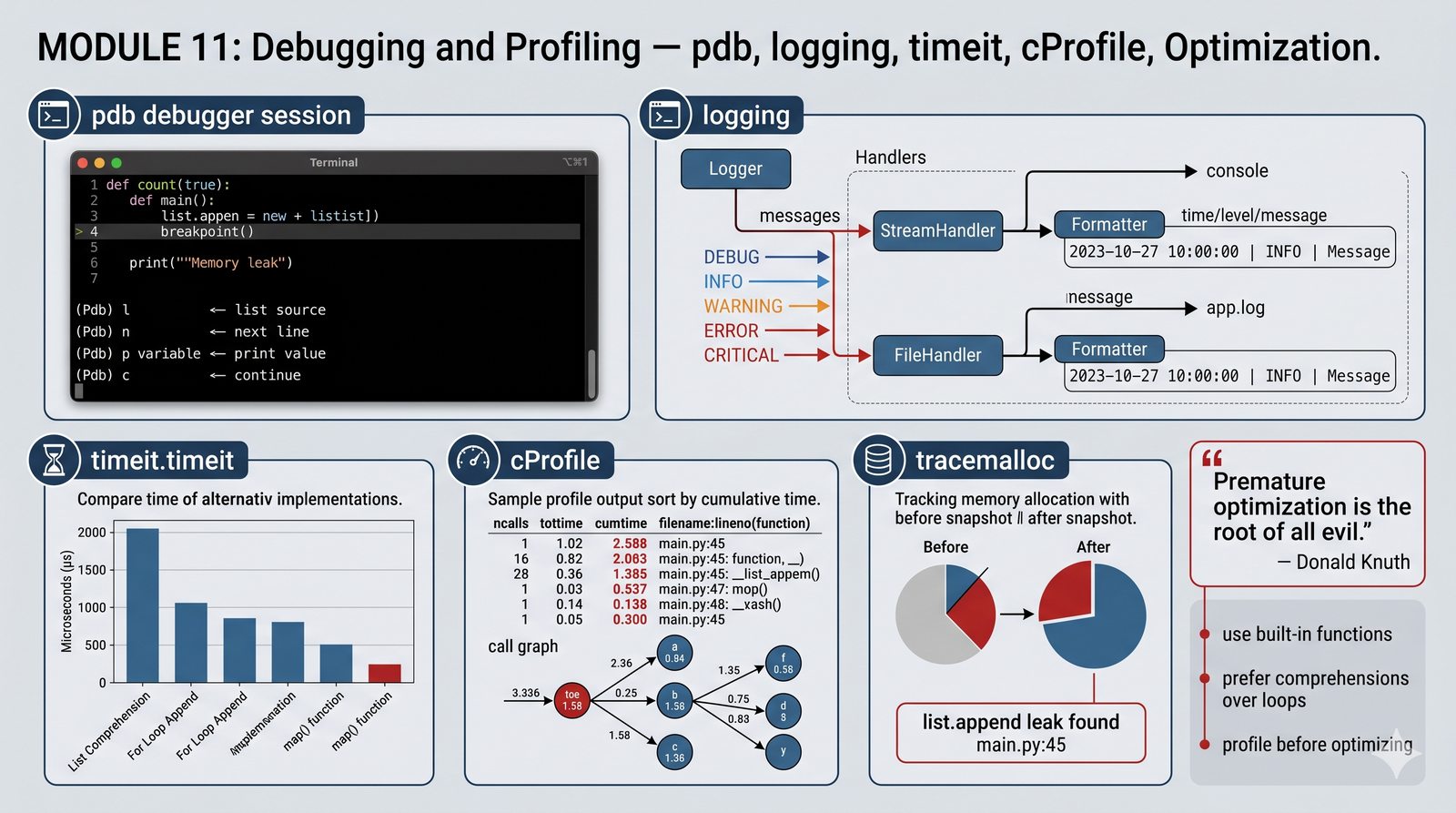
Moduł poświęcony jest debugowaniu i profilowaniu kodu w Pythonie — kluczowym umiejętnościom pozwalającym na identyfikację błędów, analizę wydajności i optymalizację aplikacji. Omówiono w nim debugger pdb z funkcją breakpoint() oraz podstawowe komendy debugera, a także system logowania z modułem logging wraz z konfiguracją loggerów, handlerów i formatterów. Materiał wyjaśnia precyzyjny pomiar czasu wykonania kodu za pomocą timeit oraz profilowanie aplikacji z użyciem cProfile i wizualizację profili wydajności. Przedstawiono również profilowanie pamięciowe z tracemalloc do wykrywania wycieków pamięci oraz strategie optymalizacji kodu z wykorzystaniem wbudowanych mechanizmów Pythona.
Kluczowe zagadnienia modułu:
- Debugowanie kodu z pdb i breakpoint — interaktywna analiza stanu programu i podstawowe komendy debugera
- System logowania (logging) — rejestrowanie zdarzeń z poziomami ważności oraz konfiguracja loggerów, handlerów i formatterów
- Pomiar czasu (timeit) i profilowanie (cProfile) — precyzyjny pomiar wydajności kodu i identyfikacja wąskich gardeł
- Profilowanie pamięciowe (tracemalloc) — monitorowanie alokacji pamięci RAM i wykrywanie wycieków
- Strategie optymalizacji — reguła Donalda Knutha, wbudowane mechanizmy Pythona i optymalizacja na bazie danych z profilera