Metody magiczne w Pythonie
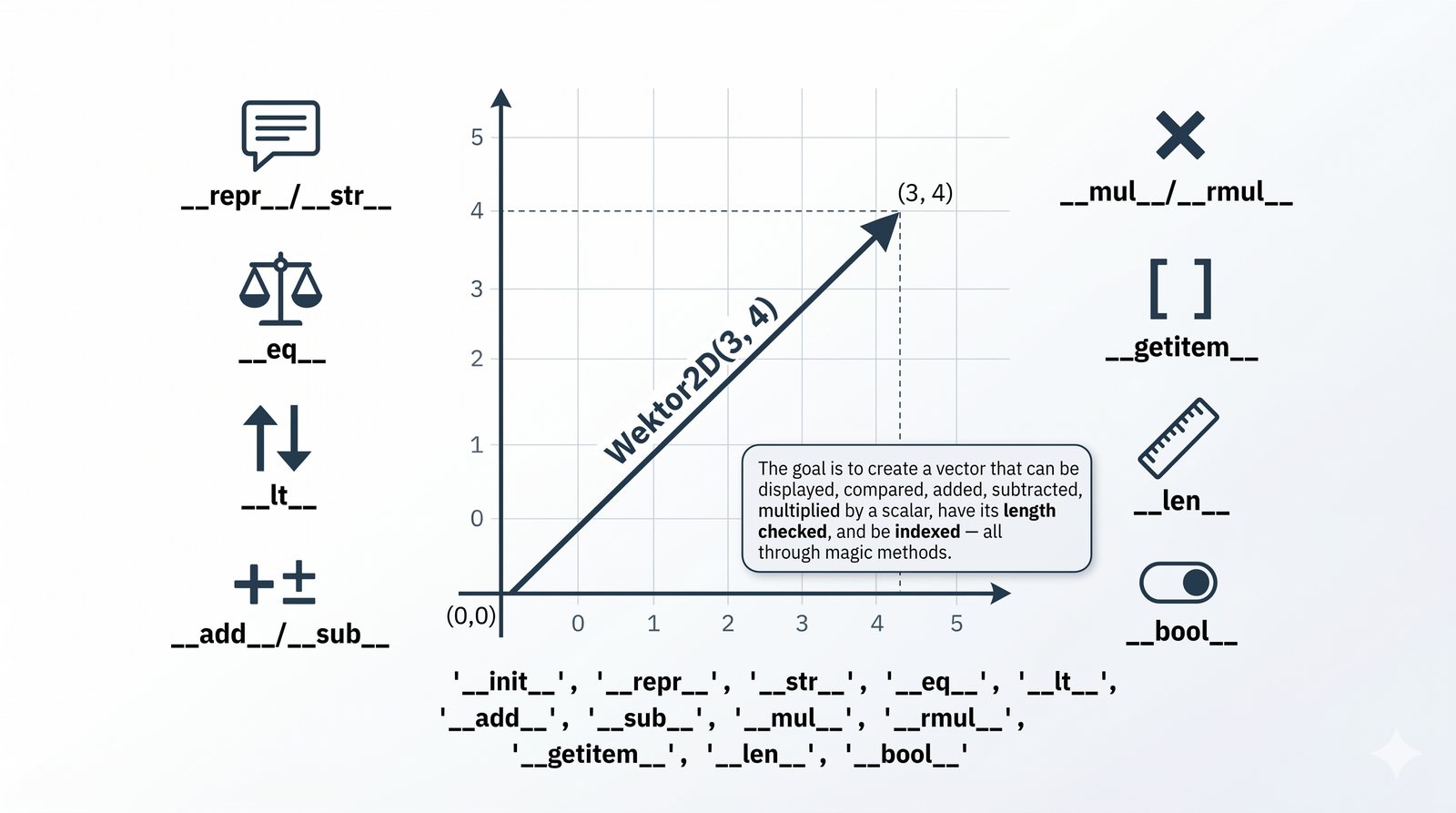
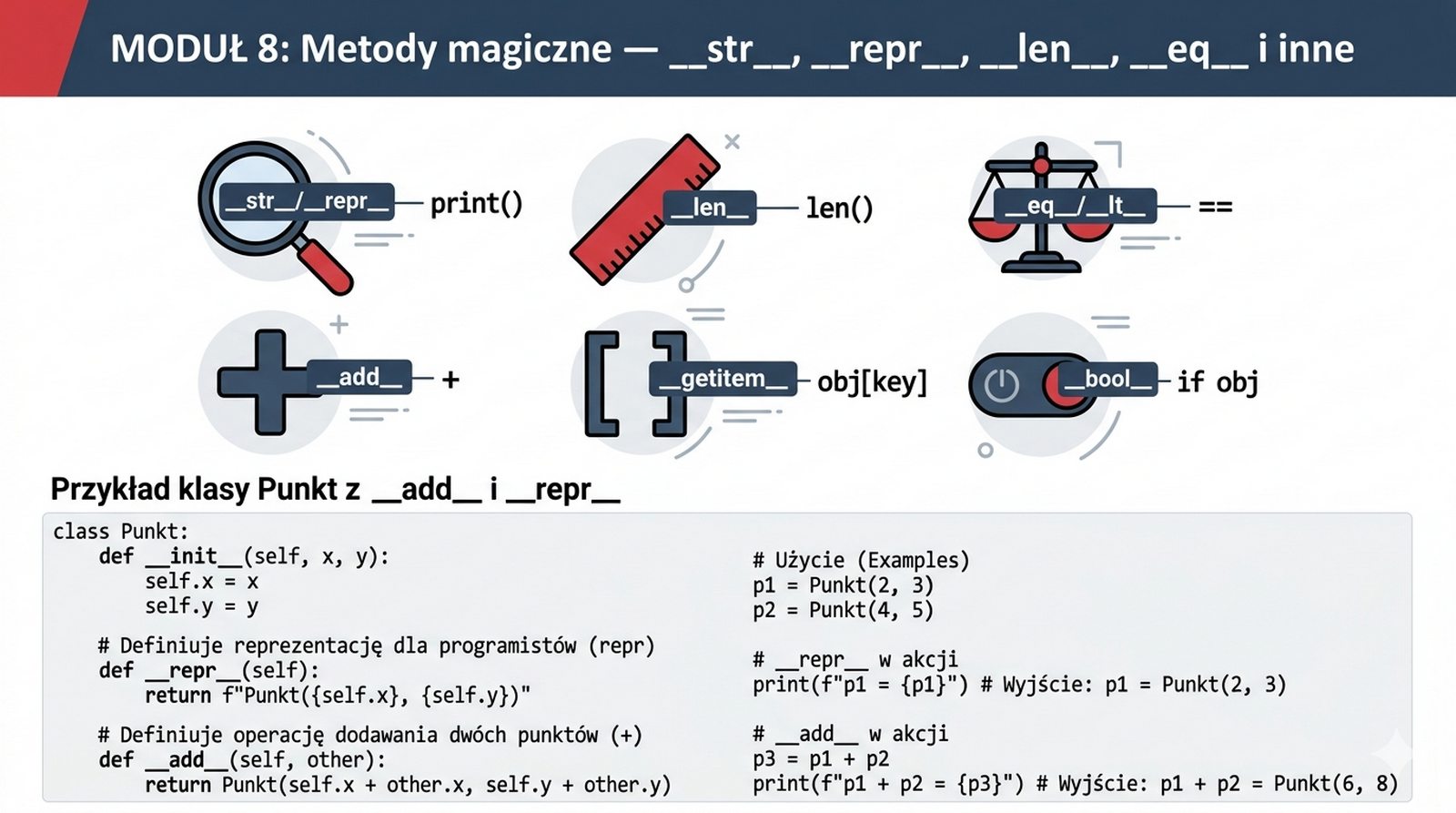
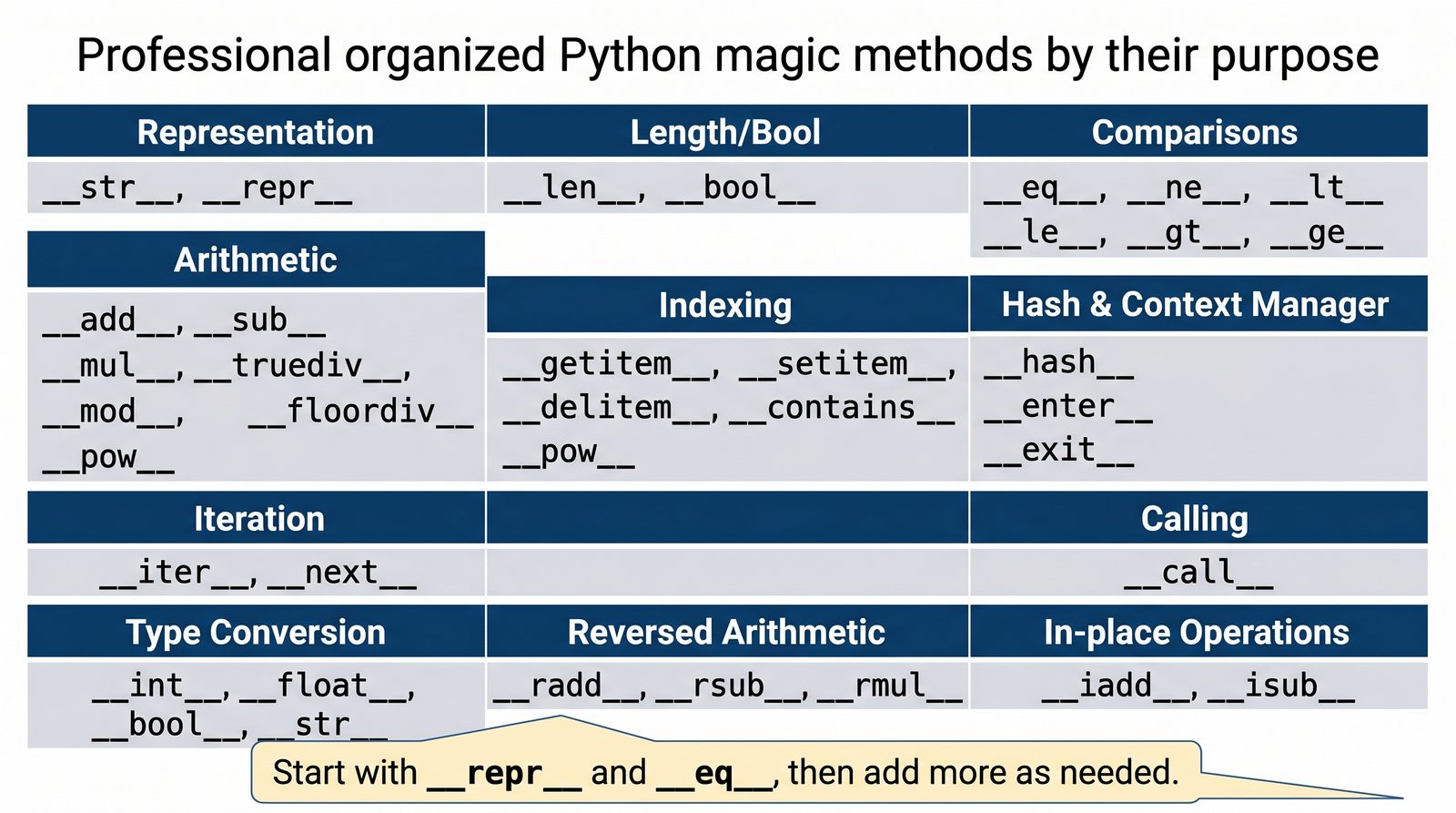
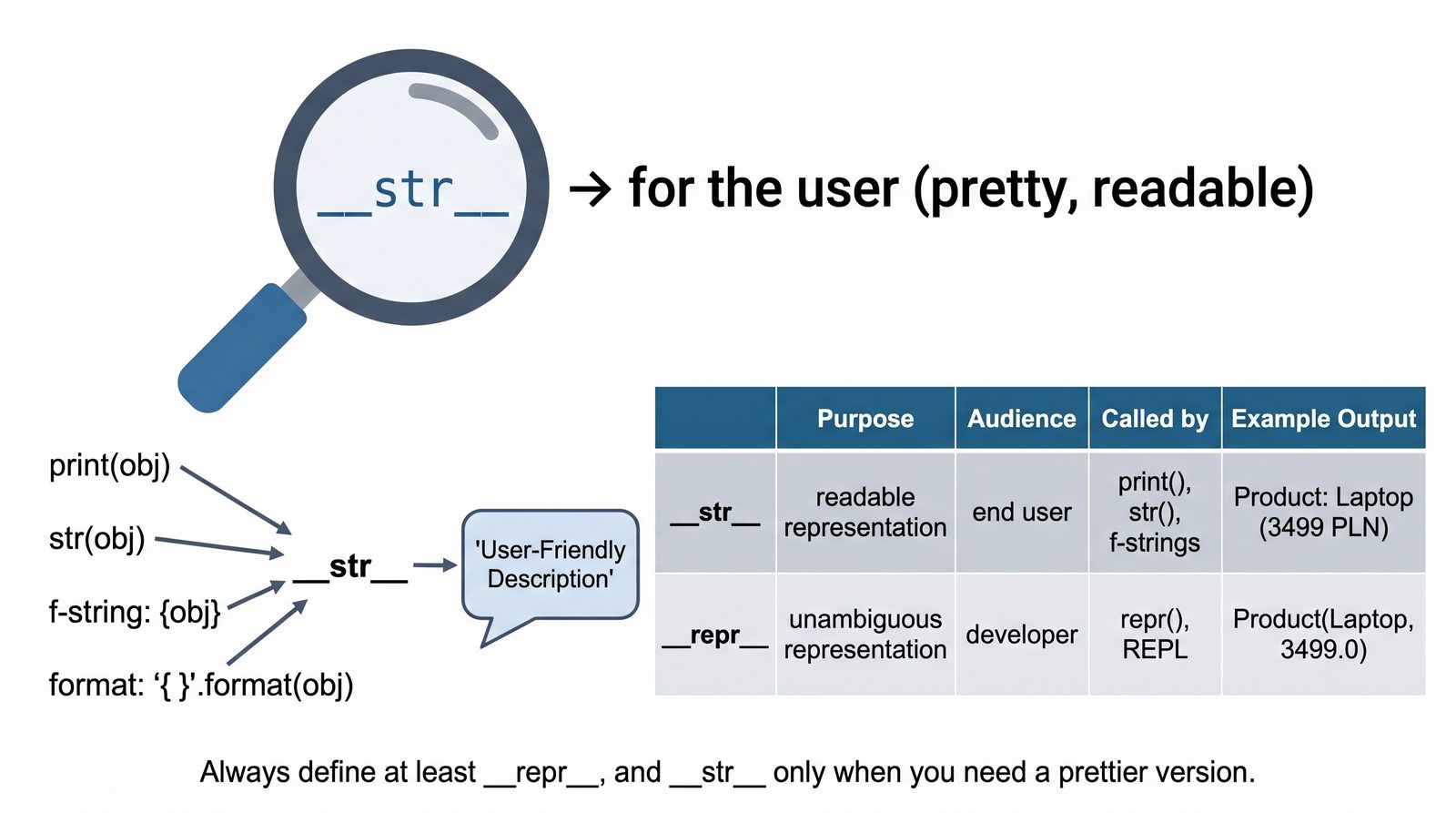
__str__
,
__repr__
,
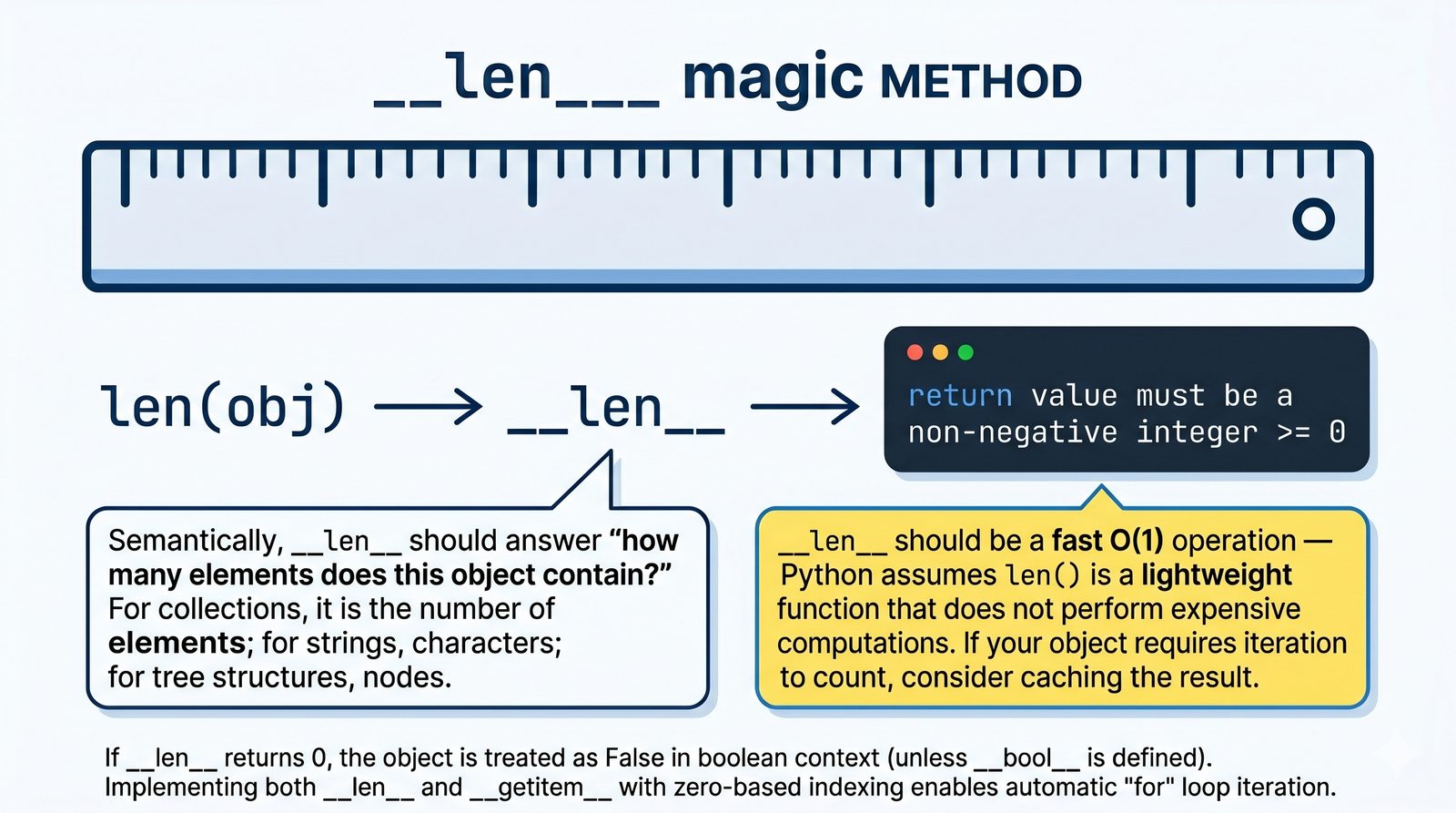
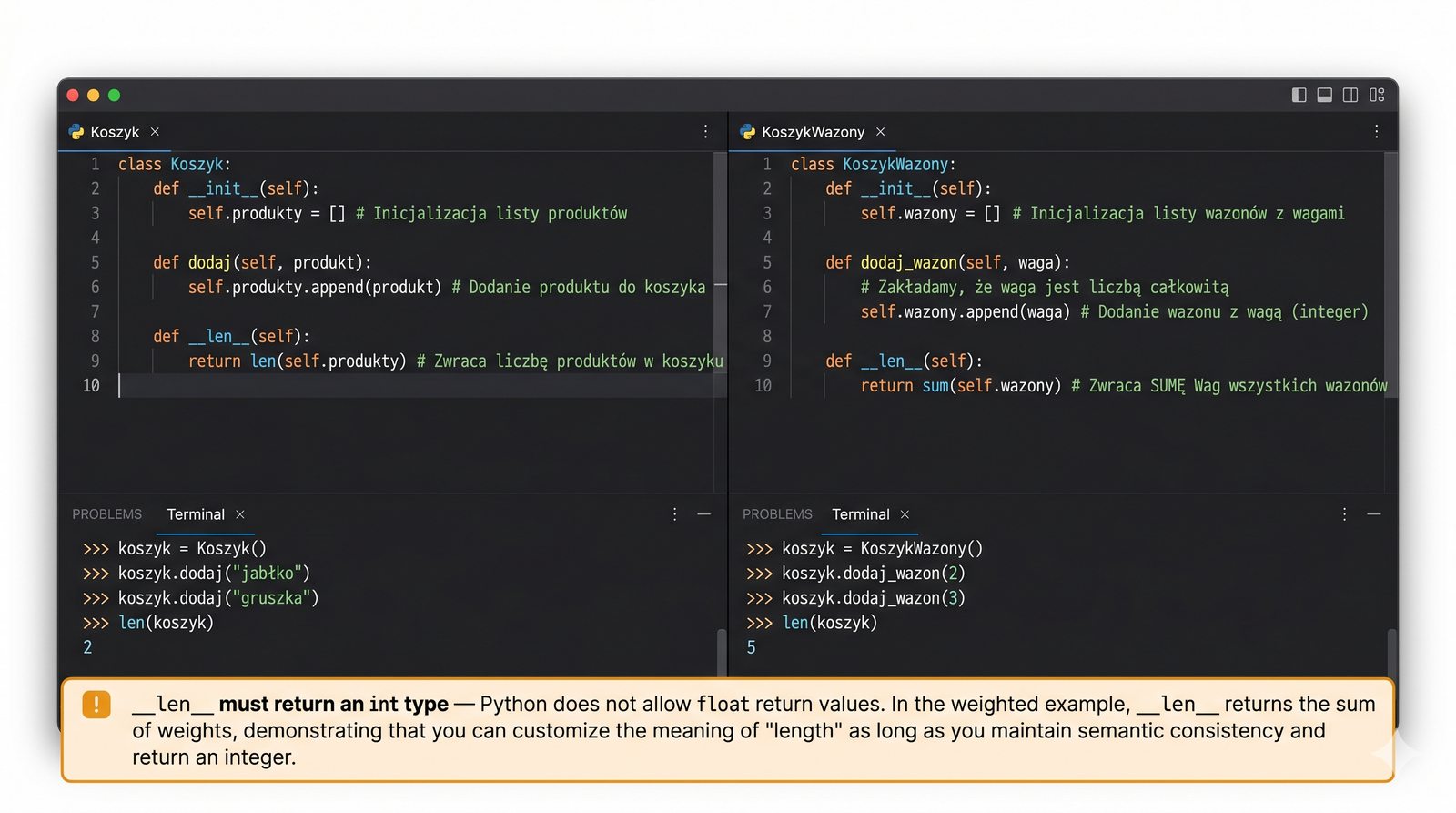
