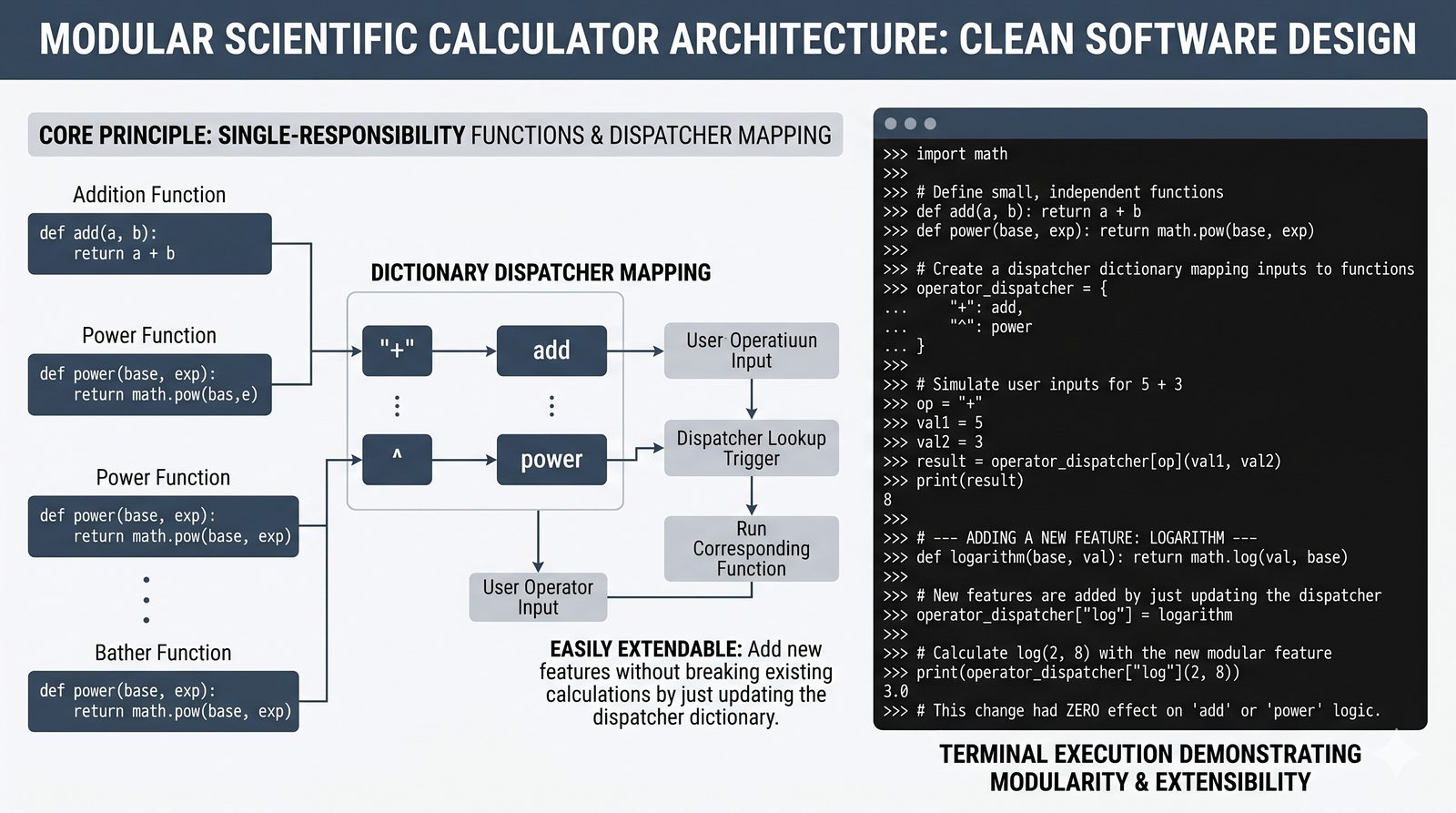
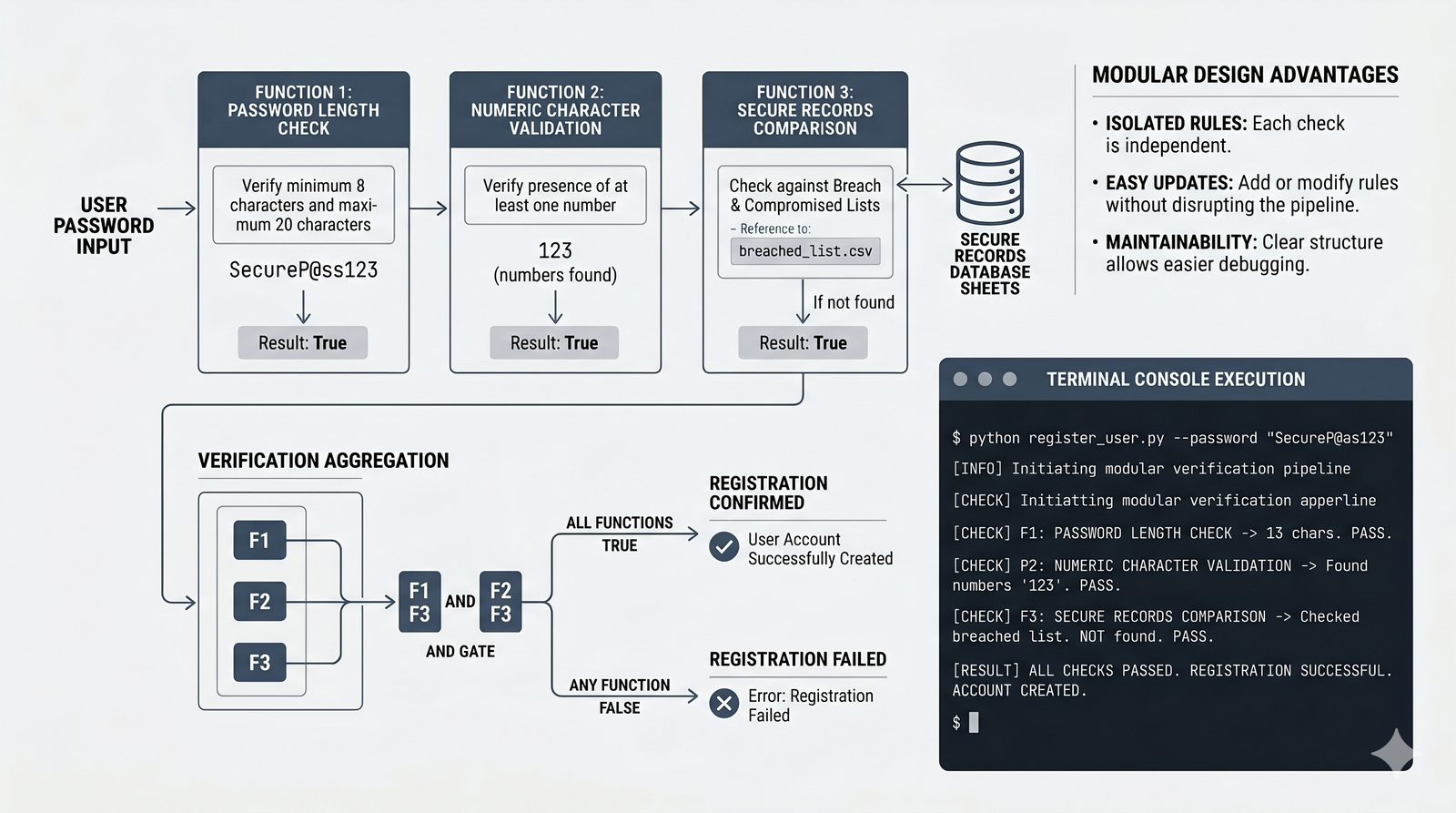
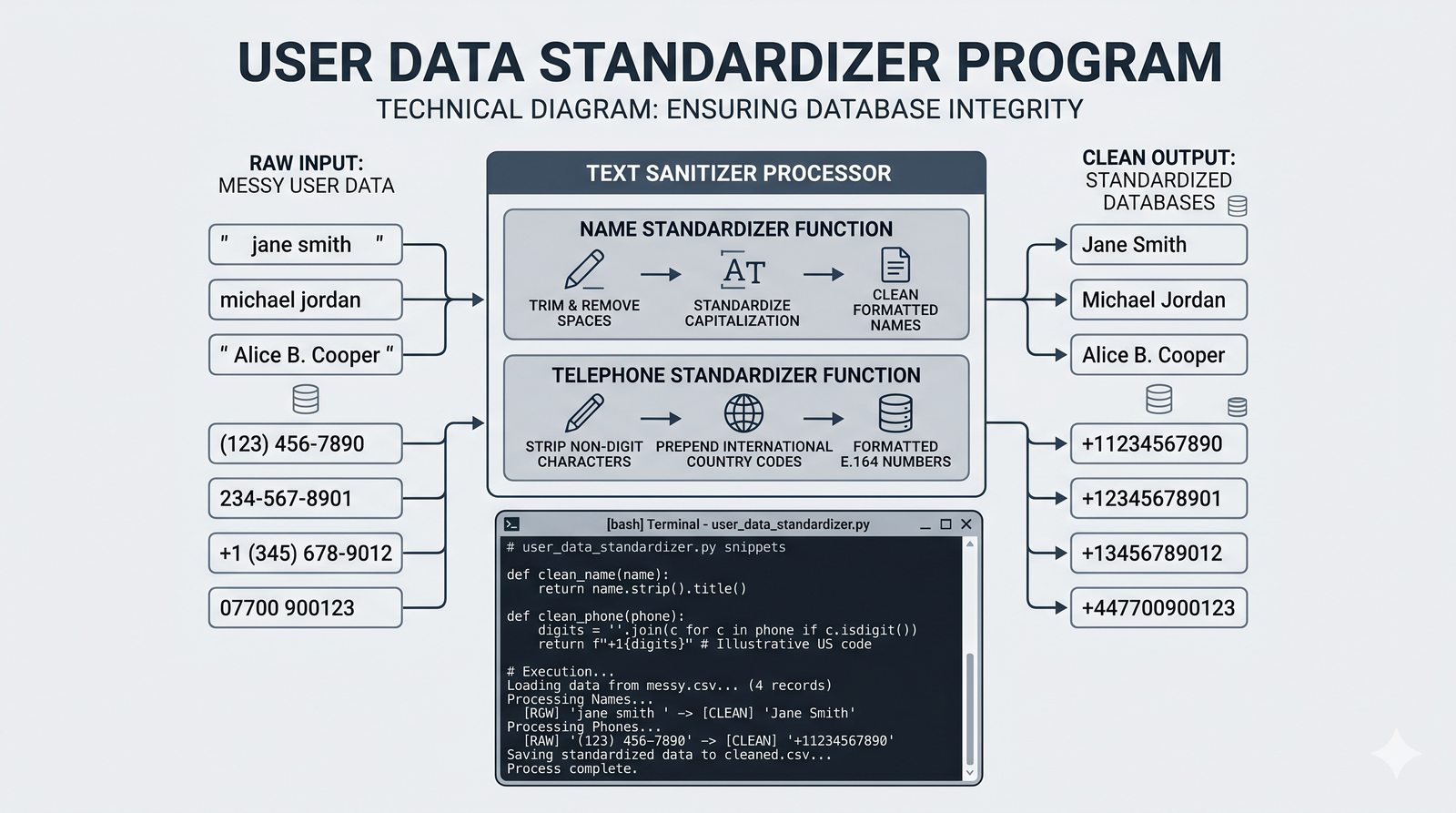
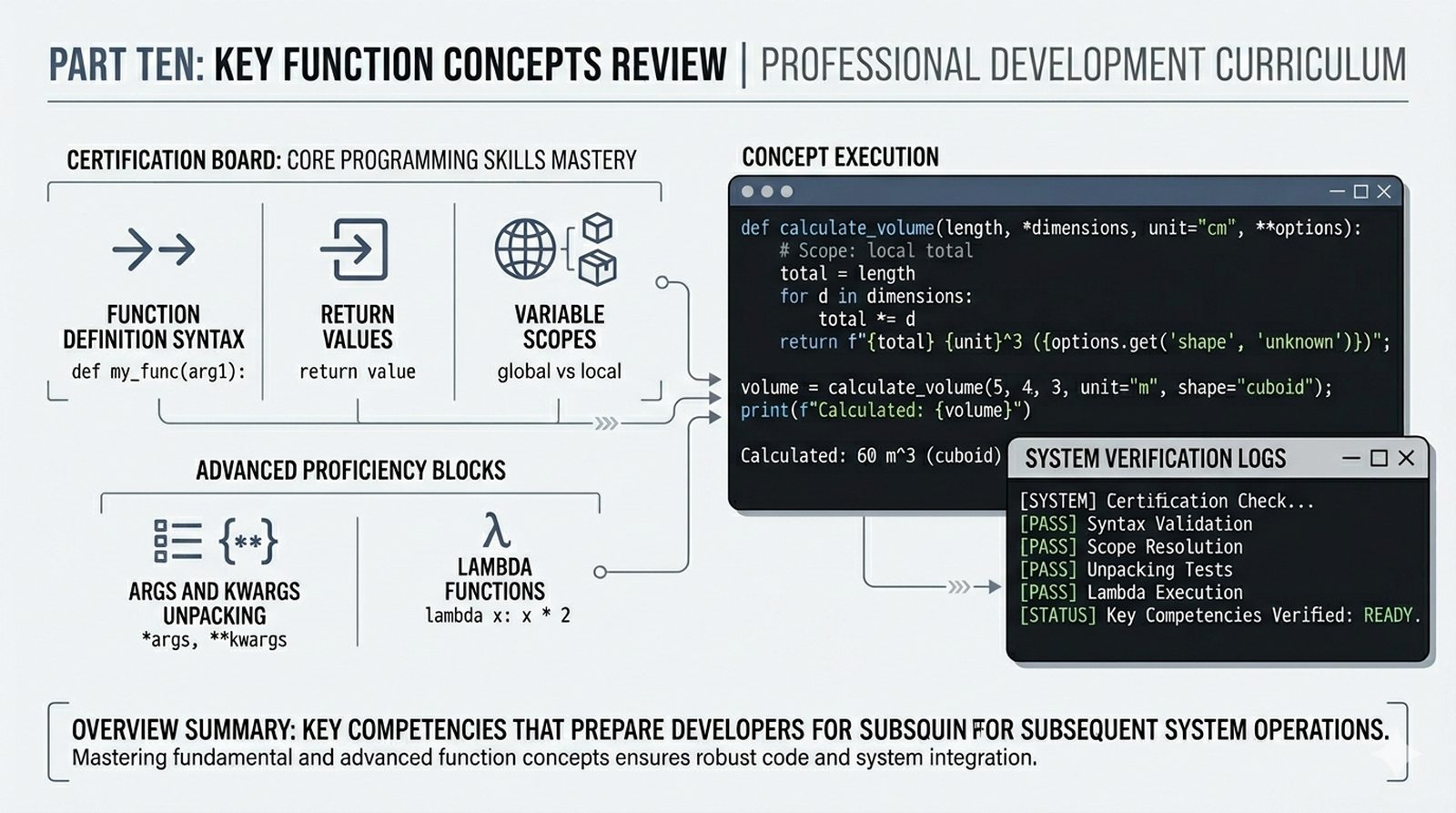
Ten moduł w całości poświęcony jest funkcjom w języku Python -- od podstaw definiowania za pomocą słowa kluczowego def, przez elastyczne przekazywanie parametrów (pozycyjne, nazwane, wartości domyślne), aż po zwracanie wyników za pomocą instrukcji return. Omówiona została różnica między parametrem a argumentem, a także niebezpieczna pułapka mutowalnych argumentów domyślnych i sposoby jej unikania. Szczegółowo przeanalizowano zasięgi zmiennych (lokalny, globalny, reguła LEGB) oraz zaawansowane mechanizmy, takie jak *args, **kwargs, funkcje lambda, rekurencja i domknięcia. Moduł wprowadza również funkcje wyższego rzędu map i filter oraz praktyczne wzorce projektowe, w tym zasadę pojedynczej odpowiedzialności i programowanie bez zmiennych globalnych. Całość uzupełniają praktyczne ćwiczenia i przykładowe programy (kalkulator naukowy, system weryfikacji haseł, standaryzator danych), które utrwalają omawiane koncepcje w realnych zastosowaniach.
