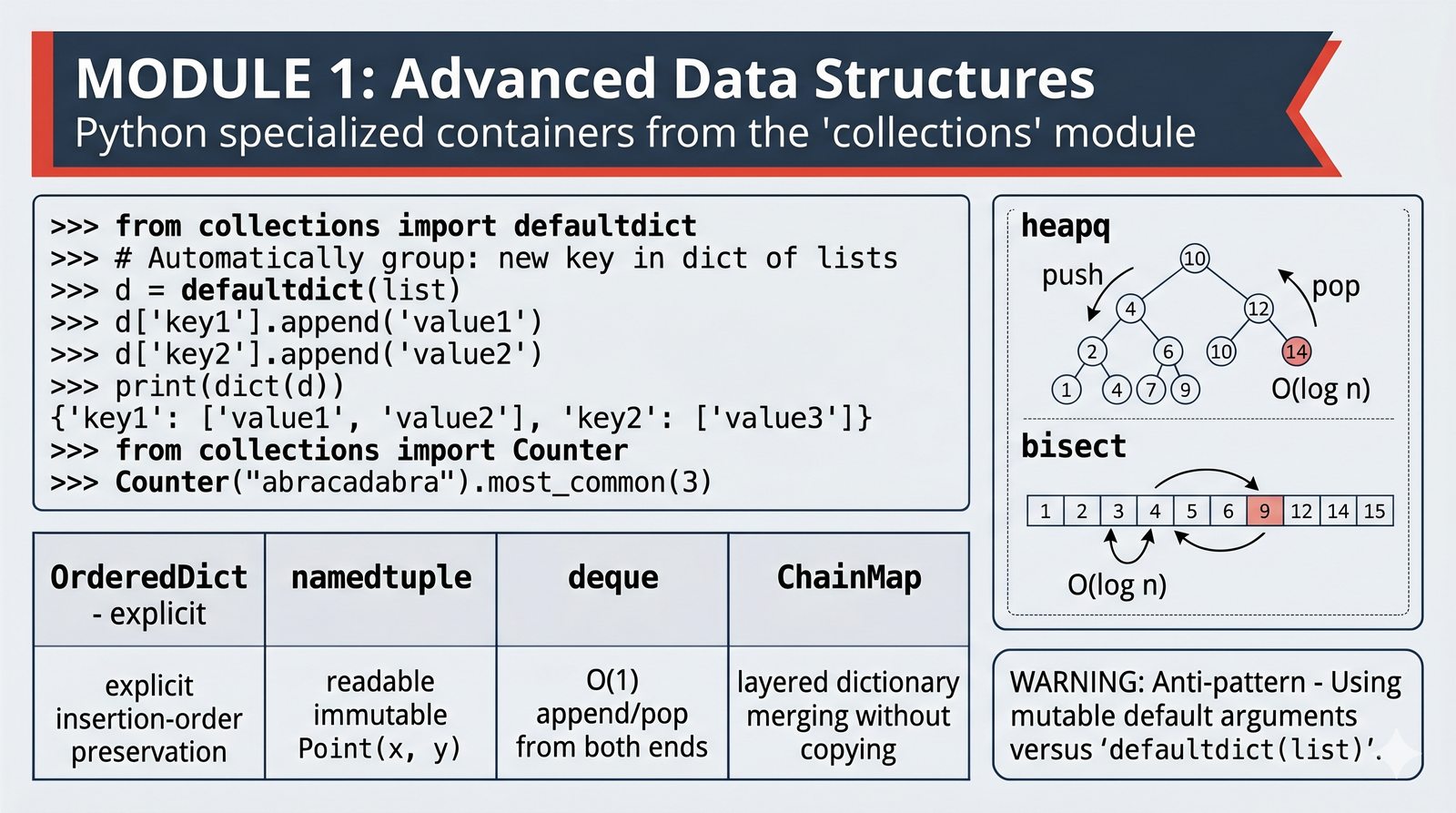
Moduł stanowi kompleksowe wprowadzenie do zaawansowanych struktur danych i algorytmów w standardowej bibliotece Pythona. Obejmuje specjalistyczne kontenery z modułu collections — defaultdict, Counter, OrderedDict, namedtuple, deque, ChainMap — oraz bezpieczne wrappery UserDict, UserList i UserString do rozszerzania typów wbudowanych. Przedstawia również moduły heapq i bisect do wydajnego zarządzania kolejkami priorytetowymi oraz wyszukiwania binarnego w posortowanych danych. Materiał kładzie nacisk na praktyczne zastosowania, typowe pułapki i antywzorce, a także dobre praktyki programistyczne zgodne ze standardem PEP 8.
Kluczowe zagadnienia modułu:
- defaultdict i Counter — automatyzacja grupowania i zliczania danych bez instrukcji warunkowych
- OrderedDict i namedtuple — zachowanie kolejności wstawiania oraz czytelne, niemutowalne struktury danych
- deque i ChainMap — wydajne kolejki dwukierunkowe oraz warstwowe łączenie słowników bez kopiowania
- UserDict, UserList, UserString — bezpieczne dziedziczenie po typach wbudowanych z własną logiką biznesową
- heapq i bisect — kopce binarne dla kolejek priorytetowych oraz wyszukiwanie binarne w posortowanych listach