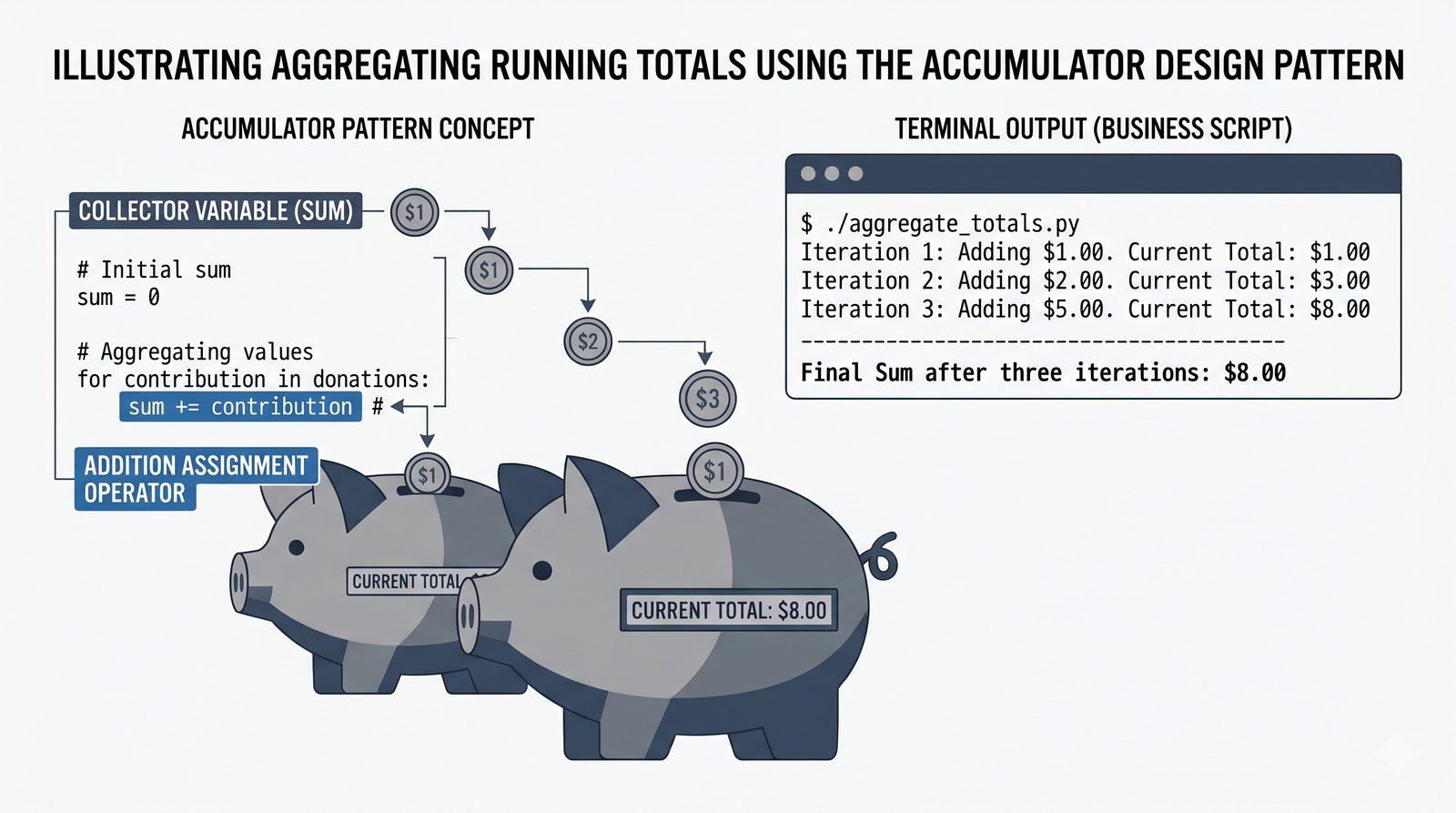
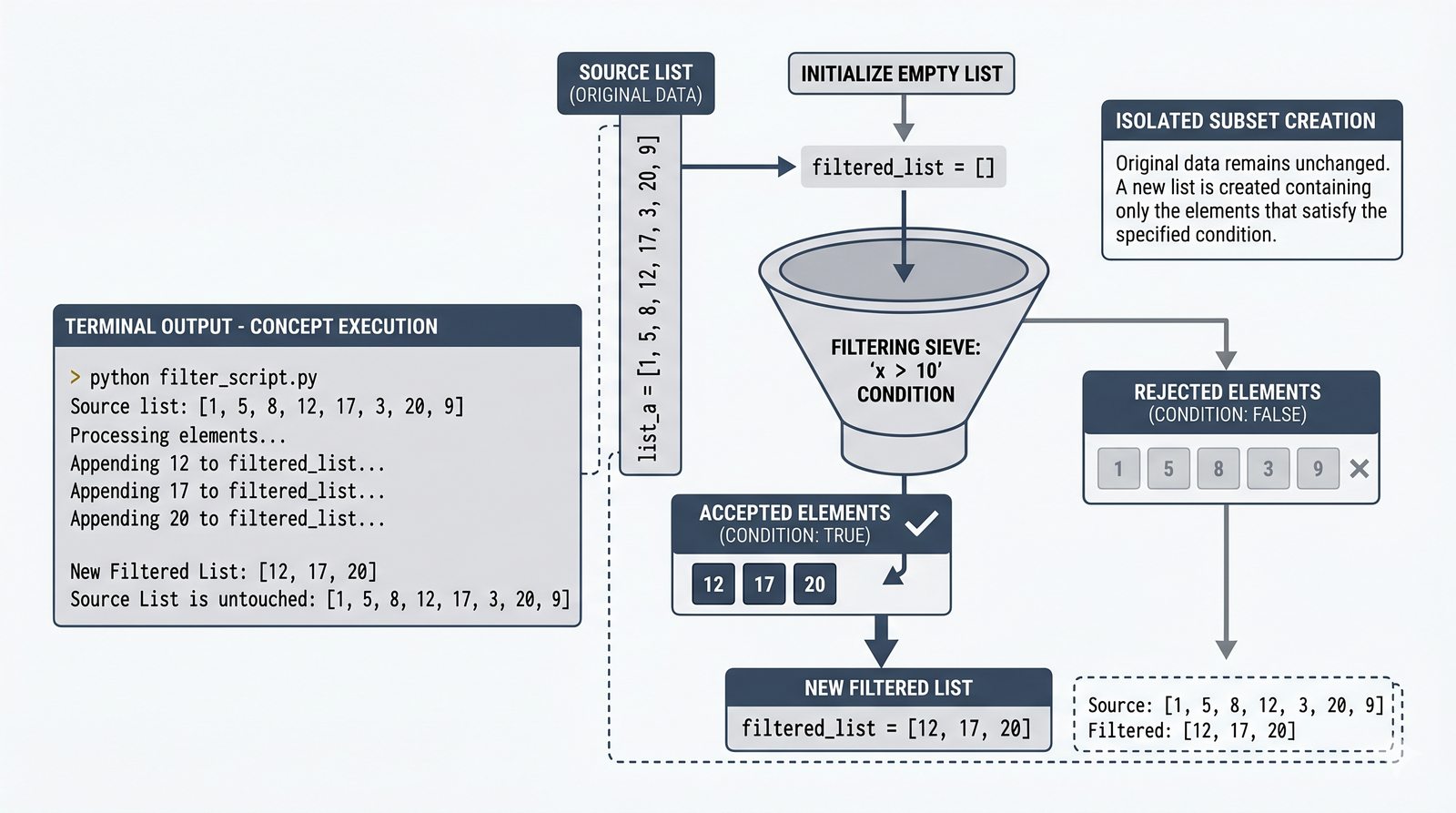