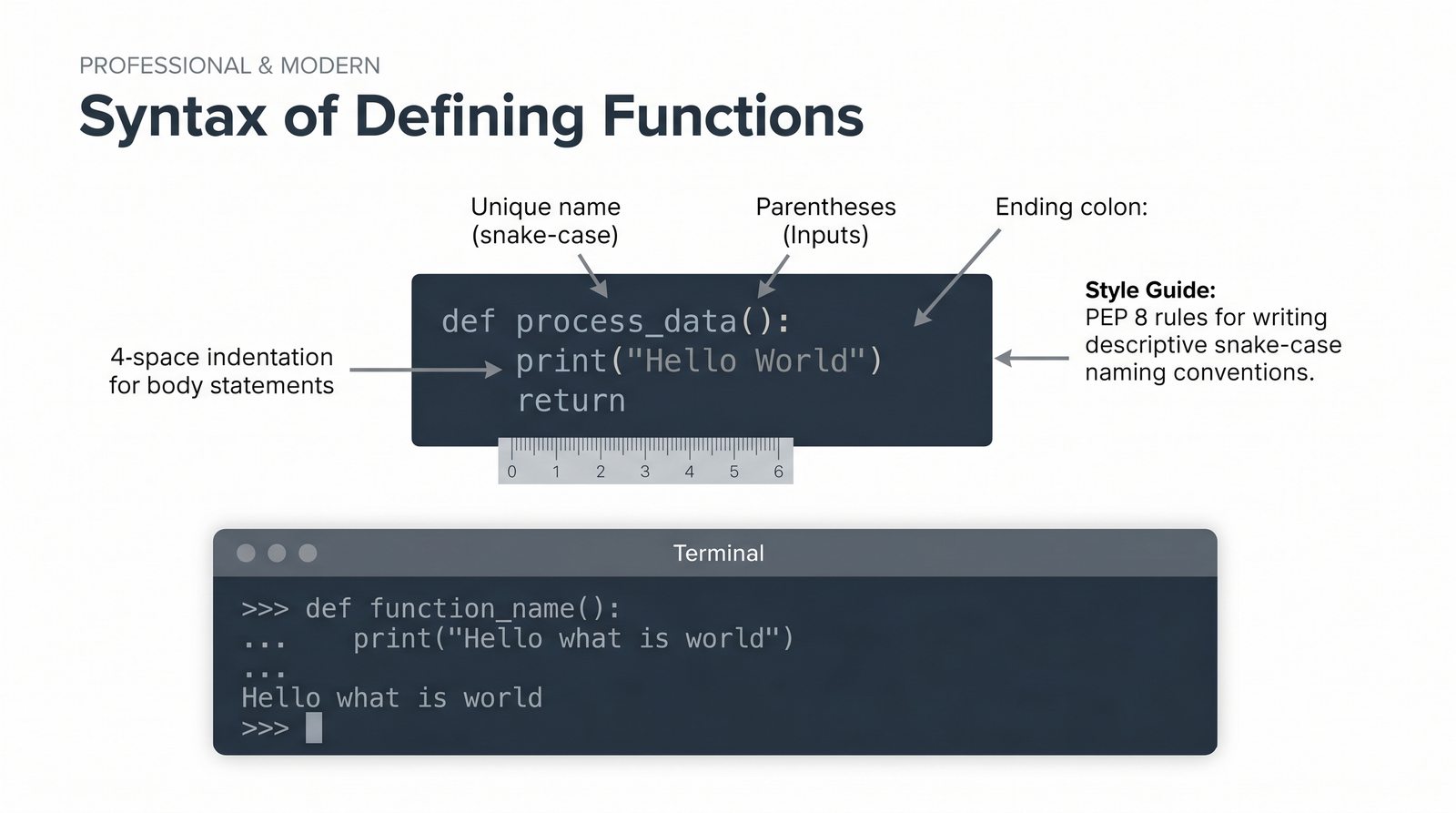
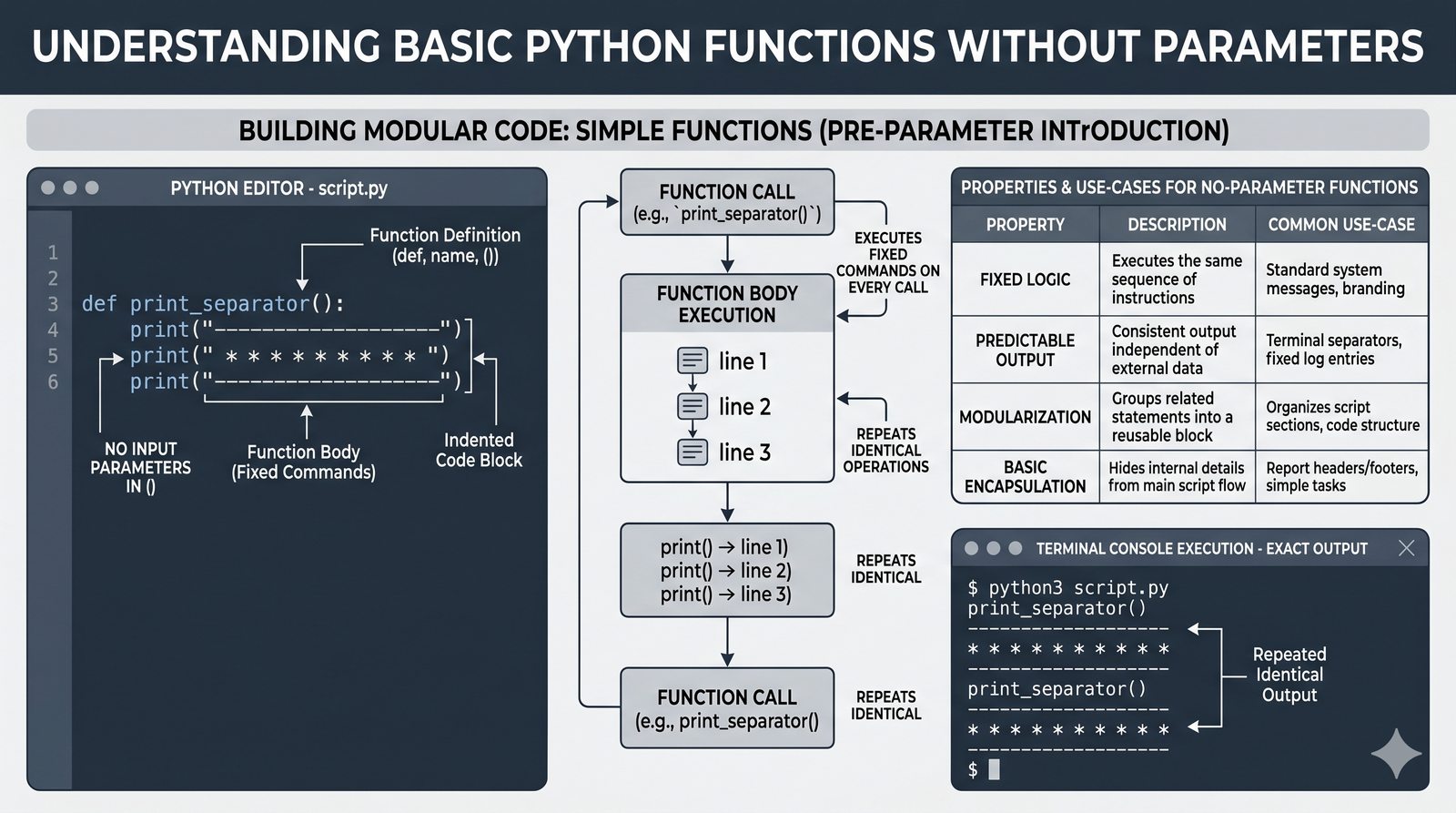
- Definiowanie funkcji -- składnia
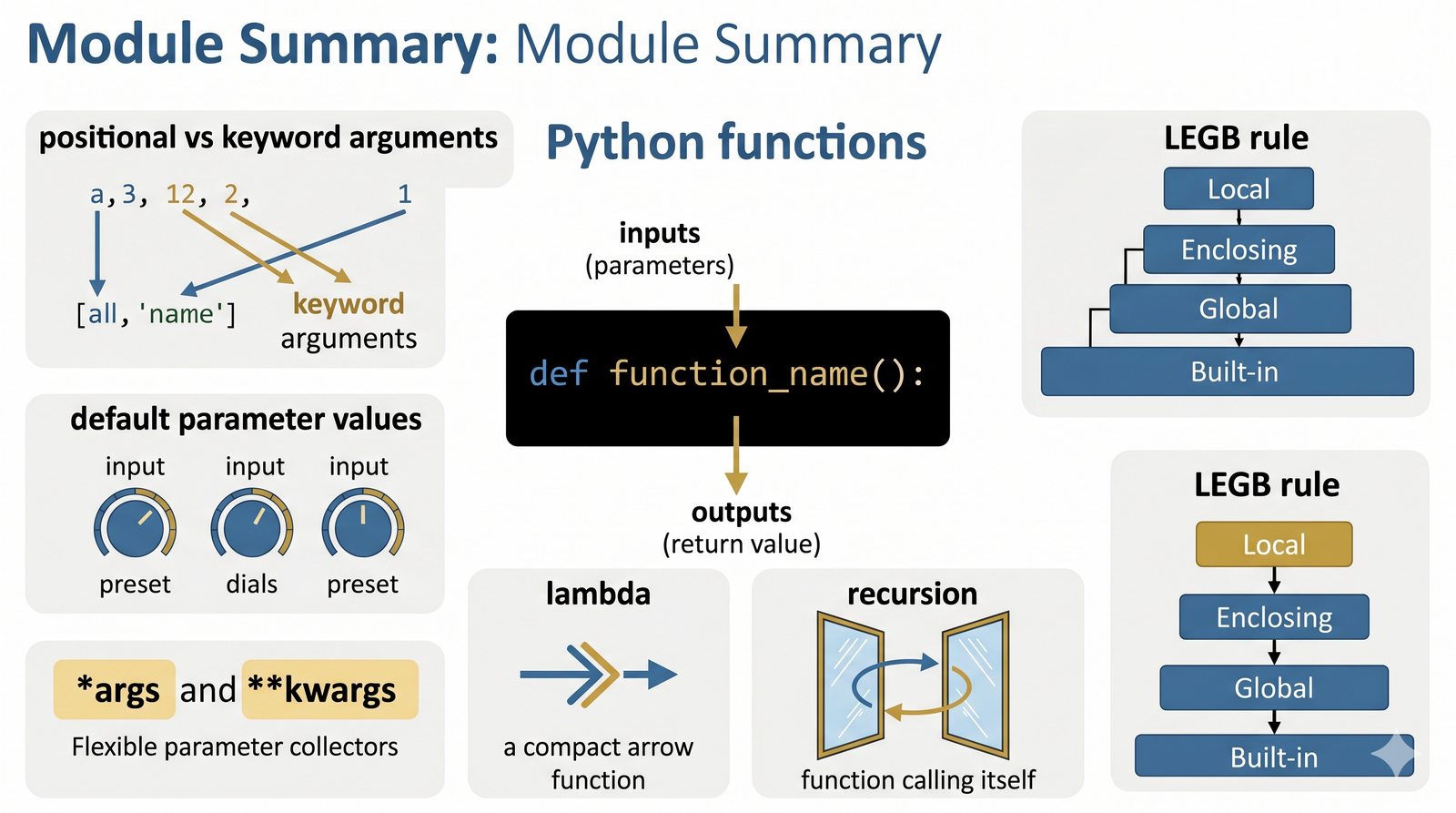
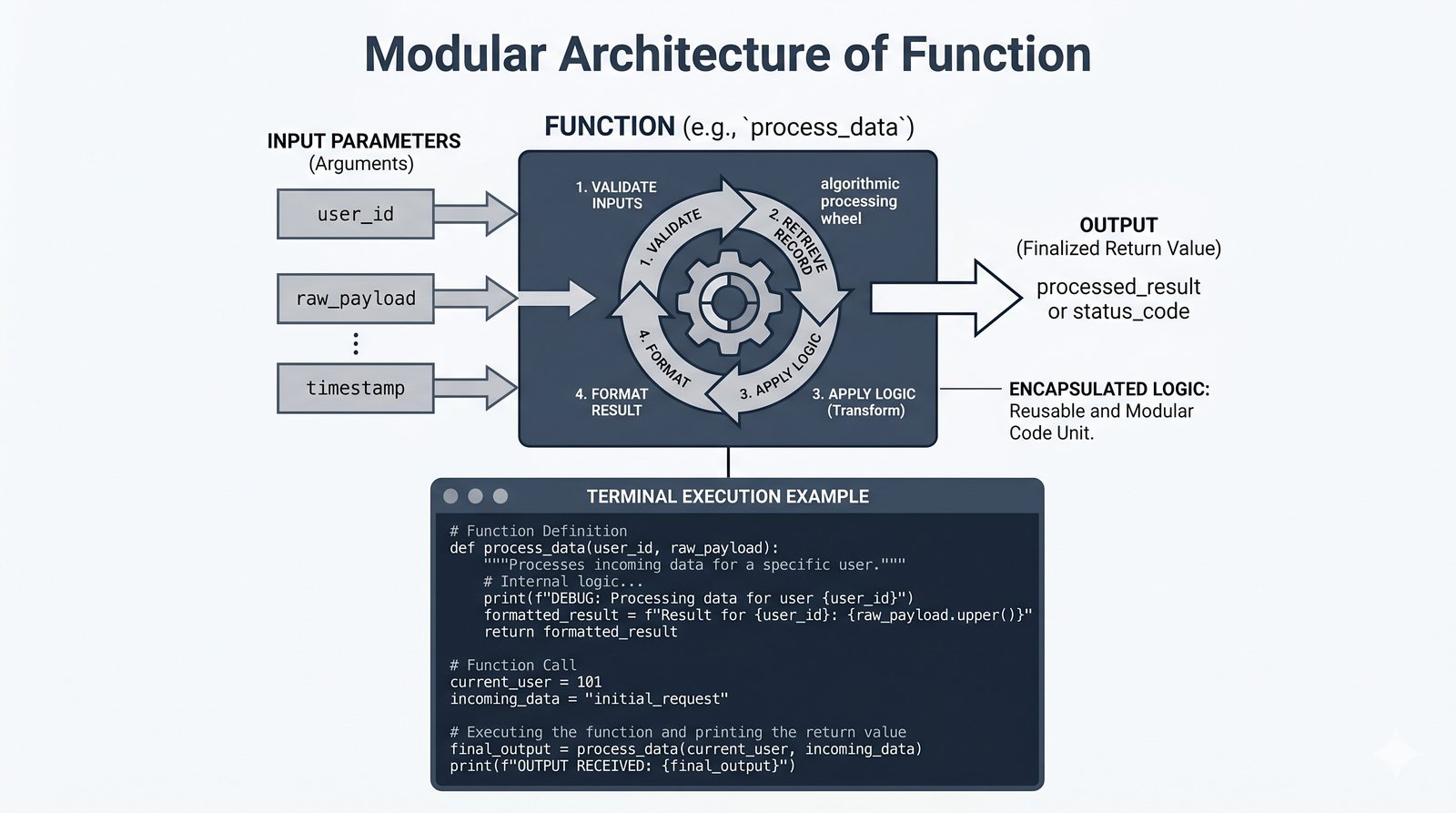
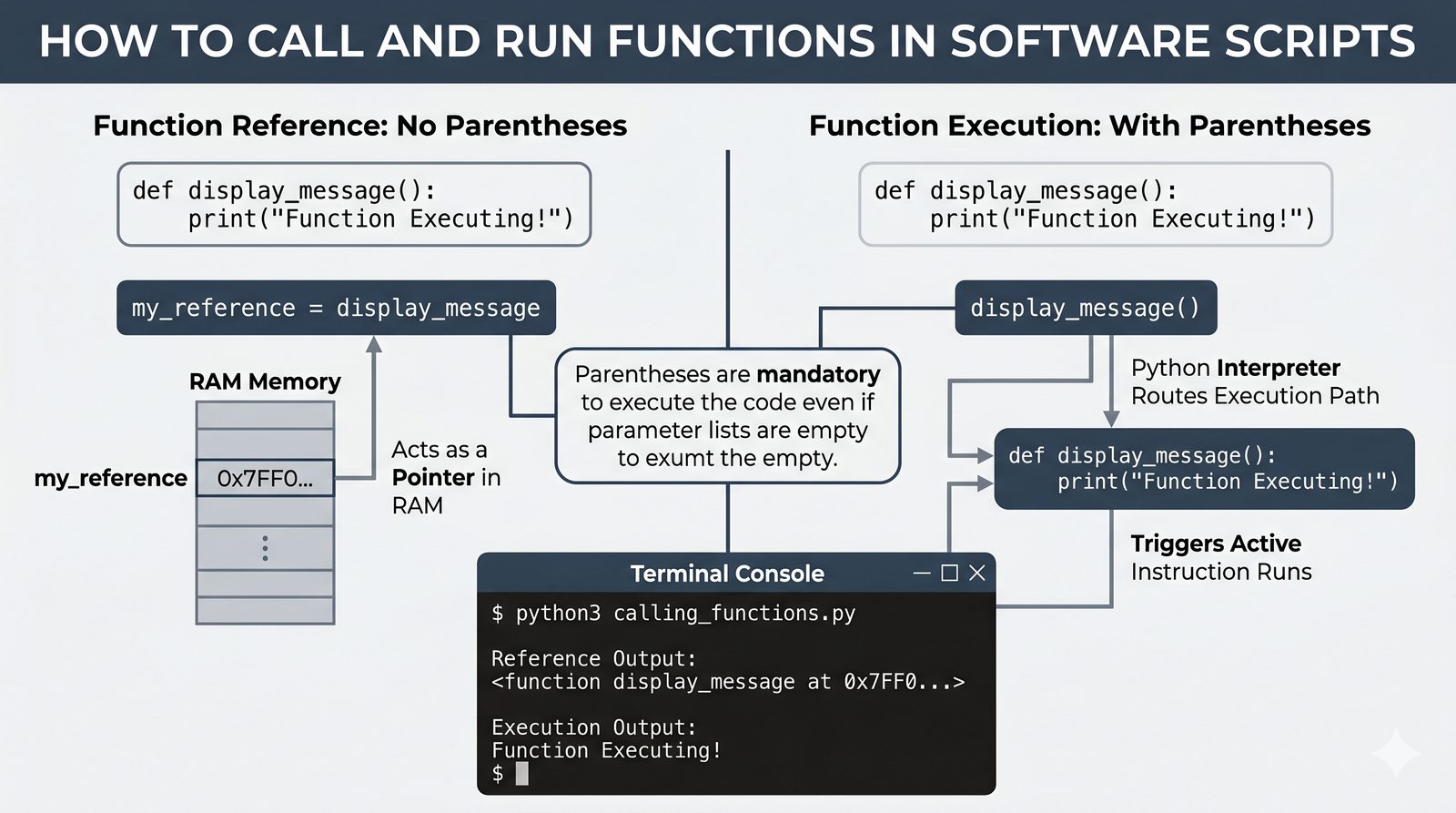
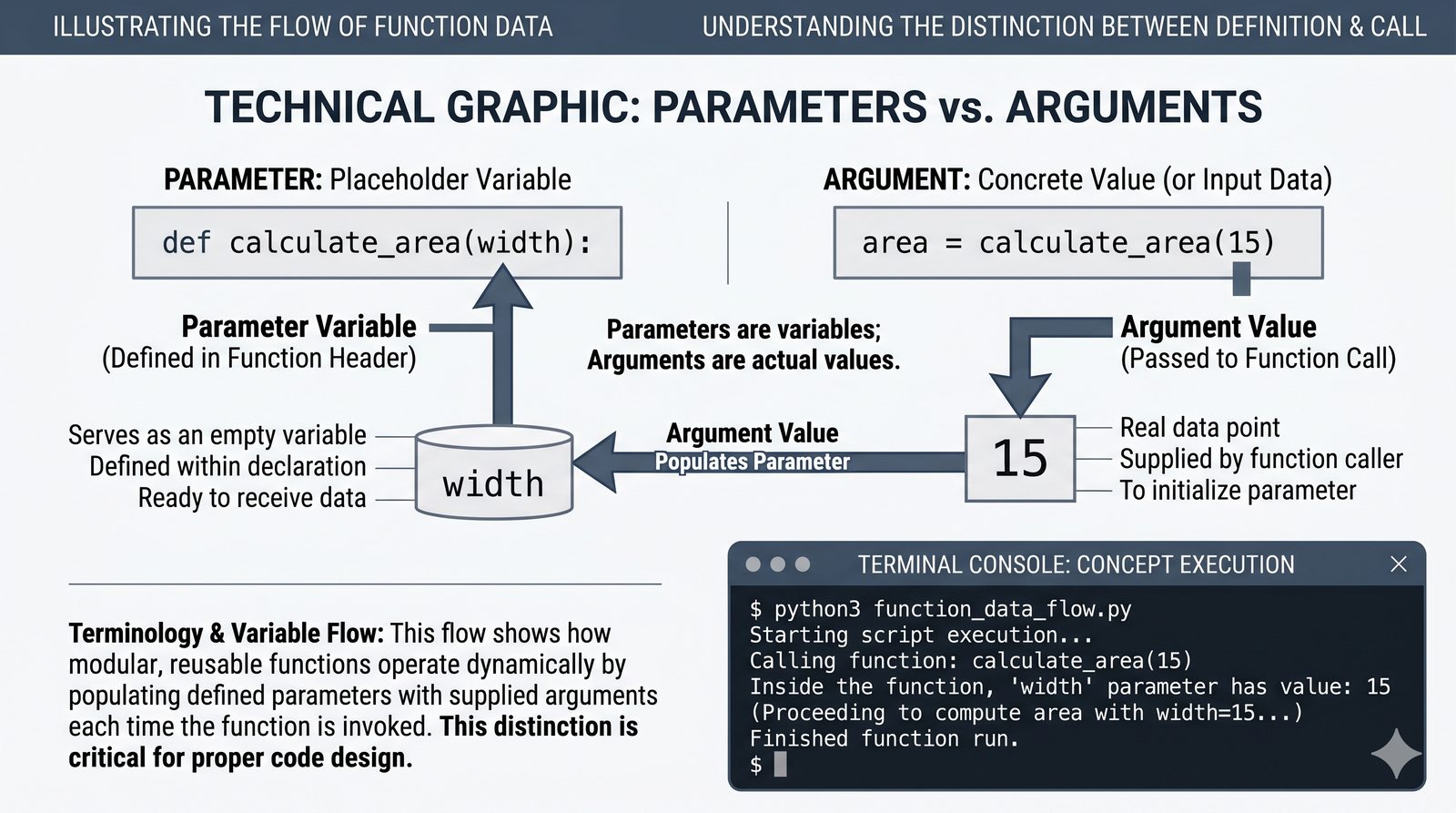