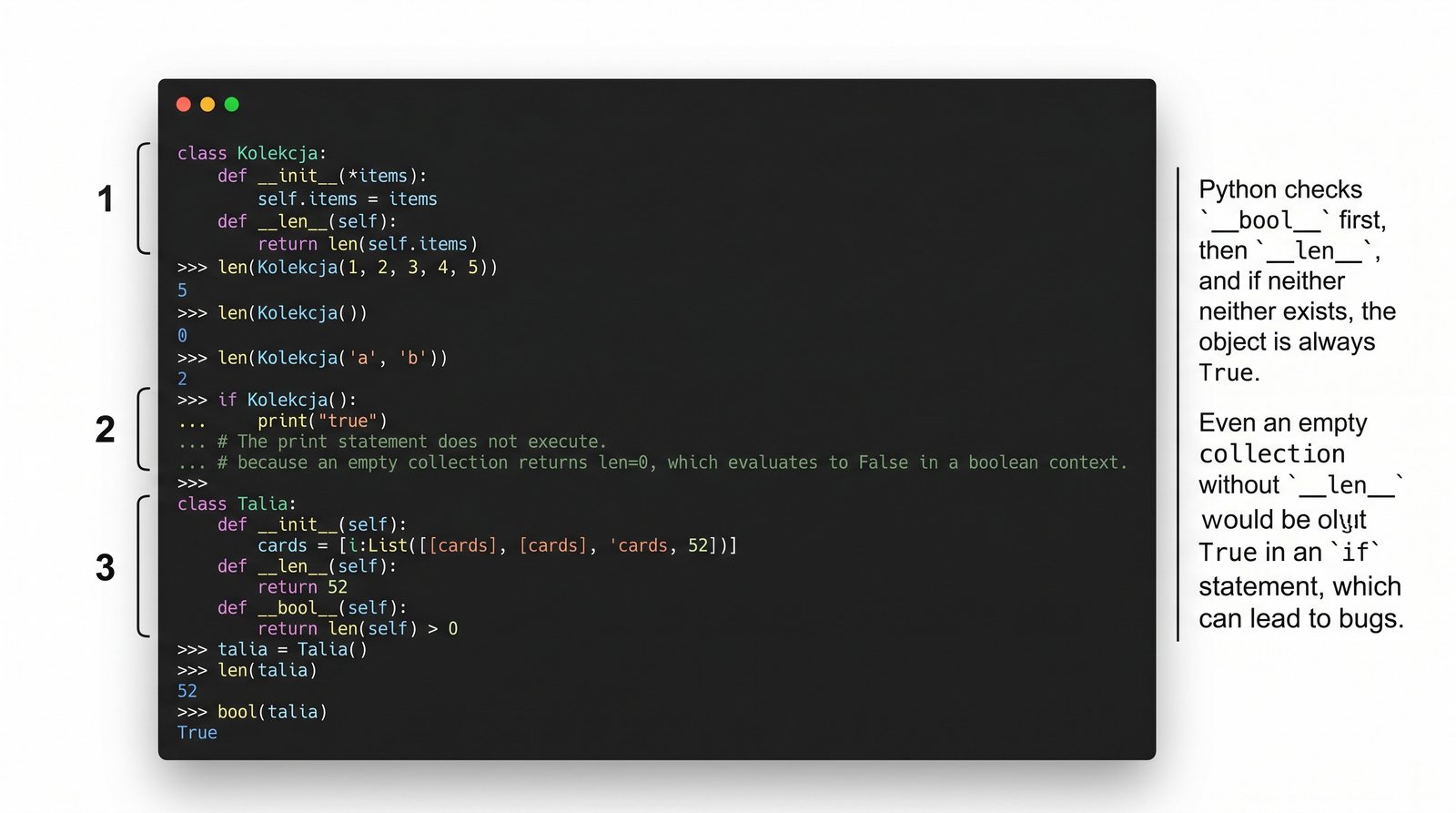
__len__
,
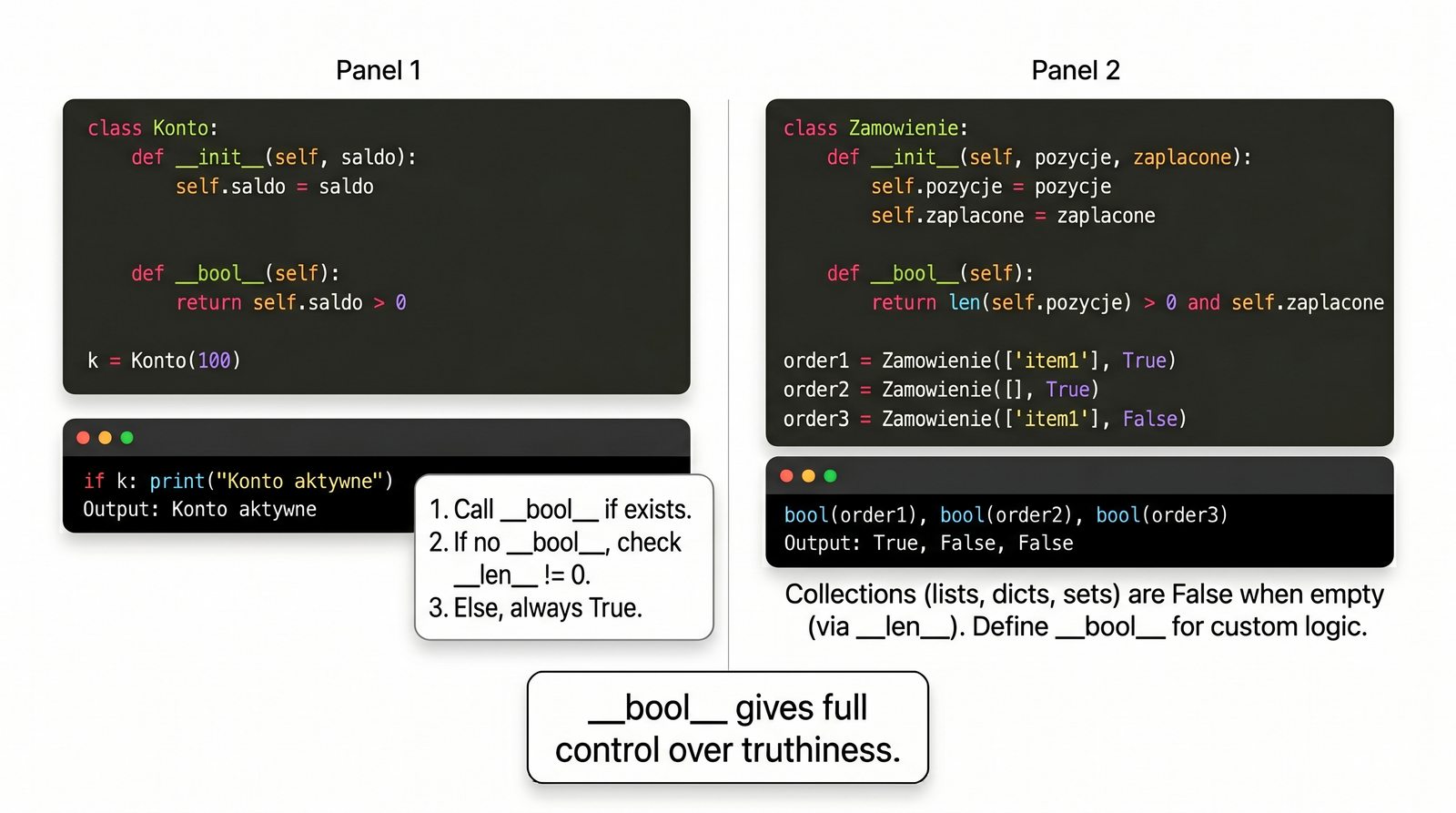
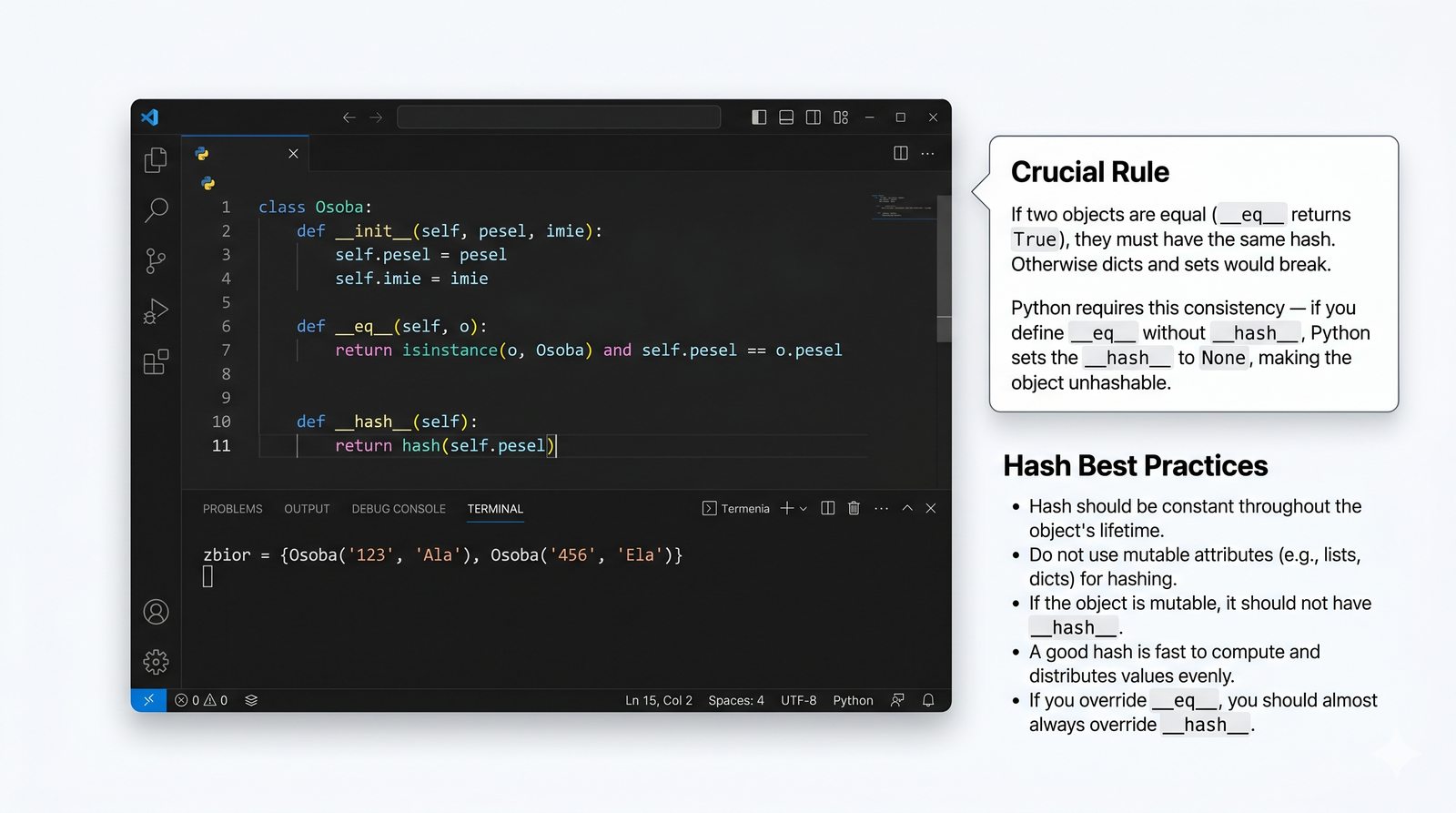
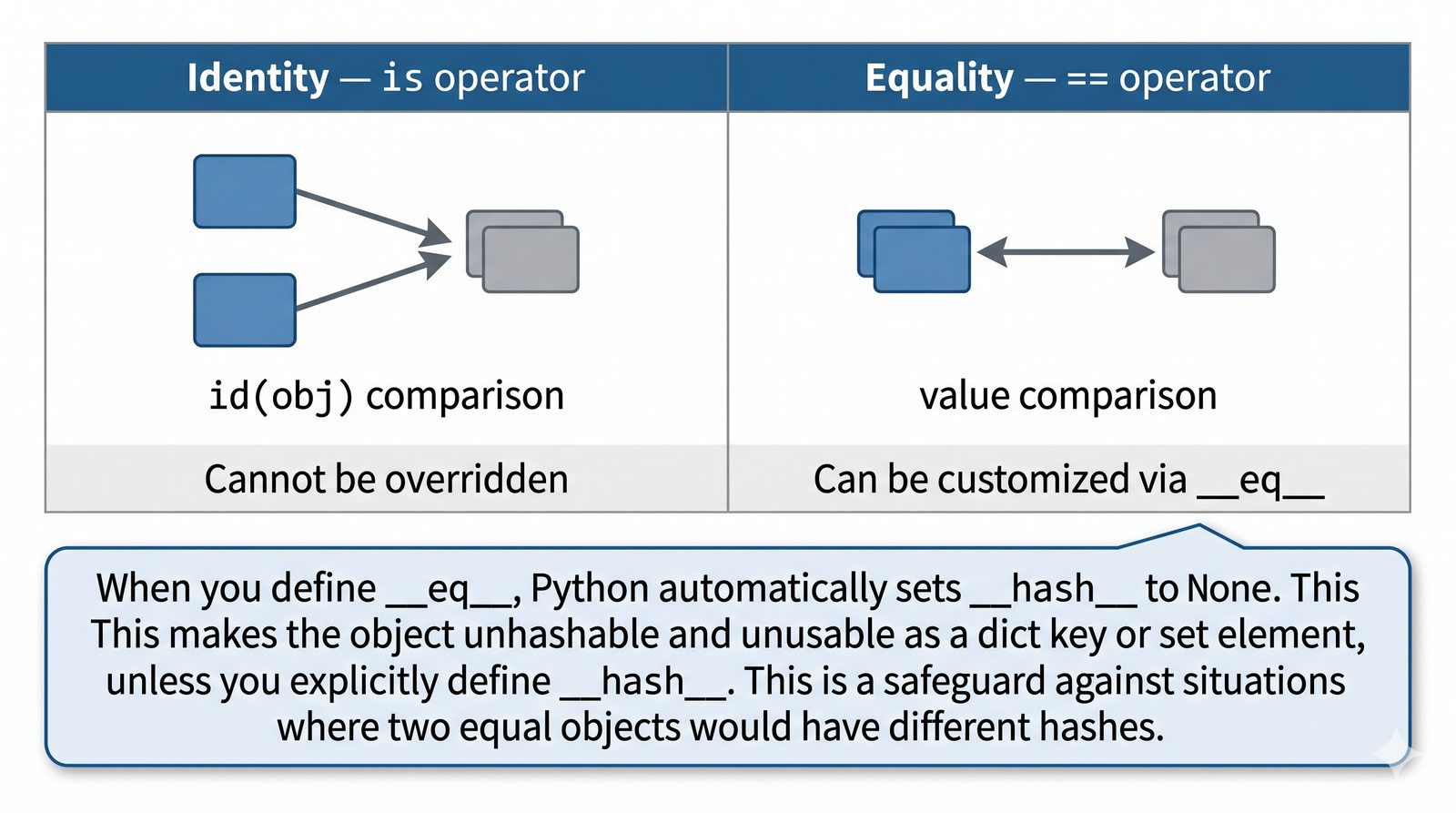
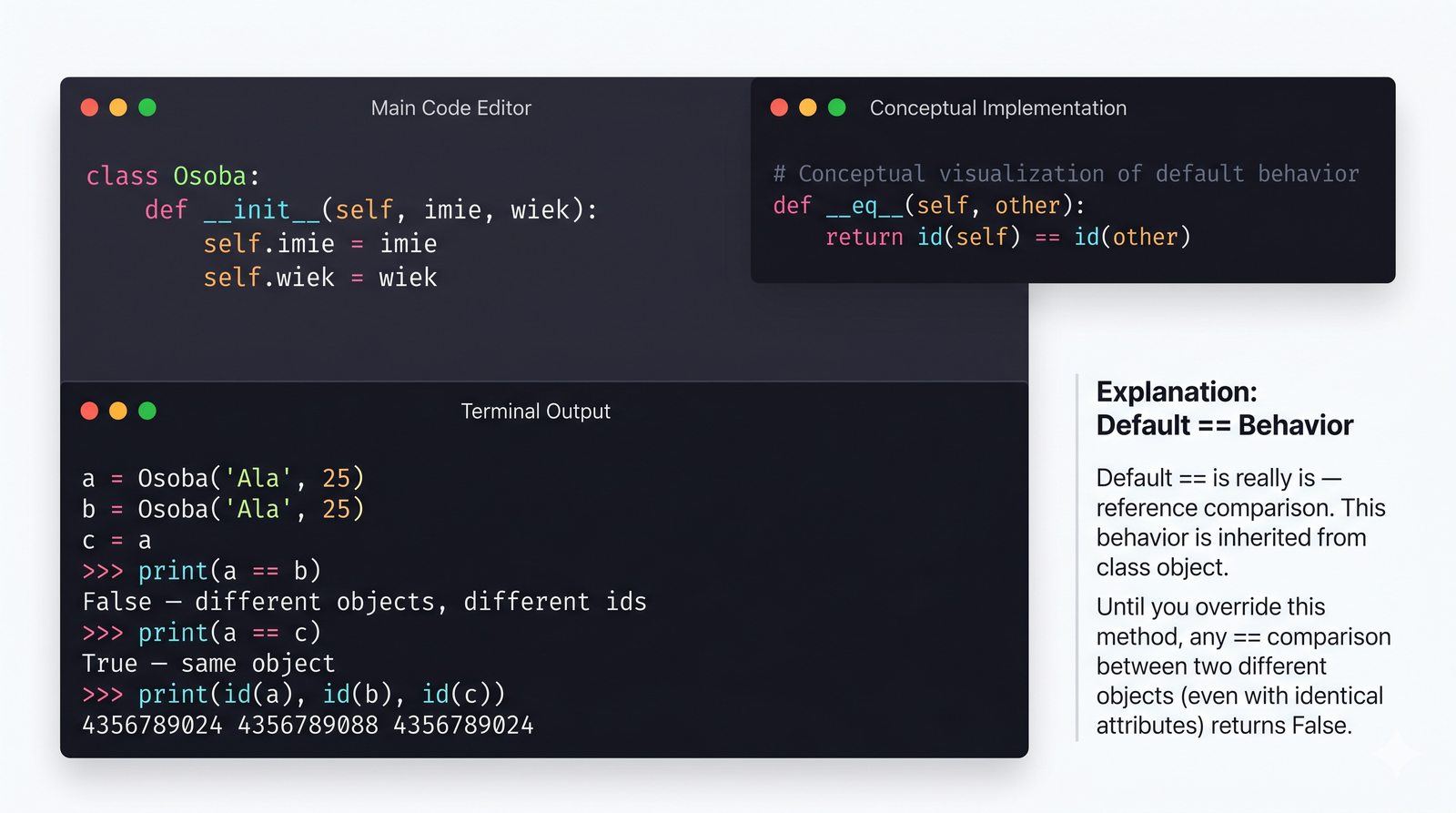
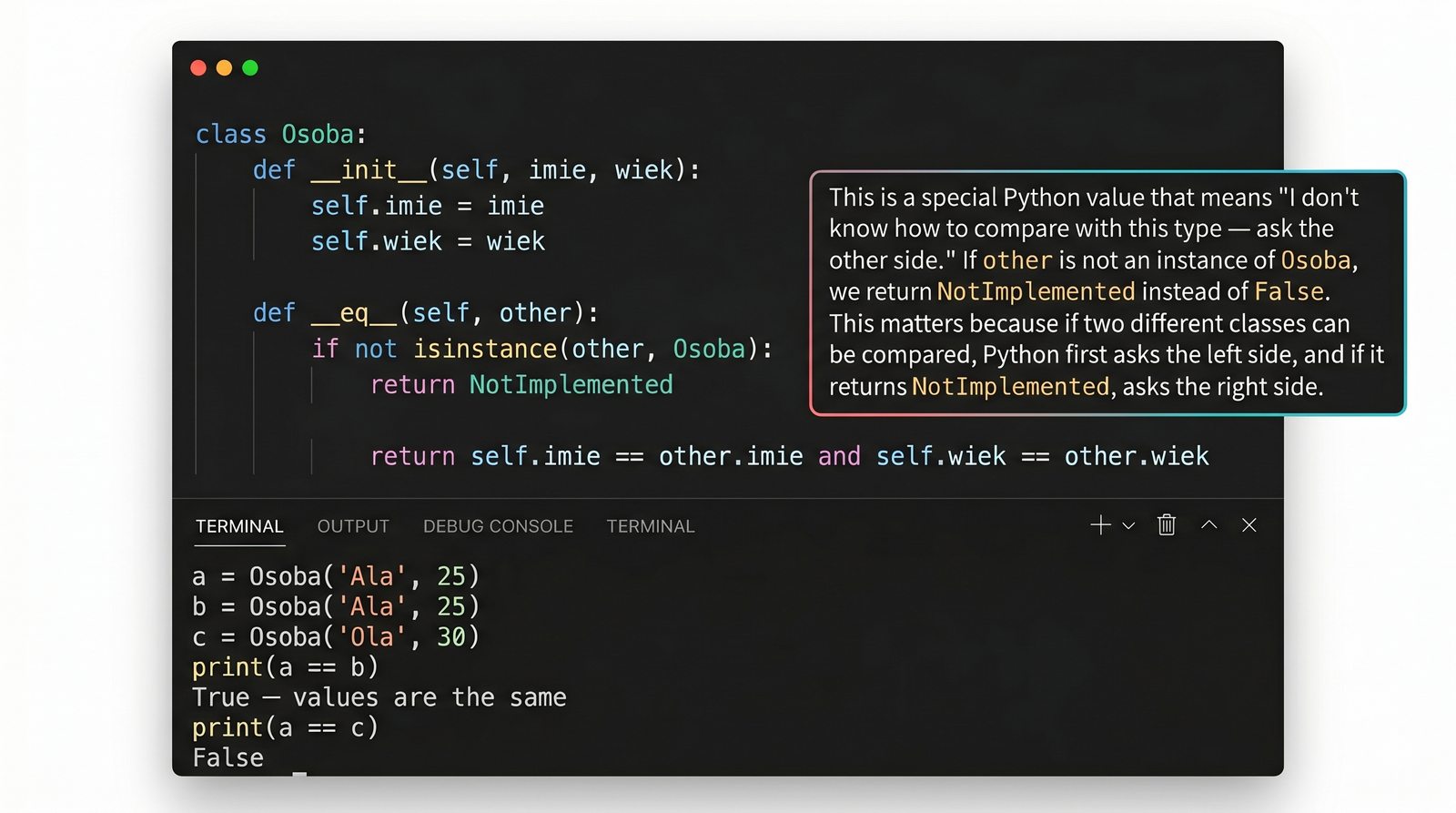