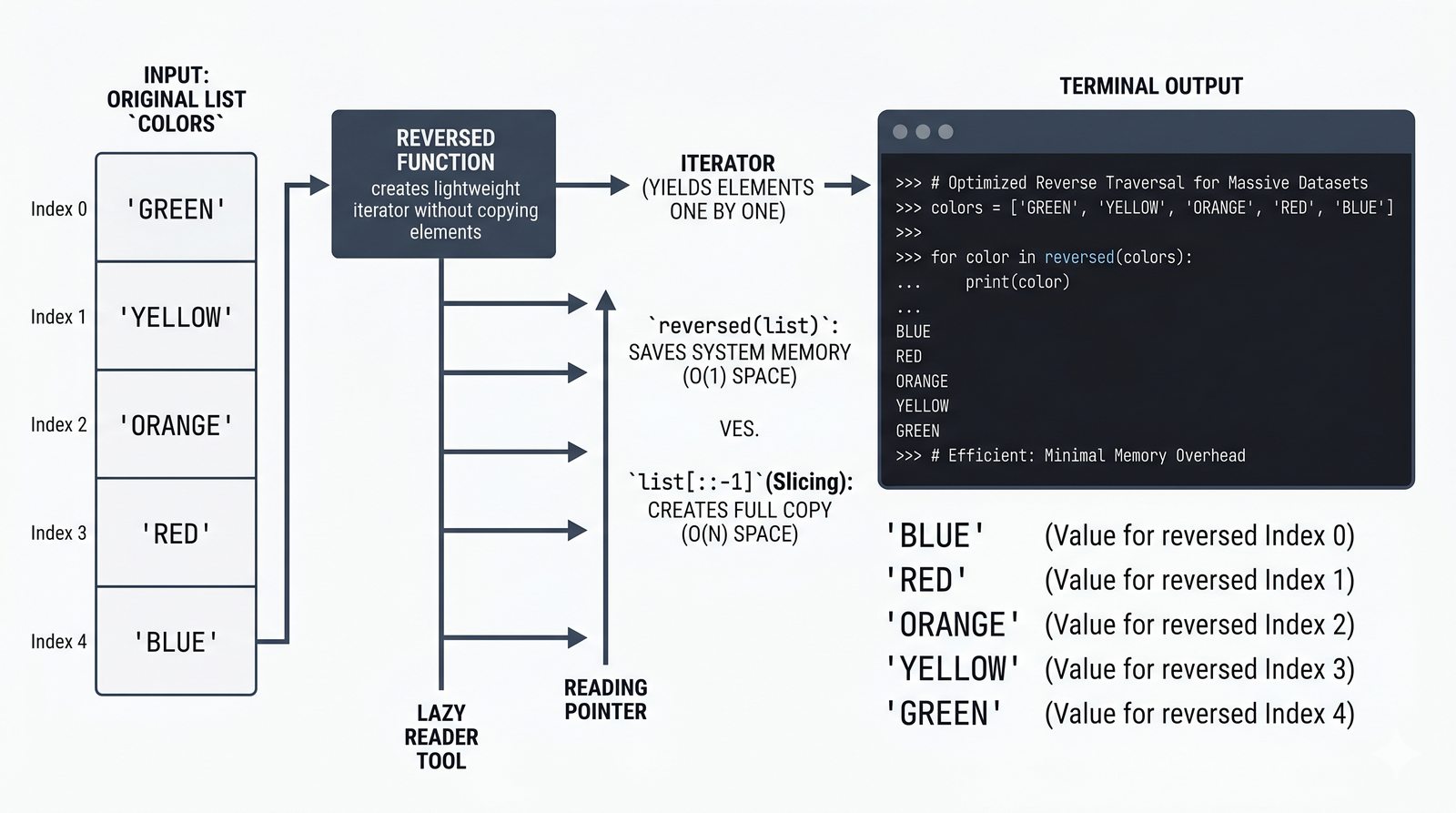
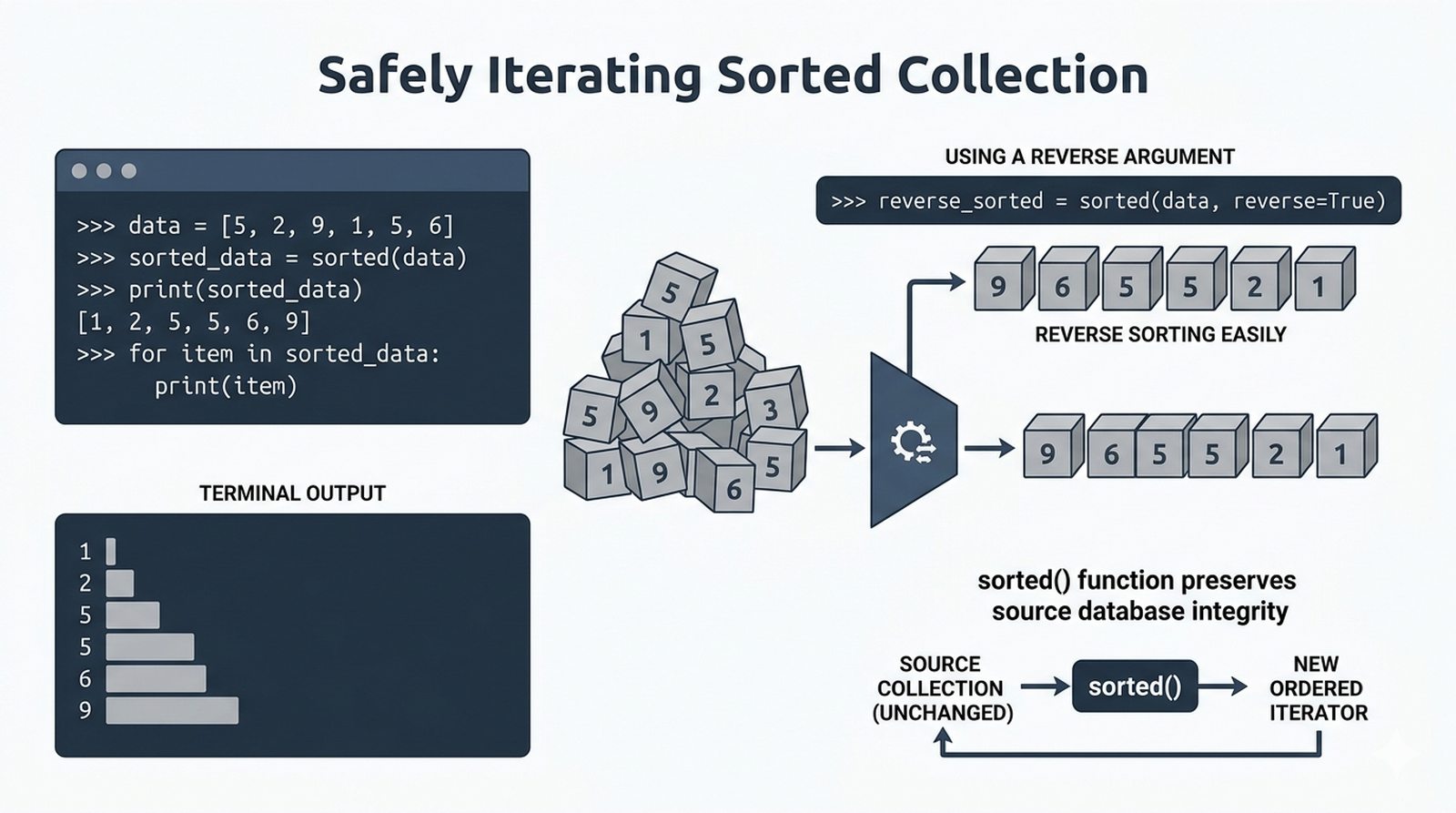