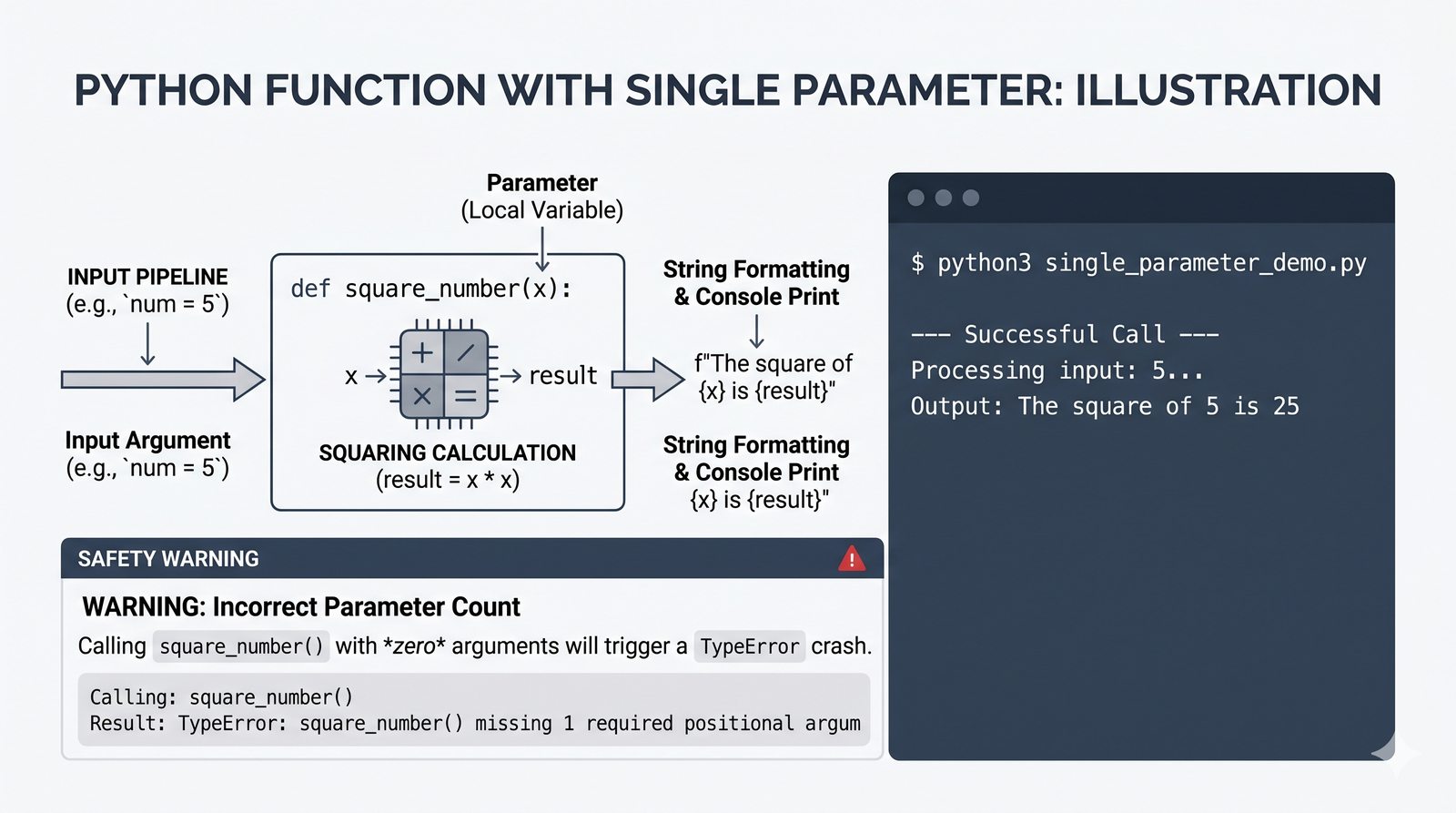
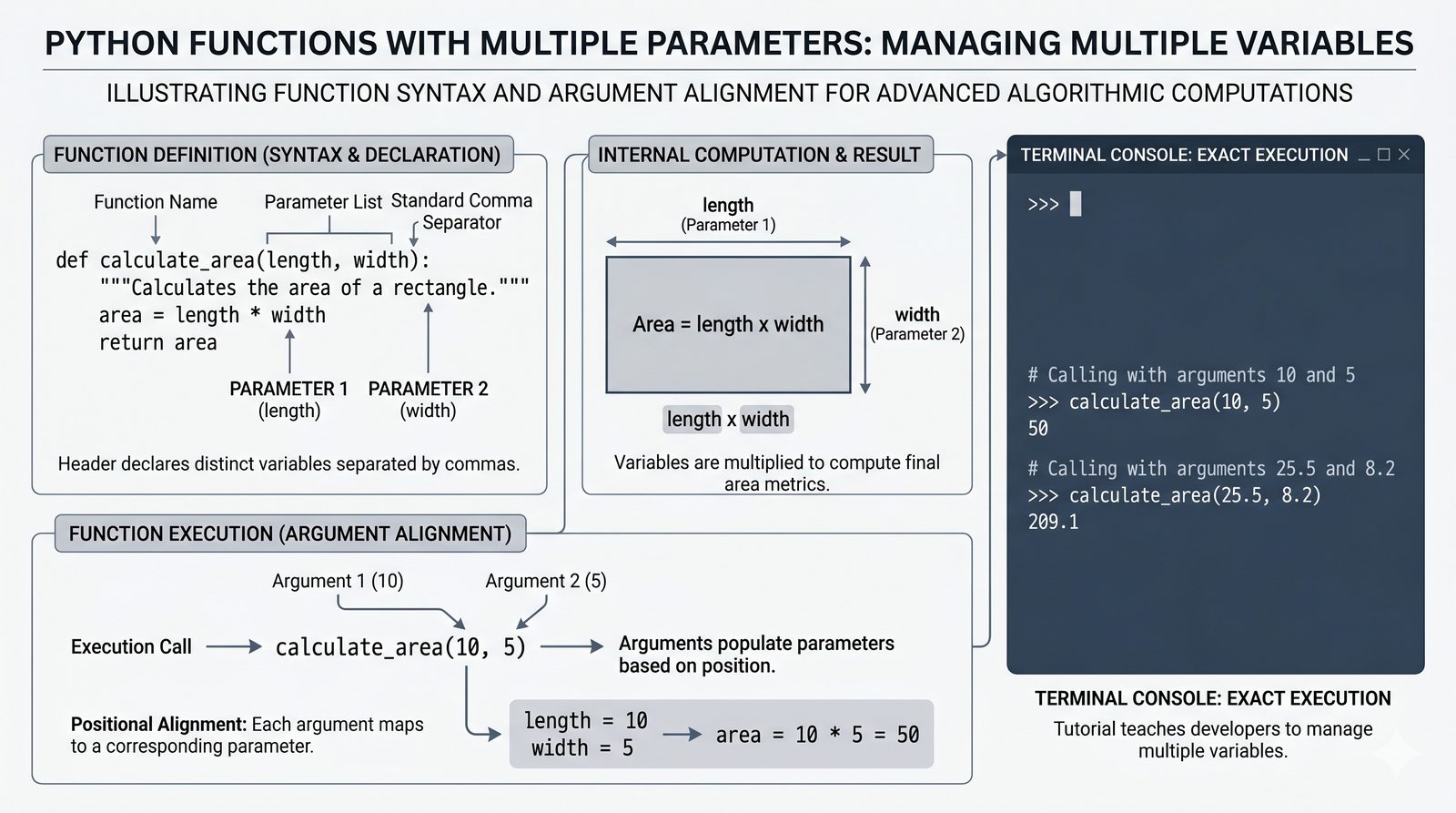
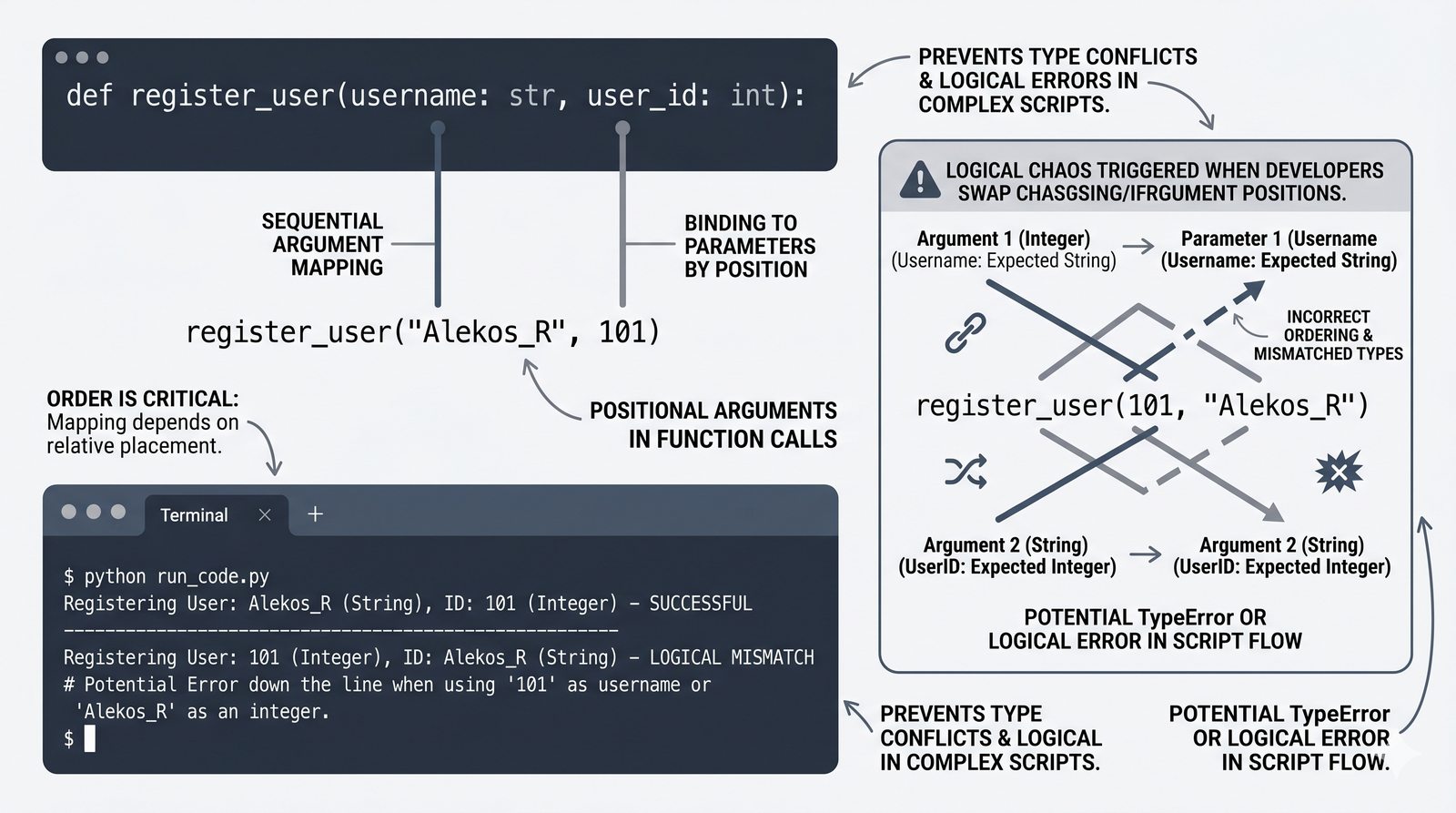
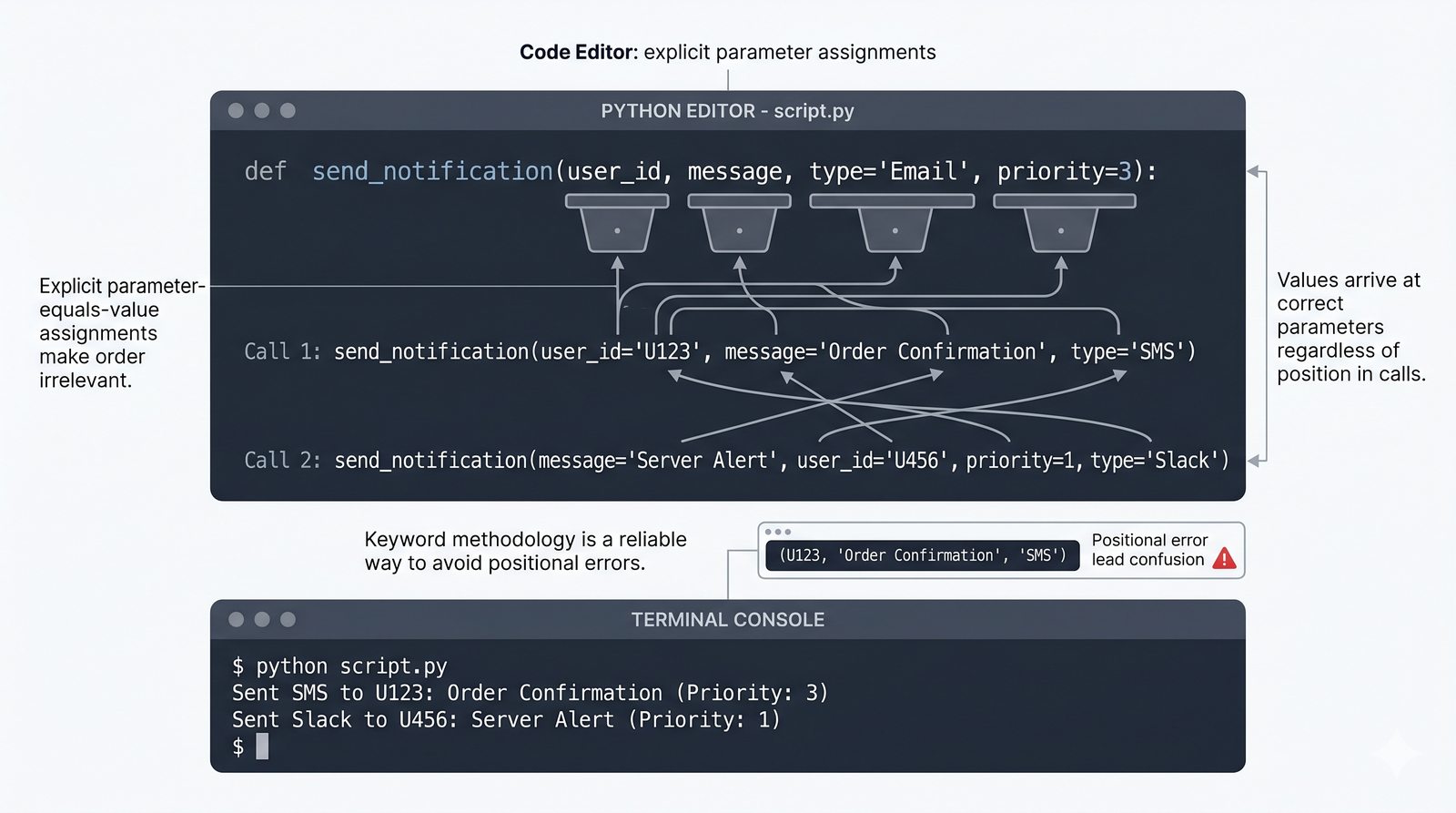
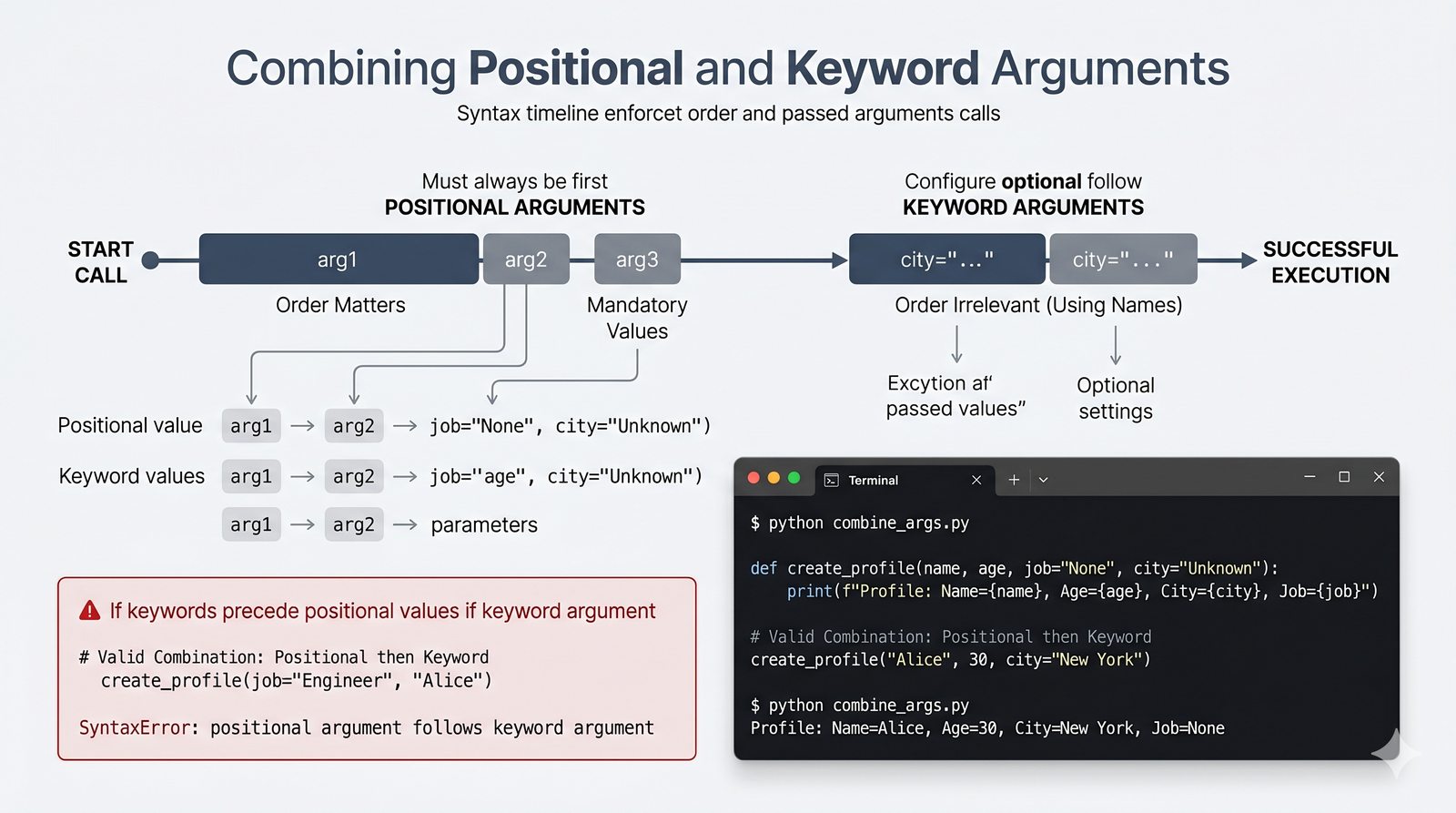
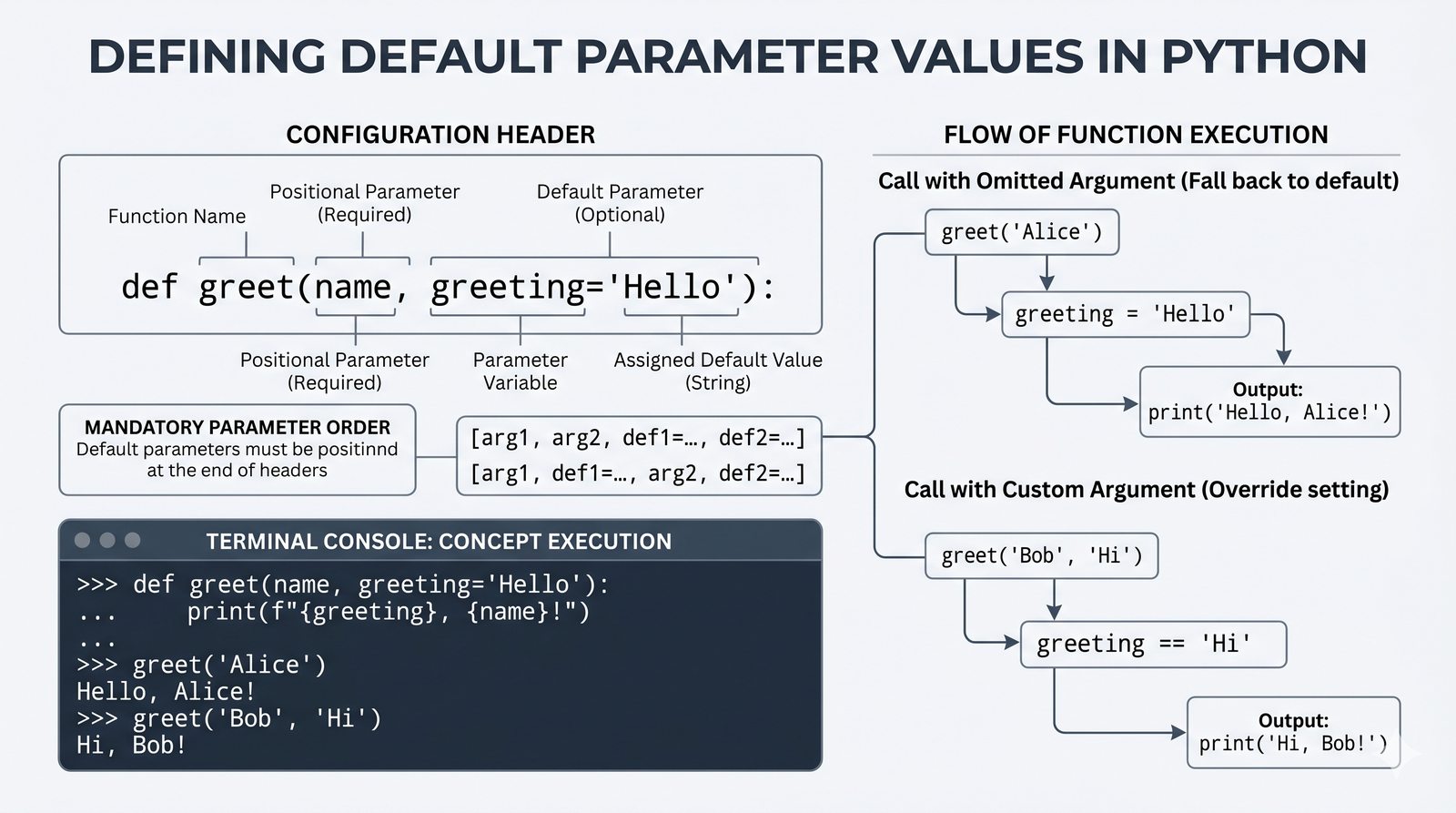
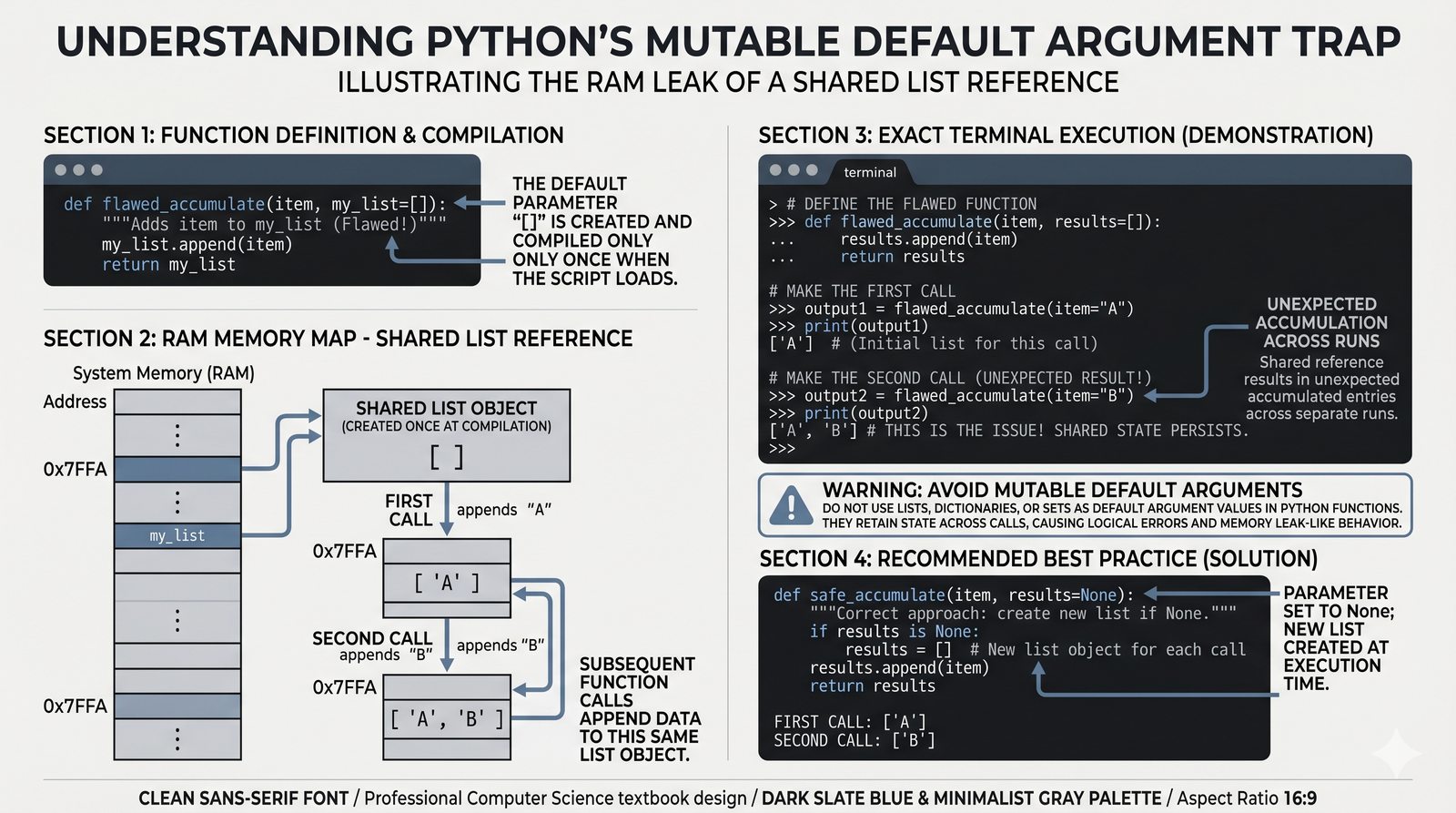