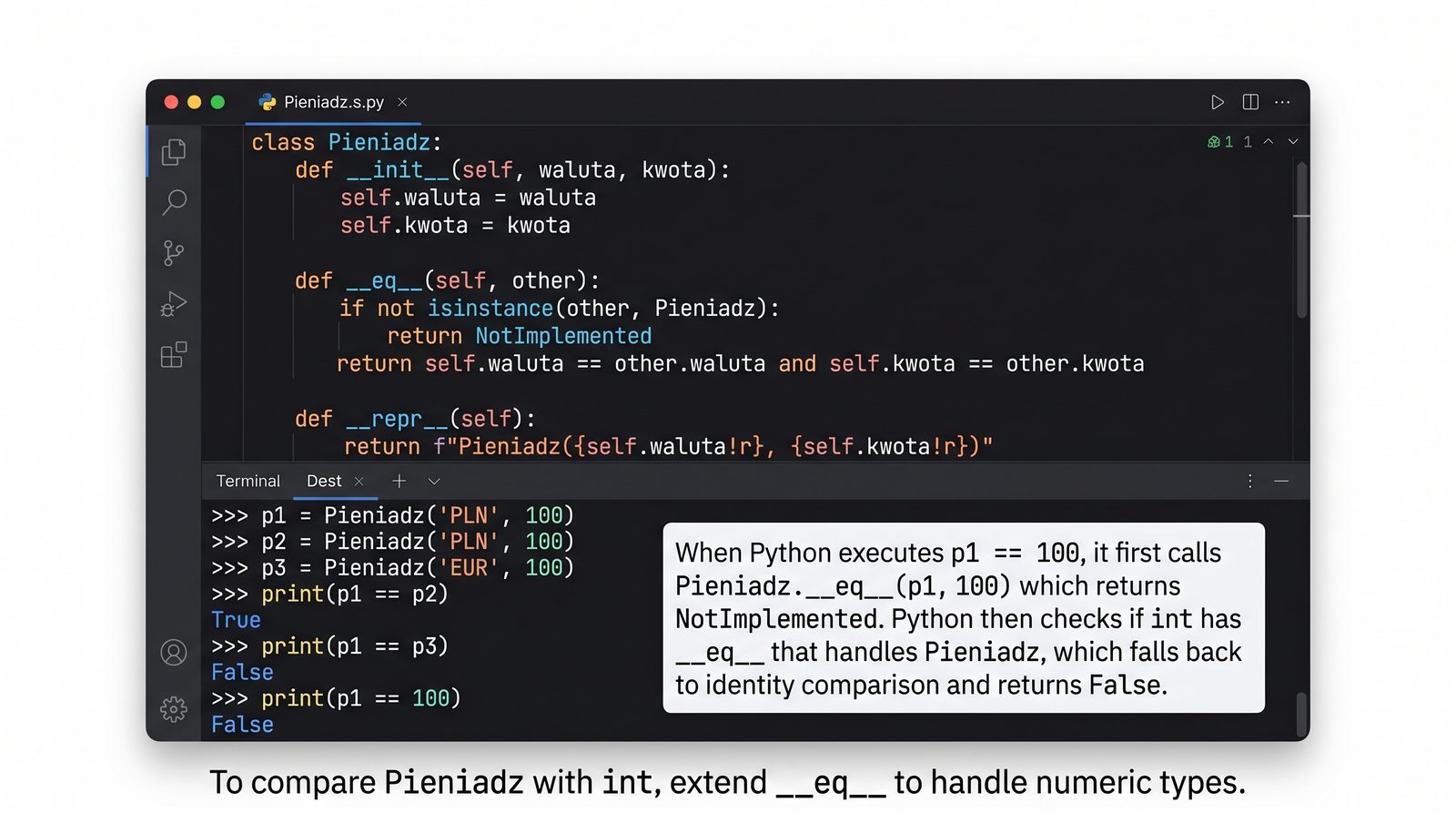
__eq__
,
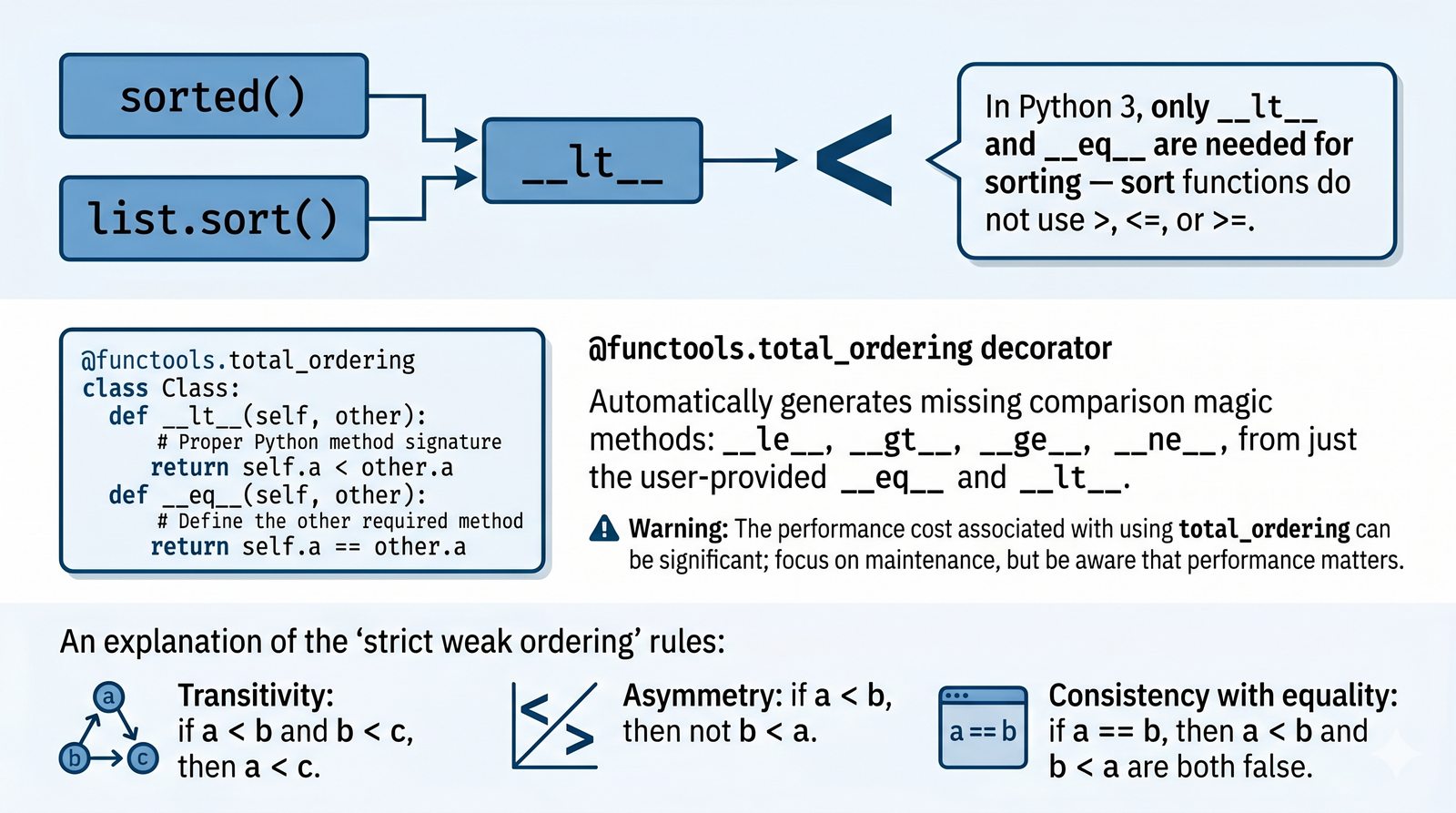
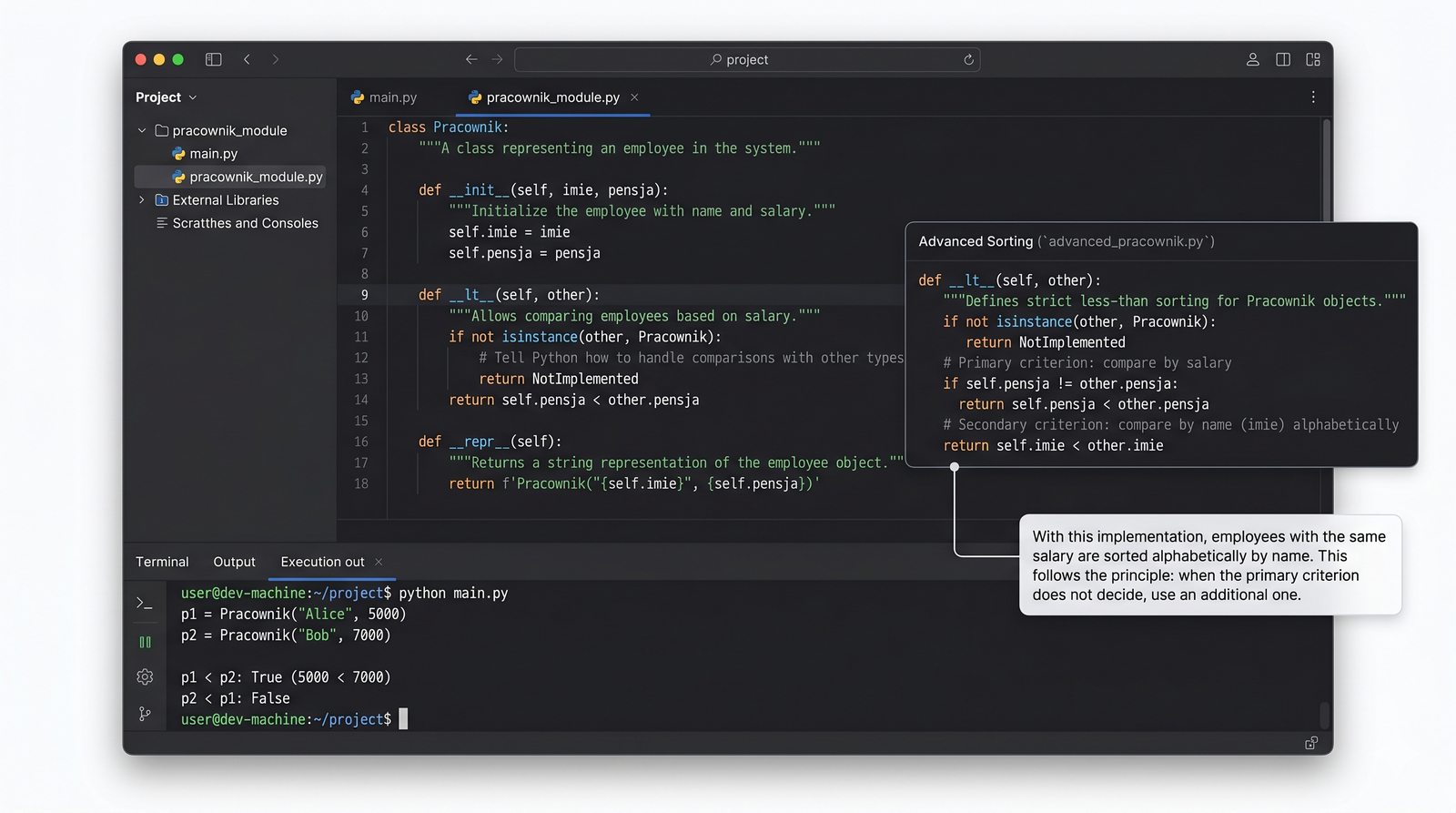
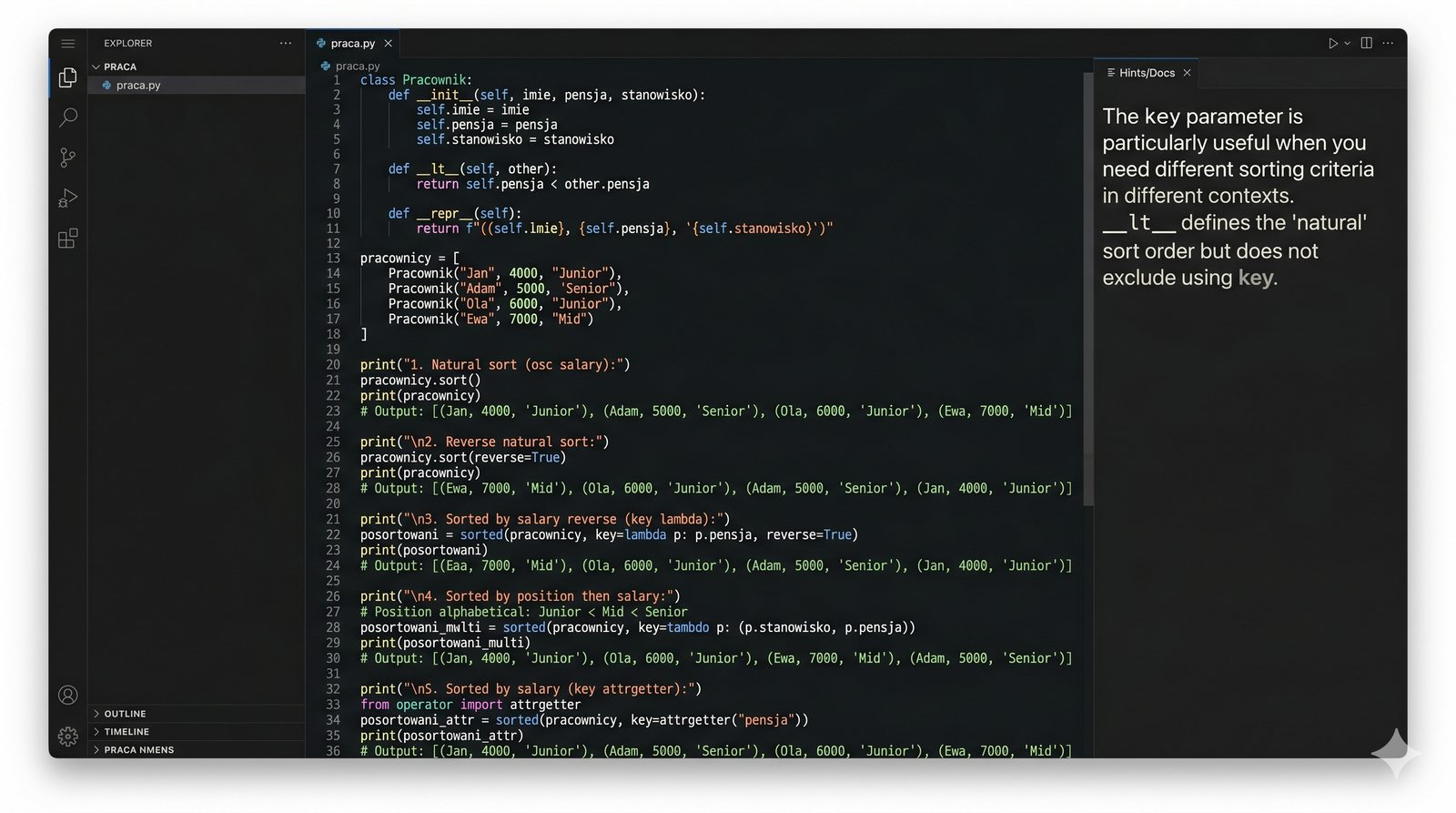
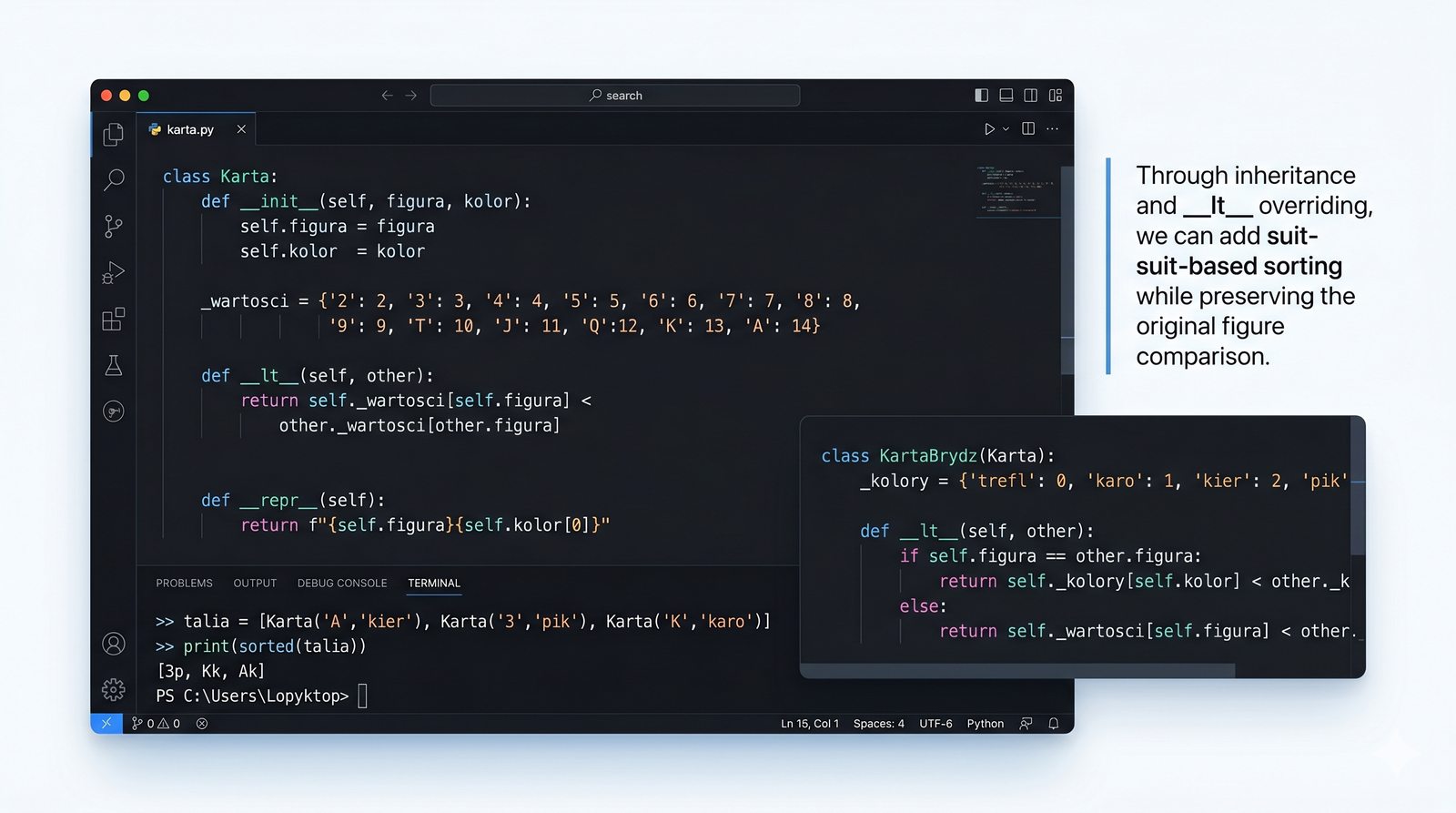
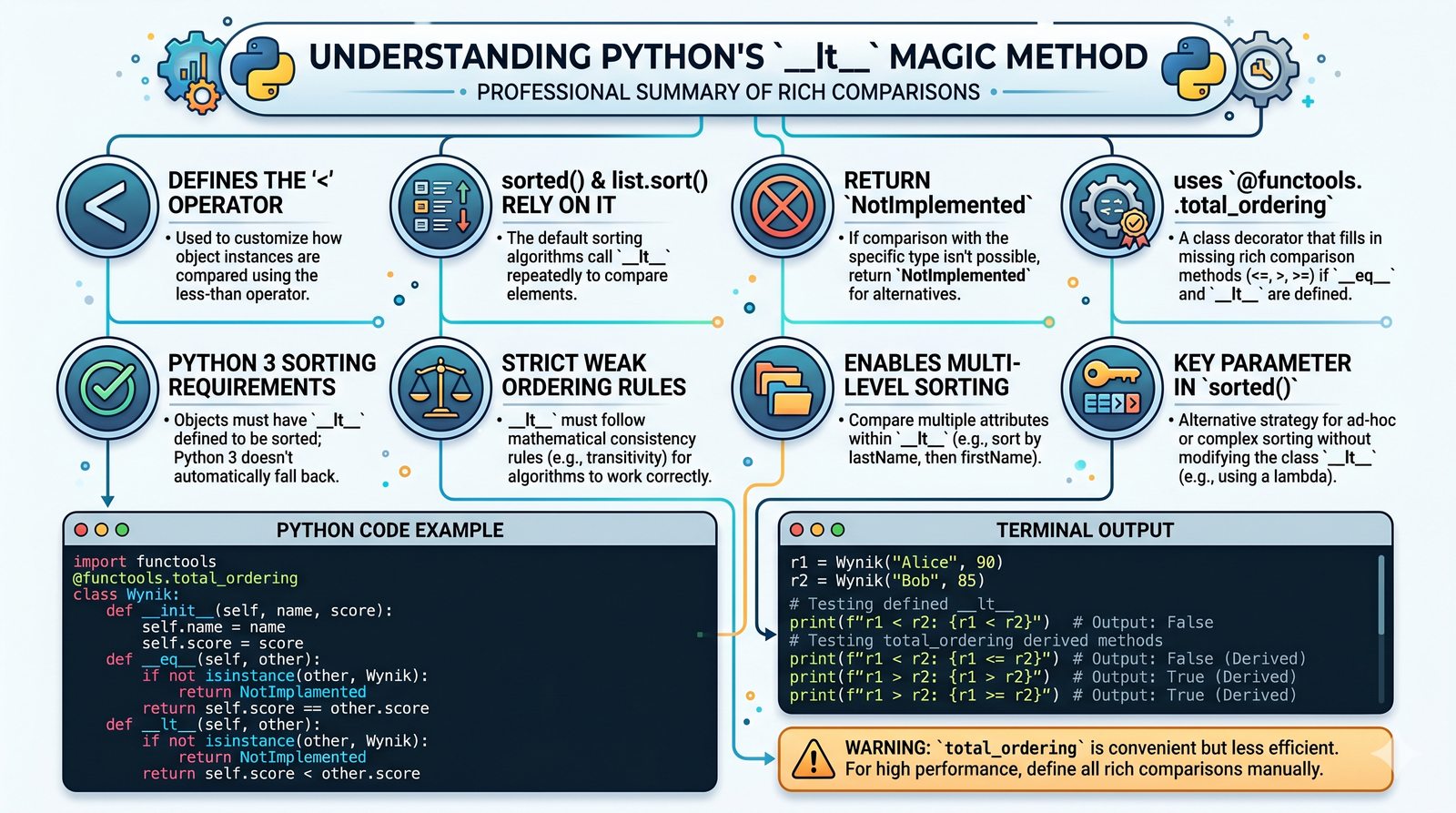
__lt__
,