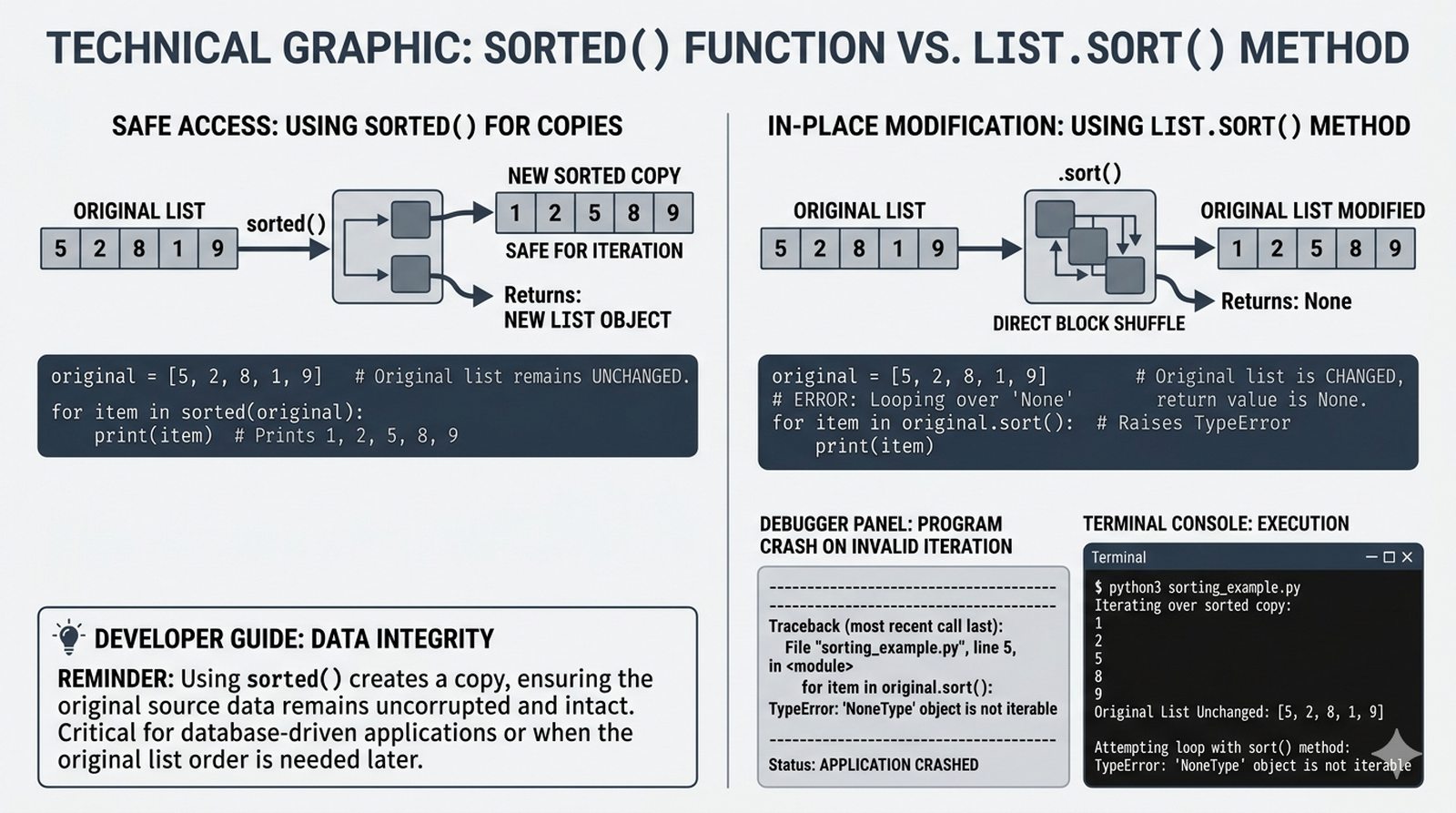
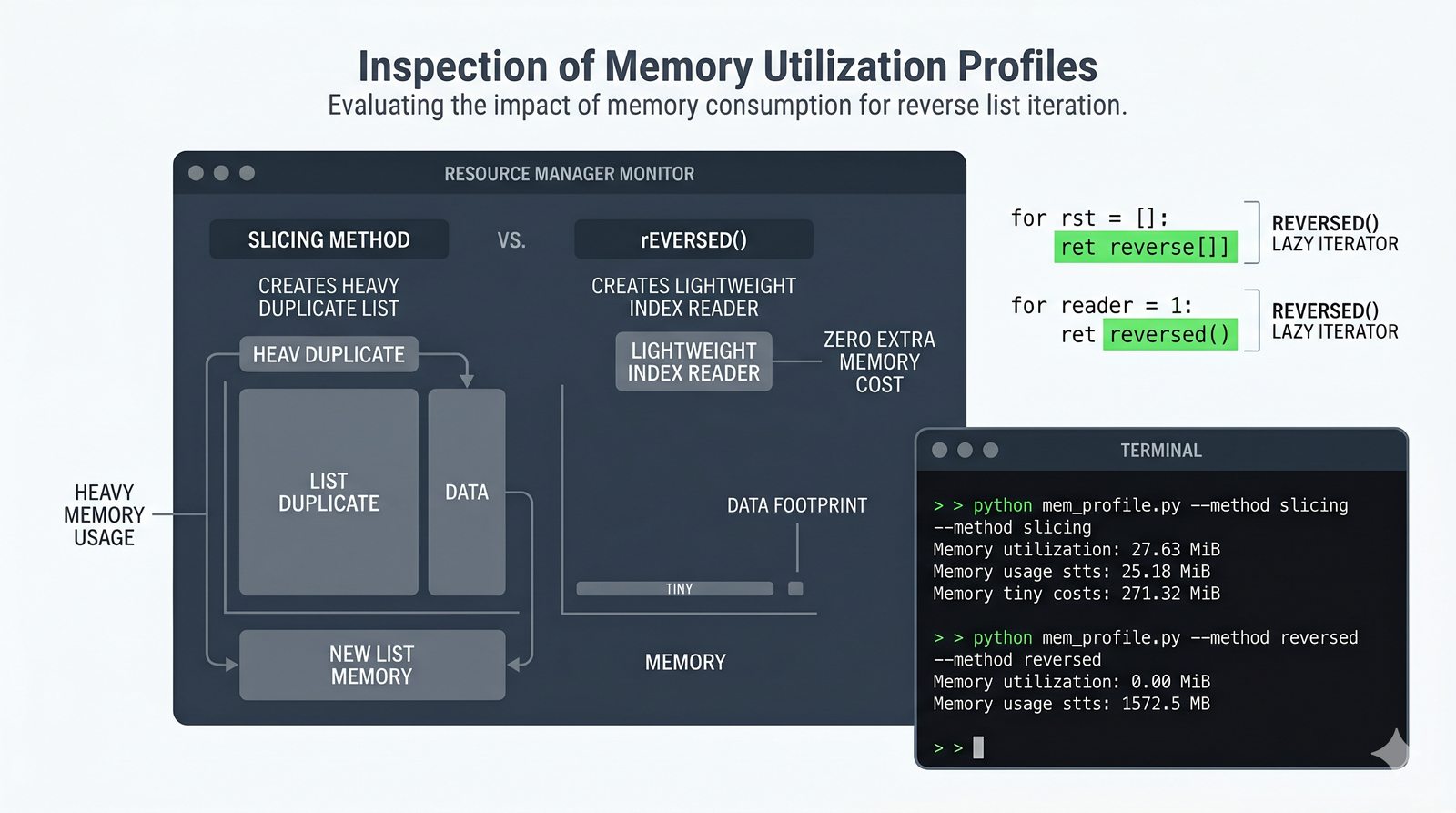
