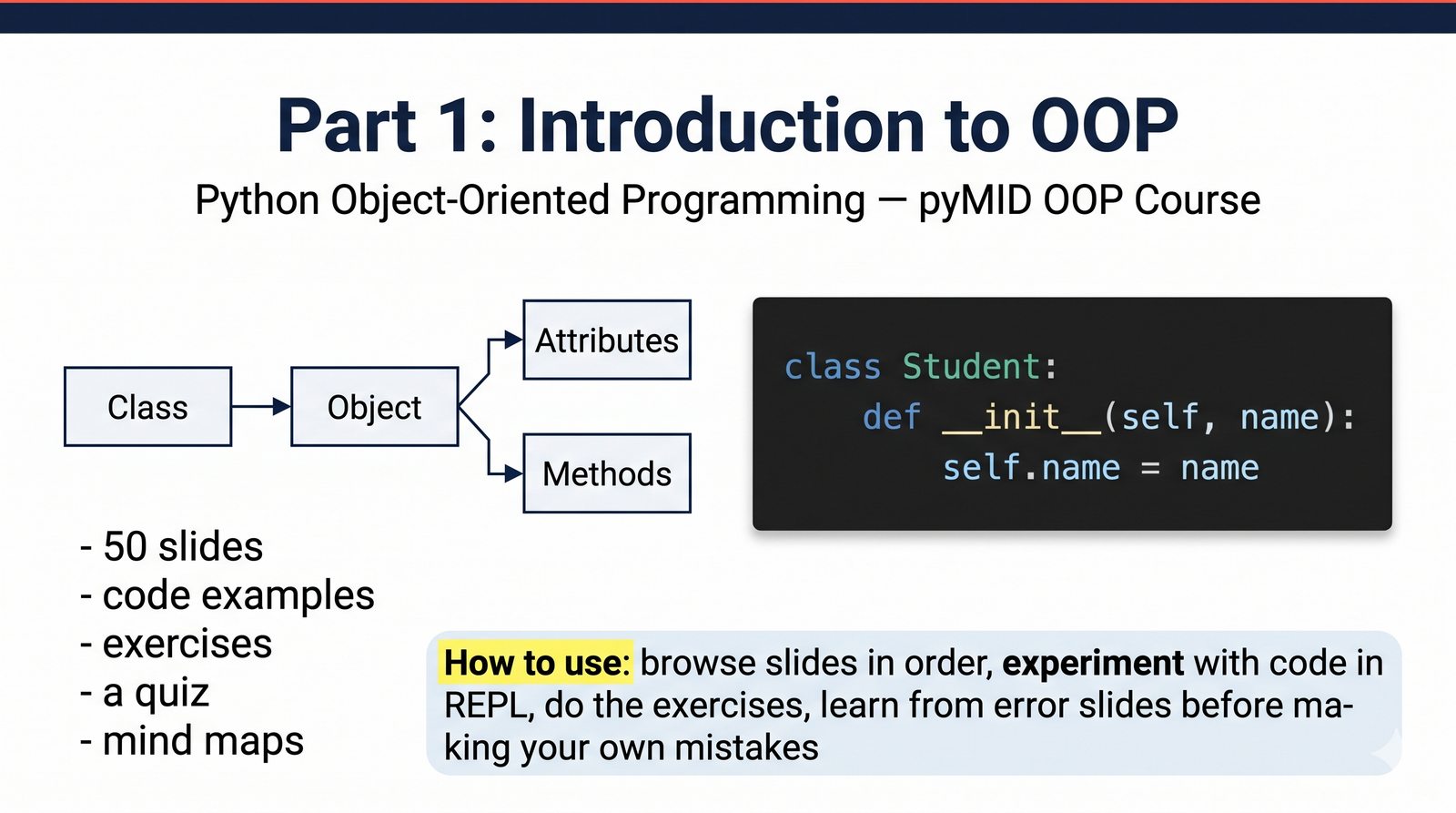
Część 1: wstęp do obiektowości
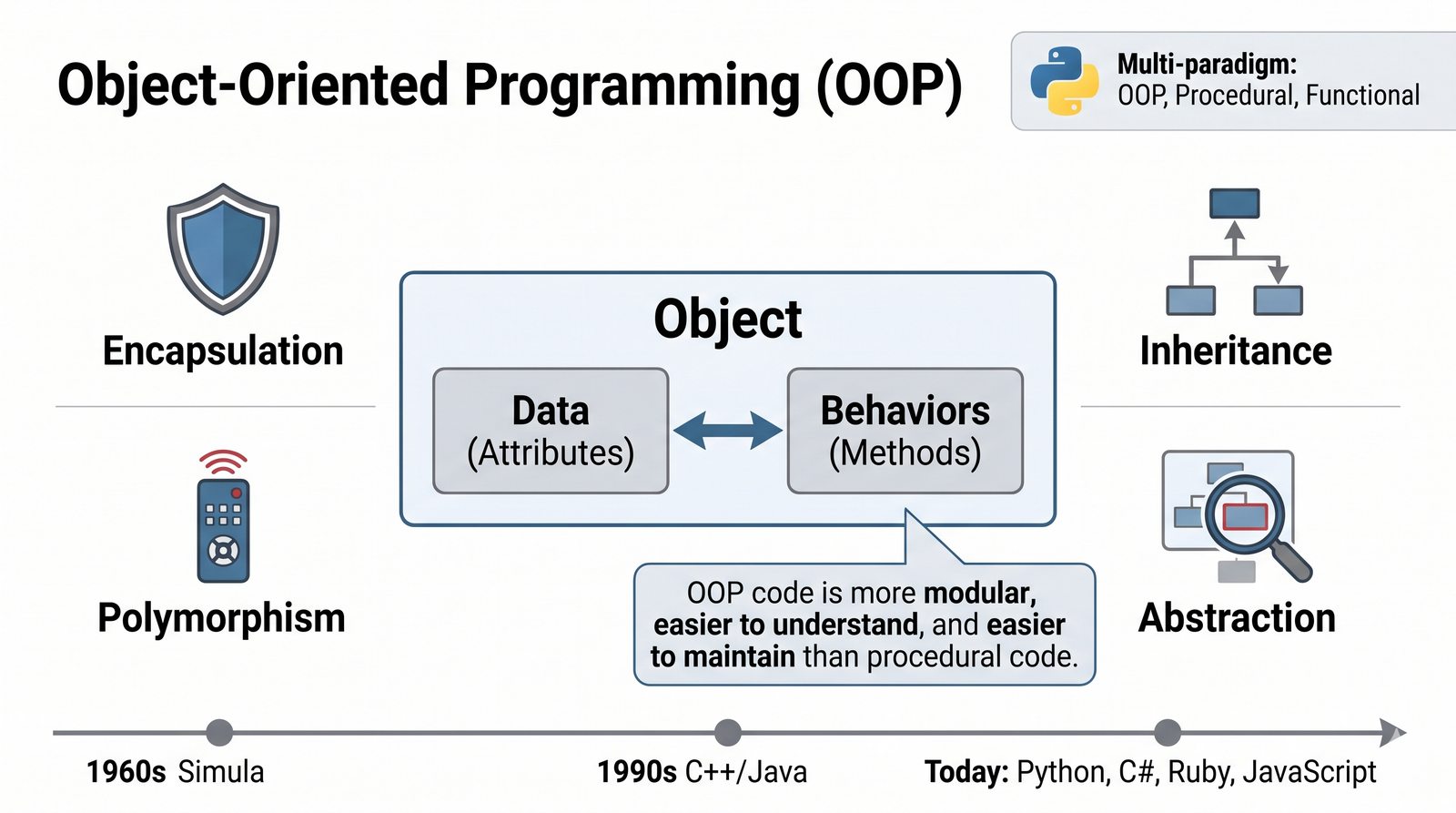
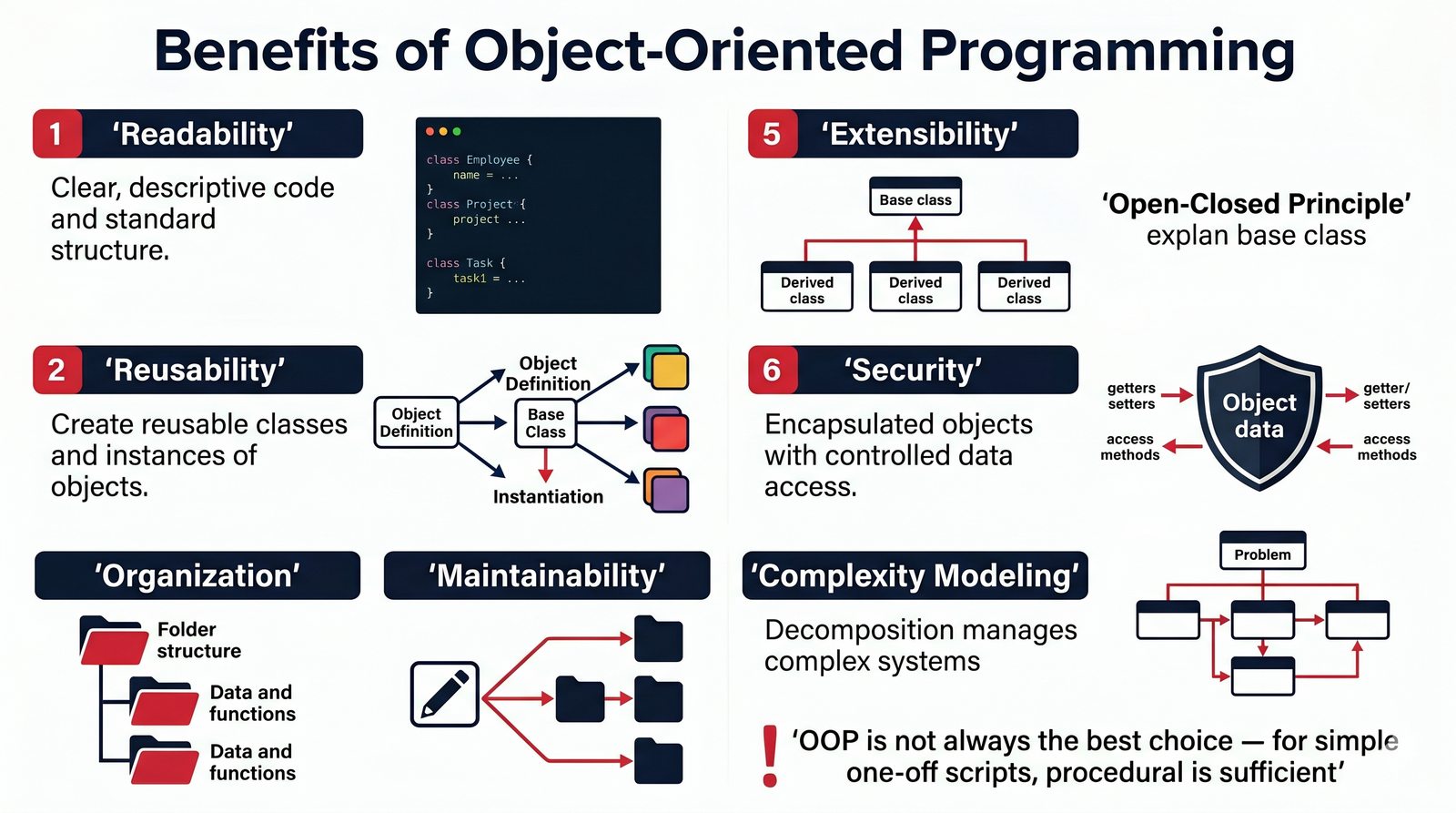
Programowanie obiektowe (OOP) to jeden z najważniejszych paradygmatów we współczesnym tworzeniu oprogramowania. Python, jako język wieloparadygmatowy, wspiera OOP w sposób elastyczny i przystępny dla początkujących.
