Moduł ósmy stanowi kompleksowe omówienie technik pracy z plikami i katalogami w języku Python. Student poznaje nowoczesne podejście obiektowe z modułem pathlib, które zastępuje tradycyjne operacje na ścieżkach tekstowych, a także tradycyjny moduł os do niskopoziomowych operacji systemowych. Kolejne zagadnienia obejmują wysokopoziomowe operacje na plikach z modułem shutil, wyszukiwanie plików za pomocą glob, a także przetwarzanie popularnych formatów danych — CSV i JSON. Moduł porusza również kwestie bezpieczeństwa danych poprzez atomowy zapis z użyciem plików tymczasowych oraz efektywne przetwarzanie dużych plików metodą strumieniową. Całość wieńczy prezentacja typowych antywzorców i błędów, których unikać powinien każdy świadomy programista.
Kluczowe zagadnienia modułu:
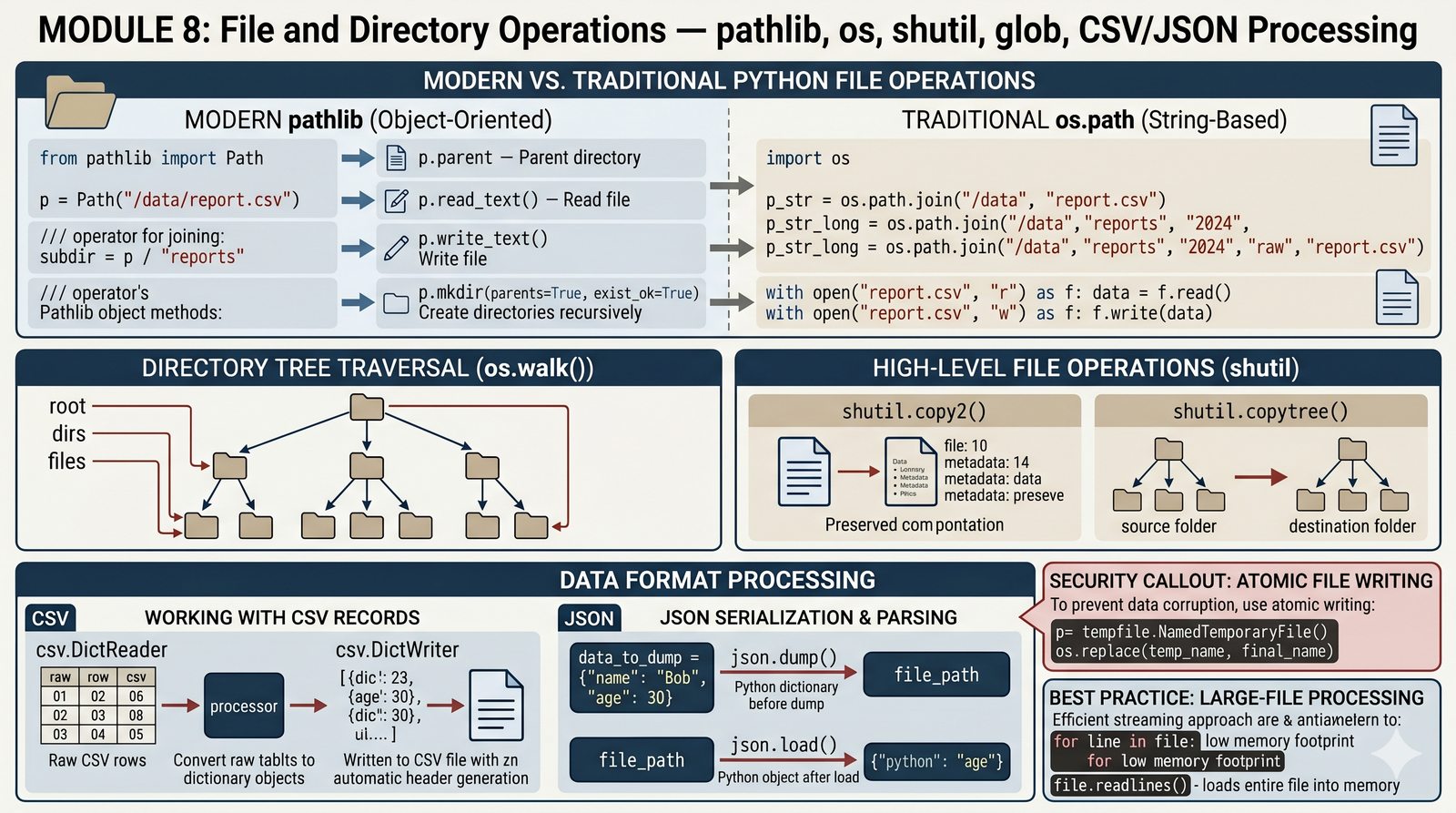
- pathlib.Path — obiektowe podejście do ścieżek: łączenie operatora
/, metodyread_text(),write_text(),glob(),rglob(), tworzenie katalogów zmkdir(parents=True, exist_ok=True). - os i shutil — operacje systemowe (
os.walk,os.stat, zmienne środowiskowe) oraz wysokopoziomowe funkcje plikowe (copy2,copytree,move,rmtree,make_archive). - CSV i JSON — bezpieczne parsowanie i zapis danych tabelarycznych za pomocą
csv.DictReader/csv.DictWriteroraz serializacja struktur Pythona do JSON przezjson.load()/json.dump(). - Bezpieczny zapis — atomowe zapisywanie plików z wykorzystaniem modułu
tempfilei funkcjios.replace(), co chroni przed utratą danych w przypadku awarii. - Duże pliki — strumieniowe czytanie linia po linii lub porcjami (chunks) zamiast
readlines(), co zapobiega przepełnieniu pamięci RAM przy plikach gigabajtowych.