def, parametry i argumenty (pozycyjne, nazwane, wartości domyślne), różnica między parametrem a argumentem - Zwracanie wartości -- instrukcja
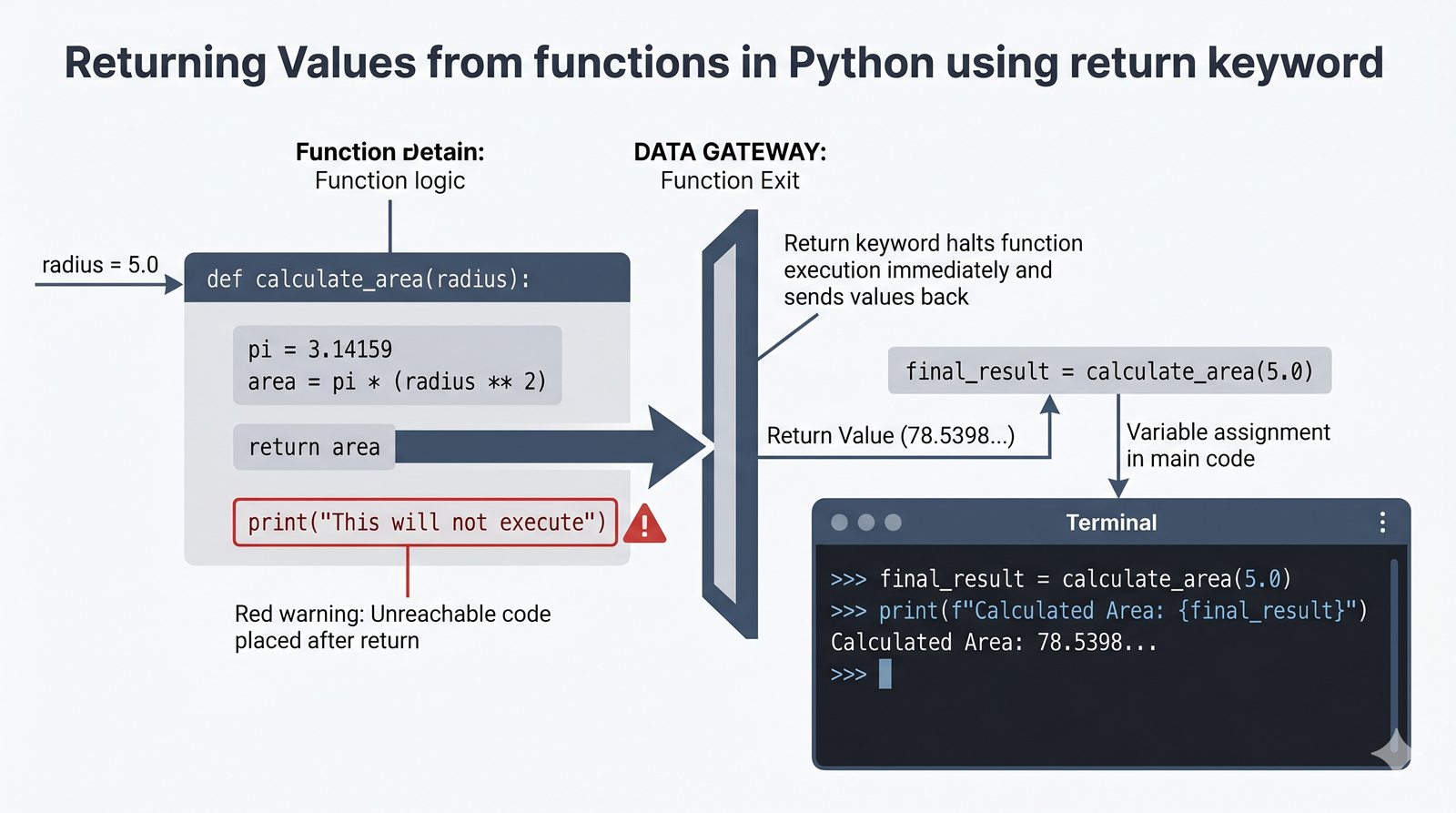
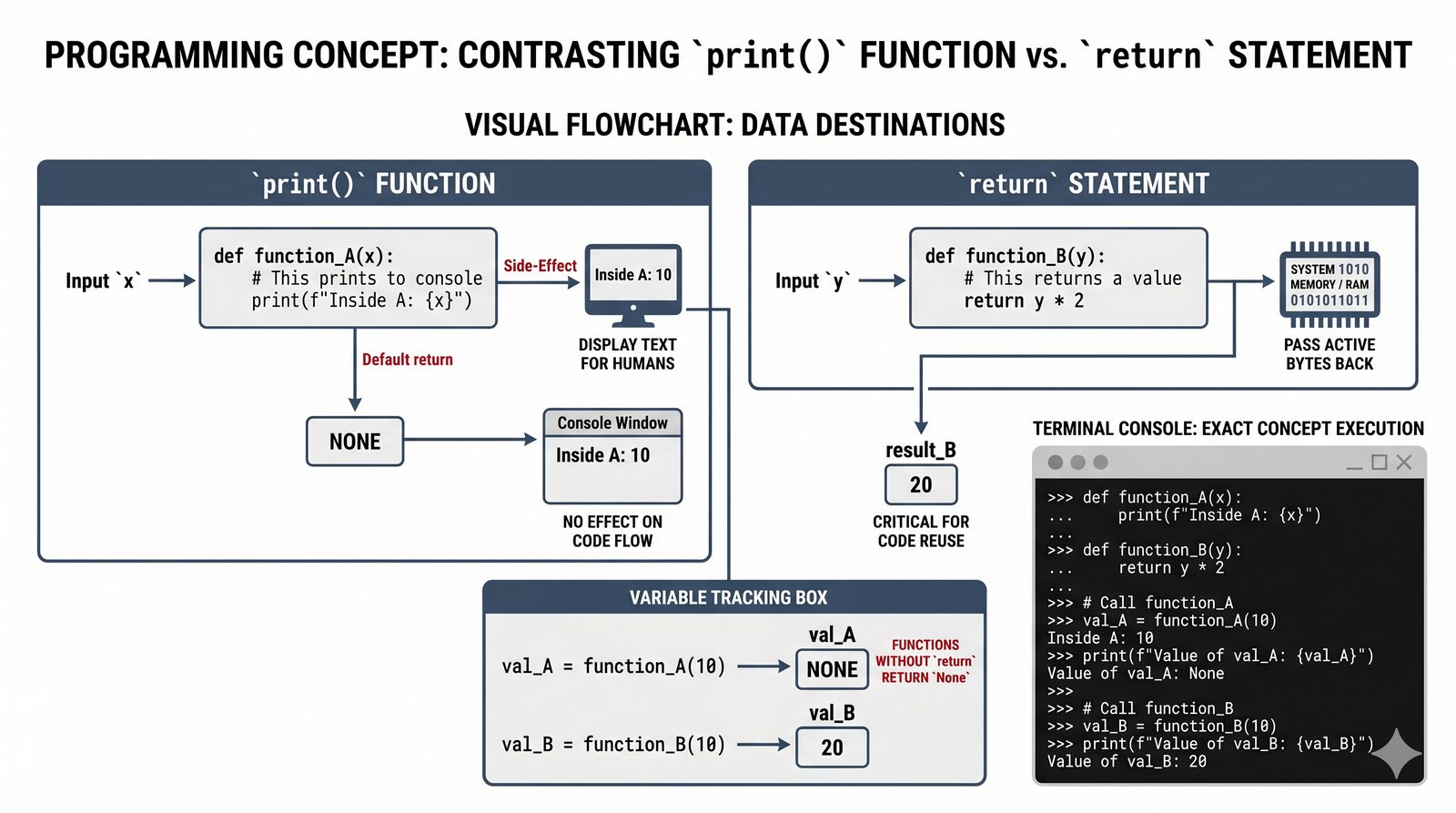
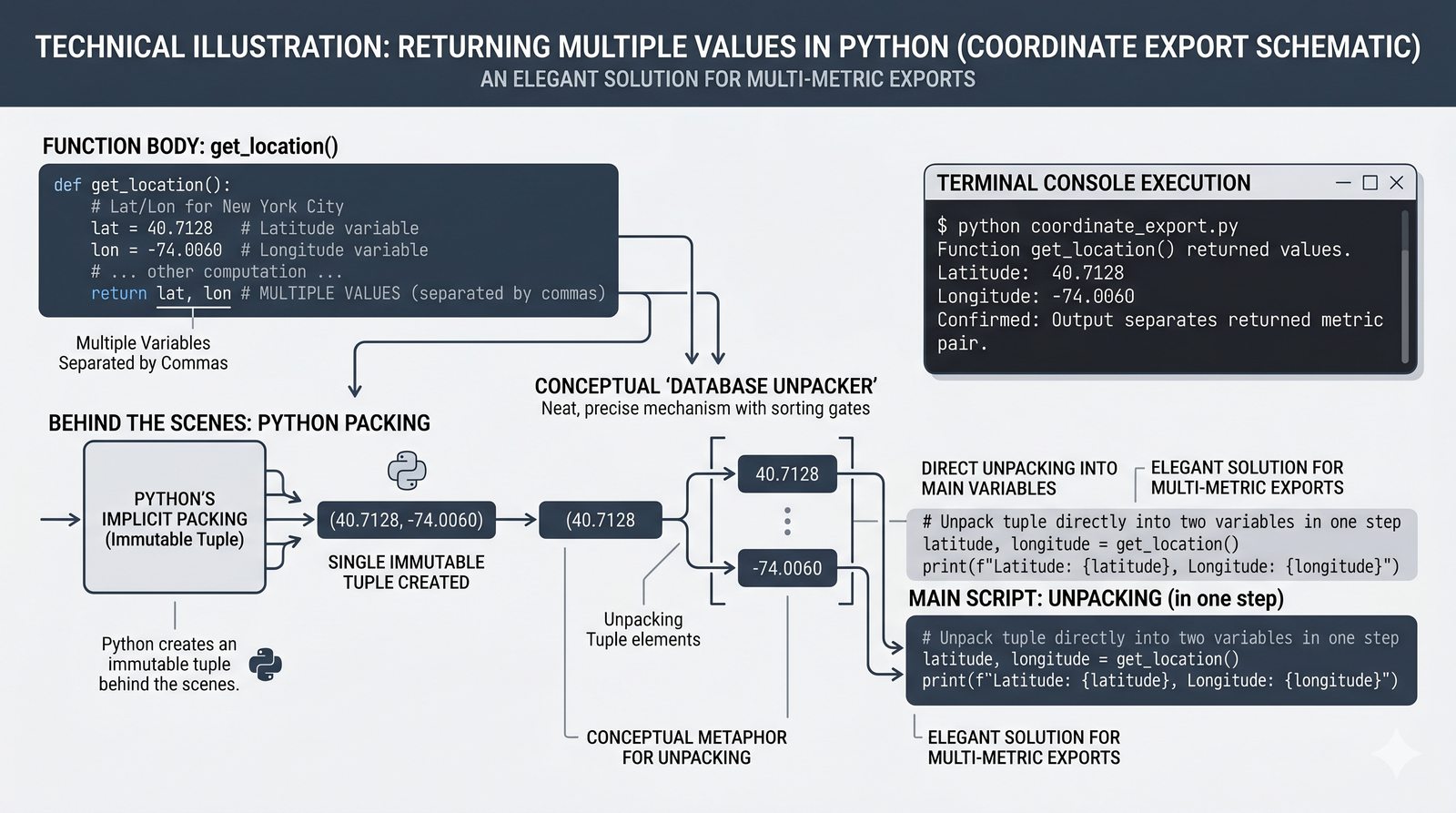
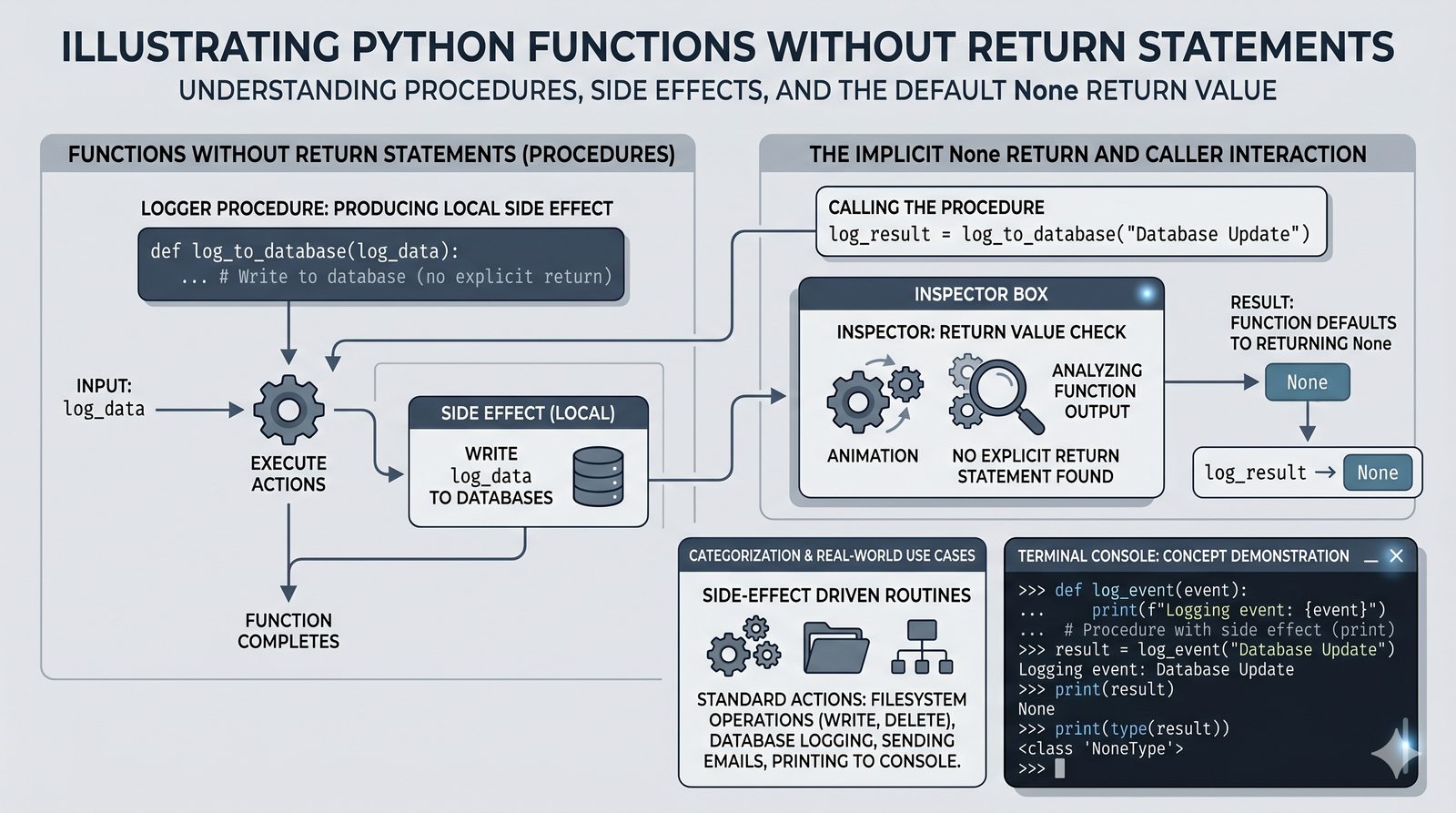
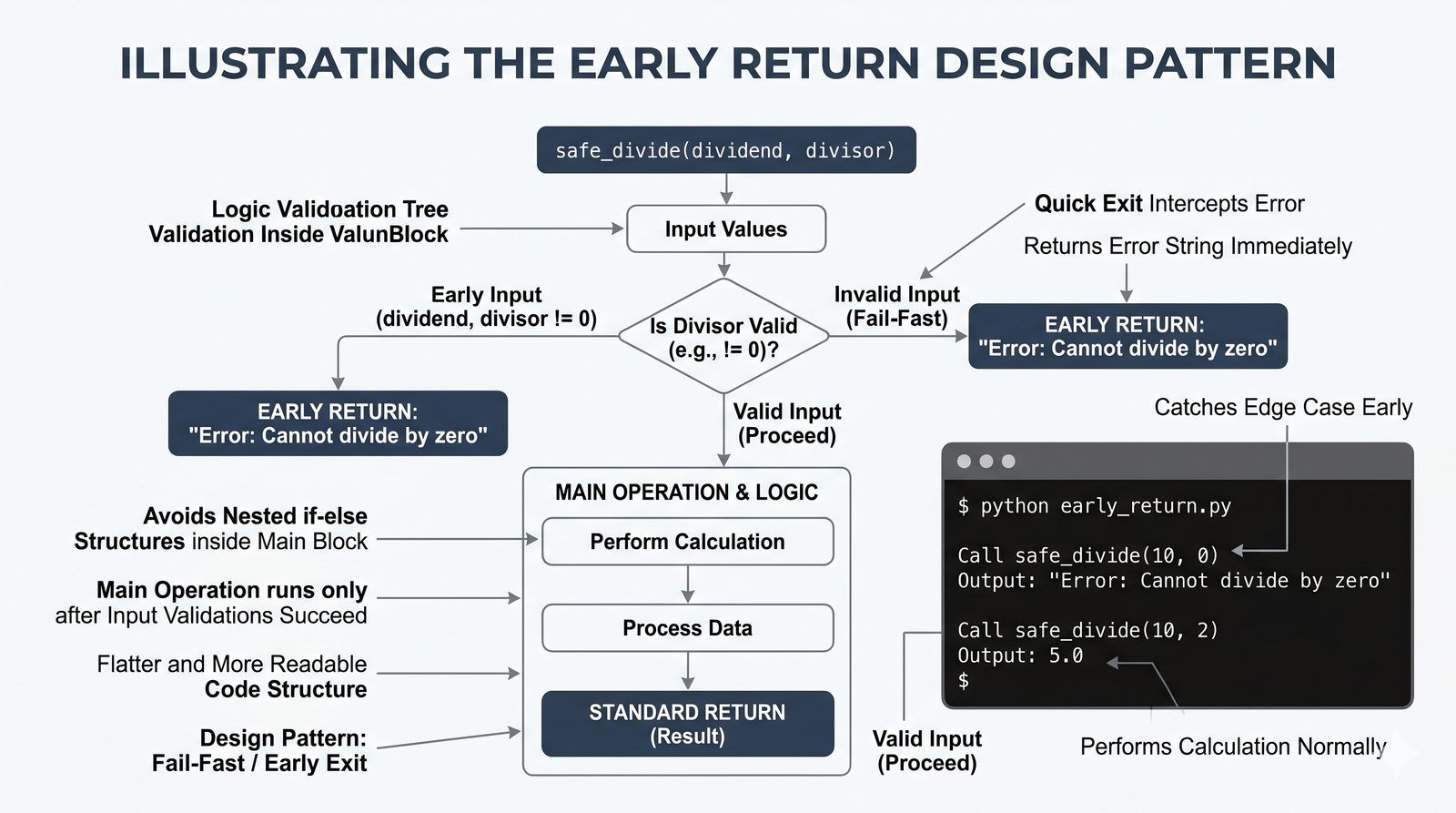
