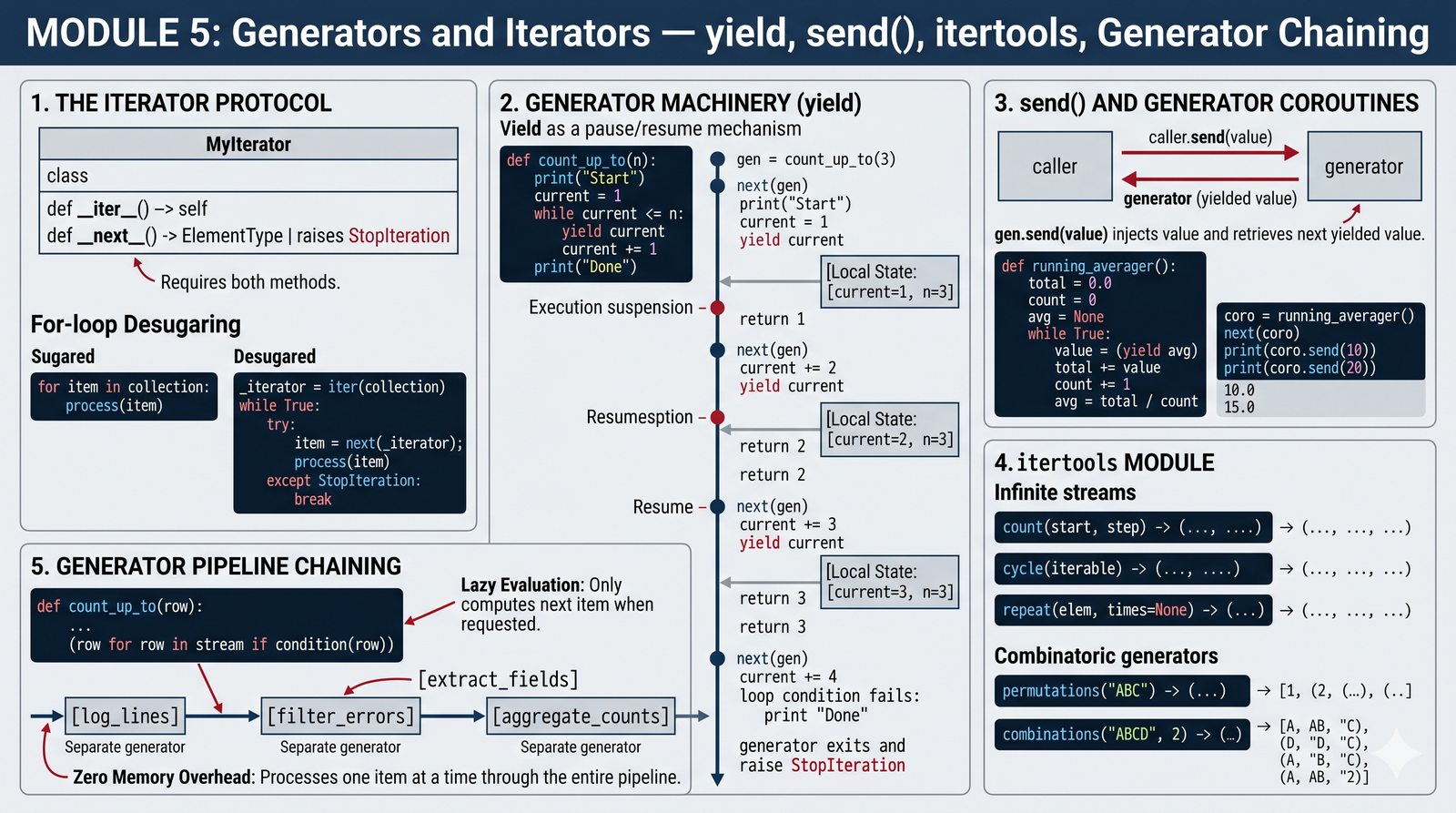
Moduł piąty omawia zaawansowane mechanizmy generatorów i iteratorów w języku Python, które są kluczowe dla pisania wydajnego i pamięciooszczędnego kodu. Uczestnik poznaje protokół iteratora oparty na metodach magicznych __iter__() i __next__(), słowo kluczowe yield tworzące generatory oraz dwukierunkową komunikację za pomocą metody send(). Dokument omawia również delegowanie generatorów poprzez yield from, metody throw() i close(), a także bogaty zestaw narzędzi z modułu itertools, w tym iteratory nieskończone i funkcje kombinatoryczne. Na koniec przedstawiono projektowanie potoków przetwarzania, które umożliwiają modularne przetwarzanie strumieni danych przy zerowym narzucie pamięciowym. Całość uzupełniona jest przykładami praktycznymi, typowymi błędami oraz dobrymi praktykami zgodnymi ze standardem PEP 8.
Kluczowe zagadnienia modułu:
- Protokół iteratora: implementacja metod
__iter__()i__next__()oraz tworzenie własnych iteratorów. - Generatory: słowo kluczowe
yield, stany i cykl życia generatora, komunikacja przezsend(). - Zarządzanie generatorem: metody
throw()iclose()oraz delegowanie przezyield from. - Moduł
itertools: nieskończone iteratory (count(),cycle(),repeat()) oraz kombinatoryka (permutations(),combinations(),groupby()). - Potoki przetwarzania: łączenie generatorów w wydajne łańcuchy przetwarzania strumieniowego.