Moduł poświęcony jest wyrażeniom regularnym (Regex) -- potężnemu minijęzykowi służącemu do wyszukiwania, walidacji i manipulacji tekstami za pomocą precyzyjnie zdefiniowanych wzorców znakowych. Uczestnik kursu pozna podstawowe funkcje modułu re, takie jak re.search(), re.match(), re.findall(), re.finditer(), re.sub() oraz re.split(), a także nauczy się kompilować wzorce za pomocą re.compile() w celu optymalizacji wydajności. Omówione zostaną metaznaki i klasy znaków (np. \d, \w, \s), kwantyfikatory zachłanne i leniwe, grupy przechwytujące oraz grupy nazwane, które pozwalają na wyodrębnianie konkretnych fragmentów dopasowań. Moduł kładzie również nacisk na typowe błędy i antywzorce, takie jak katastrofa wydajnościowa spowodowana nieprawidłowym użyciem kwantyfikatorów czy ponowna kompilacja wzorców w pętli. Całość uzupełniona jest przykładami kodu zgodnego ze standardem PEP 8 oraz wskazówkami dotyczącymi czystego i wydajnego programowania.
Kluczowe zagadnienia modułu:
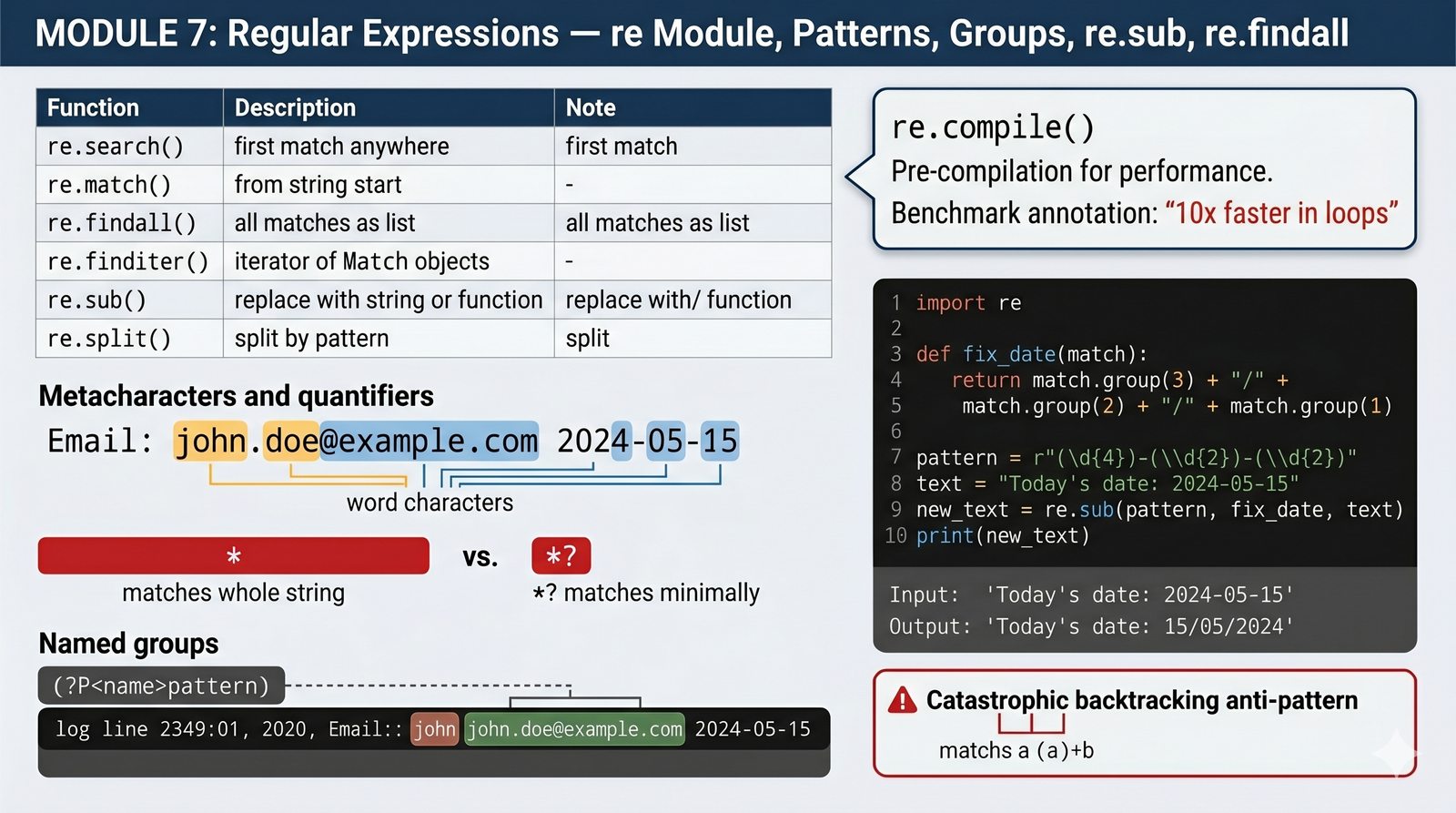
- Funkcje modułu re:
re.search()szuka wzorca w całym tekście,re.match()sprawdza wyłącznie początek tekstu,re.findall()zwraca listę wszystkich dopasowań, are.finditer()zwraca wydajny iterator obiektów Match. - Kompilacja wzorców: Funkcja
re.compile()pozwala na wstępne skompilowanie wzorca, co znacząco zwiększa wydajność aplikacji przy wielokrotnym użyciu tego samego wzorca, na przykład w pętlach przetwarzających duże ilości danych. - Metaznaki, klasy znaków i kwantyfikatory: Regex udostępnia znaki specjalne takie jak \d (cyfra), \w (litera/cyfra), \s (biały znak) oraz kropkę (dowolny znak). Kwantyfikatory (+, *, ?) są domyślnie zachłanne, ale dodanie zapytania (np. +?) przełącza je w tryb leniwy, dopasowując minimum znaków.
- Grupy przechwytujące i nazwane: Nawiasy okrągłe () tworzą grupy przechwytujące umożliwiające wyodrębnienie konkretnych fragmentów dopasowania. Python pozwala również na nadawanie nazw grupom za pomocą składni
(?P<nazwa>...), co poprawia czytelność kodu. - Modyfikacja i podział tekstu: Funkcja
re.sub()umożliwia zaawansowaną zamianę fragmentów tekstu (również z użyciem funkcji jako zamiennika), are.split()dzieli tekst według wzorca Regex. Flagi takie jakre.IGNORECASEire.MULTILINEpozwalają na globalną konfigurację zachowania silnika dopasowań.