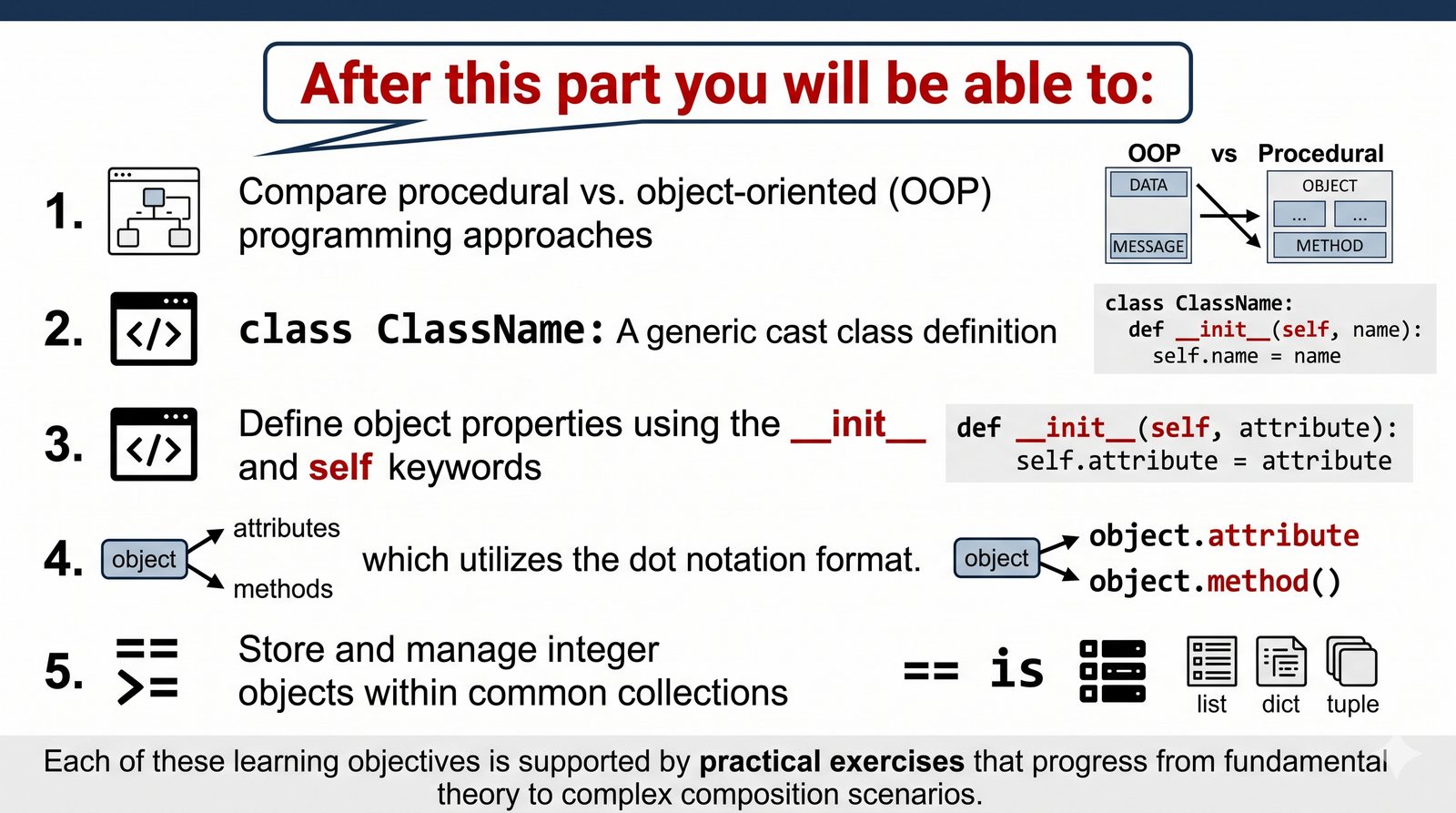
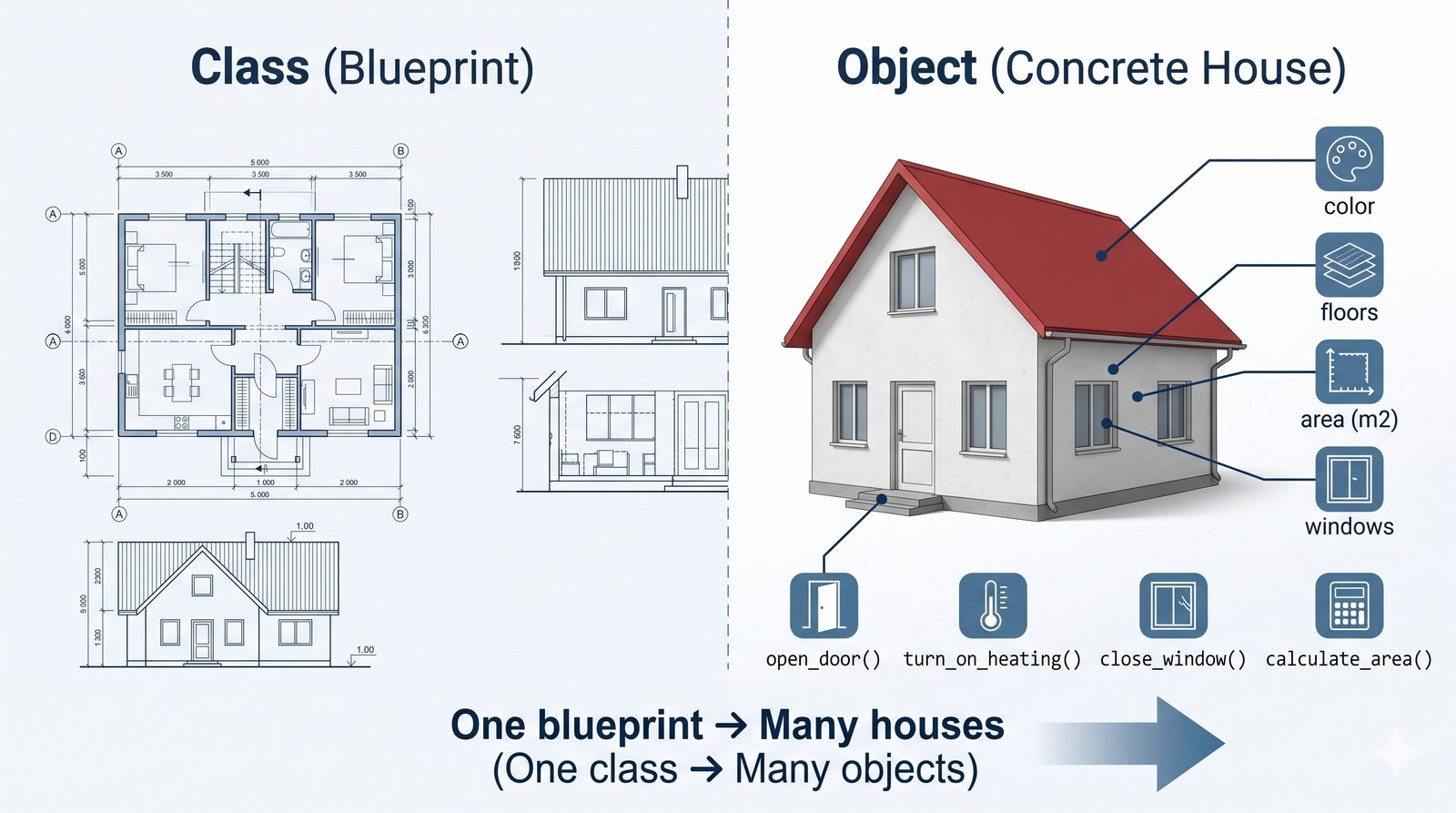
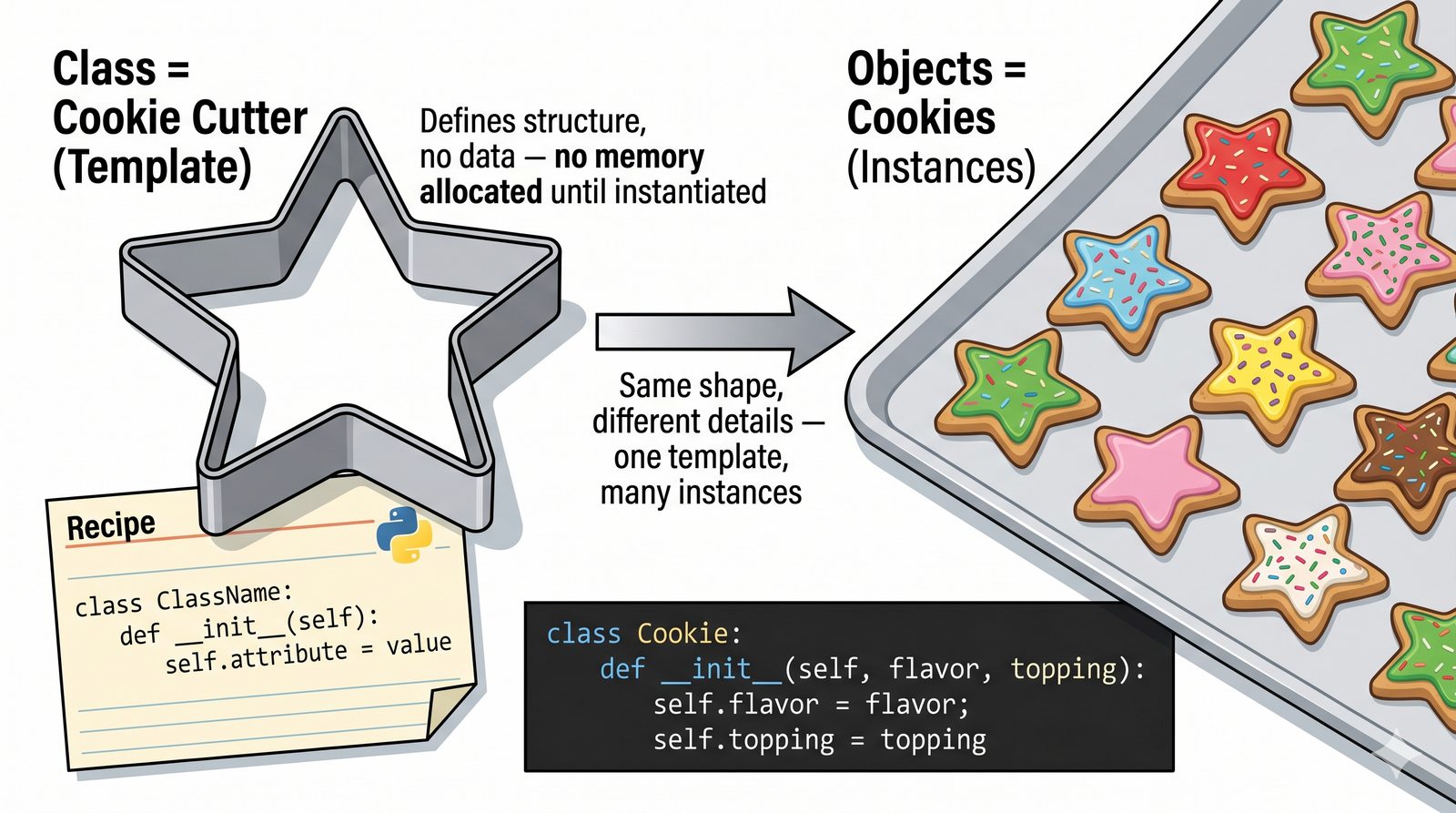
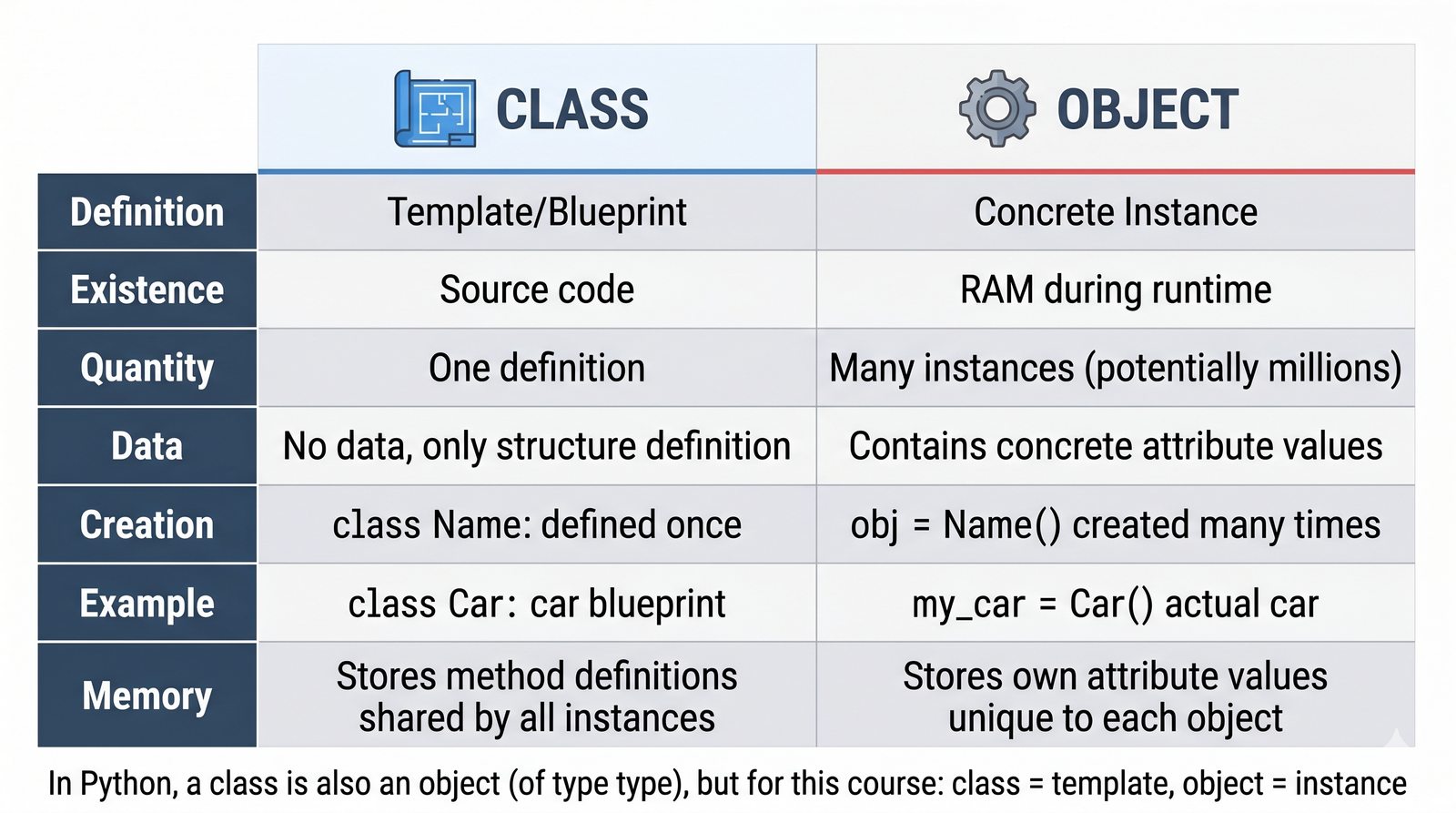
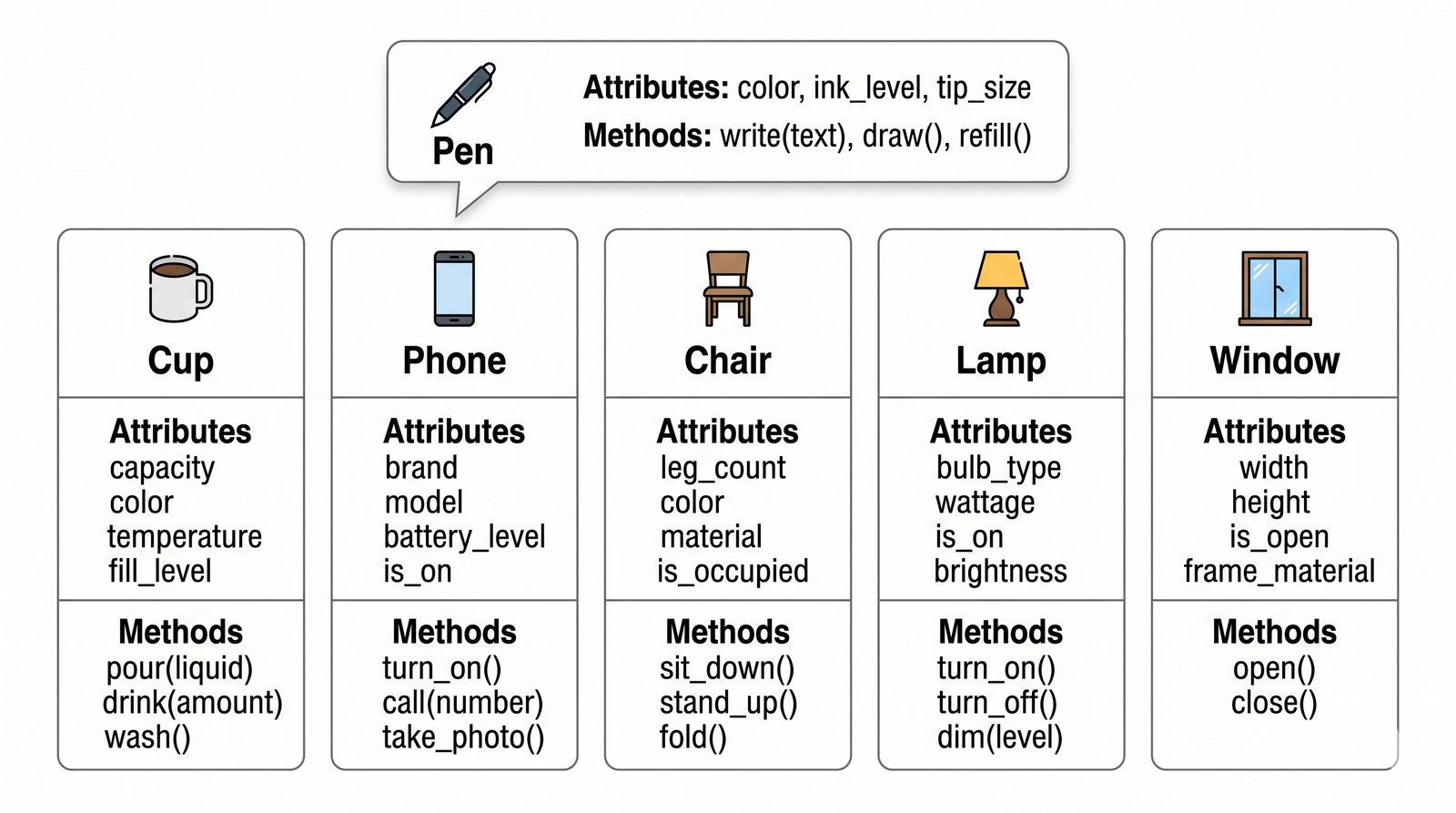