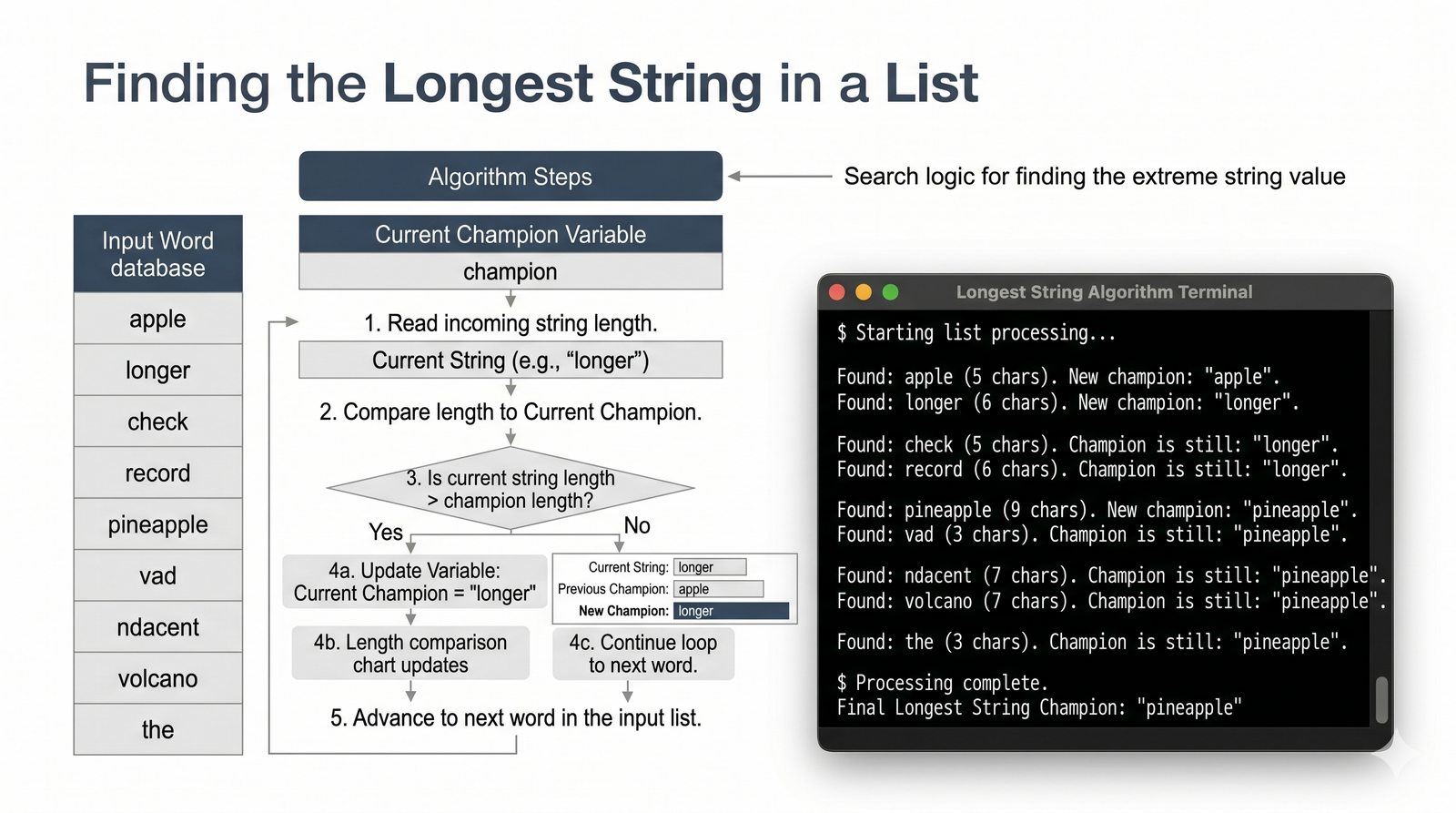
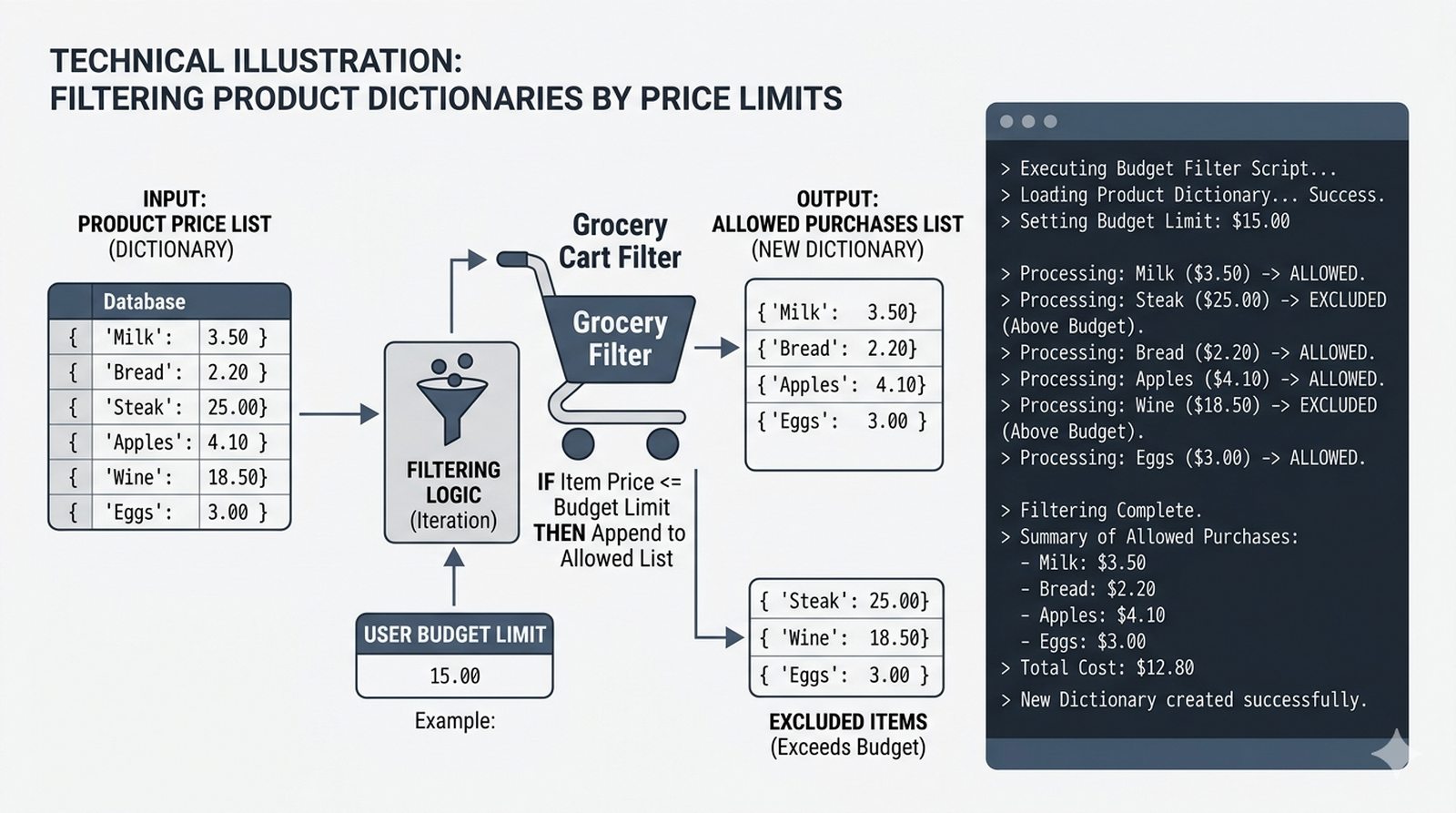