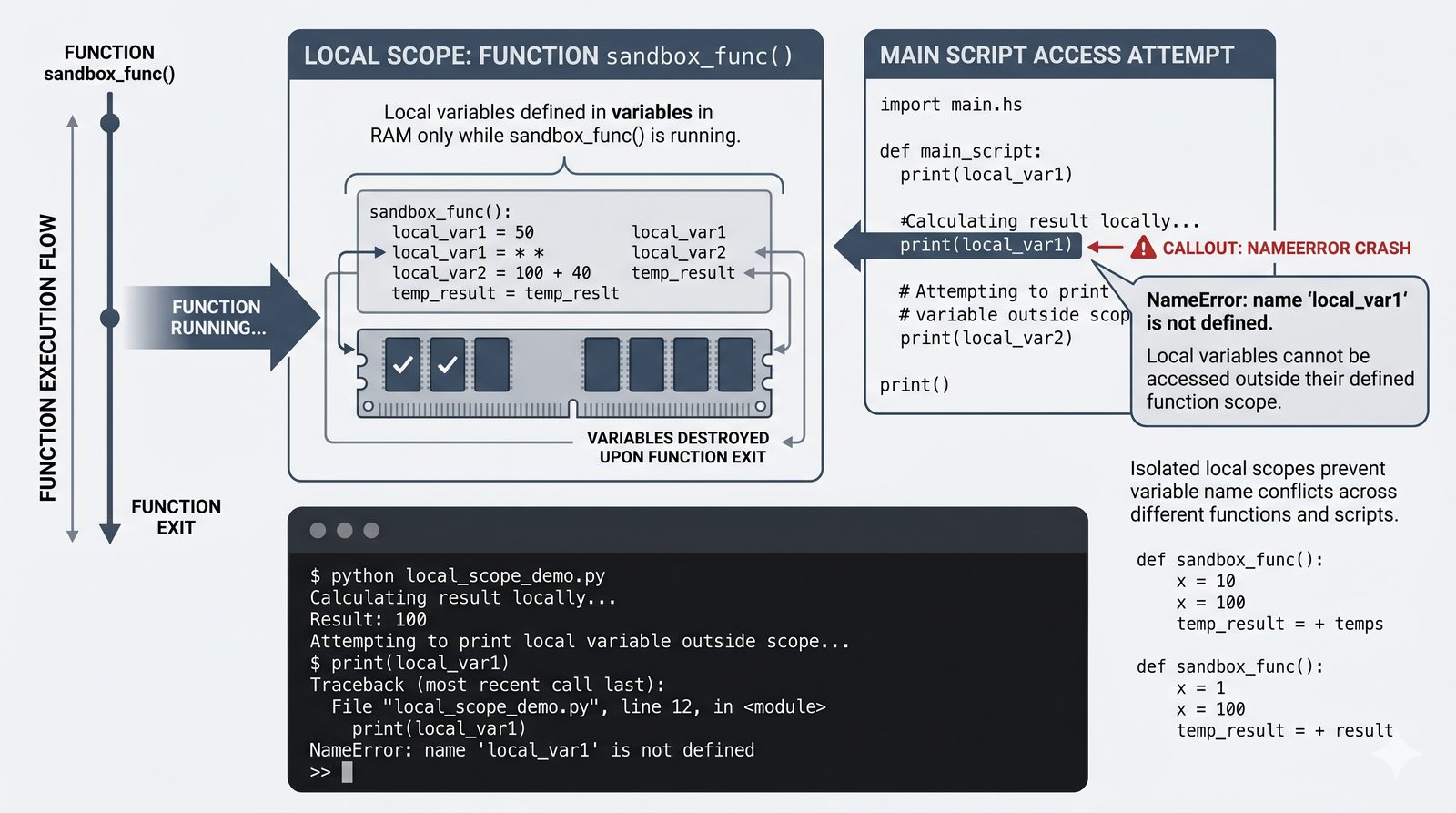
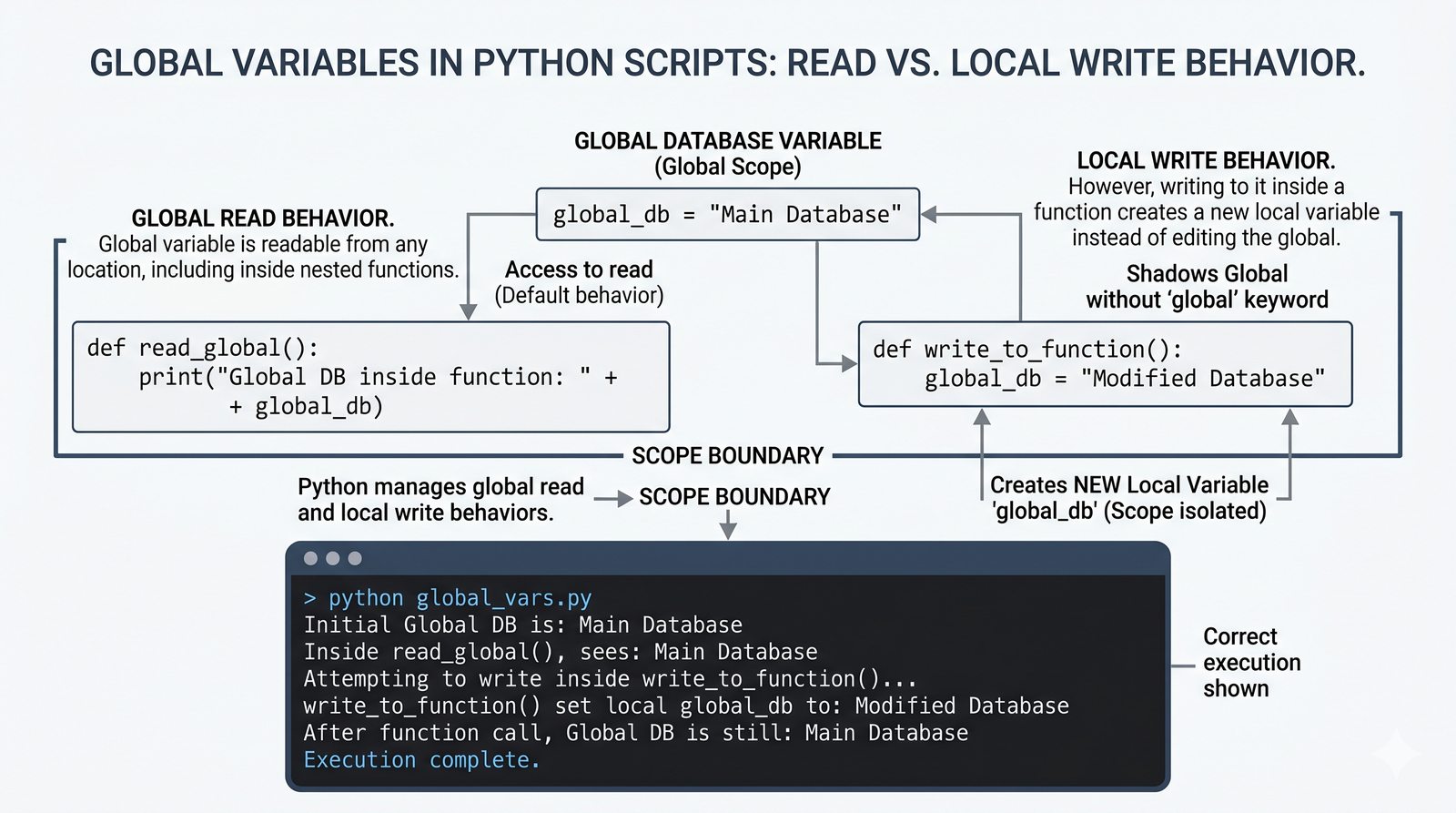
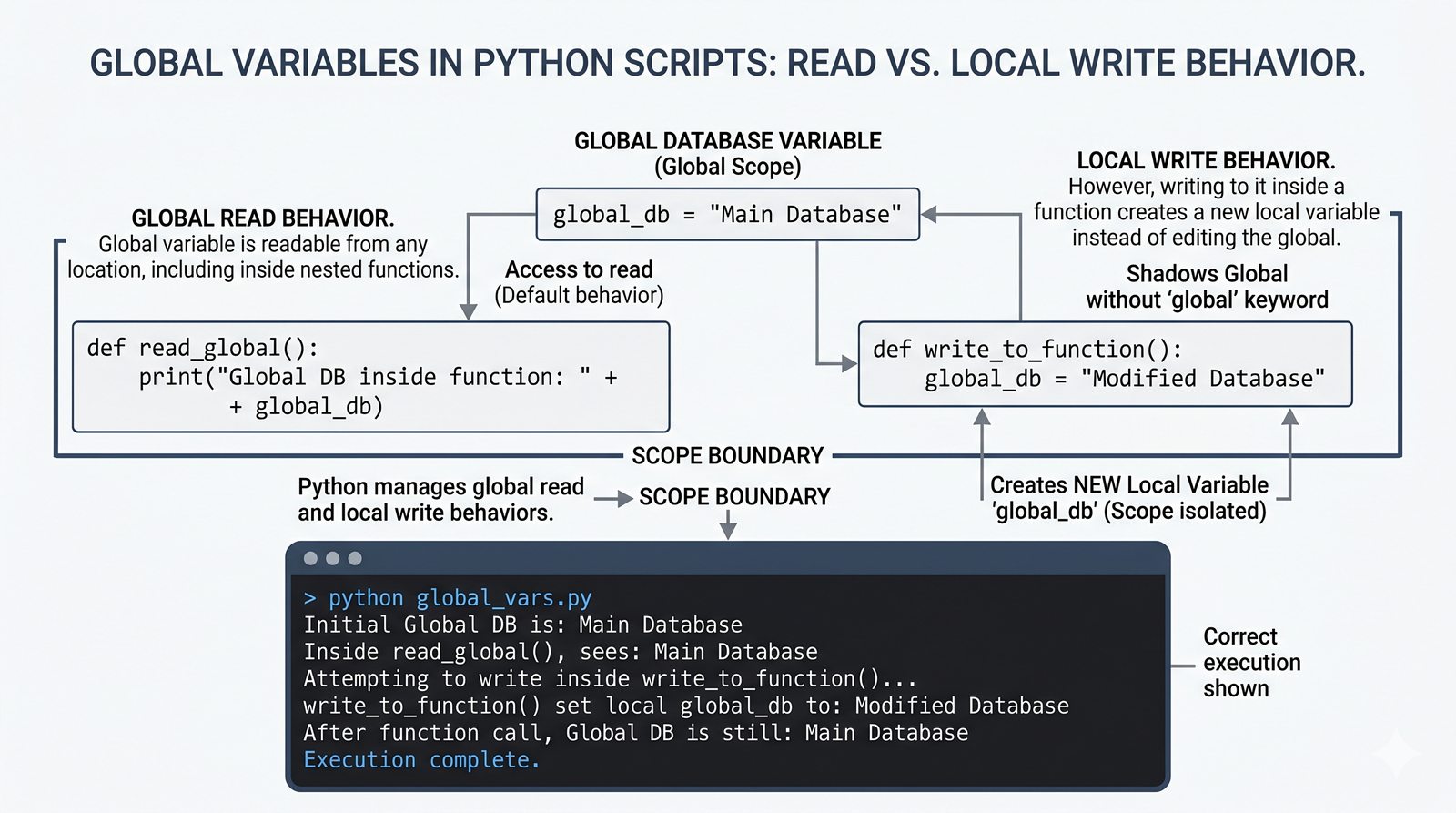
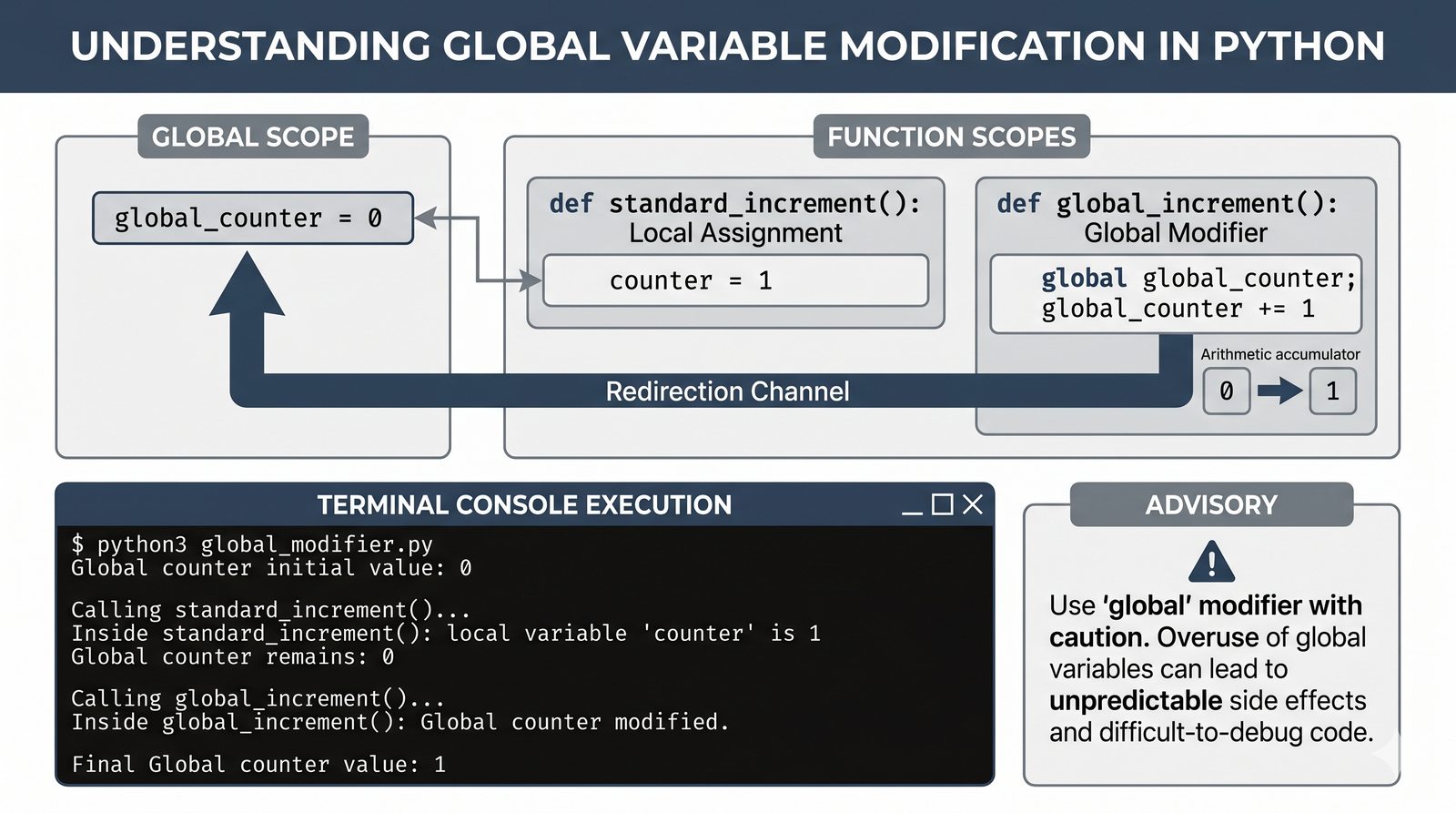
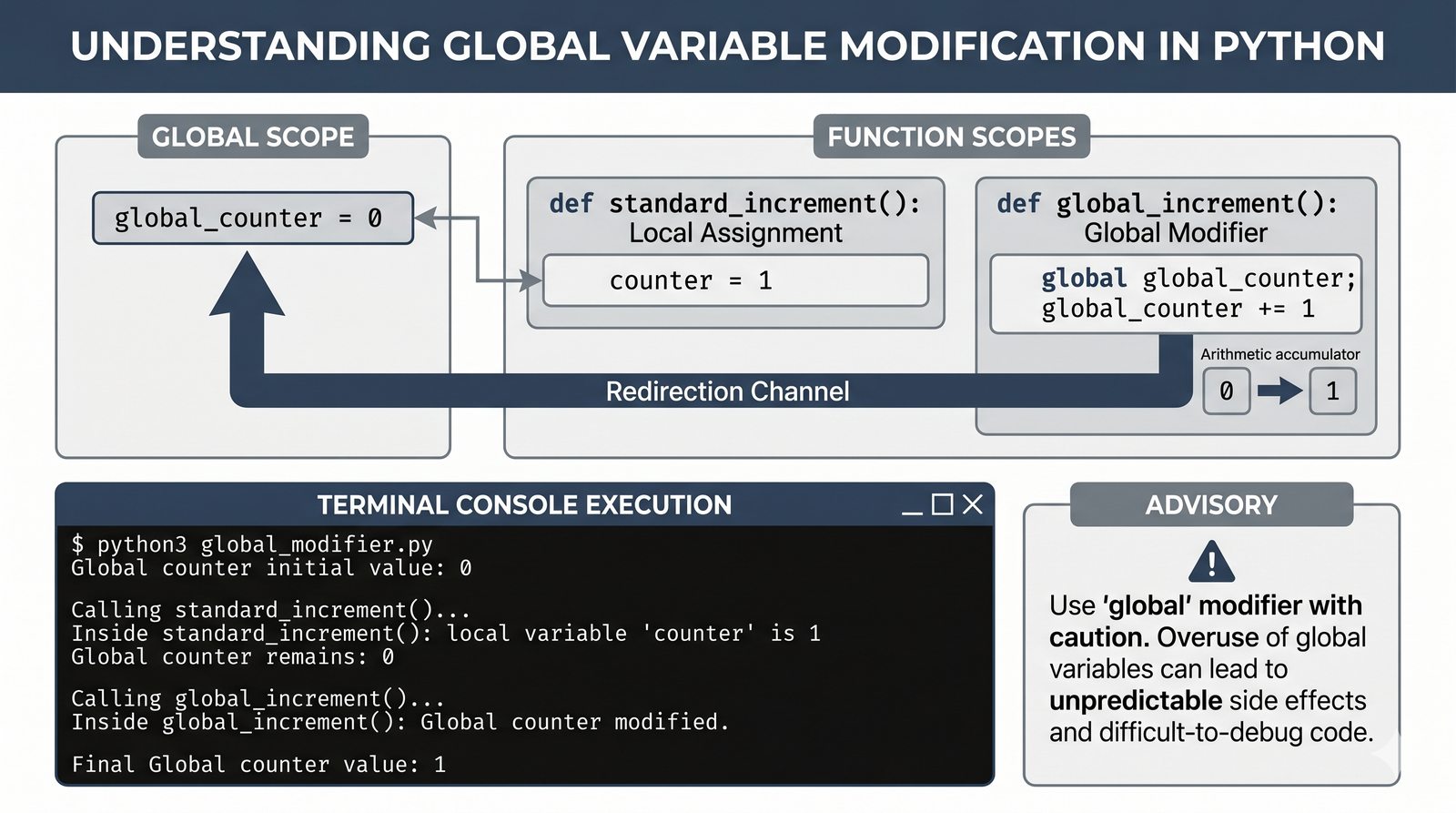
return, różnica międzyreturnaprint, zwracanie wielu wartości, wczesny return (early