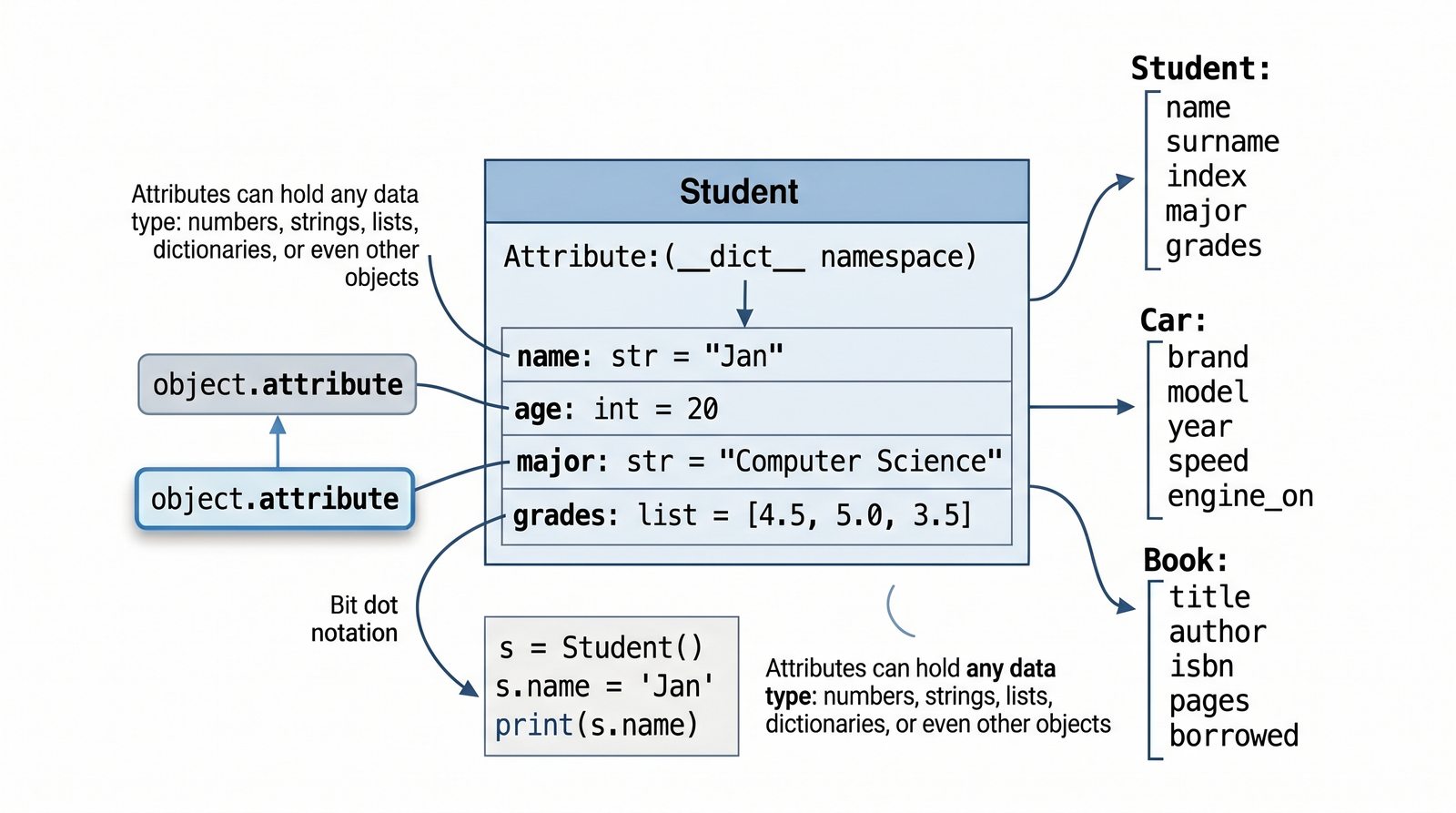
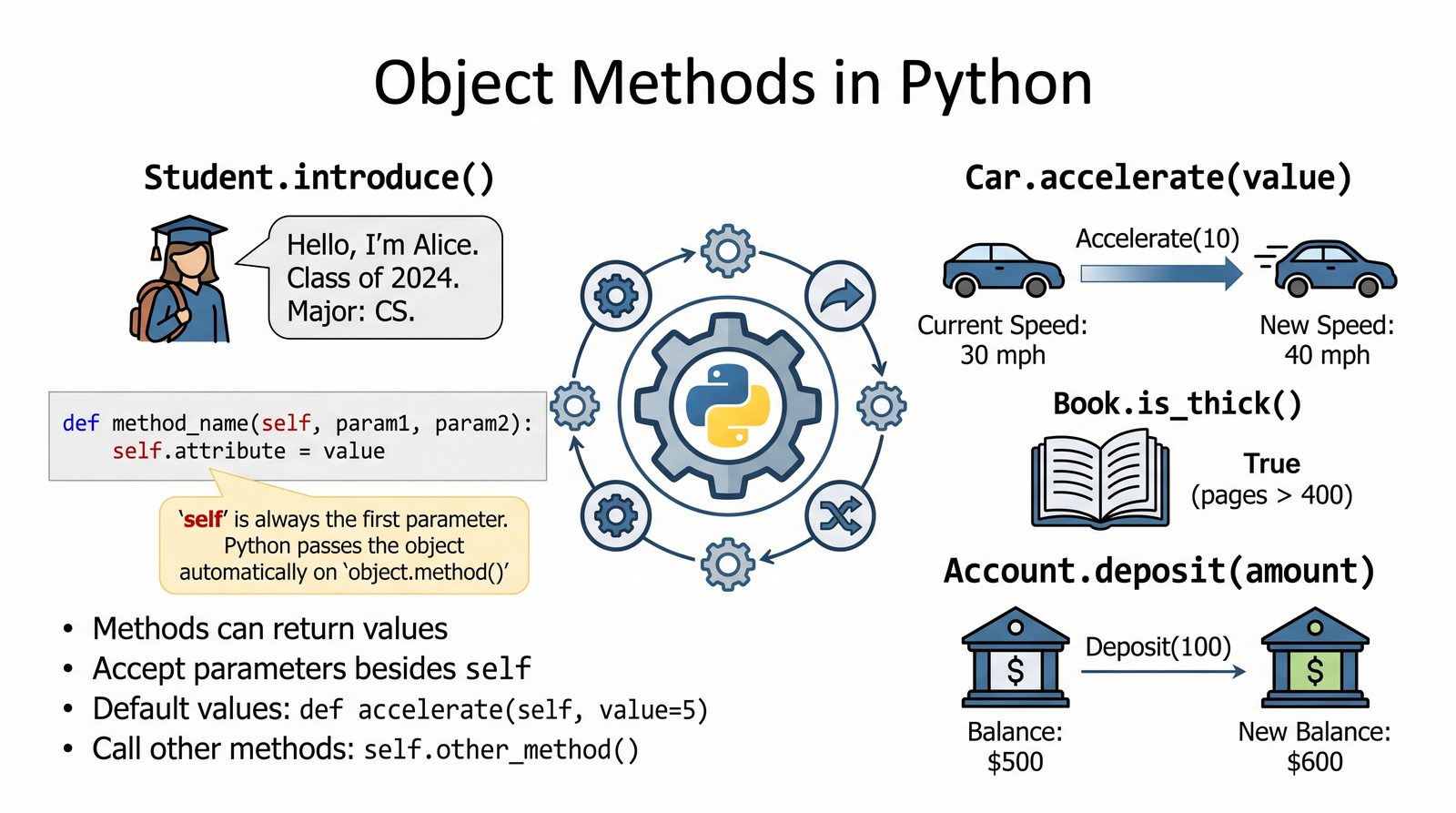
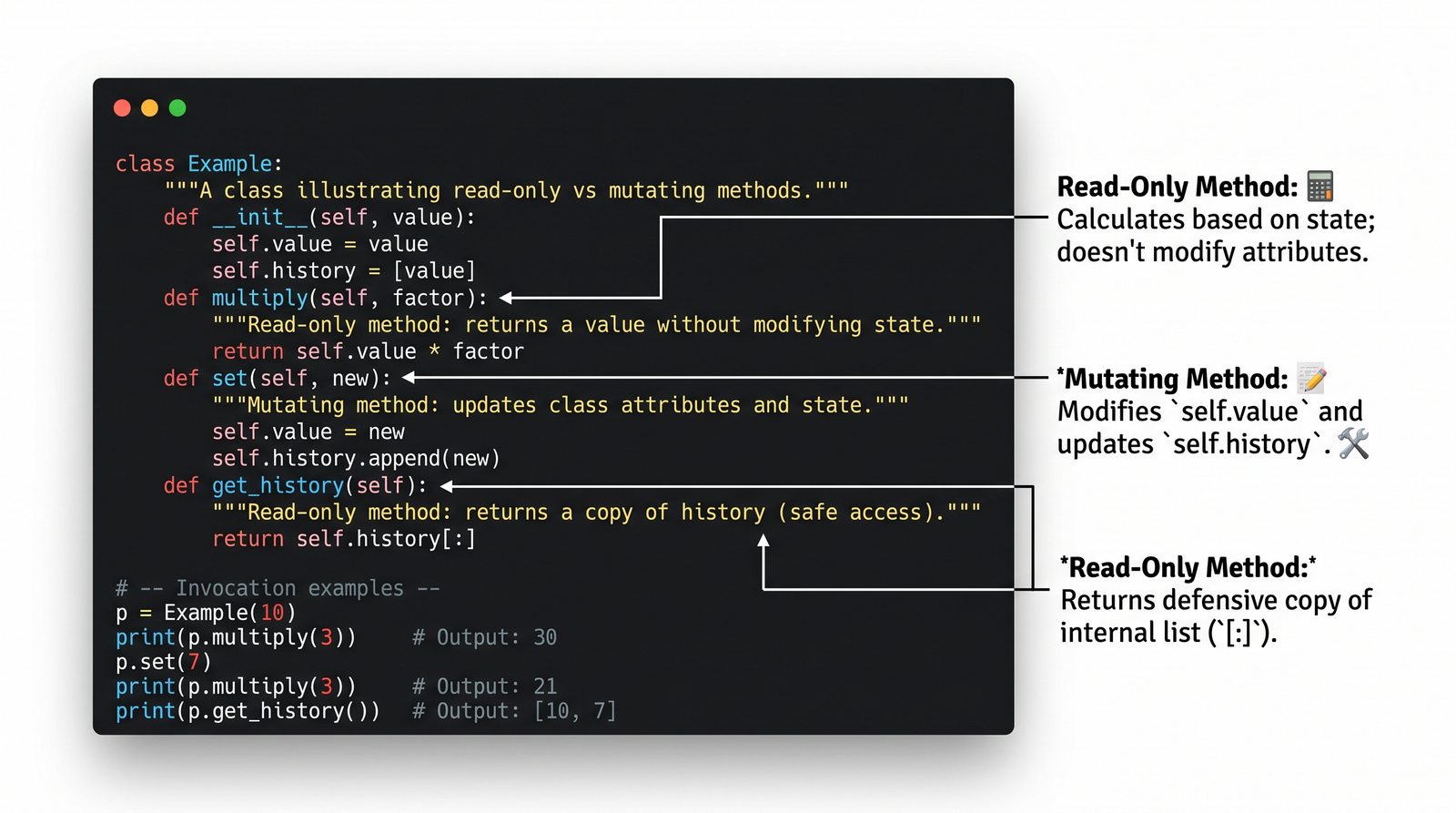
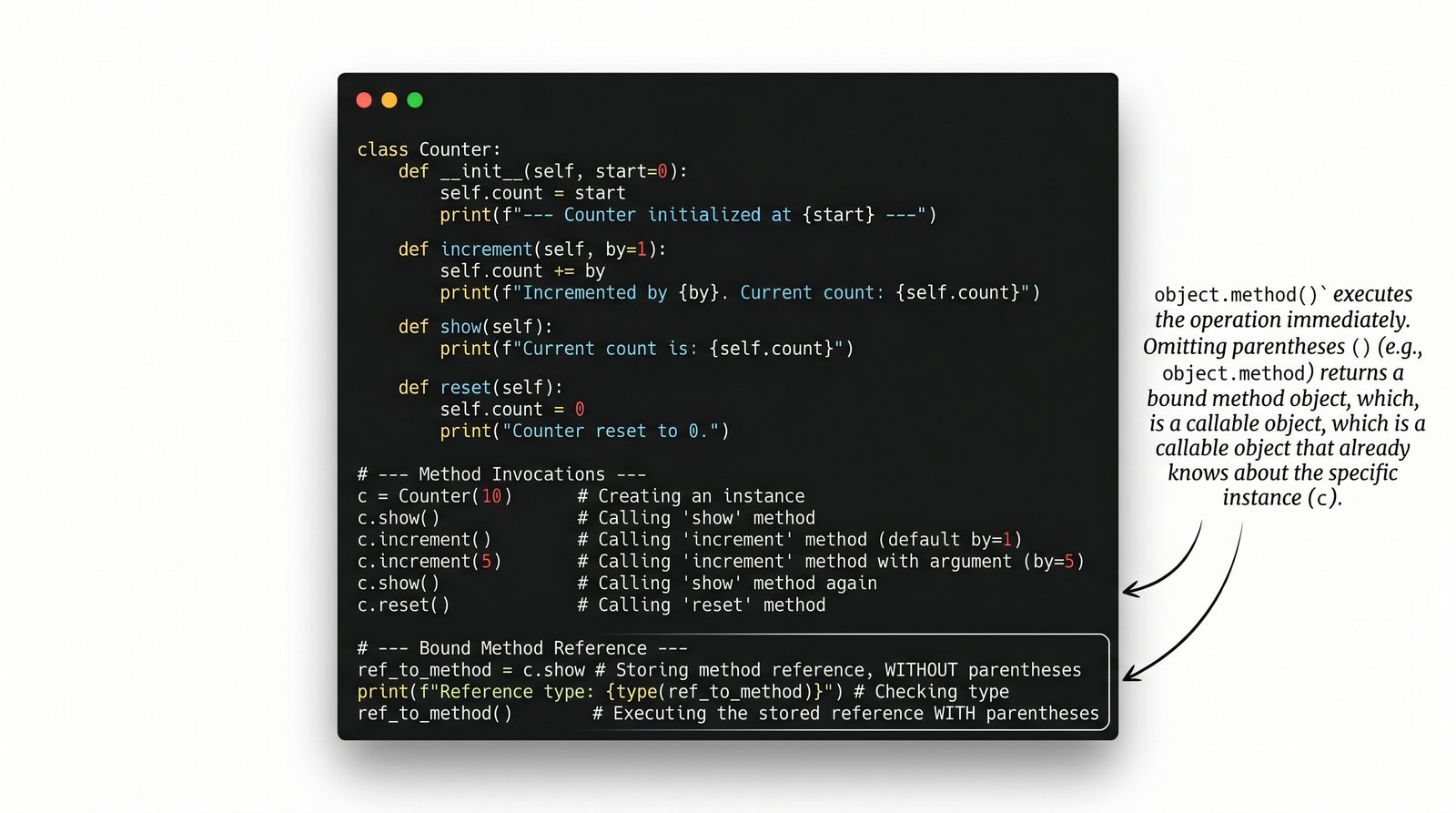
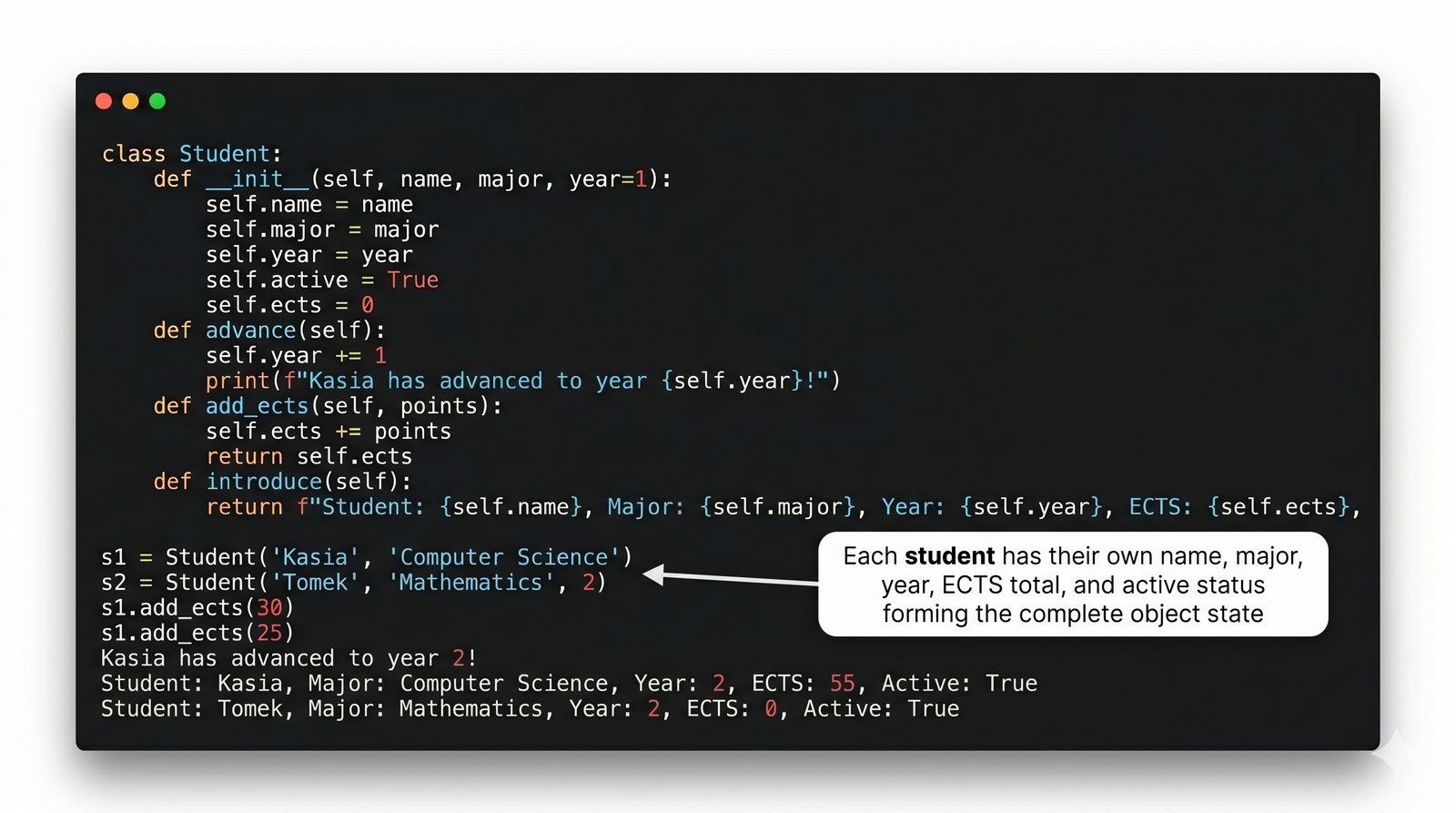
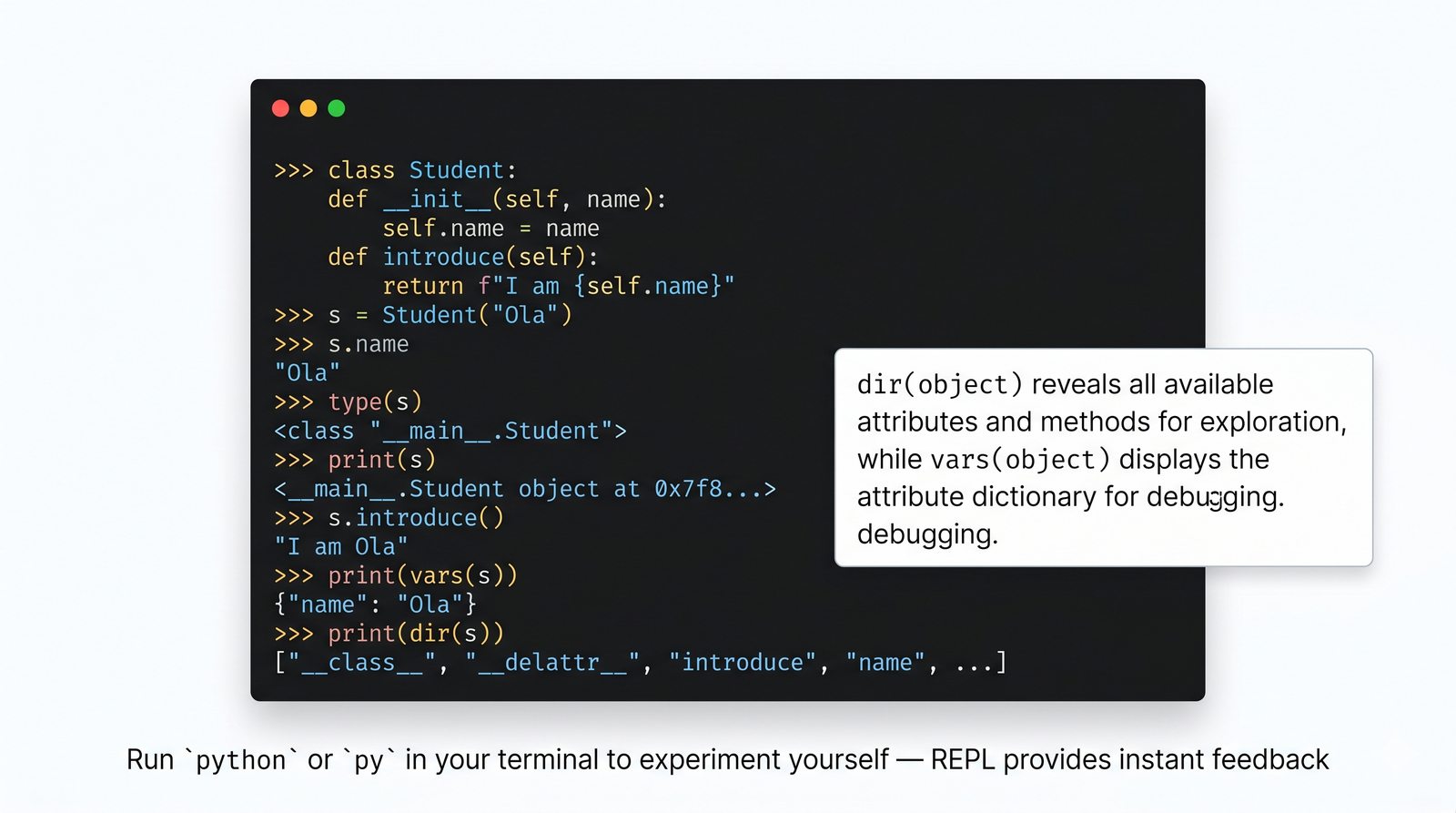