__add__
i inne - jak nadać swoim klasom zachowania znane z wbudowanych typów.
Poznaj tajniki metod nazywanych "dunder" (double underscore) i naucz się pisać kod, który jest zarówno czytelny, jak i potężny.
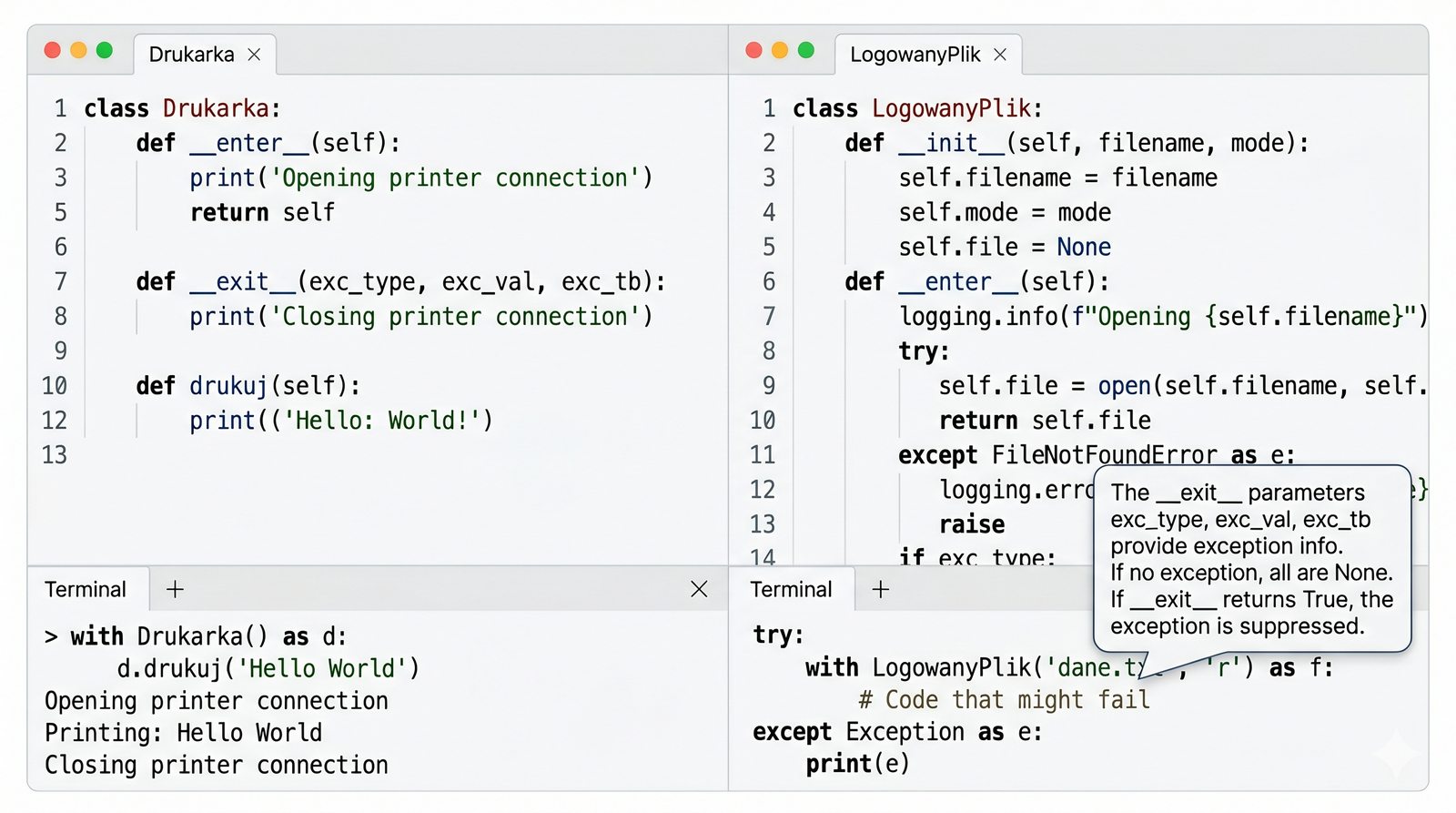
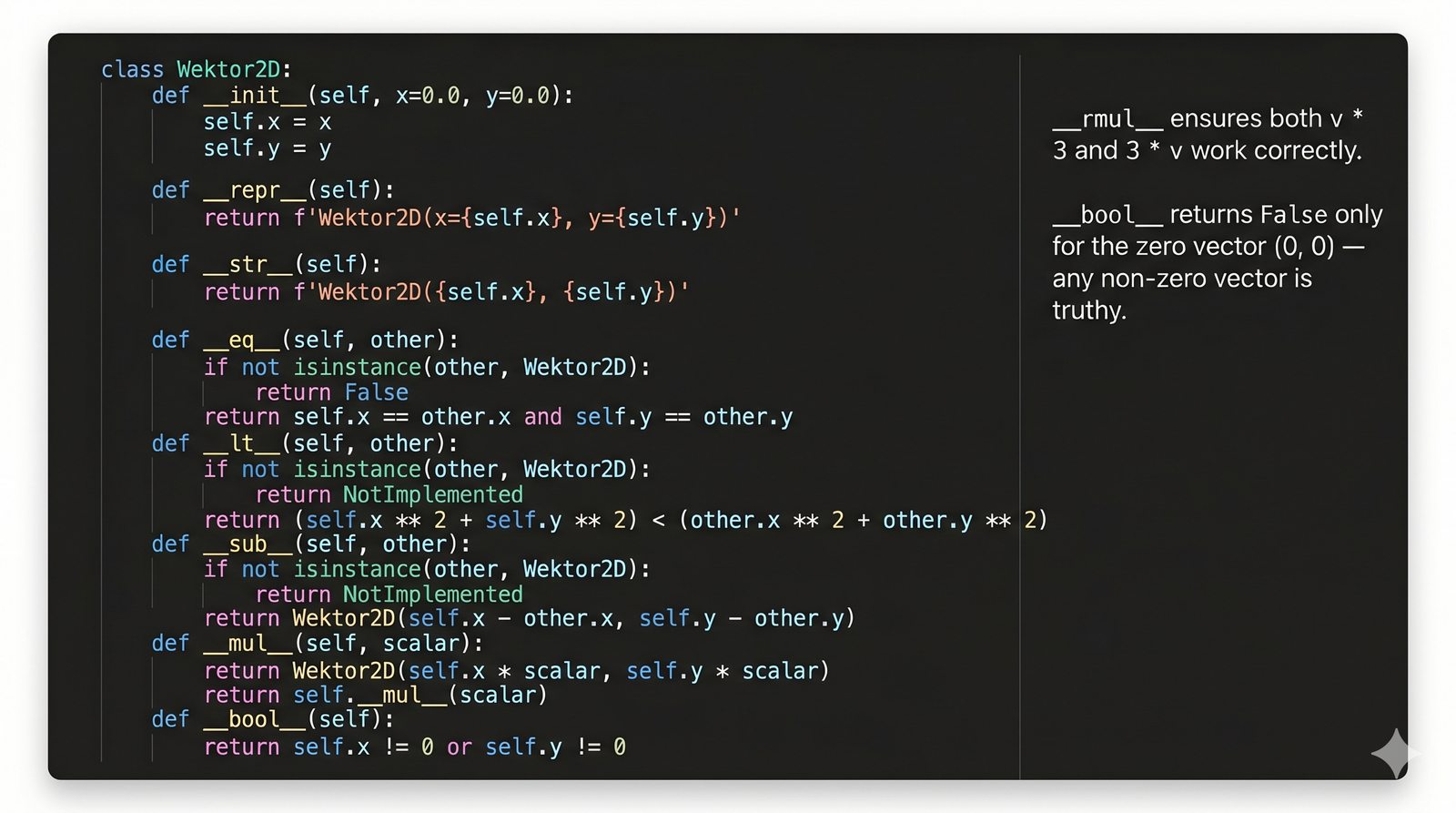
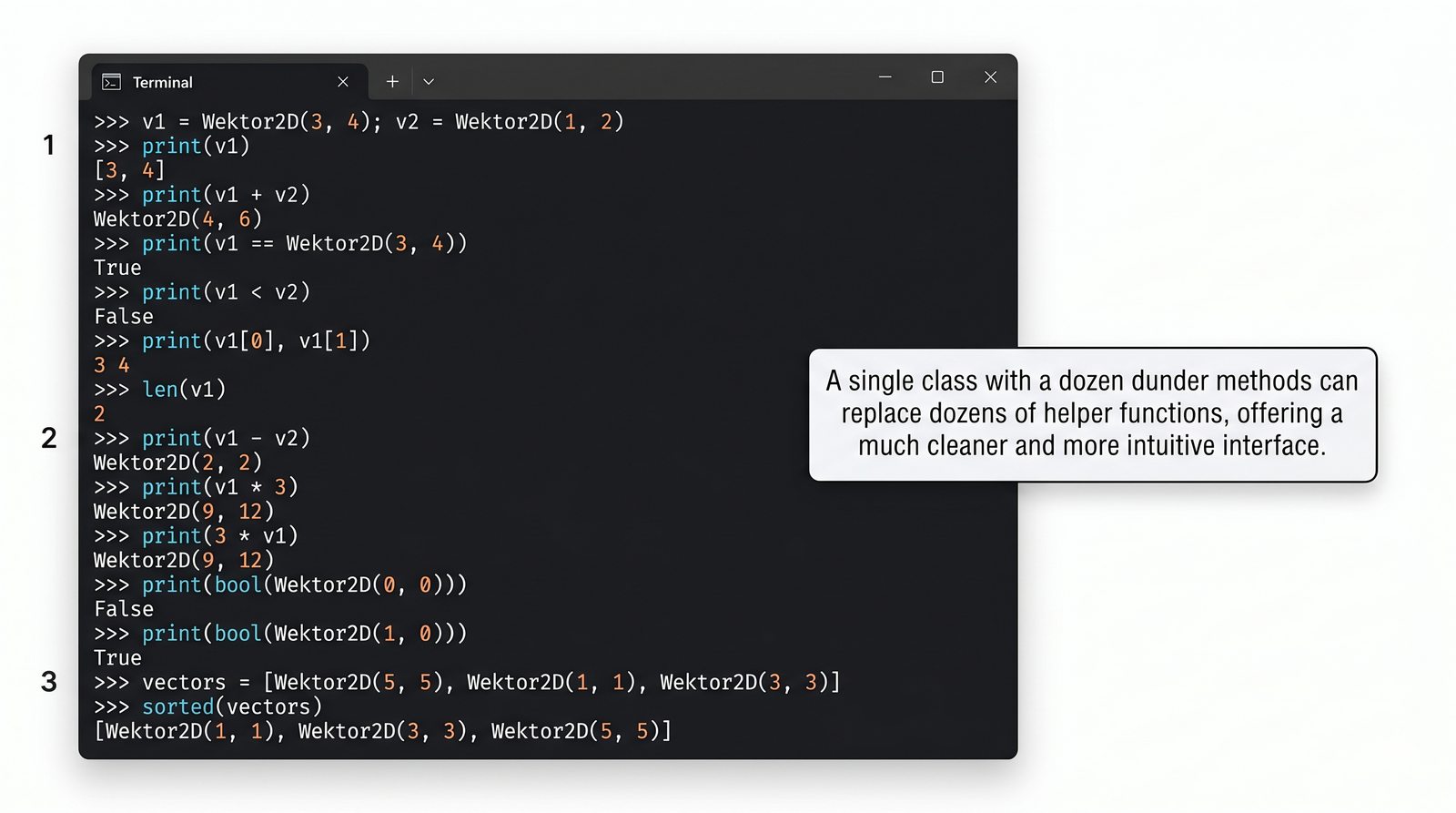