return) - Zasięgi zmiennych -- zmienne lokalne i globalne, reguła LEGB, słowo kluczowe
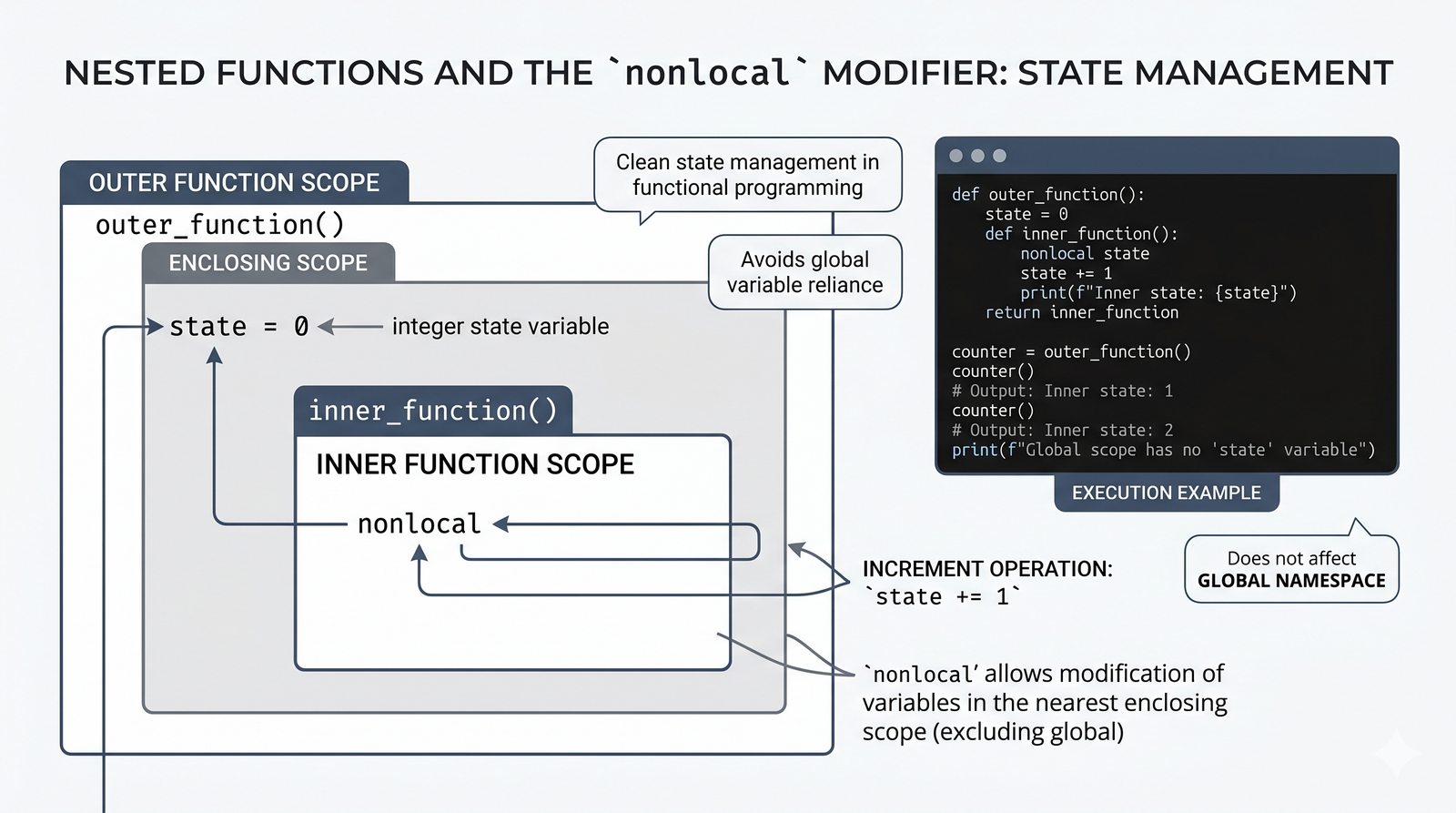
globalinonlocal, zasada unikaniaglobal - Zaawansowane mechanizmy --
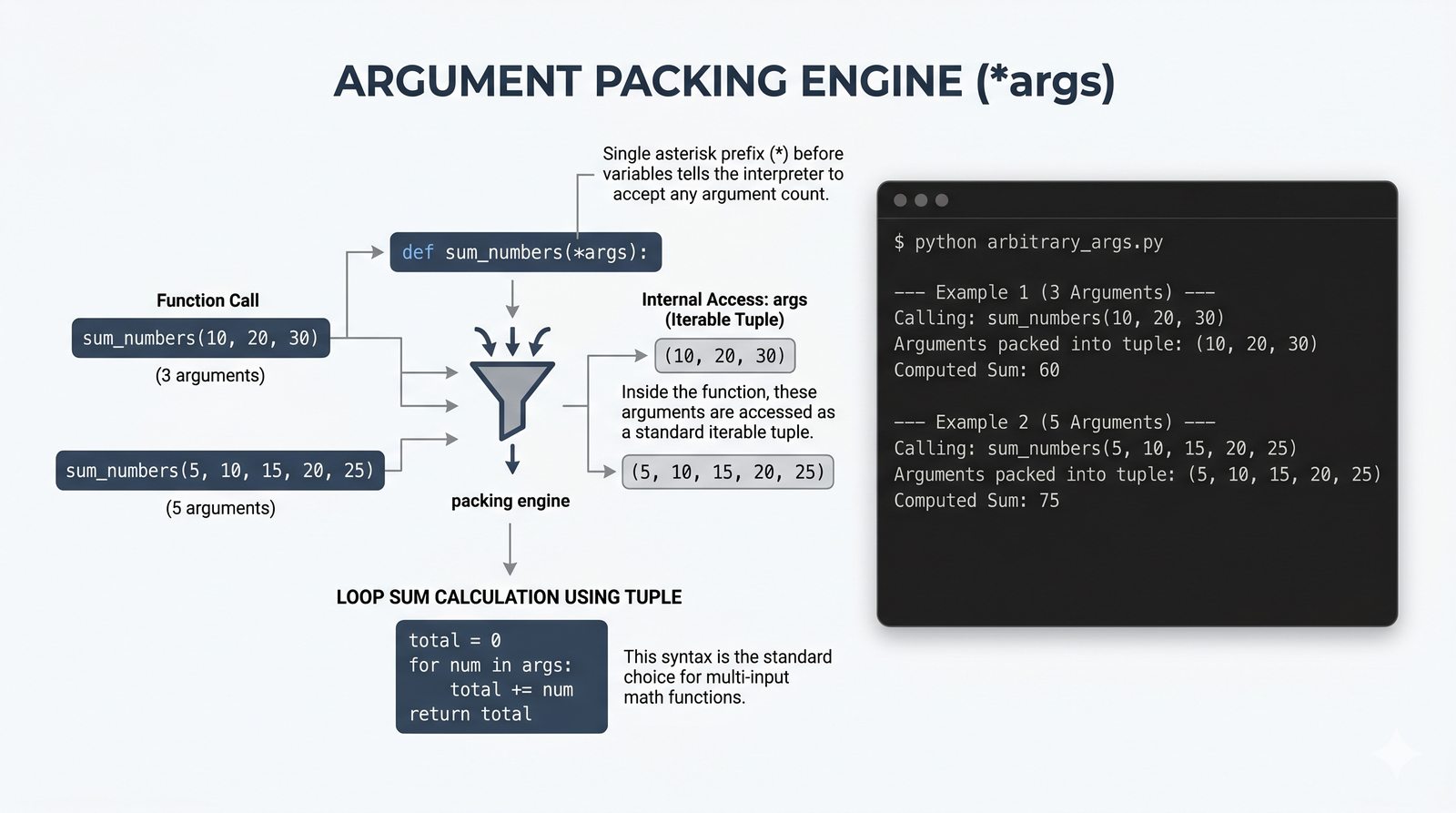
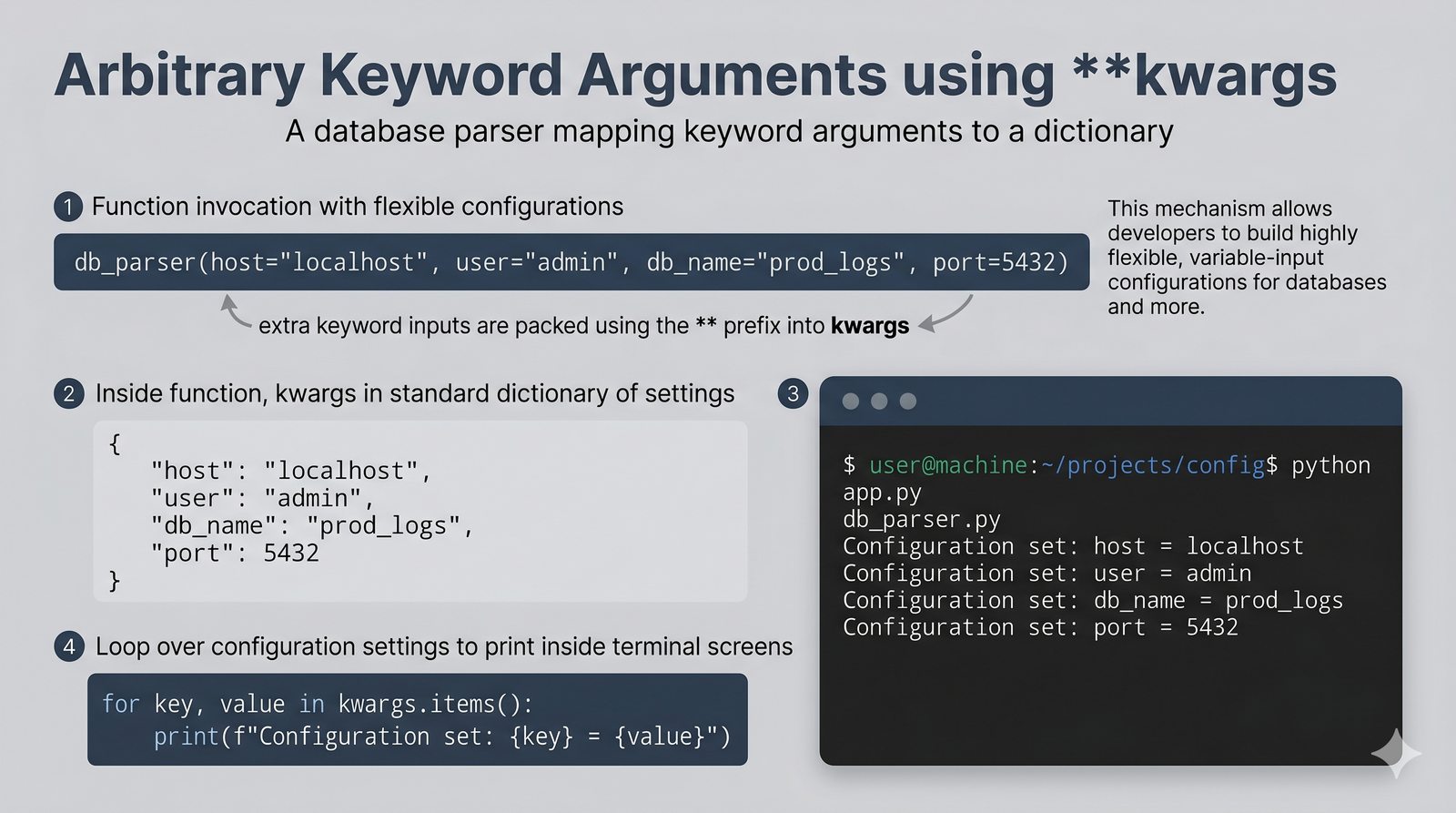
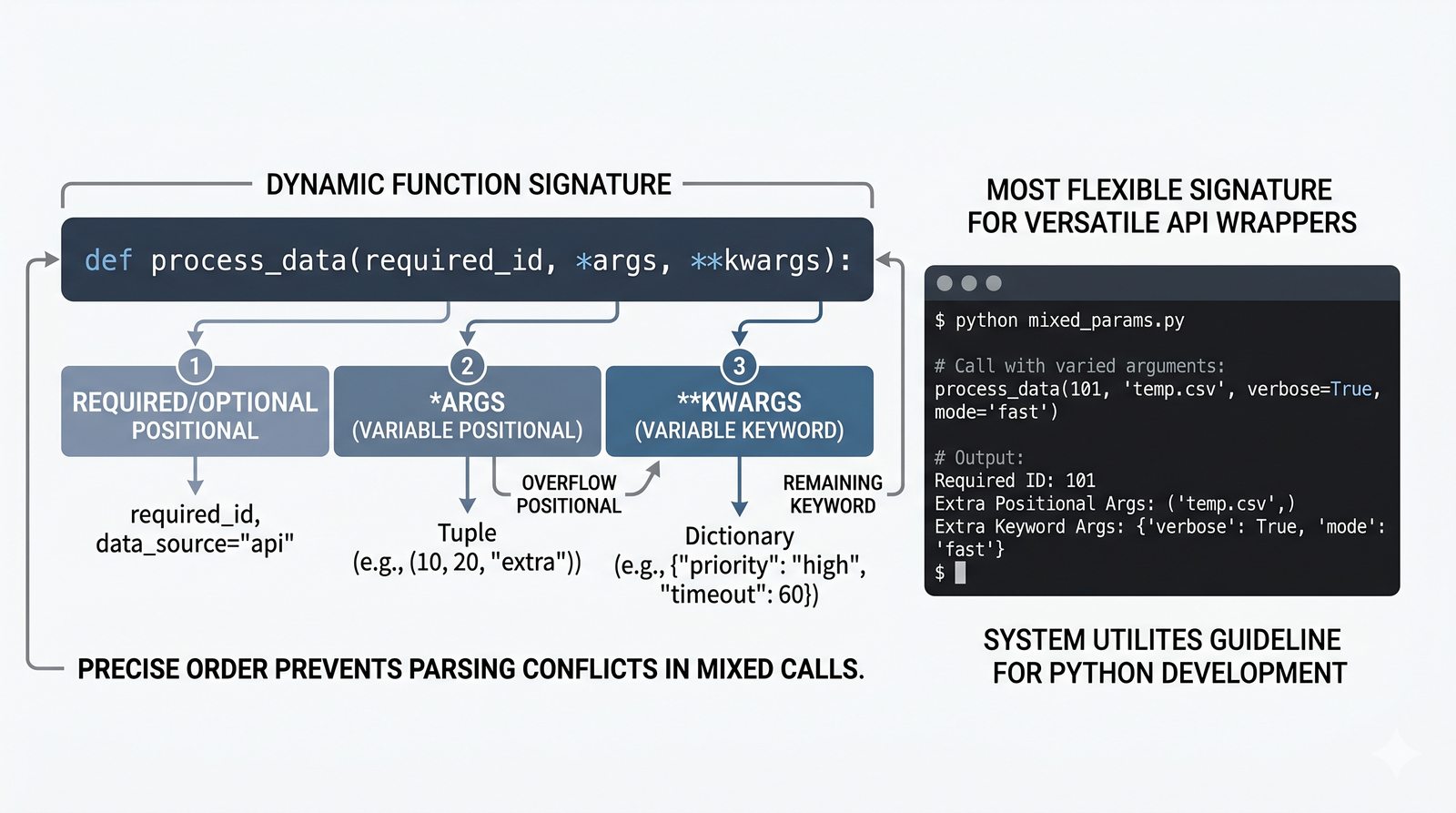