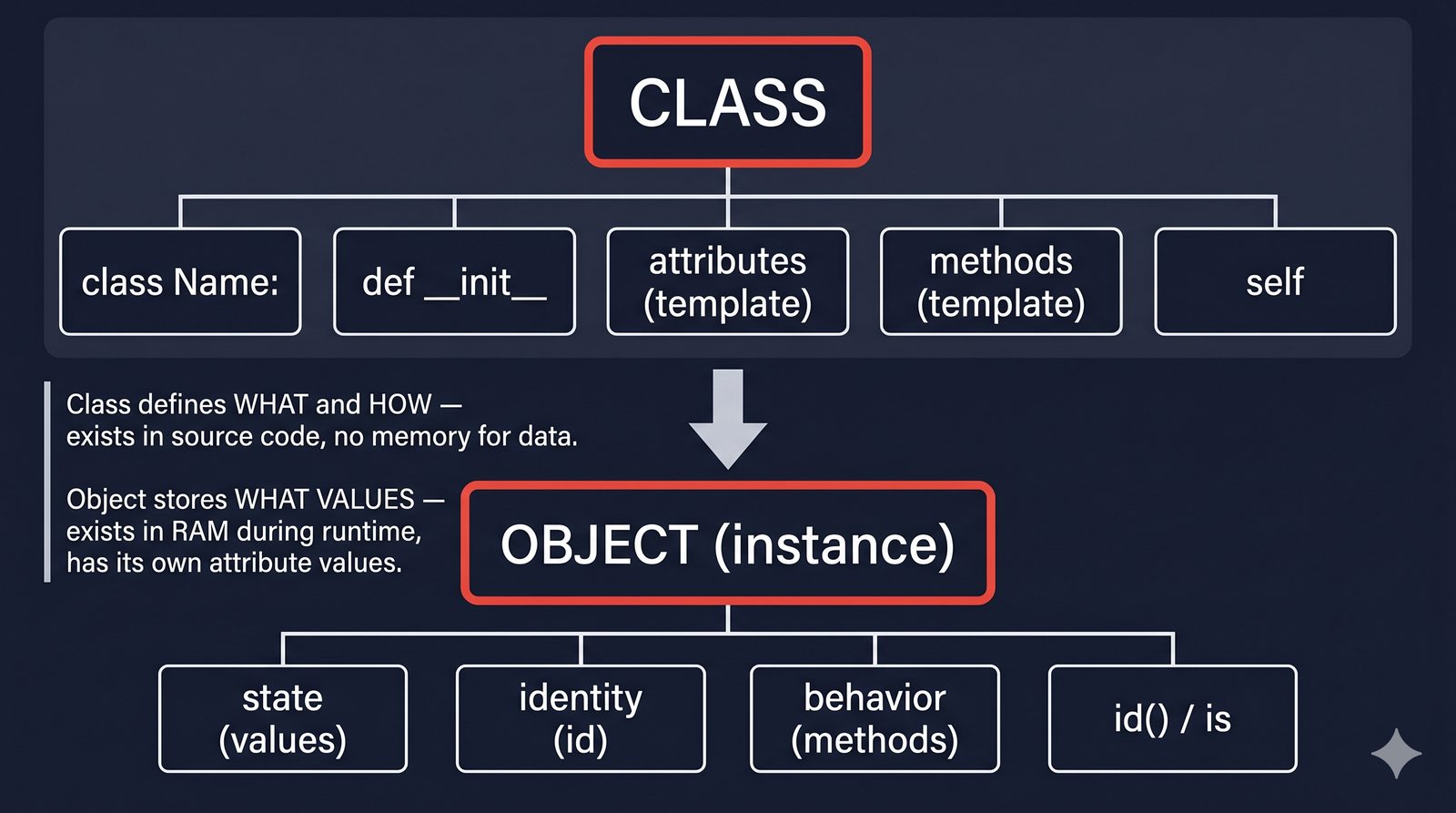
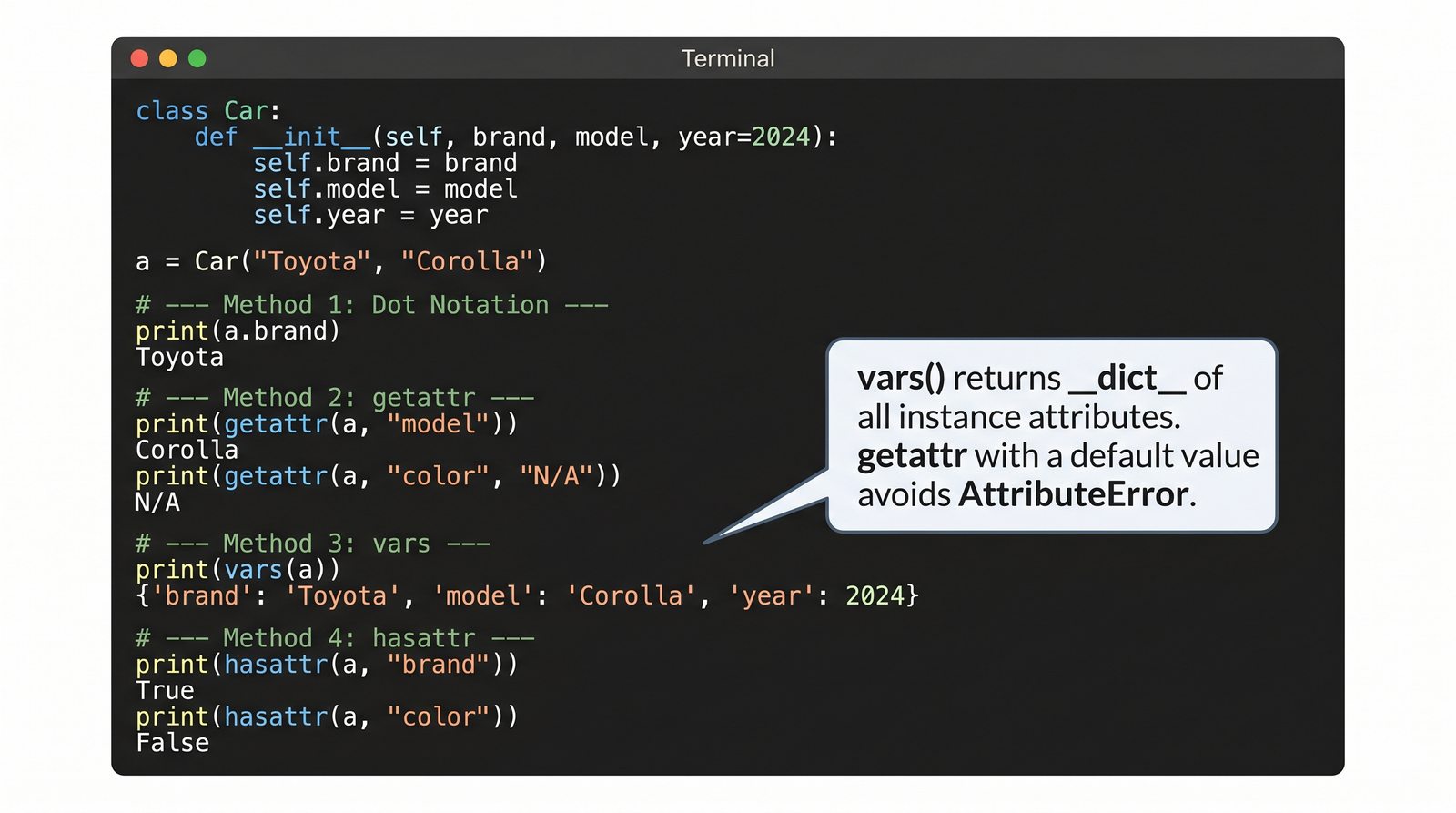
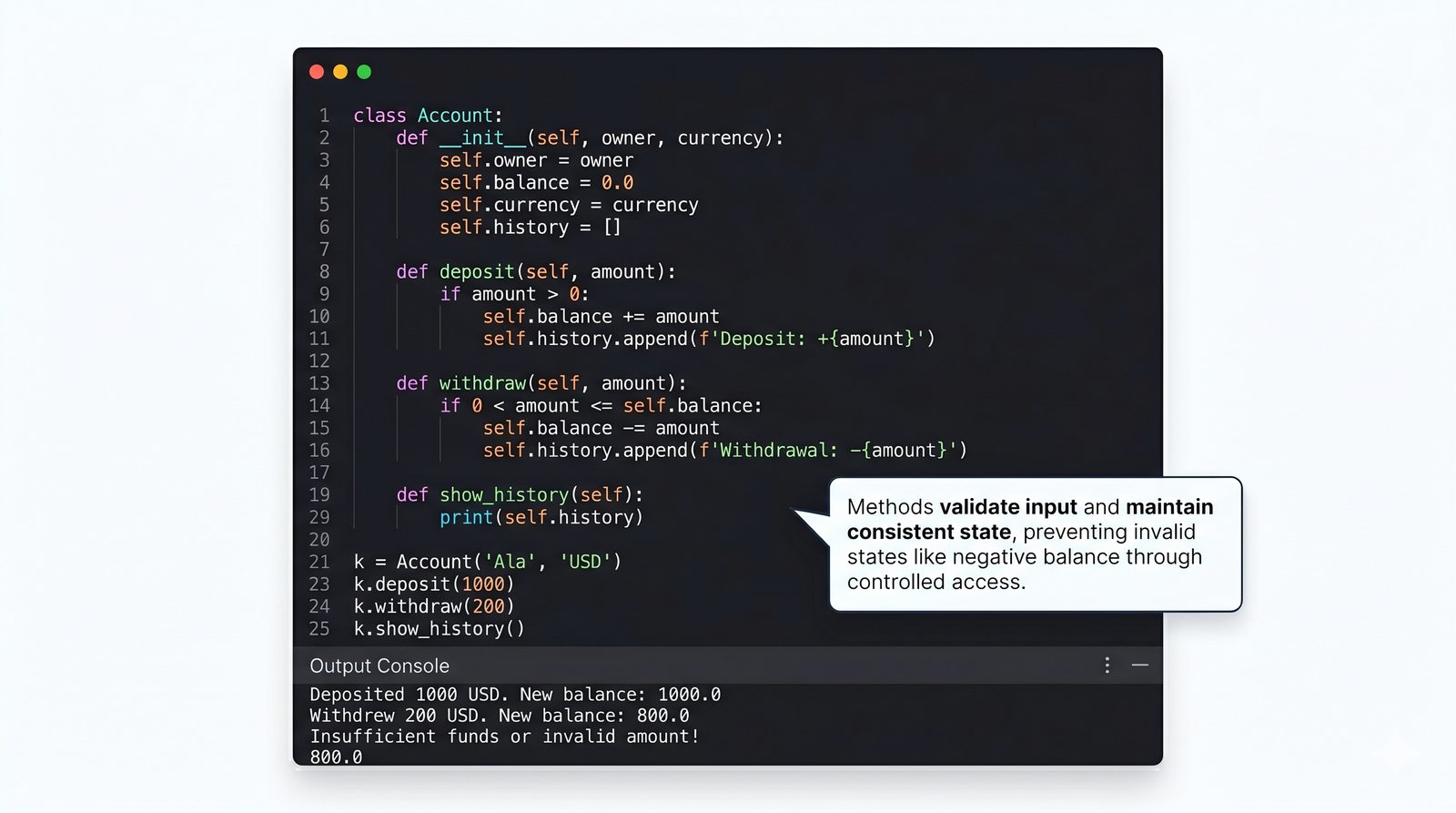
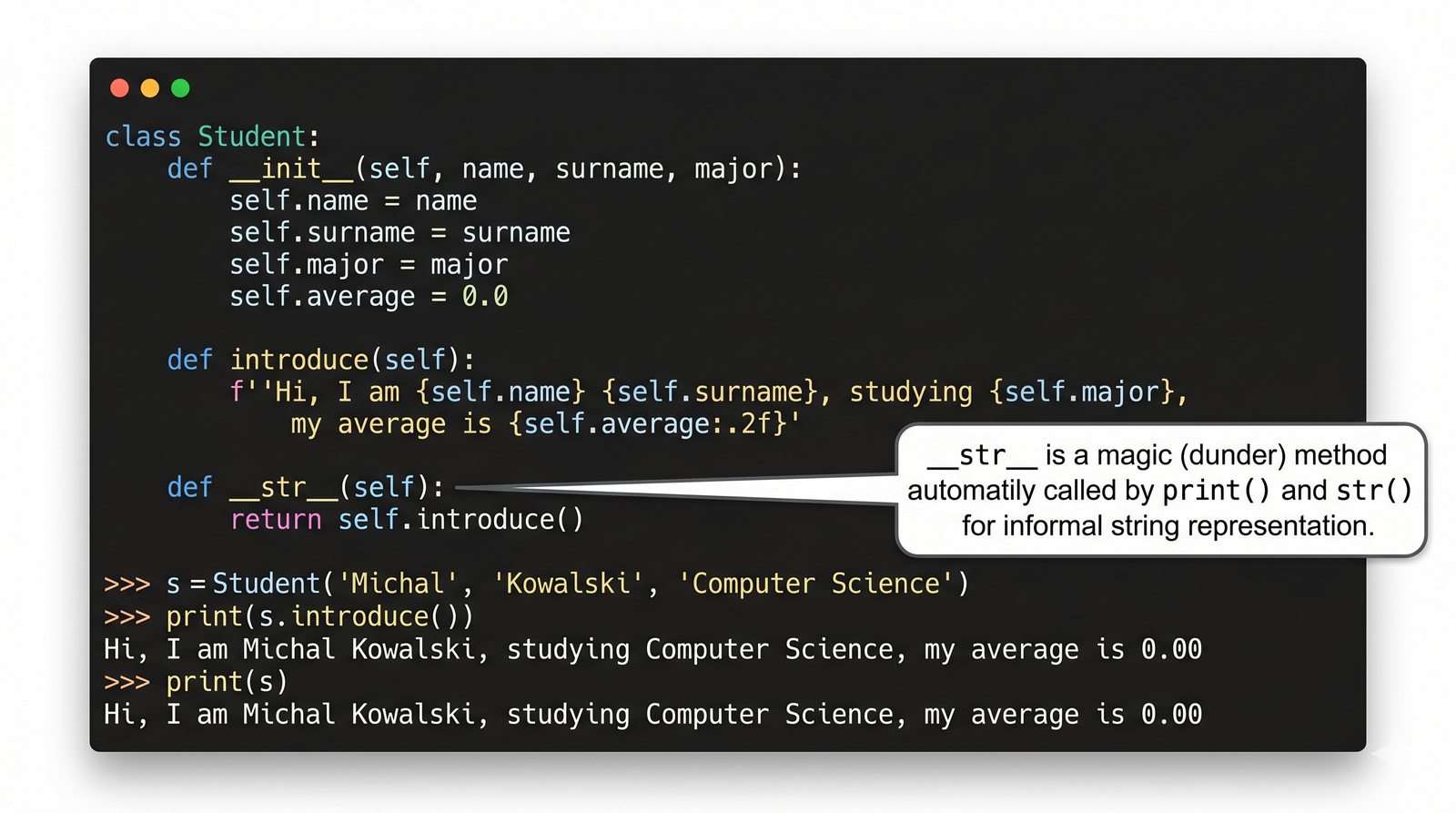
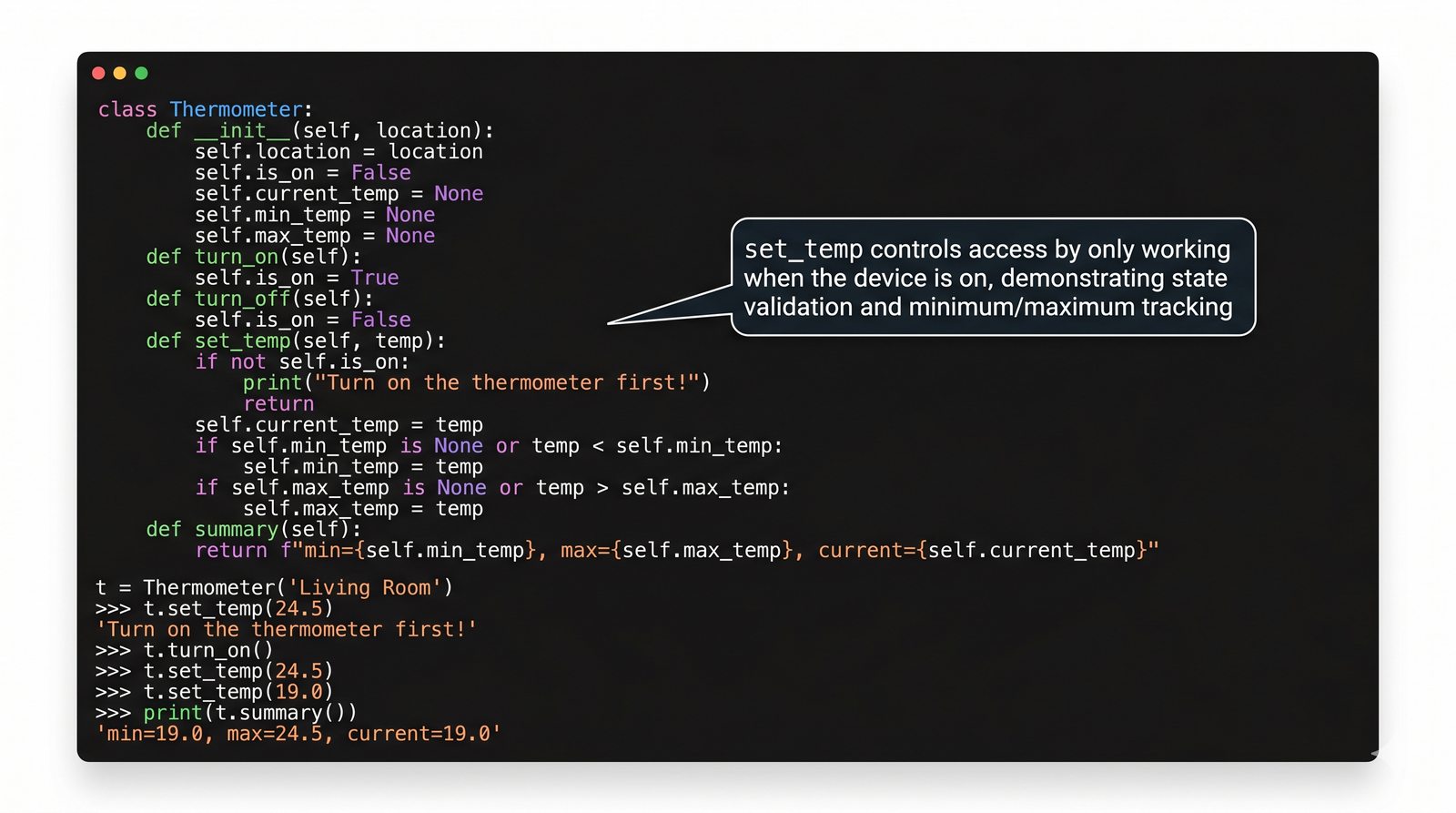