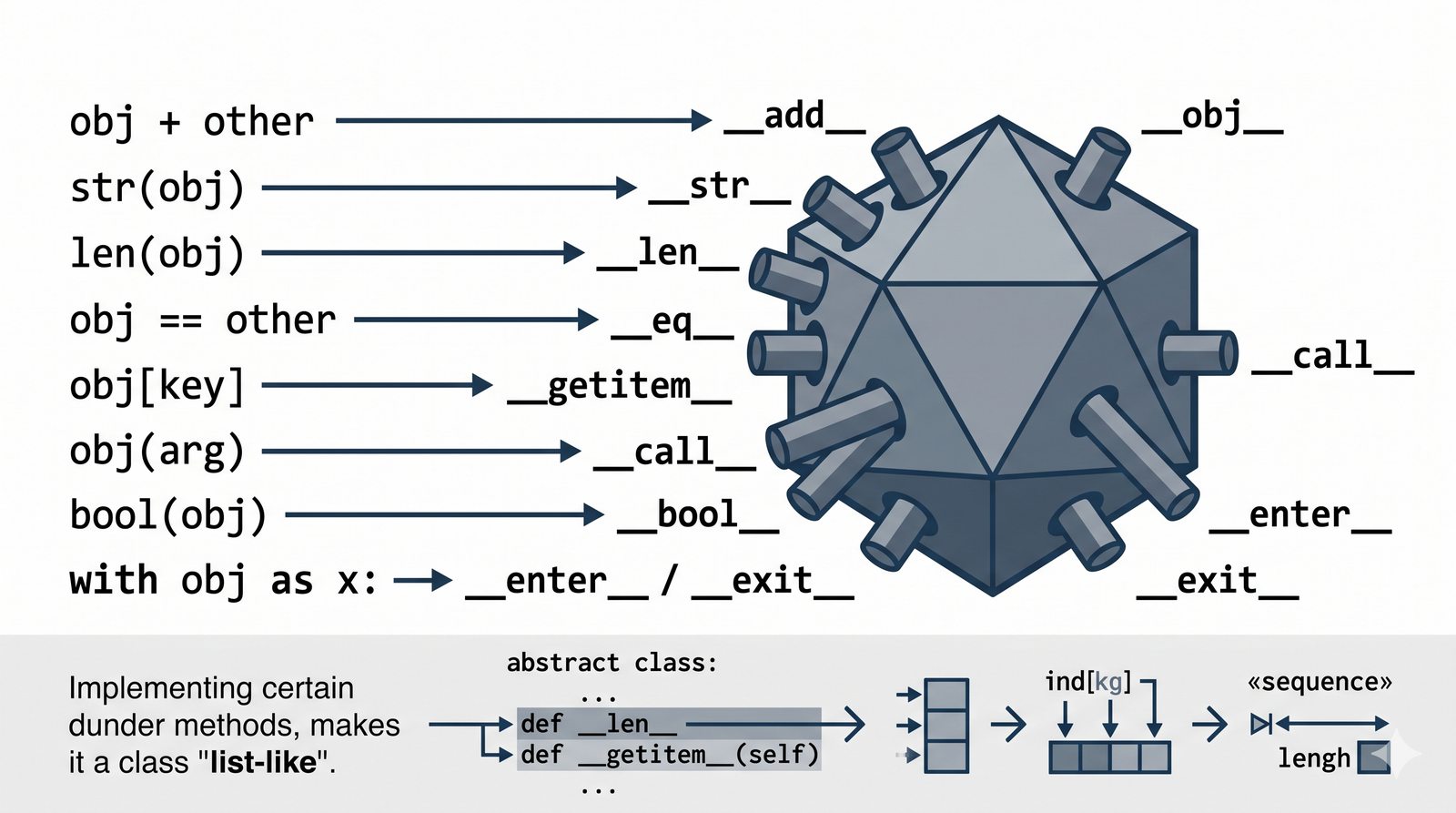
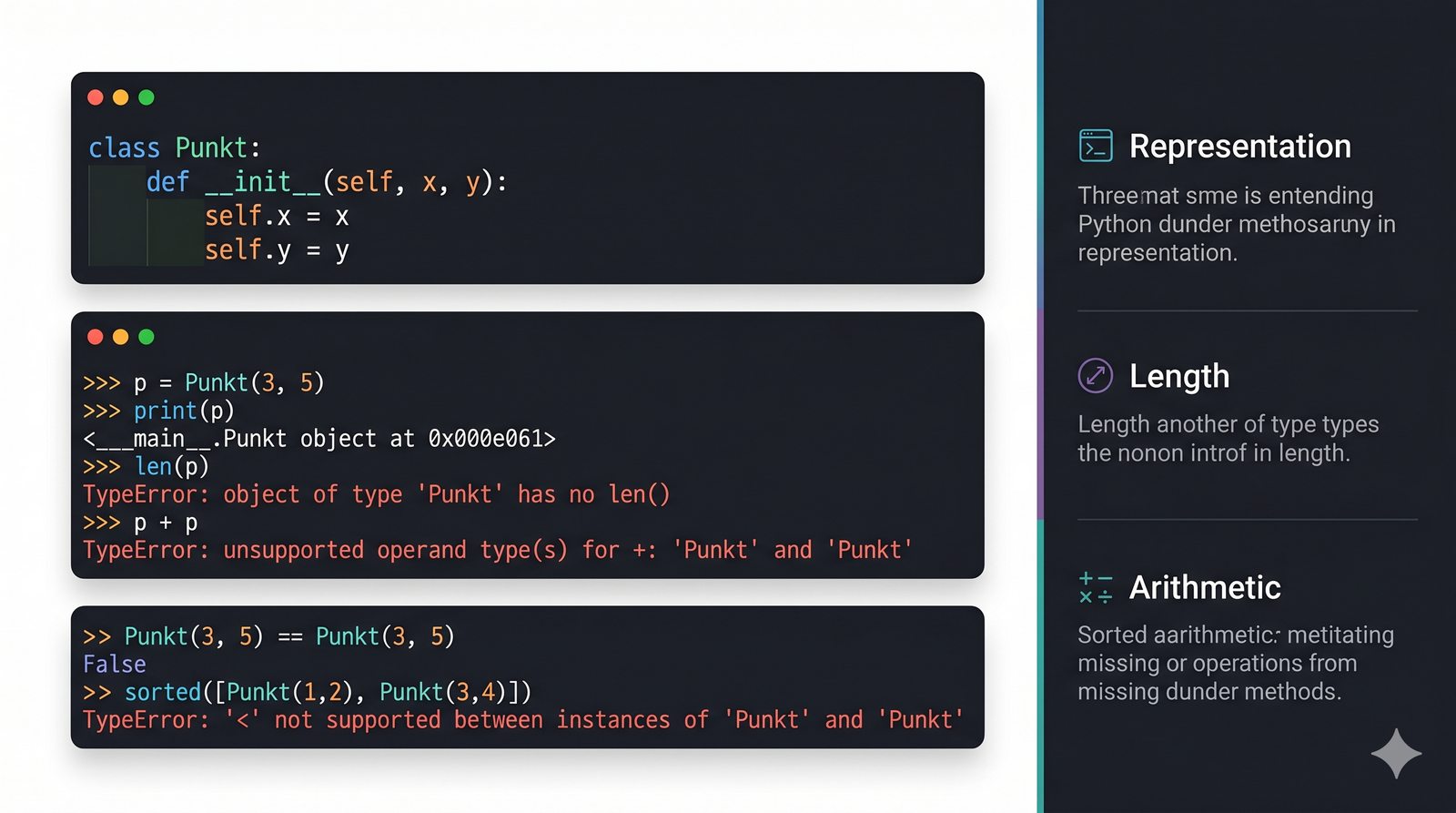
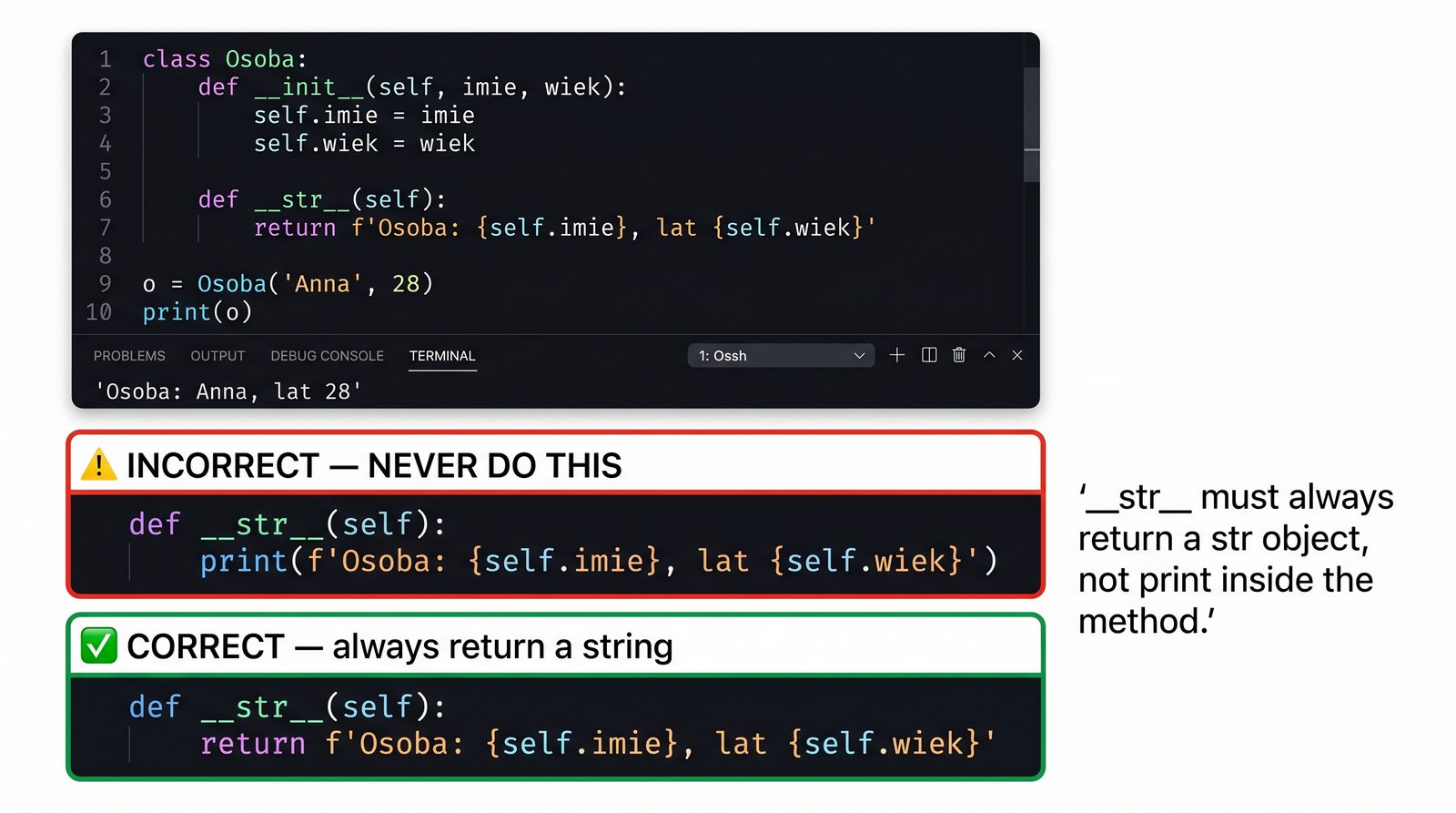
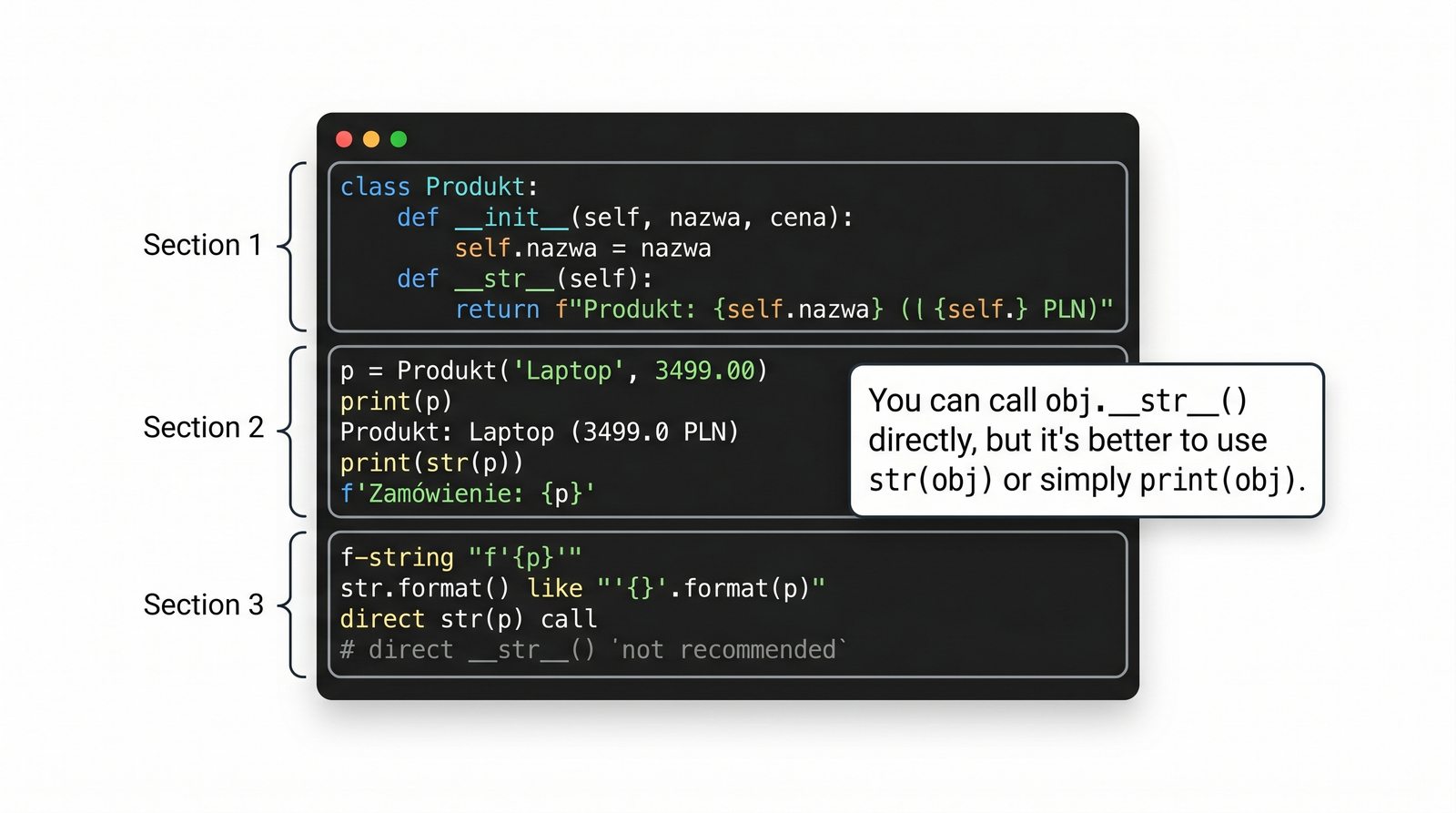
Metody magiczne to fundament Pythonicznego programowania obiektowego. Dzięki nim twoje klasy mogą