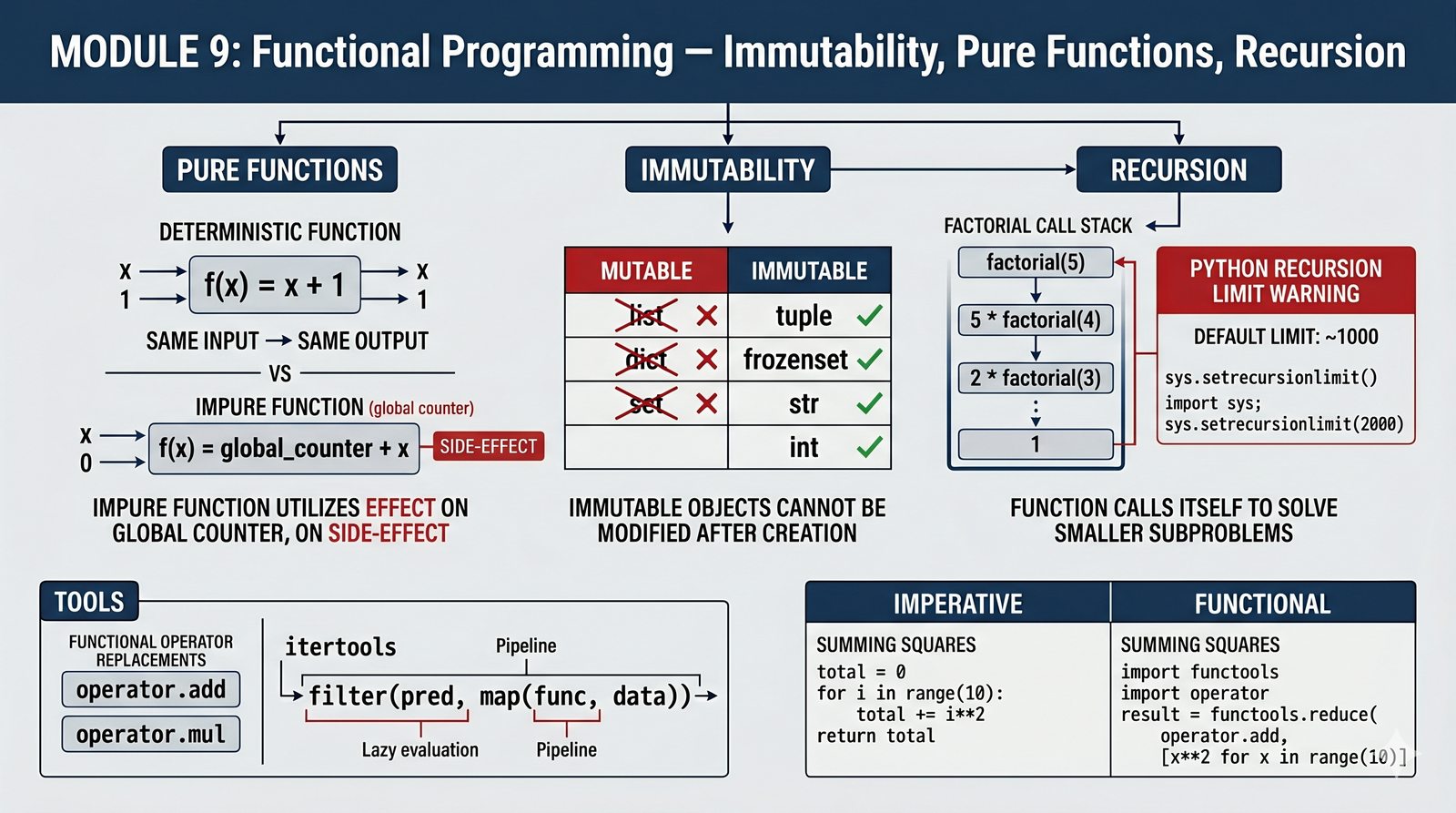
Moduł wprowadza paradygmat programowania funkcyjnego (FP) w Pythonie — podejście oparte na ewaluacji funkcji matematycznych, które unika modyfikacji stanu i mutowalnych struktur danych. Omówiono w nim czyste funkcje (pure functions), które są deterministyczne i pozbawione skutków ubocznych, a także niemutowalność danych realizowaną przez krotki, frozenset i typy proste. Materiał wyjaśnia funkcje jako obiekty pierwszej klasy, rekurencję z przypadkiem bazowym oraz limit rekurencji i możliwości jego optymalizacji. Przedstawiono również moduł operator jako funkcyjny zamiennik standardowych operatorów, biblioteki funkcyjne takie jak itertools, leniwą ewaluację z generatorami oraz projektowanie funkcyjnych potoków danych łączących czyste funkcje w wydajne łańcuchy transformacji.
Kluczowe zagadnienia modułu:
- Paradygmat programowania funkcyjnego — unikanie stanu i mutowalnych struktur danych w Pythonie
- Czyste funkcje i niemutowalność — deterministyczne wyniki i brak skutków ubocznych
- Funkcje jako obiekty pierwszej klasy oraz rekurencja — przekazywanie funkcji, przypadek bazowy i limit stosu
- Moduł operator i biblioteki funkcyjne — operator.add, operator.mul, itertools i leniwe przetwarzanie
- Funkcyjne potoki danych — łączenie czystych funkcji w łańcuchy transformacji (pipelines)