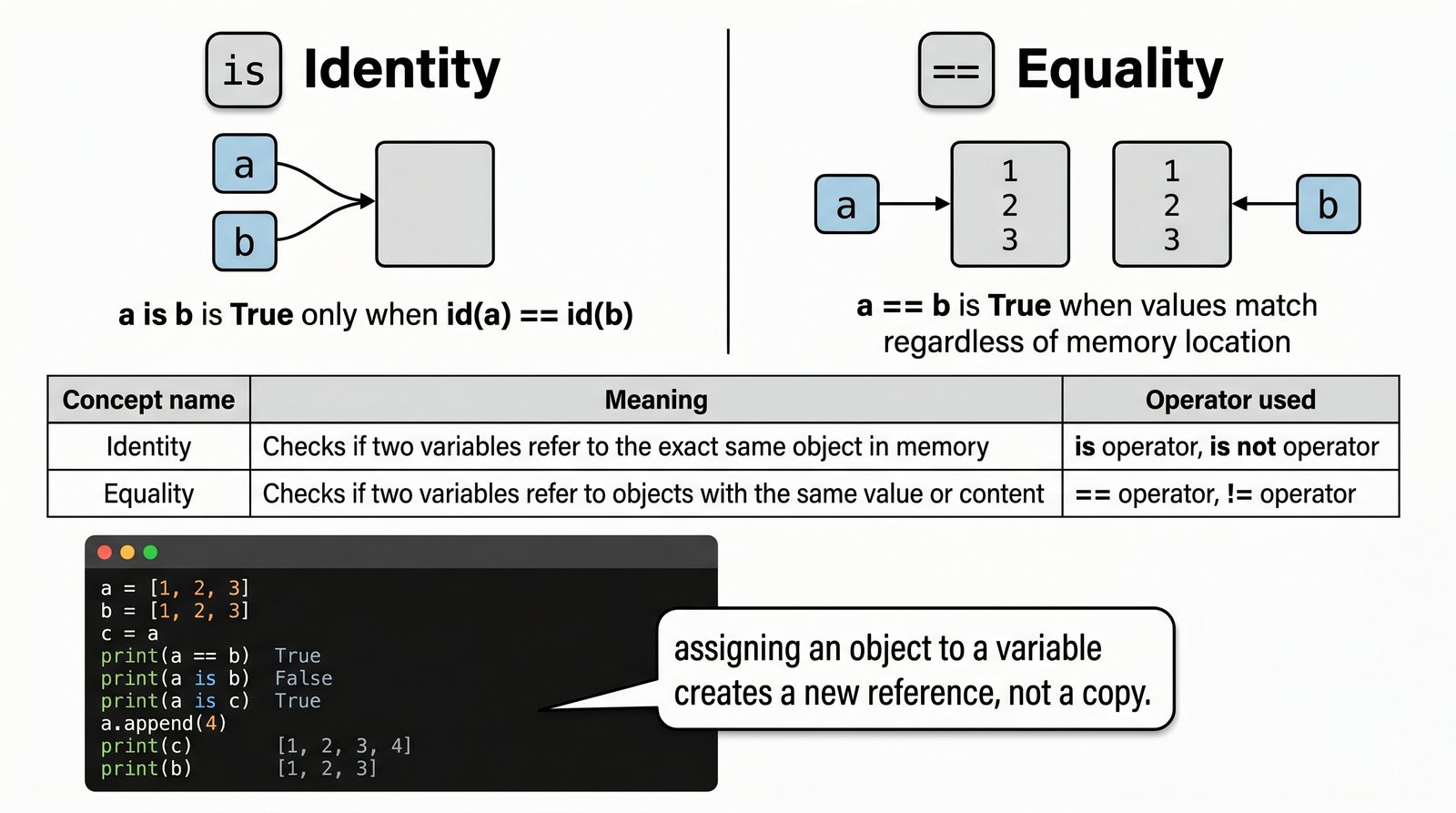
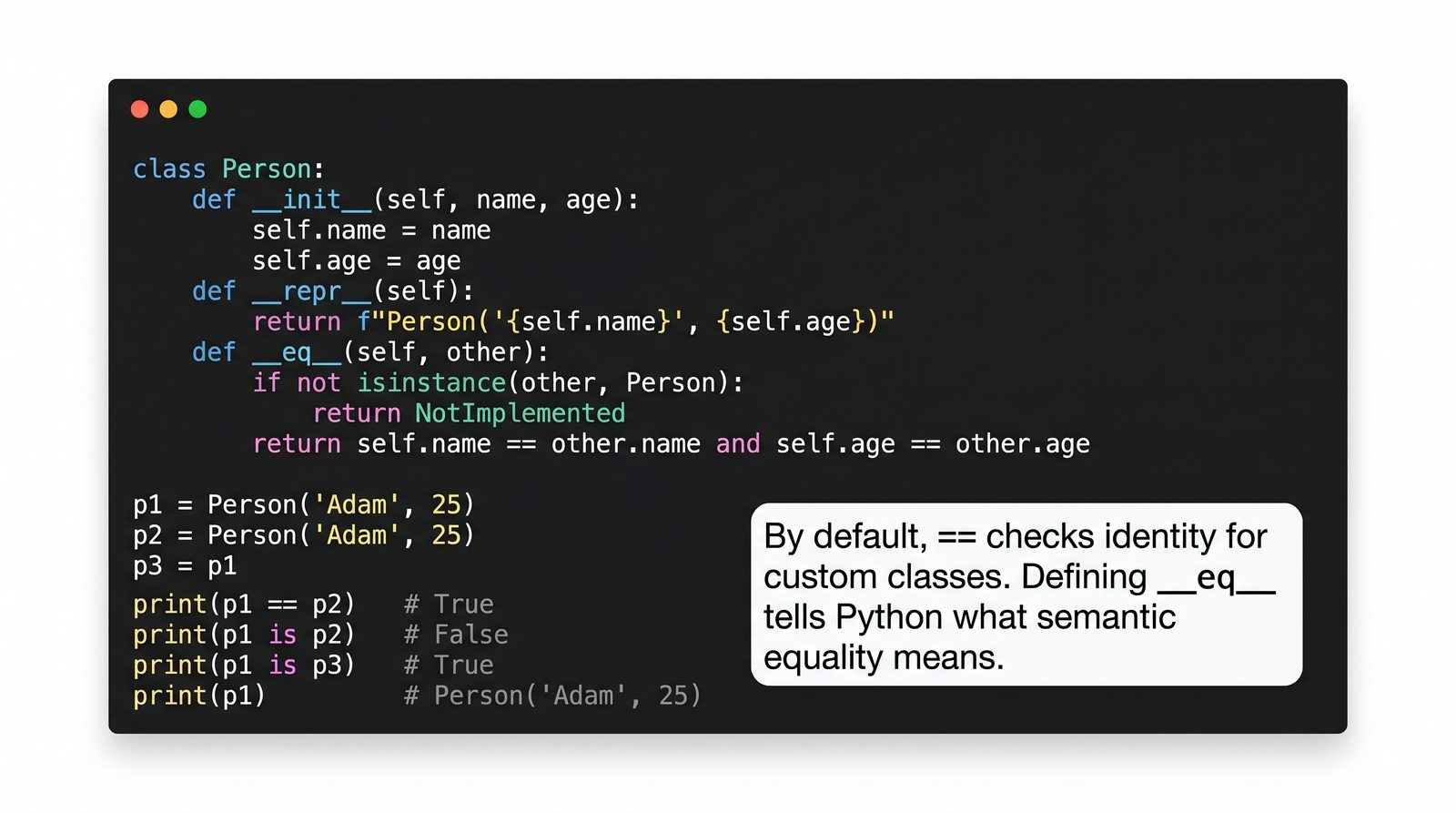
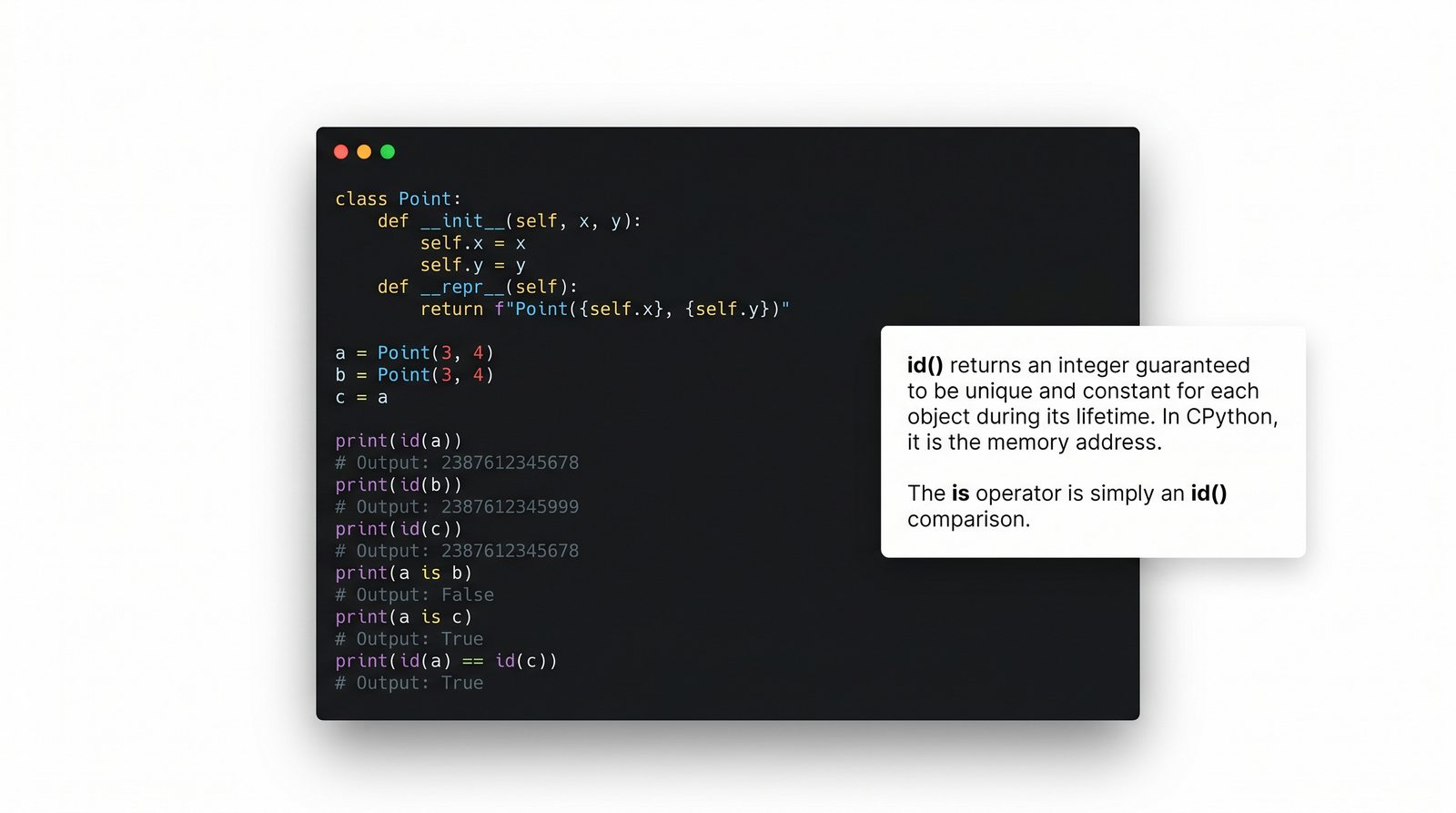
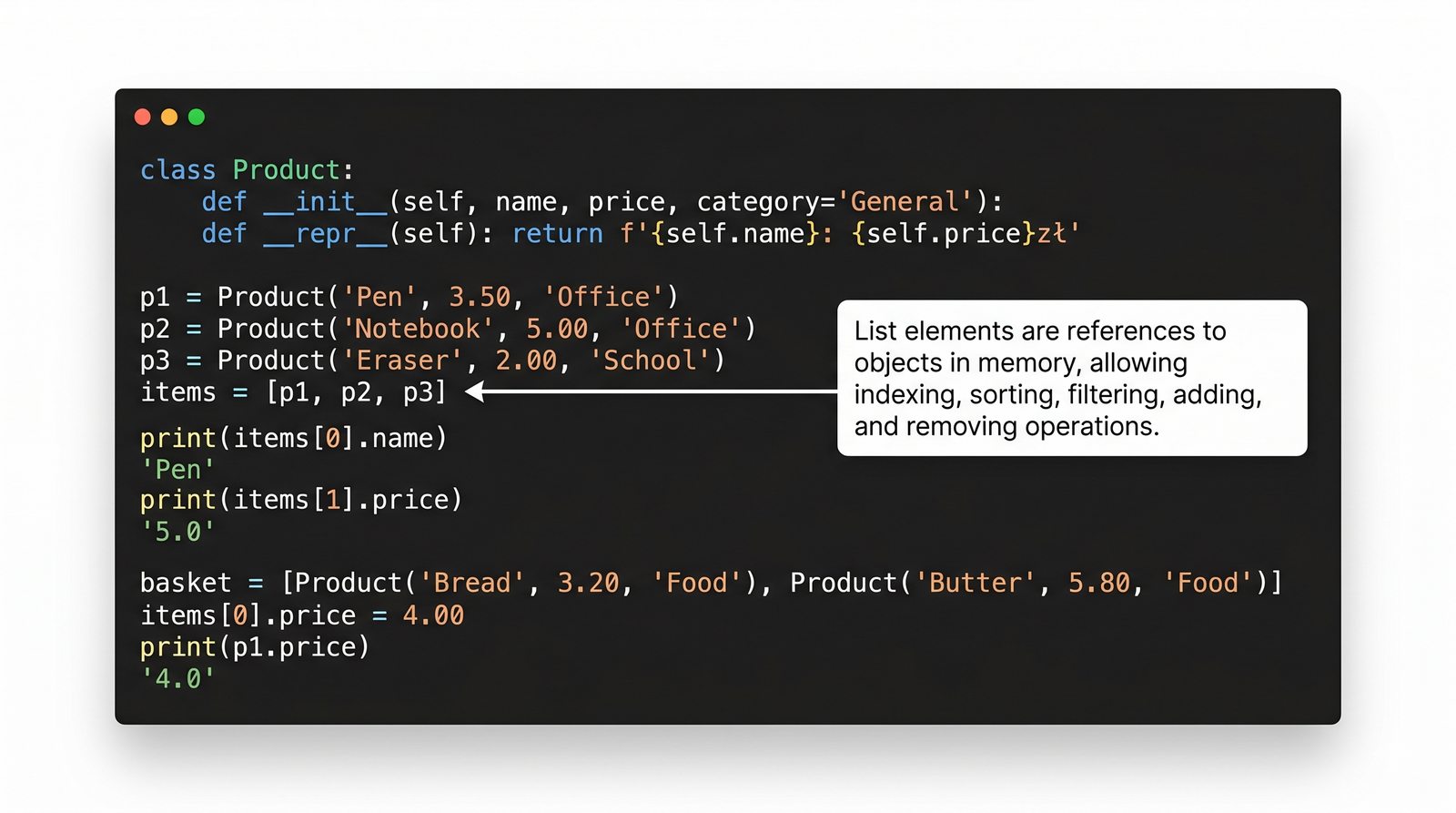
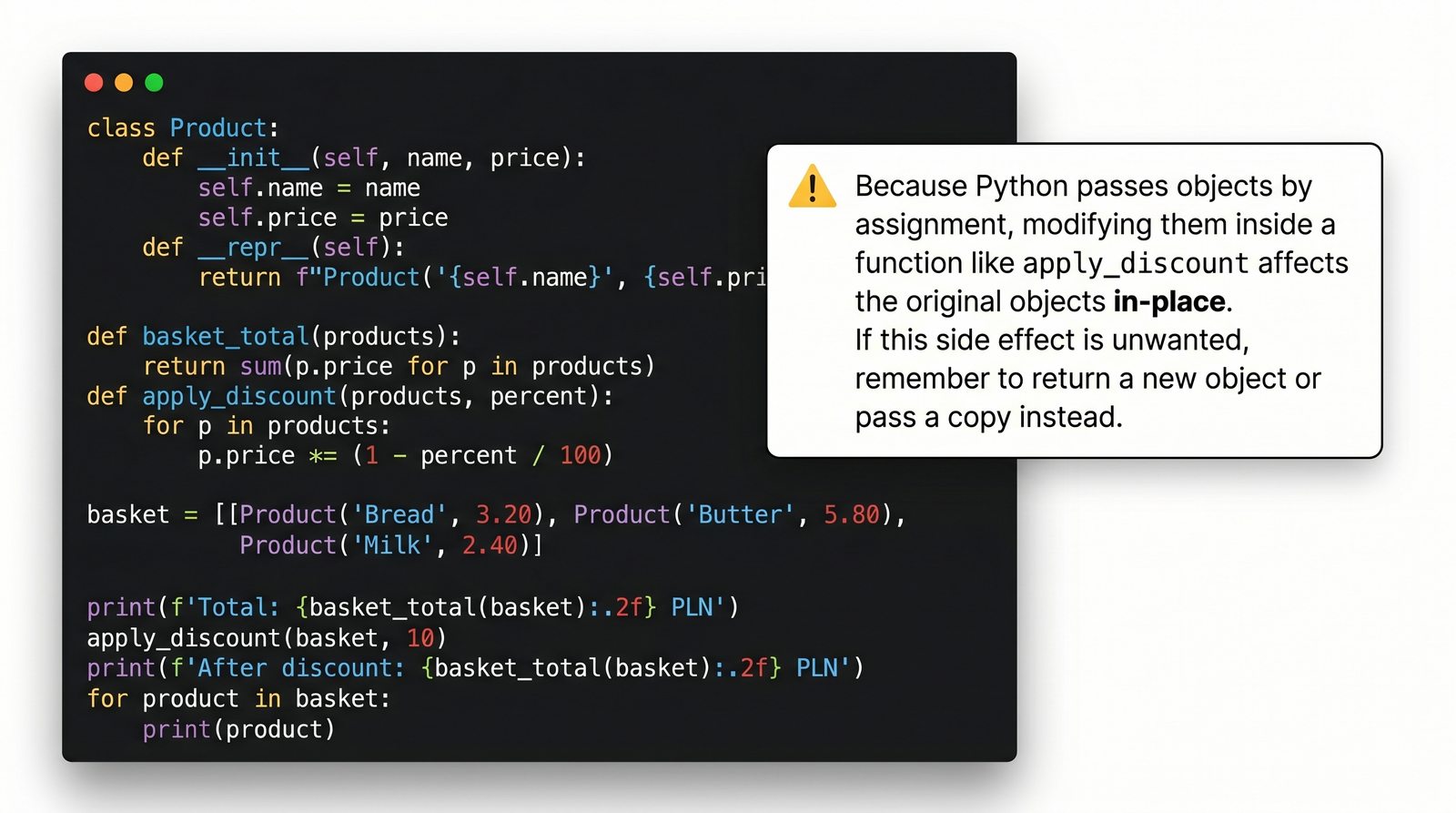