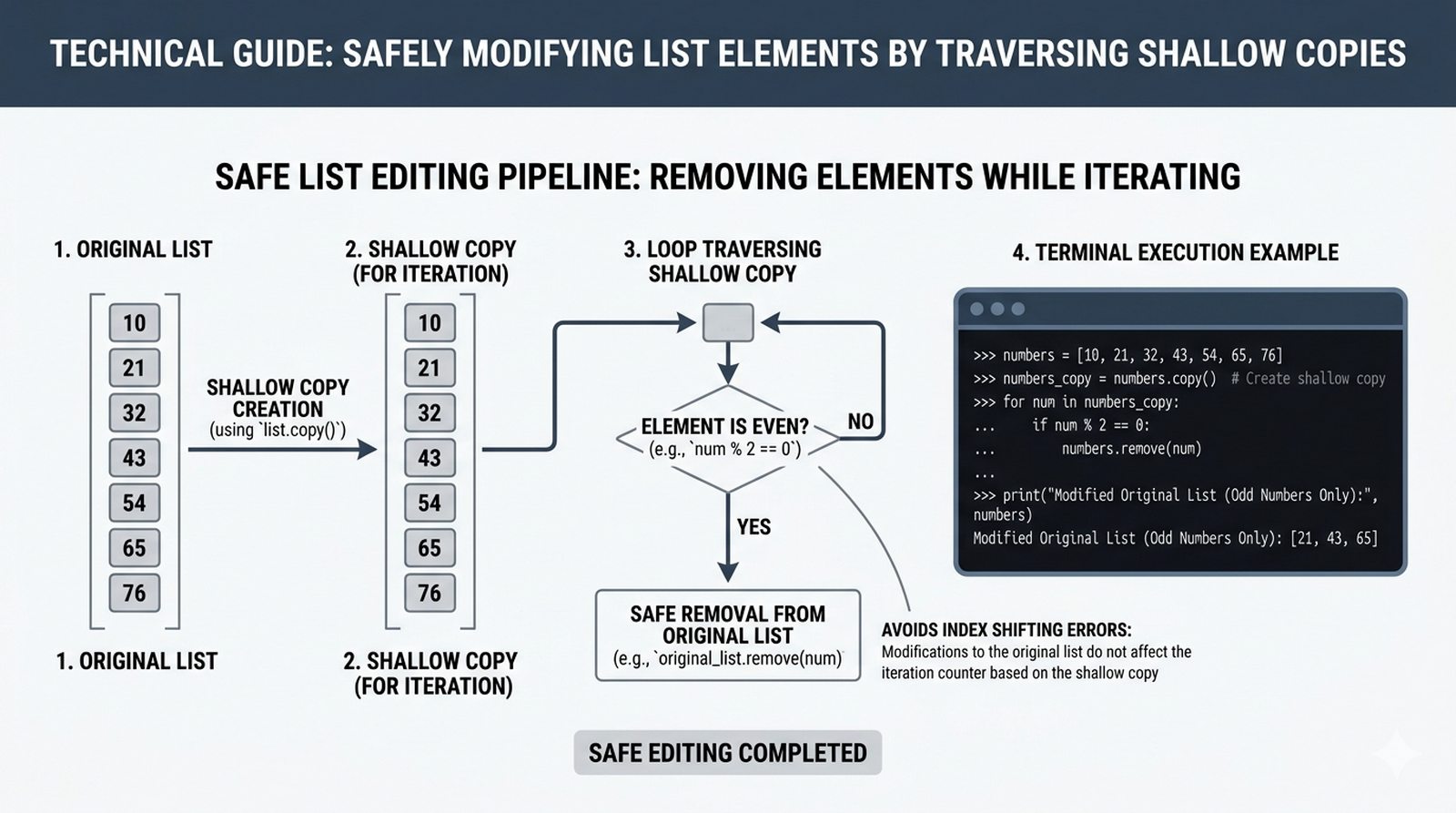