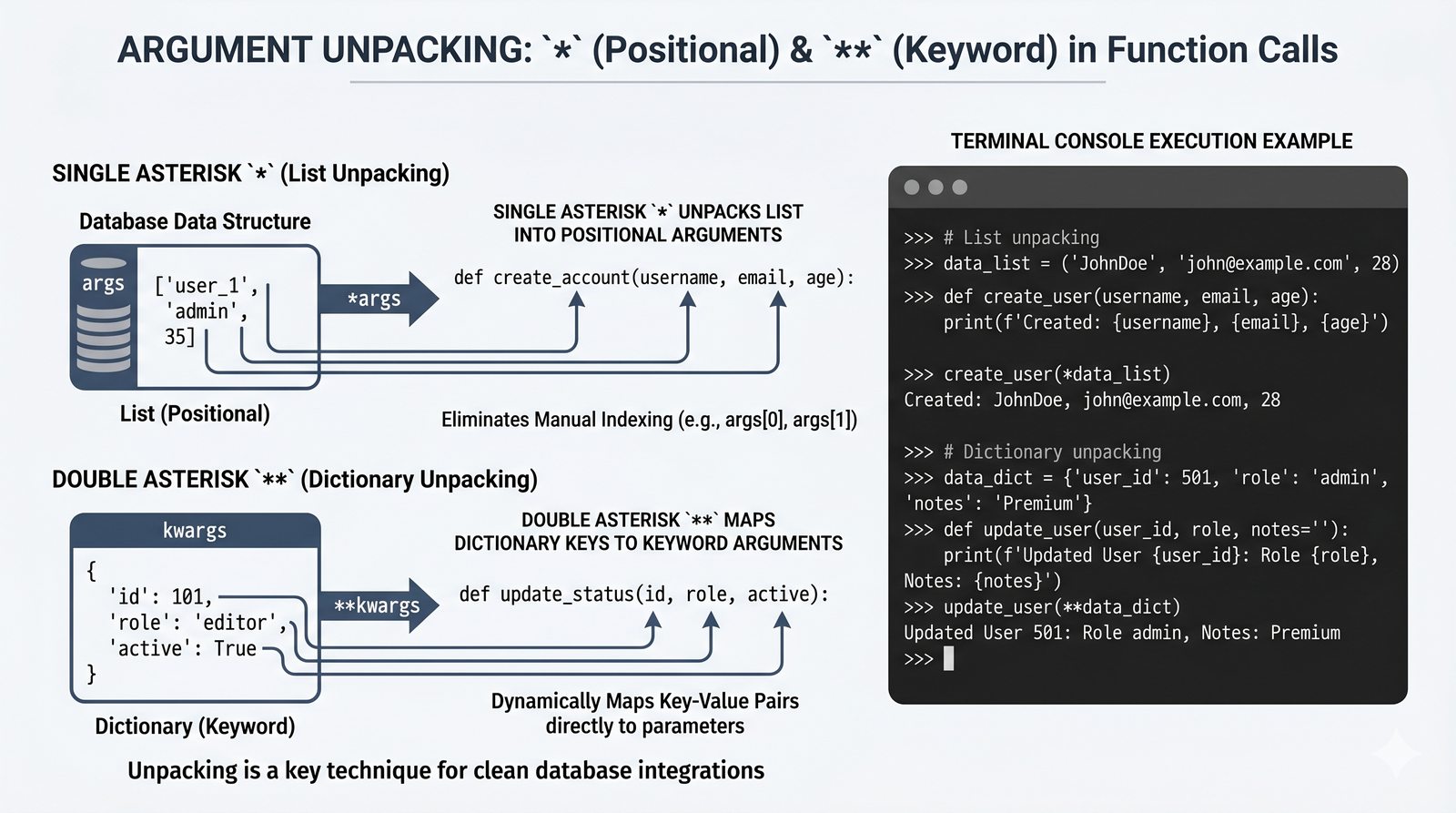
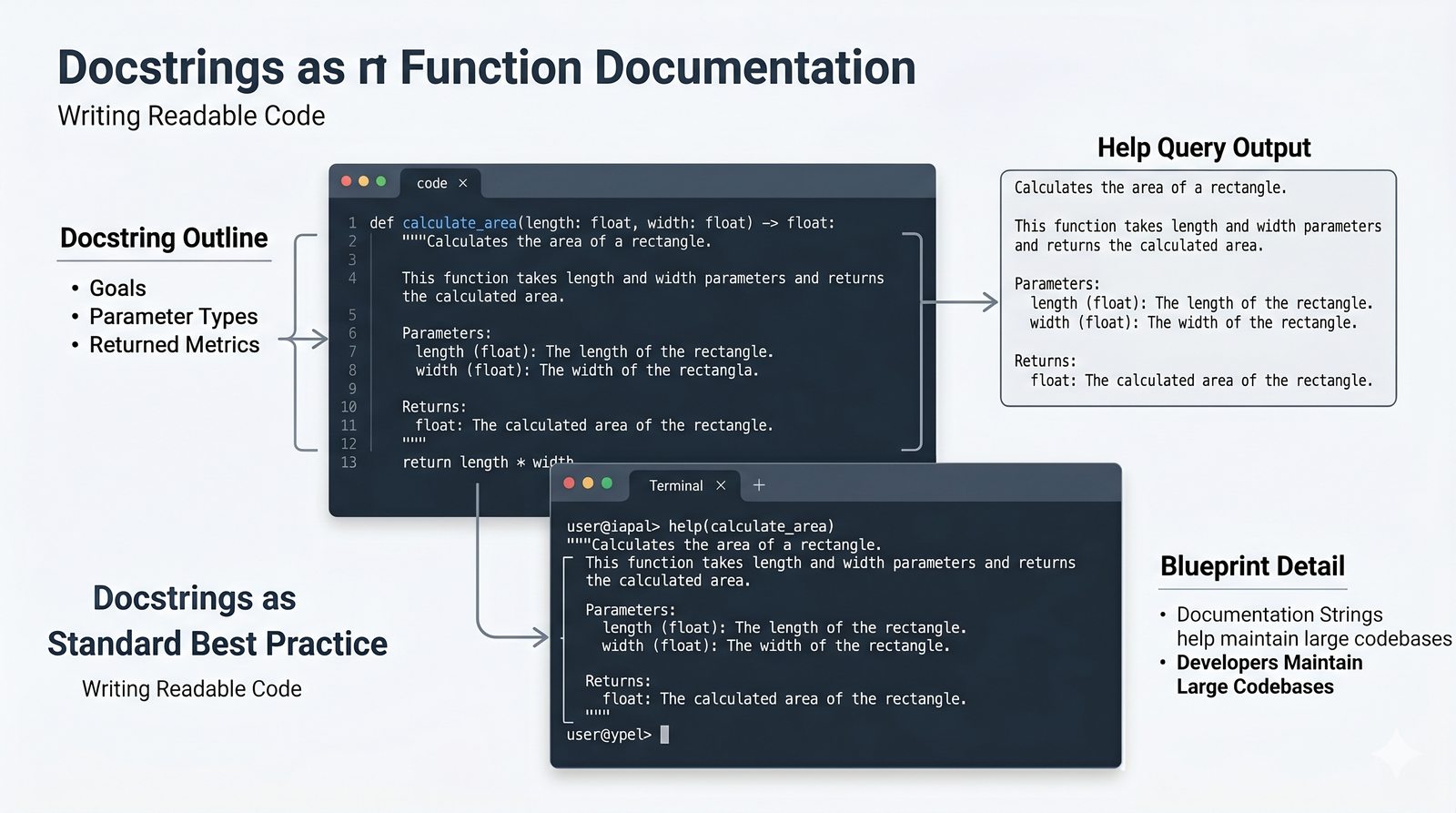
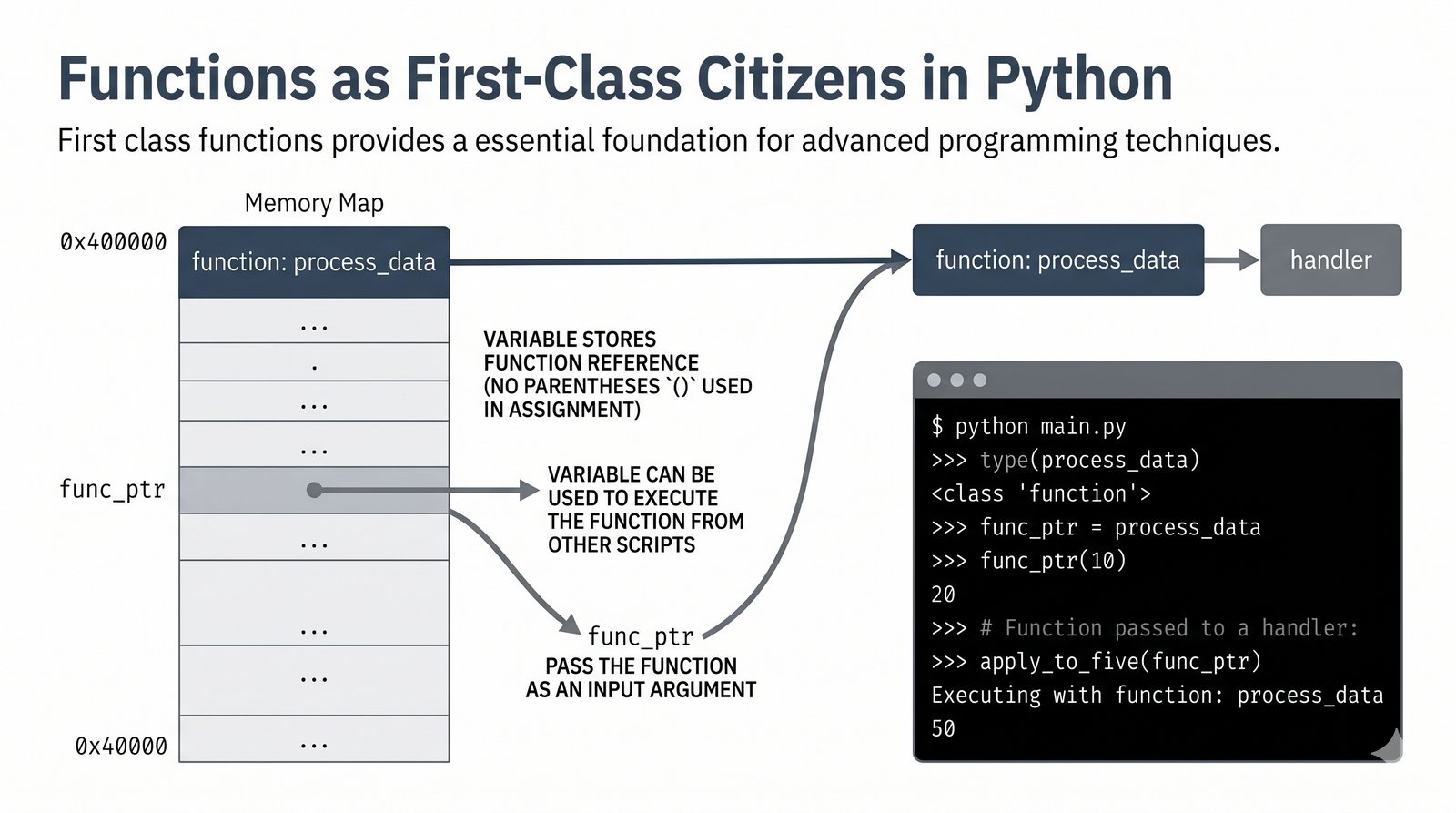
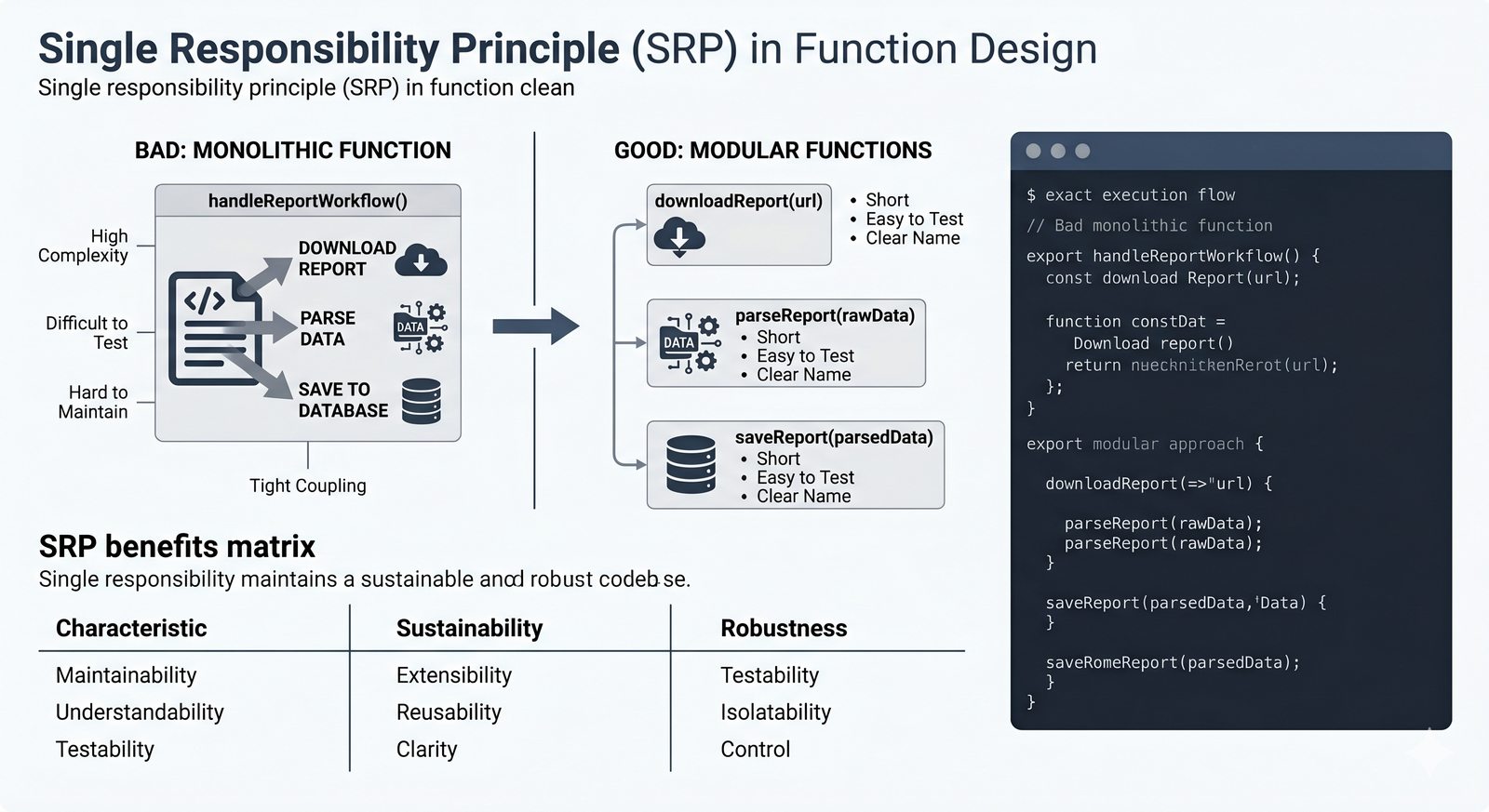
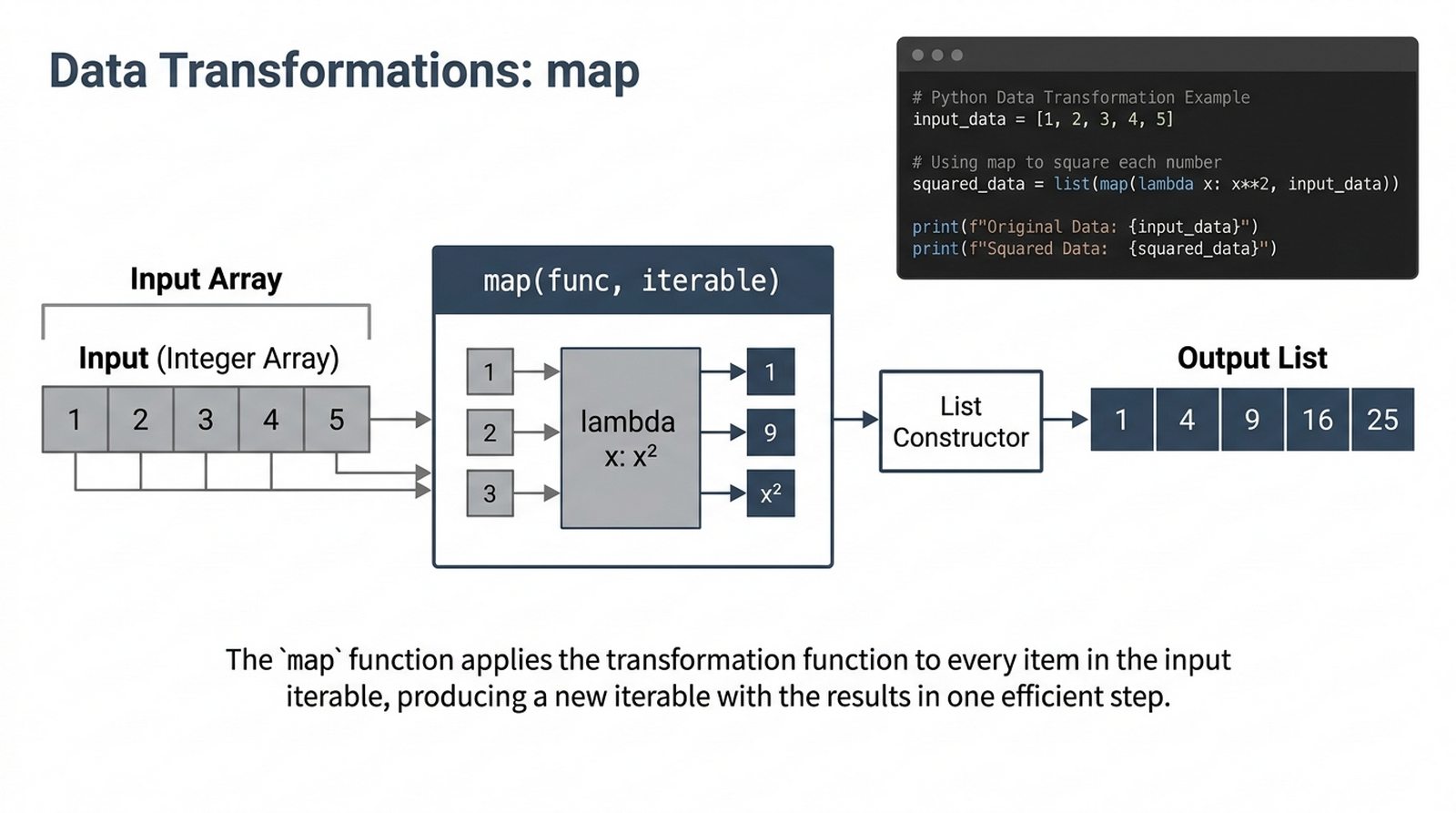
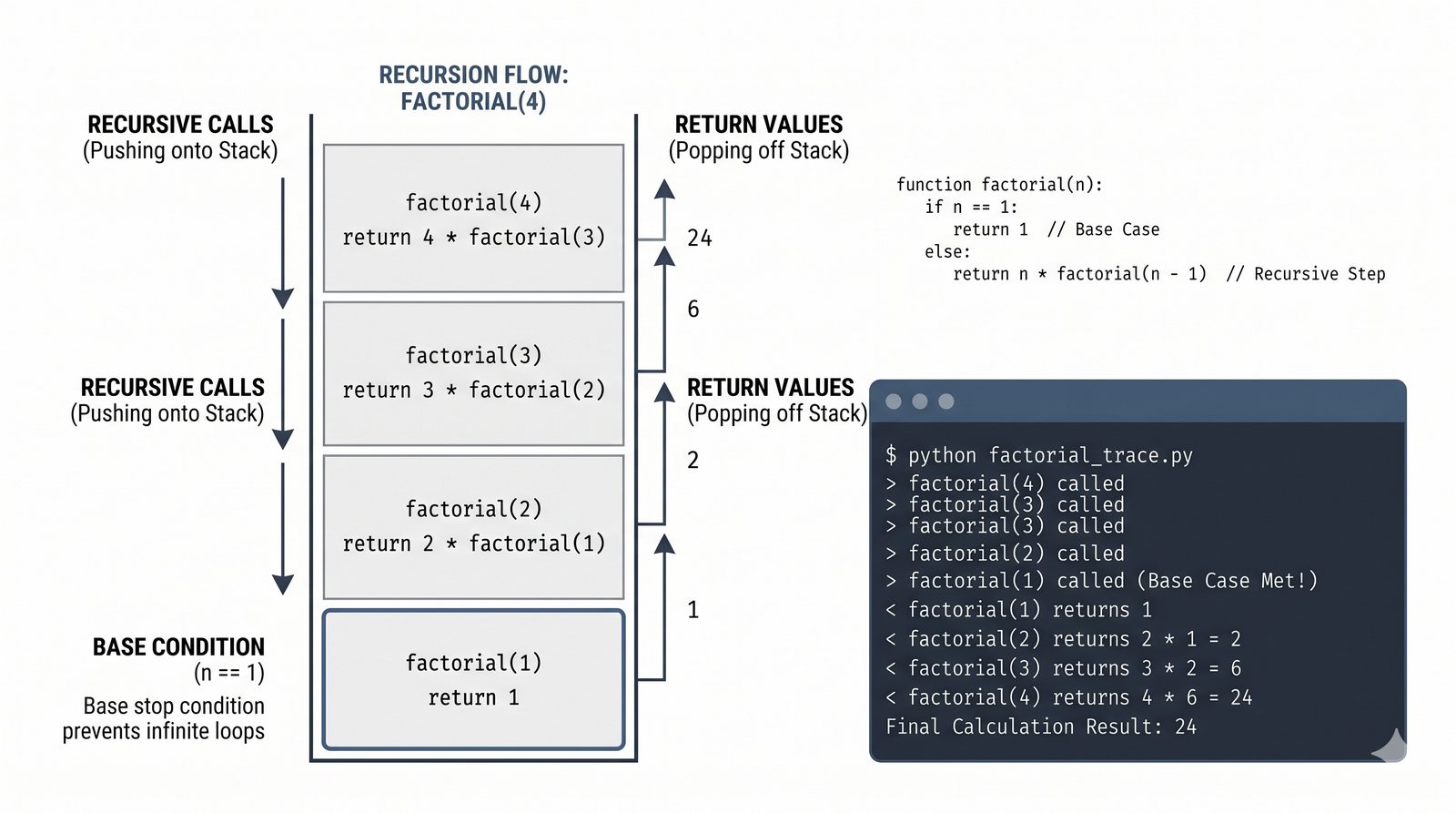
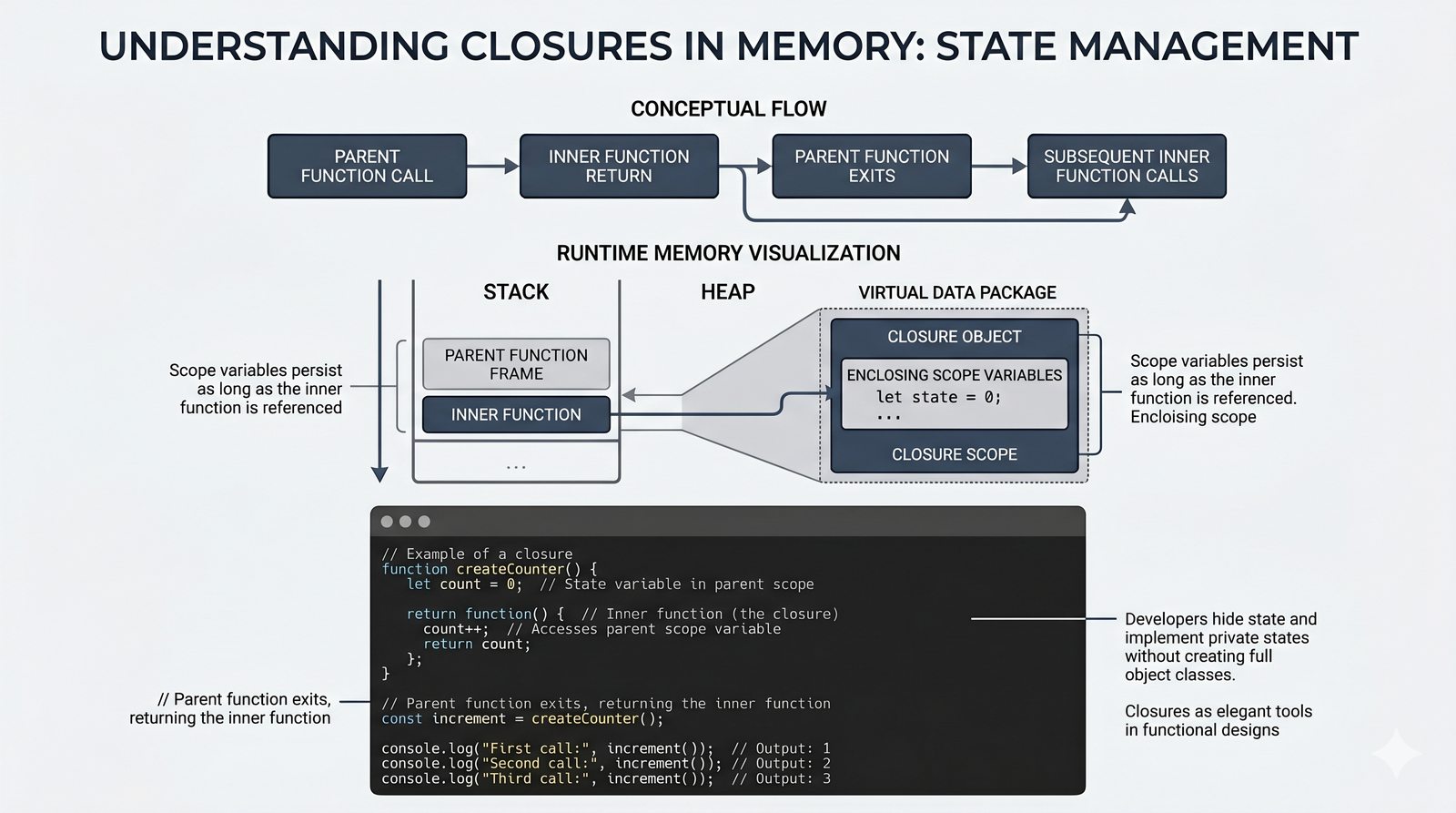