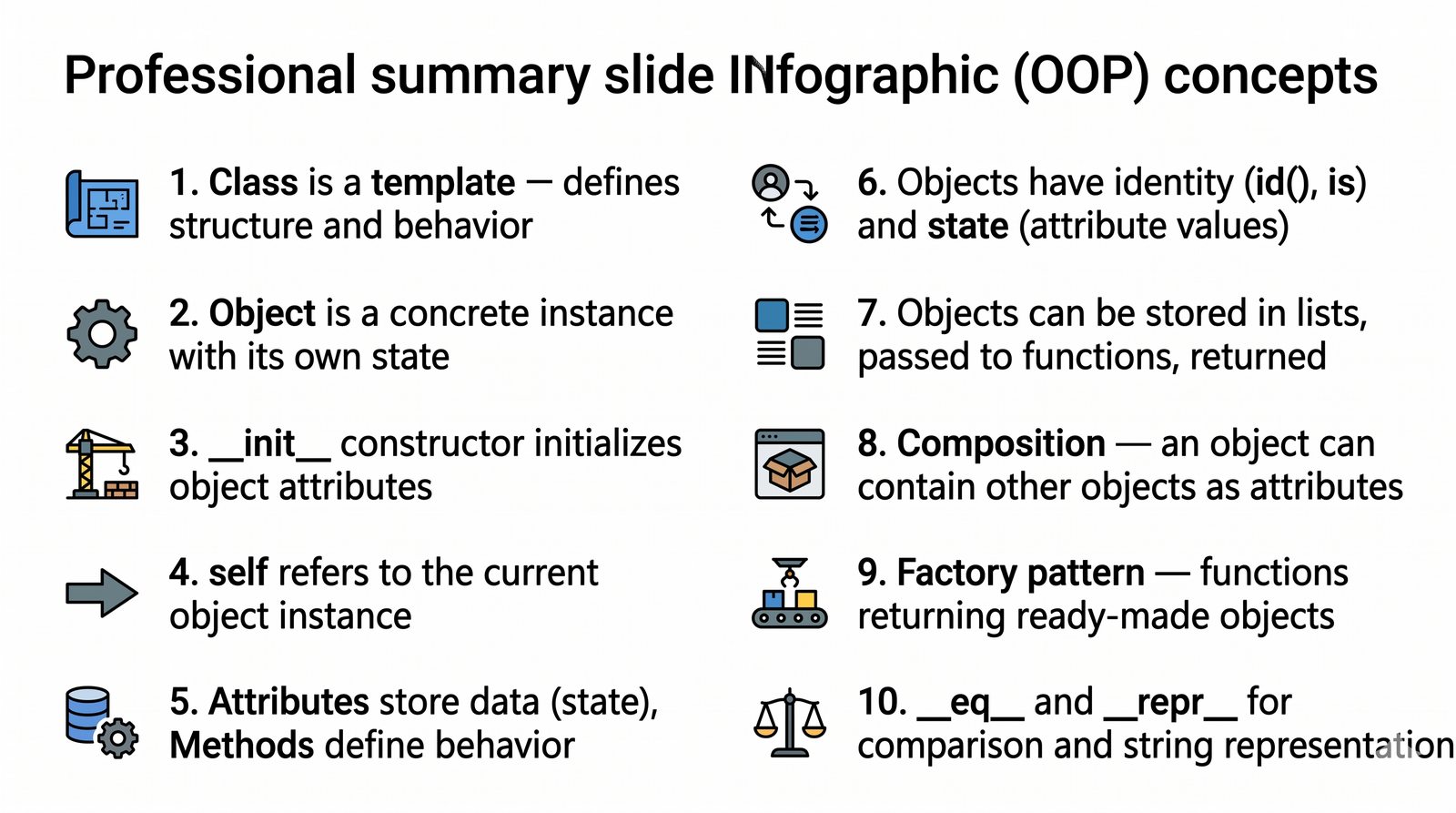
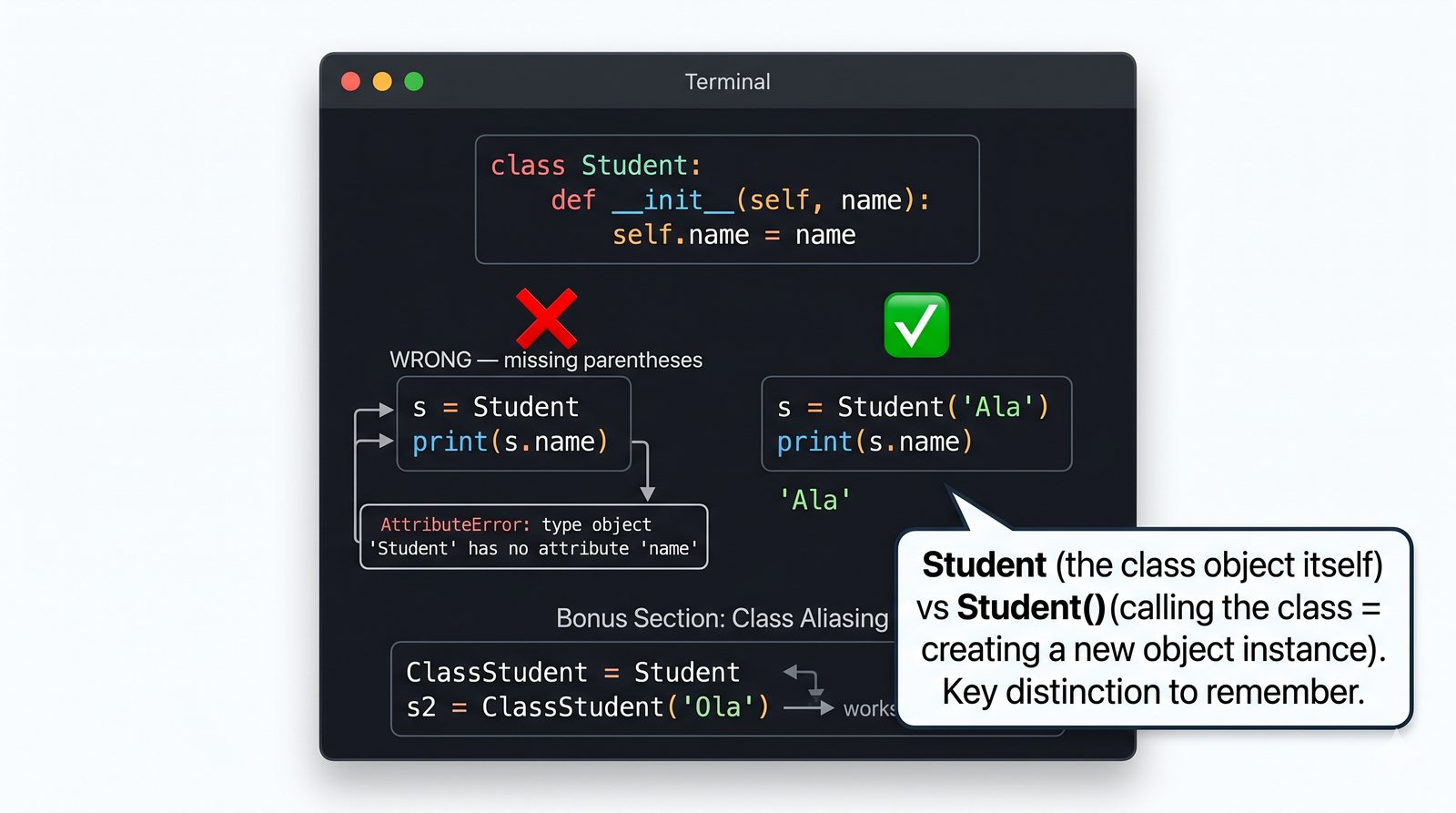
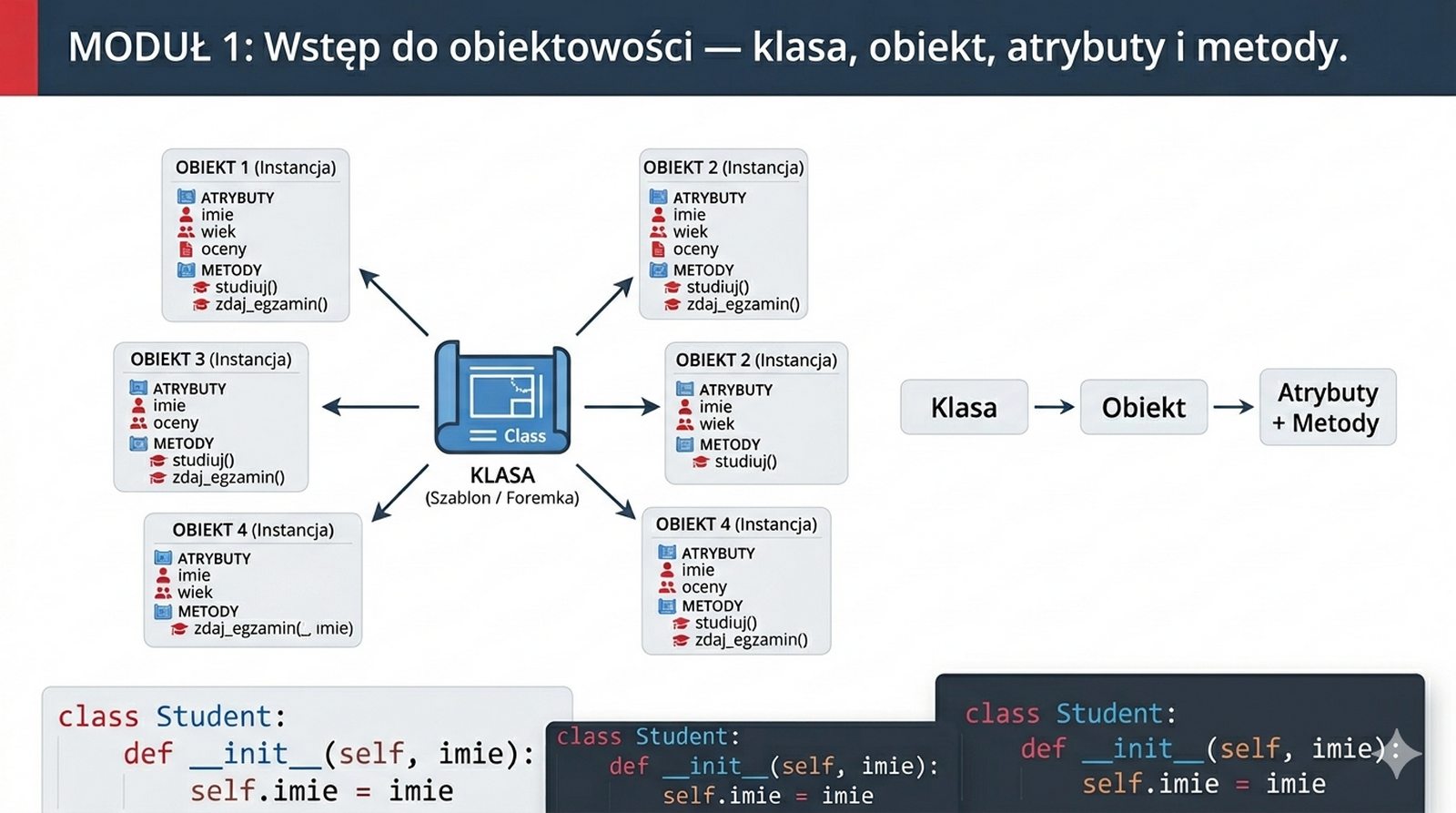
W tej części poznasz fundamentalne pojęcia: klasę , obiekt , atrybuty , metody oraz konstruktor . Zrozumiesz, czym