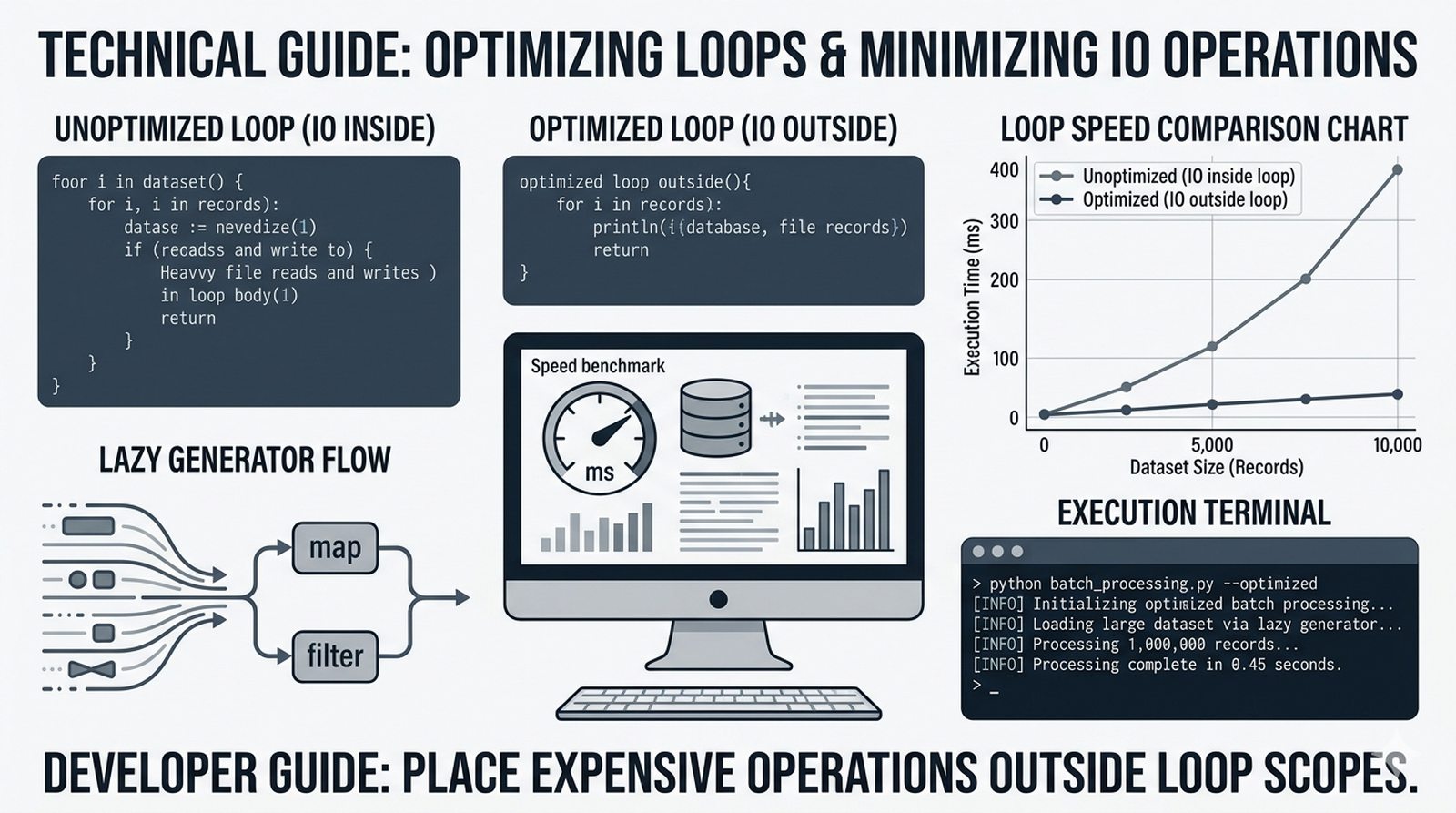
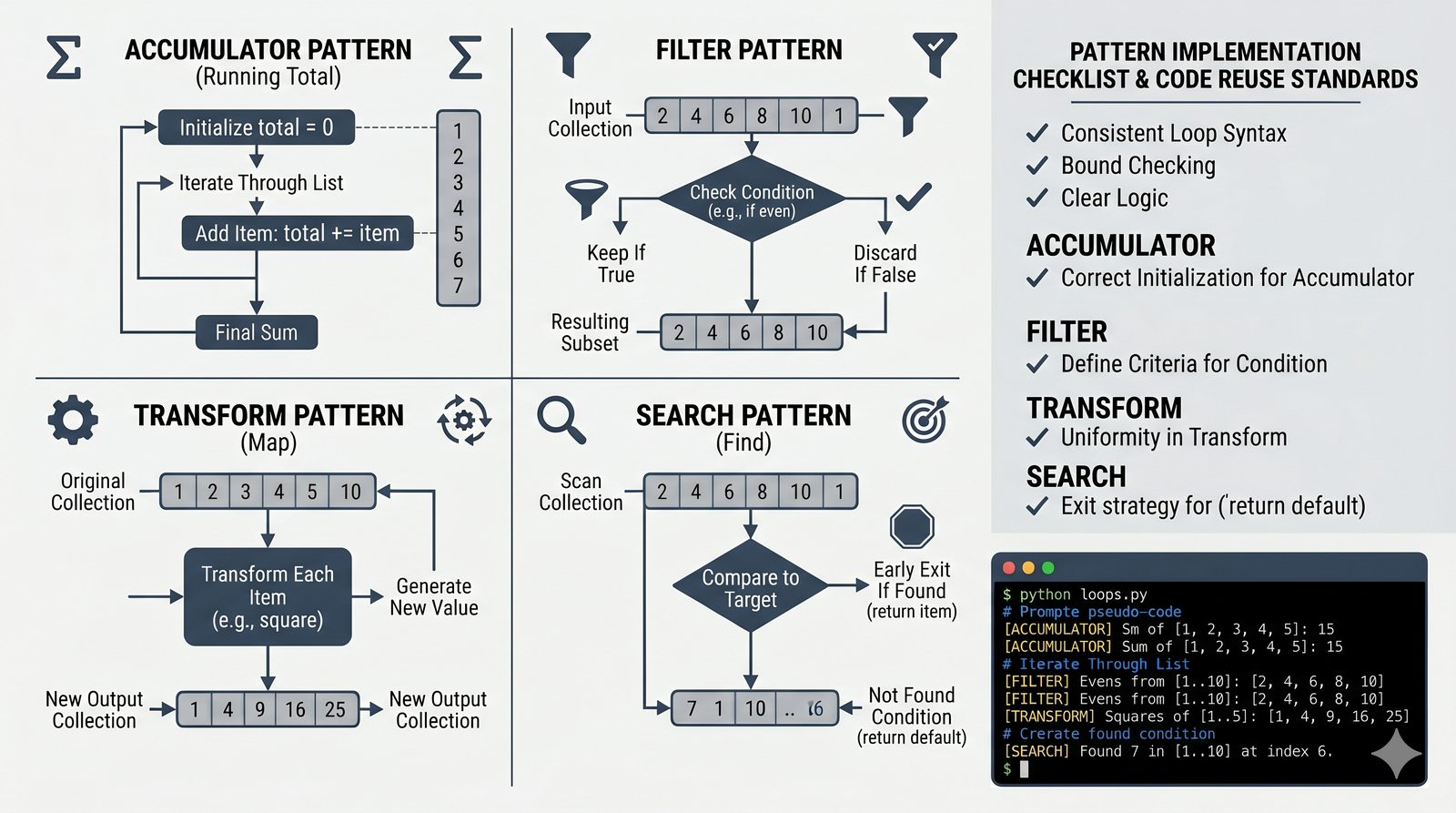
- Zaawansowane techniki – reversed(), sorted(), bezpieczna modyfikacja kolekcji przez kopię, wzorce programistyczne (akumulator, filtr, transformacja, wyszukiwanie)