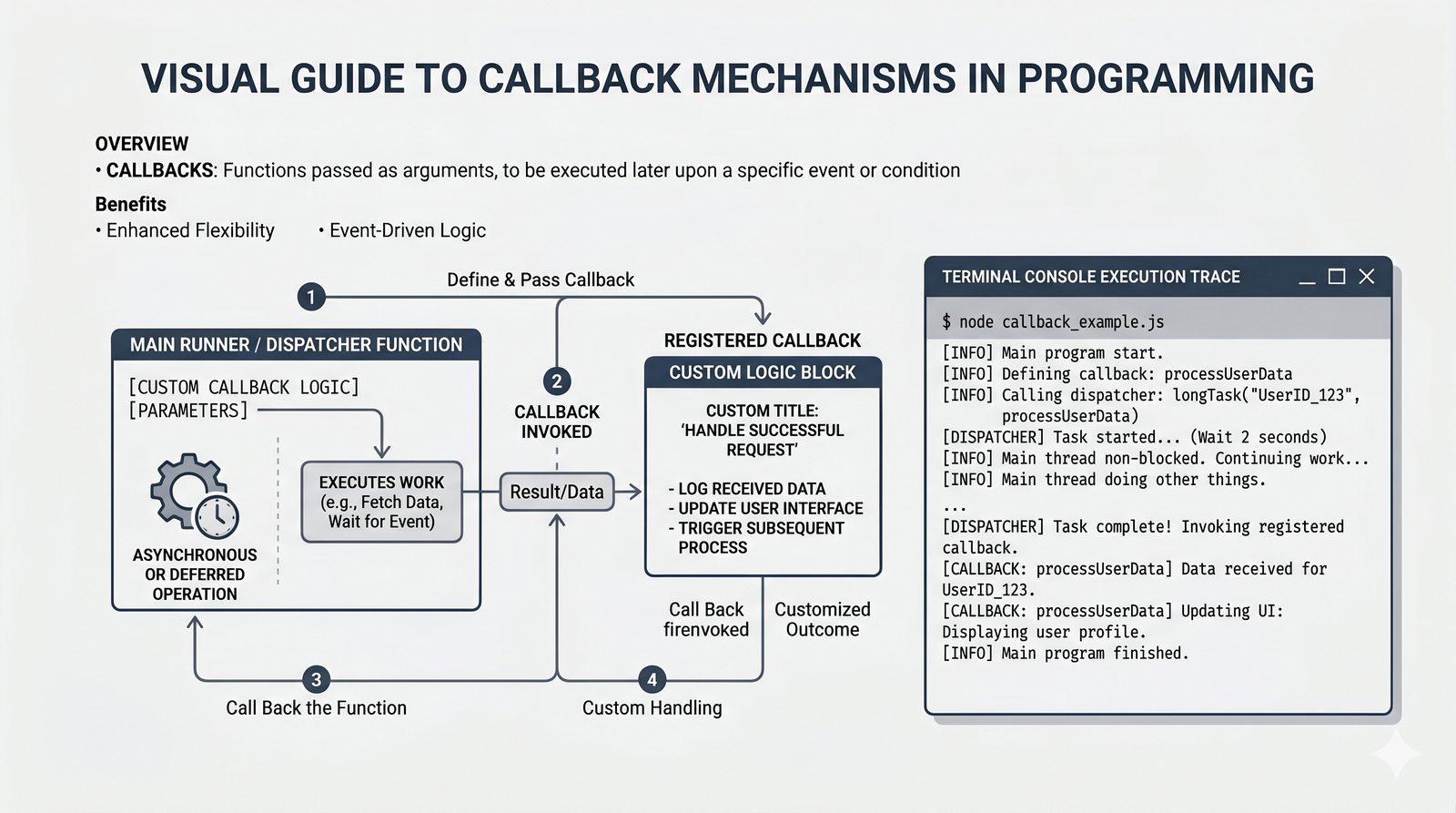
*argsi**kwargs, funkcje lambda, rekurencja, domknięcia (closures), funkcjemapifilter - Dobre praktyki i ćwiczenia -- zasada pojedynczej odpowiedzialności (SRP), czyste funkcje, docstringi, podpowiedzi typów oraz praktyczne programy do samodzielnej analizy