różni się myślenie obiektowe od proceduralnego i dlaczego OOP dominuje w nowoczesnych systemach informatycznych.
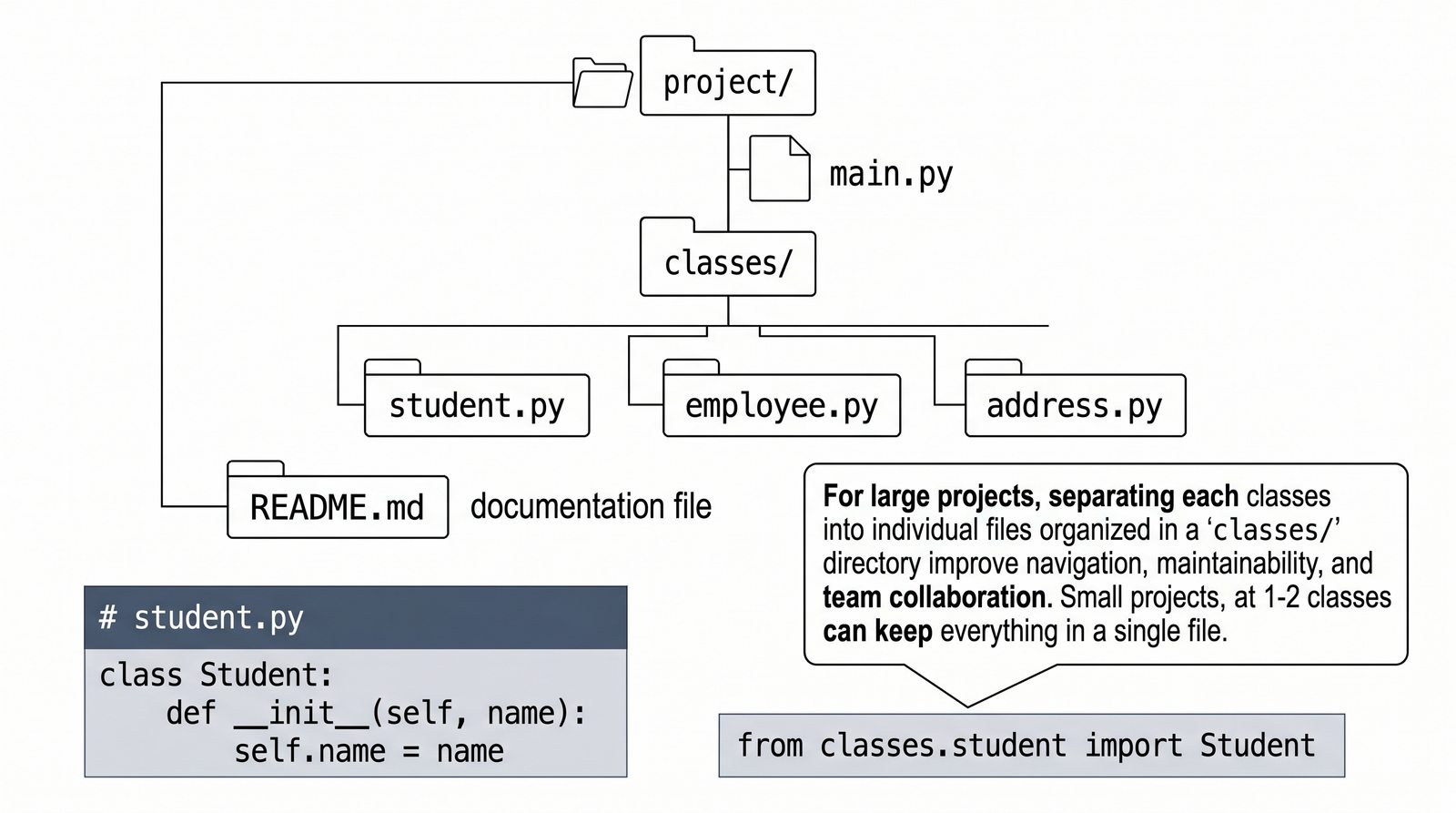
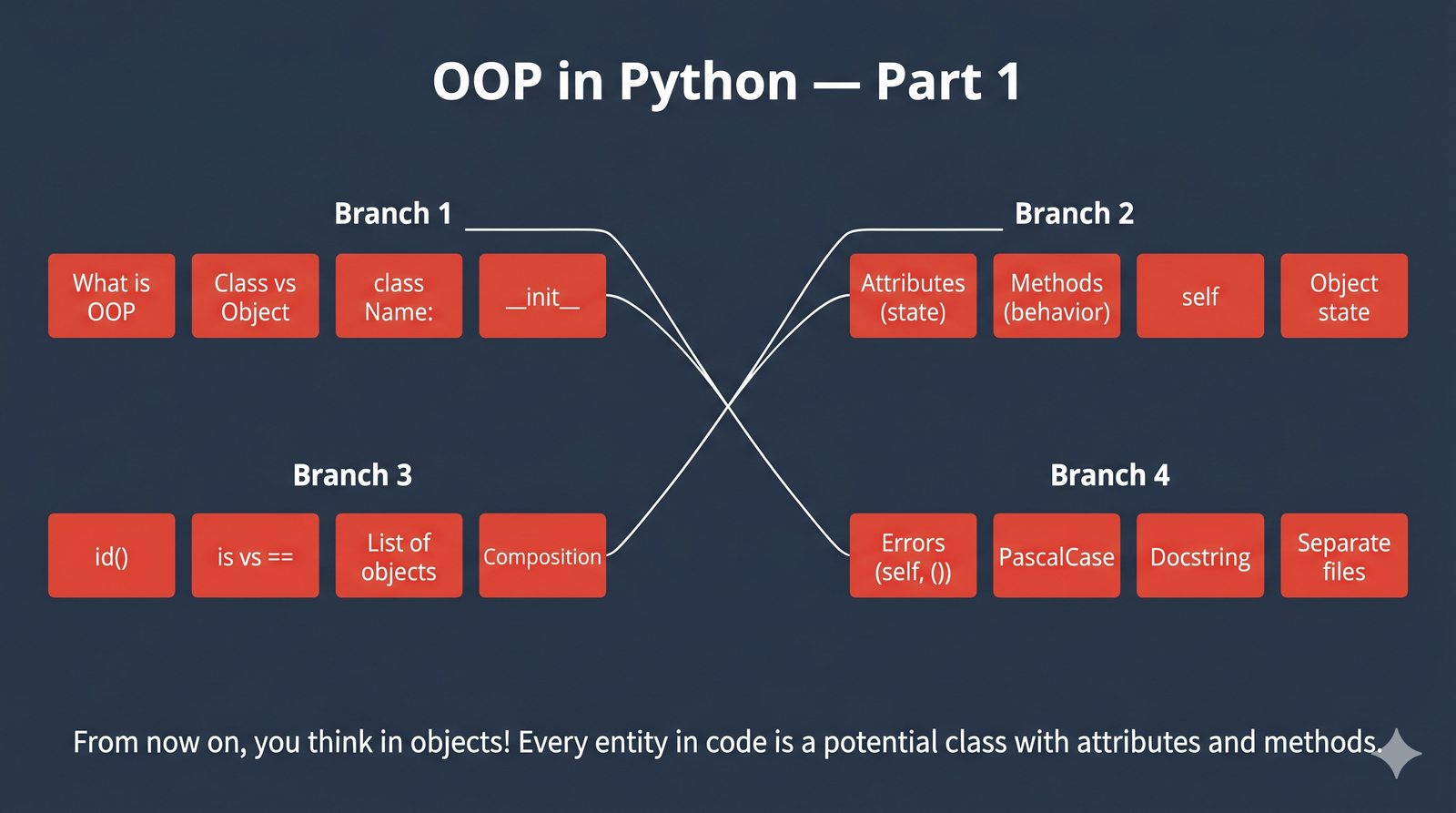
Kurs obejmuje 50 slajdów z przykładami kodu, ćwiczeniami, quizem i mapami myśli. Każdy slajd został zaprojektowany tak, by stopniowo budować Twoje zrozumienie - od analogii ze świata rzeczywistego po konkretne implementacje w Pythonie.