reagować na operatory arytmetyczne, porównania, indeksowanie, wywołania funkcyjne, konwersje typów i wiele innych mechanizmów języka. Zamiast pisać metody
obiekt.wyswietl()
wystarczy zdefiniować
__str__
, a
print(obiekt)
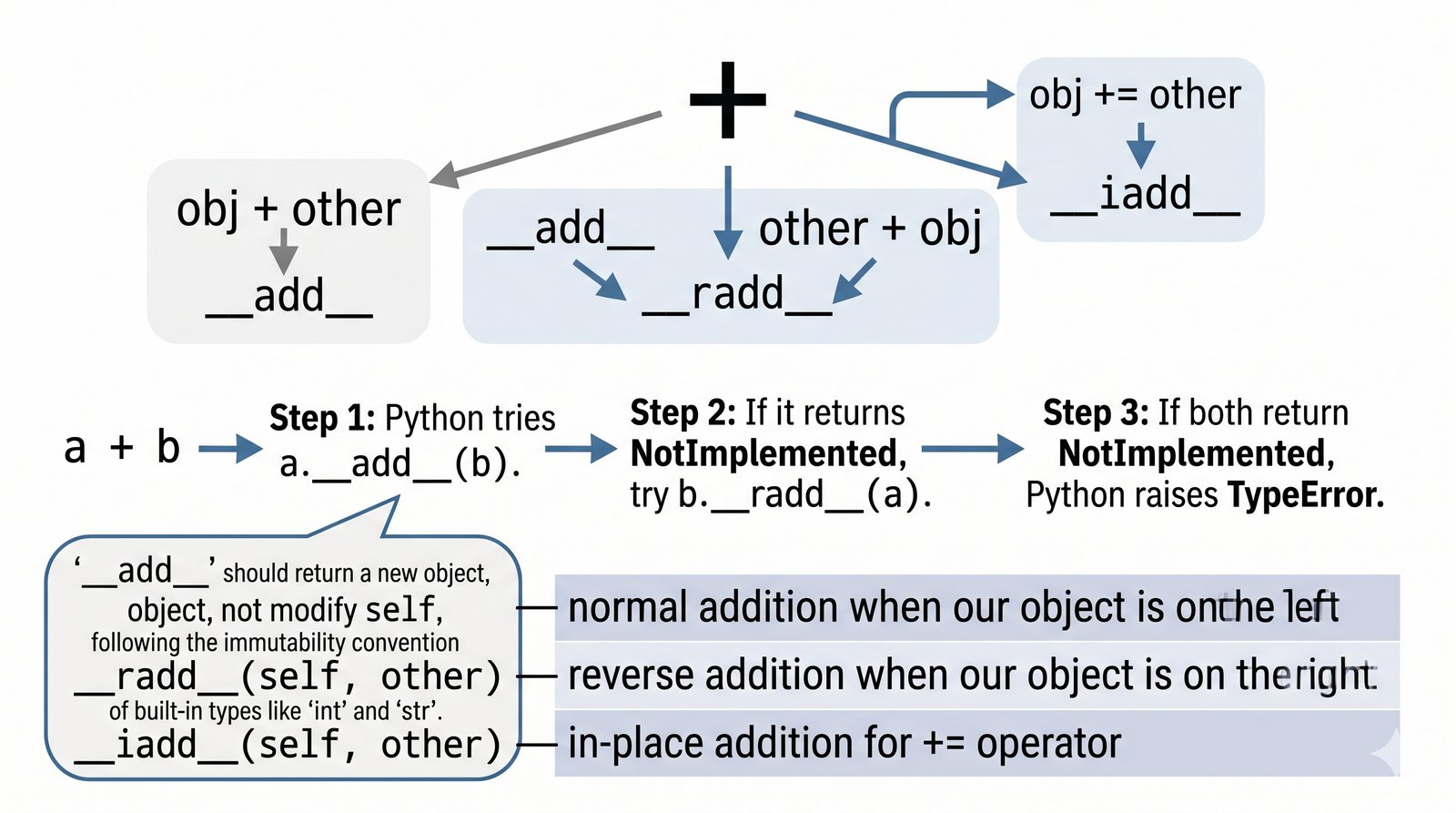
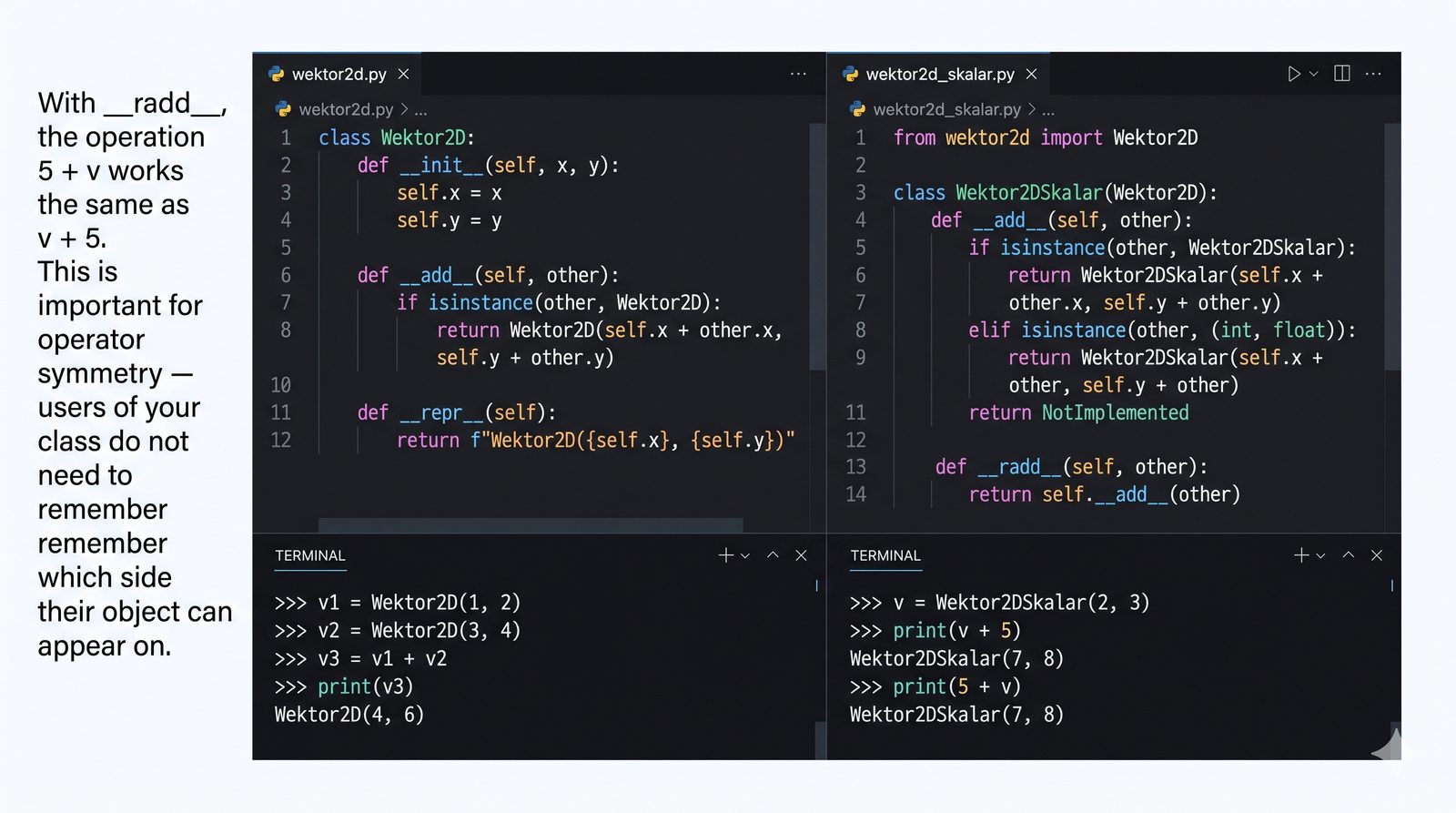
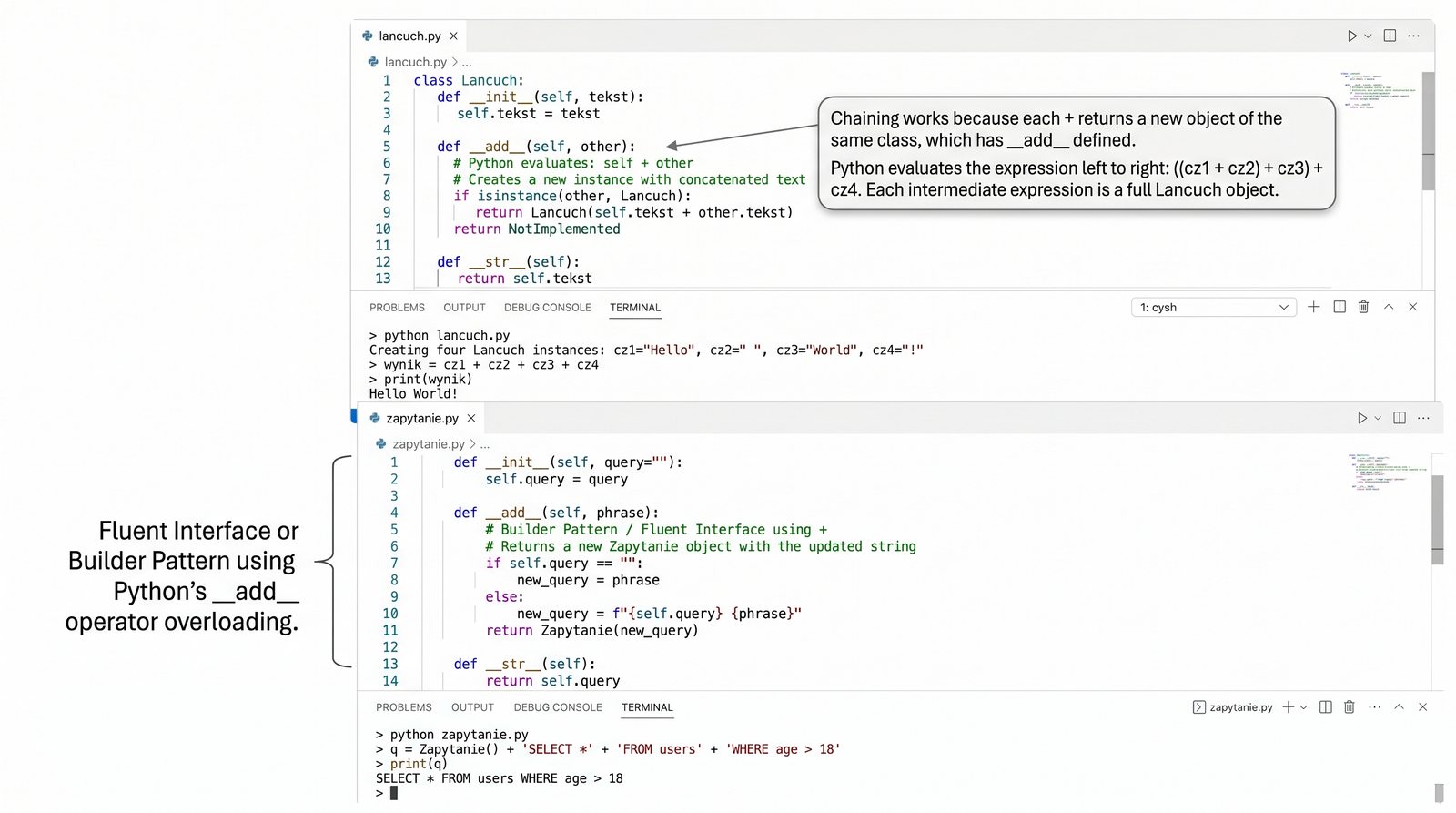
zadziała automatycznie. To samo dotyczy dodawania (
__add__
), porównań (
__eq__
,
__lt__
) czy długości (
__len__
). W tej części poznasz wszystkie najważniejsze metody dunder i nauczysz się je stosować w praktyce.
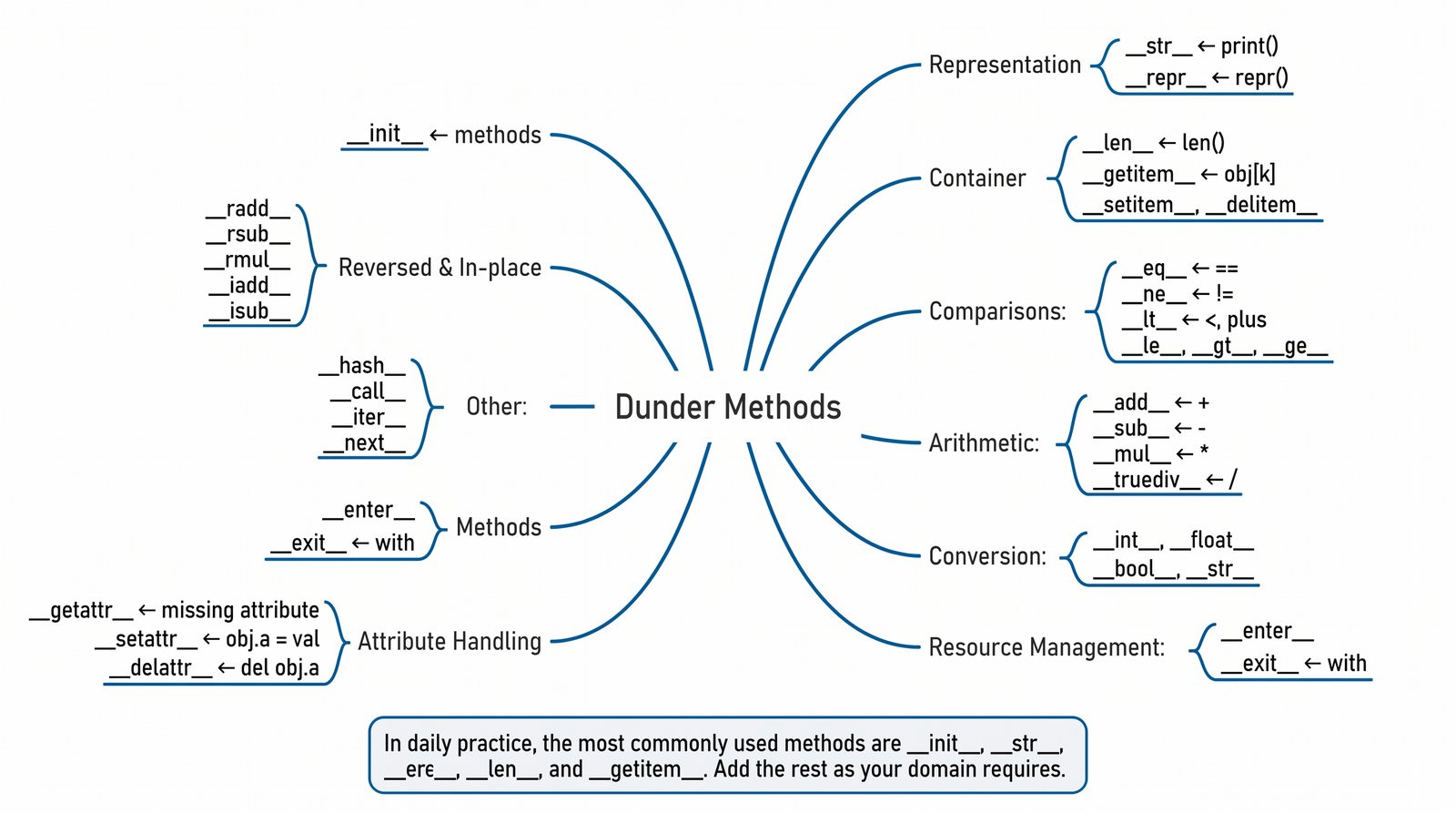
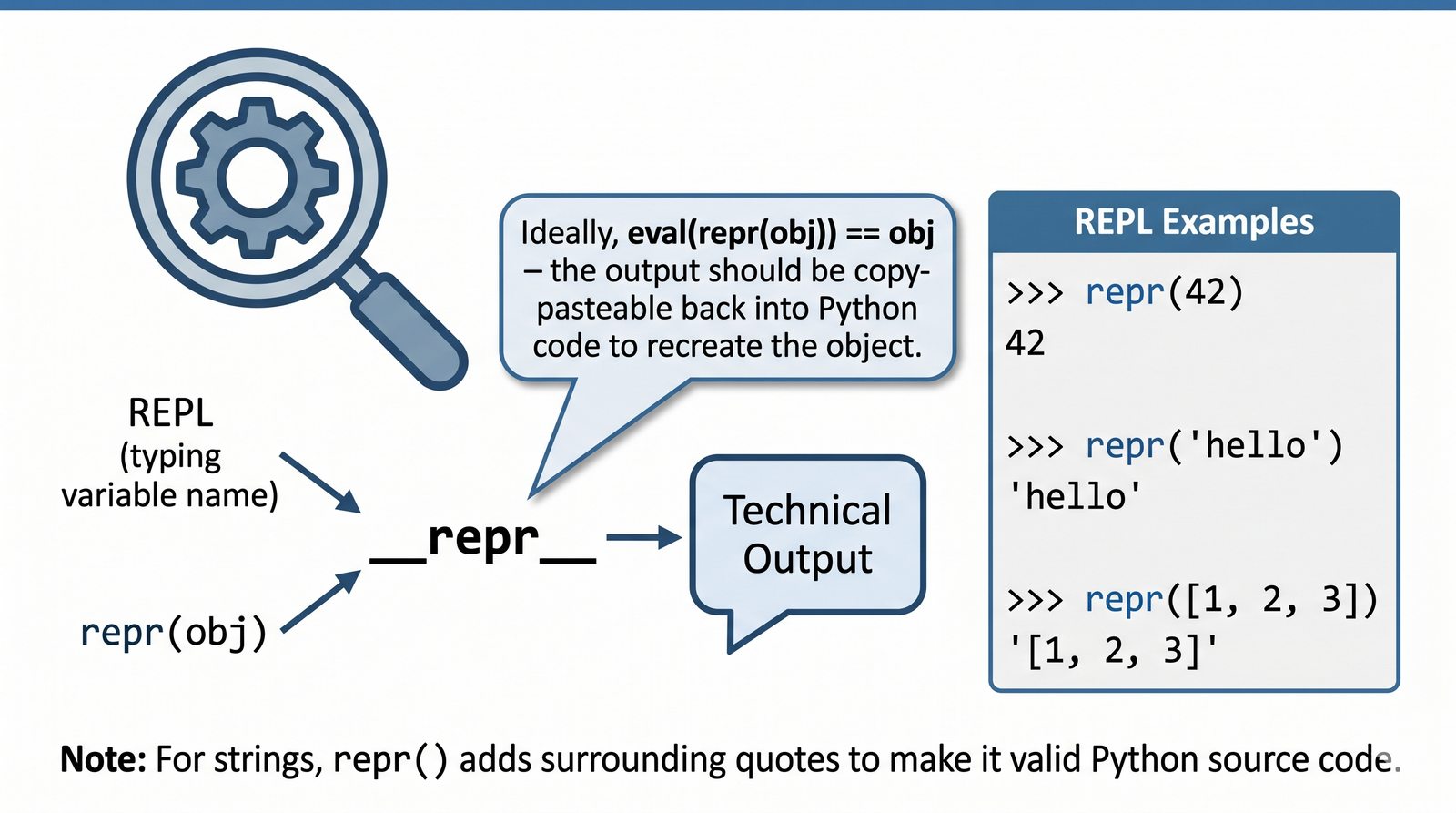
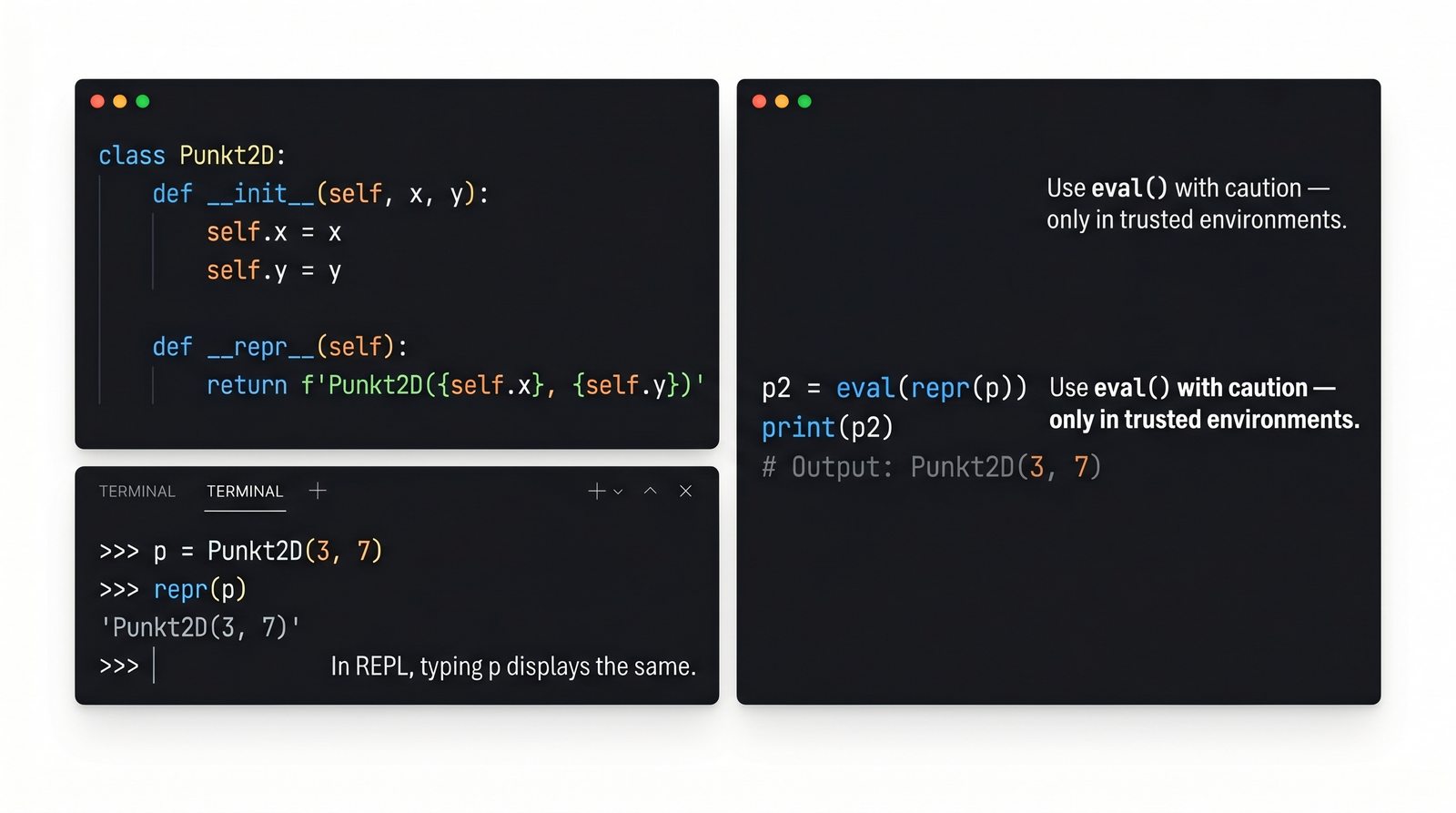
Nazwa "dunder" pochodzi od angielskiego "double underscore" (podwójny podkreślnik). Każda metoda magiczna ma nazwę otoczoną dwoma podkreślnikami z obu stron, np.
__init__
,
__str__
,
__add__
. Python rezerwuje ten schemat nazewniczy dla specjalnych metod, które są wywoływane automatycznie przez interpreter w odpowiedzi na określone operacje.
+
,
len()
,
print()
i
sorted()
, użytkownicy twojego kodu od razu wiedzą, jak jej używać.















![obiekt[klucz]](images/pySIMPLE_OOP_s08_40.jpg)